文章目錄
- 線程的理解
- 地址空間的轉換問題
- 總結
- 線程的優點
- 線程的缺點
- 線程的健壯性問題
本篇主要進行對于進程和線程的理解,以及對于線程的一部分使用方法和使用的原理
線程的理解
首先回顧前面一篇的內容中,對于進程的基本認識:
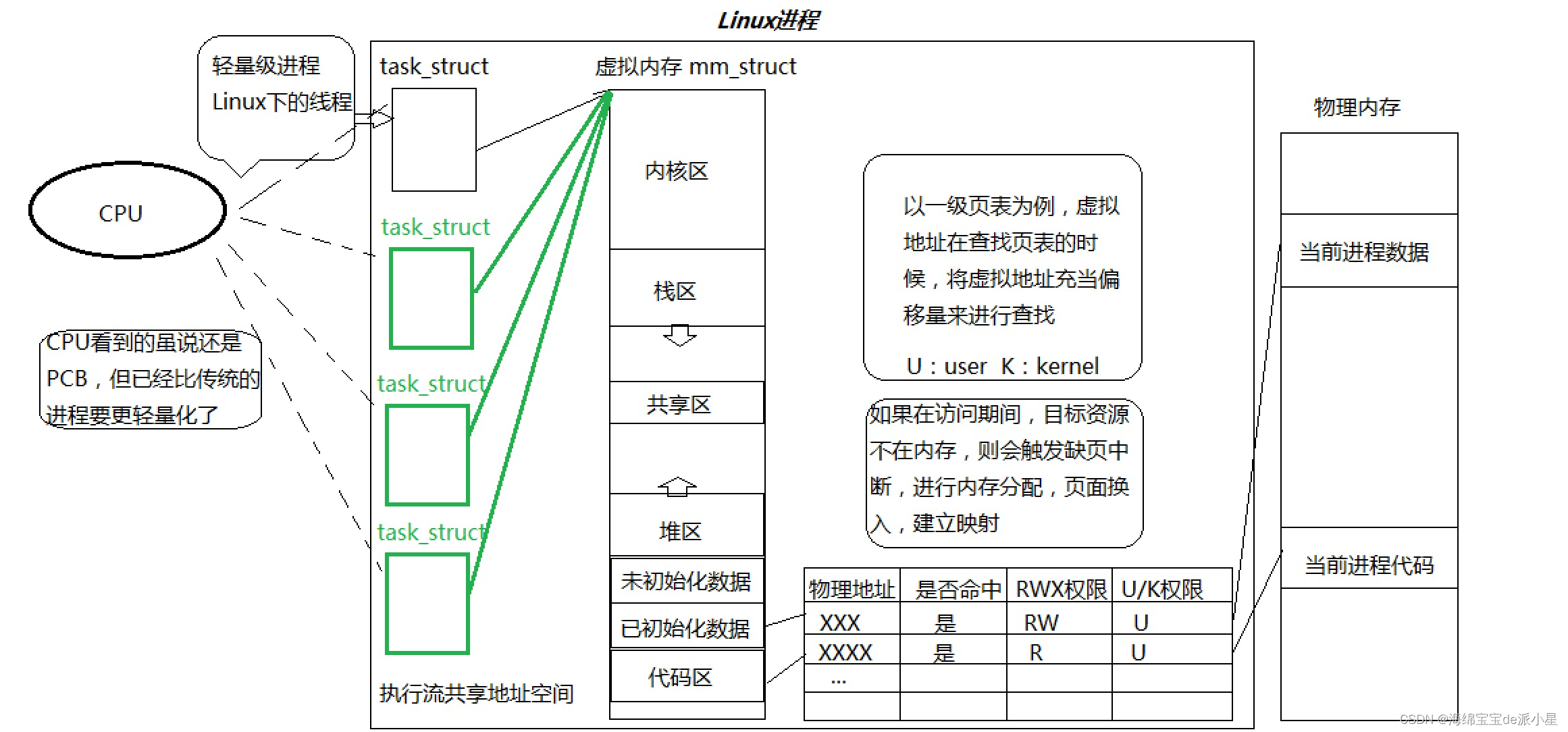
什么是線程,如何理解線程?線程是進程內部的一個執行分支,那么也就意味著肯定是先有進程,再有線程,這也是最基本的一個邏輯,那么在Linux系統中也確實是這樣,當一個代碼被編譯完成之后,如果想要執行這個進程,那么在進行啟動這個進程的時候,就會對這個進程建立起對應的地址,空間,頁表,代碼數據,內存區域的映射關系等等,這些就都是對于進程在創建之初就應該要儲備好的部分,后續在用特定的方案創建一個PCB的時候,其實只需要讓多個PCB去指向同樣的一部分內容,就可以實現在共享地址空間中做到讓多個不同的執行流去訪問同一塊進程內的代碼和數據,那么對于進程的代碼和數據資源進程合理的劃分,就能實現讓這些代碼之間的串行變成并發執行,那么這一個一個的分支就叫做線程,因此基于上述的這兩個點,可以得出下面的結論
- 線程在創建和釋放的時候可以比進程更加輕量化,只需要對于各種各樣的PCB進行管理即可
- 線程是進程內部的執行流,本質上線程是在進程的地址空間中進行運行的
- 對于進程的理解應該更加深一點:在之前的理解中,進程就是代碼和數據以及內核的數據結構,這個結論是沒有任何問題的,但是放在現在要多一個新的理解,進程是承擔分配系統資源的基本實體,具體是如何進行承擔的,簡單來說就是從各種的內核數據結構和表現上來體現的,就是要花內存占用對應的CPU資源,這樣就是體現出分配系統資源的基本實體
- 有了對于線程的理解,那么在之前對于進程的理解就應該更加廣泛一些,之前對于進程的理解是體現在了內部只有一個PCB結構,這樣的進程在現在看來是可以叫做是一個執行流的進程,現在對于進程就轉換成了一個進程內會包含有一大堆的申請的資源,并且還會有至少一個的PCB結構,而多線程其實就是內部有多個這樣的PCB結構,這就實現了一個單進程中有多線程
- Linux當中線程和進程都會被操作系統調度,那么現在的問題是,是否需要重新設計一個線程的結構呢?事實上從Linux的操作系統設計模式中可以看出并沒有這樣做,而是把之前對于進程的相關字段都重新復用了起來,也就是說Linux中的線程設計是完全用進程來進行模擬的,站在CPU的角度來說,當它拿到一個具體的PCB結構執行流的時候,它認為自己將來在CPU上跑的時候的執行的那個PCB,是要比傳統意義上理解的那個單個進程PCB是不一樣的,最起碼是小于等于單PCB的進程,所以自此之后,可以換一個角度去看Linux中的進程,可以把進程線程都看做事一個輕量級的進程,這個輕量級的進程指的就是單純這個PCB,而對應的整個地址,比如有地址空間頁表等等信息,這些全部加起來就叫做是真正意義上的進程,而并非是輕量級進程
地址空間的轉換問題
下面要談的一個問題是虛擬到物理地址轉換的問題,這個問題其實已經提過了,在最初對于進程的理解中就已經有了一個初步的描述,在前面的對于地址空間的轉換問題的理解只是停留在于,從虛擬地址到物理地址是要進行頁表的映射進行轉換,而這樣的理解其實并不是特別到位的,下面這個模塊將對于這個過程進行更加詳細的描述和理解
在之前對于文件系統的理解當中,提及過這樣的一個觀點,文件系統最終會指導操作系統和磁盤的設備進行io交互的時候,是以4kb為一個單位進行數據交互的,那么這個4kb也被叫做是一個文件塊,換句話說,站在操作系統的角度來講,它并不關心這個數據是啥,到底是圖片還是視頻還是音頻,它關心的是讀取這個文件的內容,要從外設搬到內存中,是要以一個數據塊為一個單位進行搬運的,那在進程間通信的時候,也提及過對于共享內存的創建大小,必須要以這個配置為單位
為了方便描述,畫出下面的最初步的示意圖
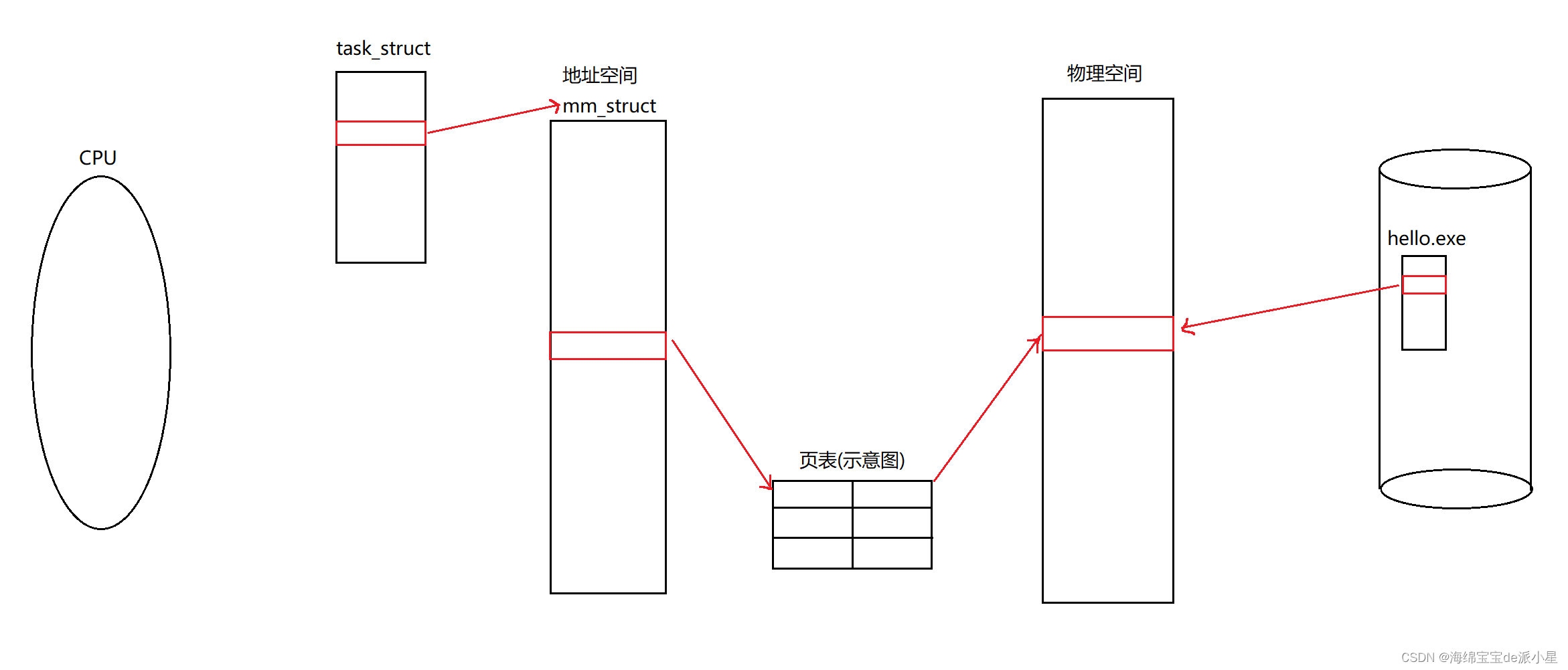
在上述的這個系統中,物理內存和磁盤進行io交互的時候,在硬件的層面上,可以通過某種方式把數據從磁盤弄到內存當中,而從純硬件的角度來講,這個過程就是把數據從一個設備拷貝到另外一個設備上,但是現在的一個問題是,把數據加載到內存的什么位置?加載多少?從哪里開始加載?這些問題都是需要解決的,甚至以至于還有比如說這個數據的訪問權限是多少,這個數據的屬性是什么,這些問題本質上來說就已經不屬于是硬件的范疇了,那這個問題的解決措施是由操作系統中的文件系統來解決的,文件系統把磁盤整體進行一個管理,那么此時文件系統就可以通過文件路徑來把對應的文件打開,再把對應的數據塊中的信息加載到物理內存中,從而實現了一個文件的加載和讀取的過程,而這個過程其實也是在之前的理解范圍之內的
這里要引出的一個結論就是,不管是什么數據,可能是這個文件的內容,也可能是這個文件的屬性,但只要是屬于這個文件的數據范圍內,它在進行加載的時候的基本單位就是4kb,這是由文件系統來進行設置的,也就是說在文件系統的層面上看這個新建的hello.exe這個可執行程序,本質上可以看成是由若干個小的4kb這樣的文件塊組成的,一般給這樣的數據段叫做是ELF數據段,那么最終的結論是,這里的每一個數據塊都是4kb為單位的,那么在最終的操作系統中,本質上也會這樣進行劃分,而這樣的每一個這樣的4kb大小的數據塊,在磁盤的角度看來就叫做是頁幀,而在物理空間中的這個4kb的一塊一塊的空間就被叫做是頁框,所以上面的圖可以修改為下面的模樣:
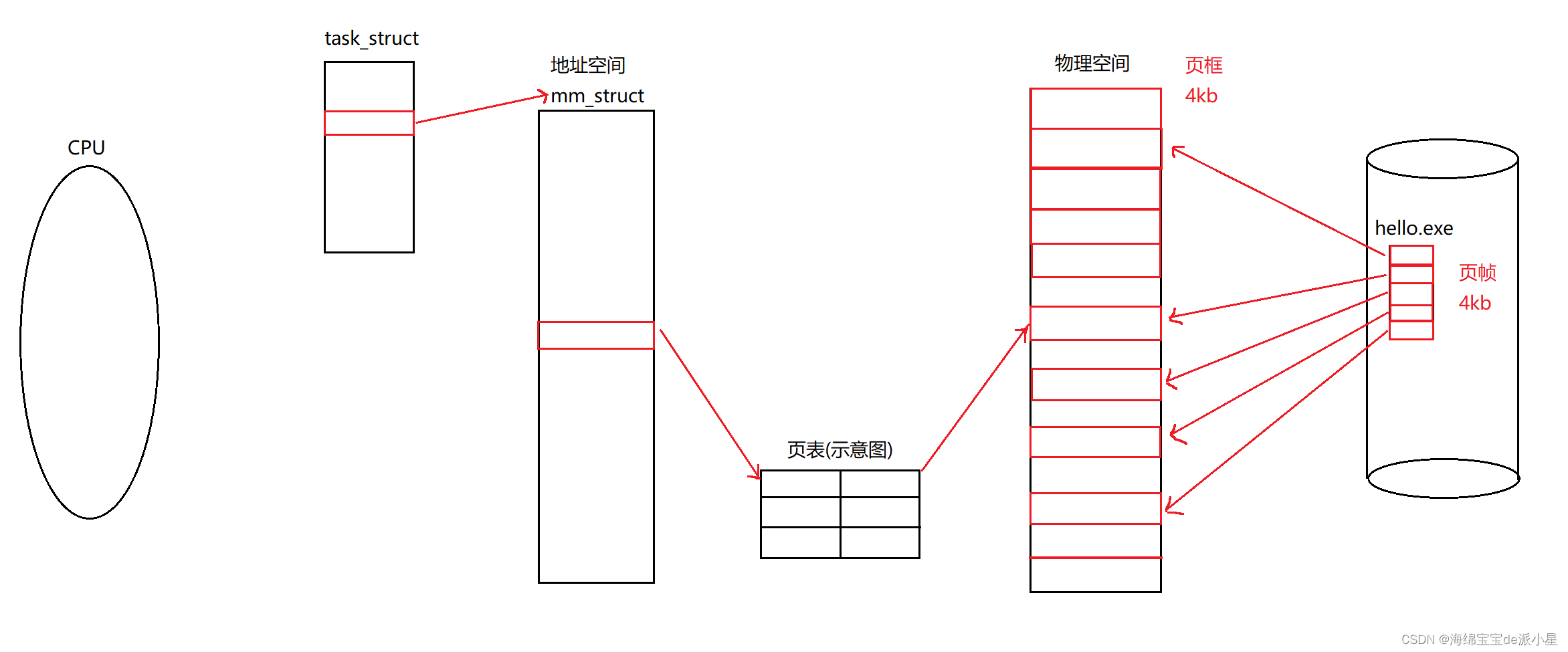
那么這樣就能得出一個樸素的結論是,未來這個文件當中哪怕只是需要修改一個比特位,也必須要把這個數據所在的這個4kb的數據塊全部弄出來加載到內存中,在內存中進行修改后,再刷新到磁盤上,這個就是基本單位的含義
下面的一個問題是,既然物理空間被劃分成了這樣,那么實際上計算一下:

在地址空間中按4kb的劃分,是需要有100多萬個頁框的,這是一個相當龐大的數據,那么下一個問題是,對于這個頁框的管理該如何進行管理呢?所以操作系統的內部會維護一個結構體對象,用來描述這個頁框的屬性,而在操作系統中就存在這樣一個數組,用來描述這個結構體,可以近似的理解為是struct page pages[1048576],而在這個結構體page中,里面存在了很多的字段,這些字段可能是意味著有物理內存是否被鎖定,也有這段內存是否被使用,當前內存是否準備釋放,每一種情況都用一個比特位來表示,所以在內存中對于物理內存的管理,就可以轉換成對于這個標記位的每一個比特位的管理
下一個問題是,頁表的大小問題,在虛擬地址中有2^32個地址,這些地址都要被頁表進行映射嗎?經過簡單的計算就可以很容易知道,這是不可能的,如果每一個地址都進行映射,那么頁表所占據的空間可能就已經是一個很大的概念了,所以得出的一個結論是,上面圖中的這個頁表其實是不完全準確的,真正的頁表結構還有其他的結構組成
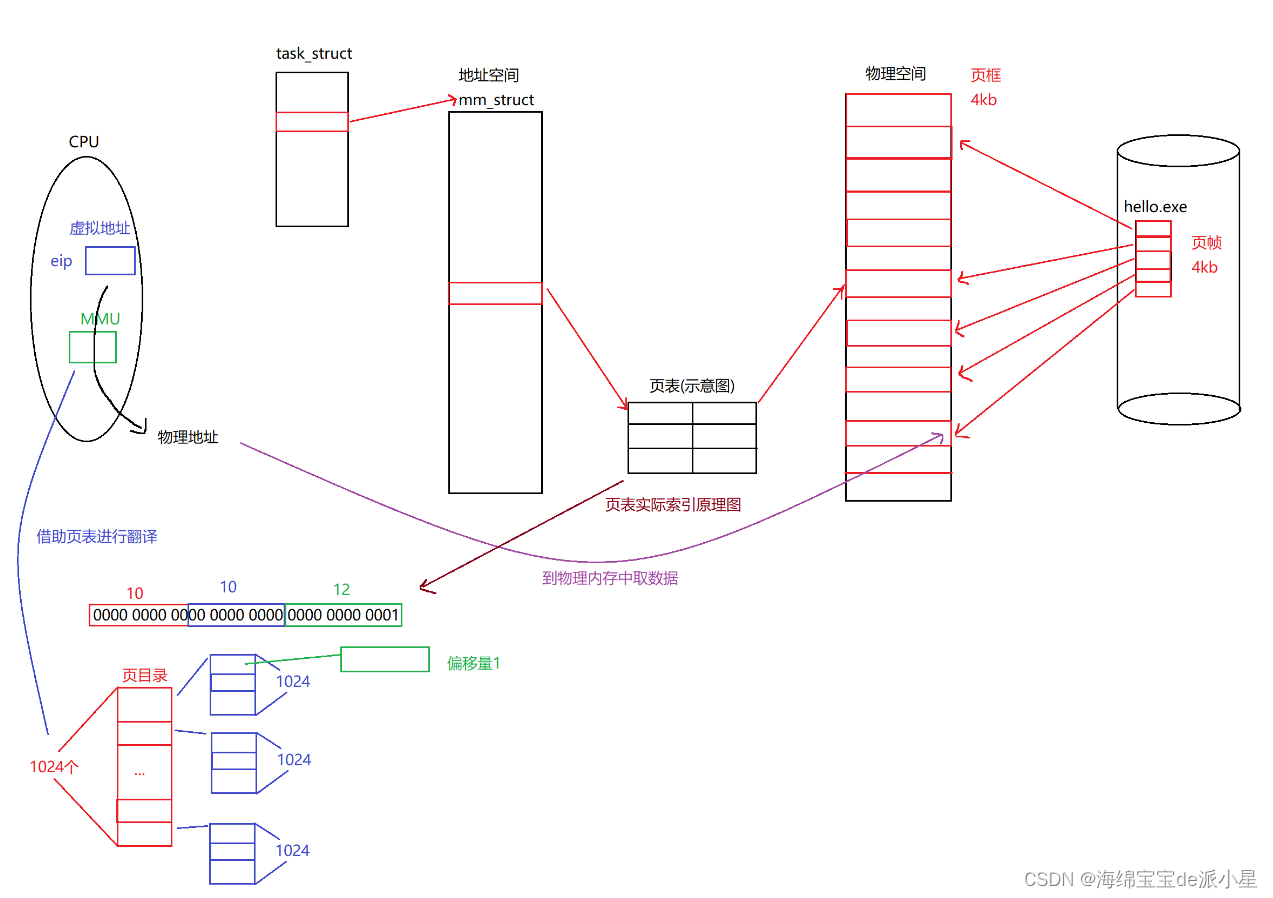
虛擬到物理地址到底是如何進行轉換的呢?在CPU中有很多的寄存器,其中一個寄存器叫做eip,那這個寄存器主要是存儲的是虛擬地址,而在CPU上還會有一個小組件叫做MMU,那這個組件其實就可以理解為可以完成從虛擬到物理地址的轉換工作,那這個轉換是如何進行轉換的?
以32位的機器為例,現在有一個地址,假設它是1111 1111 1001 0001 0000 0000 0010 1000,那么在實際的內存中其實并不會把這32個數字看成一個整體,而是會把前10個數字看出一個整體,中間10個數字看成一個整體,后面的12個數字看成一個整體,而實際上頁表也并非是一個大的頁表,而是會存在分級的情況,按32位的機器來看,會分成兩級,第一級叫做是頁目錄,頁目錄整體上來說是被用作查找的,但是頁目錄的查找只會使用前10個比特位,那頁目錄總共會有多少個呢?經過計算總共會有1024個組合方式,那么在之后進行查詢頁表的時候,就會先找到前10位對應的內容,再用中間的十位進行查找,那中間的這10位就被叫做是頁表項,也叫做是二級頁表,在實際進行查找的時候,可以把前10個轉換成一個二進制的數字,而這個數字就對應了這個數組的下標,而這個數組里面的內容指向的是下一級的頁表,從這個開始的地方就能搜索到下一級的頁表是誰,那么實際上,在這個一級頁表中其實存儲了的是一個映射關系,而這個第一部分的內容是不需要被存儲起來的,直接把前10個比特位當成是一個數組的下標用就可以了,實現了一個二進制的拆分機制
那為什么要這樣做,這樣做的好處在哪里?實際上頁表的存儲是物理內存的哪個位置,本身我們也不清楚,所以當前在進行頁表的構建的時候,從虛擬地址映射的這個過程中,如果沒有對應的這級頁表,在進行重新申請的時候就填到這個里面,最終凡是從這個地址開始的都會通過這個頁表來查,而這個頁表也可以當成是一個數組,而這個數組其中也有10個比特位,也就是1024,那么這個數字實際上也可以看出是一個數組的下標,里面存放的內容就是實際這個地址最終映射到所要申請的頁框的起始地址,因為物理內存的角度來講這個頁框的大小是以4kb進行io的,所以在實際進行尋找這個具體內容的時候,就要通過先找到這個內容屬于哪個頁框,再通過這個頁框找到內部的這個內容,那要找某一個數據或者是代碼,前提就是要找到虛擬地址所在的頁框,所以在這個頁表中存儲的就是物理內存的頁框,因此,本質上來說,對于頁表這個結構來說,整個頁目錄和頁表項當中真正有用的部分是幫助操作系統找到頁框,隨后再找到具體的對應的內容,而找到頁框之后,就可以根據最后的那12個比特位當成是一個偏移量,來找到與之對應的內容數據了,來用下面的這個圖描述一下更為清楚:
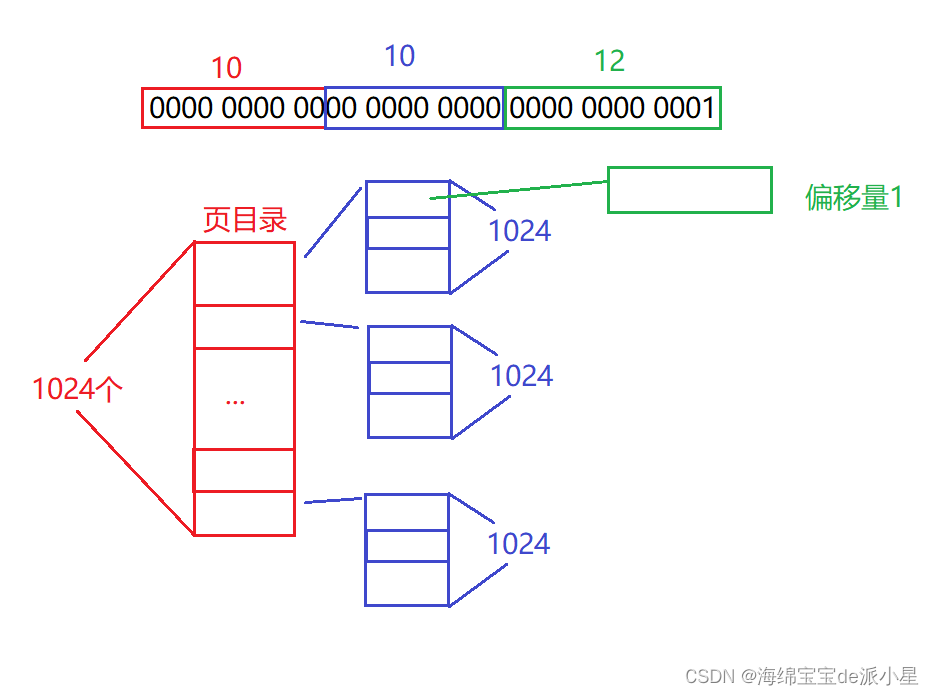
借助這樣的結構,就可以使得整個頁表的體積大大減小,但是更為重要的是,此時找到的就是物理內存中的頁框了,但是在平時進行訪問的時候其實并不關心頁框,關心的是頁框中的某一個數據,但是只需要借助最后的偏移量就可以找到了,只需要由前10個比特位找到頁目錄,然后再通過下標找到對應的頁表,再通過中間的10個比特位找到對應的頁表項,再通過頁表項的內容找到頁框,再通過最后的這個偏移量來找到所需要的數據內容
所以說,頁表中不存物理地址,但是會有頁框的物理地址,嚴格意義來說,它當中只有頁框的物理地址,通過第二級索引就能找到物理內存中頁框的物理地址,再根據偏移量就能直接定位到具體的地址了
完善一下剛才的圖:
總結
劃分頁表到底是什么呢?劃分頁表的本質是什么呢?本質上來說,就是在劃分地址空間,站在進程的角度來講,地址空間本身就是資源,所以劃分頁表就是在劃分資源
線程的優點
- 創建一個新線程的代價要比創建一個新進程小得多
- 與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多
- 線程占用的資源要比進程少很多
- 能充分利用多處理器的可并行數量
- 在等待慢速I/O操作結束的同時,程序可執行其他的計算任務
- 計算密集型應用,為了能在多處理器系統上運行,將計算分解到多個線程中實現
- I/O密集型應用,為了提高性能,將I/O操作重疊。線程可以同時等待不同的I/O操作
線程的缺點
- 性能損失
一個很少被外部事件阻塞的計算密集型線程往往無法與共它線程共享同一個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可用的資源不變 - 健壯性降低
編寫多線程需要更全面更深入的考慮,在一個多線程程序里,因時間分配上的細微偏差或者因共享了不該共享的變量而造成不良影響的可能性是很大的,換句話說線程之間是缺乏保護的 - 缺乏訪問控制
進程是訪問控制的基本粒度,在一個線程中調用某些OS函數會對整個進程造成影響 - 編程難度提高
編寫與調試一個多線程程序比單線程程序困難得多
線程的健壯性問題
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>// 新線程
void *ThreadRoutine(void *arg)
{const char *threadname = (const char *)arg;while (true){std::cout << "I am a new thread: " << threadname << ", pid: " << getpid() << std::endl;sleep(1);}
}int main()
{// 已經有進程了for (int i = 0; i < 5; i++){char threadname[64];snprintf(threadname, sizeof(threadname), "%s-%d", "thread", i);pthread_t tid;pthread_create(&tid, nullptr, ThreadRoutine, (void *)threadname);sleep(1);if (i == 4)int a = 10 / 0;}return 0;
}
運行結果如下:
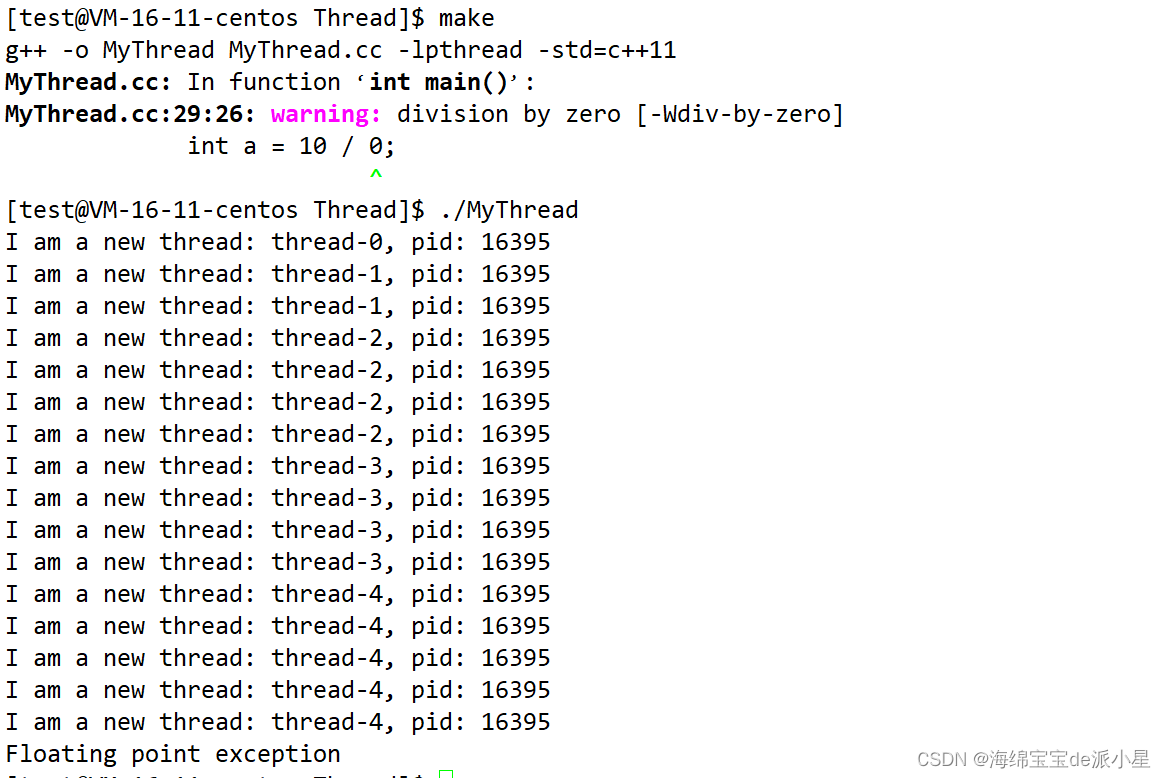
從中看出的一個問題是,當出現除0錯誤的時候,所有的線程都被終止了,這是因為所有的線程都共享信號的處理方式,所以當有一個線程收到信號后,其實所有的線程也就都被終止了


)





)










