Java虛擬機(JVM)是Java程序運行的核心組件,它負責解釋執行Java字節碼,并在各種平臺上執行。JVM的設計使得Java具有跨平臺性,開發人員只需編寫一次代碼,就可以在任何支持Java的系統上運行。我們剛開始學習Java時就下載了JDK(Java開發工具包),它提供了編譯、調試和運行Java應用程序所需的工具和庫。JDK包括了JRE(Java運行時環境),JRE包含了Java虛擬機(JVM)。由于不同的CPU的指令集可能不同,所以相同的代碼可能不能在不同的系統上都正常運行,而JVM就是為了解決這個問題,Java會先通過javac把? .java 文件編譯為 java字節碼(相當于Java自己的一套CPU指令)然后再由具體系統平臺上的的JVM(不同系統上的JVM可能存在差異),把上述字節碼轉化為對應的CPU能識別的機器指令。
1. JVM中的內存區域劃分?
?JVM其實也是一個進程(任務管理器中看到的java進程),Java程序的執行時申請的內存就是JVM從系統這邊申請到的內存,JVM會先申請一塊大的內存,這塊內存在給Java程序使用時,又會根據實際的用圖劃分出不同的區域,每個區域都有不同的作用。
-
Java堆(Java Heap): Java堆是Java虛擬機管理的最大一塊內存區域,用于存放對象實例,數組,類的成員變量。Java堆是所有線程共享的內存區域,是垃圾回收的重點區域。
-
Java虛擬機棧(Java Virtual Machine Stacks): Java虛擬機棧也稱為棧內存,用于存儲線程的方法調用、局部變量、部分結果等。每個方法在被調用時都會創建一個棧幀,并入棧;方法執行完畢后棧幀出棧。棧幀包括局部變量表、操作數棧、動態鏈接、方法返回地址等。
-
本地方法棧(Native Method Stack): 本地方法棧類似于Java虛擬機棧,但是它為Native方法服務,即JVM內部使用C、C++等編寫的本地方法。
-
程序計數器(Program Counter Register): 程序計數器是一塊較小的內存區域,用于記錄當前線程下一條執行的字節碼指令地址。在多線程環境下,每個線程都有獨立的程序計數器。
-
元數據區(Metaspace)/ 方法區(Method Area):元數據指的是一些輔助性質的描述性質的屬性,元數據區主要用于存儲類的元數據信息,例如類的結構、方法信息、字段信息等。一個程序有哪些類,每個類中有哪些方法,每個方法里要包含哪些指令,都會記錄在元數據區中,即元數據區儲存了Java代碼編譯后的Java字節碼
?注意:一個JVM進程中,堆和元數據區只有一個,棧和程序計數器可能有多份(每個線程都有一個自己的程序計數器和棧,即每個線程都有自己的執行流)。
public class Test{private int n;//堆區private static int m;//static修飾的變量為類屬性儲存在元數據區public static void main(String[] args) {Test t = new Test();//t為局部變量儲存在棧區,類的實例儲存在堆區}
}2.JVM的類加載機制?
2.1 類加載過程?
JVM的類加載機制是指JVM在運行時將類的字節碼加載到內存中并進行驗證、準備、解析和初始化的過程。JVM的類加載機制主要包括以下幾個步驟:
-
加載(Loading):查找并加載類的字節碼文件。這個過程可以通過類加載器來完成,類加載器會根據類的全限定名在文件系統、網絡或其他地方找到對應的字節碼文件,并將其讀入內存。
-
驗證(Verification):確保被加載的類的字節碼是合法、符合JVM規范的。包括文件格式驗證、元數據驗證、字節碼驗證、符號引用驗證等步驟。具體驗證依據,在Java虛擬機規范中有明確的格式說明

-
準備(Preparation):為類的靜態變量分配內存并設置默認初始值,這些變量所使用的內存都將在方法區中進行分配。
-
解析(Resolution):將類中的符號引用轉換為直接引用,這個過程可以在運行時進行也可以在編譯時進行。
class Test{String s = "hello"; }上面代碼編譯后"hello"會儲存在常量池中,s中相當于保存了“hello"的字符串常量的地址,但是代碼沒有運行時,s和"hello"都在字節碼文件中,文件中沒有地址這樣的概念,所以在代碼運行前s中存儲的是一個類似于”偏移量"的概念記錄了“hello”的相對位置,就是這里的符號引用。
-
初始化(Initialization):對類進行初始化,包括執行類構造器<clinit>()方法,靜態變量賦值等操作。在初始化階段,JVM會根據程序中對類的主動使用情況來觸發初始化,例如創建類的實例、訪問類的靜態成員、調用類的靜態方法等。
2.2 雙親委派模型
在類加載過程中,JVM采用了雙親委派模型,即由多個不同層次的類加載器組成一個層次結構,每個類加載器都有自己的責任范圍,當一個類需要加載時,先由最頂層的類加載器嘗試加載,如果無法加載再交由下一層的類加載器,依次類推,直到最底層的類加載器。
JVM中進行類加載是由一個專門的模塊“類加載器(ClassLoader)”完成的,類加載器的作用是通過“全限定類名”(帶有包名的類名,例如java.land.String,可以類比為文件路徑中的絕對路徑)查找?.class文件,把 .class文件的數據轉化為運行時需要的類對象并加載到JVM中。
JVM中默認提供了三種類加載器,分別是:
-
啟動類加載器(Bootstrap ClassLoader):負責加載Java的核心類庫,如java.lang包下的類。它是JVM自身的一部分,通常由C++編寫,并不繼承自java.lang.ClassLoader類。
-
擴展類加載器(Extension ClassLoader):負責加載Java的擴展類庫,位于jre/lib/ext目錄下的類庫。
-
應用程序類加載器(Application ClassLoader):也稱為系統類加載器,負責加載當前項目的代碼目錄,以及第三方庫的目錄。
除了這三個默認的類加載器,開發者也可以自定義類加載器來實現特定的類加載需求,比如從網絡中動態加載類、加密類加載等。自定義類加載器需要繼承自java.lang.ClassLoader類,并重寫其中的findClass()方法來實現類的加載邏輯。?
注意:這三個類加載器之間存在父子關系,上面的為父加載器,下面的為子加載器,即1是2的父親,2是3的父親。
雙親委派流程:當一個類加載器收到類加載請求時,它首先將這個請求委托給它的父類加載器處理。如果父類加載器無法完成此加載請求,子加載器才會嘗試自己去加載。這個過程會一直遞歸下去直到啟動類加載器。這樣做的目的是保證Java核心API的穩定性,防止用戶自定義的類替換掉核心類庫中的類。
1. 從Application ClassLoader作為入口
2.?Application ClassLoader不會立刻搜索自己負責的目錄,會把任務交給父類加載器Extension ClassLoader。
3.?Extension ClassLoader也不會立刻搜索自己負責的目錄,也會把任務交給父類加載器Bootstrap ClassLoader。
4.Bootstrap ClassLoader沒有父類加載器,就會搜索自己負責的目錄查找需要的 .class文件,如果找到了就直接進入打開文件/讀文件等流程中,如果沒找到,則把任務交給下一級類加載器Extension ClassLoader繼續嘗試尋找。
5.Extension ClassLoader 接受到任務此時就會在自己負責的目錄中開始尋找,如果找到了就直接進入打開文件/讀文件等流程中,如果沒找到,則同樣把任務交給下一級類加載器Application ClassLoader繼續嘗試尋找。
6.Application ClassLoader 也會在自己負責的目錄中開始尋找,如果找到了就直接進入打開文件/讀文件等流程中,如果沒找到,也會嘗試把任務交給下一級,但是默認情況下Application ClassLoader沒有下一級類加載器了,于是就會類加載失敗拋出ClassNotFoundException異常
上述流程就保證了類加載的順序,防止用戶自定義的類替換掉核心類庫中的類。例如用戶自己定義了一個java.lang.String如果這個類先被加載了,java核心庫中的String類就不會被加載。
3. 垃圾回收機制(GC)?
垃圾回收(GC)是自動內存管理的關鍵技術之一。它負責清理不再使用的對象,釋放內存空間。垃圾回收,回收的是堆的內存 ,所以也可以說是回收對象。
3.1 識別垃圾?
判定對象后續是否會繼續使用,不會繼續使用的就會被視為垃圾,如果一個對象沒有任何引用指向它,那么這個對象就無法被繼續使用了,也就會被視為垃圾。
3.1.1 引用計數
引用計數方法并沒有在JVM中使用,但是廣泛運用在其他主流語言的垃圾回收機制中,如Python,PHP。
引用計數是通過給每個對象安排一個額外的空間,記錄當前有幾個引用指向該對象。每有一個引用指向該對象時,就把值加一,反之則減一,當這個值為0時則視為垃圾,當負責垃圾回收的掃描線程獲取到這個對象的引用計數情況時,發現為0就會釋放這個對象的空間。
引用計數存在兩個關鍵的問題:
- 問題一:要給每個對象安排計數器,就會消耗額外的空間,如果對象數量很多,總的空間浪費也就很多。
- 問題二:可能產生循環引用問題,例如兩個對象互相引用,但沒有一個外部的引用指向它們,此時這兩個對象是無法被獲取到的,但他們的引用計數又不為0,也就不會被釋放。
3.1.2 可達性分析?
JVM采用的就是可達性分析來識別對象是否是垃圾。
可達性分析采用的方法是 遍歷所有變量,JVM會遍歷所有能夠被直接或者間接訪問到的對象,能訪問到的自然不是垃圾,遍歷一圈后不能訪問到的就視為垃圾。
3.2 釋放垃圾?
找到垃圾以后就需要把垃圾對象所占的內存空間進行釋放。
3.2.1 標記-清除算法
把標記為垃圾的對象直接釋放。這種釋放方式會導致內存碎片問題。
如圖所示,釋放后,會導致出現很多大大小小的內存碎片,而內存申請都是一次申請一段連續的內存空間,這就導致了部分內存碎片可能無法使用到,也就導致了空間浪費。
3.2.2 復制算法
將內存分為兩個相等的部分,每次只使用其中一半。當這一半的內存用完后,就將還在使用的對象復制到另一半,然后再清除掉已經使用過的那一半內存中的所有對象。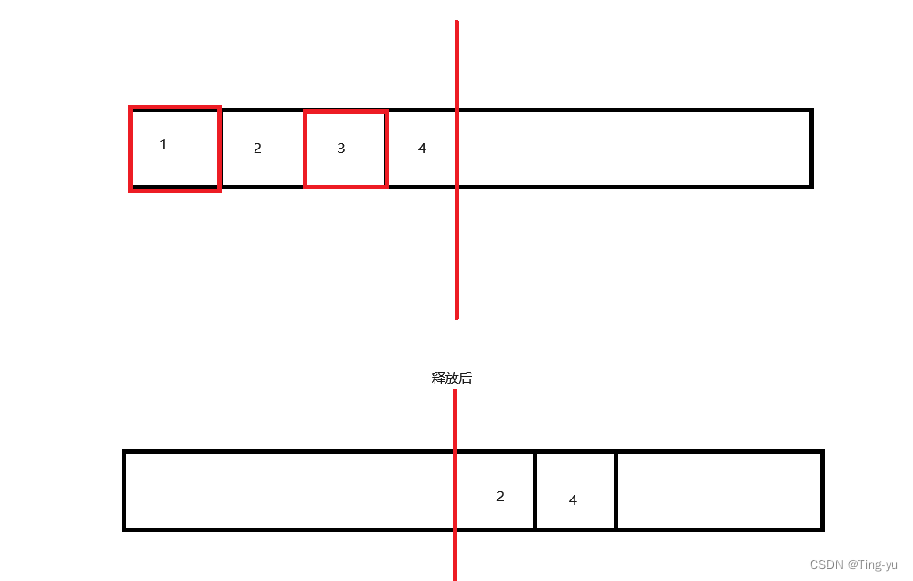
這種方法避免了內存碎片,但是總的可用空間變少了,同時復制對象也會消耗時間。
3.2.3 標記-整理算法
將所有存活的對象向一端移動,然后直接清理掉端邊界以外的內存。
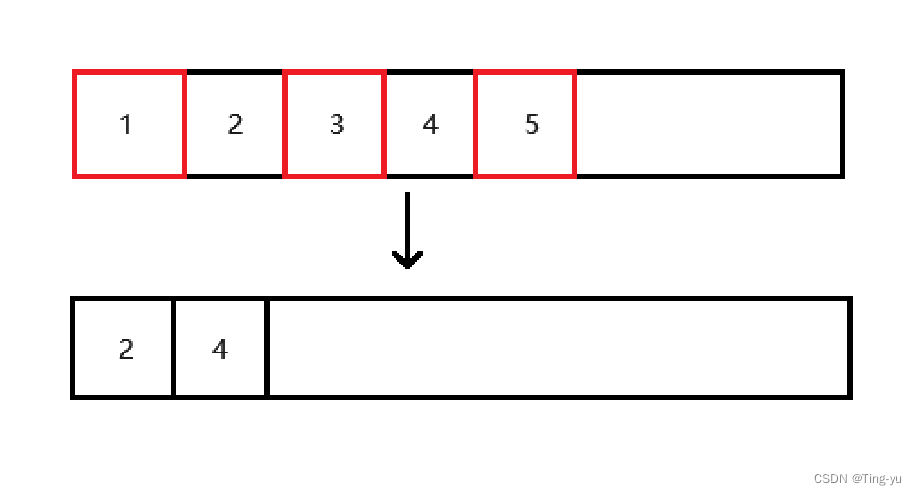 ?這樣也可以避免內存碎片問題,但是移動對象也要消耗時間。
?這樣也可以避免內存碎片問題,但是移動對象也要消耗時間。
3.2.4 分代回收算法
JVM中采用的是分代回收算法。給每個對象引入年齡的概念,JVM中存在專門的線程負責周期性的掃描/釋放對象,如果一個對象被線程掃描了一次,并且不是垃圾,該對象的年齡就會+1(初始年齡為0)。
JVM中會根據對象年齡的差異,把整個內存分成兩個大的部分,新生代(年齡較小的對象)/ 老年代(年齡較大的對象),新生代又被劃分為三個區域,其中大的一部分區域為 伊甸區 ,剩下兩塊大小相同的區域叫做? 生存區? 或者? 幸存區 。
?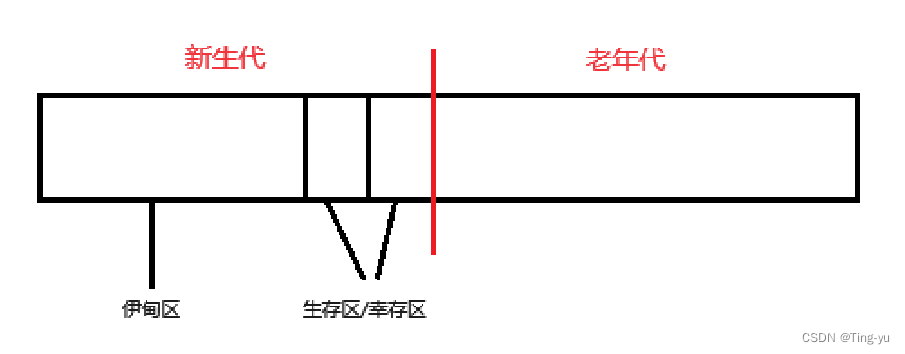
?新的對象都是從伊甸區中被創建的,第一輪GC掃描后,沒有被清除的對象就會被通過復制算法移動到生存區(即生存區相當于未被使用的那塊內存),生存區中的對象下次被GC掃描后,存活的對象又會被通過復制算法移動到另一個生存區(注意兩個生存區完全是對等的),每經歷一次GC,對象的年齡就會+1,如果某個對象在生存區中經過了若干輪GC任然沒有被清除,JVM就會認為這個對象的生命周期很長,就會把這個對象移動到老年代,老年代的對象也會被GC掃描,只不過掃描的頻率較低。老年代的對象被視為垃圾時會按照標記-整理算法釋放內存。






select子查詢)




--連續因子)







