目錄
- Task: Implement copy-on write
- step 1:對內存塊進行引用計數
- step 2:`uvmcopy` 實現 fork 時將 parent 的物理頁映射到 child 中
- step 3:在 `usertrap` 中增加對 page fault 的處理
- 執行測試
官方說明:Lab: Copy-on-Write Fork for xv6
這個實驗是利用 page fault 實現操作系統的 Copy-On-Write 功能(COW)。
COW 的意思是說,當 fork 時,子進程不會完全拷貝父進程的整個內存空間,而是與父進程共享同一份物理內存,并在 page table 中記錄映射關系,當任意一個進程需要寫某塊內存時,會發生 page fault,page fault handler 會真正分配出一塊新的內存并重新建立映射,從而節省了大量的內存拷貝。
通過這個 lab,對 COW 有了更深的了解。
Task: Implement copy-on write
這個 task 的要求是實現 COW,并通過 cowtest 和 usertests。
step 1:對內存塊進行引用計數
由于多個進程可能會共享同一份物理內存,因此像 kfree() 這類函數不能隨意釋放一個物理內存,而是需要借助引用計數來決定能否真正釋放物理內存,所以我們需要實現對每個物理內存塊的引用計數。
在 kalloc.c 文件中,我們模仿 kmem 結構體寫一個 kref,用來對每個內存塊進行引用計數:
struct {struct spinlock lock;int counts[PHYSTOP / PGSIZE];
} kref;
在 kinit() 對 kref 進行初始化:
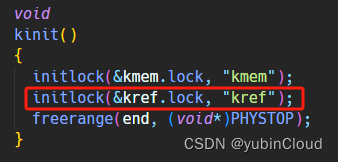
更改引用計數的函數:
// 增加對某個物理地址的引用計數
void
kref_inc(uint64 pa)
{acquire(&kref.lock);kref.counts[pa / PGSIZE]++;release(&kref.lock);
}// 減少對某個物理地址的引用計數
void
kref_dec(uint64 pa)
{acquire(&kref.lock);kref.counts[pa / PGSIZE]--;release(&kref.lock);
}// 獲取某個物理地址的引用計數
int
kref_count(uint64 pa)
{int count;acquire(&kref.lock);count = kref.counts[pa / PGSIZE];release(&kref.lock);return count;
}
然后修改 kalloc(),當新分配一個物理內存塊時,其引用計數應當為 1:
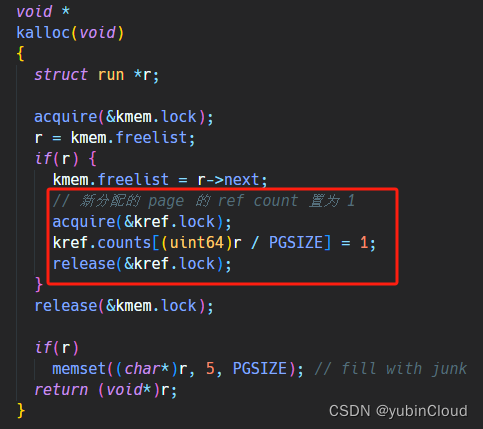
然后是修改 kfree() 函數,當通過 kfree 想釋放一個內存塊時,需要檢查這個內存塊的引用計數,如果存在多個引用,只需要對引用計數 -1 即可,只有當沒有更多進程引用這個內存塊時,才能真正釋放它:
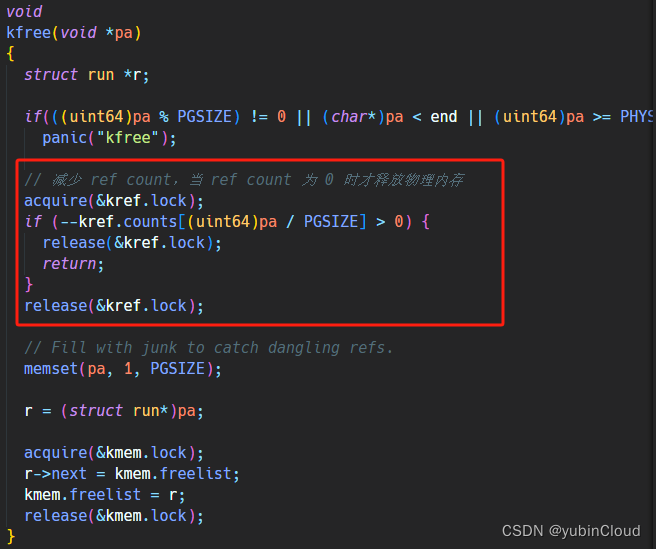
step 2:uvmcopy 實現 fork 時將 parent 的物理頁映射到 child 中
調用 fork 時,會使用 uvmcopy 來克隆一份 parent 的物理內存空間給 child,而我們為了實現 COW,在這里只需要共享同一個物理內存。
具體的做法就是,遍歷 parent 的整個內存空間,將其物理地址封裝成 PTE 放入 child 的 page table 中,同時需要將 parent 和 child 的 PTE 都改為只讀的,這樣之后任一進程在 write 時能夠發生 page fault 并進而完成實際的內存分配。
除了 PTE 需要設置為只讀的,還需要在 PTE 標記一下這是一個 COW page,從而與普通的只讀 page 進行區分,為此,需要使用 PTE 中的預留位作為 COW 標志位:
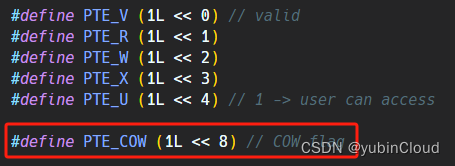
修改 uvmcopy:
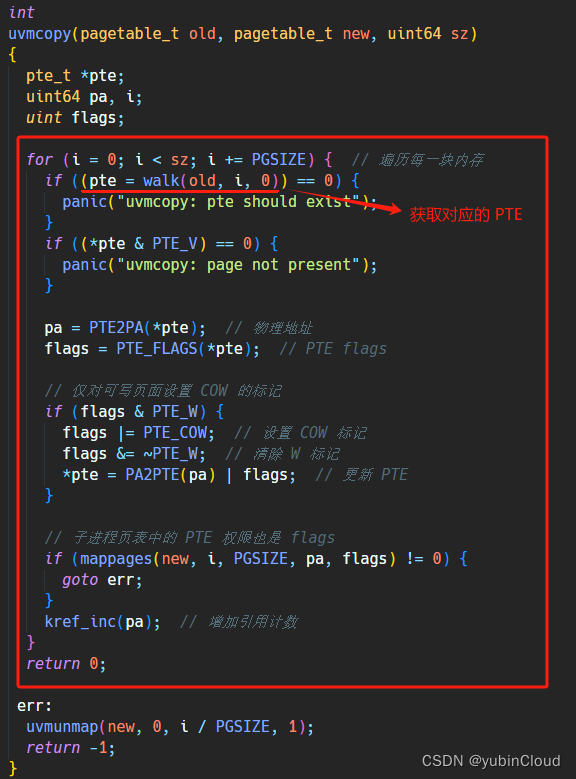
這一塊代碼對原有拷貝整個內存空間的代碼進行改造,實現遍歷整個內存空間,并獲取每塊內存的 PTE 和物理地址,對 PTE 的 flags 做了修改后,再將其添加到 child 的 page table 中。另外注意,需要增加對物理內存的引用計數,因為這里每個內存增加了一個 child 進行對其的引用。
step 3:在 usertrap 中增加對 page fault 的處理
當一個被標為 COW 的只讀 page 發生 page fault 時,我們需要對其進行 COW 的處理,為其分配一份新的物理內存,并修改 page table 中的映射,這樣當 page fault 被處理并恢復正常流程后,就可以對內存進行 write 了。
首先我們需要一個函數來判斷一個 page 是否為 COW page:
// 判斷是否為 cow page
// 是的話返回 1,否則返回 0
int is_cowpage(pagetable_t pagetable, uint64 va){if (va >= MAXVA)return 0;pte_t *pte = walk(pagetable, va, 0);if(pte == 0)return 0;if ((*pte & PTE_V) == 0)return 0;return (*pte & PTE_COW) != 0;
}
另外我們將處理 COW 導致的 page fault 的邏輯封裝為函數 handle_cow():
void* handle_cow(pagetable_t pagetable, uint64 va){va = PGROUNDDOWN(va);pte_t *pte = walk(pagetable, va, 0);if(pte == 0)return 0;uint64 pa = PTE2PA(*pte);if (pa == 0)return 0;// 根據 ref count 判斷是否需要分配新的物理頁if (kref_count(pa) == 1) {// 如果只存在一個引用,則直接修改 PTE 的 flags 并返回即可*pte |= PTE_W; // 增加 PTE 的寫權限*pte &= ~PTE_COW; // 清除 PTE 的 COW 標志return (void*)pa;}// 如果存在多個引用,則需要分配新的物理頁并拷貝舊頁面內容char *mem = kalloc(); // 分配物理內存if (mem == 0) {return 0;}memmove(mem, (void*)pa, PGSIZE); // 拷貝舊頁面內容// 修改 va 的 mapping*pte = PA2PTE(mem) | ((PTE_FLAGS(*pte) | PTE_W) & (~PTE_COW));// 將舊物理頁的 ref count 減一kfree((void*)pa);return mem;
}
這里的易錯點:
- 我們需要通過物理頁的 ref count 來決定處理 COW page fault 時,是否需要分配一個新的物理頁,因為當被標為 COW page 時,是兩個及以上的進程來共享同一個物理 page,當隨著有些進程因為 COW page fault 而創建了新的內存塊而減少 ref count,直到當 ref count 為 1 時,發生 COW page fault 的進程就不再需要分配新的物理頁,而是直接將之前的物理頁恢復可寫的 flag 即可。
- 修改 PTE 的 flags 時,注意不要出錯
有了這兩個函數,我們就可以在 usertrap() 中增加對 page fault 的處理邏輯:
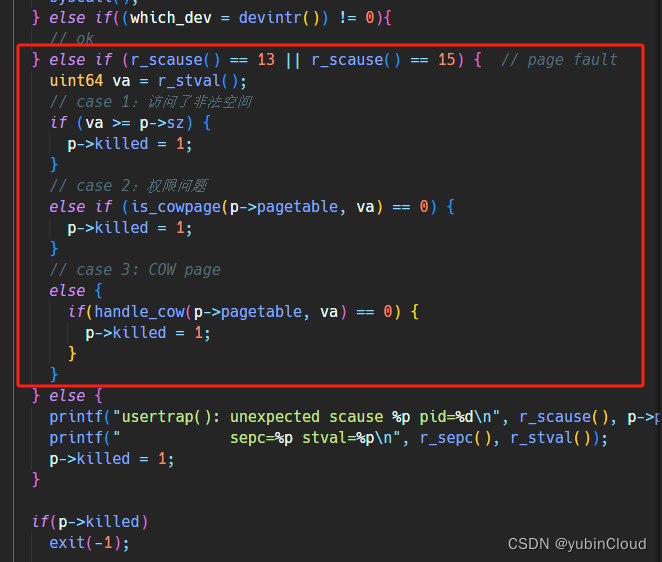
在發生 page fault 時,會有三種可能:
- 訪問了非法內存頁
- 內存頁合法,但是權限不合適(比如在不可執行的 page 上執行指令等)
- 在 COW 的只讀 page 上執行 write 操作。這也是我們唯一能處理并恢復的 page fault。
完成以上修改后,這個實驗就完成了。
執行測試
make qemu 后分別執行 cowtest 和 usertests:
測試通過~
)


















