MVCC
MVCC的目的
在搞清楚MVCC之前,我們要搞懂一個問題,MVCC到底解決的是什么問題?
我用一句話概括,那就是為了解決讀-寫可以一起的問題!
在我們的印象里,InnoDB可以讀讀并發,不能讀寫并發,或者寫寫并發
這是很正常的想法,因為如果讀寫并發的化,會有并發問題
而對于寫寫并發來說,我們還是得加鎖,這是沒辦法改的
但是對于讀-寫并發來說,我們就可以用MVCC來解決
所以,綜上所述,MVCC就是為了解決讀-寫并發,提高性能.
更準確的說,它是針對讀操作的!和寫操作關系不大
所以在MVCC的加持上,如果要解決并發問題?
讀 + MVCC
寫 + 鎖
解決哪些并發問題?
先說結論:
對于讀已提交
MVCC 解決了臟讀
對于可重復讀
MVCC 解決了臟讀 + 不可重復讀 + 幻讀
然后其次,我們要搞清楚,有四種隔離級別,我相信大家都知道
讀未提交 什么都沒解決
讀已提交 解決了臟讀
可重復讀 解決了臟讀 + 不可重復讀
串行 解決了臟讀 +不 可重復讀 + 幻讀
這我相信你也是滾瓜爛熟
那么對于MVCC來說,它實際解決了哪些問題呢? 這個我們就得分情況了,因為MVCC也是貼合四種隔離級別的!我先說這個就是為了有一個大致的方向
需要注意的是,對于MVCC來說,讀未提交 和 串行是束手無策的
你想一想就知道,讀未提交連臟讀都可以容忍,它還要你MVCC來干嘛,直接讀就可以了
對于串行來說,它的讀 + 寫都是串行化的,不管你讀還是寫,都要排隊,根本沒有讀 - 寫并發的情況
所以,我們需要明確一點,MVCC是針對讀已提交 + 可重復讀
想清楚這一點,我們再來分別看,MVCC解決的問題,你可能會問,既然你都是貼合四種隔離級別的,那不就是對應隔離級別解決的問題嘛,不是的,這里就是有一個特殊,所以我才會拿來說
對于讀已提交
MVCC 解決了臟讀
對于可重復讀
MVCC 解決了臟讀 + 不可重復讀 + 幻讀
那么比較特殊的一點就是,對于可重復讀來說,多解決了一個幻讀的問題
綜上所述,我們的結論就是,MVCC是針對讀已提交 + 可重復讀,并且在可重復讀的情況下,還多解決了一個幻讀問題
如何實現的?
讀到這里,你就很好奇了,它是如何實現的呢?
其實很簡單,就是一句話,MVCC讀的是副本,不是當前的當前正在并發的數據
我們來反過來想,為什么會出現臟讀 + 不可重復讀,就是因為事務在并發的時候,有可能會修改你正在讀的數據,這就導致,讀第二次的時候會出現不一致
那我們該如何解決呢?也很簡單,就是在事務一開始的時候,保存一份當前數據的副本,這樣就算其他事務修改了,它修改的是數據庫的數據,而不是我們的副本,這樣不就避免了這兩個問題嗎?
順著這個思路想,如果每次事務一開始的時候,我們都要取保存一份當前數據的副本,那如果有上億的讀的訪問的話,那不是內存炸了?
所以,我們得用MySQL現成的功能來實現這個副本的功能!
所以,自然而然你會想到,Undo log,只有它存著歷史的數據,那就是剛剛好的
至此,我們大致就可以引出了三個依賴
第一,隱藏字段
第二,Undo log
第三,Read View
Undo log就不用說了,就是為了生成副本的
Read View 也好說,不過是副本的官方的名字
對于隱藏字段來說,我們就得說一說了
對于聚簇索引來說,他有必要的隱藏列,
trx_id: 事務id
roll_pointer: 指針
事務id,就不用多說了,你需要一個標識來標識事務
對于roll_pointer來說,它和Undo log就會有聯系,就是一個指針嘛,我們直接看圖就能懂了,為什么需要roll_pointer,還有Undo log實際上長什么樣子
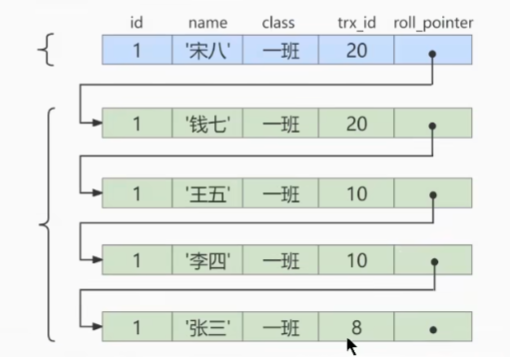
一看就懂,不就是鏈表嘛,第一個就是最新的記錄,后邊的都是歷史記錄
此時,你就大概能明白,為什么需要隱藏字段了把,其實也不是很重要,一筆帶過就行
我們特別要注意的是,Read View 副本的結構,這才是我們需要研究的東西
因為我們不熟啊
Read View結構
對于Read View我們先看圖,它的大致結構如下
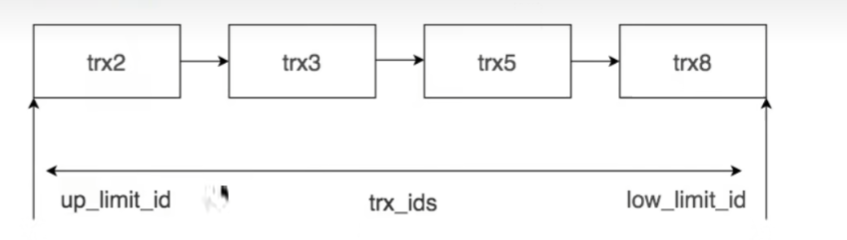
實際,它記錄的不是實際的數據,而是一群活躍的事務id
什么叫活躍的事務id呢?就是那些在并發的時候,在那搗亂的事務,為啥要記錄呢?很好理解嘛,在Undo log中,只要有這些搗蛋鬼做的記錄,我們就不看,讀那些已經提交的記錄
結構
creator_trx_id: 創建Readview的事務id
trx_ids: 活躍的事務id列表
up_limit_id: 最小的事務ID
low_limit_id: 下一個最大的事務ID
這里需要特別注意,up_limit_id是最小的
low_limit_id是最大的
還有一點是,這里的最小最大的選取標準是不一樣的
這里舉個例子,比較容易懂
比如說,事務id列表中,有三個事務id, 1,3,5
我們要假設MySQL只有這三個事務id,其他沒有,暗含的意思是,這里的id = 5,是當前生成的最大的事務id
那么up_limit_id 就是1
low_limit_id 是當前生成過的最大的事務id + 1 也就是 5 + 1 = 6
假設事務5提交了,此時的事務列表是1,3
low_limit_id 還是6,因為它類似于Auto_increment 自增id的意思,它會記錄當前生成過的最大的事務ID
ReadView的規則
我們研究這個規則,實際上就是研究MVCC的核心規則了
我們得對應著Undo log的版本鏈來看,版本鏈就是歷史記錄
如下
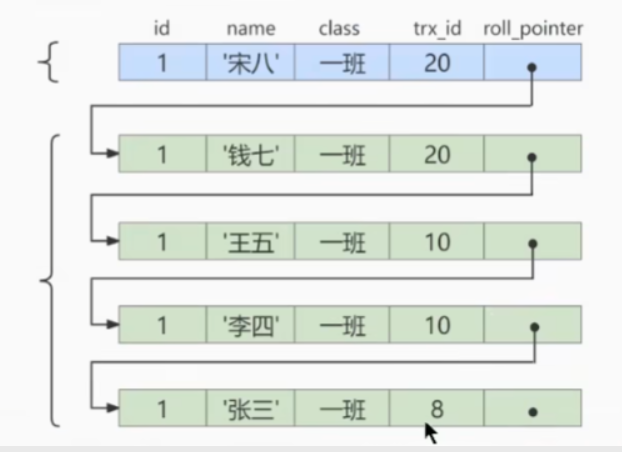
然后就著
ReadView的結構來看
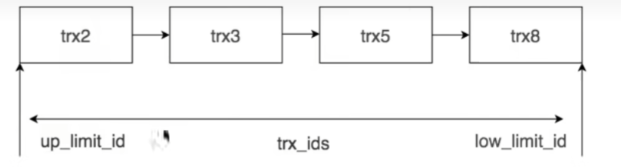
事務開始,生成一個ReadView,
然后當前事務,要讀取的時候,此時就會去查看兩個東西 ReadView + Undo log
查看Undo log就是順著鏈表一個一個往下看,找到符合條件的就返回
符合的條件就是規則
第一,如果此時查看的記錄trx_id = creator_trx_id,符合條件,讀此記錄
意思就是,當前記錄就是我們自己事務干的事,ReadView是我們當前事務自己生成的,自己讀自己的,當然沒問題
第二,如果不是自己的,就檢查,ReadView的trx_ids,也就是事務id列表
如果發現,當前訪問的記錄,就是這些搗蛋鬼其中一個干的,那就是不符合條件,如果發現不在這群事務id里邊,說明,當前讀的是,已經提交了的記錄,符合條件
第三,需要注意的是,對于第二,來說,當前的記錄的trx_id是介于
up_limit_id < 當前 事務id < low_limit_id,
up_limit_id,和low_limit_id,是一個范圍,還有一個功能就是快速的判斷
如果,最新的記錄是小于up_limit_id的,那么直接就是返回當前記錄
為什么呢?因為事務id是單調遞增的,和主鍵id一樣,如果我們最新的記錄都提交了,那更早的記錄是不是都提交了,返回返回沒問題!
如果,最新的記錄是大于等于low_limit_id的,那么不符合條件,往下找
為什么呢? 因為,如果此時最新的記錄是大于low_limit_id的,意思就是這個記錄它是在我們事務生成ReadView之后生成的,也就是
我們生成ReadView
然后緊接著,有一個事務進來修改了
那更不可能讀這條記錄了,比遲到的人還遲到.
綜上所述,我們總結一下
trx_id = creator_trx_id,可以讀
當trx_id < up_limit_id,可以讀
當trx_id >= low_limit_id,不可以讀
當up_limit_id <= trx_id < low_limit_id的時候,查看當前記錄的id是不是在trx_ids里邊,如果在的話,說明這是搗蛋鬼干的,不可以讀,如果不存在,可以讀
再總結一下,我們只要記住什么時候不可以讀
當trx_id >= low_limit_id 的時候,不可以讀
當trx_id在范圍中間,且當前的記錄id,在trx_ids里邊,不可以讀
其他情況都可以讀
讀已提交 和 可重復讀的不同流程
因為,MVCC要貼合這兩個隔離級別解決的問題,所以,他們的流程會有點不一樣
對于讀已提交來說,事務開始,每一次select都會去獲取ReadView
對于可重復讀來說,事務開始,到結束,只會獲取一次ReadView
這個想想就能明白,讀已提交,沒有解決不可重復讀問題,那么每一次讀ReadView的時候,有可能有一些事務就提交了,會讀到多的數據
可重復讀的時候,由于至始至終,只看一個ReadView,那就是事務開始的時候的ReadView,那可想而知,不會有可重復讀的問題,還有幻讀的問題了,因為,只看一個ReadView,就算多一萬遍,讀到的記錄還是不會多不會少,所以這也是為什么對于可重復讀來說,它可以解決幻讀問題了.
總結
所以我們最后來總結一下
MVCC的目的是什么?
為了解決讀-寫并發,但是只針對讀已提交 + 可重復讀
MVCC是怎么實現的?
第一,隱藏字段-> 事務id + 指針
第二,Undo log
第三,ReadView
如何實現這個問題,就轉換成ReadView如何做校驗?
對于讀已提交,每次select的時候,獲取一個ReadView
對于可重復讀,事務開始的時候,獲取一個ReadView
做實際的校驗
到最后,做校驗的問題,就轉換成校驗的規則是什么?
如果,trx_id >= low_limit_id,不符合條件
如果,up_limit_id <= trx_id < low_limit_id,并且trx_id在trx_ids中,不符合條件
其他情況都符合



![Sqli-labs靶場第16關詳解[Sqli-labs-less-16]自動化注入-SQLmap工具注入](http://pic.xiahunao.cn/Sqli-labs靶場第16關詳解[Sqli-labs-less-16]自動化注入-SQLmap工具注入)



簡介及其例題分析)











