1????集合通信對分布式訓練至關重要
在分布式訓練中,每一塊 GPU 只負責處理部分模型或者數據。集群中不同 GPU 之間通過集合通信的方式,完成梯度同步和參數更新等操作,使得所有 GPU 能夠作為一個整體加速模型訓練。
如果有一塊 GPU 在集合通信中出了狀況,將會導致其他 GPU 處于等待狀態,直到這塊 GPU 完成數據同步,集群中所有 GPU 才會開始后續工作。
所以,集合通信性能直接影響了分布式任務的速度,決定了集群中所有 GPU 能否形成合力加速模型訓練。
為了最大提升集合通信的性能,在基礎設施層面,集群通常采用基于 RDMA 的高性能物理網絡,在任務運行時使用集合通信庫進行加速。
2? ? 大模型對系統的運維能力和穩定性提出新要求
我們知道,大模型的訓練任務時長以周或月為周期,集群規模在千卡甚至萬卡以上規模。這導致在整個任務過程中會發生各種故障,導致資源利用率不高或者任務中斷。這使得大模型的訓練任務,不能只看重集群規模和性能,更需要關注系統的運維能力和穩定性。
如果系統的運維能力和穩定性不夠好,將會降低集群的「有效訓練時長」,延長項目時間產生昂貴的時間成本。比如完成整個訓練任務花了 30 天,結果有 10 天是在排除各類故障,這是不可接受的。
在分布式訓練任務中,作為系統核心組件之一的集合通信庫,同樣需要面向大模型場景,在系統的運維能力和穩定性上進行優化。
3? ? 百度集合通信庫 BCCL 概述
百度集合通信庫 BCCL(Baidu Collective Communication Library)是百度智能云推出的一款面向大模型訓練場景優化的集合通信庫,是百度百舸 3.0中的重要組件。
BCCL 基于開源的 NCCL 進行了功能擴展和能力增強,針對大模型訓練場景在可觀測性、故障診斷、穩定性等方面進行優化,進一步提升集合通信庫的可運維能力。同時,BCCL 針對百度智能云的特定 GPU 芯片進行了集合通信性能優化,進一步提升資源利用率。相比 NCCL,BCCL 的關鍵特性如下:
- 可觀測性:新增集合通信帶寬實時統計能力;
- 故障診斷:新增集合通信 hang 時的故障診斷能力;
- 穩定性:增強網絡穩定性和故障容錯能力;
- 性能優化:提升大模型訓練主流 GPU 芯片的集合通信性能。
接下來,我們將介紹 BCCL 在以上 4 個方面的能力。
4 ?? 可觀測性:集合通信帶寬實時統計
4.1????背景
在訓練過程中,有時候會出現任務正常運行,但是集群的端到端性能下降的情況。出現這類問題,可能是集群中任一組件導致的。這時候就需要運維工程師對集群進行全面的檢查。
4.2????問題
其中,存儲系統、RDMA 網絡、GPU 卡等通常都配有實時可觀測性平臺,可以在不中斷任務運行的情況下判斷是否存在異常。相比之下,針對集合通信性能的判斷,則缺乏實時和直接的手段。目前,若懷疑集合通信存在性能問題,只能使用如下 2 種手段:
- 使用 RDMA 流量監控平臺進行故障排查。這種方法僅能間接推測出跨機集合通信性能是否有異常。
- 停止訓練任務釋放 GPU 資源,使用 nccl-test 進行二分查找,最終鎖定出現故障的設備。
雖然第 2 種方法可以完成集合通信異常的診斷,但是測試場景比較有限,只能判斷是否有常規的硬件異常問題。同時整個過程中會導致訓練中斷,產生昂貴的時間成本。
4.3????特性和效果
BCCL 的實時集合通信帶寬統計功能,可以在訓練過程中對集合通信性能進行實時觀測,準確地展示集合通信在不同階段的性能表現,為故障診斷排除、訓練性能調優等提供數據支撐。即使在復雜通信模式下,BCCL 通過精確的打點技術依然能提供準確的帶寬統計的能力。
在集合通信性能異常的故障排除方面,可以進一步根據不同通信組的性能縮小故障范圍。在混合并行模式下,可以通過多個性能異常的通信組的交集進一步確認故障節點。
在訓練性能優化方面,可以評估該帶寬是否打滿硬件上限,是否有其他的優化策略,為模型調優提供更多的監控數據支撐。
5 ?? 故障診斷:集合通信故障診斷
5.1????背景
設備故障導致的訓練任務異常停止,也是大模型訓練任務時常發生的狀況。故障發生后,一般都會有報錯日志或者巡檢異常告警,比如可以發現某個 GPU 存在異常。在訓練任務異常時,我們只需要匹配異常時間點是否有相關異常事件或告警,即可確認故障 root cause。
除此之外,還存在著一類不告警的「靜默故障」。當發生故障時,整個訓練任務 hang 住,無法繼續訓練,但是進程不會異常退出,也無法確認是哪個 GPU 或哪個故障節點導致訓練任務 hang。然而,此類問題的排查難點在于,該類故障不會立刻發生,訓練任務可以正常啟動并正常訓練,但是在訓練超過一定時間后(可能是幾個小時或者數天)突然 hang 住。排查時很難穩定復現該故障,導致排查難度進一步提高。
5.2? ? 問題
由于集合通信的同步性,當某個 GPU 出現故障時,其他 GPU 仍會認為自己處于正常地等待狀態。因此,當通信過程中斷時,沒有 GPU 會輸出異常日志,使得我們很難迅速定位到具體的故障 GPU。當上層應用程序在某一多 GPU 的集合通信操作中 hang 時,應用程序也只能感知到某個集合通信組(故障 comm)出現了問題,卻無法精確地判斷是哪個 GPU 導致了此次集合通信的異常。
運維工程師通常使用 nccl-test 來嘗試復現和定位問題,但是由于壓測時間短、測試場景簡單,很難復現集合通信 hang。
在百度集團內部排查此類問題時,首先停止線上的訓練任務,然后進行長時間的壓測,比如對于現有訓練任務模型進行切分,對集群機器進行分批次壓測,不斷縮小故障范圍,從而確認故障機。排查代價通常需要 2 天甚至更多。這類故障排查的時間,將帶來巨大的集群停機成本。
5.3????特性和效果
為了應對這一挑戰,在訓練任務正常運行時,BCCL 實時記錄集合通信內部的通信狀態。當任務 hang 時,BCCL 會輸出各個 rank 的集合通信狀態。運維工程師可以根據這些數據特征來進一步縮小故障 GPU 的范圍。通過這種方法,BCCL 通過一種近乎無損的方式實現了故障機的快速定位,大幅度提高了問題排查的效率。
6 ?? 穩定性:網絡穩定性和容錯增強
6.1????背景
在模型訓練過程中,單個網絡端口偶發性的 updown 會導致當前進程異常,進而引起整個訓練任務退出。然而,單端口的偶發性 updown 在物理網絡是不可避免的。
6.2????特性和效果
BCCL 針對此類偶發性的異常場景,進行了故障容錯以避免任務退出,提升訓練任務的穩定性。
- 控制面容錯能力提升:在訓練任務啟動時,通常會由于偶發性的網絡故障或其他故障導致訓練任務啟動失敗。BCCL 針對常見的偶發性異常故障增加相應的重試機制,確保訓練任務正常啟動。
- 數據面容錯能力提升:在訓練任務正常運行時,偶發性的網絡抖動可能導致 RDMA 重傳超次,從而導致整個訓練任務異常。BCCL 優化了 RDMA 重傳超次機制,提升訓練任務的健壯性。
7 ?? 性能優化:集合通信性能優化
針對大模型訓練場景的主流 GPU 芯片,集合通信性能還存在繼續提升的空間,進一步對任務進行加速。
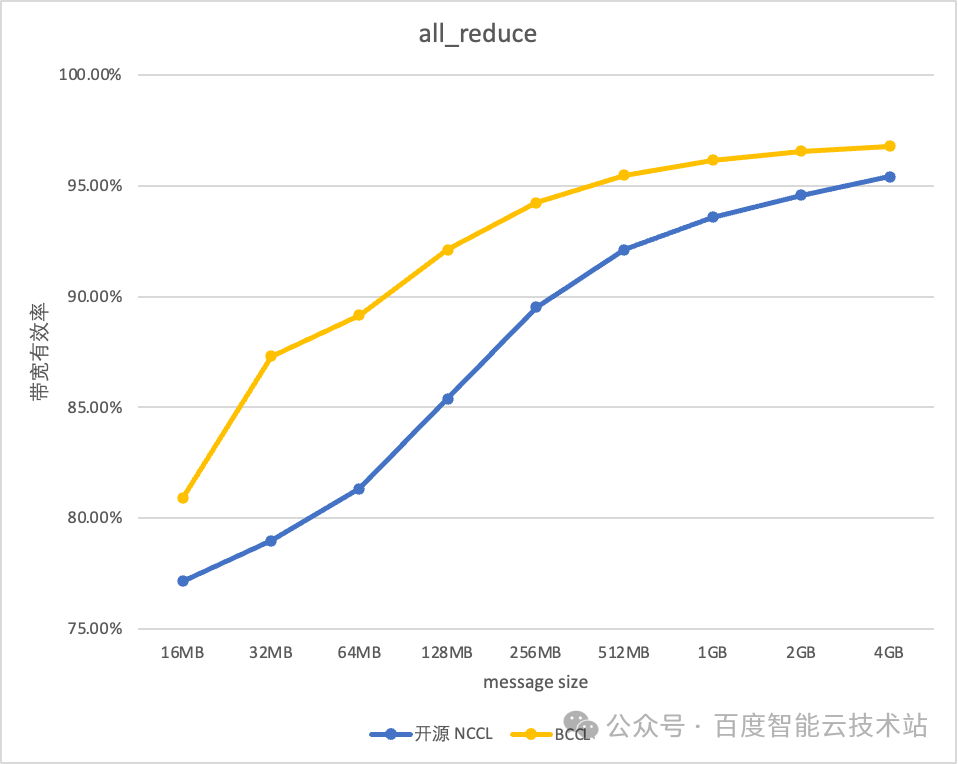
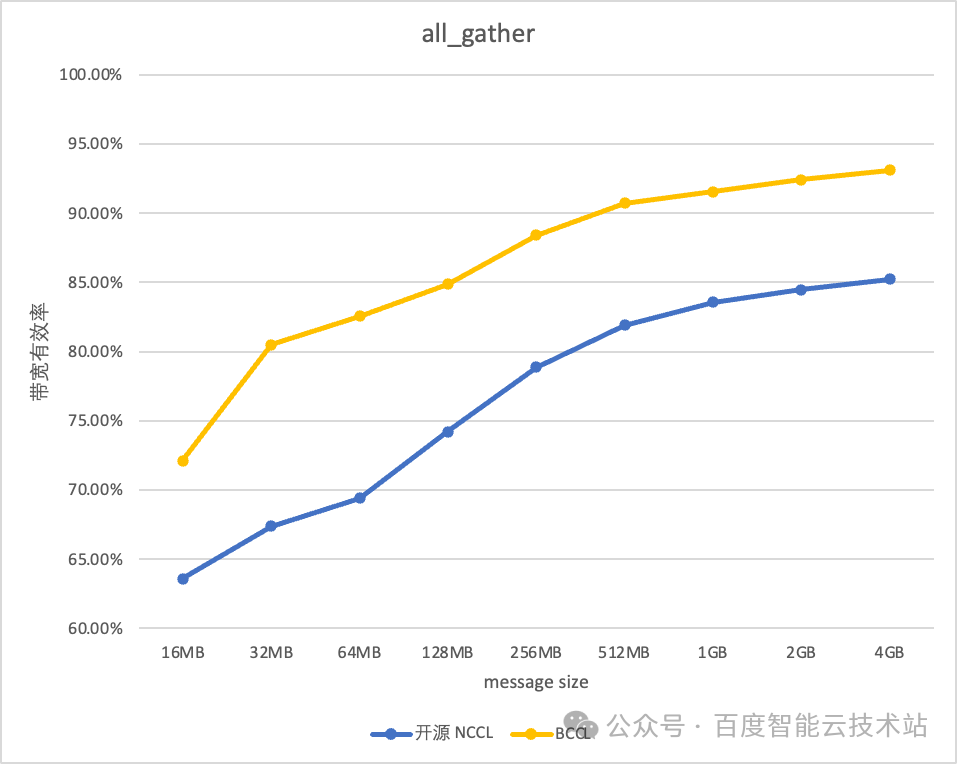
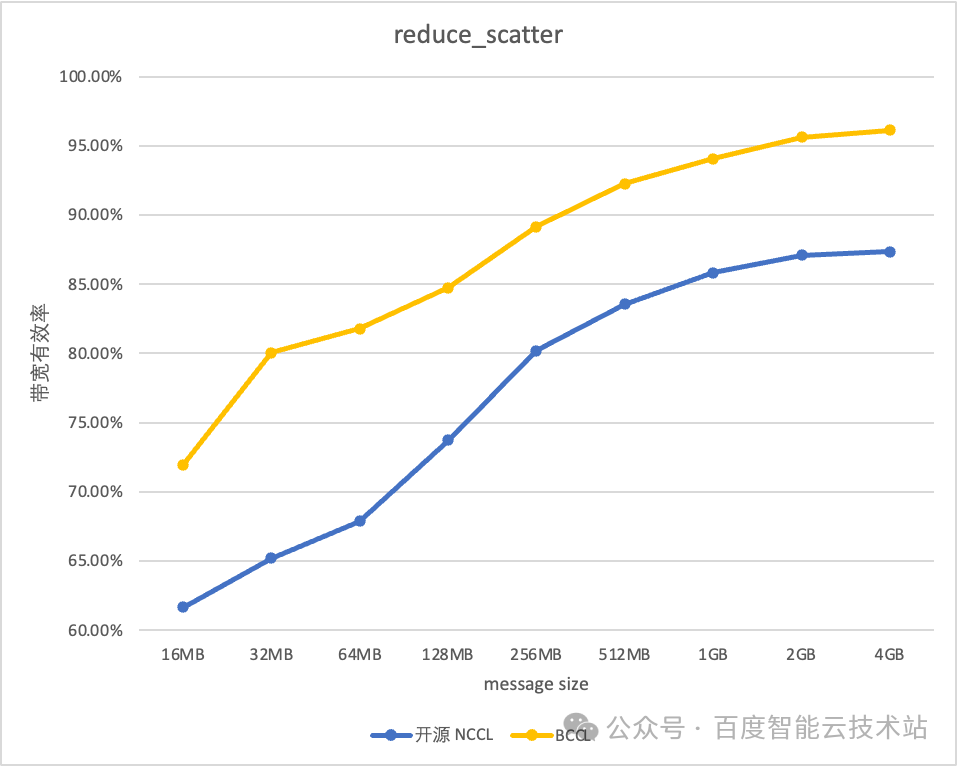
BCCL 針對百度智能云提供的主流的 GPU 芯片進行了深度優化。以雙機 H800 測試環境為例,BCCL 相比 NCCL 帶寬利用率可提升 10%。
8????總結
2023 年 12 月 20 日,百度百舸·AI 異構計算平臺 3.0 發布,它是專為大模型優化的智能基礎設施。
借助 BCCL 在運維能力和穩定性進行的優化,使得百度百舸平臺的有效訓練時長達到 98%,帶寬的有效利用率可以達到 95%。
大家可以訪問?安裝BCCL庫 - 百舸異構計算平臺AIHC | 百度智能云文檔???????,了解更多 BCCL 的相關信息。

)






)





-OpenGL)
)

)

