文章目錄
- 前端復習
- SQL
- 數據庫的分類
- 關系型數據庫
- 非關系型數據庫(NoSQL)
- 數據庫的構成
- 軟件架構
- MySQL內部數據組織方式
- SQL語言
- 登錄數據庫
- 數據庫操作
- 查看庫
- 創建庫
- 刪除庫
- 修改庫
- 數據庫中表的操作
- 選擇數據庫
- 創建表
- 刪除表
- 查看表
- 修改表
- 數據庫中數據的操作
- 添加數據
- 查詢數據
- 修改數據
- 刪除數據
- 特殊關鍵字
- where(條件關鍵字)
- distinct(過濾關鍵字)
- limit(限制結果集關鍵字)
- as(取別名關鍵字)
- order by(排序關鍵字)
- group by(分組關鍵字)
- 聚合函數
- SQL語句的執行順序
前端復習
- HTML
- 以標簽為基礎
- 主要負責頁面上內容的搭建
- css
- 控制頁面的樣式,字體的大小,圖片等等
- 主要控制樣式,頁面的布局
- 大
div套小div
- js
- 頁面上動態內容的功能,比如點擊按鈕之后、完成驗證碼的校驗等等
- html解析之后,在瀏覽器上以dom樹的形式存在,即對dom樹的增刪改查
- vue
- 幫我們操作dom,我們只用操作數據,數據會自己寫在頁面上
- 插值表達式、v-bind/v-model/v-on/v-for
SQL
數據庫的分類
關系型數據庫
- 不僅可以存儲數據,還可以存儲數據與數據之間的關系。
常見的關系型數據庫:
- Oracle
- MySQL
- MariaDB
- SQL Server
- DB2
- PostgreSQL
非關系型數據庫(NoSQL)
- 對關系型數據庫的補充,主要是用來做一些關系型數據庫不擅長的事情。
- 關系型數據庫的數據,一般是存儲在磁盤上,所以速度比較慢。非關系型數據庫一般是存在內存中的,所以性能比較好。
常見的非關系型數據庫:
- Redis
- 最常用的非關系型數據庫,數據存在內存,速度快,吞吐量高。
- Memcached
- Mongodb
- Hbase
關系型數據庫和非關系型數據庫的區別:
- 最本質的區別是::關系型數據庫以
數據和數據之間存在的關系維護數據, 而非關系型數據庫是指存儲數據的時候數據和數據之間沒有什么特定關系. - 在大多數時候,非關系型數據庫是在傳統關系型數據庫基礎上(其實已經基本上完全不同), 在功能上簡化, 在數據存儲結構上大大改變,在效率上提升, 通過減少用不到或很少用的功能,在能力弱化的同時也帶來產品性能的大幅度提高。
- 但是本質上講, 他們都是用來存儲數據的. 而對于我們Java后端開發來講, 我們在工作中基本上是以關系型數據庫為主, 非關系型數據庫為輔的用法.
數據庫的構成
軟件架構
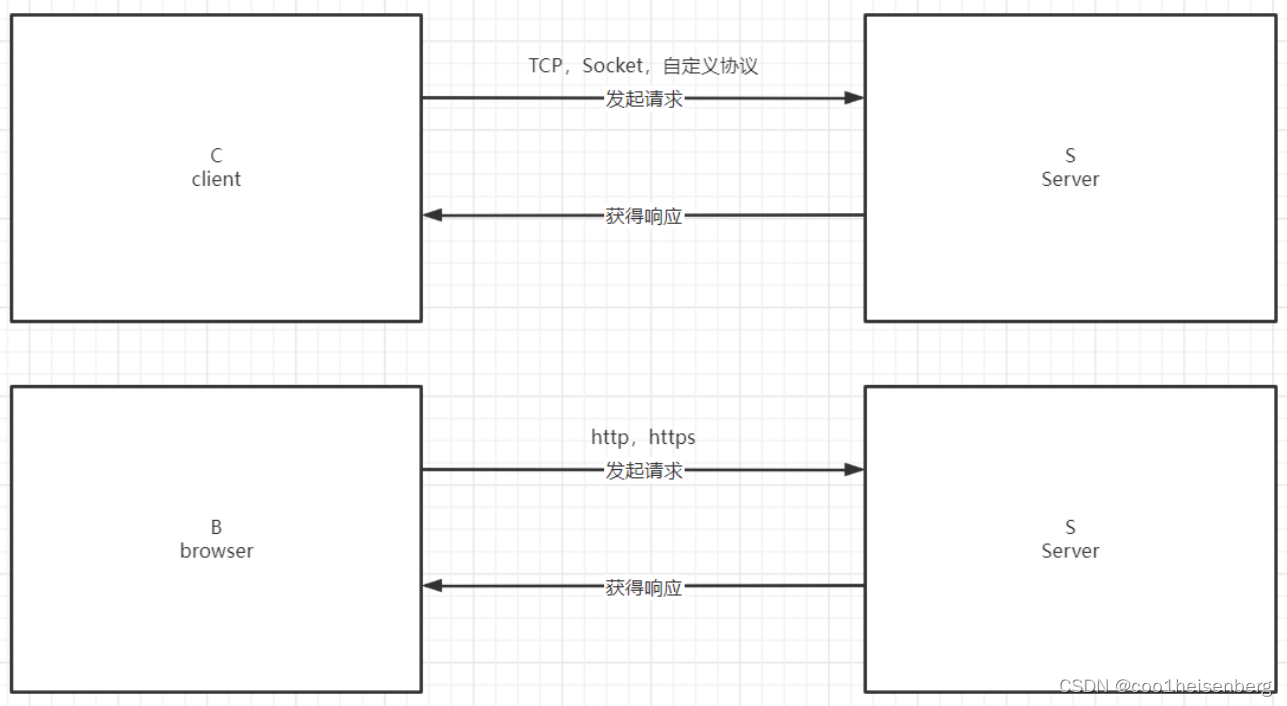
- B/S:Browser-Server即瀏覽器和服務器, 即通過瀏覽器和服務器發起網絡交互的數據請求.
- 常見的B/S架構: 淘寶、京東、拼多多、百度
- C/S:Client-Server即客戶端和服務器, 即通過客戶端和服務器發起網絡交互的數據請求.
- 常見的C/S架構:英雄聯盟、QQ、微信、數據庫、手機app
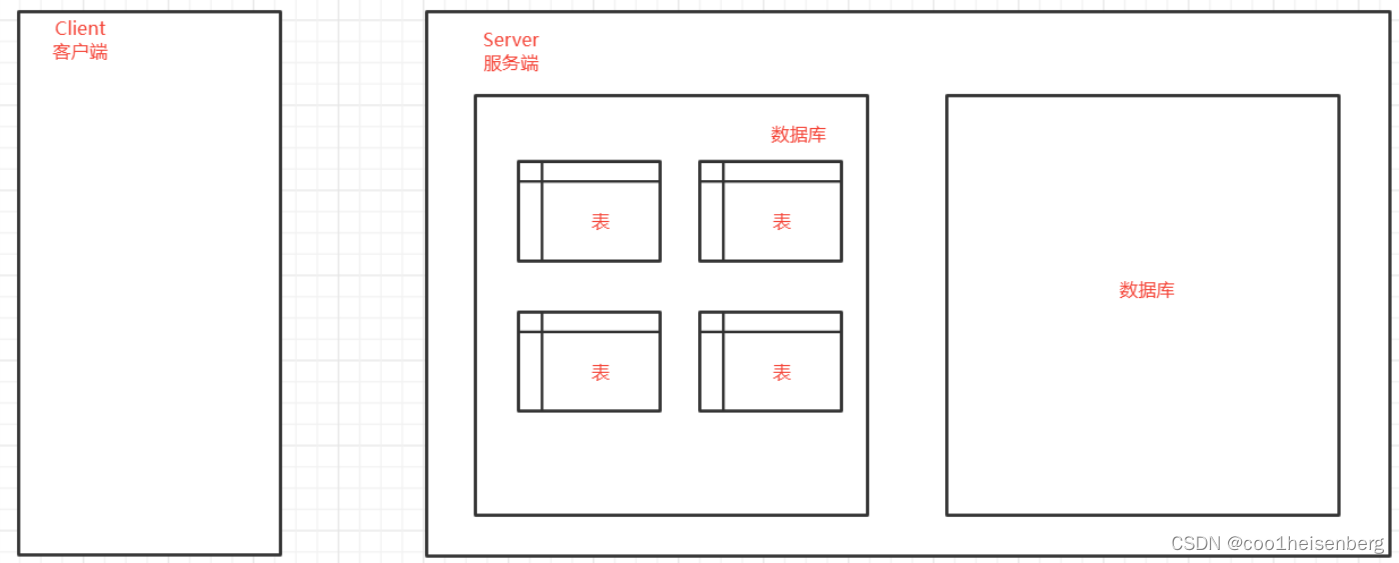
MySQL內部數據組織方式
- 數據庫: 表示一份完整的數據倉庫, 在這個數據倉庫中分為多張不同的表。
- 表:表示某種特定類型數據的的結構化清單, 里面包含多條數據。
- 數據: 表中數據的基本單元。
SQL語言
登錄數據庫
$ mysql -uroot -p
輸入密碼(******)
數據庫操作
查看庫
查看所有的數據庫
show databases;模糊匹配查看相關的數據庫
show databases like "system%";
-- test% 表示以test開頭
-- %info 表示以info結尾
-- %info% 表示info可以出現在任意位置查看當時創建數據庫的命令
show create database test;
-- 查看當時創建數據庫test的命令注釋:
1. 第一種注釋
-- <注釋的內容>
-- 兩個‘-’后面一定要有一個空格2. 第二種注釋
#<注釋的內容>
-- ‘#’后面可以不加空格3. 第三種注釋
/*
<注釋的內容>
*/
注意:
- 不要刪除系統自帶的幾個數據庫
information_schemamysqlperformance_schemasys
創建庫
創建一個數據庫
create database db_test;
-- 注意:創建一個叫 db_test 的數據庫,其中注意:庫名,表名,列名均不區分大小寫
-- 如果要寫庫名為dbTest,則可以把 dbTest 寫成 db_test創建一個數據庫并指定字符集和指定校對規則
create database db_test character set utf8mb4 collate utf8mb4_bin;
-- mysql里面有一個字符集是utf8,但它是假的,是使用1-3個字節來存儲數據,
-- 如果要使用utf8的編碼,應該使用utf8mb4,utf8mb4是4個字節存儲數據-- 校對規則是用來比較大小的
-- _ci(case insensitive 大小寫不敏感)
-- _cs(case sensitive 大小寫敏感)
-- eg:utf8mb4_bin、utf8mb4_general_ci
eg:create database db_test2 character set utf8mb4 collate utf8mb4_ci;-- 如果不指定一個字符集,則一般是默認的 latin1
-- latin1一般是不支持中文的
刪除庫
刪除名稱為db_test的數據庫:
drop database db_test;
修改庫
數據庫中未提供改庫名的操作,只提供修改字符集和校對規則。
修改指定庫的字符集和校對規則:
alter database db_test character set utf8 collate utf8_bin;
數據庫中表的操作
選擇數據庫
選擇指定的數據庫:
use db_test;查看當前在什么庫:
select database();
創建表
- Mysql中大小寫不敏感
- 不要使用數據庫來存儲大文件
- 設計數據庫字段的時候,一定要留有一定的冗余
create table table_name(字段名 字段類型);
-- 括號里面寫有哪些列,以及列類型
eg:
create table test_time(id int, date1 date, time1 timestamp);
create table test_number(id int, float1 float(4,2));
字段類型:
-
數字(整數型)
-
tinyint:1字節。 -
int: 4字節。(直接用) -
bigint: 8字節。
-
-
數字(小數)
float(M,D):4字節。浮點型M:表示最大的長度D:表示小數位最大長度
double(M,D): 8字節。浮點型(直接用)decimal (M, D),dec: 壓縮的“嚴格”定點數M+2 個字節。定點型。- 定點型就是用字符串來存儲的
- eg:
float(4, 2):表示最多存儲4位,小數位數最多2位。- 如果整數位多了,比如存了
100.23,則會報錯 - 如果小數位多了,比如存了
10.233,則會四舍五入,變為10.23
- 如果整數位多了,比如存了
- 如果要存儲貨幣,需要使用
decimal定點數來存,或者是字符串
-
日期
year:年(YYYY)。time: 時分秒(HH:MM:SS)。date: 年月日(YYYY-MM-DD)。(直接用)datetime: 年月日時分秒。(YYYY-MM-DD HH:MM:SS)。- 是用字符串存的,8個字節
timestamp: 年月日時分秒。(YYYY-MM-DD HH:MM:SS)。(直接用)- 是用時間戳存的。存的是從1970-01-01到現在的毫秒數
- 2038年這個時間戳就會用完
- 使用場景:操作/更新的時間
- 寫表的時候默認會寫兩個:
begin_time、update_time
-
字符串
char(M): 定長字符串,設置了長度。- eg:
char(M)代表最長存儲M個長度,如果沒有存到M個長度,會往后面添加空格。取出來的時候,會去掉空格。
- eg:
varchar(M):變長字符串,會用1-2字節來存儲長度。也就是實際長度+1(2)。最大長度65535字節。(直接用)- eg:存儲
'ls',則是實際占用空間加上一個字節來存儲現在的長度
- eg:存儲
text:文本字符串,會用2字節來存儲長度。最大長度65535字節,約64K。longtext:大文本字符串。會使用4字節存儲長度。最大長度2^32,約4G。
寫SQL,就是一個翻譯的過程:
- 需要想好你的表名
- 需要想好要存的所有的數據
- 想好類型、字段名
- 寫SQL
刪除表
刪除名為table_name的表:
drop table table_name;
查看表
查看所有表:
show tables;查看表格結構(有哪些列):
desc table_name;
describe table_name;查看表的創建語句:
show create table table_name;
修改表
不建議工作中修改表
修改表名:
rename table old_table_name to new_table_name;
alter table old_table_name rename to new_table_name;修改表字符集 排序規則:
alter table table_name character set utf8mb4 collate utf8mb4_bin;添加列:
alter table table_name add column column_name column_type;刪除列:
alter table table_name drop column column_name;修改某列的類型:
alter table table_name modify column column_name column_type;
數據庫中數據的操作
添加數據
插入數據
方式1:指定需要插入的列名,values需要與之對應。
insert into table_name (column1, column2, ......) values (value1, value2, ......)方式2:不指定需要插入的列名。values,必須要寫所有value,且與建表語句一一對應
insert into table_name values (value1, value2, ......)方式3:使用set方式
insert into table_name set column1=value1, column2=value2,...;可以插入多行:
insert into table_name values
(value1, value2, ......),(valuem,valuen,......),(valuem,valuen,......);
eg:
指定插入列:
-- 要在values后面寫與之對應的值
-- 插入的類型一定要匹配
insert into student_test(id, name, age, address, remark)
values (1, "lihua", 20, "china", "None");不指定插入的列:
-- 插入列的順序與創建表的時候一致
insert into student_test values (2, "zhangsan", 19, "Asia", "None");-- 插入 一條數據
insert into student_test set id=3,name="mike",age=21,address="china",remark="None";-- 還可以一次插入多行,格式就是 在前面指定的
insert into student_test(id, name, age, address, remark) values
(4, "Jack", 20, "china", "None"), (5, "Bob", 25, "china", "None");
查詢數據
查詢語句:
-- 關鍵詞 select ... from
select * from table_name;-- * 代表選出所有列
-- 也可以寫表中的列,多列使用, 分割
-- 比如 select id,name from students;
-- table_name 是表名
使用where關鍵詞。where相當于是過濾器。
eg:
-- 找出name是 zs 的表記錄
select * from table_name where name='ls';-- 找出年齡大于 18歲的人
select * from table_name where age > 18;
修改數據
寫update語句和delete語句一定要加where條件
更新滿足條件的表記錄,設置列值:
update table_name set column1=value1, column2=value2 [ where 條件];
eg:
update student_test set age = 18 where id = 4;
刪除數據
刪除滿足條件的數據:
delete from table_name [WHERE 條件];
eg:
delete from student_test where id = 5;
特殊關鍵字
where(條件關鍵字)
- 使用
where關鍵字并指定查詢條件|表達式, 從數據表中獲得滿足條件的數據內容 - 在
where后面寫條件,其實就是篩選出符合條件的數據select就是把這些數據篩選出來展示update只更新符合條件的delete只刪除符合條件的
- 使用位置:查詢語句(select)、更新語句(update)、刪除語句(delete)
一些重要的SQL運算符:
- 算數運算符
- 用在
select后面表示我要選擇的數據怎么計算出來的 - 用在
where后面表示篩選數據
- 用在
| 運算符 | 作用 |
|---|---|
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
| % | 取余 |
- 比較和邏輯運算符
| 運算符 | 作用 | 運算符 | 作用 |
|---|---|---|---|
| = | 等于 | <=> | 等于(可比較null) |
| != | 不等于 | <> | 不等于 |
| < | 小于 | > | 大于 |
| <= | 小于等于 | >= | 大于等于 |
| between and | 在閉區間內 | like | 通配符匹配(%:通配, _占位) |
| is null | 是否為null | is not null | 是否不為null |
| in | 不在列表內 | not in | 不在列表內 |
| and | 與 | && | 與 |
| or | 或 | || | 或 |
注:
=不能用來判斷null_只能匹配一次
distinct(過濾關鍵字)
- 獲取某個列的不重復值
- 語法:
select distinct <字段名> from <表名>;- 使用
distinct對數據表中一個或多個字段重復的數據進行過濾,重復的數據只返回其一條數據給用戶。
- 使用
eg:
-- 返回所有的address
select address from student_test;-- 返回不重復的 address
select distinct address from student_test;
limit(限制結果集關鍵字)
select <查詢內容|列等> from <表名字> limit 記錄數目;select <查詢內容|列等> from <表名字> limit 初始位置,記錄數目;select <查詢內容|列等> from <表名字> limit 記錄數目 offset 初始位置;
eg:
-- limit 限制了返回的最大數目
select * from student_test limit 2;-- limit offset number1, number2
-- number1:表示偏移的數量(默認是從0開始的)
-- number2:表示限制的個數
-- 從第2個開始返回,限制返回2個
select * from student_test limit 2 offset 1;
select * from student_test limit 1,2;
as(取別名關鍵字)
as關鍵字用來為表和字段指定別名as可以省略
<內容> as <別名>
eg:
select address as dizhi from student_test;
order by(排序關鍵字)
select <查詢內容|列等> from <表名字> order by <字段名> [asc|desc];
注:
order by對查詢數據結果集進行排序- 不加排序模式: 升序排序(默認)
asc: 升序排序desc: 降序排序
order by也可以按照多個列排序- 如果第一列相同,就按照第二列進行排序。如果第二列相同,則按照第三列進行排序。以此類推
eg:
select * from student_test order by age desc;select * from student_test order by age asc;
group by(分組關鍵字)
- 按照某個、某些字段分組
select <查詢內容|列等> from <表名字> group by <字段名...>
group by后,select中只能寫group by后面的列- 還可以寫一些聚合函數
group_concat()函數會把每個分組的字段值都拼接顯示出來having可以讓我們對分組后的各組數據過濾。(一般和分組+聚合函數配合使用)round(x, d):x 指要處理的數,d 是指保留幾位小數min、max、sum、avg、count
- 當
select后 既有表結構本身的字段,又有需要使用聚合函數(count()、sum()、avg()、max()、min()等)的字段,就要用到group by分組
eg:
select group_concat(name),address from student_test group by address;-->
+--------------------+---------+
| group_concat(name) | address |
+--------------------+---------+
| zhangsan | Asia |
| lihua,mike,Jack | china |
+--------------------+---------+select group_concat(name),age,address from student_test group by age having address = "china";-->
+--------------------+------+---------+
| group_concat(name) | age | address |
+--------------------+------+---------+
| lihua | 20 | china |
| mike | 21 | china |
+--------------------+------+---------+group by的特點:
group by代表分組的意思,把值相同的分到一組select后面的列,只能寫group by后面的列,或者聚合函數- 如果
group by后面有多個列,會首先按照第一個列進行分組,第一個列相同,再按照第二個列進行分組 - 如果
select后面可以看出來是哪一列聚合,group by后面可以寫1 2
eg:select class, count(*) from students group by class;
可以寫成select class, count(*) from students group by 1; where與having的區別:where是原始數據進行過濾having是分組之后進行過濾
聚合函數
聚合函數一般用來計算列相關的指定值. 通常和分組一起使用
| 函數 | 作用 | 函數 | 作用 |
|---|---|---|---|
| count | 計數 | sum | 和 |
| avg | 平均值 | max | 最大值 |
| min | 最小值 |
count(*)與count(column_name)的區別:
count(*):純粹計算有多少行count(column_name):計算非null的行數
SQL語句的執行順序
- SQL語句的關鍵字是有順序的,需要按照下面的順序來寫
select column_name, ... from table_name, ...
[where ...][group by ...][having ...][order by ...][limit ...](5) SELECT column_name, ...:標識出來篩選的列 (1) FROM table_name, ...:打開表 (2) [WHERE ...]:過濾 (3) [GROUP BY ...]:分組 (4) [HAVING ...]:對分組后的數據進行篩選 (6) [ORDER BY ...]:對數據進行排序(7) [Limit ...]:限制



)





-OpenGL)
)

)






