
這張圖片展示了一種如何更好地引導大語言模型進行編程的方法。
首先,最簡單也是最有效的方法是讓大語言模型重復運行多次,每次增加一些額外的信息,直到獲得想要的結果。這種方法雖然簡單,但可能需要多次嘗試才能得到滿意的結果。
為了提高效率,可以采用微調提示詞的方法,即逐步增加提示詞的數量和復雜性,以引導模型生成更準確的代碼。例如,可以使用Few-shot提示優化,增加示例數量和示例多樣性,以提高模型的性能。此外,還可以采用復現提示策略,將復雜的編程任務分解成多個簡單的子任務,讓模型逐步完成。
為了進一步提高模型的編程能力,可以采用LTM提示法,將編程任務分解成三個階段:說明編程背景、函數功能和返回結果格式。每個階段都提供詳細的提示,幫助模型理解編程任務的要求。
此外,還可以利用大語言模型的自我一致性,即讓模型自己檢查自己的輸出結果。這可以通過構建模型自查流程來實現,讓模型自己審查自己的輸出結果。這樣可以提高模型的編程質量,減少錯誤的發生。
最后,還可以采用多子模型微調和模型微調的方法,針對特定的編程任務進行微調,以提高模型的性能。

這張圖片是一個思維導圖,展示了基于大語言模型的高效開發流程的三個階段。每個階段都有其特定的核心變化和工作內容。
在階段一,人工為主,大語言模型輔助開發。此時的人工工作包括產品需求梳理、功能實現方案、項目管理方法、核心代碼編寫和功能測試等。而大語言模型則輔助回答技術相關問題、輔助編寫代碼提交給人工審核。
在階段二,人工和大語言模型配合完成開發。此時的人工工作包括需求梳理、代碼編寫和自動測試,而大模型的工作則包括功能開發自動化。
在階段三,大語言模型為主,人工引導大語言模型來高效完成開發任務。此時人的工作是引導模型理解人類需求、創建自動化流程,而大模型的工作則是理解和實現人類需求、理解并自動創建外部函數流。
相比于階段二,階段三的核心變化在于將基本的項目管理工作交給大語言模型來執行,向大語言模型傳遞開發項目的管理流程和意圖,并引導大語言模型完成一個類似的開發項目,在各開發項目執行時不斷優化項目管理流程。通過這種方式,能夠引導Chat模型理解流程并自動進行項目管理,包括自行Debug、分級錯誤匯報、提示庫優化、自動執行代碼本地管理等工作。

這張圖片展示了一個采用LTM提示流程來編寫Python函數的過程。
首先,用戶提出需求,例如“請幫我查一下我的Gmail郵箱中總共有多少封郵件”。
接著,根據用戶需求創建一個Prompt,如“請幫我編寫一個Python函數,用于查看我的Gmail郵箱中總共有多少封郵件,函數要求如下……”。
然后,使用Few-shot學習,得到函數創建所需的代碼提示。根據提示,可以創建一個名為`retrieve_emails`的函數,它接受一個參數`n`和一個默認值為`"me"`的`user_id`參數。
在函數創建過程中,需要拆解問題找出用戶需求中的變量,得到子問題的答案,并將原問題和子問題的答案帶入函數創建。在這個例子中,函數創建后的代碼如下:
```python
def retrieve_emails(n, user_id="me"):
? ? # 函數的具體實現代碼
```
最后,將函數創建完成后,用戶可以使用這個函數來滿足他們的需求。
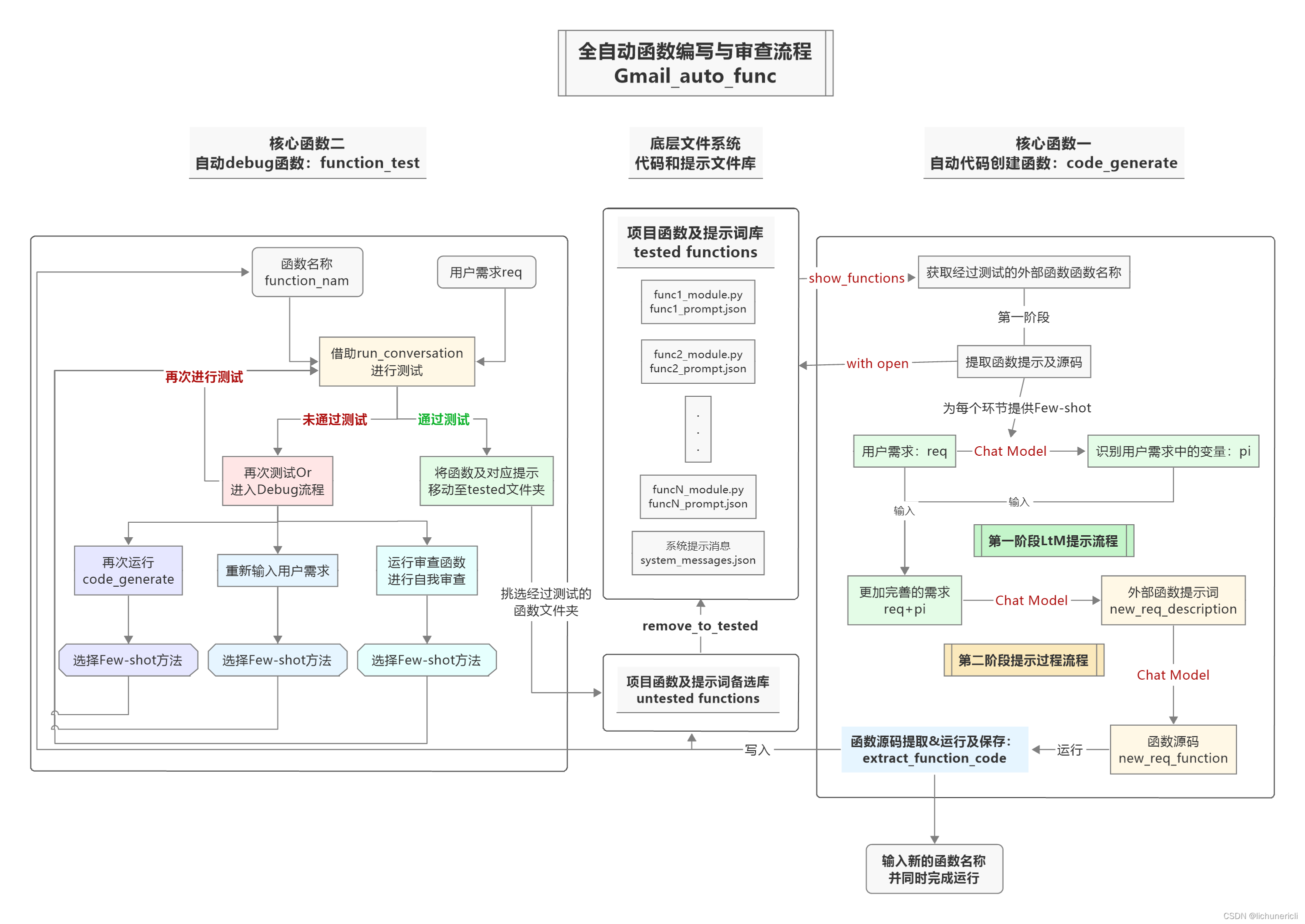
這張圖片描述了一個全自動化函數編寫與審查的流程,主要分為三個核心部分:
1. 核心函數一:自動代碼創建函數`code_generate`,它負責根據用戶的需求生成函數源代碼。
2. 核心函數二:自動debug函數`function_test`,它負責對生成的函數進行測試和調試,確保其通過測試。
3. 底層文件系統代碼和提示文件庫,包括`tested_functions`和`untested_functions`兩個文件夾,分別存放經過測試的函數及其提示信息,以及未經過測試的函數及其提示信息。
在實際操作中,用戶首先需要提供函數名稱`function_name`和用戶需求`req`,然后通過`run_conversation`進行測試。如果測試未通過,則可以選擇重新輸入用戶需求,或者進入Debug流程。如果測試通過,則將函數及其對應的提示移動至`tested_functions`文件夾中。
在第一階段的LSTM提示流程中,用戶需求`req`被識別為變量`pi`,并作為外部函數提示詞`new_req_description`的一部分。在第二階段的提示過程中,通過`extract_function_code`函數獲取函數源代碼,并運行新的`new_req_function`函數。
在流程的最后,用戶需要輸入新的函數名稱,并同時完成運行。
)

、選擇器、事件、動畫)
)
![[滲透教程]-013-嗅探工具-wireshark操作](http://pic.xiahunao.cn/[滲透教程]-013-嗅探工具-wireshark操作)



(std::tuple)(二))
)









