使用GPTQ進行4位LLM量化
- 最佳腦量化
- GPTQ算法
- 步驟1:任意順序洞察
- 步驟2:延遲批量更新
- 第三步:喬爾斯基重塑
- 用AutoGPTQ量化LLM
- 結論
- References
權重量化的最新進展使我們能夠在消費級硬件上運行大量大型語言模型,例如在RTX 3090 GPU上運行LLaMA-30B模型。這要歸功于性能降低最小的4-bit量化技術,如GPTQ、GGML和NF4。
在上一篇文章中,我們介紹了na?ve 8位量化技術和優秀的LLM.int8()。在本文中,我們將探討流行的GPTQ算法,以了解它是如何工作的,并使用AutoGPTQ庫實現它。
最佳腦量化
讓我們從介紹我們試圖解決的問題開始。對于網絡中的每個層 l l l,我們希望找到原始權重 W l W_l Wl?的量化版本 W l ^ \hat{W_l} Wl?^?。這被稱為 layer-wise 壓縮問題。更具體地說,為了最大限度地減少性能下降,我們希望這些新權重的輸出 W l ^ X l \hat{W_l}X_l Wl?^?Xl?盡可能接近原始權重 W l X l W_lX_l Wl?Xl?。換句話說,我們想找到:

已經提出了不同的方法來解決這個問題,但我們在這里感興趣的是最優腦量化(OBQ)框架。
這種方法的靈感來自一種修剪技術,從訓練后的密集神經網絡(Optimal Brain Surgeon)中仔細去除權重。它使用近似技術,并提供最佳單權重 w q w_q wq? 去刪除和優化更新 δ F δ_F δF?,以調整剩余的非量化權重 F F F ,以彌補去除:

其中 quant(w) 是 quantization 給出的權重四舍五入, H F H_F HF? 是Hessian。
使用OBQ,我們可以首先量化最簡單的權重,然后調整所有剩余的非量化權重來補償這種精度損失。然后我們選擇下一個權重來量化,以此類推。
這種方法的一個潛在問題是,當存在離群值權重時,可能導致高量化誤差。通常,這些離群值最后會被量化,此時剩下的非量化權重很少,可以調整以補償較大的誤差。當一些權重被中間更新推到網格之外時,這種效果可能會惡化。一個簡單的啟發式應用來防止這種情況:異常值一出現就被量化。
這個過程可能需要大量的計算,特別是對于LLMs。為了解決這個問題,OBQ方法使用了一種技巧,避免在每次簡化權重時重新進行整個計算。量化權重后,它通過刪除與該權重相關的行和列(使用高斯消去)來調整計算中使用的矩陣(Hessian矩陣)。

該方法還采用向量化的方法,一次處理多行權矩陣。盡管OBQ的效率很高,但隨著權值矩陣的增大,OBQ的計算時間也會顯著增加。這種三次增長使得在具有數十億個參數的非常大的模型上使用OBQ變得困難。
GPTQ算法
由Frantar等人(2023)引入的GPTQ算法從OBQ方法中獲得靈感,但進行了重大改進,可以將其擴展到(非常)大的語言模型。
步驟1:任意順序洞察
OBQ方法按照一定的順序選擇權重(模型中的參數)進行量化,這取決于哪個順序添加的額外誤差最小。然而,GPTQ觀察到,對于大型模型,以任何固定順序量化權重都可以達到同樣的效果。這是因為即使一些權重可能單獨引入更多的誤差,但在稍后的過程中,當剩下的其他可能增加誤差的權重很少時,它們也會被量化。所以順序并不像我們想象的那么重要。
基于這種見解,GPTQ旨在以相同的順序對矩陣的所有行量化所有權重。這使得計算過程更快,因為某些計算只需要對每一列執行一次,而不是對每個權重執行一次。

步驟2:延遲批量更新
這個方案不會很快,因為它需要更新一個巨大的矩陣,每個條目的計算量很少。這種類型的操作不能充分利用gpu的計算能力,并且會因內存限制(內存吞吐量瓶頸)而減慢速度。
為了解決這個問題,GPTQ引入了延遲批處理更新。結果表明,給定列的最終舍入決策僅受對該列執行的更新的影響,而不受對后面列執行的更新的影響。因此,GPTQ可以一次將算法應用于一批列(如128列),僅更新這些列和矩陣的相應塊。在一個塊被完全處理后,算法對整個矩陣執行全局更新。
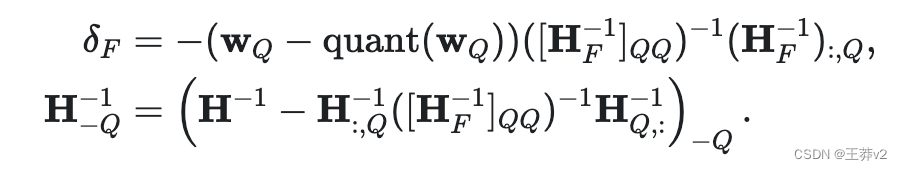
第三步:喬爾斯基重塑
然而,還有一個問題需要解決。當算法擴展到非常大的模型時,數值不精確可能成為一個問題。具體地說,某一操作的重復應用會累積數值誤差。
為了解決這個問題,GPTQ使用了Cholesky分解,這是一種用于解決某些數學問題的數值穩定方法。它涉及使用Cholesky方法從矩陣中預先計算一些所需的信息。這種方法與輕微的阻尼(向矩陣的對角線元素添加一個小常數)相結合,有助于算法避免數值問題。
整個算法可以總結為幾個步驟:
- GPTQ算法從Hessian逆(一個幫助決定如何調整權重的矩陣)的Cholesky分解開始,
- 然后循環運行,一次處理一批列。
- 對于批處理中的每一列,它量化權重,計算誤差,并相應地更新塊中的權重。
- 處理完批處理后,它根據塊的錯誤更新所有剩余的權重。
GPTQ算法在各種語言生成任務上進行了測試。比較了其他量化方法,如將所有權重四舍五入到最接近的量化值(RTN)。GPTQ與BLOOM (176B參數)和OPT (175B參數)模型族一起使用,模型使用單個NVIDIA A100 GPU進行量化。
用AutoGPTQ量化LLM
GPTQ在創建4-bit精度的模型時非常流行,可以有效地在gpu上運行。你可以在Hugging Face Hub找到很多例子,尤其是TheBloke。如果您正在尋找一種對cpu更友好的方法,那么GGML目前是您的最佳選擇。最后,帶bitsandbytes的transformer庫允許您在加載模型時使用loadin 4bit=true參數量化模型,這需要下載完整的模型并將其存儲在RAM中。
讓我們使用AutoGPTQ庫實現GPTQ算法,并量化GPT-2模型。這需要一個GPU,但谷歌Colab上的免費T4就可以了。我們首先加載庫并定義我們想要量化的模型(在本例中是GPT-2)。
!BUILD_CUDA_EXT=0 pip install -q auto-gptq transformers
import randomfrom auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from datasets import load_dataset
import torch
from transformers import AutoTokenizer# Define base model and output directory
model_id = "gpt2"
out_dir = model_id + "-GPTQ"
現在我們想要加載模型和標記器。該標記器是使用transformer庫中的經典AutoTokenizer類加載的。另一方面,我們需要傳遞一個特定的配置(BaseQuantizeConfig)來加載模型。
在這個配置中,我們可以指定要量化的位數(這里,bits=4)和組大小(惰性批處理的大小)。注意,這個組的大小是可選的:我們也可以為整個權重矩陣使用一組參數。在實踐中,這些組通常以非常低的成本提高量化的質量(特別是當組大小=1024時)。阻尼百分比值在這里是為了幫助Cholesky重新配方,不應該改變。
最后,desc act(也稱為act order)是一個棘手的參數。它允許您根據激活的減少來處理行,這意味著首先處理最重要或最有影響的行(由采樣的輸入和輸出決定)。該方法旨在將大部分量化誤差(在量化過程中不可避免地引入)放在不太重要的權重上。這種方法通過確保以更高的精度處理最重要的權重,提高了量化過程的總體準確性。然而,當與組大小一起使用時,desc act可能導致性能變慢
# Load quantize config, model and tokenizer
quantize_config = BaseQuantizeConfig(bits=4,group_size=128,damp_percent=0.01,desc_act=False,
)
model = AutoGPTQForCausalLM.from_pretrained(model_id, quantize_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
量化過程在很大程度上依賴于樣本來評估和提高量化質量。它們提供了一種比較原始模型和新量化模型產生的輸出的方法。提供的樣本數量越多,就越有可能進行更準確和有效的比較,從而提高量化質量。
在本文中,我們使用C4 (Colossal Clean crawl Corpus)數據集來生成我們的樣本。C4數據集是一個大規模的、多語言的網絡文本集合,收集自Common Crawl項目。這個擴展的數據集已經經過清理,并專門為訓練大規模語言模型而準備,使其成為此類任務的重要資源。WikiText數據集是另一個流行的選擇。
在下面的代碼塊中,我們從C4數據集加載1024個樣本,對它們進行標記并格式化。
# Load data and tokenize examples
n_samples = 1024
data = load_dataset("allenai/c4", data_files="en/c4-train.00001-of-01024.json.gz", split=f"train[:{n_samples*5}]")
tokenized_data = tokenizer("\n\n".join(data['text']), return_tensors='pt')# Format tokenized examples
examples_ids = []
for _ in range(n_samples):i = random.randint(0, tokenized_data.input_ids.shape[1] - tokenizer.model_max_length - 1)j = i + tokenizer.model_max_lengthinput_ids = tokenized_data.input_ids[:, i:j]attention_mask = torch.ones_like(input_ids)examples_ids.append({'input_ids': input_ids, 'attention_mask': attention_mask})
WARNING:datasets.builder:Found cached dataset json (/root/.cache/huggingface/datasets/allenai___json/allenai--c4-6e494e9c0ee1404e/0.0.0/8bb11242116d547c741b2e8a1f18598ffdd40a1d4f2a2872c7a28b697434bc96)
Token indices sequence length is longer than the specified maximum sequence length for this model (2441065 > 1024). Running this sequence through the model will result in indexing errors
%%time# Quantize with GPTQ
model.quantize(examples_ids,batch_size=1,use_triton=True,
)# Save model and tokenizer
model.save_quantized(out_dir, use_safetensors=True)
tokenizer.save_pretrained(out_dir)
CPU times: user 4min 35s, sys: 3.49 s, total: 4min 39s
Wall time: 5min 8s('gpt2-GPTQ/tokenizer_config.json','gpt2-GPTQ/special_tokens_map.json','gpt2-GPTQ/vocab.json','gpt2-GPTQ/merges.txt','gpt2-GPTQ/added_tokens.json','gpt2-GPTQ/tokenizer.json')
像往常一樣,可以使用AutoGPTQForCausalLM和AutoTokenizer類從輸出目錄加載模型和tokenizer。
device = "cuda:0" if torch.cuda.is_available() else "cpu"# Reload model and tokenizer
model = AutoGPTQForCausalLM.from_quantized(out_dir,device=device,use_triton=True,use_safetensors=True,
)
tokenizer = AutoTokenizer.from_pretrained(out_dir)
讓我們檢查一下模型是否正常工作。AutoGPTQ模型(大多數情況下)作為普通的變壓器模型工作,這使得它與推理管道兼容,如下面的示例所示
from transformers import pipelinegenerator = pipeline('text-generation', model=model, tokenizer=tokenizer)
result = generator("I have a dream", do_sample=True, max_length=50)[0]['generated_text']
print(result)
The model 'GPT2GPTQForCausalLM' is not supported for text-generation. Supported models are ['BartForCausalLM', 'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM', 'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM', 'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM', 'ErnieForCausalLM', 'FalconForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM', 'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MusicgenForCausalLM', 'MvpForCausalLM', 'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PLBartForCausalLM', 'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'ReformerModelWithLMHead', 'RemBertForCausalLM', 'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM', 'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'XGLMForCausalLM', 'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM', 'XLNetLMHeadModel', 'XmodForCausalLM'].
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
I have a dream," she told CNN last week. "I have this dream of helping my mother f
更深入的評估將需要測量量化模型與原始模型的 perplexity。但是,我們將其排除在本文的范圍之內。
結論
在本文中,我們介紹了GPTQ算法,這是一種在消費級硬件上運行llm的最先進的量化技術。我們展示了它是如何解決分層壓縮問題的,它基于一種改進的OBS技術,具有任意順序洞察力、延遲批處理更新和Cholesky重構。這種新穎的方法顯著降低了內存和計算需求,使LLM能夠被更廣泛的受眾所接受。
此外,我們在一個空閑的T4 GPU上量化了我們自己的LLM模型,并運行它來生成文本。你可以在huggingFace Hub上推送你自己版本的GPTQ 4-bit 量化模型。正如在介紹中提到的,GPTQ不是唯一的4-bit量化算法:GGML和NF4是很好的替代算法,但作用域略有不同。
References
- B. Hassibi, D. G. Stork and G. J. Wolff, “Optimal Brain Surgeon and general network pruning,” IEEE International Conference on Neural Networks, San Francisco, CA, USA, 1993, pp. 293-299 vol.1, doi: 10.1109/ICNN.1993.298572.
- Elias Frantar, Sidak Pal Singh, & Dan Alistarh. (2023). Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, & Dan Alistarh. (2023). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, & Peter J. Liu. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- https://mlabonne.github.io/blog/posts/4_bit_Quantization_with_GPTQ.html#conclusion














查詢性能Top SQL)




:SpringBoot介紹)