Cora_dataset description
Cora數據集是一個常用的學術文獻用網絡數據集,用于研究學術文獻分類和圖網絡分析等任務。
該數據集由機器學習領域的博士論文摘要組成,共計2708篇論文,涵蓋了7個不同的學科領域。每篇論文都有一個唯一的ID,并且被分為以下7個類別之一:Case_Based、Genetic_Algorithms、Neural_Networks、Probabilistic_Methods、Reinforcement_Learning、Rule_Learning和Theory。
除了論文之間的引用關系外,Cora數據集還包含了每篇論文的詞袋表示,即將每篇論文表示為一個詞頻向量(0-1嵌入,每行有多個1,非one-hot vector,feature of node)。這些詞頻向量表示了論文中出現的單詞及其在該論文中的出現頻率。
Cora數據集常用于圖神經網絡的研究和評估,可以用于學術文獻分類、引文網絡分析、節點嵌入等任務。
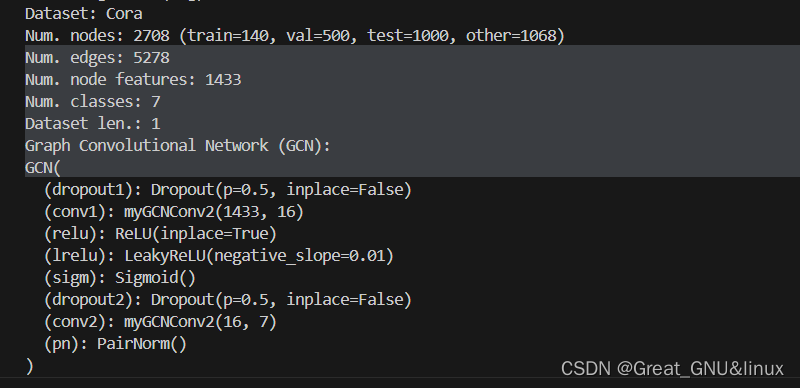
print cora
dataset = Planetoid("./tmp/Cora", name="Cora", transform=T.NormalizeFeatures())
num_nodes = dataset.data.num_nodes
# For num. edges see:
# - https://github.com/pyg-team/pytorch_geometric/issues/343
# - https://github.com/pyg-team/pytorch_geometric/issues/852num_edges = dataset.data.num_edges // 2
train_len = dataset[0].train_mask.sum()
val_len = dataset[0].val_mask.sum()
test_len = dataset[0].test_mask.sum()
other_len = num_nodes - train_len - val_len - test_len
print(f"Dataset: {dataset.name}")
print(f"Num. nodes: {num_nodes} (train={train_len}, val={val_len}, test={test_len}, other={other_len})")
print(f"Num. edges: {num_edges}")
print(f"Num. node features: {dataset.num_node_features}")
print(f"Num. classes: {dataset.num_classes}")
print(f"Dataset len.: {dataset.len()}")
GCN原理與實現
卷積公式: f ? g = F ? 1 ( F ( f ) ? F ( g ) ) f*g=F^{-1}(F(f)·F(g)) f?g=F?1(F(f)?F(g))
給定一個圖信號x和一個卷積核, x ? g = U ( U T x ⊙ U T g ) = U ( U T x ⊙ g θ ) = D ~ ? 0.5 A ~ D ~ ? 0.5 X Θ x*g=U(U^Tx\odot U^Tg)=U(U^Tx\odot g_{\theta})=\widetilde D^{-0.5}\widetilde A\widetilde D^{-0.5}X\Theta x?g=U(UTx⊙UTg)=U(UTx⊙gθ?)=D ?0.5A D ?0.5XΘ
其中A為圖的鄰接矩陣,D為圖的度數矩陣,
D ~ = D + γ I , A ~ = A + γ I \widetilde D=D+\gamma I,\widetilde A=A+\gamma I D =D+γI,A =A+γI,添加自環以縮小 λ \lambda λ(Laplace matrix)
1.computation of D ~ ? 0.5 A ~ D ~ ? 0.5 \widetilde D^{-0.5}\widetilde A\widetilde D^{-0.5} D ?0.5A D ?0.5
def gcn_norm(edge_index, edge_weight=None, num_nodes=None,
add_self_loops=True, flow="source_to_target", dtype=None):
fill_value = 1.
num_nodes = maybe_num_nodes(edge_index, num_nodes)
if add_self_loops: #添加自環
edge_index, edge_weight = add_remaining_self_loops(
edge_index, edge_weight, fill_value, num_nodes)
edge_weight = torch.ones((edge_index.size(1), ), dtype=dtype,
device=edge_index.device)
row, col = edge_index[0], edge_index[1]
idx = col
deg = scatter(edge_weight, idx, dim=0, dim_size=num_nodes, reduce='sum')
deg_inv_sqrt = deg.pow_(-0.5)
deg_inv_sqrt.masked_fill_(deg_inv_sqrt == float('inf'), 0)
edge_weight = deg_inv_sqrt[row] * edge_weight * deg_inv_sqrt[col]
return edge_index, edge_weight
代碼解釋
edge_index, edge_weight = add_remaining_self_loops(edge_index, edge_weight,fill_value, num_nodes):
D ~ = D + γ I , A ~ = A + γ I \widetilde D=D+\gamma I,\widetilde A=A+\gamma I D =D+γI,A =A+γI;
deg = scatter(edge_weight, idx, dim=0, dim_size=num_nodes, reduce='sum'):
根據edge_weight和idx=edge_index[1]得到度數矩陣,deg=D
- explantation:edge_weight是要放入的對角陣,
deg_inv_sqrt = deg.pow_(-0.5):require D ? 0.5 D^{-0.5} D?0.5
deg_inv_sqrt.masked_fill_(deg_inv_sqrt == float('inf'), 0):
由于D非對角元=0,其-0.5次冪=∞,需要轉化為0,
edge_weight = deg_inv_sqrt[row] * edge_weight * deg_inv_sqrt[col]:
輸出歸一化后的edge_index
2. PairNorm

3.GCNConv的實現如下(刪改自torch_geometric.nn.GCNConv)
class myGCNConv2(MessagePassing):def __init__(self, in_channels: int, out_channels: int,add_self_loops: bool = True,bias: bool = True):super().__init__()self.in_channels = in_channelsself.out_channels = out_channelsself.add_self_loops = add_self_loopsself.lin = Linear(in_channels, out_channels, bias=False,weight_initializer='glorot')if bias:self.bias = Parameter(torch.Tensor(out_channels))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self):super().reset_parameters()self.lin.reset_parameters() #卷積層zeros(self.bias) #偏置層def forward(self, x: Tensor, edge_index: Adj,edge_weight: OptTensor = None) -> Tensor:edge_index, edge_weight = gcn_norm( # yapf: disableedge_index, edge_weight, x.size(self.node_dim),self.add_self_loops, self.flow, x.dtype)x = self.lin(x)# propagate_type: (x: Tensor, edge_weight: OptTensor)out = self.propagate(edge_index, x=x, edge_weight=edge_weight,size=None)if self.bias is not None:out = out + self.biasreturn outdef message(self, x_j: Tensor, edge_weight: OptTensor) -> Tensor:return x_j if edge_weight is None else edge_weight.view(-1, 1) * x_jdef message_and_aggregate(self, adj_t: SparseTensor, x: Tensor) -> Tensor:return spmm(adj_t, x, reduce=self.aggr)
代碼解釋
x = self.lin(x): X ′ = X Θ , X ∈ R n ? d 1 , Θ ∈ R d 1 ? d 2 X'=X\Theta,X\in R^{n*d1},\Theta \in R^{d1*d2} X′=XΘ,X∈Rn?d1,Θ∈Rd1?d2,對X降維
out = self.propagate(edge_index, x=x, edge_weight=edge_weight,size=None):
out= A ′ X ′ = D ~ ? 1 2 A ~ D ~ ? 1 2 X Θ A'X'=\widetilde D^{-\frac 1 2}\widetilde A \widetilde D^{-\frac 1 2 } X \Theta A′X′=D ?21?A D ?21?XΘ
Converge {x1’,…,xn’} ,each of which be a sampled vector,into target form.
message&message_and_aggregate為MessagePassing.propagate的相關函數,
經測試,刪除后,val acc下降,故予以保留
4.Net(GCN)的實現
class GCN(torch.nn.Module):
def __init__(
self,
num_node_features: int,
num_classes: int,
hidden_dim: int = 16,
dropout_rate: float = 0.5,
) -> None:
super().__init__()
self.dropout1 = torch.nn.Dropout(dropout_rate)
self.conv1 = myGCNConv2(num_node_features,
hidden_dim,add_self_loops=True)
self.relu = torch.nn.ReLU(inplace=True)
self.dropout2 = torch.nn.Dropout(dropout_rate)
self.conv2 = myGCNConv2(hidden_dim, num_classes,add_self_loops=True)
self.pn=PairNorm()
def forward(self, x: Tensor, edge_index: Tensor) -> torch.Tensor:
x = self.pn(x)
x = self.dropout1(x)
x = self.conv1(x, edge_index)
x = self.relu(x)
x = self.dropout2(x)
x = self.conv2(x, edge_index)
return x
代碼解釋
x = self.pn(x):對x作PairNorm處理,之后xi~N(0,s2),各節點特征范數大小平衡,作用不明顯;
采用2層GCN卷積層,中間用relu激活,dropout避免過擬合
DropEdge Realization的手動實現
- idea
- 首先把有向圖的邊,轉化為無向圖的邊,保存在single_edge_index中,實現時先用single_edge字
典存儲每條無向邊(key-value 任意)1次,再把single_edge轉化成無向圖的邊集索引(2-dim tensor
array)
#single_edge_index
single_edge={}
for i in range(len(dataset.data.edge_index[0])):if(((dataset.data.edge_index[0][i],dataset.data.edge_index[1][i]) not in single_edge.items()) and ((dataset.data.edge_index[1][i],dataset.data.edge_index[0][i]) not in single_edge.items())):single_edge[dataset.data.edge_index[0][i]]=dataset.data.edge_index[1][i]single_edge_index=[[],[]]for key,value in single_edge.items():single_edge_index[0].append(key)single_edge_index[1].append(value) single_edge_index=torch.tensor(single_edge_index)
- 再把無向邊集舍去dropout_rate比例的部分,之后轉成有向邊集索引
def drop_edge(single_edge_index, dropout_rate):# 計算需要丟棄的邊數num_edges = single_edge_index.shape[1]num_drop = int(num_edges * dropout_rate)# 隨機選擇要丟棄的邊remain_indices = torch.randperm(num_edges)[num_drop:]remain_single_edges = single_edge_index[:, remain_indices]reverse_edges = torch.stack([remain_single_edges[1],remain_single_edges[0]],dim=0)remain_edges=torch.cat([remain_single_edges,reverse_edges],dim=1)return remain_edges





)


)






)

![[vue error] TypeError: AutoImportis not a function](http://pic.xiahunao.cn/[vue error] TypeError: AutoImportis not a function)
)
)