前文:最近跟著DataWhale組隊學習這一期“Sora原理與技術實戰”,本篇博客主要是基于DataWhale成員、廈門大學平潭研究院楊知錚研究員分享的Sora技術原理詳解課件內容以及參考網上一些博客資料整理而來(詳見文末參考文獻),算是對Sora技術路徑的發展有個系統性的認識。
Sora是什么
Sora是大火的人工智能公司OpenAI推出的新一代文生視頻AI模型,其官網為https://openai.com/sora。Sora的亮點在于:最長支持60s高清視頻生成、確保連續畫面中人和場景的一致性、根據視頻生成視頻時具有絲滑視頻過渡能力、同一場景多視角/鏡頭生成能力、支持任意分辨率、寬高比的視頻生成,因此秒殺Pika、Runway等同行,在2024年2月份也火爆出拳,OpenAI的技術報告稱其為“作為世界模擬器的視頻生成模型”(源地址:Video generation models as world simulators)。然而Sora也有許多局限,特別是對物理規律的理解仍然比較有限,例如生成一個玻璃杯摔碎的場景時并未很好表現碎片四溢的物理過程。
Sora的能力可以總結為:文生視頻、圖生視頻和視頻生成視頻。Sora是通過不同長度、分辨率和長寬比的視頻和圖像數據共同訓練出的一種“文本條件擴散模型”,其中Sora只是模型名統稱,底層包含Diffusion model、Transformer等SOTA模型架構。
Sora模型訓練
Sora模型架構
Sora整合了自家的GPT和DALL-E模型,其中,GPT-4就是基于Transformer架構的大型神經網絡,目前在自然語言處理領域獨樹一幟,而最新的DALL-E 3是基于文本提示生成圖像的圖像生成模型。Sora使用了DALL-E 3中的重新標注技術,準備了大量帶有文本標題的視頻數據,通過訓練一個高度描述性的標題模型,為所有視頻生成文本標題,來提高文本準確性,改善了視頻質量。同時,Sora利用GPT將用戶簡短的提示轉化為更長、更詳細的標題,指導視頻的生成過程,從而使Sora能夠生成高質量的視頻,并準確地遵循用戶的指示。如下為一張Sora模型訓練流程示意圖:
 由于Sora未完全開放,目前魔塔社區所推測的Sora模型架構(與Latent Diffusion Model很像)如下:原始數據輸入經過視頻壓縮網絡后變成時間和空間上都被壓縮的潛在表示,隨后在時空潛空間上,基于conditioning訓練中的video caption技術所生成視頻-文本對的指導,通過Diffusion Transformer(DiT)生成新的視頻潛在表示,最后經過解碼器映射回像素空間。
由于Sora未完全開放,目前魔塔社區所推測的Sora模型架構(與Latent Diffusion Model很像)如下:原始數據輸入經過視頻壓縮網絡后變成時間和空間上都被壓縮的潛在表示,隨后在時空潛空間上,基于conditioning訓練中的video caption技術所生成視頻-文本對的指導,通過Diffusion Transformer(DiT)生成新的視頻潛在表示,最后經過解碼器映射回像素空間。
 Sora模型訓練一些要點:
Sora模型訓練一些要點:
- 類似于大語言模型(LLM)中的基本訓練單位為:文本token,圖像模型的基本訓練單位:圖像patch;通過visual encoder將高維度的視頻數據(NxHxW幀圖像)切分為圖像塊(spatial temporal patch),從而將視頻壓縮到一個低維度的spacetime latent space;
- 圖像patch包含時間序列信息和空間像素信息,基于patch的表示有助于模型處理圖像局部信息,并能訓練具有不同分辨率、持續時間和長寬比的視頻和圖像;
- 圖像patch將展開為一維向量,并通過einops張量操作庫進行操作,從而有效處理圖像數據;
擴散模型之DDPM
Sora采用了Diffusion模型中的DDPM (Denoising Diffusion Probabilistic Models)作為圖像生成模型。相比GAN來說,Diffusion模型訓練更穩定,而且能夠生成更多樣本,OpenAI的論文《Diffusion Models Beat GANs on Image Synthesis》也證明了Diffusion 模型能夠超越GAN。一些主流的文生圖像模型如DALL-E 2, stable diffusion以及Imagen都紛紛采用了Diffusion模型用于圖像生成。
一般來說,Diffusion模型包含兩個過程,均為一個參數化的馬爾科夫鏈 (Markov chain):
- 前向擴散過程 (diffusion):對一張圖像逐漸添加高斯噪音直至變成隨機噪音的過程(數據噪聲化)
- 反向生成過程 (reverse diffusion):從隨機噪音開始逐漸去噪直至生成一張圖像,這也是需要求解/訓練的部分(去噪生成數據)
Diffusion模型與其它主流生成模型的對比如下所示:

目前所采用的Diffusion模型大都是基于2020年的工作《DDPM: Denoising Diffusion Probabilistic Models》。DDPM對之前的擴散模型進行了簡化和改進,更加注重對噪聲的預測而非直接生成圖像,并通過變分推斷(variational inference)來進行建模,這主要是因為擴散模型也是一個隱變量模型(latent variable model),相比VAE這樣的隱變量模型,擴散模型的隱變量是和原始數據是同維度的,而且擴散過程往往是固定的。
DDPM的優化目標是讓網絡預測的噪音和真實的噪音一致,其訓練過程如下圖所示:
- Training階段:隨機選擇一個訓練樣本 x 0 x_0 x0? -> 從 1 ? T 1-T 1?T隨機抽樣一個 t t t -> 隨機產生噪音并計算當前所產生的帶噪音數據 -> 輸入網絡預測噪音(紅色框所示) -> 計算產生的噪音和預測的噪音的L2損失 -> 計算梯度并更新網絡。
- Sampling階段:從一個隨機噪音開始,并用訓練好的網絡預測噪音,然后計算條件分布的均值(紅色框所示),然后用均值加標準差乘以一個隨機噪音,直至 t = 0 t=0 t=0完成新樣本的生成(最后一步不加噪音)。
PS:實際的Sampling代碼實現和上述過程略有區別(而是先基于預測的噪音生成,并進行了clip處理(范圍[-1, 1],原始數據歸一化到這個范圍),然后再計算均值(這應該算是一種約束,既然模型預測的是噪音,那么我們也希望用預測噪音重構處理的原始數據也應該滿足范圍要求)

擴散模型的核心在于訓練噪聲預測模型,由于噪聲和數據同維度,可以選擇采用AutorEncoder架構作為噪聲預測模型。DDPM所采用的是一個基于residual模塊和self-attention模塊的U-Net模型(encoder-decoder架構)。注意,DDPM在各個residual模塊中都引入了time embedding(類似于transformer中的position embedding)。
DDPM基于加噪和去噪的圖像生成過程可以用一張圖形象概括:

Sora關鍵技術拆解
Sora可以拆分為Visual encoder, Diffusion Transformer和Transformer Decoder三個部分,下面對其分別闡述:
Visual encoder
輸入的視頻數據可以看成是NxHxW的若干幀圖像, 通過Encoder被切分成spatial temporal patch,這些patch最終會被flatten成一維向量,送入diffusion model。其中,這里的patch的定義借鑒了Vision Transformer (ViT)中的patch,一些要點如下:
- 由于這里的每個樣本都是來自輸入圖像的一個patch,模型對樣本在序列中的位置一無所知。因此,圖像被連同positional embedding vector一起提供到encoder中。這里需要注意的一點是位置嵌入也是可學習的,所以實際上不需要將硬編碼的向量 w.r.t 位置。
- 將一維(壓平)的patches組成一個大矢量,并得到乘以一個embedding矩陣,這也是可學習的,創建embedding patches。將這些與位置向量相結合,輸入到transformer中。
對視頻進行采樣/處理的方法包括:
- 攤大餅法:幀圖像拼接成大圖,切成token,此后按ViT方式處理
- 切塊法:對多幀圖像切為若干個tuplet,每個tuplet包含時間、寬、高信息,經過spatial-tempral attention直接建模獲得有效的視頻表征token

Diffusion Transformer
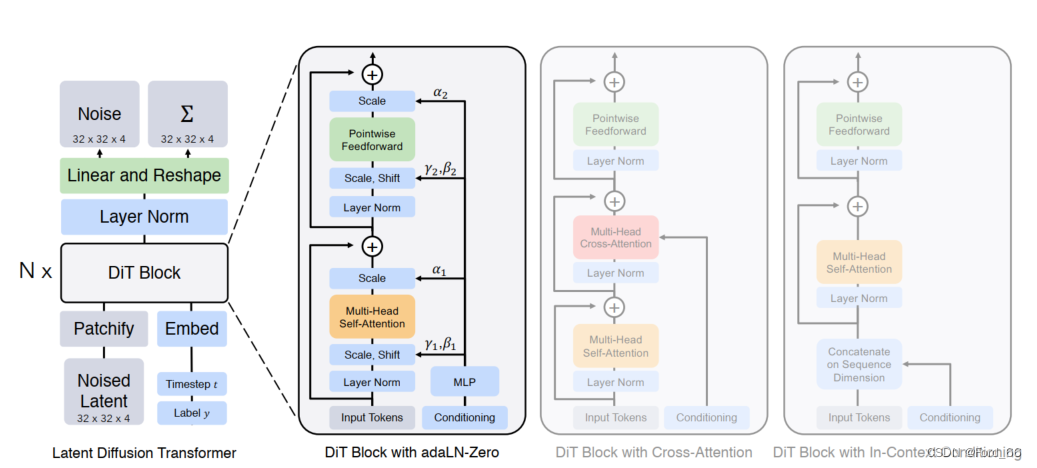
Sora的主要是Peebles William(直博3年半期間3篇一作論文,非常solid),他于2023年在ICCV上發表了Diffusion Transformer (DiT) 的工作,可以認為:DiT = VAE encoder + ViT + DDPM + VAE decoder,但把DPPM中的卷積U-Net架構換成了transformer。這篇工作是通過結合diffusion model和transformer,從而達到可以scale up model來提升圖像生成質量的效果。DiT文章在technical report的reference中給出,由于把圖像的scaling技術運用到視頻場景也非常直觀,因此可以確定是Sora的技術之一。
下圖展示了DiT的主要原理,輸入是一張256x256x3的圖片,對圖片做切patch后經過投影得到每個patch的token,得到32x32x4的latent(在推理時輸入直接是32x32x4的噪聲),結合當前的step t, 輸入label y作為輸入, 經過N個DiT Block通過mlp進行輸出,得到輸出的噪聲以及對應的協方差矩陣,經過T個step采樣,得到32x32x4的降噪后的latent。
思考與總結
- 截止到2024年3月2日,Sora還未完全開放使用,只有內測,現有的中文互聯網中所謂“帶你玩轉Sora”的AI付費課程都是純純割韭菜;
- Sora文生視頻模型可謂是之前許多模型的集大成者,雖然沒有公開太多技術細節,但我們可以學習到Sora背后所涉及的一系列模型架構和訓練方法(如Transformor, Diffusion模型等);
- 要訓練一個多模態大模型(LMM),海量訓練數據 + 優秀模型架構 + 算力資源都缺一不可,其中算力限制對中國公司發展人工智能提出了挑戰;
- 作為一家違背“不盈利,造福人類”初衷的微軟旗下閉源商業公司(doge),OpenAI是不會透露過多許多技術細節的,包括:如何構建Sora的具體模型、Transformer需要scale up到多大、從頭訓練到收斂的trick、如何實現訓練長達1分鐘視頻的支持(切斷+性能優化?)、如何保證視頻實體的高質量和一致性,這些我們都還不完全清楚,需要大量工程實踐去摸索。
參考文獻
[1] DataWhale開源課程《Sora原理與技術實戰》
[2] DataWhale成員優秀筆記分享:sora筆記(一):sora前世今生與技術梗概
[3] 怎么理解今年 CV 比較火的擴散模型(DDPM)? - 小小將的回答 - 知乎
https://www.zhihu.com/question/545764550/answer/2670611518
[4] Ho, J., et al. (2020). “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33: 6840-6851.
[5] Peebles, W. and S. Xie (2023). Scalable diffusion models with transformers. Proceedings of the IEEE/CVF International Conference on Computer Vision.


)










)


介紹)


