目錄
一、背景
1.1 企業背景
1.2?面臨的問題
二、早期架構
三、新數倉架構
3.1 技術選型
3.2?運行架構
3.2.1 數據模型
?縱向分域
橫向分層
數據同步策略
3.2.2 數據同步策略
?增量策略
全量策略
四、應用實踐
4.1?業務模型
4.2?具體應用
五、實踐經驗
5.1?數據導入
5.2?數據模型
5.3?查詢優化—前綴索引
5.4?外部數據源讀取
5.5?數據字典
六、架構收益
七、生產問題
? 原文大佬的這篇Doris數倉的實戰文章寫的挺全面(跟本人目前所負責的數倉項目,有些分析場景 很相似),這里直接摘抄下來用作學習和知識沉淀。
一、背景
1.1 企業背景
? ? ?傳統行業面對數字化轉型往往會遇到很多困難,比如缺乏數據管理體系、數據需求開發流程冗長、煙囪式開發、過于依賴紙質化辦公等,美聯物業也有遇到類似的問題。本文主要介紹關于美聯物業在數據體系方面的建設,以及對數據倉庫搭建經驗進行的分享和介紹,旨在為數據量不大的傳統企業提供一些數倉思路,實現數據驅動業務,低成本、高效的進行數倉改造。
1.2?面臨的問題
? ? 美聯物業早在十多年前就已深入各城市開展房地產中介業務,數據體系的建設和發展與大多數傳統服務型公司類似。
? ? ?我們的數據來源于大大小小的子業務系統和部門手工報表數據等,存在歷史存量數據龐大,數據結構多樣復雜,數據質量差等普遍性問題。此外,早期業務邏輯處理多數是使用關系型數據庫 SQL Server 的存儲過程來實現,當業務流程稍作變更,就需要投入大量精力排查存儲過程并進行修改,使用及維護成本都比較高。
? 基于此背景,我們面臨的挑戰可以大致歸納為以下幾點:
?(1)缺乏數據管理體系,數據無法降本復用:多部門、多系統、多字段,命名隨意、表違反范式結構混亂;對同一業務來源數據無法做到多份報表復用,反復在不同報表編寫同一套計算邏輯。
(2)歷史大多數業務數據存儲在關系型數據庫中,分表分庫已無法做到上億數據秒級分析查詢。
(3)數據需求開發流程冗長、煙囪式開發。每當業務部門提出一個數據需求,數據開發就需要在多個系統之間進行數據兼容編寫存儲過程,從而導致存儲過程的可移植性和可讀性都非常差。
(4)部門之間嚴重依賴文本文檔的處理工作,效率低下。
二、早期架構
? ?針對上述的幾個需求,我們在平臺建設的初期選?了 Hadoop、Hive、Spark 構建最初的離線數倉架構,也是比較普遍、常見的架構,運作原理不進行過多贅述。
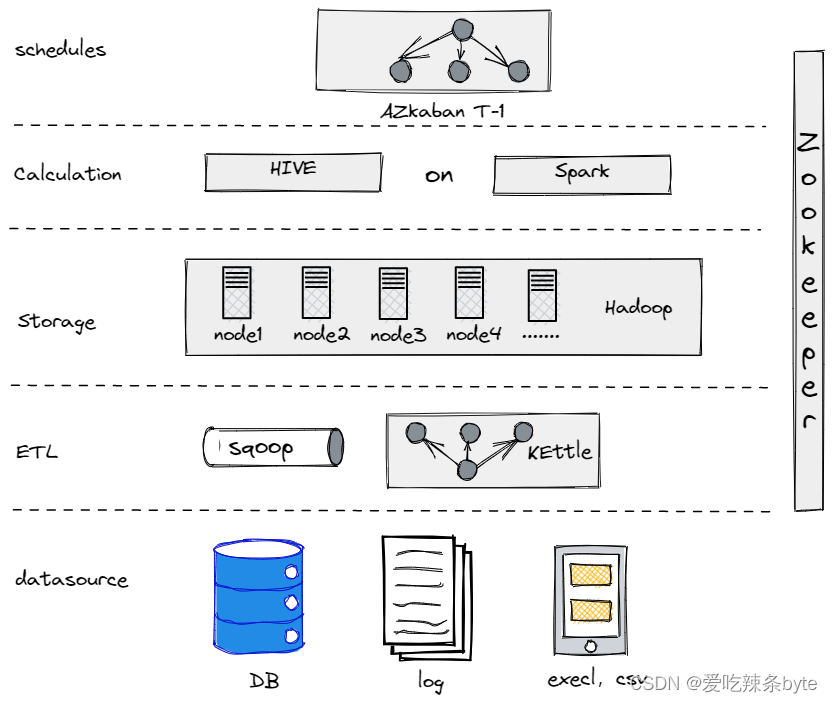
? ?我們數據體系主要服務對象以內部員工為主,如房產經紀人、后勤人員、行政人事、計算機部門等。當前數據體系無需面向 C 端用戶,因此在數據計算和資源方面的壓力并不大,早期基于 Hadoop 的架構可以滿足一部分基本的需求。但是隨著業務的不斷發展、內部人員對于數據分析的復雜性、分析的效率也越來越高,該架構的弊端日益越發的明顯,主要體現為以下幾點:
(1)傳統數據架構組件繁多,維護復雜,運維難度非常高。
(2)數據處理鏈路過長,導致查詢延遲變高
(3)數據時效性低:只可滿足T+1的數據需求,導致數據分析效率低下
(4)傳統公司的計算量和數據量不大,搭建Hadoop生態組件顯得殺雞用牛刀。
三、新數倉架構
? ?基于上述業務需求及痛點,我們開始了架構升級,并希望在這次升級中實現幾個目標:
-
初步建立數據管理體系,搭建數據倉庫。
-
搭建報表平臺和報表快速開發流程體系。
-
實現數據需求能夠快速反應和交付(1小時內),查詢延遲不超過 10s。
-
最小成本原則構建架構,支持滾動擴容。
3.1 技術選型
? ? 經過調研了解以及朋友推薦,了解到了Doris ,并很快與社區取得了聯系,Doris的優勢如下:
(1)極速性能
? ? Doris 依托于列式存儲引擎、自動分區分桶、向量計算、多表Join能力強悍和物化視圖等功能的實現,可以覆蓋眾多場景的查詢優化,海量數據也能可以保證低延遲查詢,實現分鐘級或秒級響應。
(2)極低成本
? ? ?降本提效已經成為現如今企業發展的常態,免費的開源軟件就比較滿足我們的條件,另外基于 Doris 極簡的架構、語言的兼容、豐富的生態等,為我們節省了不少的資源和人力的投入。并且 Doris 支持 PB 級別的存儲和分析,對于存量歷史數據較大、增量數據較少的公司來說,僅用 5-8 個節點就足以支撐上線使用。
(3)足夠簡單
? ??美聯物業及大部分傳統公司的數據人員除了需要完成數據開發工作之外,還需要兼顧運維和架構規劃的工作。因此我們選擇數倉組件的第一原則就是"簡單",簡單主要包括兩個方面:
-
架構簡單:Doris 的組件架構由 FE+BE 兩類進程組成,不依賴其他系統,整體架構簡潔易用,極簡運維,彈性伸縮.
-
使用簡單:Apache Doris 兼容 MySQL 協議,支持標準 SQL,有利于開發效率和共識統一,此外,Doris 的 ETL 編寫腳本主要使用 SQL進行開發,使用 MySQL 協議登陸使用,兼容多數 MySQL 語法,提供豐富的數據分析函數,省去了 UDF 開發工作。
3.2?運行架構

? ? 在對Doris性能檢測之后,我們完全摒棄了之前使用 Hadoop、Hive、Spark 體系建立的數倉,決定基于Doris 對架構進行重構,以 Doris 作為數倉底座進行開發,實現存,算統一。
- 數據集成:利用?DataX、Flink CDC 和Doris 的 Multi Catalog 功能等進行數據集成。
-
數據管理:利用 Apache Dolphinscheduler 進行腳本開發的生命周期管理、多租戶人員的權限管理、數據質量校驗等。
-
監控告警:采用 Grafana + Prometheus進行監控告警,Doris 的各項監控指標可以在上面運行,解決了對組件資源和日志的監控問題。
-
數據服務:使用帆軟 Report 為用戶提供數據查詢和分析服務,帆軟支持表單制作和數據填報等功能,支持自助取數和自助分析。
3.2.1 數據模型
?縱向分域
? ? 房地產中介行業的大數據主題大致如下,一般會根據這些主題進行數倉建模。建模主題域核心圍繞"企業用戶"、"客戶"、"房源"、"組織"等幾個業務實體展開,進行維度表和事實表的設計。
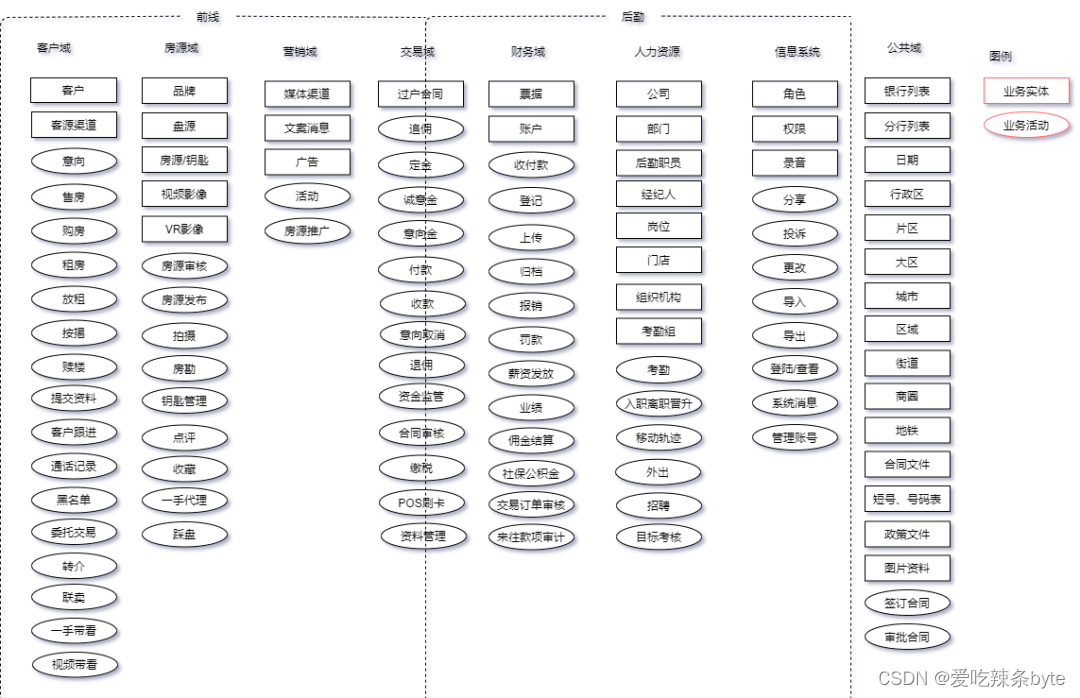
? ?我們從前線到后勤,對業務數據總線進行了梳理,旨在整理業務實體和業務活動相關數據,如多個系統之間存在同一個業務實體,應統一為一個字段。梳理業務總線有助于掌握公司整體數據結構,便于維度建模等工作。
? ?下圖為我們簡單的梳理部分房地產中介行業的業務總線:
橫向分層
? ?數據分層采用傳統數倉最常見的 5 層結構(ods, dwd,dim,dws,ads),主要是利用 Apache Doris + Apache DolphinScheduler 進行層級數據之間的調度任務編排和管理。
數據同步策略
? 我們在8點到24點之間采用增量策略,0點到8點執行全量策略,采用增量+全量的方式是考慮到:當ODS表因為記錄的歷史狀態字段變更或者CDC出現數據未完全同步的情況下,可以及時進行全量補數和修正歷史狀態變化數據。
| 層級 | 備注 | 存儲策略 |
| ODS | 利用datax doris write進行數據的本地導入要注意參數設置exec_mem_limit參數大小,部分全量數據較大超過限制會導致stream load 失敗 | 8點到24點增量策略;0點到8點全量策略一次 |
| DWD | 部分事實表涉及緩慢變化維,需要進行拉鏈存儲 | 8點到24點增量策略;0點到8點全量策略一次,部分表拉鏈存儲 |
| DWS和ADS | 注意數據校驗問題,加入審計時間,如etl_time,last_etl_time,create_time等字段,方便后續故障排查 | 8點到24點增量策略;0點到8點全量策略一次 |
| DIM | 維度表存放層,如客戶,房源,職員,職級,崗位等 | 每小時整點全量 |
3.2.2 數據同步策略
?增量策略
1)where >= "業務時間-1天或-1小時"
? ? ?增量的 SQL 語句不使用where ="業務時間當天"的原因是為了避免數據漂移情況發生,換言之,調度腳本之間存在時間差,如 23:58:00 執行了腳本,腳本的執行周期是10 分鐘/次,但是源庫中最后一條數據是在23:59:00才新增的,真正這時候where="業務時間當天"就會將該數據漏掉。
2)每次跑增量腳本前,需要將表中最大的主鍵ID存入輔助表,where >= "輔助表記錄ID"
? ? 如果 Doris 表使用的是 Unique Key 模型,且恰好為組合主鍵,當主鍵組合在源表發生了變化,這時候where >=" 業務時間-1天"會記錄該變化,把主鍵發生變化的數據 Load 進來,從而造成數據重復。而使用這種自增策略可有效避免該情況發生,且自增策略只適用于源表自帶業務自增主鍵的情況。
3)表分區
? ?例如日志表等基于時間的自增數據,且歷史數據和狀態基本不會變更,數據量非常大,全量或快照計算壓力非常大的場景,這種場景需要對 Doris 表進行建表分區,每次增量進行分區替換操作即可,同時需要注意數據漂移情況。
全量策略
1)Truncate Table清空表插入
? ? ? ?如果是面向C端用戶的公司和白天調度時間千萬別這么做,否則會導致一段時間沒有數據,Truncate Table適合數據量較小的表,凌晨沒有用戶使用系統的公司。
2)ALTER TABLE tbl1 REPLACE WITH TABLE tbl2??表替換
? ? 這種方式是一種原子操作,適合數據量大的全量表。每次執行腳本前先 Create 一張數據結構相同的臨時表,把全量數據 Load 到臨時表,再執行表替換操作,可以進行無縫銜接。
四、應用實踐
4.1?業務模型
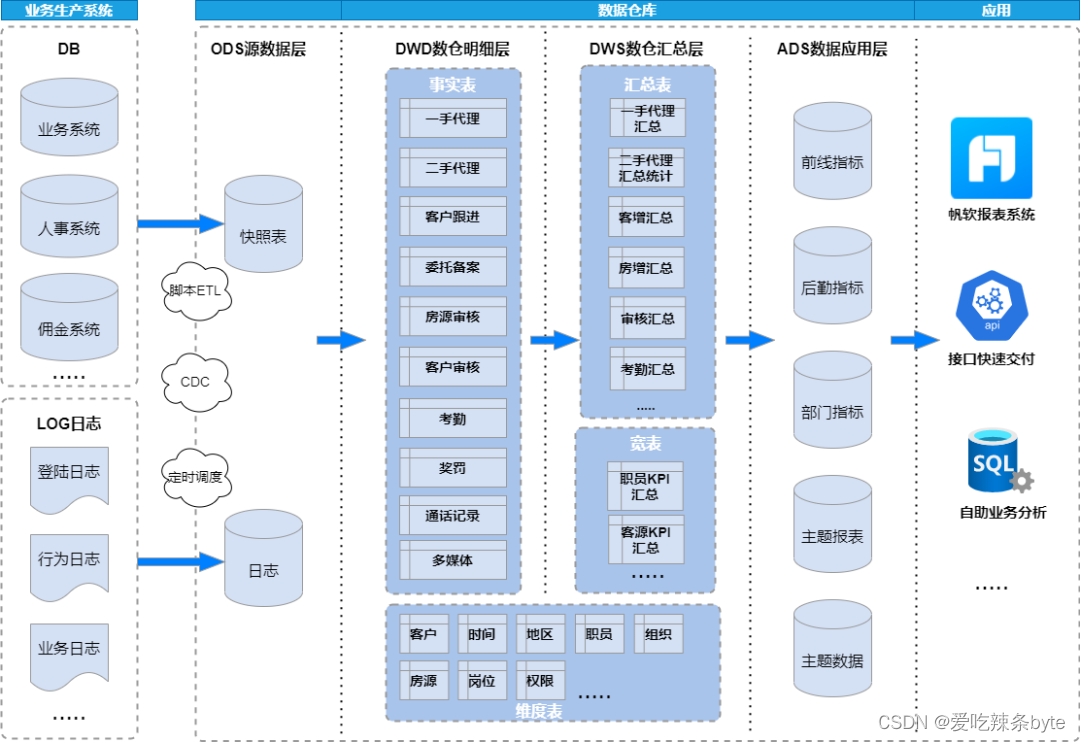
- 業務模型是最常見的分鐘級調度ETL
- 離線數據利用DataX批量同步,通過Flink CDC將RDS的數據實時同步到Doris,利用Doris的物化視圖或者Aggregate模型表進行實時匯總處理。
- 所有層級表模型大部分采用Unique key主鍵模型,可以有效保證數據腳本的冪等性,解決下游數據重復的問題
- ETL腳本通過Dolphinscheduler(簡稱DS)進行編排和統一調度
-
帆軟BI進行自助取數和分析
部署建議
-
初次部署建議配置:8 節點 2FE * 8BE 混合部署
-
節點配置:32C * 60GB * 2TB SSD
-
對于存量數據TB級、增量數據GB級的場景完全夠用,如有需要可以進行滾動擴容。
4.2?具體應用
? ? 1)離線業務數據和日志數據集成利用 DataX 進行增量和全量調度,Datax支持CSV格式和多種關系型數據庫的Redear,而 Doris 在很早之前就提供了 DataX Doris writer 連接器。
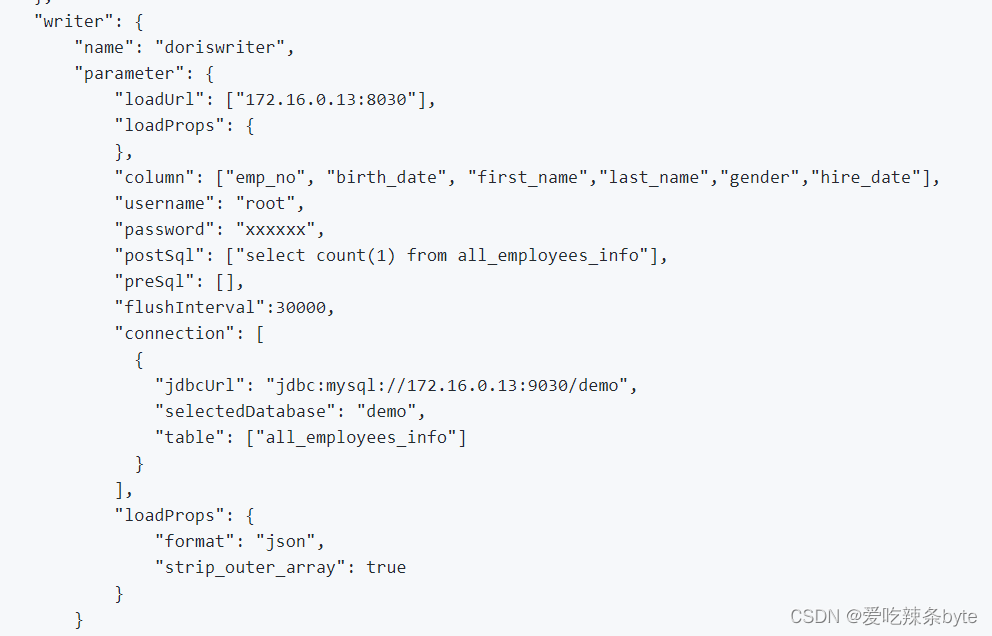
? ?2)實時部分借助了Flink CDC將RDS的數據實時同步到Doris,利用Doris的物化視圖或者Aggregate模型表進行實時指標的匯總處理,因為我們只有部分指標需要實時處理,不希望產生過多的數據庫連接和 Flink Job,因此我們使用Dinky的多源合并和整庫同步功能,也可以自己簡單實現一個Flink DataStream 多源合并任務,只通過一個 Job 可對多個 CDC 源表進行維護。值得一提的是, Flink CDC 和 Apache Doris 新版本支持 Schema Change 實時同步,在成本允許的前提下,可完全使用 CDC 的方式對 ODS 層進行改造。
EXECUTE CDCSOURCE demo_doris WITH ('connector' = 'mysql-cdc','hostname' = '127.0.0.1','port' = '3306','username' = 'root','password' = '123456','checkpoint' = '10000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'ods.ods_*,ods.ods_*','sink.connector' = 'doris','sink.fenodes' = '127.0.0.1:8030','sink.username' = 'root','sink.password' = '123456','sink.doris.batch.size' = '1000','sink.sink.max-retries' = '1','sink.sink.batch.interval' = '60000','sink.sink.db' = 'test','sink.sink.properties.format' ='json','sink.sink.properties.read_json_by_line' ='true','sink.table.identifier' = '${schemaName}.${tableName}','sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3) 腳本語言采用shell+sql或純sql的形式,我們在Apache DolphinScheduler上進行腳本生命周期管理和發布,如ODS層,可以編寫通用的DataX Job 文件,通過傳參的方式將DataX Job 文件傳參執行源表導入,無需在每一個源表編寫不同的DataX Job,支持統一配置參數和代碼內容,維護起來非常方便。另外我們在 DolphinScheduler上對 Doris 的 ETL 腳本進行管理,還可以進行版本控制,能有效控制生產環境錯誤的發生,進行及時回滾。

4)?發布 ETL 腳本后導入數據,可直接在帆軟 Report 進行頁面制作。基于登陸賬號來控制頁面權限,如需控制行級別、字段級別權限,可以制作全局字典,利用 SQL 方式進行控制。Doris 完全支持對賬號的庫表權限控制,這一點和 MySQL 的設置完全一樣,使用起來非常便捷。
? 在新的架構體系,新增的數據需求直接利用帆軟BI進行自助取數和分析,最快可在當天響應交付
? ?除以上之外,還可以利用 Doris備份實現容災恢復、Grafana + Prometheus對集群進行指標規則監控告警、開啟 Doris審計日志對執行 SQL 效率進行監控等,慢查詢定位及優化等,因篇幅限制,此處不進行詳細說明。
五、實踐經驗
5.1?數據導入
? 我們使用 DataX進行離線數據導入,DataX 采用的是 Stream Load方式導入,該方式可以通過參數控制導入批次流量,DataX導入不需要借助計算引擎,開箱即用的特點非常方便。另外,Stream Load導入是同步返回結果,而其他導入方式一般是異步返回結果。
? ? 在數據導入方式上,大部分返回結果是異步操作,即在Doris里該導入任務狀態有可能是失敗的,而Dolphinscheduler會誤以為該腳本已經執行成功,因此在bash等腳本里執行Doris的導入操作邏輯時,還需要判斷上游任務狀態是否成功,可以在腳本里執行show load,再用正則去過濾狀態進行判斷。
5.2?數據模型
? ?所有層級表模型大部分采用Unique key主鍵模型,可以有效保證數據腳本的冪等性,解決下游數據重復的問題。
5.3?查詢優化—前綴索引
? ? 盡量把非字符類型的,如int類型的、where條件中最常用的字段放前排36個字節內,在點查場景下,過濾這些字段返回的結果基本可在毫秒級別實現。
5.4?外部數據源讀取
? ?Catalog 方式:使用 JDBC 外表連接,對 Doris生產集群數據進行讀取,便于生產數據直接 Load 進測試服務器進行測試。另外,新版支持多數據源的Catalog,可以基于 Catalog 對 ODS 層進行改造,無需使用 DataX 對ODS 進行導入。
? ?但這種方式對FE節點的壓力會很大,在導入過程中可明顯觀察FE節點CPU資源被拉滿,如果Fe資源并不充足的情況下,建議選擇Stream load的方式進行數據導入,如Datax。
5.5?數據字典
? ? ?利用Doris自帶的information_schema元數據可以制作簡單的數據字典,這一點對公司還未建立數據治理體系前是非常重要的一步,方便低成本管理數倉人員的操作規范。
利用 Doris自帶的information_schema元數據制作簡單的數據字典,利用數據字典可快速對表格和字段的全局查找和釋義,這一點對公司還未建立數據治理體系前是非常重要的一步,最低成本形成數倉人員的數據規范,減少人員溝通成本,提高開發效率。
六、架構收益
? ?引入?Doris 之后,美聯物業實現了只用少數服務器、快速搭建一套數據倉庫,成功實現降本賦能。在這段時間的運行中,給我們帶來的部分收益如下:
- 自動取數導數:數據倉庫的明細表可以定時進行取數、導數,自助組合維度進行分析。
-
效率提升:T+1 的離線任務,時效降低至分鐘級。
-
查詢延遲降低:面對上億行數據的表,利用Doris在索引和點查方面的能力,即席查詢延遲平均在1秒內,復雜查詢也能5秒內響應。
-
運維成本降低:從數據集成到數據服務,只需維護少數組件就可以實現整個鏈路的高效管理。
-
存儲資源節省:Doris 超高的壓縮比,將數據壓縮了70%,相較于 Hadoop 來說,存儲資源的消耗大幅降低。
-
數據管理體系初步形成:Doris 數倉的實現使得數據資產得以規范化的沉淀。
七、生產問題
-
內存一直不釋放
? ? ?Doris的BE節點在舊版本是開啟PageCache 和 ChunkAllocator 的,目的是為了減少查詢的延遲,這兩個功能會占用一定比例的內存,并且一直不會釋放,長此以往就會導致be計算資源越來越緊張。新版本直接禁用了這兩個配置,但美聯物業數倉是開啟了這2項配置,并且每天凌晨進行be滾動重啟的,既能保證be內存及時釋放,也能降低查詢延遲。
-
數據備份
? ? ?目前Doris的備份依賴Broker load,只能基于BOS、HDFS 等文件系統,對于沒有安裝HDFS這類的服務器基本用不了。
參考文章:
Apache Doris 在美聯物業的數據倉庫應用實踐,助力傳統行業數字化革新|應用實踐
美聯物業基于Apache Doris數倉實踐





)

)




![尋找峰值[中等]](http://pic.xiahunao.cn/尋找峰值[中等])

![Java之美[從菜鳥到高手演變]之Json類型數據的處理](http://pic.xiahunao.cn/Java之美[從菜鳥到高手演變]之Json類型數據的處理)
||Unity--自動版面(Vertical Layout Group))



)