MySQL 常用優化方式
- sql 書寫順序與執行順序
- SQL設計優化
- 使用索引
- 避免索引失效
- 分析慢查詢
- 合理使用子查詢和臨時表
- 列相關使用
- 日常SQL優化場景
- limit語句
- 隱式類型轉換
- 嵌套子查詢
- 混合排序
- 查詢重寫
sql 書寫順序與執行順序
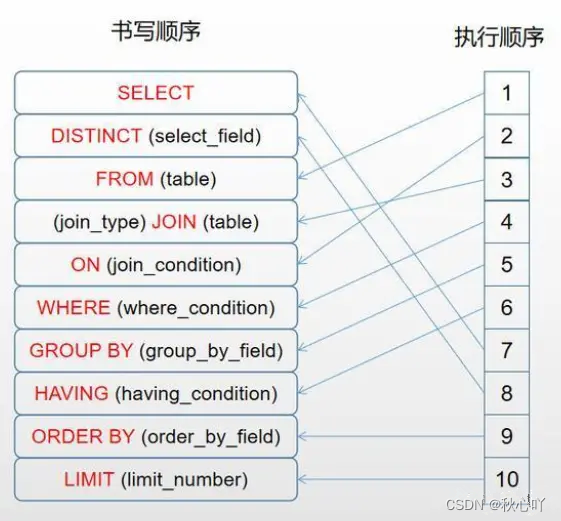
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <main_table>
(3) <join_type> JOIN <join_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
SQL設計優化
使用索引
- 確保對經常作為查詢條件的列創建索引
- 對JOIN的列創建索引
- 但要注意不要過度索引,因為這會減慢寫操作(如INSERT、UPDATE、DELETE)。
避免索引失效
- 匹配前綴:如果在WHERE子句中使用LIKE操作符,且匹配模式的開始部分是通配符(例如LIKE ‘%xyz’),將不會使用索引。但如果是’xyz%',則使用索引。
- 使用函數或表達式:在列上使用函數或表達式(例如WHERE YEAR(column) = 2021)會導致索引失效,因為MySQL無法利用索引直接定位數據
- OR條件:or表達式兩邊都必須有索引才會走索引,否則將不會走索引。
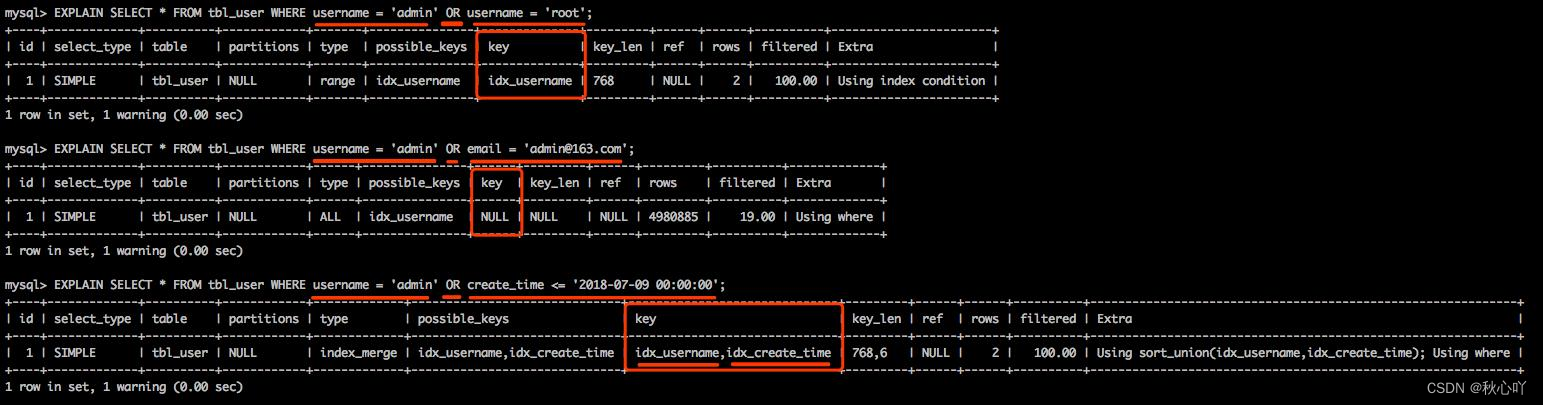
- 反向條件不走索引 != 、 <> 、 NOT IN、IS NOT NULL
- 數據類型不一致,隱式轉換(可能)導致索引失效【這點在隱式類型轉換中有場景演示】
分析慢查詢
- 使用
EXPLAIN關鍵字可以幫助你分析SQL查詢的執行計劃。通過分析,你可以發現潛在的性能瓶頸,如全表掃描、沒有使用索引等問題。
合理使用子查詢和臨時表
- 子查詢和臨時表如果不當使用,會造成性能問題。在可能的情況下,嘗試使用JOIN來替代它們。
列相關使用
-
使用最適合數據的最小數據類型,如INT、VARCHAR等,這可以減少磁盤IO,提高查詢效率。
-
盡量避免使用
SELECT *,而是明確指定需要查詢的字段。這不僅可以減少數據傳輸量,還能提高查詢效率。
日常SQL優化場景
limit語句
SELECT *
FROM operation
WHERE type = 'SQLStats'AND name = 'SlowLog'
ORDER BY create_time
LIMIT 1000, 10;
在優化上面SQL時,如果數據量特別龐大,除了在type, name, create_time 字段上加組合索引,還可以記錄上一次返回列表最后一條數據,以它為開始,優化后(并不會根據數據量的增長而發生變化):
SELECT *
FROM operation
WHERE type = 'SQLStats'
AND name = 'SlowLog'
AND create_time > '2017-03-16 14:00:00'
ORDER BY create_time limit 10;
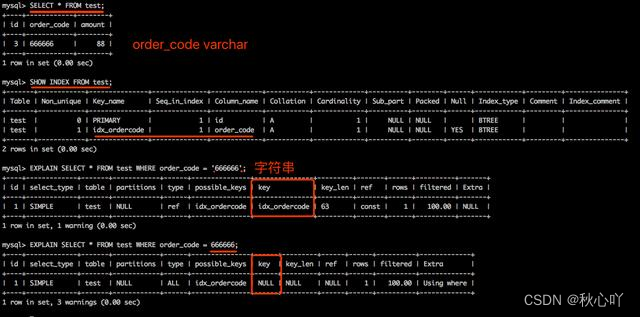
隱式類型轉換
隱式轉換,就是不帶轉換類型的轉換,當一個字段類型為varchar,但是在判斷時SQL是用int去判斷,MySQL 就會對這個int進行隱式轉換,將其int類型轉換為varchar
-- salecode 為varchar類型
explain select * from my_distribute where salecode=898

在上述例子中,salecode為varchar類型,其列有索引,但是SQL并沒有使用索引,是因為SQL中發生了隱式轉換,導致了全表掃描,那是不是所有隱式轉換都會使索引失效?
-- address 為int類型
explain select * from my_distribute where address='22'

還是同一個表,address類型為int,其列有索引,但是SQL卻使用索引[address],以上可知,隱式轉換不一定會導致索引失效,而是根據索引的類型變化,如果是數值類型,則右邊無論是數值還是字符串都可以走索引,但是我們在開發中,一定要格外注意,避免隱式轉換索引失效
嵌套子查詢
UPDATE operation o
SET status = 'applying'
WHERE o.id IN (SELECT idFROM (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) t);
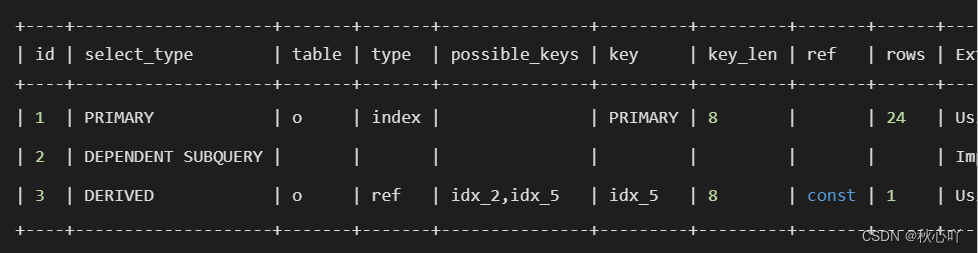
上述例子中,更新operation使用了子查詢去做過濾,并且使用了in條件,子查詢將會在檢索operation每一條數據時,都會執行一遍子查詢,并將結果集返回判斷operation的o.id是否在結果集中,效率非常低下,我們在開發中,也盡量使用join去替代子查詢,改良后的sql:
UPDATE operation oJOIN (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) tON o.id = t.id
SET status = 'applying'
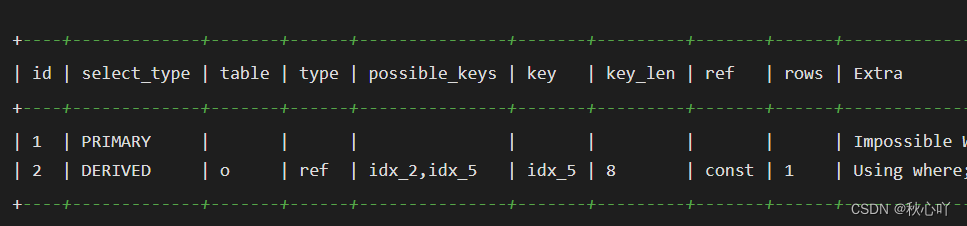
混合排序
MySQL 不能利用索引進行混合排序。但在某些場景,還是有機會使用特殊方法提升性能的。
SELECT *
FROM my_order o
INNER JOIN my_appraise a ON a.orderid = o.id
ORDER BY a.is_reply ASC,a.appraise_time DESC
LIMIT 0, 20
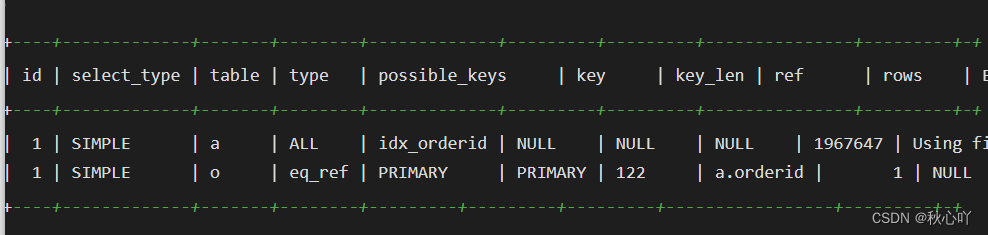
由于 is_reply 只有0和1兩種狀態,可以按照下面的方法重寫:
SELECT *
FROM ((SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 0ORDER BY appraise_time DESCLIMIT 0, 20)UNION ALL(SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 1ORDER BY appraise_time DESCLIMIT 0, 20)) t
ORDER BY is_reply ASC,appraisetime DESC
LIMIT 20;
使用表子查詢,將兩個查詢結果集UNION ALL 合并結果實現排序
查詢重寫
SELECTa.*,c.allocated
FROM(SELECT resourceid FROM my_distribute d WHERE isdelete = 0 AND cusmanagercode = '22353' ORDER BY salecode LIMIT 20 ) aLEFT JOIN ( SELECT resourcesid, sum( ifnull( allocated, 0 )* 12345 ) allocated FROM my_resources GROUP BY resourcesid ) c ON a.resourceid = c.resourcesid
以上SQL中因為c表使用了全表聚合,導致了數據全表掃描10w數據,優化后:
SELECTr.resourcesid,sum( ifnull( allocated, 0 ) * 12345 ) allocated
FROMmy_resources r,( SELECT resourceid, cusmanagercode FROM my_distribute d WHERE isdelete = 0 AND cusmanagercode = '22353' ORDER BY salecode LIMIT 20 ) a
WHEREr.resourcesid = a.resourceid
GROUP BYresourceid

)
【詳解】)
)





)









)
