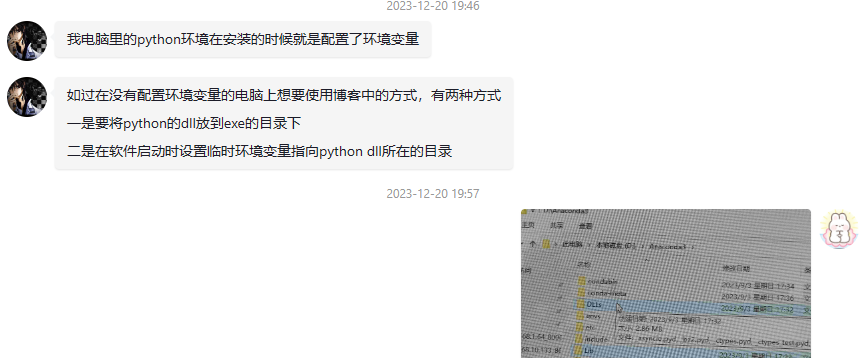
一、前言
之前一陣子一直在做的就是怎么把yolo項目部署成c++項目,因為項目需要嵌套進yolo模型跑算法。因為自己也是本科生小白一枚,基本上對這方面沒有涉獵過,自己一個人從網上到處搜尋資料,寫代碼,調試,期間遇到的bug不能說多,只能說很多!!!
最開始的思路一直都是,有沒有什么辦法能夠直接用C++代碼直接調用整個yolo項目,也就是如何用C++調用python項目。
這期間真的,碰壁不少,先是安裝opencv環境,能顯示圖像了,然后就是調用python。網上的教程很少或者說基本沒有關于如何直接用c++調用整個python項目的。一般也是用c++調用一個python腳本文件的。可即使就是用c++調用一個python腳本文件,也遇到了數不盡的bug。無法找到python36.dll呀、python環境變量沖突呀…怎么說呢,反正是網上關于c++調用python腳本的bug,不管是查得到的還是查不到的,我全遇到了…
下面是自己記錄的一些問題以及解決辦法:
-
途中報錯:由于找不到python36.dll,無法繼續執行代碼。重新安裝程序可能會解決此問題
只要重新下載python37.dll解壓復制到C:\Windows\System32\這里就行了
-
QT調用python腳本時遇到的坑(十一大坑全有)
-
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding, when trying to start uwsgi這個問題應該還是跟環境變量什么的有關系,最后還是沒解決(可能是我電腦上python環境太多太雜亂了?)反正試了很多辦法也沒解決。最后的最后呢,換了臺電腦,重新按照教程,注意一些坑點,成功調用了一個python腳本文件。
主要參考教程如下:
-
VS+QT調用python腳本
-
C++ QT調用python腳本并將軟件打包發布
在這里特別想感謝第一篇教程的博主十里春風_jzh,因為在調用python腳本的時缺少遇到了很多bug和困難,這個博主一直耐心回答幫助我解決問題,真的十分感謝!這也是為什么我一直堅持寫博客,分享知識的原因,因為一個人的力量總是渺小的,而更多人的智慧是無量的!
最后由于精力耗費太大,網上相關資料又太少,雖然實現了C++調用一個python腳本文件,但是還是沒有實現C++直接調用一整個python項目的。(當時不知道為什么QT項目又只能在Debug模式下跑、也想到又要集成python整個大的項目,最后的軟件體積是否會非常大?))況且網上的方法一般還是把yolo模型用其他C++框架(opencv-dnn、onnxruntime、TensorRT)部署的比較多,于是轉戰直接用c++和相關框架來部署了。
當時記錄的新路歷程:
?yolo轉為onnx,用c++進行推理
發現直接用c++去調用整個yolov8的ultralytics項目網上的方法少之又少,而且通過了解知道yolo的底層框架什么的其實也是c++,看到很多用c++部署yolo的都是轉換為onnx模型,現在那就按照這種方法試試吧,畢竟參考資料很多。雖然之前一開始也想到了這種部署方法,但是出于對c++的恐懼以及對Yolov8項目的沒有很深入的了解,還有pytorch這些框架的不了解,感覺很害怕,怕自己弄錯,于是想著偷懶,如果能找到c++直接調用python整個項目的該多好。但是現在才反應過來,技術的懶你是一點也偷不了,這塊你不克服、你不去弄懂、你不去嘗試,你就跨不過去這個坎。反而弄懂之后不但掃清了你的障礙,還對這塊技術有了更深入的了解,還可以反觀之前那種偷懶方法隱含的弊端。
一開始是發現YOLO官方直接有相關的onnxruntime-cpp的代碼實現:ultralytics/examples
/YOLOv8-ONNXRuntime-CPP/。
-
注意點一、改變語言標準為c++17
VS2019修改C++標準(支持C++17)
-
注意點2:配置好onnx環境()
-
cuda和onnxruntime的環境配置(40系列的顯卡至cuda至少要11.8->這個點暫時不確定,因為后來我在項目中使用11.2版本的cuda沒有問題)
VS2019配置onnxruntime推理環境
使用gpu版本onnxruntime的推理需要使用cuda
cuda的安裝過程看這個CUDA安裝及環境配置——最新詳細版
結合CUDA11.0+VS2019+WIN10環境配置
???????主要還是參考官方yolo教程,但是yolo的教程運行起來還是報錯,然后還是一開始使用的這個博客使用opencv的方法進行Yolov8的推理:(注意環境必須是opencv4.8.0/4.8.1
yolov8 opencv模型部署(C++版)
但是出現問題:opencv4.8版本ok,enableCuda也設置了true,但是推理一張圖片居然要5s,看任務管理器也發現沒有用GPU,看這個博客評論得到以下點\
- 使用CUDA需要將cv::Mat類型轉換為GpuMat(好吧,后來試了這個發現顯示cv沒有GpuMat,不知道是不是英文opencv需要進行編譯的原因(勸退了,opencv編譯太難了
- ?博主也給出opencv+cuda源碼編譯有(看來需要將opencv進行特定的編譯?)同時也給出可以直接使用tensorrt,速度會比opencv+cuda快很多,說折騰這個時間成本高,且折騰完了所以對于也相對較慢(博主也給出了tensorrt進行部署的教程:win10下 yolov8 tensorrt模型部署?
(🙇🏻?♀?說實話當時tensorrt有點勸退了,好像有點復雜,再試試如何啟用opencv進行cuda加速把)
下面先給出基于opencv版本的yolo部署:
二、opencv部署:
2.1:前言
yolov8 opencv模型部署(C++ 版)
參考學習的博客:win10下 yolov8 tensorrt模型部署?
使用opencv推理yolov8模型,僅依賴opencv,無需其他庫,以yolov8s為例子,注意:
使用opencv4.8.1 !
使用opencv4.8.1 !
使用opencv4.8.1 !
如果你使用別的版本,例如opencv4.5,可能會出現錯誤
至于怎么安裝yolov8、訓練模型、導出onnx博客中都有,這里不做詳細解釋。關于vs2019配置opencv環境的博客網上也是一大堆,這里也不再重復造輪子了
2.2:代碼(含詳細注釋版)
inference.h
#ifndef INFERENCE_H
#define INFERENCE_H// Cpp native
#include <fstream>
#include <vector>
#include <string>
#include <random>// OpenCV / DNN / Inference
#include <opencv2/imgproc.hpp>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>//Detection結構體用來保存目標檢測的結果實例
struct Detection
{int class_id{ 0 };//整形變量用來存儲檢測到的目標的類別,默認值為0std::string className{};//字符串變量用來存儲檢測到的目標的名稱,默認值為空字符串float confidence{ 0.0 };//目標檢測的置信度(即對目標存在的確定程度)。默認值為0.0。cv::Scalar color{};//OpenCV庫中的Scalar類型變量,用于存儲顏色信息。它可以表示RGB、BGR或灰度顏色空間中的顏色cv::Rect box{}; //cv::Rect 類型包含四個成員變量:x、y、width 和 height
};//Infrence類用來執行目標檢測
class Inference
{
public://構造函數(modelInputShape是值模型的大小,默認為640,640;classesTxtFile是類別名稱的文本文件路徑(可選參數,默認為空字符串);runWithCuda是一個布爾值,指示是否使用CUDA加速運行(可選參數,默認為true)。Inference(const std::string& onnxModelPath, const cv::Size& modelInputShape = { 640, 640 }, const std::string& classesTxtFile = "", const bool& runWithCuda = true);//公有成員函數,用于執行目標檢測推斷。它接受一個cv::Mat類型的輸入圖像,并返回一個std::vector<Detection>類型的檢測結果。該函數將執行目標檢測算法,將檢測到的目標信息封裝到Detection結構體中,并將所有檢測結果存儲在一個向量中。std::vector<Detection> runInference(const cv::Mat& input);//私有成員函數,用于內部操作
private://loadClassesFromFile函數從文本文件中加載類別名稱void loadClassesFromFile();//loadOnnxNetwork函數加載ONNX模型void loadOnnxNetwork();//formatToSquare函數將輸入圖像調整為正方形形狀。cv::Mat formatToSquare(const cv::Mat& source);//這些是私有成員變量std::string modelPath{};//存儲模型文件路徑std::string classesPath{};//類別文件路徑bool cudaEnabled{};//CUDA加速的狀態//字符串向量,用于存儲目標檢測的類別名稱。默認情況下,它包含了一些通用的目標類別名稱std::vector<std::string> classes{ "screw", "number", "pump" };//std::vector<std::string> classes{ "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush" };//這是一個OpenCV庫中的Size2f類型變量,用于存儲模型的輸入形狀(寬度和高度)。cv::Size2f modelShape{};//設置目標檢測的閾值float modelConfidenceThreshold{ 0.25 };//目標置信度的閾值float modelScoreThreshold{ 0.45 };//目標得分的閾值float modelNMSThreshold{ 0.50 };//非最大抑制的閾值//布爾變量,指示是否使用letterbox技術將輸入圖像調整為正方形形狀bool letterBoxForSquare = true;//該類封裝了目標檢測推斷的相關操作和參數,通過調用構造函數和成員函數,你可以加載模型、執行推斷,并獲取目標檢測的結果cv::dnn::Net net;//penCV庫中的Net類型變量,用于存儲加載的目標檢測網絡模型
};#endif // INFERENCE_Hinference.cpp
#include "inference.h"Inference::Inference(const std::string& onnxModelPath, const cv::Size& modelInputShape, const std::string& classesTxtFile, const bool& runWithCuda)
{modelPath = onnxModelPath;modelShape = modelInputShape;classesPath = classesTxtFile;cudaEnabled = runWithCuda;loadOnnxNetwork();// loadClassesFromFile(); The classes are hard-coded for this example
}std::vector<Detection> Inference::runInference(const cv::Mat& input)
{cv::Mat modelInput = input;if (letterBoxForSquare && modelShape.width == modelShape.height)modelInput = formatToSquare(modelInput);cv::Mat blob;cv::dnn::blobFromImage(modelInput, blob, 1.0 / 255.0, modelShape, cv::Scalar(), true, false);net.setInput(blob);std::vector<cv::Mat> outputs;net.forward(outputs, net.getUnconnectedOutLayersNames());//cv::Mat cpuOutput;//outputs[0].copyTo(cpuOutput); // 將數據從 GPU 復制到 CPU 的 cv::Mat 對象中//float* data = reinterpret_cast<float*>(outputs.data); // 將數據賦值給 float* 指針int rows = outputs[0].size[1];int dimensions = outputs[0].size[2];bool yolov8 = true;// yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])if (dimensions > rows) // Check if the shape[2] is more than shape[1] (yolov8){yolov8 = true;rows = outputs[0].size[2];dimensions = outputs[0].size[1];outputs[0] = outputs[0].reshape(1, dimensions);cv::transpose(outputs[0], outputs[0]);}//if (cv::cuda::getCudaEnabledDeviceCount() > 0) { // 檢查是否啟用了GPU計算// // cv::cuda::GpuMat gpuData(outputs[0]); // 將 GPU 數據包裝到 cv::cuda::GpuMat 中// cv::Mat cpuData;// gpuData.download(cpuData); // 將 GPU 數據下載到 CPU 的 cv::Mat 中// float* data = (float*)cpuData.data; // 獲取 CPU 上的數據指針//}//else { // 在沒有啟用GPU計算時,直接使用CPU內存中的數據指針// data = (float*)outputs[0].data;//}//float* data = (float*)outputs[0].data;//************************GPU和CPU的數據交換//cv::UMat umatData = outputs[0].getUMat(cv::ACCESS_READ);//cv::Mat cpuData;//umatData.copyTo(cpuData);//********************************//float* data = (float*)cpuData.data;float* data = (float*)outputs[0].data;float x_factor = modelInput.cols / modelShape.width;float y_factor = modelInput.rows / modelShape.height;std::vector<int> class_ids;std::vector<float> confidences;std::vector<cv::Rect> boxes;for (int i = 0; i < rows; ++i){if (yolov8){float* classes_scores = data + 4;cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);cv::Point class_id;double maxClassScore;minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);if (maxClassScore > modelScoreThreshold){confidences.push_back(maxClassScore);class_ids.push_back(class_id.x);float x = data[0];float y = data[1];float w = data[2];float h = data[3];int left = int((x - 0.5 * w) * x_factor);int top = int((y - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);boxes.push_back(cv::Rect(left, top, width, height));}}else // yolov5{float confidence = data[4];if (confidence >= modelConfidenceThreshold){float* classes_scores = data + 5;cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);cv::Point class_id;double max_class_score;minMaxLoc(scores, 0, &max_class_score, 0, &class_id);if (max_class_score > modelScoreThreshold){confidences.push_back(confidence);class_ids.push_back(class_id.x);float x = data[0];float y = data[1];float w = data[2];float h = data[3];int left = int((x - 0.5 * w) * x_factor);int top = int((y - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);}}}data += dimensions;}std::vector<int> nms_result;cv::dnn::NMSBoxes(boxes, confidences, modelScoreThreshold, modelNMSThreshold, nms_result);std::vector<Detection> detections{};for (unsigned long i = 0; i < nms_result.size(); ++i){int idx = nms_result[i];Detection result;result.class_id = class_ids[idx];result.confidence = confidences[idx];std::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<int> dis(100, 255);result.color = cv::Scalar(dis(gen),dis(gen),dis(gen));result.className = classes[result.class_id];result.box = boxes[idx];detections.push_back(result);}return detections;
}void Inference::loadClassesFromFile()
{std::ifstream inputFile(classesPath);if (inputFile.is_open()){std::string classLine;while (std::getline(inputFile, classLine))classes.push_back(classLine);inputFile.close();}
}void Inference::loadOnnxNetwork()
{net = cv::dnn::readNetFromONNX(modelPath);if (cudaEnabled){std::cout << "\nRunning on CUDA" << std::endl;net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA_FP16);}else{std::cout << "\nRunning on CPU" << std::endl;net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);}
}cv::Mat Inference::formatToSquare(const cv::Mat& source)
{int col = source.cols;int row = source.rows;int _max = MAX(col, row);cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);source.copyTo(result(cv::Rect(0, 0, col, row)));return result;
}核心調用功能代碼
//執行視頻檢測算法和處理bool runOnGPU = false;int deviceId = 0; // 指定要使用的GPU設備的索引cv::cuda::setDevice(deviceId);// 1. 設置你的onnx模型// 注意,在這個例子中類別是硬編碼的,'classes.txt'只是一個占位符。Inference inf("D:/C++(2019)/models/static_best.onnx", cv::Size(640, 640), "classes.txt", runOnGPU); // classes.txt 可以缺失// 2. 設置你的輸入視頻路徑std::vector<std::string> videoPaths;videoPaths.push_back("D:/C++(2019)/data/video_good/test_video.mp4");//ui.status->setText("video path:D:/C++(2019)/data/video_good/test_video.mp4");//這里還是硬編碼,可以自主選擇所有視頻列表中的哪些視頻進行檢測(這里測試第一個視頻for (int i = 0; i < 1; ++i){const std::string& videoPath = videoPaths[i];cv::VideoCapture videoCapture(videoPath);if (!videoCapture.isOpened()){ui.status->setText("Failed to open video: ");std::cerr << "Failed to open video: " << videoPath << std::endl;continue;}cv::Mat frame;while (videoCapture.read(frame)){// Inference starts here...std::vector<Detection> output = inf.runInference(frame);int detections = output.size();std::cout << "Number of detections: " << detections << std::endl;for (int i = 0; i < detections; ++i){Detection detection = output[i];cv::Rect box = detection.box;cv::Scalar color = detection.color;//根據類別不同,顯示不同的顏色if (detection.class_id == 0) {color = cv::Scalar(0, 255, 0); // 紅色 (B, G, R)}else if (detection.class_id == 1) {color = cv::Scalar(0, 0, 255); // 紅色 (B, G, R)}else {color = cv::Scalar(255, 0, 0); // 紅色 (B, G, R)}// Detection boxcv::rectangle(frame, box, color, 2);// Detection box textstd::string classString = detection.className + ' ' + std::to_string(detection.confidence).substr(0, 4);cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);cv::rectangle(frame, textBox, color, cv::FILLED);cv::putText(frame, classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);}cv::namedWindow("Inference", cv::WINDOW_NORMAL); // 創建具有可調整大小功能的窗口cv::imshow("Inference", frame); // 在窗口中顯示圖像if (cv::waitKey(1) == 27) // Press Esc to exitbreak;}cv::destroyAllWindows();}
三、調用GPU-OpenCV的編譯問題
你會發現,從官網上下下來的opencv4.8.1,配置到vs環境中,就算你把上面核心調用功能中的代碼runOnGPU設置為了true,打開任務管理器,還是發現沒有調用GPU,這是為什么呢?
我們看看GPT的回答:
當使用OpenCV部署模型時,無法調用GPU可能有以下幾個原因:
- OpenCV版本: 確保你使用的OpenCV版本是支持GPU的。OpenCV 4.2及以上版本在DNN模塊中提供了對GPU的支持。
- GPU支持的構建: OpenCV需要使用具有GPU支持的構建版本。如果你是從預編譯的二進制文件安裝的OpenCV,可能沒有包含GPU支持。你可能需要從源代碼編譯OpenCV,并確保在編譯時啟用了CUDA支持。
- CUDA和cuDNN: 為了讓OpenCV利用GPU加速,你的系統上應該安裝了NVIDIA的CUDA Toolkit和cuDNN庫,并且它們應該與你的GPU兼容。
模型兼容性:并非所有的深度學習模型都能在GPU上運行。確保你的模型支持GPU加速。 - 代碼配置: 在代碼中,你需要明確指定使用GPU。例如,在OpenCV的DNN模塊中,你可以使用cv::dnn::Net::setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA)和cv::dnn::Net::setPreferableTarget(cv::dnn::DNN_TARGET_CUDA)來指定后端和目標。
- GPU資源: 如果你的系統中有多個GPU或者GPU資源被其他應用占用,OpenCV可能無法訪問它們。你可能需要配置你的代碼或環境,以確保正確的GPU被選中和使用。
- 操作系統和驅動程序: 確保你的操作系統和NVIDIA驅動程序是最新的,并且與你的CUDA Toolkit版本兼容。
- 硬件限制: 你的GPU硬件必須支持CUDA,這意味著它應該是NVIDIA的GPU。并非所有的NVIDIA GPU都支持CUDA,而且較老的型號可能不支持最新版本的CUDA Toolkit。
如果你確定了以上各項都已滿足,但仍然無法使用GPU,你可能需要檢查你的具體代碼配置或查閱OpenCV的官方文檔以獲取更多信息。在某些情況下,可能還需要查看錯誤日志或使用調試工具來確定問題所在。
說到底一句話核心就是:官網下載下來的都是預編譯的Opencv,預編譯的版本不支持GPU!需要你自己手動進行編譯!!!!
你看到這個時候可能跟我當時有一樣的疑問:為什么官方非要弄一個預編譯版本呢?直接加上支持GPU的不可以嗎?
我們再來看GPT的回答:
預編譯的OpenCV二進制文件通常不包括GPU支持,原因包括:
- 兼容性問題: 預編譯的二進制文件是為了在盡可能多的系統上運行,而不是針對特定的硬件或軟件配置。因為CUDA和GPU加速是NVIDIA專有的技術,只適用于NVIDIA的GPU,預編譯的OpenCV版本需要在沒有NVIDIA硬件的系統上也能工作。
- 版本控制: CUDA和cuDNN有多個版本,與特定版本的NVIDIA GPU驅動和硬件兼容。預編譯的OpenCV需要用戶自己根據他們的具體環境編譯CUDA支持。
- 文件大小: 包括GPU支持的預編譯二進制文件會顯著增大,因為它們需要包含額外的庫和資源。為了減少下載和安裝時間,通常不包含這些額外的組件。
許可和法律問題:CUDA是NVIDIA的專有技術,與之相關的分發可能涉及特定的許可和法律限制。 - 用戶需求: 并非所有OpenCV用戶都需要GPU支持。許多用戶在不需要進行大規模圖像處理或機器學習任務的情況下使用OpenCV,這時CPU運行可能就足夠了。
因此,預編譯的OpenCV版本通常不包括對GPU的支持,以保持最大的通用性和便捷性。需要GPU加速的用戶可以根據自己的具體硬件配置從源代碼編譯OpenCV,并啟用CUDA支持。
說到底,核心問題還是前面兩點。因為各個用戶的硬件各種各樣,要想調用GPU,就必須和具體場景兼容。像我們后面使用Tensorrt和onnxruntime進行調用GPU時,也要根據自己的硬件選擇合適的CUDA和CUDNN,這個原理是一樣的!
所以,那我們就編譯一下唄,編譯一下一個支持當前硬件水平的OpenCV唄。
沒錯,當時心高氣傲的我也是這么說的,知道我第四天還以為各種報錯而編譯不出來gpu版本的opencv時,我終于像它低頭了!
這里,關于網上編譯gpu版本的opencv的教程很多,我也試了很多(雖然最后我也沒編譯成功)。下面是我當時根據各個教程以及實驗總結出來的步驟:
OpenCV+CUDA進行編譯(cmake+vs2019)
- Step1:下載好OpenCV4.8.1的源碼、OpenCV4.8.1 contrib
- Step2:放入cmake:
- 第一次configure
- 第2次configure后:
- 搜索
CUDA,勾選三個; - 搜索world,不用勾選BUILD_opencv_world(后續用Vs編譯時會導致不正確:無法引入opencv_worldxxx.lib文件)
- 搜索MOULDELS,把value改成
OpenCV4.8.1 contrib的moulds路徑 - 輸入SET,查找OPENCV_GENERATE_SETUPVARS,不勾選
- 輸入test查找OPENCV_PERF_TESTS、BUILD_TESTS\BUILD_opencv_tests,不勾選
- 輸入java和JAVA,取消相應勾選
- 輸入python,取消相應勾選
- 搜索Nonfree,這個控制是否編譯擴展庫,如果使用需要勾選
- 第3次configure后:
- 再次搜索cuda,將CUDA_arch_bin中的顯卡算例改成自己的顯卡算力,并且勾選enable_fast_math,取消勾選rgbd了
- 然后configure,然后再generate,再open project
- 在vs2019中先雙擊CMakeTargets目錄先的ALL_BUILD右鍵點擊·生成·,然后漫長等待之后再點擊同樣目錄下的INSTALL右鍵生成
Tips:這處坑點挺多的,比如有文件下不下來要手動下載,最好對參考幾個博客再開始用
cmake編譯!!!
最后,是我的同學在第四天終于編譯成功!但是呢,我用的時候卻出現問題!
現象就是一個檢測結果也沒有!
后來我們一步一步debug,在源碼發現了問題:我們現在在c++環境下用opencv可以運行yolov8n. onnx模型,而且推理結果是準確的。但是啟用cuda之后模型輸出結果有問題,net.forward(outputs, net.getUnconnectedOutLayersNames());的結果outputs[0]的data總是0,導致推理結果不準確,好像是cpu到gpu之間數據傳輸的問題,網上也沒搜到。
這個問題也不了了之了,不知道是同學編譯的opencv有問題,還是其他的問題!因為在網上也沒有找到答案…
另外,在這期間我們還用onnxruntime部署了,可喜可賀的是終于能成功調用gpu了!但是!精度特別差,很多在python版本的yolo里面跑,幾乎92+%的置信度,在onnxruntime部署的根本沒檢測出來!!!由于知識能力有限,我也不知道是神經網絡的問題還是其他的問題,這個問題也擱置了。。。
關于onnxruntime部署的我會再寫一篇博客詳細介紹一下,以及代碼!
Web前端開發Vue-Element)
)

















