一、為什么要對模型進行評估?
對機器學習和神經網絡的模型進行評估是至關重要的,原因如下:
- 得知模型的泛化能力
????????模型評估的主要目的是了解模型在未見過的數據上的表現,即其泛化能力。這是因為模型的性能在訓練數據上可能會過擬合,即模型過于復雜以至于學習了訓練數據中的噪聲,而不是學習到了真正的底層規律。通過評估,我們可以確保模型具有強大的泛化能力,能夠在新的、未見過的數據上表現出色。
- 提供模型選擇依據
????????在機器學習中,通常會有多種模型可供選擇,如線性回歸、決策樹、支持向量機、神經網絡等。通過對這些模型進行評估,我們可以比較它們的性能,從而選擇最適合特定任務的模型。
- 調整模型參數
????????模型評估還可以幫助我們找到最佳的模型參數。通過調整模型的參數,我們可以觀察模型性能的變化,從而找到最優的參數組合。這對于提高模型的性能至關重要。
- 防止過擬合與欠擬合
????????通過模型評估,我們可以發現模型是否出現過擬合或欠擬合的情況。如果模型在訓練數據上表現良好,但在測試數據上表現不佳,那么可能是出現了過擬合。相反,如果模型在訓練數據上表現不佳,那么可能是出現了欠擬合。這兩種情況都需要我們對模型進行調整。
二、從數據劃分的角度進行模型評估的常用方法
(1)留出法
????????將原始數據集劃分為訓練集和測試集,用訓練集訓練模型,然后用測試集評估模型的性能。這是最簡單、最常用的評估方法。通常劃分比例是70%-30%,或者80%-20%等。
????????然而,留出法的一個缺點是它只能給出模型在測試集上的性能估計,而不能給出模型在所有可能數據上的性能。
(2)交叉驗證法
????????將原始數據集劃分為k個子集,每次選擇k-1個子集作為訓練集,剩下的一個子集作為測試集,進行k次訓練和測試,最終得到k個測試結果的平均值作為模型的性能估計。其中最常見的形式是10折交叉驗證,即k=10。
????????交叉驗證法可以有效地利用數據集,減少數據浪費,并且可以得到更穩定的性能估計。
三、舉例說明
(1)多項式回歸模型的選擇
? ? ? ? 當你想進行一個回歸任務,訓練出的模型是一個多項式函數,那么這樣的模型就被稱為多項式模型,他有一些優缺點:
- 多項式回歸的優點是可以更好地擬合復雜的、非線性的數據模式。
- 其缺點是可能引入過擬合問題,尤其在n(多項式的最高次冪)較大時,即模型過于復雜,無法泛化到新的數據。
?那么問題來了,選擇怎樣次數的多項式模型才能得到最好的泛化結構呢?
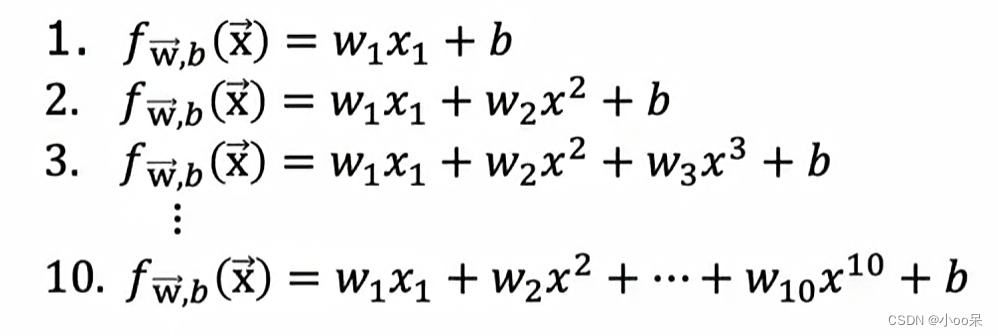
?一定是次數n越高越好嗎?未必,因為n較大時可能會出現過擬合現象:
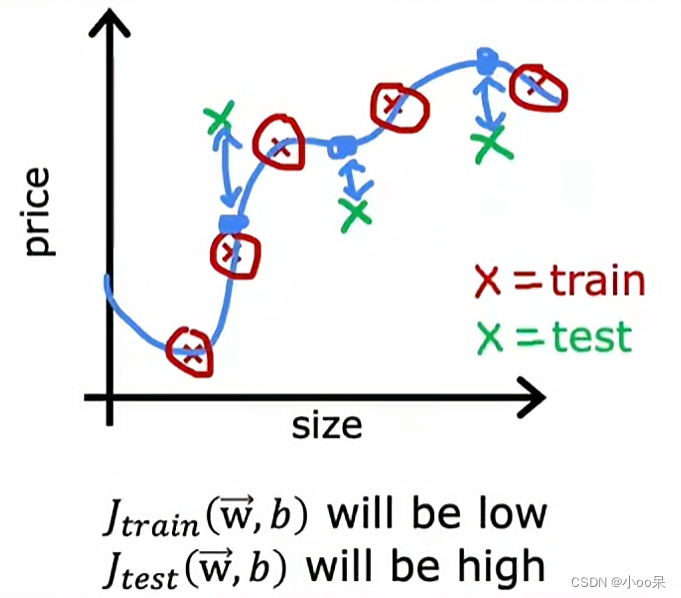
?這時候的解決方法是,是驗證集對模型進行評估,在這個例子里我們可以使用均方誤差損失函數。具體的做法:
- 步驟一:先用訓練集訓練模型(這里已經訓練了10個不同n的模型)
- 步驟二:用驗證集驗證模型,取均方誤差最小的模型(假如最好的是n=4)
- 步驟三:用測試集對n=4的多項式模型進行測試,評估出它的泛化能力。
四、從評價指標的角度進行模型評估的常用方法
- 對于回歸問題:MSE(均方誤差)、MAE (平均絕對誤差)、RMSE (均方根誤差)等。
- 對于分類問題:Accuracy (準確率)、Precision (精確率)、Recall (召回率)、AUC (ROC曲線下的面積)等。
更多對模型評價指標的講解,我會單獨出一篇文章來說明哦!








)


,Lab: Copy-on-Write Fork)
)






