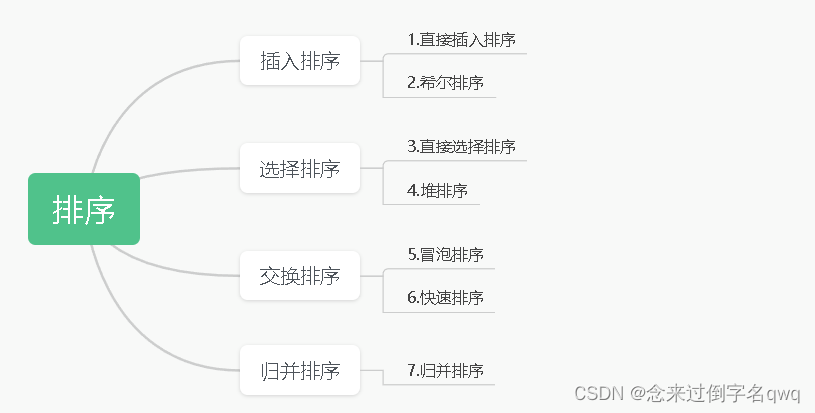
文章目錄
- 相關概念
- 1. 冒泡排序(Bubble Sort)
- 2. 直接插入排序(Insertion Sort)
- 3. 希爾排序(Shell Sort)
- 4. 直接選擇排序(Selection Sort)
- 5. 堆排序(Heap Sort)
- 6. 快速排序(Quick Sort)
- 6.1 hoare快排(最早的快排方法)
- 優化快排(重要)
- 1. 減少函數遞歸的棧幀開銷(雖然不用,但必須了解)
- 2.三位取中法取基準值(重點)
- 6.2 挖坑法快排
- 6.3 雙指針法快排
- 6.4 非遞歸快排
- 快速排序的排序速度比較(包含測試代碼)
- 7. 歸并排序(Merge Sort)
相關概念
- 排序:所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作。
- 穩定性:說簡單點就是有相同值時,排序后這些相同值互相順序沒發生變化則稱為穩定的排序算法。假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序算法是穩定的;否則稱為不穩定的。
- 內部排序:數據元素全部放在內存中的排序(重點)。
- 外部排序:數據元素太多不能同時放在內存中,根據排序過程的要求不能在內外存之間移動數據的排序(了解)。
常見排序算法時間、空間、穩定性:
- 直接插入排序:O(n2),正常情況下最快的O(n2)排序算法,穩定。
- 希爾排序:O(n1.3),比O(n*log2n)慢一點點,不穩定。
- 直接選擇排序:O(n2),比冒泡快,比插入慢,不穩定。
- 堆排序:O(n*log2n),不穩定。
- 冒泡排序:O(n2),穩定。
- 快速排序: O(n*log2n),不穩定,空間O(log2n)。
- 歸并排序 O(n*log2n),穩定,空間O(n)。
排序不特別說明,則排序以升序為例。
時間復雜度不特別說明,則默認最壞時間。
空間復雜度不特別說明,則默認O(1)。
1. 冒泡排序(Bubble Sort)
思想:兩兩比較,再交換。前一個值比后一個值大,交換兩個值。


優化冒泡排序,冒泡排序優化版:

void BubbleSort(int* a, int n)
{int sortBorder = n - 1;int lastExchange = 0; for (int i = 0; i < n - 1; ++i) {bool isSorted = true; for (int j = 0; j < sortBorder; ++j) {if (a[j] > a[j + 1]) {Swap(&a[j], &a[j + 1]);isSorted = false;lastExchange = j;}}if (isSorted) {break;}sortBorder = lastExchange;}
}
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}
2. 直接插入排序(Insertion Sort)
思想:類似將撲克牌排序的過程,數據越有序,排序越快。
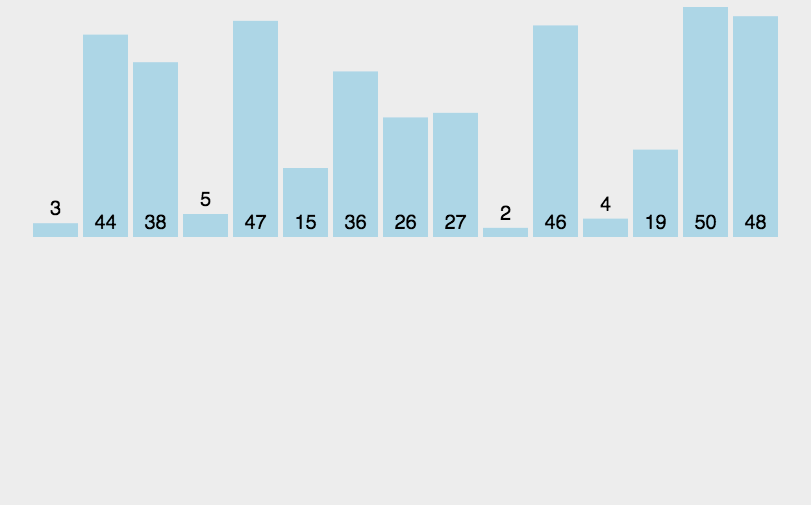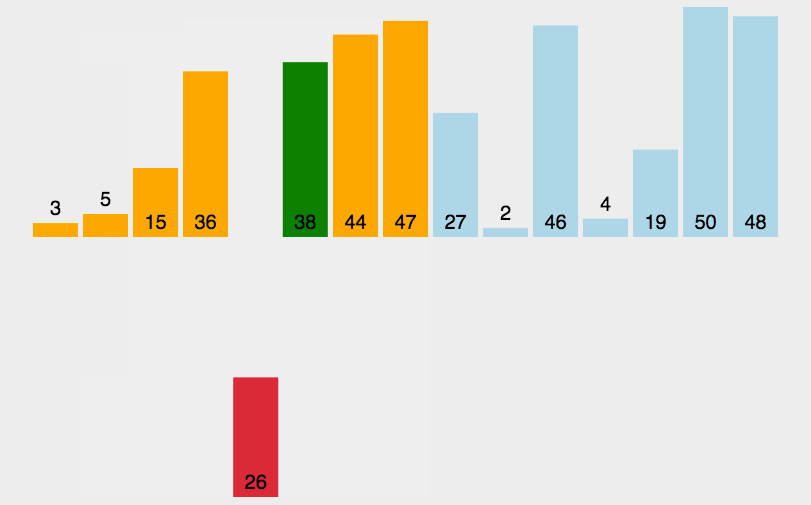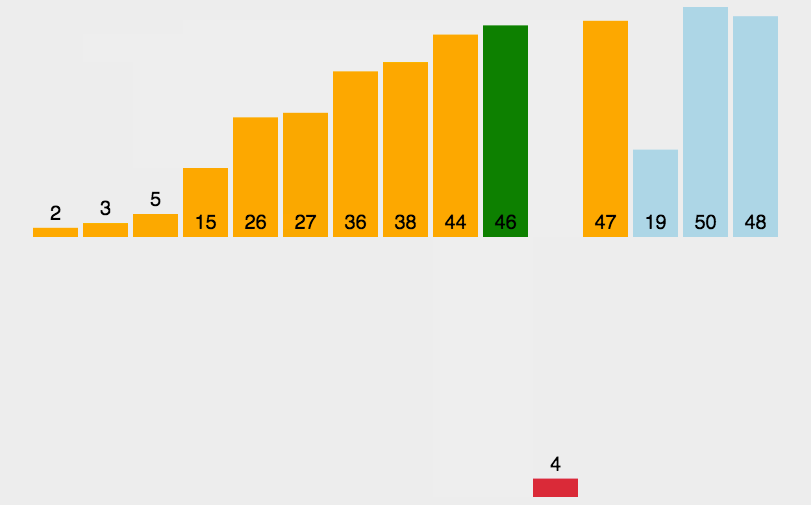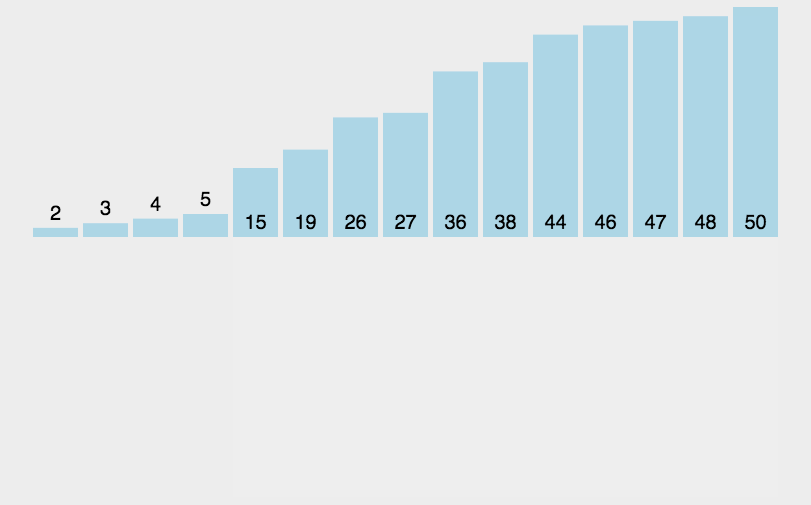

void InsertionSort(int* a, int n)
{for (int i = 0; i < n - 1; ++i){int end = i;int insertVal = a[end + 1];while (end >= 0 && insertVal < a[end]){a[end + 1] = a[end];--end;}a[end + 1] = insertVal;}
}
直接插入排序O(n*n),n方的排序中,直接插入排序是最有價值的。其它的如冒泡,直接選擇排序等與直接插入排序一樣N方的排序都是五十步和百步的區別,總體來看沒啥區別,都不如直接插入排序,看以下幾點分析以及排序時間比較,再就是大家自己編一串數據走查一下排序過程即可發現。
1.排升序而數據大致是降序,或排降序而數據大致是升序情況下,直接插入排序的時間復雜度是O(n*n),因為比較挪數據次數是等差數列之和。
2.數據大致有序,且排序順序與數據順序一致情況下,直接插入排序的時間復雜度是O(n),因為比較挪數據次數較少(不進入while循環)。比如排升序,而數據也大致也是升序狀態(較為有序 或 直接就是有序的)。
3.雖然直接插入排序與冒泡排序的時間復雜度是同一個量級,但不談上面第一種情況,
正常大多都是數據隨機排列情況下前者比后者快很多,這時比較挪數據次數不會是等差數列之和,中間一般多少會有一部分是有序的,有那么幾趟是不進入while循環的,比較挪數據次數當然是比等差數列之和要少的。雖然還是O(n*n)的量級,但明顯是比冒泡快,至于快多少則是看有序的數據多不多(極限就是第二種情況)。
10w個數據 排序速度對比:

release環境是發布版本環境,對代碼是有很大優化的,優化點大致是:
- 相比于debug環境,release環境生成的目標文件包含很少調試信息甚至沒有調試信息。
- 減少了很多消耗性能或不必要的操作,不對代碼進行邊界檢查,空指針檢查、assert斷言檢查等。
- 特別是對遞歸優化巨大,也就是對函數棧幀的創建/棧的消耗優化很大,比如對于debug環境下棧溢出的程序,切換成release則不會造成棧溢出。
博主水平有限,不知道更多相關細節或是底層原理,如有錯誤懇請指正。
3. 希爾排序(Shell Sort)
希爾排序是直接插入排序的優化版,對于直接插入排序而言,數據越有序,排序越快,希爾排序正是借助直接插入排序的特點進行了優化。
思想:先對數據分組進行幾次預排序(對數據分組進行直接插入排序),使數據形成較為有序的情況,最后整體進行一趟直接插入排序即可完成排序。
void ShellSort(int* a, int n)
{int gap = n; while (gap > 1) {gap = gap / 3 + 1; // gap / 2也可for (int j = 0; j < n - gap; ++j) {int end = j;int insertVal = a[end + gap];while (end >= 0 && insertVal < a[end]) {a[end + gap] = a[end];end -= gap;}a[end + gap] = insertVal;}}
}
-
希爾排序不好計算確切的時間復雜度,有牛人通過大量實驗證明平均時間復雜度大致為O(n^1.3),比O(n*logn)要慢一點點,但兩者差不多是同一量級。
-
gap>1時是預排序,gap=1時等于直接插入排序。
-
gap的取值,gap/2或gap/3+1是當前主流,也被認為是gap最好的取值。gap相當于劃分多少組進行預排序,如果定死gap=1則與直接插入排序無異。gap/2或gap/3+1則是劃分每組多少個數進行預排序,gap/3+1中的+1是因為要保證最后一組排序時gap=1進行直接插入排序操作。嚴格來說只要能保證最后一趟gap=1,無論gap除以幾加幾,都算是希爾排序。
-
每一組預排序后,都會逐漸加大數據的有序情況。后面幾組預排序雖然每組劃分的數據多了(gap逐漸減小間隔變小了),也就是比較次數變多了,但經過前面的預排序后數據漸漸有序,實際不會進行過多的比較挪數據操作,每前一次預排序都為后一次預排序減輕壓力。
速度對比(毫秒):

4. 直接選擇排序(Selection Sort)
每一次從待排序的數據元素中選出最小(或最大)的一個元素,存放在序列的起始位置,逐步向后存放。
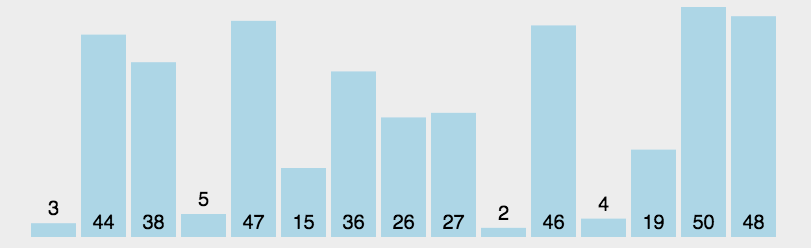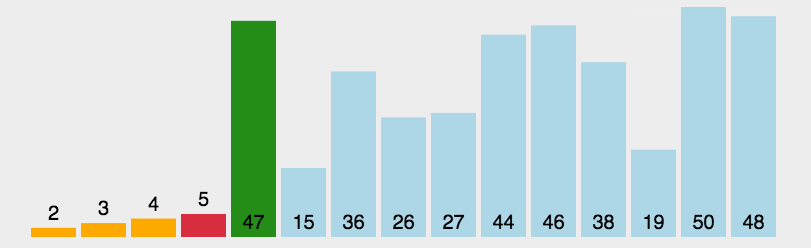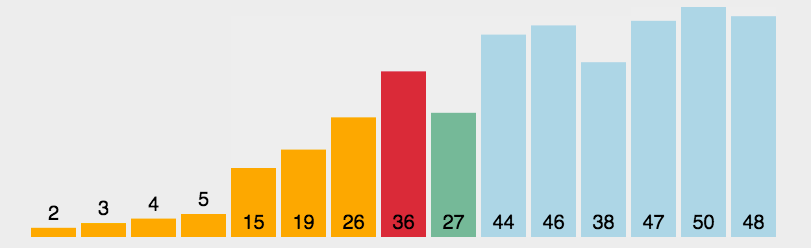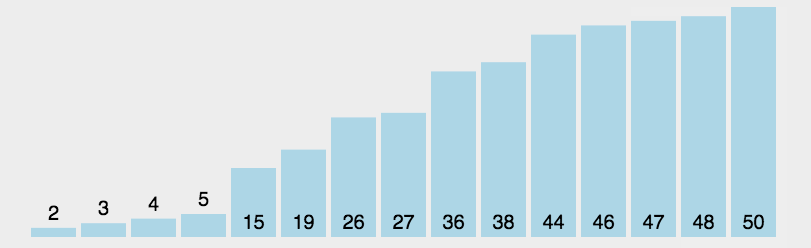

數據較為有序的情況下,直接選擇排序選要比冒泡、直接插入排序慢。
void SelectionSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int min = begin, max = end;for (int i = begin; i <= end; ++i){if (a[i] < a[min]) min = i;if (a[i] > a[max]) max = i;}Swap(&a[begin], &a[min]);if (max == begin){max = min;}Swap(&a[end], &a[max]);++begin; --end;}
}
在優化版中,必須有這樣一個判斷max==begin,并更新max的下標值!最小的數a[min]換到了左邊begin位置,如果最大的數的下標max正好等于begin,那就出現這種問題:最大的數a[max]已經被換到min下標位置了,即a[min]才是最大數;而本來a[max]是最大的數,由于max==begin,而經過前面a[begin]與a[min]交換的影響,導致a[begin]/a[max]變成了最小的數,不加判斷并更新max的后果是把最小的數放在右邊end位置了。
5. 堆排序(Heap Sort)
了解堆請看:文章 堆 / 堆排序 / TopK問題(Heap)
時間復雜度O(nlog2n),排序速度與希爾差不多。也可以向上調整建堆,但比向下調整建堆要慢一些。
void HeapSort(int* a, int n)
{for (int parent = (n - 1 - 1) / 2; parent >= 0; --parent) {AdjustDown(a, n, parent);}for (int end = n - 1; end > 0; --end){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);}
}
/* 將堆向下調整為大堆 */
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1; // 選出較大子節點child = child + 1 < size && a[child + 1] > a[child]? child + 1 : child;while (child < size && a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child; // 重復往下child = parent * 2 + 1;child = child + 1 < size && a[child + 1] > a[child]? child + 1 : child;}
}
parent初始為最后一個非葉子節點(多一個 -1 的原因),
向下調整(建大堆),往堆頂方向走把所有非葉子結點調整一遍。
堆頂最大值與堆底較小值交換,然后排除這個堆底的最大值(a[end]),
剩下的作為堆,從堆頂較小值開始向下調整為大堆(–end一步步排除新的最大值a[end])。
10w個數據,排序速度對比:

堆排序時間復雜度嚴格來算:
- 向上調整建堆O(nlogn) + 排序O(nlong):O(2n*2logn)。
- 向下調整調整建堆O(n) + 排序O(nlogn):O(2n*logn)。
所以說希爾排序O(n1.3)比O(n*log2n)要慢些,但卻是同一量級。不過堆排序的時間復雜度嚴格來說比真正的O(nlog2n)要慢一點點,所以希爾排序與堆排序的速度相同。
6. 快速排序(Quick Sort)
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法。
6.1 hoare快排(最早的快排方法)
基本思想:取待排序數據中的某個元素作為基準值,將數據分割成兩子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后左右子序列重復該過程進行分割,直到所有元素都排列在相應位置上為止。
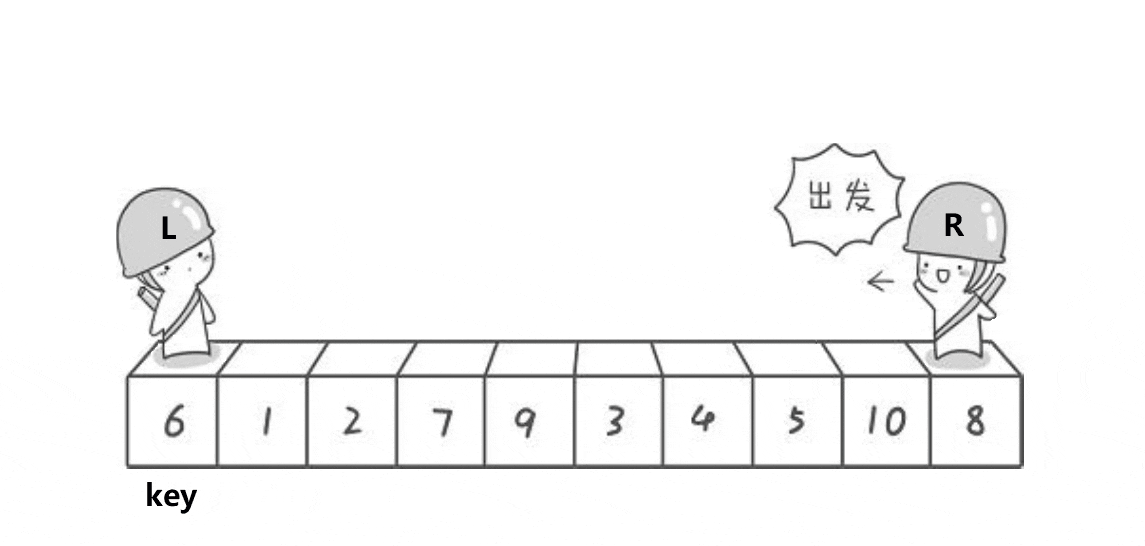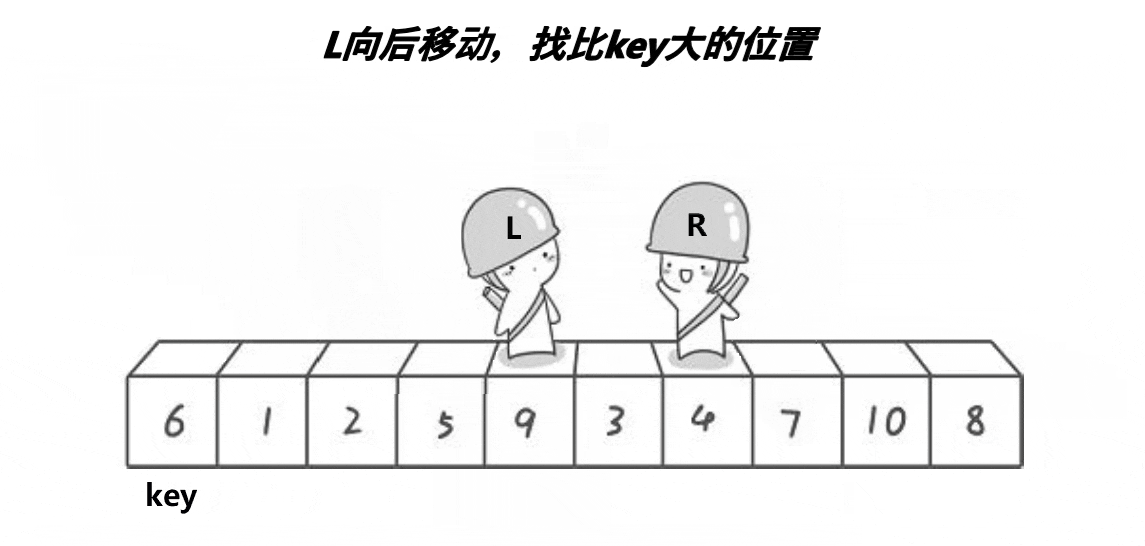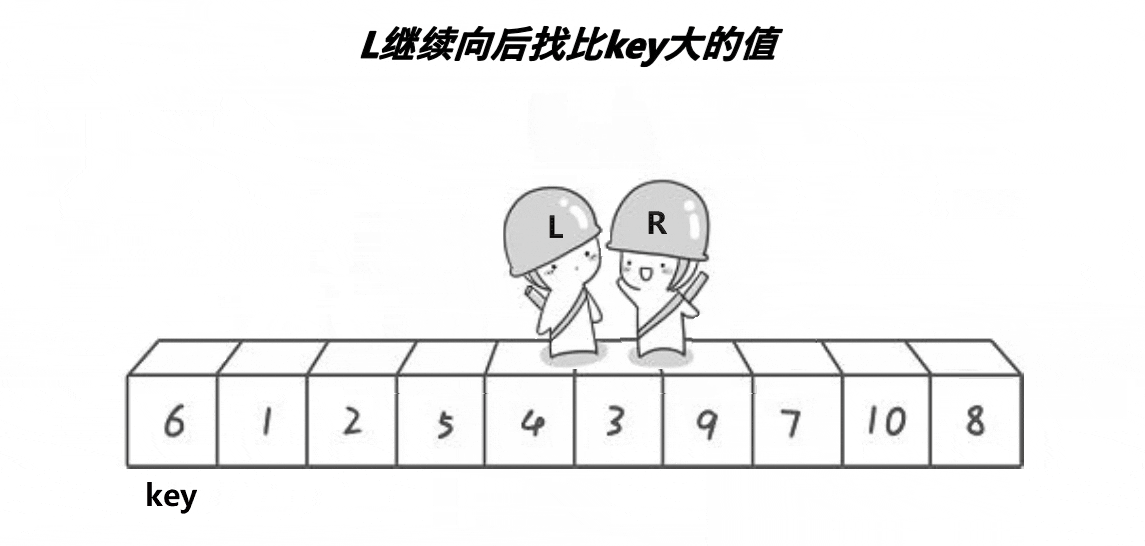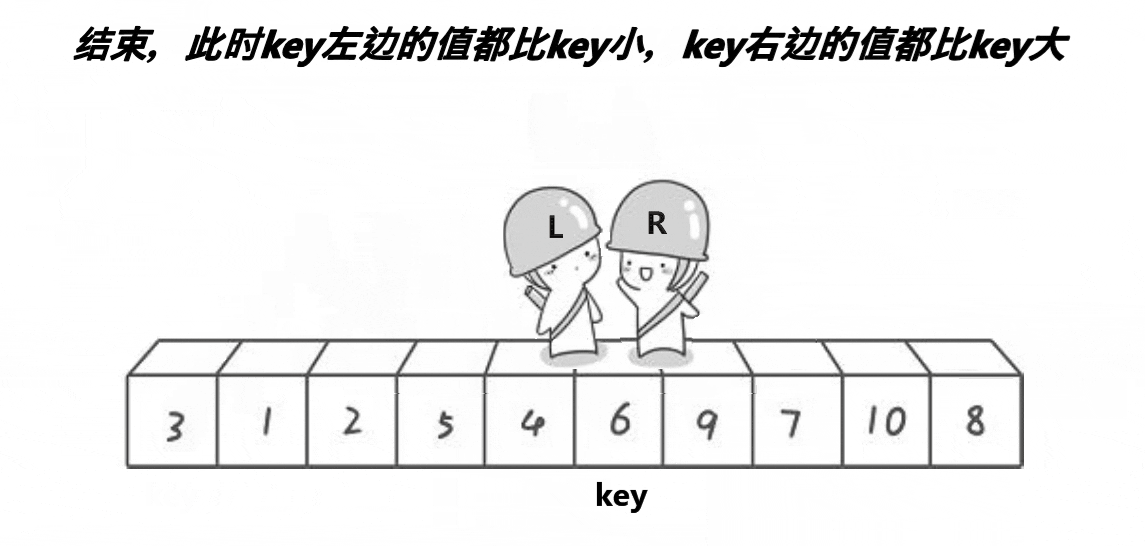
// 1.hoare遞歸(最早的快排方法)
void QuickSort1(int* a, int begin, int end)
{if (begin < end) {int left = begin;int right = end;int keyi = begin; // 基準值(下標)while (left < right) { /* 必須加上left<right防止內循環越界;>=而不是>,<=而不是<,防止重復值死循環。*/while (left < right && a[right] >= a[keyi]) {--right; // 找小的}while (left < right && a[left] <= a[keyi]) {++left; // 找大的}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);QuickSort0(a, begin, left - 1); // 左區間序列QuickSort0(a, left + 1, end); // 右區間序列}
}
基準值的取法:
- 取序列第一個數據,需要右指針right先走(學習時往往采用的方式,上面動圖演示也是基于這個方式);或取序列最后一個數據,需要左指針left先走(本質與前者沒區別)。
- 三位取中法:key、left和right中取第二大的值作為基準值。(這是優化版,推薦)
優化快排(重要)
1. 減少函數遞歸的棧幀開銷(雖然不用,但必須了解)
優化hoare快排的遞歸開銷:遞歸樹最后兩三層(小區間)改用插入排序,減少大量函數棧幀內存消耗。該優化在debug環境下確實能優化,在邏輯上也確實能優化,但release環境同樣也對遞歸進行了優化,而且優化力度只會更大,所以小區間使用插入排序減少遞歸棧幀的優化方案或許起不到效果。
例如一顆滿二叉樹,可以看到最后兩三層的數量是最多的:
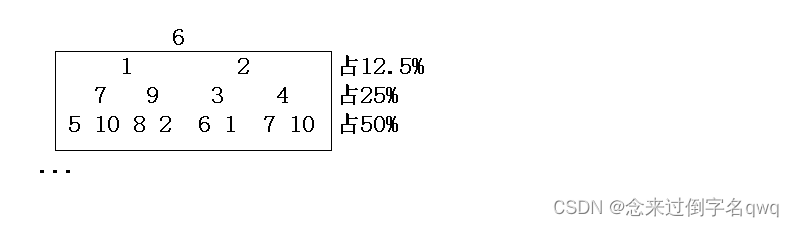
對于hoare快排劃分左右區間同理:

#define RECUR_MAX 10
void QuickSortX(int* a, int begin, int end)
{if (begin < end){if (end - begin + 1 <= RECUR_MAX){InsertionSort(a, end - begin + 1);}else{int left = begin;int right = end;int keyi = begin; // 基準值(下標)while (left < right){ /* 必須加上left<right防止內循環越界;>=而不是>,<=而不是<,防止重復值死循環。*/while (left < right && a[right] >= a[keyi]) {--right; // 找小的}while (left < right && a[left] <= a[keyi]) {++left; // 找大的}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);QuickSort0(a, begin, left - 1); // 左區間序列QuickSort0(a, left + 1, end); // 右區間序列}}
}
2.三位取中法取基準值(重點)
該優化提升非常大,主要是優化對較為有序的數據進行排序的情況。先看例子:一個較為有序的序列 1 2 3 4 7 6 8 10 9 對于這組數據,對于現在沒有使用三位取中的快排而言,前面幾趟排序是比較難受的。
比如第一趟,right一直不到比key要大的值,找最后搞得–right來到了key的位置,這就導致沒有左區間,右區間從2開始,數據越是有序,快排速度越慢,最慢時退化到O(n2)。
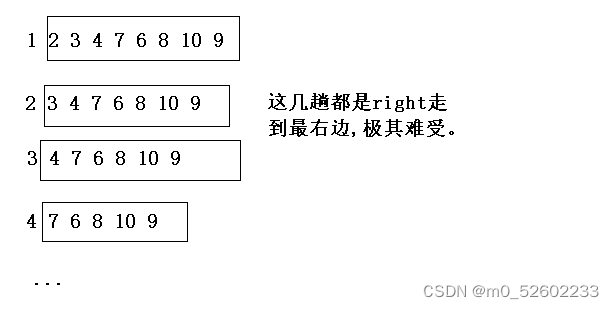
解決辦法就是不要直接取第一位作為基準值,從begin、mid和end之間選出第二大的值作為基準值。

每趟排序前先三位取中做交換,這樣就不至于面對這種情況,每趟排序right都走到最右邊。
6.2 挖坑法快排
該方法思想與hoare版差不多,算是hoare版的改進,可能更好理解一些,但排序速度比起hoare版沒啥大變化,差不多。
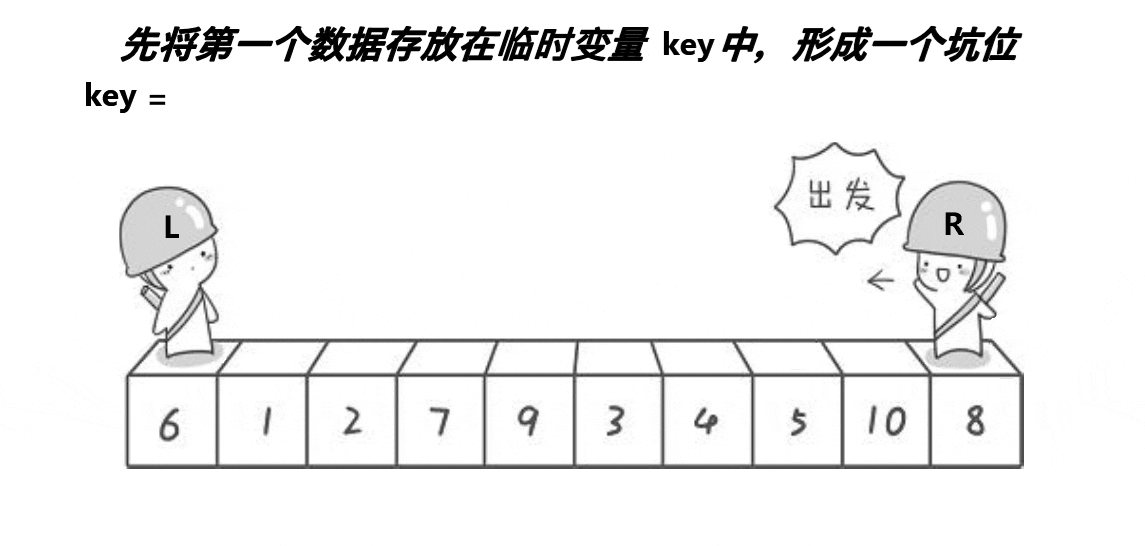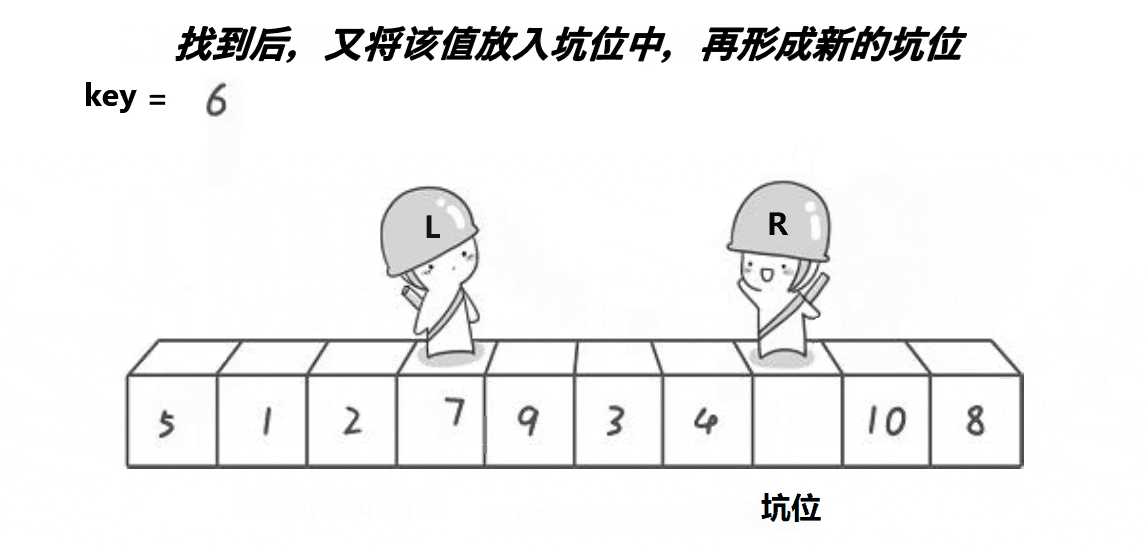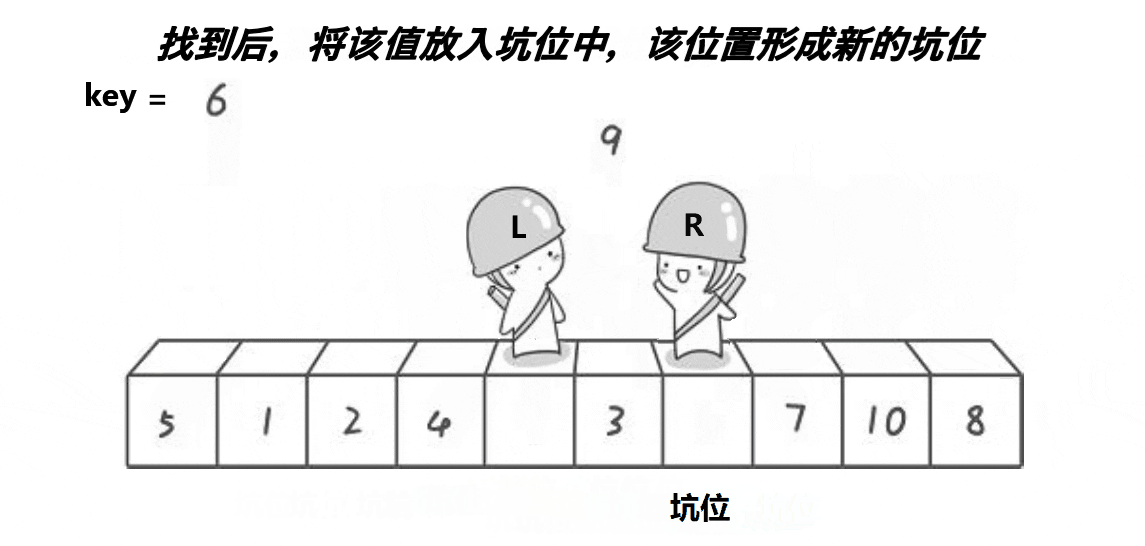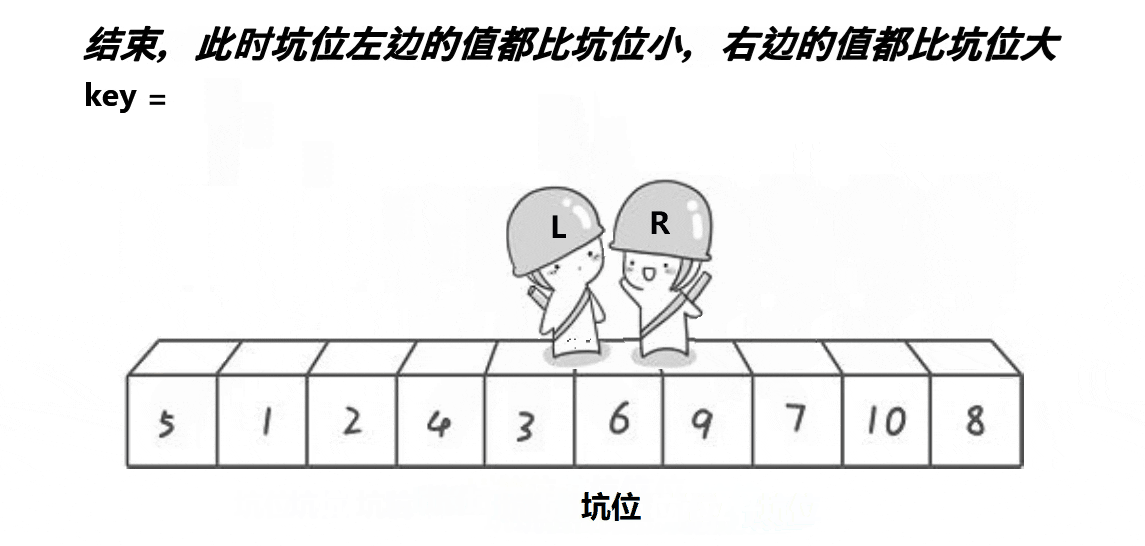
void QuickSort2(int* a, int begin, int end)
{if (begin < end){if ((end - begin) + 1 <= RECUR_MAX) {InsertionSort(a + begin, (end - begin) + 1);}else{int midi = MidIndex(a, begin, end);Swap(&a[begin], &a[midi]);int left = begin;int right = end;int key = a[begin];int pos = begin;while (left < right){while (left < right && a[right] >= key) {--right;}a[pos] = a[right];pos = right;while (left < right && a[left] <= key) {++left;}a[pos] = a[left];pos = left;}a[pos] = key;QuickSort2(a, begin, pos - 1);QuickSort2(a, pos + 1, end);}}
}
6.3 雙指針法快排
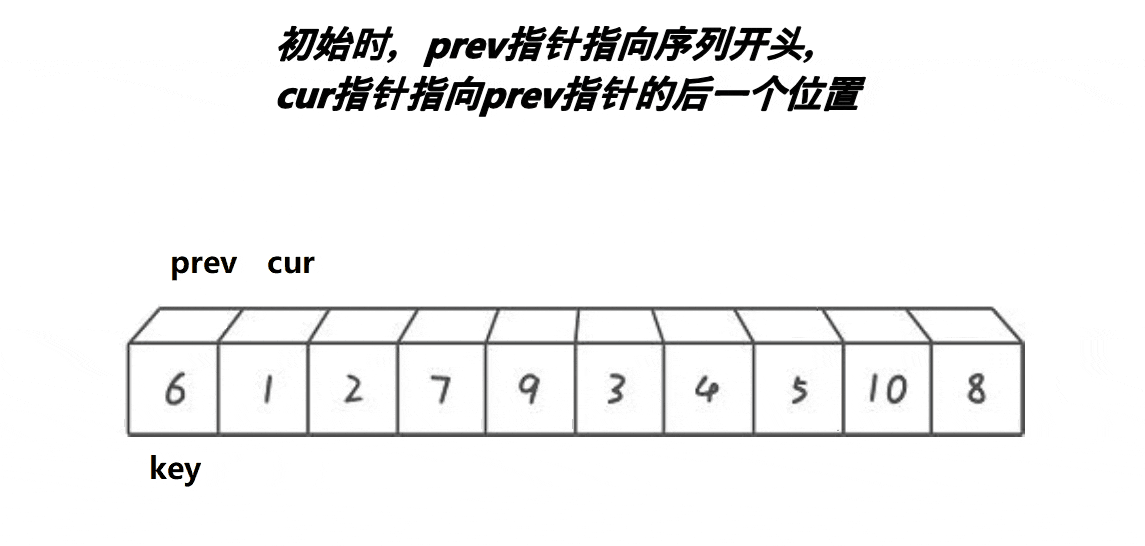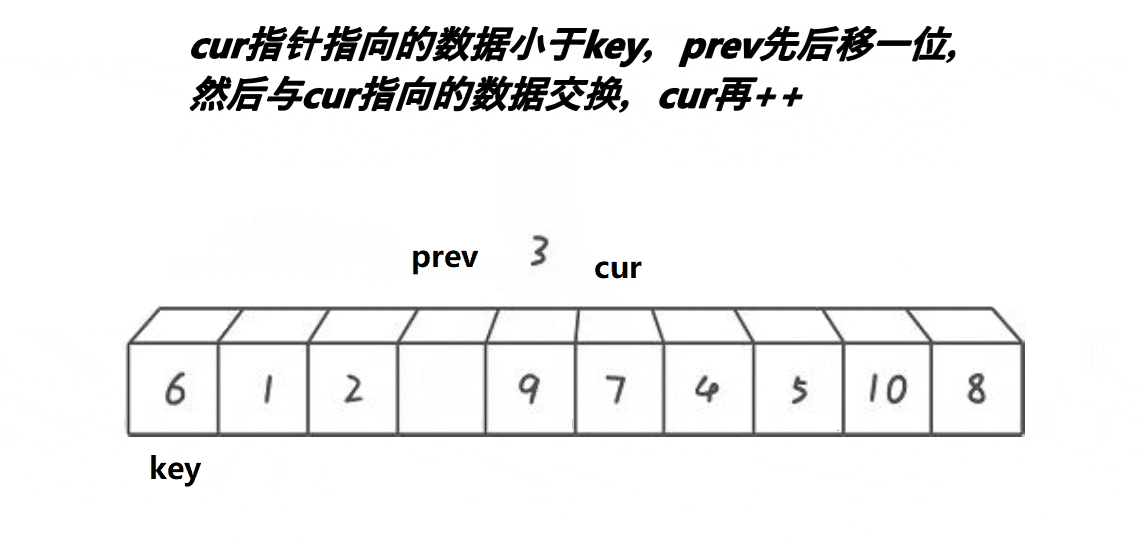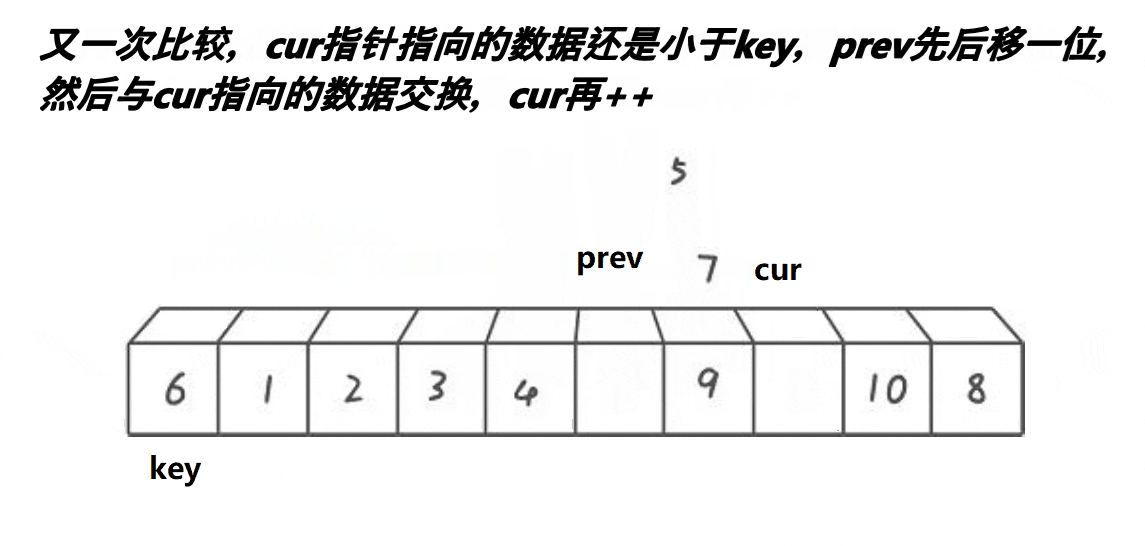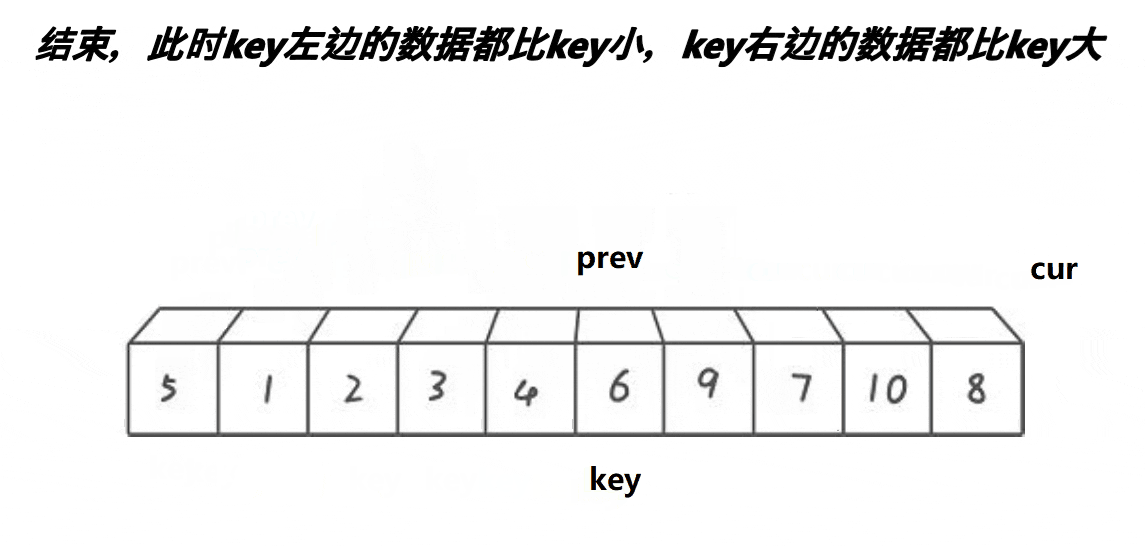
void QuickSort3(int* a, int begin, int end)
{if (begin < end){int midi = MidIndex(a, begin, end);Swap(&a[begin], &a[midi]);int keyi = begin;int pre = begin;int cur = begin + 1;while (cur <= end){if (a[cur] <= a[keyi]) {++pre;Swap(&a[pre], &a[cur]);}++cur;}Swap(&a[keyi], &a[pre]);keyi = pre;QuickSort3(a, begin, keyi - 1);QuickSort3(a, keyi + 1, end);}
}
6.4 非遞歸快排
需要借助棧(Stack),本質與遞歸一樣,遞歸也是棧幀的開辟與銷毀。
void QuickSortNonRecur(int* a, int begin, int end)
{assert(begin < end);Stack stack;Init(&stack);Push(&stack, begin); Push(&stack, end);// 類似遞歸while (!Empty(&stack)){// 出棧int right = Top(&stack); Pop(&stack);int left = Top(&stack); Pop(&stack);if (left < right){// 一趟快排int keyi = left;int previ = left;int curi = left + 1;while (curi <= right){if (a[curi] <= a[keyi]){++previ;Swap(&a[previ], &a[curi]);}++curi;}Swap(&a[keyi], &a[previ]);keyi = previ;// 入棧if (left < keyi - 1){Push(&stack, left);Push(&stack, keyi - 1);}if (keyi + 1 < right){Push(&stack, keyi + 1);Push(&stack, right);}}}Destroy(&stack);
}
快速排序的排序速度比較(包含測試代碼)
單位為毫秒。
500w個數據:
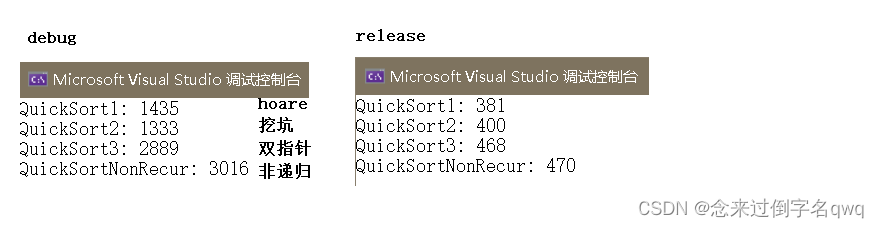
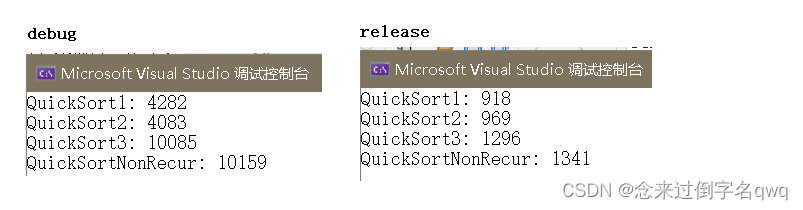
1000w個數據:
#include "Sort.h"void TestPerformance();int main() {TestPerformance();
}void TestPerformance() {const int N = 10000000;//int* a1 = (int*)malloc(sizeof(int) * N);//int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);//int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a10 = (int*)malloc(sizeof(int) * N);int* a11 = (int*)malloc(sizeof(int) * N);int* a12 = (int*)malloc(sizeof(int) * N);srand((unsigned int)time(0));for (int i = 0; i < N; i++) {//a1[i] = rand();//a2[i] = a1[i];a3[i] = rand();//a4[i] = a1[i];a5[i] = a3[i];a6[i] = a3[i];a10[i] = a3[i];a11[i] = a3[i];a12[i] = a3[i];}//int begin1 = clock();//BubbleSort(a1, N);//int end1 = clock();//int begin2 = clock();//InsertionSort(a2, N);//int end2 = clock();int begin3 = clock();ShellSort(a3, N);int end3 = clock();//int begin4 = clock();//SelectionSort(a4, N);//int end4 = clock();int begin5 = clock();HeapSort(a5, N);int end5 = clock();int begin6 = clock();QuickSort1(a6, 0, N - 1);int end6 = clock();int begin10 = clock();QuickSort2(a10, 0, N - 1);int end10 = clock();int begin11 = clock();QuickSort3(a11, 0, N - 1);int end11 = clock();int begin12 = clock();QuickSort3(a12, 0, N - 1);int end12 = clock();//printf("BubbleSort: %d\n", end1 - begin1);//printf("InsertionSort: %d\n", end2 - begin2);printf("ShellSort: %d\n", end3 - begin3);//printf("SelectionSort: %d\n", end4 - begin4);printf("HeapSort: %d\n", end5 - begin5);printf("QuickSort1: %d\n", end6 - begin6);printf("QuickSort2: %d\n", end10 - begin10);printf("QuickSort3: %d\n", end11 - begin11);printf("QuickSortNonRecur: %d\n", end12 - begin12);
}7. 歸并排序(Merge Sort)
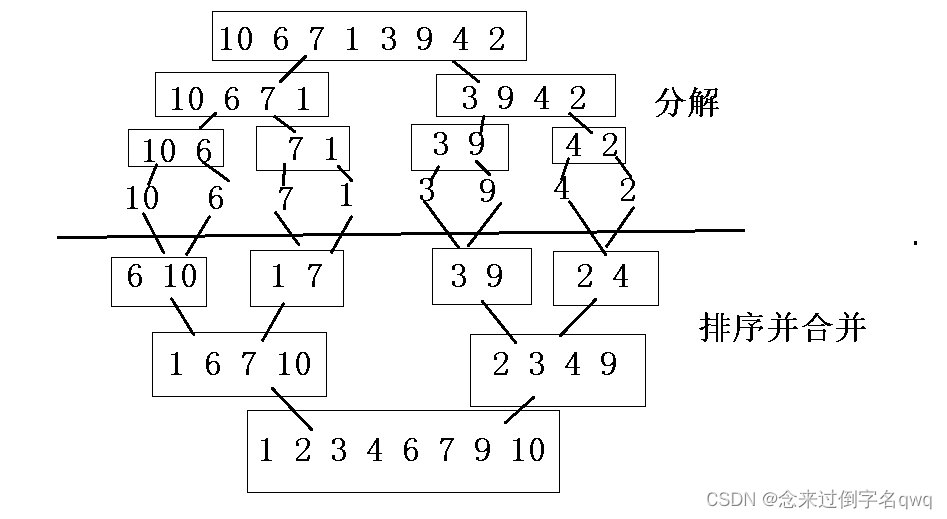
思想:分治法(Divide and Conquer),遞歸分治后小規模兩兩排序,逐漸合并大規模兩兩排序,最后到兩個子序列合并成一個有序列表,該方法也稱“二路歸并”,時間復雜度為O(nlogn)。
歸并排序需要借助一個額外的數組,因此空間復雜度為O(n),在這個臨時數組中排好序后,將排好序的數據復制回原序列。
// 二路歸并排序
void Merge(int* a, int begin, int end, int* tmpArr);
void MergeSort(int* a, int begin, int end)
{if (begin < end){int* tmpArr = (int*)malloc(sizeof(int) * (end + 1));if (tmpArr == NULL){perror("MergeSort malloc failed.");return;}Merge(a, begin, end, tmpArr);free(tmpArr);tmpArr = NULL;}
}
void Merge(int* a, int begin, int end, int* tmpArr)
{// 分解int mid = (begin + end) / 2;if (begin < end){Merge(a, begin, mid, tmpArr);Merge(a, mid + 1, end, tmpArr);}// 排序,合并存入臨時數組int begin1 = begin;int begin2 = mid + 1;int k = begin;while (begin1 <= mid && begin2 <= end){if (a[begin1] < a[begin2]) tmpArr[k++] = a[begin1++];elsetmpArr[k++] = a[begin2++];}// 兩個序列中某一個可能有剩余while (begin1 <= mid) {tmpArr[k++] = a[begin1++];}while (begin2 <= end) {tmpArr[k++] = a[begin2++];}// 臨時數組中排好序的數組,拷貝回原數組for (int i = begin; i <= end; i++) {a[i] = tmpArr[i];}
}
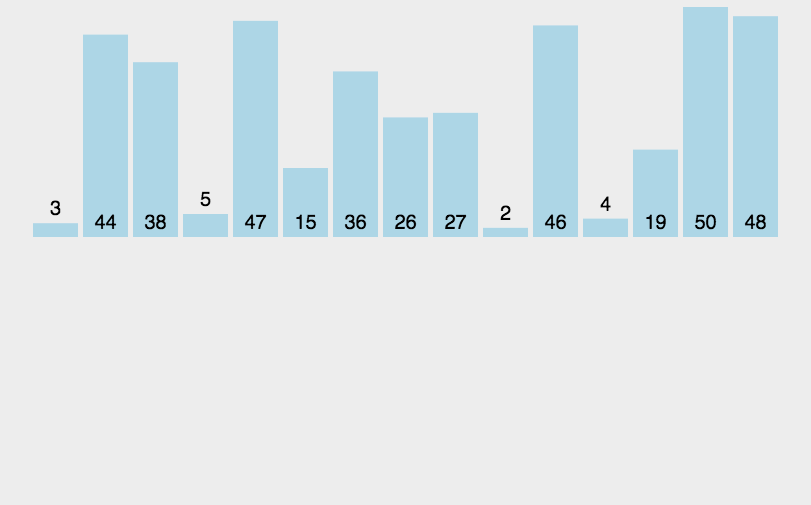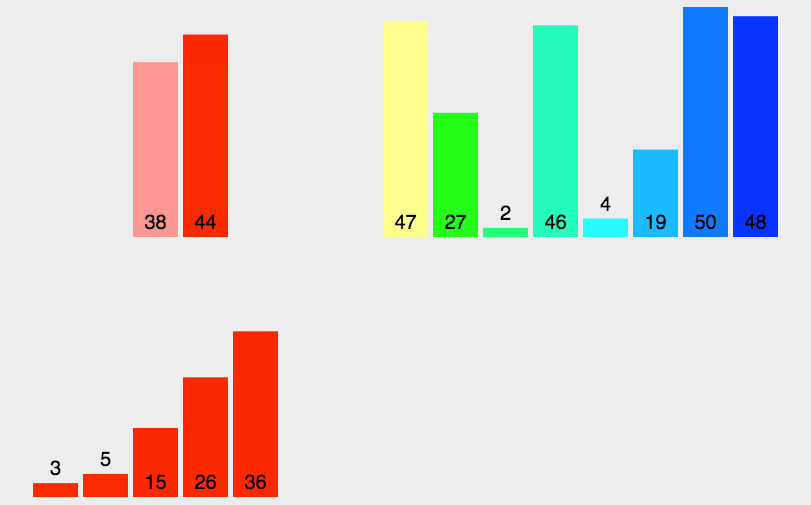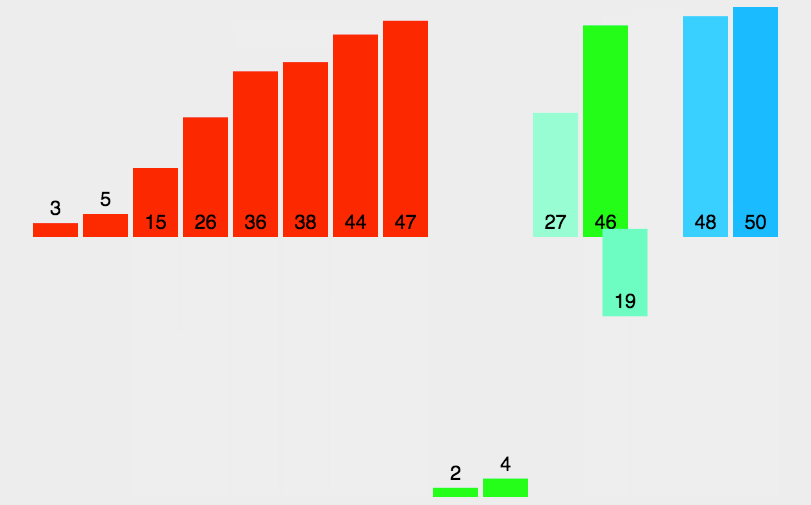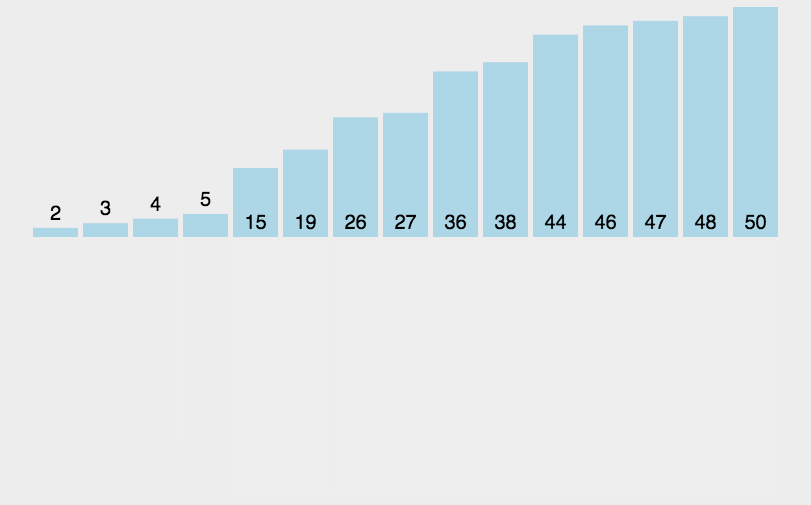
歸并排與快排的排序速度比較:










13.5-Mcal Mcu時鐘的配置)




)

13.4-Mcal Dio代碼分析)


