目錄
一、前言
二、hive默認分隔符規則以及限制
2.1 正常示例:單字節分隔符數據加載示例
2.2 特殊格式的文本數據,分隔符為特殊字符
2.2.1 文本數據的字段中包含了分隔符
三、突破默認限制規則約束
3.1? 數據加載不匹配情況 1
3.2? 數據加載不匹配情況 2
3.3? 解決方案一:替換分隔符
3.4? 解決方案二:RegexSerDe正則加載
問題一處理過程:
問題二處理過程:
3.5? 解決方案三:自定義InputFormat
3.5.1 操作流程
四、URL解析函數
4.1 URL基本組成
4.1.1 parse_url
4.1.2 問題分析
4.1.3 parse_url_tuple
4.1.4 案例操作演示
一、前言
分隔符是hive在建表的時候要考慮的一個重要因素,根據要加載的原始數據的格式不同,通常數據文件中的分隔符也有差異,因此可以在建表的時候指定分隔符,從而映射到hive的數據表。
二、hive默認分隔符規則以及限制
Hive默認序列化類是LazySimpleSerDe,其只支持使用單字節分隔符(char)來加載文本數據,例如逗號、制表符、空格等等,默認的分隔符為”\001”。
根據不同文件的不同分隔符,我們可以通過在創建表時使用 row format delimited 來指定文件中的分割符,確保正確將表中的每一列與文件中的每一列實現一一對應的關系。
如下是hive建表語法樹中的一部分

在這個語法樹中,大家熟知的分隔符即 DELIMITED 關鍵字,從語法中看出來默認情況下,其分割的都是單字節的數據,可現實情況下,實際要處理的文本數據內容可能要復雜很多,比如下面這些情況:
2.1 正常示例:單字節分隔符數據加載示例
下面這種文本格式的原始數據,可以直接使用沒問題;

?
2.2 特殊格式的文本數據,分隔符為特殊字符
每一行數據的分隔符是多字節分隔符,例如:”||”、“--”等,如下面這樣的數據;

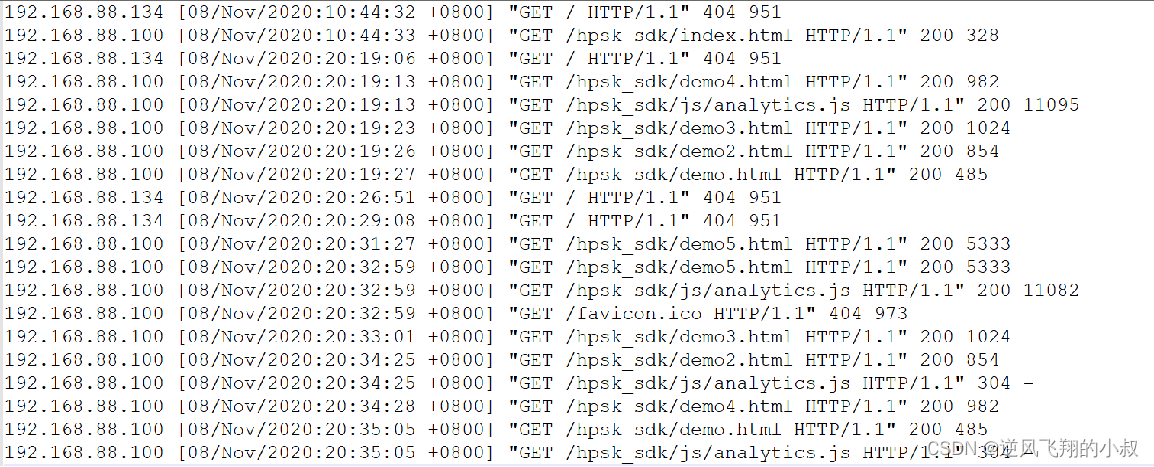
2.2.1 文本數據的字段中包含了分隔符
每列的分隔符為空格,但是數據中包含了分割符,時間字段中也有空格;
三、突破默認限制規則約束
3.1? 數據加載不匹配情況 1
文本內容數據格式如下

?建表sql,這里字段分隔符采用 || 與文本對應;
drop table singer;
create table singer(id string,name string,country string,province string,gender string,works string)
row format delimited fields terminated by '||';load data local inpath '/usr/local/soft/selectdata/test01.txt' into table singer;執行建表并加載數據
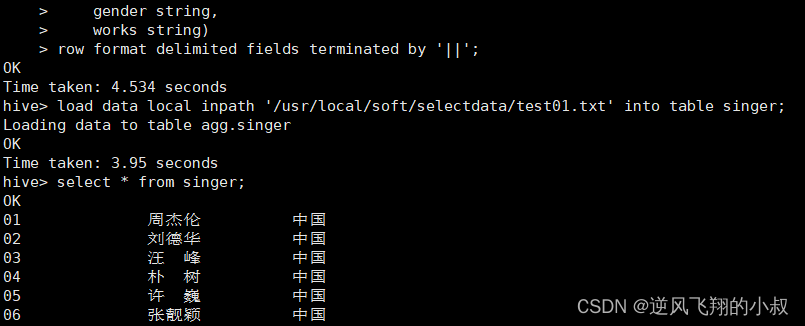
從數據來看,字段并沒有解析完全,并且某些字段解析失敗,和預期的不太一樣,這是怎么回事呢?
3.2? 數據加載不匹配情況 2
原始文本數據內容格式如下
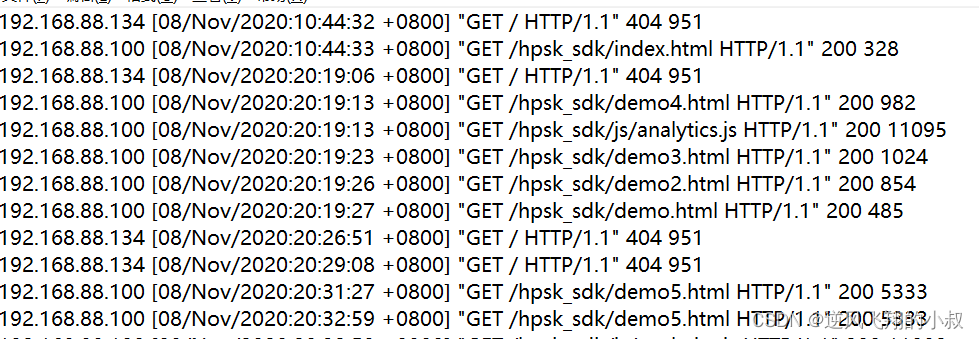
建表并加載數據,這里采用空格作為分隔符;
drop table apachelog;
create table apachelog( ip string,stime string,mothed string,url string,policy string,stat string,body string)
row format delimited fields terminated by ' ';load data local inpath '/usr/local/soft/selectdata/apache_web_access.log' into table apachelog;執行完成后檢查數據
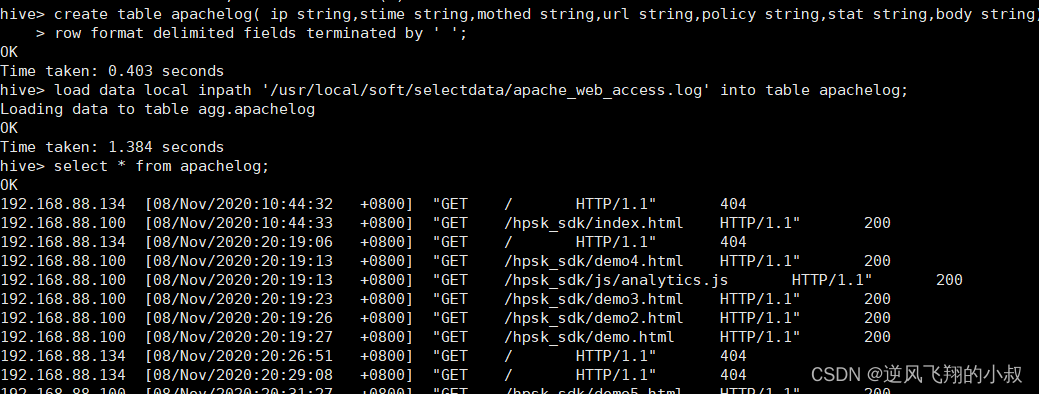
從數據來看,某些字段的解析不僅錯誤,而且字段也出現了錯位;
從上面兩個簡單的示例來看,如果要解析的原始文本數據中的某些字段自身包含了分隔符,這時候再使用默認的LazySimpleSerDe序列化加載數據時,將得不到預期的結果,出現數據解析錯誤的情況。
關于上述問題,下面提幾種常用的解決辦法。
3.3? 解決方案一:替換分隔符
在第一個示例中的數據,要想使用默認分隔符,可以考慮對原始數據進行預處理,將雙|轉換為單個|后再導入;

至于轉換的過程,可以人工處理,也可以使用MR程序處理,使用MR程序處理的話可以參考下面的偽代碼,
package bigdata.itcast.cn.hbase.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;import java.io.IOException;/*** @ClassName ChangeSplitCharMR* @Description TODO MapReduce實現將多字節分隔符轉換為單字節符* @Create By itcast*/
public class ChangeSplitCharMR extends Configured implements Tool {public int run(String[] arg) throws Exception {/*** 構建Job*/Job job = Job.getInstance(this.getConf(),"changeSplit");job.setJarByClass(ChangeSplitCharMR.class);/*** 配置Job*///input:讀取需要轉換的文件job.setInputFormatClass(TextInputFormat.class);Path inputPath = new Path("datas/split/test01.txt");FileInputFormat.setInputPaths(job,inputPath);//map:調用Mapperjob.setMapperClass(ChangeSplitMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);//reduce:不需要Reduce過程job.setNumReduceTasks(0);//outputjob.setOutputFormatClass(TextOutputFormat.class);Path outputPath = new Path("datas/output/changeSplit");TextOutputFormat.setOutputPath(job,outputPath);/*** 提交Job*/return job.waitForCompletion(true) ? 0 : -1;}//程序入口public static void main(String[] args) throws Exception {//調用runConfiguration conf = new Configuration();int status = ToolRunner.run(conf, new ChangeSplitCharMR(), args);System.exit(status);}public static class ChangeSplitMapper extends Mapper<LongWritable,Text,Text,NullWritable>{//定義輸出的Keyprivate Text outputKey = new Text();//定義輸出的Valueprivate NullWritable outputValue = NullWritable.get();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//獲取每條數據String line = value.toString();//將里面的||轉換為|String newLine = line.replaceAll("\\|\\|", "|");//替換后的內容作為Keythis.outputKey.set(newLine);//輸出結果context.write(this.outputKey,this.outputValue);}}
}3.4? 解決方案二:RegexSerDe正則加載
顧名思義就是使用hive提供的相關正則的語法來處理這個問題,為什么呢?因為hive內置了很多SerDe類;
Hive內置的SerDe
- 除了使用最多的LazySimpleSerDe,Hive該內置了很多SerDe類;
- 官網地址:https://cwiki.apache.org/confluence/display/Hive/SerDe;
- 多種SerDe用于解析和加載不同類型的數據文件,常用的有ORCSerDe 、RegexSerDe、JsonSerDe等;
1、RegexSerDe用來加載特殊數據的問題,使用正則匹配來加載數據;
2、根據正則表達式匹配每一列數據;
官網參考文檔

針對上面演示時的問題,來看看如何使用這種方式來解決,比如第一份數據,針對這份數據,只需要寫一個正則,能夠識別到其中的分隔符雙 || ,將建表時的字段分割符使用這個正則,然后加載數據的時候就可以把hive解析出預期的數據格式了;

使用正則Regex處理這兩個問題,下面看具體的操作演示
問題一處理過程:
建表并加載數據
--如果表已存在就刪除表
drop table if exists singer;
--創建表
create table singer(id string,--歌手idname string,--歌手名稱country string,--國家province string,--省份gender string,--性別works string)--作品
--指定使用RegexSerde加載數據
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "([0-9]*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)");--加載數據
load data local inpath '/usr/local/soft/selectdata/test01.txt' into table singer;執行過程

檢查數據發現,通過這種方式數據就能正確的加載了;

問題二處理過程:
創建表并加載數據,使用正則處理
--如果表存在,就刪除表
drop table if exists apachelog;
--創建表
create table apachelog(ip string, --IP地址stime string, --時間mothed string, --請求方式url string, --請求地址policy string, --請求協議stat string, --請求狀態body string --字節大小
)
--指定使用RegexSerde加載數據ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
--指定正則表達式WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)") stored as textfile ;load data local inpath '/usr/local/soft/selectdata/apache_web_access.log' into table apachelog;執行過程
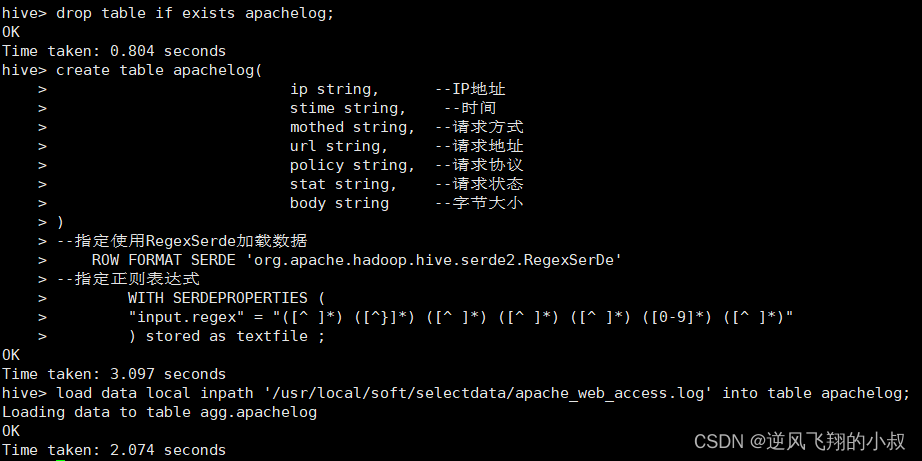
檢查數據發現,通過這種方式數據就能正確的加載了;

3.5? 解決方案三:自定義InputFormat
Hive中也允許使用自定義InputFormat來解決以上問題,通過在自定義InputFormat,來自定義解析邏輯實現讀取每一行的數據。
下面是官方文檔關于該方案的說明;?

3.5.1 操作流程
自定義InputFormat,與MapReudce中自定義InputFormat一致,繼承TextInputFormat,下面是完整的代碼;
自定義UserInputFormat
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;import java.io.IOException;/*** @ClassName UserInputFormat* @Description TODO 用于實現自定義InputFormat,讀取每行數據*/public class UserInputFormat extends TextInputFormat {@Overridepublic RecordReader<LongWritable, Text> getRecordReader(InputSplit genericSplit, JobConf job,Reporter reporter) throws IOException {reporter.setStatus(genericSplit.toString());UserRecordReader reader = new UserRecordReader(job,(FileSplit)genericSplit);return reader;}
}UserRecordReader
用于自定義讀取器,在自定義InputFormat中使用,將讀取到的每行數據中的||替換為|
代碼如下
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.LineRecordReader;
import org.apache.hadoop.mapred.RecordReader;import java.io.IOException;
import java.io.InputStream;/*** @ClassName UserRecordReader* @Description TODO 用于自定義讀取器,在自定義InputFormat中使用,將讀取到的每行數據中的||替換為|*/public class UserRecordReader implements RecordReader<LongWritable, Text> {private static final Log LOG = LogFactory.getLog(LineRecordReader.class.getName());int maxLineLength;private CompressionCodecFactory compressionCodecs = null;private long start;private long pos;private long end;private LineReader in;private Seekable filePosition;private CompressionCodec codec;private Decompressor decompressor;public UserRecordReader(Configuration job, FileSplit split) throws IOException {this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);start = split.getStart();end = start + split.getLength();final Path file = split.getPath();compressionCodecs = new CompressionCodecFactory(job);codec = compressionCodecs.getCodec(file);FileSystem fs = file.getFileSystem(job);FSDataInputStream fileIn = fs.open(split.getPath());if (isCompressedInput()) {decompressor = CodecPool.getDecompressor(codec);if (codec instanceof SplittableCompressionCodec) {final SplitCompressionInputStream cIn = ((SplittableCompressionCodec) codec).createInputStream(fileIn, decompressor, start, end,SplittableCompressionCodec.READ_MODE.BYBLOCK);in = new LineReader(cIn, job);start = cIn.getAdjustedStart();end = cIn.getAdjustedEnd();filePosition = cIn; // take pos from compressed stream} else {in = new LineReader(codec.createInputStream(fileIn, decompressor), job);filePosition = fileIn;}} else {fileIn.seek(start);in = new LineReader(fileIn, job);filePosition = fileIn;}if (start != 0) {start += in.readLine(new Text(), 0, maxBytesToConsume(start));}this.pos = start;}private boolean isCompressedInput() {return (codec != null);}private int maxBytesToConsume(long pos) {return isCompressedInput() ? Integer.MAX_VALUE : (int) Math.min(Integer.MAX_VALUE, end - pos);}private long getFilePosition() throws IOException {long retVal;if (isCompressedInput() && null != filePosition) {retVal = filePosition.getPos();} else {retVal = pos;}return retVal;}public LongWritable createKey() {return new LongWritable();}public Text createValue() {return new Text();}/*** Read a line.*/public synchronized boolean next(LongWritable key, Text value) throws IOException {while (getFilePosition() <= end) {key.set(pos);int newSize = in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength));String str = value.toString().replaceAll("\\|\\|", "\\|");value.set(str);pos += newSize;if (newSize == 0) {return false;}if (newSize < maxLineLength) {return true;}LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize));}return false;}public float getProgress() throws IOException {if (start == end) {return 0.0f;} else {return Math.min(1.0f, (getFilePosition() - start) / (float) (end - start));}}public synchronized long getPos() throws IOException {return pos;}public synchronized void close() throws IOException {try {if (in != null) {in.close();}} finally {if (decompressor != null) {CodecPool.returnDecompressor(decompressor);}}}public static class LineReader extends org.apache.hadoop.util.LineReader {LineReader(InputStream in) {super(in);}LineReader(InputStream in, int bufferSize) {super(in, bufferSize);}public LineReader(InputStream in, Configuration conf) throws IOException {super(in, conf);}}
}
本地打成jar包并上傳到服務器

使用命令上傳jar到hive的依賴包目錄

重新創建表,加載數據,同時指定InputFormat為自定義的InputFormat
--如果表已存在就刪除表
drop table if exists singer;--創建表
create table singer(id string,--歌手idname string,--歌手名稱country string,--國家province string,--省份gender string,--性別works string)
--指定使用分隔符為|
row format delimited fields terminated by '|'
--指定使用自定義的類實現解析
stored as
inputformat 'bigdata.com.congge.hive.mr.UserInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';--加載數據
load data local inpath '/usr/local/soft/selectdata/test01.txt' into table singer;執行過程

?檢查數據,可以發現通過這種方式也可以成功的將數據加載到表中;

小結
當數據文件中出現多字節分隔符或者數據中包含了分隔符時,會導致數據加載與實際表的字段不匹配的問題,基于這個問題我們提供了三種方案:
- 替換分隔符;
- 正則加載RegexSerde;
- 自定義InputFormat;
其中替換分隔符無法解決數據字段中依然存在分隔符的問題,自定義InputFormat的開發成本較高,所以整體推薦使用正則加載的方式來實現對于特殊數據的處理。
四、URL解析函數
業務需求中,經常需要對用戶的訪問、用戶的來源進行分析,用于支持運營和決策。例如對用戶訪問的頁面進行統計分析,分析熱門受訪頁面的Top10,觀察大部分用戶最喜歡的訪問最多的頁面等。如下截取的是統計到的一個關于網站訪問地址稍微匯總數據。
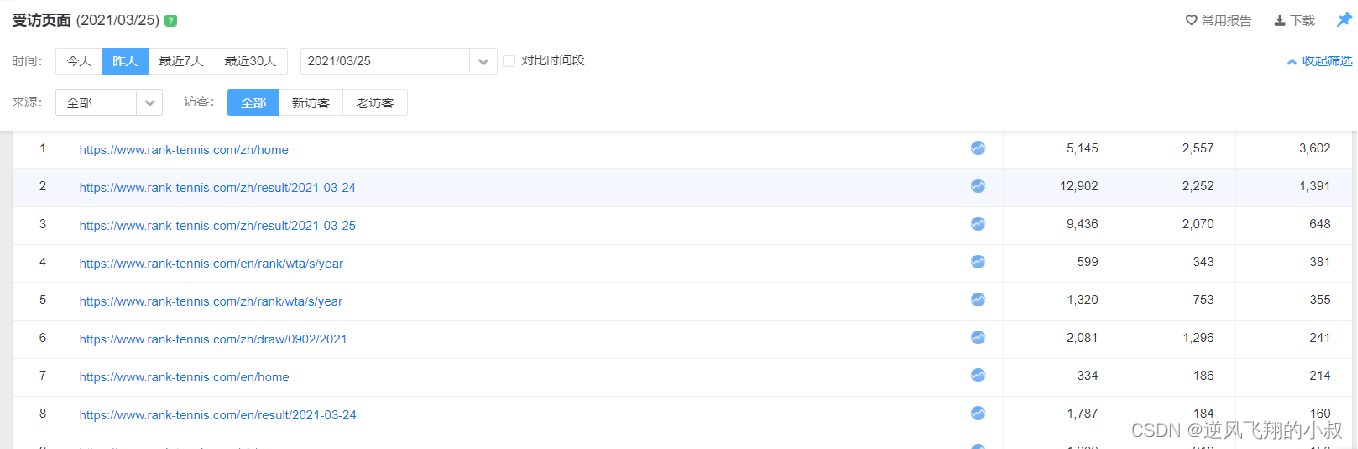
業務上,需要對用戶訪問的頁面進行統計分析,比如說:分析熱門受訪頁面的Top10,觀察大部分用戶最喜歡的訪問最多的頁面等,然后通過圖表的方式展示出來,以支撐運營和商業決策等;
4.1 URL基本組成
要想實現上面的受訪分析、來源分析等業務,必須在實際處理數據的過程中,對用戶訪問的URL和用戶的來源URL進行解析處理,獲取用戶的訪問域名、訪問頁面、用戶數據參數、來源域名、來源路徑等信息。
在對URL進行解析時,我們要先了解URL的基本組成部分,再根據實際的需求從URL中獲取對應的部分,例如一條URL由以下幾個部分組成:
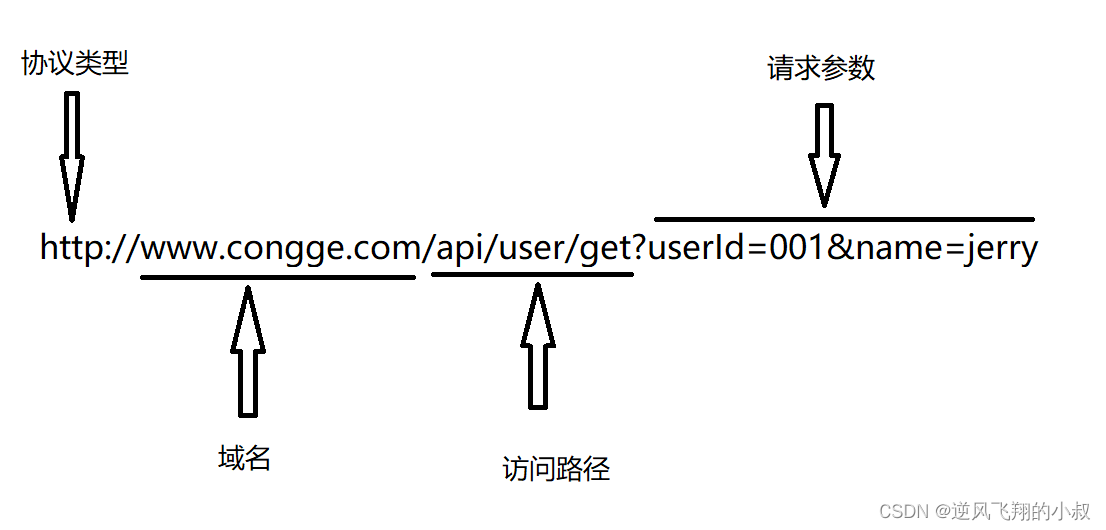
試想如果要將上面這個完整的URL的各個部分解析出來,你會怎么做呢?可以通過正則,或者字段分割,或者截取等方式達到目的,但這些都不是最好的方式,Hive中為了實現對URL的解析,專門提供了解析URL的函數parse_url和parse_url_tuple,在show functions中可以看到對應函數;
4.1.1 parse_url
語法格式
parse_url(url, partToExtract[, key]) - extracts a part from a URL
Parts: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO key
比如嘗試使用該函數解析上面圖中的URL,可以看到HOST部分就被解析出來了;

或者解析參數信息
SELECT parse_url('http://www.congge.com/api/user/get?userId=001&name=jerry', 'QUERY');SELECT parse_url('http://www.congge.com/api/user/get?userId=001&name=jerry', 'QUERY', 'name');
4.1.2 問題分析
上面這種解析方式,每次解析時只能解析出其中一個參數,也就是說,該函數為普通的一對一函數類型。如果想一次解析多個參數,需要使用多次函數,這就帶來了很大的不便,這時候,parse_url_tuple函數就派上用場了。
4.1.3 parse_url_tuple
?parse_url_tuple函數是Hive中提供的基于parse_url的url解析函數,可以通過一次指定多個參數,從URL解析出多個參數的值進行返回多列,函數為特殊的一對多函數類型,即通常所說的UDTF函數類型。
語法格式
parse_url_tuple(url, partname1, partname2, ..., partnameN) - extracts N (N>=1) parts from a URL;
It takes a URL and one or multiple partnames, and returns a tuple;
4.1.4 案例操作演示
創建一張表并加載數據
drop table if exists tb_url;
--建表
create table tb_url(id int,url string
)row format delimited
fields terminated by '\t';--加載數據
load data local inpath '/usr/local/soft/selectdata/url.txt' into table tb_url;執行過程
檢查數據是否加載成功

接下來體驗下parse_url_tuple函數的使用
解析host和path
select parse_url_tuple(url,"HOST","PATH") as (host,path) from tb_url;

解析出 PROTOCOL,HOST和PATH
select parse_url_tuple(url,"PROTOCOL","HOST","PATH") as (protocol,host,path) from tb_url;

解析查詢參數
select parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query) from tb_url;





)
)
![LeetCode 刷題 [C++] 第73題.矩陣置零](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第73題.矩陣置零)
)
和機器視覺(Machine Vision))

)
![【洛谷 P8682】[藍橋杯 2019 省 B] 等差數列 題解(數學+排序+輾轉相除法)](http://pic.xiahunao.cn/【洛谷 P8682】[藍橋杯 2019 省 B] 等差數列 題解(數學+排序+輾轉相除法))
)


------數據的復制)

利用pytorch復現全卷積神經網絡FCN)

