目錄
一.只出現一次的數字
二.寶石與石頭
三.舊鍵盤
四.給定一個數組,統計每個元素出現的次數
五.前K個高頻單詞
一.只出現一次的數字
136. 只出現一次的數字 - 力扣(LeetCode)

算法原理:我們將nums中每個元素都存入到set中去,但是存入是有條件的,如果不存在就加進去,如果已經存在了那么我們就就將那個值移除。然后循環結束后我們看到只剩下一個元素,然后我們再次遍歷這個數組,因為set中就包含了一個元素,那么如果遍歷后那個數存在在set中,那么就返回那個值,否則返回-1;
class Solution {public int singleNumber(int[] nums) {HashSet<Integer> set=new HashSet<>();for(int x:nums){if(!set.contains(x)){set.add(x);//不包含就增加}else{set.remove(x);//包含就刪除}}//集合中只有一個元素for(int x:nums){if(set.contains(x)){return x;}//然后遍歷,如果包含就返回x}return -1;// TreeSet<Integer> set=new TreeSet<>();// for(int x:nums){// if(!set.contains(x)){// set.add(x);//不包含就增加// }else{// set.remove(x);//包含就刪除// }// }// //集合中只有一個元素// for(int x:nums){// if(set.contains(x)){// return x;// }// }// return -1;// }
}二.寶石與石頭
771. 寶石與石頭 - 力扣(LeetCode)

算法原理:我們設定一個HashSet,然后先將寶石中的字符串各個字符都存入到set中去,然后繼續遍歷石頭字符串,如果石頭中的字符串在set中,那么就計數++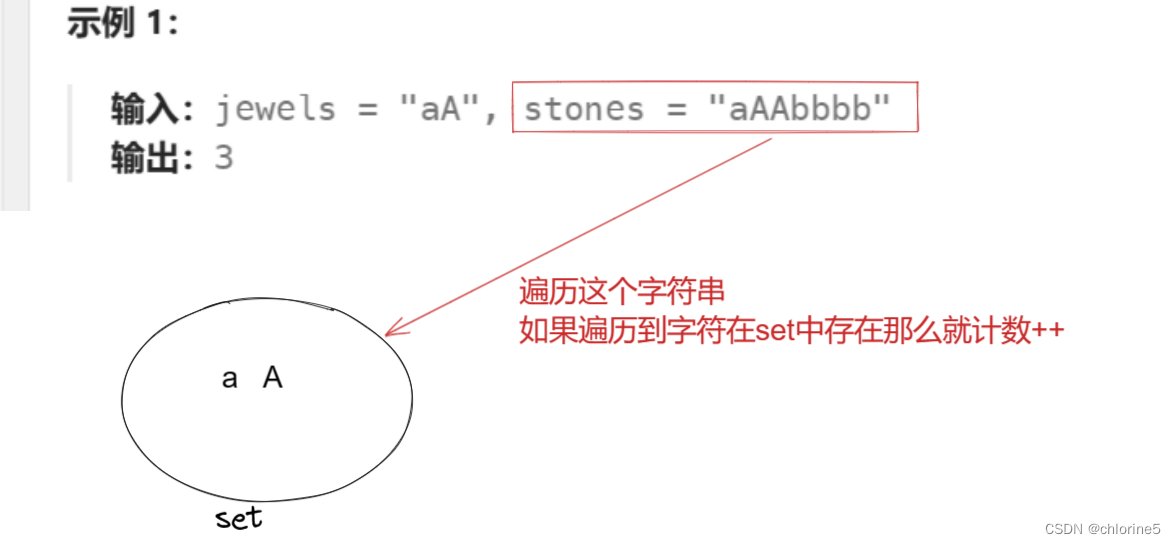
class Solution {public int numJewelsInStones(String jewels, String stones) {HashSet<Character>set=new HashSet<>();//先讓寶石里面的各個字符都放進hashset中for(char x:jewels.toCharArray()){set.add(x);}//ToCharArray( )的用法,將字符串對象中的字符轉換為一個字符數組。int sum=0;//然后遍歷石頭里的各個字符,判斷是否包含在set里面,如果包含就sum++for(char ch:stones.toCharArray()){if(set.contains(ch)){sum++;}}return sum;}
}toCharArray是將字符串轉為字符數組。
三.舊鍵盤
舊鍵盤 (20)__牛客網 (nowcoder.com)
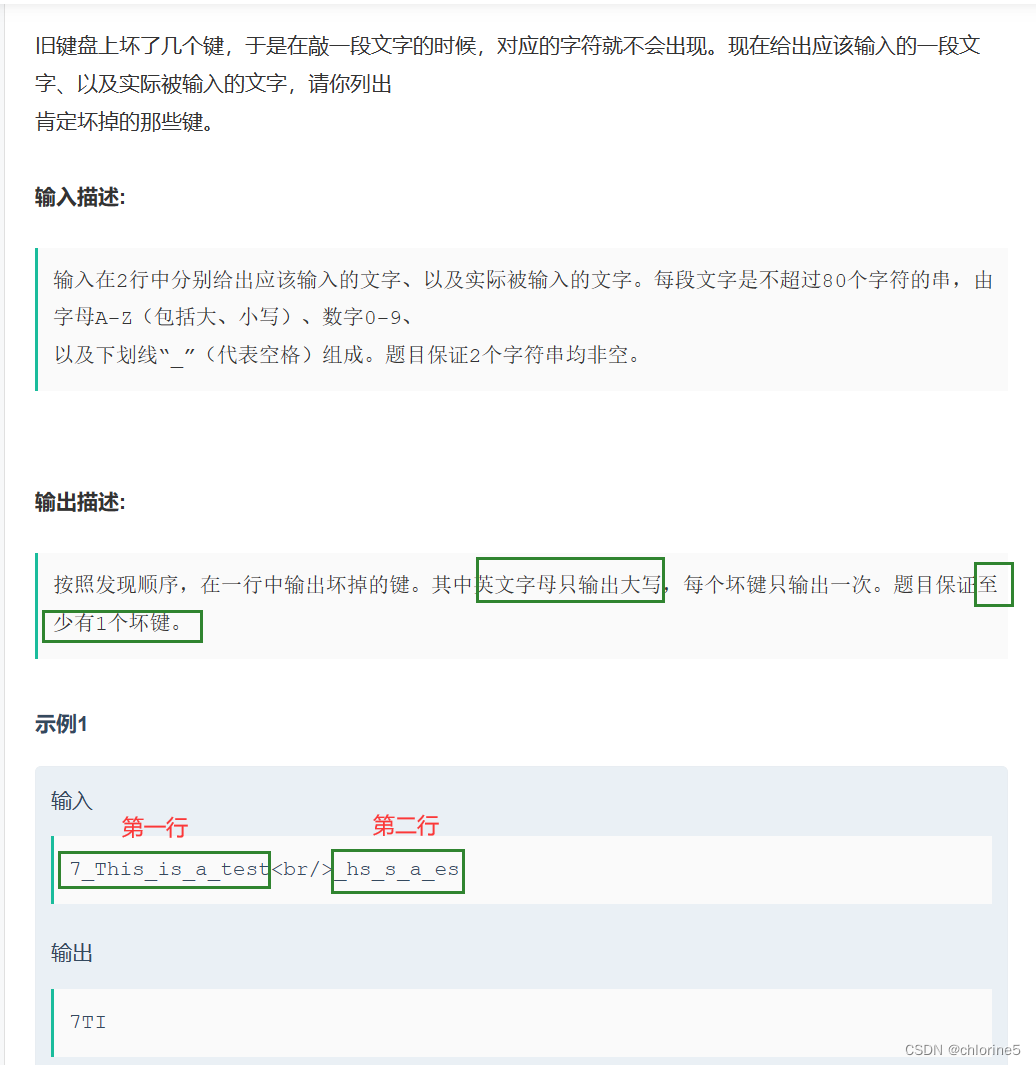
題目解析:
- 我們輸入第一行 (鍵盤沒壞) ——7_This_is_a_test
- 輸入第二行? ?(鍵盤壞了)—— _hs_s_a_es
我們看到壞掉的字符有? 7T i i t t 但是我們本題說明了,只輸出大寫,所以在第一行輸入的時候,t和T都是一樣的。而且題目也限制了,每個壞鍵只輸出一次。
倆個條件:1.每個壞鍵只輸出一次? ?2.只輸出大寫(說明在輸入第一行中,t和T都是一樣的)
算法原理:
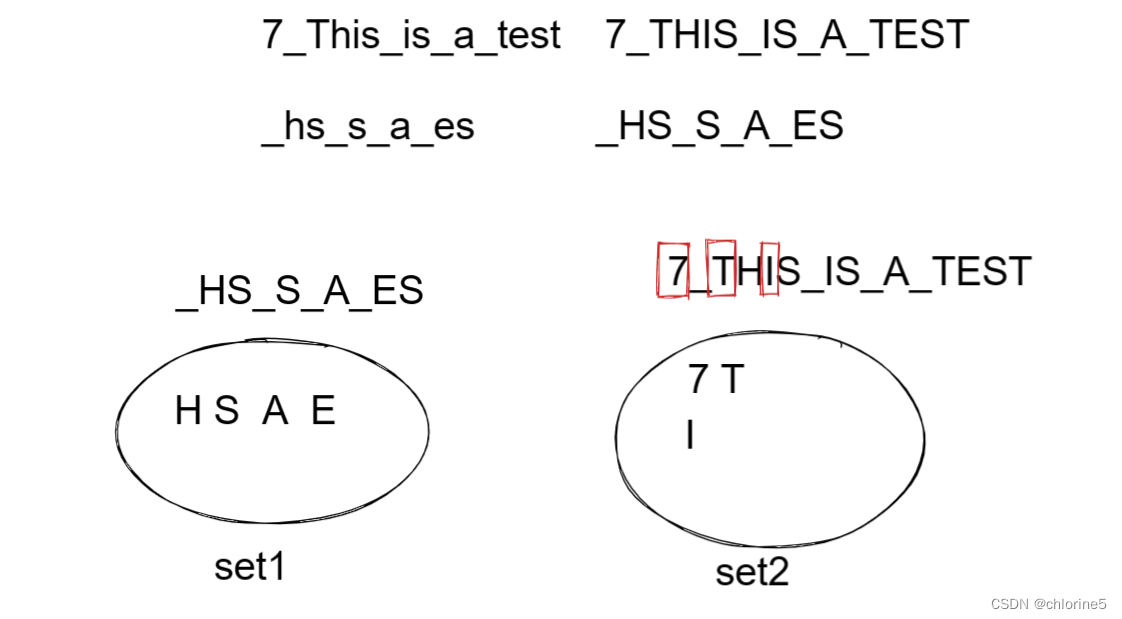
我們用str1記錄第一行,用str2記錄第二行。我們先將str2遍歷一遍,將str2中每個元素都存入到set中,然后遍歷str2字符串,如果遇到不包含的元素,我們就輸出,但是如果后面遇到同樣 比如 上面的字符串7_This_is_a_test,中i出現了倆次,題目規定壞鍵只能輸出一次。所以這時候我們就再定義一個set2,倆個條件,那個元素既不包含str1,也不包含在str2中,我們才輸出,并且讓那個值加到set2中。

所以我們 看到倆個條件,每個壞鍵只能輸出一次,所以當前面已經出現的字符,我們就不能在輸出了,此時就需要在創建一個set2,還有一個條件就是 不區分大小寫,T和t都是同一個字母,所以哪個已經輸出了,那么t就不能輸出了,所以我們直接將倆個字符串的每個字符都弄成大寫。
import java.util.*;// 注意類名必須為 Main, 不要有任何 package xxx 信息
public class Main {public static void main(String[] args) {Scanner in = new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的區別while (in.hasNextLine()) { // 注意 while 處理多個 caseString str1 = in.nextLine();String str2 = in.nextLine();func(str1,str2);}}private static void func(String str1,String str2){HashSet<Character> set1=new HashSet<>();for(char ch: str2.toUpperCase().toCharArray()){set1.add(ch);}//先將字符串2放入set中//然后再遍歷字符串1,如果字符串1中有元素不包含再字符串1和字符串2中,那么就輸出,并且將該字符加進set2中HashSet<Character> set2=new HashSet<>();//先轉大寫,然后轉字符數組for(char ch:str1.toUpperCase().toCharArray()){if(!set1.contains(ch) && !set2.contains(ch)){System.out.print(ch);set2.add(ch);}}}
}
我們需要先將字符串的每個元素轉成大寫,然后轉成字符數組。
四.給定一個數組,統計每個元素出現的次數
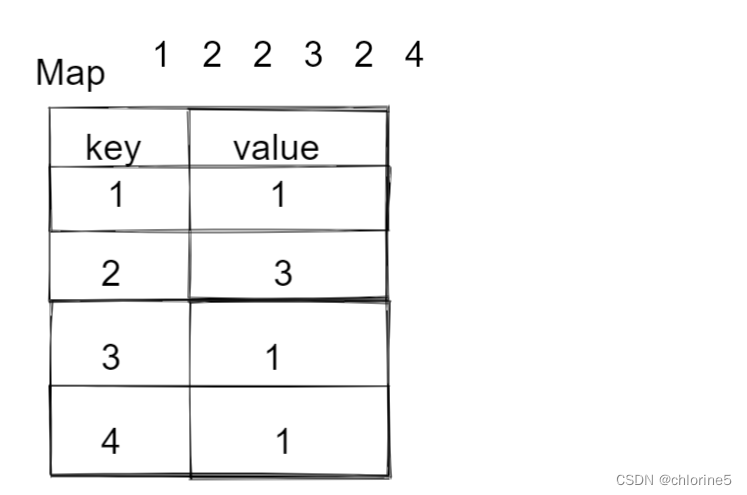
解題思路:
map中有個方法是get(),獲取key得到value,我們依次遍歷array數組,如果我們獲取到key,如果返回的value值是空,我們就put假如到map中,并計入key和value=1,如果value值不等于空,那么我們就先獲取當前key的value值,然后讓value值加1.
//給定一個數組,然后輸出每個元素出現的個數int[] array={1,2,3,3,1,4};HashMap<Integer,Integer>map=new HashMap<>();for(Integer x:array){if(map.get(x)==null){//如果x出現個數是null,那么我們就將value設置1map.put(x,1);}else{//如果3出現了1次之后,我們要先獲取3對應的個數,然后+1int value=map.get(x);map.put(x,value+1);}}for (Map.Entry<Integer,Integer>entry: map.entrySet()){System.out.println("key: "+entry.getKey()+" value: "+entry.getValue());}
 ?然后Map中有個Entry<K,V>,調用entrySet()就能得到所有的key-value映射關系。
?然后Map中有個Entry<K,V>,調用entrySet()就能得到所有的key-value映射關系。

五.前K個高頻單詞
692. 前K個高頻單詞 - 力扣(LeetCode)


算法原理:
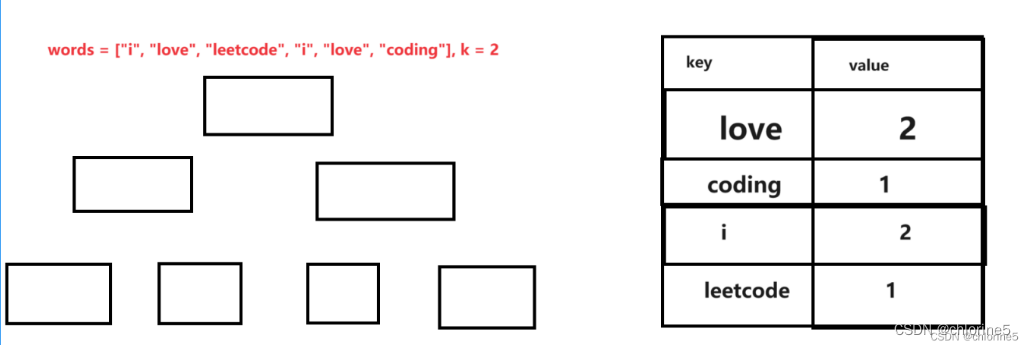
1.首先我們要記錄每個字符串出現的次數(請看第4題)
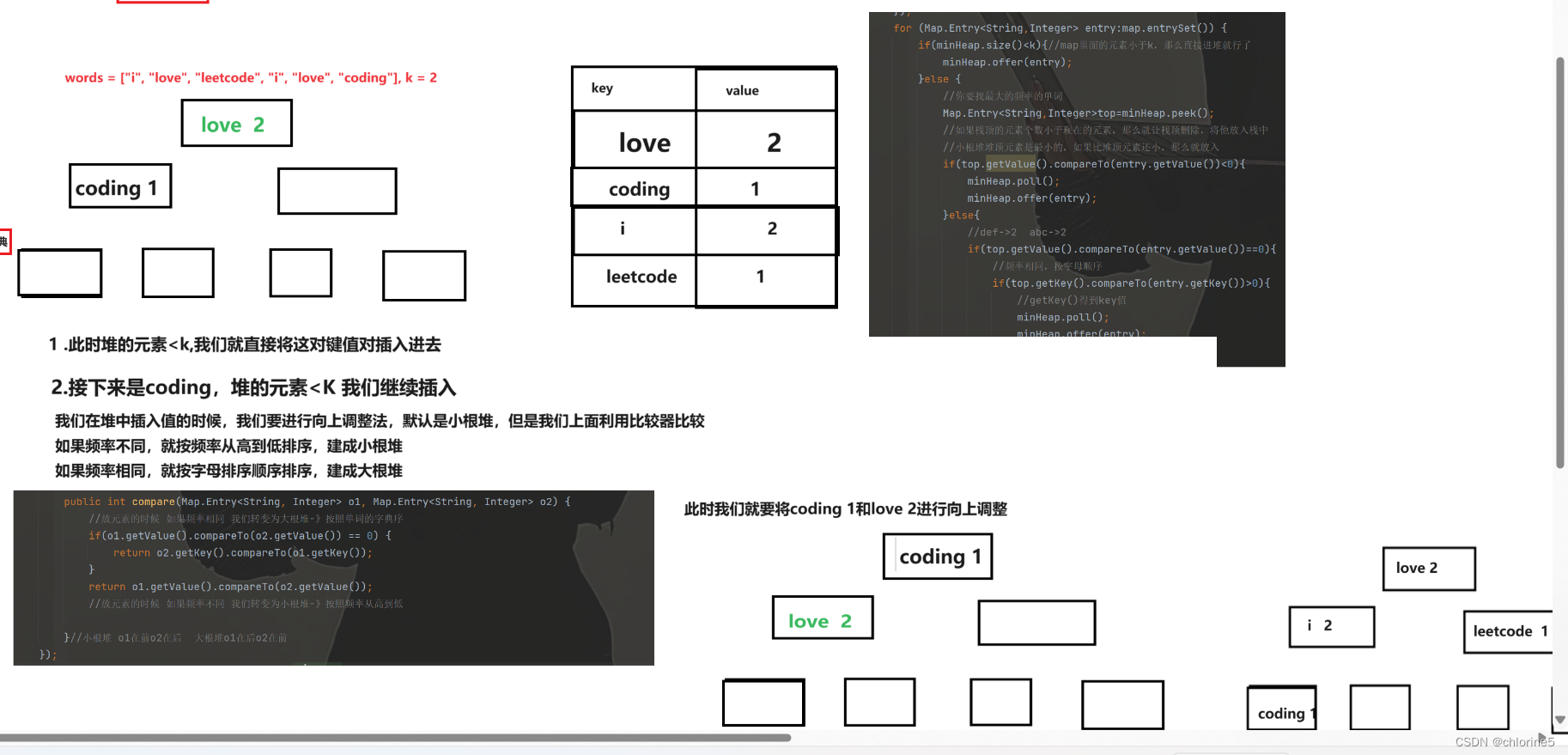
2.遍歷好統計的Map,把每組數據存儲到小根堆中
如果頻率相同,按字母比較(從小到大)——大根堆,頻率不同,按頻率高到低(從大到小)——小根堆。
//遍歷好統計的Map,把每組數據存儲到小根堆中PriorityQueue<Map.Entry<String,Integer>>minHeap =new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {//放元素的時候 如果頻率相同 我們轉變為大根堆-》按照單詞的字典序if(o1.getValue().compareTo(o2.getValue()) == 0) {return o2.getKey().compareTo(o1.getKey());}//放元素的時候 如果頻率不同 我們轉變為小根堆-》按照頻率大小排序return o1.getValue().compareTo(o2.getValue());}});//小根堆 o1在前o2在后 大根堆o1在后o2在前因為我們要分情況 建大堆 還是建小堆。
然后遍歷Map,利用Map的entrySet(),找前k個出現單詞數最多的,你要找頻率最大單詞,如果堆的元素小于k,那么我們就直接將Map的鍵值對都offer進去,如果大于k,我們就要先獲取堆頂元素,然后判斷堆頂元素的value值是不是小于當前的entry的value,如果小于,那么就將堆頂刪除,然后讓offer當前的元素,如果大于,就繼續循環,如果堆頂的value等于entry的value(說明出現的頻率是相等的)那么,我們就要比較當前堆頂的key值和entry的key值是大于還是小于,如果大于,那么就要將當前的刪除,然后offer當前entry值。
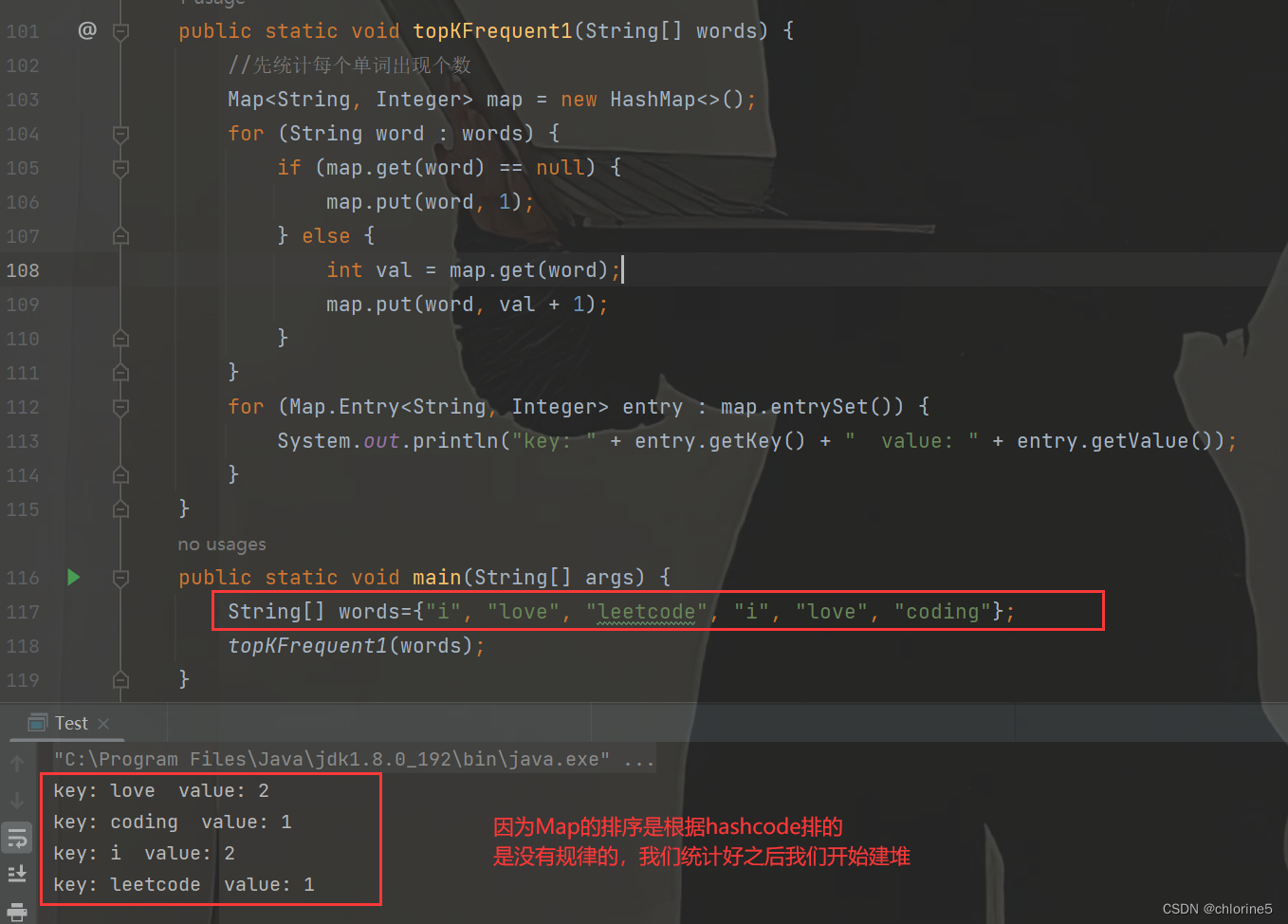
class Solution {public List<String> topKFrequent(String[] words, int k) {//先統計每個單詞出現個數Map<String,Integer>map=new HashMap<>();for (String word:words) {if(map.get(word)==null){map.put(word,1);}else{int val=map.get(word);map.put(word,val+1);}}//遍歷好統計的Map,把每組數據存儲到小根堆中PriorityQueue<Map.Entry<String,Integer>>minHeap =new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {//放元素的時候 如果頻率相同 我們轉變為大根堆-》按照單詞的字典序if(o1.getValue().compareTo(o2.getValue()) == 0) {return o2.getKey().compareTo(o1.getKey());//大根堆}return o1.getValue().compareTo(o2.getValue());//小根堆}//小根堆 o1在前o2在后 大根堆o1在后o2在前});for (Map.Entry<String,Integer> entry:map.entrySet()) {if(minHeap.size()<k){//map里面的元素小于k,那么直接進堆就行了minHeap.offer(entry);}else {//你要找最大的頻率的單詞Map.Entry<String,Integer>top=minHeap.peek();//如果棧頂的元素個數小于現在的元素,那么就讓棧頂刪除,將他放入棧中//小根堆堆頂元素是最小的,如果比堆頂元素還小,那么就放入if(top.getValue().compareTo(entry.getValue())<0){minHeap.poll();minHeap.offer(entry);}else{//def->2 abc->2if(top.getValue().compareTo(entry.getValue())==0){//頻率相同,按字母順序if(top.getKey().compareTo(entry.getKey())>0){//getKey()得到key值minHeap.poll();minHeap.offer(entry);}}}}}//2 3 4List<String>ret=new ArrayList<>();for (int i = 0; i <k ; i++) {Map.Entry<String,Integer>top=minHeap.poll();ret.add(top.getKey());}//拿到的是 2 3 4,然后需要逆置Collections.reverse(ret);//Collections是逆置return ret;}
}好好的生活,來又去,去又來。



![[LeetBook]【學習日記】鏈表反轉](http://pic.xiahunao.cn/[LeetBook]【學習日記】鏈表反轉)






 使用提醒)




![c++ [[nodiscard]]關鍵字詳解](http://pic.xiahunao.cn/c++ [[nodiscard]]關鍵字詳解)
 ● 322. 零錢兌換 ● 279.完全平方數)


)