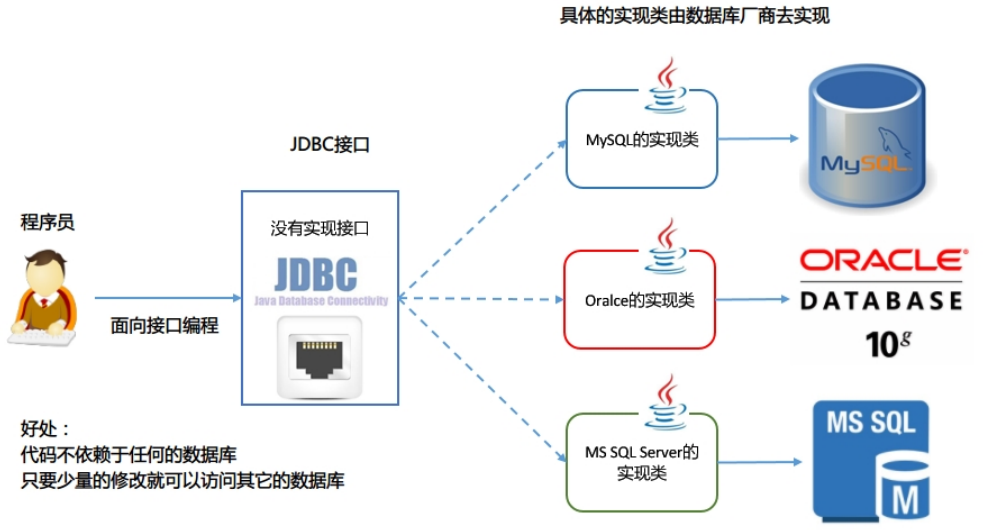
Java數據庫連接 Java DataBase Connectivity。JDBC 規范定義接口,具體的實現由各大數據庫廠商來實現。
JDBC可讓Java通過程序操作關系型數據庫,JDBC基于驅動程序實現與數據庫的連接與操作。
JDBC 是 Java 訪問數據庫的標準規范,真正怎么操作數據庫還需要具體的實現類,也就是數據庫驅動。每個數據庫廠商根據自家數據庫的通信格式編寫好自己數據庫的驅動。
使用 JDBC 的好處:
- 程序員如果要開發訪問數據庫的程序,只需要會調用 JDBC 接口中的方法即可,不用關注類是如何實現的。
- 使用同一套 Java 代碼,進行少量的修改就可以訪問其他 JDBC 支持的數據庫
JDBC開發使用到的包:
java.sql:所有與 JDBC 訪問數據庫相關的接口和類javax.sql:數據庫擴展包,提供數據庫額外的功能。如:連接池。- 數據庫的驅動:由各大數據庫廠商提供,需要額外去下載,是對 JDBC 接口實現的類。
JDBC核心API:
DriverManager類:管理和注冊數據庫驅動、得到數據庫連接對象。Connection接口:一個連接對象,可用于創建 Statement 和 PreparedStatement 對象。Statement接口:一個 SQL 語句對象,用于將 SQL 語句發送給數據庫服務器。PreparedStatemen接口:一個 SQL 語句對象,是 Statement 的子接口。ResultSet接口:用于封裝數據庫查詢的結果集,返回給客戶端 Java 程序。
快速入門
- 注冊和加載驅動(可以省略)
- 獲取連接
- Connection 獲取 Statement 對象,執行SQL語句
- 返回結果集
- 釋放資源
package com.arbor.jdbc.sample;
import java.sql.*;/*** 描述:標準JDBC操作步驟*/
public class StandardJDBCSample {public static void main(String[] args) {Connection conn = null;try {// 一、加載并注冊jdbc驅動// 先將MySQL的驅動包放入lib文件夾下,然后加載Driver類Class.forName("com.mysql.cj.jdbc.Driver");// 二、創建數據庫連接// DriverManager.getConnection():獲取數據庫連接conn = DriverManager.getConnection(// 數據庫連接地址"jdbc:mysql://localhost:3306/arbor_study?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai",// 數據庫用戶名"root",// 數據庫密碼"1019");// 三、創建Statement對象,用來執行sql語句Statement stmt = conn.createStatement();// executeQuery():用于執行查詢語句// ResultSet:結果集對象ResultSet rs = stmt.executeQuery("select * from jdbc_employee where dname = '研發部'");// 四、遍歷查詢結果// next():每執行一次,會提取一條新的記錄,有下一行返回true,沒有下一行返回false// 循環遍歷rs中的數據while (rs.next()) {// 將查詢的這一行數據的第一列作為int類型輸出,并用int接收int eno = rs.getInt(1); // 1 代表的是字段的位置,就是這一行的第一列,jdbc字段索引從1開始String ename = rs.getString("ename"); // ename 代表的是字段的名稱float salary = rs.getFloat("salary");String dname = rs.getString("dname");// 輸出查詢到的記錄System.out.println(eno + " - " + ename + " - " + salary + " - " + dname);}} catch (Exception e) {e.printStackTrace();} finally {// 五、關閉連接,釋放資源try {// 如果conn不是空的,并且連接沒有被關閉,則執行close()方法關閉連接// isClosed():判斷當前連接是否關閉if (conn != null && !conn.isClosed()) {// 關閉連接,釋放資源conn.close();}} catch (Exception ex) {ex.printStackTrace();}}}
}
加載和注冊驅動
Class.forName(數據庫驅動實現類):加載和注冊數據庫驅動,數據庫驅動由 mysql 廠商提供。
| 數據庫 | JDBC驅動類 | 連接字符串 |
|---|---|---|
| MySQL5 | com.mysql.jdbc.Driver | jdbc:mysql://主機ip:端口/數據庫名 |
| MySQL8 | com.mysql.cj.jdbc.Driver | jdbc:mysql://主機ip:端口/數據庫名 |
| Oracle | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:@主機ip:端口:數據庫名 |
| SQL Server | com.mircosoft.sqlserver.jdbc.SQLServerDriver | jdbc:mircosoft:sqlserver:主機ip:端口:databasename=數據庫名 |
從JDBC3開始,目前已經普遍使用的版本。可以不用注冊驅動而直接使用。Class.forName這句話可以省略。
DriverManager類(創建連接)
用于注冊/管理JDBC驅動程序,創建數據庫連接。
-
Connection getConnection (String url, String user, String password):通過連接字符串,用戶名,密碼來得到數據庫的連接對象。String url:數據庫的連接字符串String user:登錄數據庫的用戶名String password:登錄數據庫的密碼
-
Connection getConnection (String url, Properties info):通過連接字符串,屬性對象來得到連接對象。
數據庫的連接字符串:
jdbc:mysql://[主機ip][:端口]/數據庫名?參數列表,參數列表采用URL編碼,格式:參數值1=值1&參數值2=值3&...
jdbc:mysql://localhost:3306/arbor_study?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKyeRetrieval=true

MySQL連接字符串常用參數
| 參數名 | 建議參數值 | 說明 |
|---|---|---|
useSSL | true(生產) false(開發) | 是否禁用SSL |
useUnicode | true | 啟用unicode編碼傳輸數據 |
characterEncoding | UTF-8 | 使用UTF-8編碼傳輸數據 |
serverTimezone | Asia/Shanghai | 使用東8時區時間,UTC+8 |
allowPublicKyeRetrieval | true | 允許從客戶端獲取公鑰加密傳輸 |
Connection接口
用于JDBC與數據庫的網絡通信對象,具體的實現類由數據庫的廠商實現,代表一個連接對象。所有數據庫的操作都建立在Connection。
Statement createStatement():創建一條SQL語句對象PreparedStatement prepareStatement(String sql):指定預編譯的 SQL 語句,SQL 語句中使用占位符?創建一個語句對象
Statement接口
代表一條語句對象,用于發送 SQL 語句給服務器,用于執行靜態 SQL 語句并返回它所生成結果的對象。
int executeUpdate(String sql):用于發送 DML 語句,增刪改的操作,insert、update、delete,返回對數據庫影響的行數ResultSet executeQuery(String sql):用于發送 DQL 語句,執行查詢的操作,select,返回查詢的結果集
PreparedStatement接口
PreparedStatement 是 Statement 接口的子接口,繼承于父接口中所有的方法。對SQL進行參數化,預防SQL注入攻擊,安全性更高。因為有預先編譯的功能,比Statemen執行效率更高。提高了程序的可讀性。

常用方法
int executeUpdate():執行DML,增刪改的操作,返回影響的行數。不用傳參
返回值:返回對數據庫影響的行數
ResultSet executeQuery():執行DQL,查詢的操作,返回結果集。不用傳參
返回值:查詢的結果集
設置參數的方法
setDouble(int parameterIndex, double x):將指定參數設置為給定double值setFloat(int parameterIndex, float x):將指定參數設置為給定float值setInt(int parameterIndex, int x):將指定參數設置為給定int值setLong(int parameterIndex, long x):將指定參數設置為給定long值setObject(int parameterIndex, Object x):使用給定對象設置指定參數的值setString(int parameterIndex, String x):將指定參數設置為給定String值
時間類型轉換
批處理
addBatch():將參數加入批處理任務,添加任務,不執行executeBatch():執行批處理任務
// 時間類型轉換
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date udHiredate = null ;
try {
udHiredate = sdf.parse(strHiredate);
} catch (ParseException e) {
e.printStackTrace();
}
long time = udHiredate.getTime();
java.sql.Date sdHiredate = new java.sql.Date(time);// 批處理
preparedStatement = conn.prepareStatement(sql);
for (int i = 200000; i < 300000; i++) {
preparedStatement.setInt(1, i);
preparedStatement.setString(2, "員工" + i);
preparedStatement.setFloat(3, 4000);
preparedStatement.setString(4, "測試部");
preparedStatement.addBatch();// 將參數加入批處理任務,添加任務,不執行
}
preparedStatement.executeBatch();// 執行批處理任務
使用 PreparedStatement 的步驟:
- 編寫SQL語句,未知內容使用
?占位:SELECT * FROM user WHERE name=? AND password=?; - 獲得 PreparedStatement 對象
- 設置實際參數:setXxx(占位符的位置,真實的值)
- 執行參數化 SQL 語句
- 關閉資源
ResultSet接口
封裝數據庫查詢的結果集,對結果集進行遍歷,取出每一條記錄。
boolean next():游標向下移動 1 行,返回 boolean 類型,如果還有下一條記錄,返回 true,否則返回 false數據類型 getXxx(String str/int no):通過字段名,參數是 String 類型,返回不同的類型;通過列號,參數是整數,從 1 開始,返回不同的類型
| SQL 類型 | Jdbc 對應方法 | 返回類型 |
|---|---|---|
| BIT(1) bit(n) | getBoolean() | boolean |
| TINYINT | getByte() byte | byte |
| SMALLINT | getShort() | short |
| INT | getInt() | int |
| BIGINT | getLong() | long |
| CHAR,VARCHAR | getString() | String |
| Text(Clob) Blob | getClob getBlob() | Clob Blob |
| DATE | getDate() | java.sql.Date 只代表日期 |
| TIME | getTime() | java.sql.Time 只表示時間 |
| TIMESTAMP | getTimestamp() | java.sql.Timestamp 同時有日期和時間 |
java.sql.Date、Time、Timestamp(時間戳),三個共同父類是:java.util.Date
- 如果光標在第一行之前,使用
rs.getXX()獲取列值,報錯:Before start of result set- 如果光標在最后一行之后,使用
rs.getXX()獲取列值,報錯:After end of result set- 使用完畢以后要關閉結果集 ResultSet,再關閉 Statement,再關閉 Connection,先開的后關,后開的先關
JDBC事務管理
自動提交事務模式: 指每執行一次寫操作SQL,自動提交事務,是JDBC默認行為,此模式無法保證多數據一致性
手動提交事務模式: 可保證多數據一致性,但必須手動調用提交/回滾方法
Connection接口中與事務有關的方法
setAutoCommit(boolean autoCommit):參數是 true 或 false,如果設置為 false,表示關閉自動提交,相當于開啟事務commit():提交事務rollback():回滾事務
public class TransactionSample {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;try {conn = DBUtils.getConnection();String sql = "insert into jdbc_employee (eno, ename, salary, dname) values (?, ?, ?, ?)";// 關閉自動事務,開啟手動事務conn.setAutoCommit(false);for (int i = 1000; i < 2000; i++) {// 模擬一個異常/*if (i == 1005) {throw new RuntimeException("插入失敗");}*/ps = conn.prepareStatement(sql);ps = conn.prepareStatement(sql);ps.setInt(1, i);ps.setString(2, "員工" + i);ps.setFloat(3, 4000);ps.setString(4, "測試部");ps.executeUpdate();}} catch (Exception e) {e.printStackTrace();try {// 回滾事務if (conn != null && !conn.isClosed()) {conn.rollback();}} catch (SQLException throwables) {throwables.printStackTrace();}} finally {// 提交事務try {if (conn != null && !conn.isClosed()) {conn.commit();}} catch (SQLException e) {e.printStackTrace();}DBUtils.closeConnection(null, ps, conn);}}
}
JDBC 連接池
連接池是一個容器(集合),存放數據庫連接的容器。當系統初始化好后,容器被創建,容器中會申請一些連接對象,當用戶來訪問數據庫時,從容器中獲取連接對象,用戶訪問完之后,會將連接對象歸還給容器。
- 節約資源
- 用戶訪問高效
阿里巴巴Druid連接池
Druid是阿里巴巴開源連接池組件,是最好的連接池之一,Druid對數據庫連接進行有效管理與重用,最大化程序執行效率,連接池負責創建管理連接,程序只負責取用與歸還。
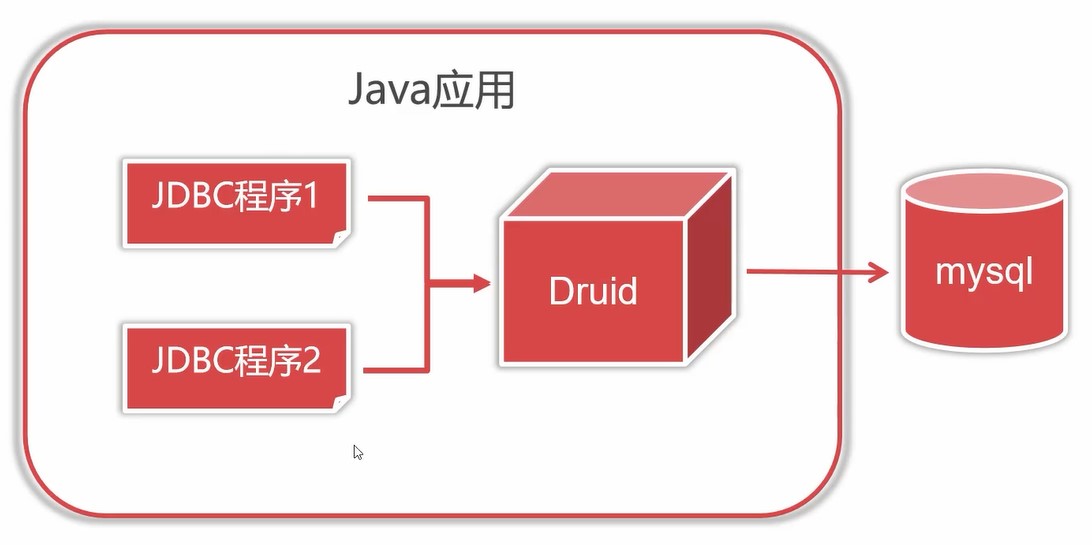
不使用連接池關閉資源的話是關閉連接,使用連接池關閉資源的話,是將連接回收至連接池中。
第一步: 導入jar包,下載地址:https://github.com/alibaba/druid/releases
第二步: 定義配置文件 druid-config.properties(文件名可以更改)
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/arbor_study?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKyeRetrieval=true
username=root
password=1019# 初始連接數
initialSize=10
# 最大連接數
maxActive=20
第三步: 加載配置文件
第四步: 獲取DataSource數據源對象
第五步: 創建數據庫連接
第六步: 關閉資源
/*** 描述:Druid連接池的配置和使用*/
public class DruidSample {public static void main(String[] args) {// 一、加載屬性文件Properties properties = new Properties();// 獲取配置文件的路徑String propertyFile = DruidSample.class.getResource("/druid-config.properties").getPath();try {// 設置獲取到的路徑的編碼propertyFile = URLDecoder.decode(propertyFile, "UTF-8");// 加載配置文件properties.load(new FileInputStream(propertyFile));} catch (Exception e) {e.printStackTrace();}Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {// 二、獲取DataSource數據源對象DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);// 三、創建數據庫連接connection = dataSource.getConnection();preparedStatement = connection.prepareStatement("select * from jdbc_employee limit 0,10");resultSet = preparedStatement.executeQuery();while (resultSet.next()) {int eno = resultSet.getInt(1);String ename = resultSet.getString("ename");float salary = resultSet.getFloat("salary");String dname = resultSet.getString("dname");Date hiredate = resultSet.getDate("hiredate");// 輸出查詢到的記錄System.out.println(eno + " - " + ename + " - " + salary + " - " + dname + " - " + hiredate);}} catch (Exception e) {e.printStackTrace();}finally {DBUtils.closeConnection(resultSet, preparedStatement, connection);}}
}
C3P0連接池
第一步: 導入jar包 (兩個jar包) ,下載地址:https://sourceforge.net/projects/c3p0/
第二步: 定義配置文件 c3p0-config.xml(文件名固定)
<?xml version="1.0" encoding="UTF-8" ?>
<c3p0-config><default-config><property name="driverClass">com.mysql.cj.jdbc.Driver</property><property name="jdbcUrl">jdbc:mysql://localhost:3306/arbor_study?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKyeRetrieval=true</property><property name="user">root</property><property name="password">1019</property><!--初始連接數--><property name="initialPoolSize">10</property><!--最大連接數--><property name="maxPoolSize">20</property></default-config>
</c3p0-config>
第三步: 加載配置文件,并創建DataSource
第四步: 創建數據庫連接
第五步: 關閉資源
/*** 描述:C3P0連接池的配置和使用*/
public class C3P0Sample {public static void main(String[] args) {// 一、加載配置文件,并創建DataSourceDataSource dataSource = new ComboPooledDataSource();Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;try {// 二、創建數據庫連接connection = dataSource.getConnection();preparedStatement = connection.prepareStatement("select * from jdbc_employee limit 0,10");resultSet = preparedStatement.executeQuery();while (resultSet.next()) {int eno = resultSet.getInt(1);String ename = resultSet.getString("ename");float salary = resultSet.getFloat("salary");String dname = resultSet.getString("dname");Date hiredate = resultSet.getDate("hiredate");// 輸出查詢到的記錄System.out.println(eno + " - " + ename + " - " + salary + " - " + dname + " - " + hiredate);}} catch (Exception e) {e.printStackTrace();}finally {DBUtils.closeConnection(resultSet, preparedStatement, connection);}}
}
JDBC工具類
Apache Commons DBUtils
commons-dbutils是 Apache提供的開源 JDBC工具類庫,它是對JDBC的簡單封裝,學習成本極低,使用commons-dbutils可以極大簡化JDBC編碼工作量。
第一步: 導入jar包,下載地址:http://commons.apache.org/proper/commons-dbutils/download_dbutils.cgi
第二步: 創建Druid數據庫連接
第三步: 使用commons dbutils
查詢:
Properties properties = new Properties();
try {String propertyFile = DBUtilsSample.class.getResource("/druid-config.properties").getPath();propertyFile = URLDecoder.decode(propertyFile, "UTF-8");properties.load(new FileInputStream(propertyFile));DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);// 使用commons dbutilsQueryRunner runner = new QueryRunner(dataSource);List<Employee> list = runner.query("select * from jdbc_employee limit ?,10",new BeanListHandler<>(Employee.class), // 返回的類型的定義new Object[]{10}); // 對應的是SQL語句中 ? 的值// 循環遍歷查詢到的數據for (Employee employee : list) {System.out.println(employee);}
} catch (Exception e) {e.printStackTrace();
}
更新:
Properties properties = new Properties();
Connection connection = null;
try {String propertyFile = DBUtilsSample.class.getResource("/druid-config.properties").getPath();propertyFile = URLDecoder.decode(propertyFile, "UTF-8");properties.load(new FileInputStream(propertyFile));DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);connection = dataSource.getConnection();// 開啟事務,因為需要事務操作,所以需要獲取Connection對象connection.setAutoCommit(false);String sql1 = "update jdbc_employee set salary = salary + 1000 where eno = ?";String sql2 = "update jdbc_employee set salary = salary - 500 where eno = ?";QueryRunner runner = new QueryRunner();runner.update(connection, sql1, 1000);runner.update(connection, sql2, 1001);// 提交事務connection.commit();
} catch (Exception e) {e.printStackTrace();try {if (connection != null && !connection.isClosed())// 回滾事務connection.rollback();} catch (Exception exception) {exception.printStackTrace();}
}finally {try {if (connection != null && !connection.isClosed())// 回收資源connection.close();} catch (Exception exception) {exception.printStackTrace();}
}
Spring JDBC
Spring框架對JDBC的簡單封裝。提供了一個JDBCTemplate對象簡化JDBC的開發。
第一步: 導入jar包
第二步: 創建JdbcTemplate對象。依賴于數據源DataSource
JdbcTemplate template = new JdbcTemplate(ds);
第三步: 調用JdbcTemplate的方法來完成CRUD的操作
update():執行DML語句。增、刪、改語句。queryForMap():查詢結果將結果集封裝為map集合,將列名作為key,將值作為value 將這條記錄封裝為一個map集合。這個方法查詢的結果集長度只能是1。queryForList():查詢結果將結果集封裝為list集合,將每一條記錄封裝為一個Map集合,再將Map集合裝載到List集合中。query():查詢結果,將結果封裝為JavaBean對象。query的參數:RowMapper,一般使用BeanPropertyRowMapper實現類。可以完成數據到JavaBean的自動封裝new BeanPropertyRowMapper<類型>(類型.class)queryForObject:查詢結果,將結果封裝為對象,一般用于聚合函數的查詢













(下))

求解23個基準函數)



:Sora技術路徑整體認知)