文章目錄
- 前言
- 一、Ack機制
- 二、ISR集合
- 總結
前言
本篇主要介紹kafka 的 Ack機制 和 ISR集合
一、Ack機制
Kafka提供了三種不同的應答機制(ACK):
acks=0:這是最不可靠的模式。在這種模式下,生產者不會等待來自服務器的確認,這意味著消息可能會在發送之后丟失,而生產者將無法知道它是否成功到達服務器。
acks=1:這是默認模式,也是一種折衷方式。在這種模式下,生產者會在消息發送后等待來自分區領導者的確認,但不會等待所有副本的確認。這意味著只要消息被寫入分區領導者,生產者就會收到確認。如果分區領導者成功寫入消息,但在同步到所有副本之前宕機,消息可能會丟失。
acks=all:這是最可靠的模式。在這種模式下,生產者會在消息發送后等待所有副本的確認。只有在所有副本都成功寫入消息后,生產者才會收到確認。這確保了消息的可靠性,但會導致更長的延遲。
二、ISR集合
ISR(in-sync replica) 就是 Kafka 為某個分區維護的一組同步集合,即每個分區都有自己的一個 ISR 集合,處于 ISR 集合中的副本,意味著 follower 副本與 leader 副本保持同步狀態,只有處于 ISR 集合中的副本才有資格被選舉為 leader。一條 Kafka 消息,只有被 ISR 中的副本都接收到,才被視為“已同步”狀態。這跟 zk 的同步機制不一樣,zk 只需要超過半數節點寫入,就可被視為已寫入成功。
如果一個follower因為某種故障遲遲無法與leader 同步,那么如果選擇 ack 為 all 的話,leader 要一直等待follower 同步完才發 ack 嗎
顯然不是,in-sync replica set (ISR),意為和leader保持同步的follower集合。當ISR中的follower完成數據的同步之后,leader就會給producer發送ack。如果follower長時間未向leader同步數據,則該follower將被踢出ISR,該時間閾值由replica.lag.time.max.ms參數設定。Leader發生故障之后,就會從ISR中選舉新的leader。
被踢出 ISR 的 follower 在選舉新的 leader 時不被考慮,待該follower恢復后,follower會讀取本地磁盤記錄的上次的HW,并將log文件高于HW的部分截取掉,從HW開始向leader進行同步。等該follower的LEO大于等于該Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
同樣的 leader 故障的話,會從ISR中選出一個新的leader,之后,為保證多個副本之間的數據一致性,其余的follower會先將各自的log文件高于HW的部分截掉,然后從新的leader同步數據。
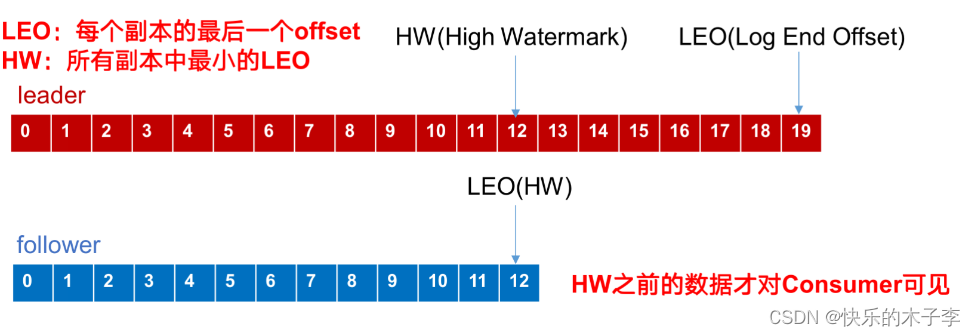
LEO:指的是每個副本最大的offset;
HW:指的是消費者能見到的最大的offset,ISR隊列中最小的LEO。
總結
千里之行,始于足下!


)






)

![[vue error] TypeError: AutoImportis not a function](http://pic.xiahunao.cn/[vue error] TypeError: AutoImportis not a function)
)
)

 img大圖預覽)



![[python隊列廣搜]請佩戴好口罩](http://pic.xiahunao.cn/[python隊列廣搜]請佩戴好口罩)