JVM的內存區域劃分
JVM它其實也是一個進程,進程運行的過程中,會從操作系統中申請一些資源.內存就是其中的一種.這些內存就支撐了java程序的運行.JVM從系統中申請的一大塊內存,會根據實際情況和使用用途來劃分出不同的空間,這個就是區域劃分.它一般分為 堆區, 棧區, 程序計數器, 元數據區4個區域.
堆區
我們代碼中new出來的對象就是在堆當中,對象持有的非靜態成員變量,也是在堆當中.
棧區
棧區分為本地方法棧和虛擬機棧. 本地方法棧是jvm通過c++寫的代碼的調用關系和局部變量.一般我們只關心虛擬機棧. 虛擬機棧是記錄了java代碼的調用關系和java代碼的局部變量.
程序計數器
這是一塊小區域,專門用來存儲下一條要執行的java指令的地址,和x86cpu中的eip寄存器差不多.
元數據區
在之前也叫做 "方法區". 它里面記錄的是類的信息,方法的信息, 一個程序有哪些類,每個類有哪些方法,方法里面都會包含哪些指令,都會記錄在元數據區中.想我們的代碼中的各種邏輯都會轉化為java字節碼,這些字節碼就會在程序運行的時候被jvm加載到內存中,放到方法區當中.程序怎么執行就會按照元數據區中的java字節碼來依次執行.
注意: 這里堆和元數據區只有一份,但是棧區和程序計數器由N份,和線程數目相關.
JVM的類加載機制
這里的類加載就是java進程來運行的時候,需要把.class文件從硬盤讀取到內存,且進行一系列的校驗解析的過程. 這里加載的過程可以分為5個步驟. 加載 - 驗證 - 準備 - 解析 - 初始化.
加載
大概就是把硬盤中的.class文件找到,打開文件且讀取到文件內容.
驗證
把當前讀到的文件內容需要確保是合法的.class文件格式.
準備
給類對象申請內存空間.這里的申請到的內存空間,里面的默認值都是0.類對象中的靜態成員變量的值也就是0)
解析
這里就是對類中的字符串常量進行處理.將常量池中的符號引用轉換為直接引用的過程.(符號引用可以理解為字符串和它的引用在文件中有偏移量,直接引用則就是地址).
初始化
針對類對象完成后續的初始化過程(這里還會執行靜態代碼塊的邏輯,父類的加載)
雙親委派模型(加載環節)
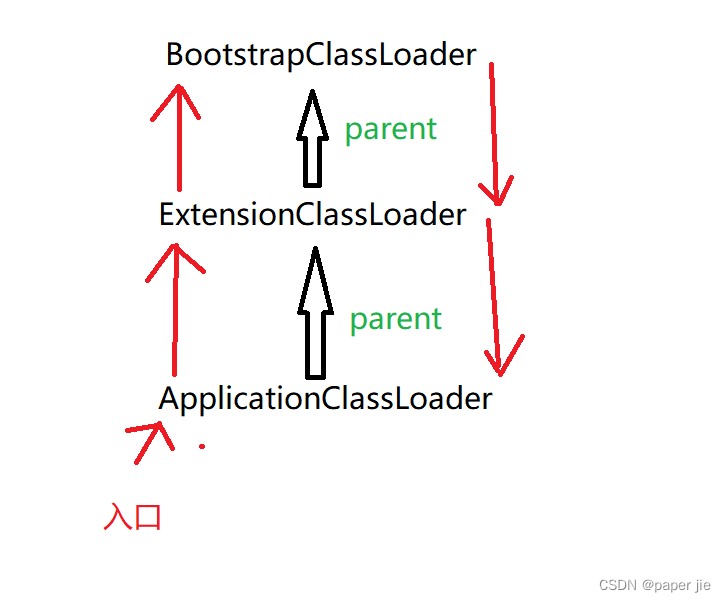
這里描述了怎么樣來查找.class文件的策略.在我們的JVM中進行類加載的操作,會有一個專門的模塊 - "類加載器(ClassLoader)". JVM中有三個ClassLoader.這里類加載器的作用就是給它一個帶有包名的類名,來找到對應的.class文件.
三個庫的作用:
BootstrapClassLoader: 負責查找標準庫中的目錄.
ExtensionClassLoader: 負責查找擴展庫中的目錄.
ApplicationClassLoader: 負責查找當前項目的代碼目錄和第三方庫.? ?? ?
這三個加載器的關系類似于父子關系.

工作過程
1. 先以ApplicationClassLoader為入口,開始工作.,但是它不會立刻開始查找自己負責的目錄,而是將任務交給它的父親.
2. 任務到ExtensionClassLoader,它也不會立刻開展工作,而是交給它的父親.
3. 任務到BootsstrapClassLoader,它才會開始真正的搜索負責的目錄.通過全限定類名,來嘗試在標準庫中找到符合的.class文件.找到了就進入打開文件,讀文件的流程.沒找到則交給它的孩子來處理.
4. ExtensionClassLoader拿到父親給它的任務后,也會通過全限定類名,在擴展庫中查找符合的.class文件.找到了就進入讀文件的流程.沒找到再交給它的孩子處理.
5. ApplicationClassLoader拿到夫妻給它的任務后,也會通過全限定類名,在項目中的目錄和第三方庫的目錄中查找.找到了就進入讀文件流程.沒找到說明加載失敗.則會拋出ClassNotFoundException異常.
這樣設定的目的其實最主要的就是確保這幾個類加載器的優先級. 按照這樣的方式就算你自己寫的類不小心和標準庫中的類名字重復了,也可以避免導致標準庫中的類失效.
JVM的垃圾回收機制(GC)
JVM的垃圾回收,說的就是將內存回收.在JVM的多個區中. 程序計數器不需要GC,棧不需要,因為它的局部變量在代碼塊執行結束后就會進行自動銷毀. 元數據區也不需要,它一般都是涉及到類加載,很少涉及到類卸載. 這里最主要使用GC的就是堆區.因為它里面記錄的是對象,而代碼中可能會new出許許多多的對象,有的對象可能不使用了,就需要銷毀.所以這里的內存回收,也可以看成是對象回收.
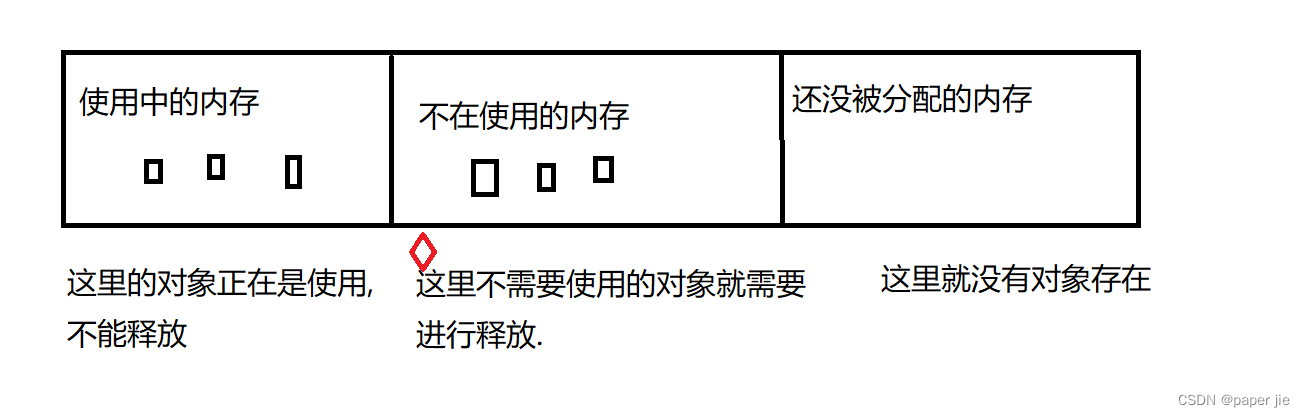
垃圾回收分為兩步:
1. 識別出垃圾,哪些對象是垃圾,哪些對象不是垃圾.
2. 把標記為垃圾的對象的內存空間進行釋放.
識別垃圾
這里識別一個對象是不是需要繼續使用,就是判斷還有沒有引用在指向它.如果沒有,它就可以視為垃圾.這里有兩種方法: 1. 引用計數 2. 可達性分析
引用計數
這個方法在JVM中并沒有使用,但是在其他的主流語言中還是在廣泛應用中.
它的處理方式就是:
給每一個對象安排一個額外的空間,這個空間里就保存當前有幾個引用. 而另一邊會有專門的掃描線程,去獲取到當前每個對象的引用計數的情況,一但發現這個對象的引用計數為0,就代表可以釋放了.
但是它會存在一些問題:
1. 會消耗額外的內存空間.尤其是當對象比較小時,你的計數器消耗的空間可能就達到對象的一半了.
2.引用計數可能會產生循環引用的問題.

可達性分析(JVM使用的方法)
它的本質就是用時間來換空間. 它就不會產生額外的空間和循環引用的問題.
在代碼中,會定義出很多變量,棧上的局部變量,堆上的成員變量,方法區的靜態變量,常量池中引用的對象... 它就可以從這些變量作為起點,去進行遍歷.這個遍歷就是沿著這些變量持有的引用類型的成員,再進行下一步的訪問. 可以遍歷到的對象就不是垃圾,反之.
這里的遍歷我們可以想象為二叉樹的遍歷.一但有一個節點為null,那這個結點后面的也都為null,也就是垃圾.
JVM中會存在掃描線程,對代碼不斷進行遍歷.
清理垃圾
清理垃圾就是將被標記的內存空間進行釋放.這里釋放有三種方法.
標記 - 清除
這里就是直接將標記為垃圾的對象直接釋放掉.但是一般不會使用這個方案.因為它會有內存碎片問題.直接釋放,就會產生很多小的,離散的空閑內存空間,這就可能導致后續的內存申請失敗.因為內存申請一般都是申請一塊連續,大范圍的空間.
復制
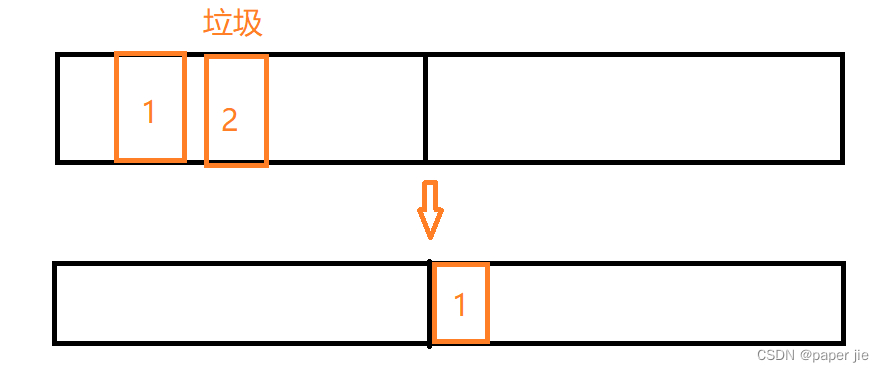
它的核心就不是直接釋放內存,也是將不是垃圾的對象,復制到另一半的空間中(它會將可用內存空間分為兩半).?
這樣子就規避了內存碎片化的問題,但是也會有一些缺點.
1. 總用的內存空間變少了.
2. 如果每次需要復制的對象比較多,復制開銷就會很大了(它適合大部分對象都釋放,少部分對象存活,這個時候使用復制)
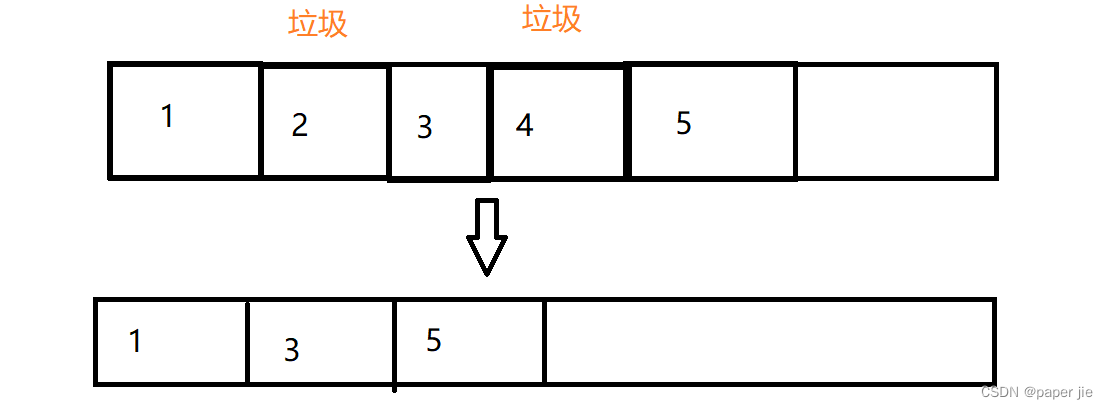
標記 - 整理
這個方式就類似于順序表中的刪除中間元素,需要進行搬運.通過這個過程,也就解決了內存碎片的問題,但是它這里的搬運內存開銷會很大.
JVM的分代回收
?因為上面方法的優缺點,JVM就結合上面的思想,搞出來了一個綜合方案.
JVM會給對象進行年齡記錄,被JVM的掃描線程掃描過一次后就加一歲,起始歲數為0. 而還給堆內存劃分了兩個區域:分為為新生代和老年代.且新生代中還分了三個區:伊甸區和兩個生存區.
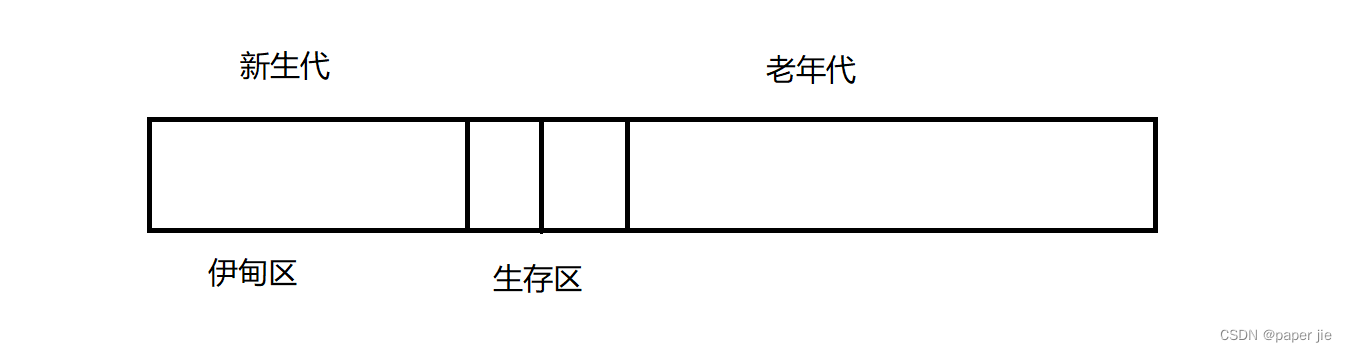
?處理流程:
1. 當代碼中new出一個新的對象時,就是創建在伊甸區中的,伊甸區中會有很多對象.(放在里面是有一個經驗規矩: 伊甸區的對象大多都是活不過第一輪GC的,"朝生夕死")
2. 當第一輪GC后,少部分存活下來的對象,就會通過復制算法拷貝到生存區中(GC后存活下來的對象不會很多,復制開銷也不會很大).后續還會有GC掃描,不僅會掃描伊甸區,還會掃描生存區.生存區的大多數對象也會在掃描中被標記為垃圾.少部分存活的,又會繼續復制算法拷貝到另一個生存區匯中.這樣不斷往復,且每過一次GC,生存下來的對象年齡就會+1.
3. 當一個對象在生存區中經歷了若干次GC還沒有消亡,則JVM就會認為它的生命周期特別長,就會將它從生存區拷貝到老年代.
4. 老年代的對象也會被GC掃描,但是掃描頻率會大大降低.
5.當老年代的對象消亡時,JVM就會按照標記整理的方式,釋放內存(老年代的對象很少,所以搬運開銷不會很大)
到這里,上面的就是JVM中GC的核心思想.但是在一些實現細節上還是會有一些變數和優化~





![Sqli-labs靶場第16關詳解[Sqli-labs-less-16]自動化注入-SQLmap工具注入](http://pic.xiahunao.cn/Sqli-labs靶場第16關詳解[Sqli-labs-less-16]自動化注入-SQLmap工具注入)



簡介及其例題分析)









