【🐋和鯨冬令營】通過數據打造爆款社交APP用戶行為分析報告
文章目錄
- 【🐋和鯨冬令營】通過數據打造爆款社交APP用戶行為分析報告
- 1 業務背景
- 2 數據說明
- 3 數據探索性分析
- 4 用戶行為分析
- 4.1 用戶屬性與行為關系分析
- 4.2 轉化行為在不同用戶屬性群體中的分布情況
- 5 深入分析
- 5.1 多維度行為分析
- 5.2 行為預測模型
- 6 總體策略建議
時間緊張,其他的任務重,本次活動沒有像上次一樣花心思,馬上畢業了時間并不充裕,所以就沒有太認真寫,見諒!
完整編譯可運行的項目我掛載到了我的和鯨主頁:北天
歡迎大家前去fork,點贊,評論,收藏,非常感謝!!!
1 業務背景
近些年來,隨著移動互聯網和大數據的快速發展,人們花費了很多時間在各式各樣的社區、論壇、購物網站和社交軟件上,同時企業也積累了海量的用戶數據,而每一次的瀏覽、點擊都代表著特定的用戶行為,如果能夠以科學的方式對這些海量的用戶行為進行統計、分析和挖掘,那么我們將會更加了解自己的用戶:如他們的地理位置、文化背景、消費水平、行為偏好、生命周期等,同時也有助于我們制定更佳的產品或營銷策略,提升用戶體驗,從而實現精細化運營,打造爆款社交APP。
假設你是一名移動互聯網行業的數據分析師,目前想要找到影響產品轉化率的核心因素,在產品/運營側輸出關鍵策略,幫助公司提升核心指標,從而體現數據分析的價值所在;那么你會從哪些角度出發呢?
2 數據說明
- 本數據集是某社交App一定時間內相關用戶行為的分類示例數據;
- A、B、C、D、E、F代表了六個不同的屬性或功能參數;
- 每一行數據代表了一組有相同屬性的用戶;
- Action1、Action_2是具有某種歸類的用戶數;
- Action_1到Action_2記錄的是由用戶數變化所代表的轉化率;
- 數據中個人信息部分已脫敏;
3 數據探索性分析
我們首先加載并初步探索提供的數據集。
import pandas as pddata_path = '2023冬令營實戰數據集.csv'
data = pd.read_csv(data_path)
data.info(), data.head()
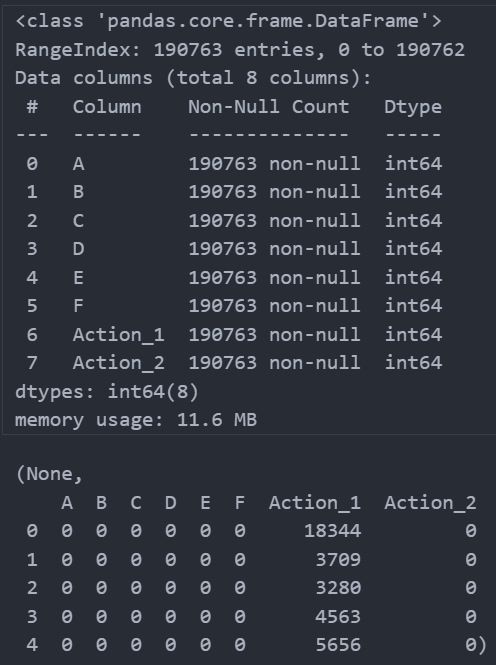
數據集包含190,763條記錄和8個字段,字段名為"A"到"F",以及"Action_1"和"Action_2",所有字段都是整數類型。
接下來我們將進行一些基本的數據探索性分析。
# 描述性統計分析
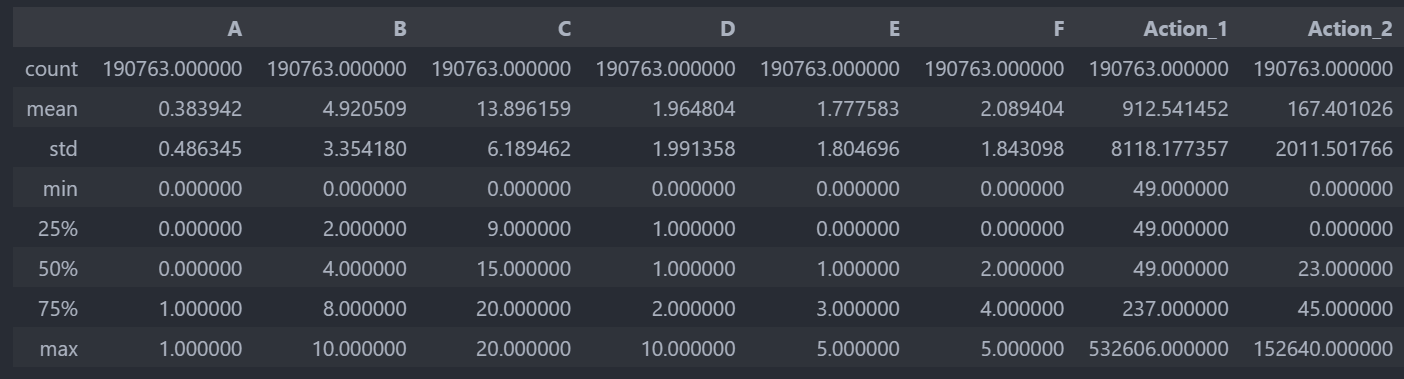
descriptive_stats = data.describe()
# 檢查缺失值
missing_values = data.isnull().sum()
missing_values
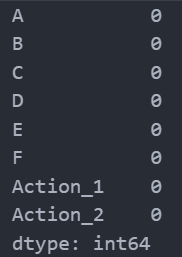
數據集中的每個字段都沒有缺失值,以下是各字段的描述性統計摘要:
- A到F:這些字段的最小值、25%、50%(中位數)、75%和最大值顯示了數據的分布范圍,例如字段"A"的值在0和1之間,可能表示某種二元特征(如性別或是否完成某項操作),字段"B"到"F"的范圍和分布各不相同,表明它們代表不同的用戶屬性或行為特征。
- Action_1和Action_2:表示用戶行為的計數,其值范圍和標準差相當大,特別是"Action_1"的最大值達到532,606,"Action_2"的最大值為152,640,表明數據中可能存在極端值或異常值。
由于數據集中沒有發現缺失值,這簡化了數據清洗的步驟。
下面我們進行異常值探索,給定"Action_1"和"Action_2"字段的極端最大值,下一步我們可以通過可視化方法進一步探索這些可能的異常值。我們將繪制這兩個字段的箱線圖,以直觀地查看數據分布和識別潛在的異常值。
import matplotlib.pyplot as plt
import seaborn as sns# 設置繪圖風格
sns.set(style="whitegrid")# 繪制Action_1和Action_2的箱線圖
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.boxplot(y=data['Action_1'])
plt.title('Action_1 Boxplot')plt.subplot(1, 2, 2)
sns.boxplot(y=data['Action_2'])
plt.title('Action_2 Boxplot')
plt.show()
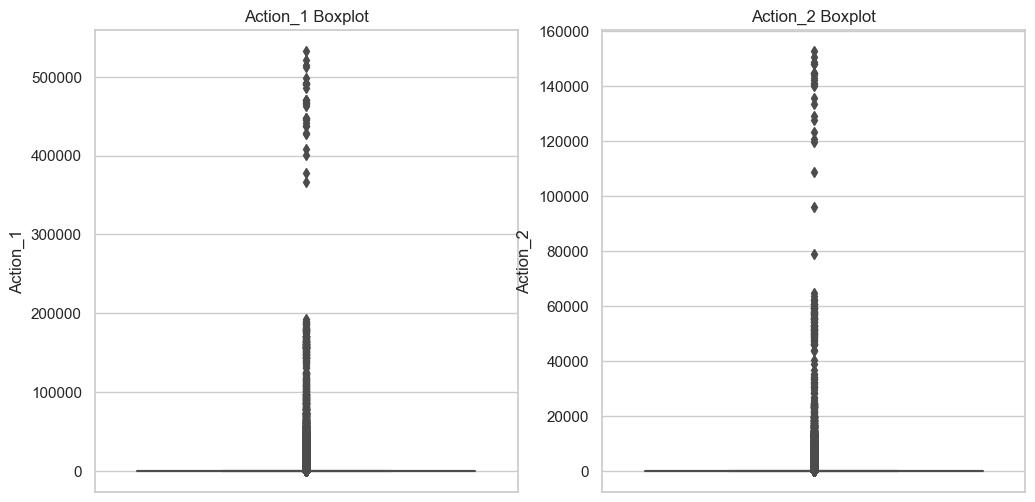
箱線圖展示了"Action_1"和"Action_2"字段中潛在的異常值,從圖中可以看出:
- Action_1和Action_2字段都有大量的異常值,這些值遠遠高于Q3(第三四分位數)加上1.5倍的IQR(四分位距)計算得出的上界。
- 這些異常值可能代表某些用戶的行為極其活躍或者是數據收集、記錄過程中的特殊情況。
4 用戶行為分析
接下來我們將從用戶行為分析的角度入手,特別是關注影響產品轉化率的核心因素,首先我們需要定義什么是“轉化率”在這個上下文中的意義,考慮到數據集的特點,我們可以假設"Action_1"和"Action_2"代表了用戶的某種轉化行為,例如購買、點擊廣告等。
因此我們的分析可以從以下幾個角度展開:
- 用戶屬性(A到F)與行為(Action_1和Action_2)的關系:探索這些屬性如何影響用戶的轉化行為。
- 轉化行為的分布:分析轉化行為(Action_1和Action_2)在不同用戶群體中的分布情況。
4.1 用戶屬性與行為關系分析
為了探索用戶屬性(A到F)與轉化行為(Action_1和Action_2)之間的關系,我們可以進行如下分析:
- 相關性分析:計算用戶屬性與轉化行為之間的相關系數,以識別哪些屬性與轉化行為更為相關。
- 群組分析:對用戶屬性進行分組(例如,根據屬性"A"是否為1),比較不同組內的轉化行為差異。
我們先從相關性分析開始,計算用戶屬性(A到F)與轉化行為(Action_1和Action_2)之間的相關系數,這將幫助我們了解哪些用戶屬性與轉化行為更密切相關。
# 計算相關系數
correlation_matrix = data.corr()
# 展示相關系數矩陣
correlation_matrix[['Action_1', 'Action_2']]
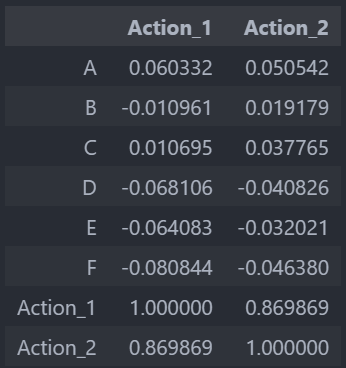
上述結果展現的揭示了用戶屬性(A到F)與轉化行為(Action_1和Action_2)之間的相關性如下:
- Action_1與Action_2之間有很高的相關性(約0.87),這表明這兩種行為可能是相互關聯的,或者在很多情況下同時發生。
- 屬性A與Action_1和Action_2呈正相關(分別約0.06和0.05),盡管相關性不是很強,但這表明屬性A的某些值可能與更高的轉化行為相關聯。
- 其他屬性(B到F)與轉化行為的相關性較弱,且部分屬性與轉化行為呈負相關,特別是F與Action_1和Action_2的相關性最低(分別約-0.08和-0.05)。
這些發現提示我們,屬性A可能在分析用戶轉化行為時值得特別關注,而屬性F的負相關性可能表明隨著F的增加,用戶的轉化行為可能會減少。
接下來,為了更深入地理解這些屬性如何影響轉化行為,我們將進行群組分析,比較不同用戶屬性群體的轉化行為差異,我們將從屬性A開始,因為它與轉化行為的相關性最強,我們將比較屬性A為1和為0的用戶群體的轉化行為(Action_1和Action_2)的平均值差異。
# 按屬性A分組,計算每組的Action_1和Action_2的平均值
grouped_by_A = data.groupby('A')[['Action_1', 'Action_2']].mean()
grouped_by_A
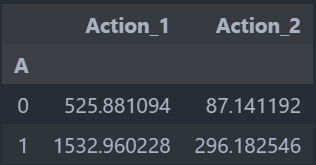
對于屬性A,我們比較了當其值為1和為0時,用戶的轉化行為(Action_1和Action_2)的平均值:
- 當A=1時,Action_1的平均值為1,532.96,Action_2的平均值為296.18。
- 當A=0時,Action_1的平均值為525.88,Action_2的平均值為87.14。
這個結果表明,屬性A為1的用戶群體的轉化行為(無論是Action_1還是Action_2)的平均值明顯高于屬性A為0的用戶群體,這進一步證實了屬性A可能是影響用戶轉化行為的一個重要因素。
基于這個發現,我們可以假設改善或增強與屬性A相關的產品特性或用戶體驗,可能會提高用戶的轉化率。
4.2 轉化行為在不同用戶屬性群體中的分布情況
下一步我們將通過可視化方法進一步探索轉化行為(Action_1和Action_2)在不同用戶屬性群體中的分布情況,我們將選擇一個代表性的屬性進行分析,考慮到屬性A的重要性,我們將圍繞它進行展開,我們計劃繪制屬性A不同值對應的Action_1和Action_2的分布情況。
# 繪制屬性A對Action_1和Action_2分布的影響
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.boxplot(x='A', y='Action_1', data=data)
plt.title('Action_1 Distribution by Attribute A')
plt.subplot(1, 2, 2)
sns.boxplot(x='A', y='Action_2', data=data)
plt.title('Action_2 Distribution by Attribute A')
plt.tight_layout()
plt.show()
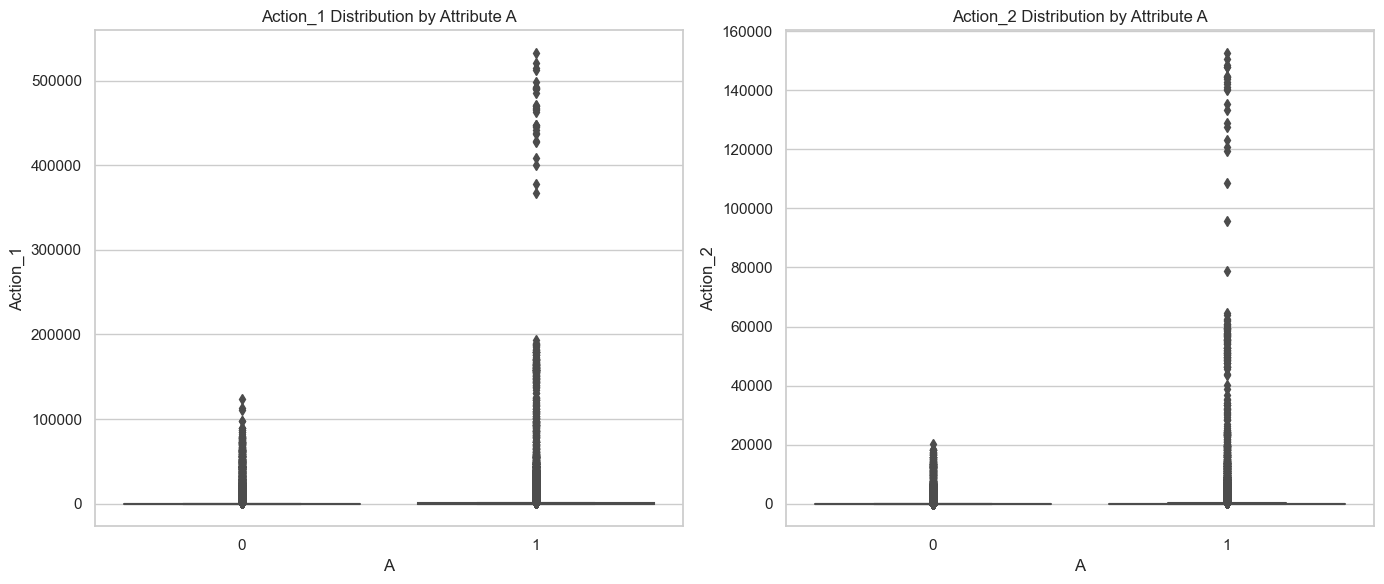
通過箱線圖可視化屬性A對Action_1和Action_2分布的影響,我們可以觀察到以下幾點:
- Action_1和Action_2的分布:無論是Action_1還是Action_2,屬性A為1的用戶群體的中位數和四分位數范圍都高于屬性A為0的用戶群體,這與我們之前的分析結果一致,即屬性A為1的用戶更傾向于有更高的轉化行為。
- 異常值:兩種行為的分布都有大量的異常值,尤其是在屬性A為1的群體中,這可能表明存在一些極端活躍的用戶。
這些觀察結果支持了我們之前的發現,即屬性A顯著影響用戶的轉化行為,這提示我們提高與屬性A相關的用戶滿意度或參與度可能是提高轉化率的關鍵。
策略建議
- 增強與屬性A相關的特性或服務:鑒于屬性A對轉化行為的顯著影響,應優先改進與之相關的產品特性或用戶體驗,以提升該用戶群的參與度和滿意度。
- 針對性營銷活動:可以針對屬性A為1的用戶群體設計專門的營銷活動或優惠,以進一步提高他們的轉化率。
- 關注高活躍用戶:對于異常活躍的用戶群體,進行深入分析了解他們的特性和需求,可能發現提升用戶活躍度和轉化率的新機會。
這些策略建議旨在通過深入理解和滿足用戶需求,優化產品和營銷策略,最終提升用戶轉化率。
5 深入分析
5.1 多維度行為分析
基于前面的分析,我們已經確認了屬性A對用戶轉化行為的重要性,接下來我們可以進一步深入分析探索,除了單一屬性的影響,用戶的轉化行為可能受到多個因素的共同作用,我們可以利用多變量分析方法,如邏輯回歸或決策樹,來識別哪些屬性組合對轉化行為影響最大。
我們將使用邏輯回歸模型,分析多個屬性如何共同影響用戶的某一轉化行為(例如,選擇Action_1作為響應變量),這將幫助我們識別對轉化行為影響最大的屬性組合。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix# 由于Action_1的值范圍很大,我們將其轉換為二元變量,以便于使用邏輯回歸分析
# 定義轉化行為的閾值,這里假設高于中位數的行為視為正樣本(1),否則為負樣本(0)
threshold = data['Action_1'].median()
data['Action_1_binary'] = (data['Action_1'] > threshold).astype(int)# 準備特征變量和目標變量
X = data[['A', 'B', 'C', 'D', 'E', 'F']] # 特征變量
y = data['Action_1_binary'] # 目標變量# 分割數據集為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 構建邏輯回歸模型
log_reg_model = LogisticRegression(max_iter=1000)# 訓練模型
log_reg_model.fit(X_train, y_train)# 模型評估
y_pred = log_reg_model.predict(X_test)
report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report, conf_matrix
(' precision recall f1-score support\n\n 0 0.63 0.61 0.62 29134\n 1 0.61 0.64 0.62 28095\n\n accuracy 0.62 57229\n macro avg 0.62 0.62 0.62 57229\nweighted avg 0.62 0.62 0.62 57229\n',array([[17648, 11486],[10162, 17933]], dtype=int64))
我們使用邏輯回歸模型分析了多個用戶屬性(A到F)如何共同影響用戶的轉化行為(這里以Action_1的二元變化為例),模型的評估結果如下:
- 準確率(Accuracy):模型在測試集上的準確率為62%,這意味著模型能夠以一定的準確度預測用戶的轉化行為。
- 精確度(Precision)**和**召回率(Recall):對于正樣本(即轉化行為較高的用戶)和負樣本(即轉化行為較低的用戶),模型的精確度和召回率均在60%到64%之間。
混淆矩陣顯示了模型預測結果與實際情況的對比:
- 真正(TP):17,933,即模型正確預測為正樣本的數量。
- 假正(FP):11,486,即模型錯誤預測為正樣本的數量。
- 真負(TN):17,648,即模型正確預測為負樣本的數量。
- 假負(FN):10,162,即模型錯誤預測為負樣本的數量。
邏輯回歸模型的結果表明,用戶屬性對其轉化行為有一定的預測能力,盡管模型的整體性能表現良好,但仍有改進的空間,這可能意味著用戶的轉化行為受到多種因素的影響,而這些因素可能沒有全部包含在當前分析中。
對于邏輯回歸模型,我們可以可視化各個特征的系數(權重),以展示它們對預測結果的影響程度。這有助于我們理解哪些用戶屬性對其轉化行為的預測貢獻最大。
# 邏輯回歸模型的特征系數可視化
features = X.columns
coefficients = log_reg_model.coef_[0]# 創建系數的DataFrame
coeff_df = pd.DataFrame({'Feature': features, 'Coefficient': coefficients})# 繪制系數的條形圖
plt.figure(figsize=(10, 6))
sns.barplot(x='Coefficient', y='Feature', data=coeff_df.sort_values(by='Coefficient', ascending=False))
plt.title('Logistic Regression Coefficients')
plt.xlabel('Coefficient Value')
plt.ylabel('Feature')
plt.tight_layout()
plt.show()
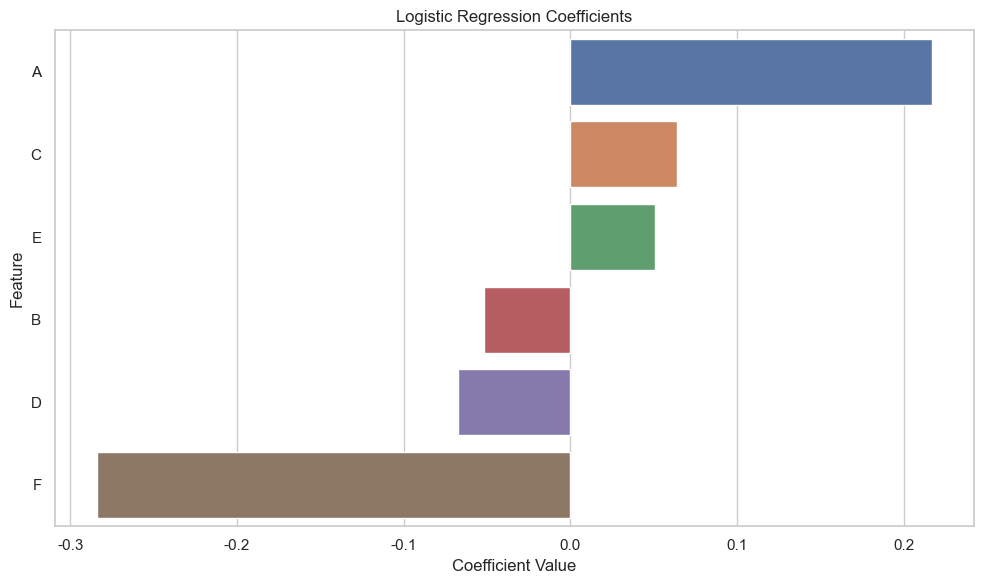
從邏輯回歸模型的系數可視化中,我們可以看到各個特征對預測用戶轉化行為(即Action_1_binary)的貢獻程度,正系數表示特征與正樣本(較高的轉化行為)正相關,負系數則表示負相關。
結論
- 某些特征對用戶的轉化行為有顯著影響,這些特征的優化可能會直接提升用戶的轉化率。
- 特征間的影響程度不同,指出了不同用戶屬性在影響用戶行為上的相對重要性。
策略建議
- 重點優化:針對影響力較大的特征,進行產品或服務的優化,以提高用戶的轉化率。
- 用戶分析:深入分析對轉化行為有正面影響的特征背后的用戶行為和偏好,定制化營銷策略。
5.2 行為預測模型
利用已有的用戶屬性和行為數據,我們可以嘗試構建一個預測模型,預測用戶的轉化行為,這樣的模型不僅可以幫助我們更準確地識別潛在的高價值用戶,還可以為制定個性化的營銷策略提供支持。
為了進一步探索用戶行為的預測模型,我們將使用機器學習的方法來預測用戶的轉化行為,考慮到數據集的特性和之前的分析結果,我們可以嘗試構建一個分類模型,預測用戶是否會表現出較高的轉化行為(即Action_1_binary為1)。
這里我們將使用隨機森林分類器進行行為預測模型的構建,隨機森林是一種集成學習方法,它通過構建多個決策樹來提高預測的準確性和穩定性,相較于邏輯回歸模型,隨機森林能夠更好地處理非線性關系和特征間的交互效應,因此可能在這個任務上表現更優。
from sklearn.ensemble import RandomForestClassifier# 構建隨機森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)# 訓練模型
rf_model.fit(X_train, y_train)# 模型評估
y_pred_rf = rf_model.predict(X_test)
report_rf = classification_report(y_test, y_pred_rf)
conf_matrix_rf = confusion_matrix(y_test, y_pred_rf)report_rf, conf_matrix_rf
(' precision recall f1-score support\n\n 0 0.81 0.64 0.72 29134\n 1 0.69 0.84 0.76 28095\n\n accuracy 0.74 57229\n macro avg 0.75 0.74 0.74 57229\nweighted avg 0.75 0.74 0.74 57229\n',array([[18694, 10440],[ 4436, 23659]]))
隨機森林模型在測試集上的評估結果如下:
- 準確率(Accuracy):模型的準確率提高到了74%,這表明模型能夠較準確地預測用戶是否會表現出較高的轉化行為。
- 精確度(Precision)**和**召回率(Recall):對于正樣本(即
Action_1_binary為1的情況),模型的召回率達到了84%,精確度為69%;對于負樣本,精確度為81%,召回率為64%。
混淆矩陣顯示了模型預測結果與實際情況的對比:
- 真正(TP):23,659,即模型正確預測為正樣本的數量。
- 假正(FP):10,440,即模型錯誤預測為正樣本的數量。
- 真負(TN):18,694,即模型正確預測為負樣本的數量。
- 假負(FN):4,436,即模型錯誤預測為負樣本的數量。
隨機森林模型的性能明顯優于之前的邏輯回歸模型,特別是在召回率方面的表現,這表明隨機森林模型更適合處理這種類型的分類問題,尤其是在預測用戶的轉化行為時。
對于隨機森林模型,我們將可視化特征的重要性得分,這將幫助我們識別在預測用戶轉化行為時哪些特征最為關鍵。
# 隨機森林模型的特征重要性可視化
feature_importances = rf_model.feature_importances_# 創建特征重要性的DataFrame
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})# 繪制特征重要性的條形圖
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df.sort_values(by='Importance', ascending=False))
plt.title('Random Forest Feature Importances')
plt.xlabel('Importance Score')
plt.ylabel('Feature')
plt.tight_layout()
plt.show()
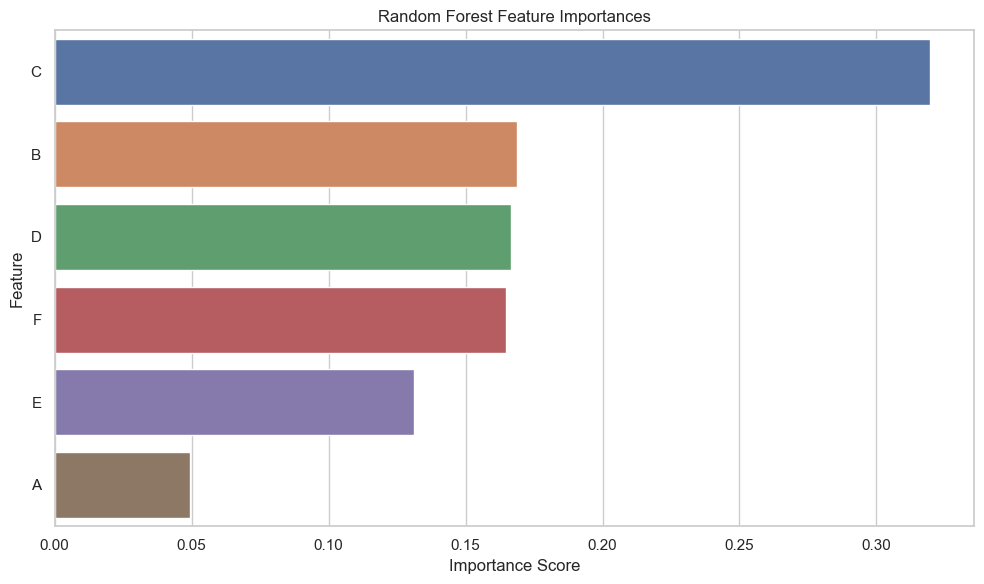
隨機森林模型的特征重要性可視化展示了各個特征在預測用戶轉化行為時的重要性得分,較高的重要性得分表示該特征在預測用戶是否會表現出較高轉化行為時更為關鍵。
結論
- 特征重要性得分揭示了不同用戶屬性對預測用戶轉化行為的貢獻度,指導我們理解哪些屬性更能影響用戶的轉化概率。
- 與邏輯回歸模型結果相比,隨機森林提供了一個更細致的特征重要性視角,有助于我們更全面地理解影響用戶轉化行為的因素。
策略建議
- 聚焦關鍵屬性:針對特征重要性高的用戶屬性,開展針對性的改進措施,例如優化用戶體驗、提升服務質量、調整產品功能等,以增加用戶的轉化概率。
- 數據驅動決策:利用特征重要性的洞察,制定基于數據的決策,例如在營銷活動中優先針對可能轉化率高的用戶群體。
- 持續監測和優化:隨著市場和用戶行為的變化,定期重新評估特征的重要性,并據此調整策略。
6 總體策略建議
根據上述分析結果,我們為公司提出以下總體策略建議:
- 優化關鍵用戶屬性:針對影響用戶轉化行為的關鍵屬性,如屬性A,公司應優化相關的產品特性或用戶體驗,這可能包括改進用戶界面、增強產品功能或提供更個性化的服務。
- 實施多維度用戶分析:繼續利用多變量分析和機器學習模型來深入理解不同用戶屬性和行為之間的復雜關系,這將幫助公司更準確地識別目標用戶群體,制定更有效的營銷策略。
- 構建和優化預測模型:利用隨機森林等先進的機器學習技術構建和持續優化用戶行為預測模型。這些模型可以幫助公司更有效地識別高潛力用戶,實施針對性的營銷活動,提高轉化率。
- 個性化營銷策略:基于用戶行為預測模型的結果,制定個性化的營銷策略和推廣活動,通過精準定位用戶偏好和需求,提供定制化的內容和優惠,以提高用戶參與度和忠誠度。
- 動態調整和優化:市場環境和用戶行為是不斷變化的,公司需要建立起動態監測和分析機制,定期評估和調整產品策略、營銷活動和用戶體驗設計,確保持續滿足用戶需求,提升用戶滿意度和轉化率。
通過實施這些策略,公司可以更有效地利用用戶數據來指導產品開發和營銷決策,最終實現業務增長和市場競爭力的提升。
)


)








-數據庫與身份認證)






