
前言:Hello大家好,我是小哥談。YOLOv8是一種目標檢測算法,它是YOLO(You Only Look Once)系列算法的第8個版本。YOLOv8相比于之前的版本,在檢測精度和速度上都有所提升,它在各種場景下都表現出色,特別適用于實時目標檢測、視頻分析和無人駕駛等領域。為了讓大家更好地了解和應用YOLOv8算法,本節課就帶領大家對其項目目錄結構進行詳細解析!~🌈 ?
? ? ?目錄
🚀1. 官方源碼
🚀2. .github
🚀3. docker
🚀4. docs
🚀5. examples
🚀6. test
🚀7.?ultralytics(重點)
🍀(1)assets
🍀(2)cfg
🍀(3)data
🍀(4)engine
🍀(5)hub
🍀(6)models
🍀(7)nn
🍀(8)solutions
🍀(9)trackers
🍀(10)utils
🚀8. 其他文件

🚀1. 官方源碼
YOLOv8是一種目標檢測算法,它是YOLO(You Only Look Once)系列算法的第8個版本。YOLOv8采用了一種單階段的檢測方法,可以實時地在圖像或視頻中檢測出多個目標物體的位置和類別。相比于傳統的兩階段檢測方法,YOLOv8具有更快的速度和更高的實時性。
YOLOv8的核心思想是將目標檢測任務轉化為一個回歸問題,通過在圖像上劃分網格,并在每個網格上預測邊界框和類別概率來實現目標檢測。YOLOv8使用了Darknet作為基礎網絡,并引入了一些改進措施,如使用更深的網絡結構、使用更多的卷積層和殘差連接等,以提高檢測性能。
YOLOv8相比于之前的版本,在檢測精度和速度上都有所提升。它在各種場景下都表現出色,特別適用于實時目標檢測、視頻分析和無人駕駛等領域。?
YOLOv8官方源碼地址:GitCode - 開發者的代碼家園
在官方網站下載源碼之后,放在項目文件夾中,用PyCharm打開呈現頁面如下所示:👇

可以清晰的看到,頁面左邊即為項目目錄結構。目錄結構如下所示:?
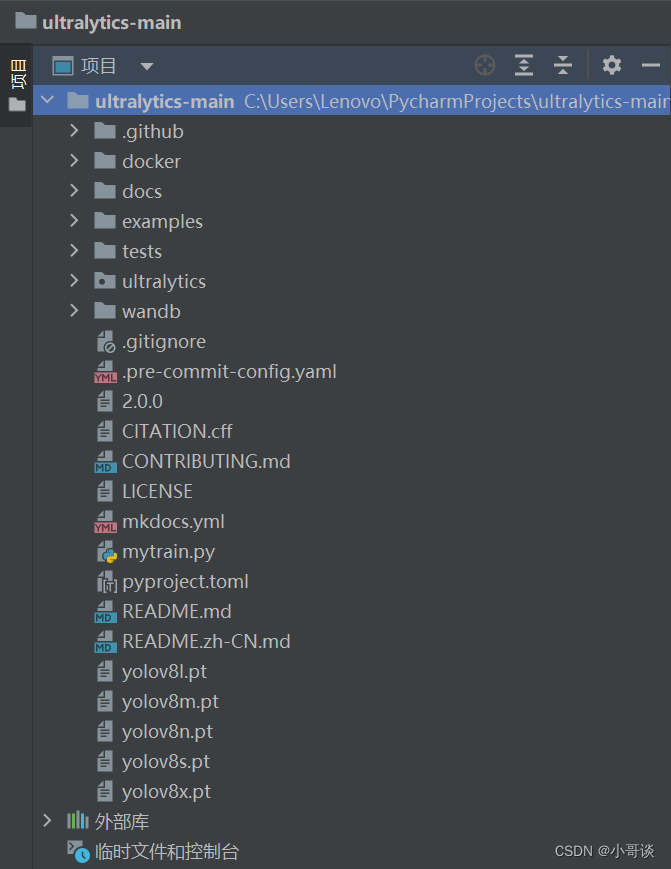
備注:其中的權重文件及mytrain.py文件為談導后加的。?
下面就讓我們來逐個分析YOLOv8的項目目錄結構及組成。?
🚀2. .github
本文件夾所包含的內容如下圖所示:👇
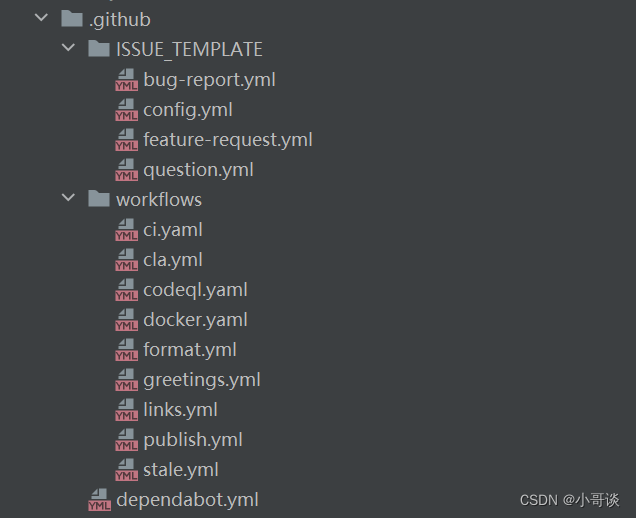
解析:
ISSUE_TEMPLATE:提供不同類型的問題報告模板,包括bug-report.yml、config.yml、feature-request.yml和question.yml。這些模板幫助用戶以結構化的方式報告錯誤、提出功能請求或提問。
- bug-report.yml:是一個常用的配置文件,用于記錄和跟蹤軟件中的bug報告。
- config.yml:是一個配置文件,用于配置軟件或系統的各種參數和選項。
- feature-request.yml:是一個用于記錄和管理軟件功能請求的文件。
- question.yml:是一個常用的問題集合文件。
workflows:包含多個工作流文件,如 ci.yaml(持續集成)、cla.yml(貢獻者許可協議)、codeql.yaml(代碼質量檢查)、docker.yaml(Docker配置)、greetings.yml(自動問候新貢獻者)、links.yml、publish.yml(自動發布)、stale.yml(處理陳舊問題)等。
dependabot.yml:是一個配置文件,用以配置Dependabot的行和設置。Dependabot是一個自化的依賴更新工具,它可以幫助你保持項目中的依賴庫和組件的最版本。
在dependabot.yml文件中,可以指定要監視的依賴庫、更新策略、通知設置等。以下是一些常見dependabot.yml配置選項:
- version
:指定Dependabot的版本,例如2。 - updates
:指定要監視的依賴庫和更新策略。你可以選擇監視所有依賴庫,或者只監視特定的依賴庫。 - package-ecosystem
:指定要監視的依賴庫的生態系統,例如"npm"、"docker"等。 - directory
:指定要監視的依賴庫所在的目錄路徑。 - schedule
:指定更新檢查的頻率和時間表。 - labels
:為生成的PR(Pull Request)添加標簽。 - assignees
:為生成的PR指定負責人。 - reviewers
:為生成的PR指定審查人員。 - ignore:指定要忽略的依賴庫或版本范圍。
這只是一些常見的配置選項,你可以根據自己的需求進行更多的配置。通過使用dependabot.yml文件,你可以自定義Dependabot的行為,使其符合你的項目需求。這些文件共同支持項目的自動化管理,包括代碼質量保證、持續集成和部署、社區互動和依賴項維護。
🚀3. docker
本文件夾所包含的內容如下圖所示:👇
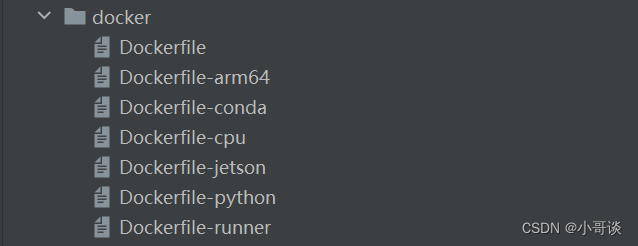
解析:
在YOLOv8中,docker文件夾是用于構建和運行YOLOv8的Docker容器的文件夾。Docker是一種容器化技術,可以將應用程序及其依賴項打包成一個獨立的容器,使其可以在不同的環境中進行部署和運行。docker目錄包含多個Dockerfile,每個文件都是為不同環境或平臺配置的,例如:
Dockerfile:這是一個文本文件,用于定義Docker鏡像的構建規則。其中包含了基礎鏡像、安裝依賴項、設置環境變量等步驟。
Dockerfile-arm64:針對ARM64架構的設備(如某些類型的服務器或高級嵌入式設備)定制的Docker配置。
Dockerfile-conda:使用Conda包管理器配置環境的Docker配置文件。
Dockerfile-cpu:為不支持GPU加速的環境配置的Docker配置文件。
Dockerfile-jetson:專為NVIDIA Jetson平臺定制的Docker配置。
Dockerfile-python:是一個用于構建Docker鏡像的文件,用于在Docker容器中運行Python應用程序。
Dockerfile-runner:可能用于配置持續集成/持續部署(CI/CD)運行環境的Docker配置。
這些配置文件是用來部署用的,用戶可以根據自己的需要選擇合適的環境來部署和運行項目。
名詞解釋:??????
Docker是一個開源的容器化平臺,它可以幫助開發者將應用程序及其依賴項打包成一個獨立的、可移植的容器。這個容器可以在任何支持Docker的環境中運行,無論是開發環境、測試環境還是生產環境。Docker的核心概念是容器,它是一個輕量級、獨立的運行單元,包含了應用程序及其所有的依賴項(例如庫、運行時環境等)。與傳統的虛擬機相比,容器更加輕量級、啟動更快,并且可以在同一臺主機上運行多個容器。
使用Docker可以帶來以下幾個好處:
- 簡化部署:Docker容器可以在不同的環境中運行,避免了由于環境差異導致的部署問題。
- 提高開發效率:開發者可以將應用程序及其依賴項打包成一個容器,方便在不同的開發環境中進行測試和調試。
- 資源利用率高:由于容器是輕量級的,可以在同一臺主機上運行多個容器,提高了資源利用率。
- 系統隔離性好:每個容器都是相互隔離的,一個容器的問題不會影響其他容器的運行。
🚀4. docs
本文件夾所包含的內容如下圖所示:👇
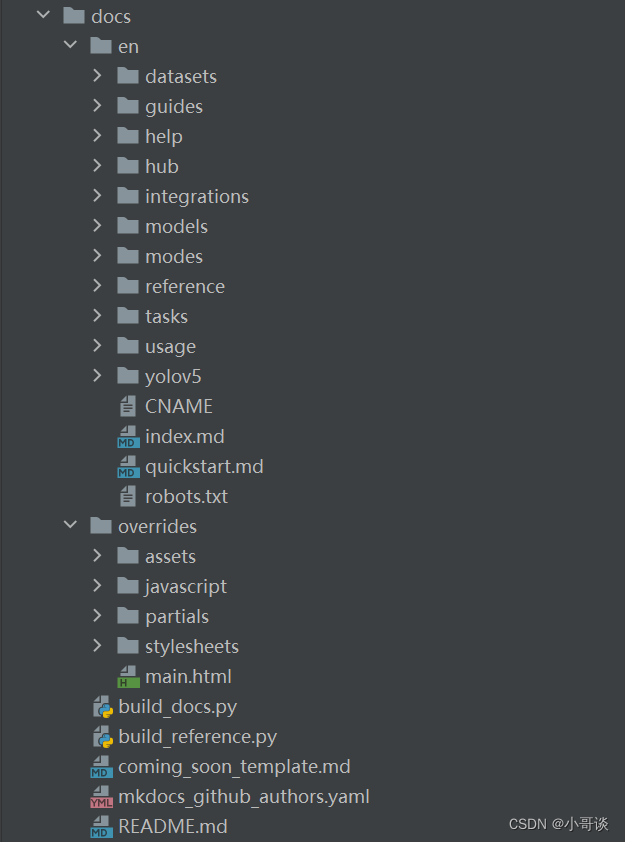
解析:
docs目錄通常用于存放文檔資料,包括多種語言的翻譯。例如,此目錄下有多個文件夾,每個文件夾代表一種語言(如en代表英語文檔)。除此之外,還有幾個重要的Python腳本和配置文件給大家說一下。
build_docs.py:是一個用于構建文檔的Python腳本。它通常用于生成項目的文檔,例如軟件庫、框架或應用程序的文檔。
該腳本的功能通常包括以下幾個方面:
- 收集源代碼中的注釋:build_docs.py會解析源代碼文件,并提取其中的注釋內容。這些注釋可以是函數、類、模塊等的說明文檔。
- 生成文檔頁面:根據收集到的注釋內容,build_docs.py會生成相應的文檔頁面。這些頁面通常以HTML或Markdown格式呈現,可以包含函數、類、模塊的說明、參數、返回值等信息。
- 構建文檔索引:build_docs.py會生成一個文檔索引,用于快速查找和導航文檔頁面。索引可以按照模塊、類、函數等進行組織,方便用戶瀏覽和搜索。
- 自定義配置:build_docs.py通常提供一些配置選項,允許用戶自定義生成文檔的方式。例如,可以指定要包含的源代碼文件、文檔輸出目錄、文檔樣式等。
總之,build_docs.py是一個用于自動化構建項目文檔的工具,它可以幫助開發者更方便地生成和維護項目的文檔。
build_reference.py:是一個Python腳本,用于構建參考文獻的引用格式。它可以根據給定的文獻信息生成符合特定引用風格(如APA、MLA等)的參考文獻列表。
coming_soon_template.md:是一個常用的模板文件,通常用于在網站或應用程序中顯示即將推出的功能或頁面。該模板的目的是向用戶傳達信息,告知他們即將到來的內容,并提供一些相關的細節。
mkdocs_github_authors.yaml:是一個用于配置MkDocs項目的文件,用于指定GitHub上的作者信息。
在MkDocs項目中,可以使用GitHub作為版本控制系統,并且可以配置mkdocs_github_authors.yaml文件來指定GitHub上的作者信息。這個文件通常位于項目的根目錄下。
🚀5. examples
本文件夾所包含的內容如下圖所示:👇
解析:
在examples文件夾中,大家可以找到不同編程語言和平臺的YOLOv8實現示例:
YOLOv8-CPP-Inference:是一個基于YOLOv4/YOLOv5的目標檢測算法的C++推理庫。它是使用C++編寫的,可以在CPU上進行實時目標檢測。YOLOv8-CPP-Inference具有以下特點:
- 高性能:通過使用C++編寫和優化的算法,YOLOv8-CPP-Inference在CPU上實現了實時目標檢測。
- 簡單易用:YOLOv8-CPP-Inference提供了簡潔的API接口,使得用戶可以輕松地集成到自己的項目中。
- 多平臺支持:YOLOv8-CPP-Inference可以在多個平臺上運行,包括Windows、Linux和macOS等。
- 支持多種輸入格式:YOLOv8-CPP-Inference支持常見的圖像格式,如JPEG、PNG等,并且可以從攝像頭或視頻文件中讀取輸入。
YOLOv8-LibTorch-CPP-Inference:是一個基于Torch和C++的YOLOv8目標檢測模型推理庫。YOLOv8是一種流行的實時目標檢測算法,它能夠在圖像或視頻中準確地檢測出多個不同類別的物體。該庫的主要功能是加載預訓練的YOLOv8模型,并使用C++代碼進行目標檢測推理。它提供了簡單易用的API,可以方便地將該庫集成到自己的項目中。
使用YOLOv8-LibTorch-CPP-Inference,你可以通過以下步驟進行目標檢測:
- 加載預訓練模型:使用該庫提供的函數加載預訓練的YOLOv8模型文件。
- 圖像預處理:將待檢測的圖像進行預處理,如縮放、歸一化等操作。
- 執行推理:將預處理后的圖像輸入到模型中,執行推理過程,得到目標檢測結果。
- 后處理:對模型輸出的結果進行后處理,如篩選、極大值抑制等操作。
- 可視化結果:檢測到的目標在圖像上進行可視化展示。
該庫的優點是使用了LibTorch作為底層框架,具有高效的推理性能,并且支持跨平臺部署。同時,它還提供了豐富的示例代碼和文檔,方便用戶快速上手和集成。每個示例都配有相應的文檔,是當我們進行模型部署的時候在不同環境中部署和使用YOLOv8的示例。
YOLOv8-ONNXRuntime:是一個基于ONNXRuntime的目標檢測模型,它是YOLOv3的改進版本。YOLOv8-ONNXRuntime的主要特點和改進包括:
- 更高的檢測精度:YOLOv8-ONNXRuntime在YOLOv3的基礎上進行了一系列改進,提升了目標檢測的準確度。
- 更快的推理速度:通過使用ONNXRuntime作為推理引擎,YOLOv8-ONNXRuntime能夠充分利用硬件加速,提高模型的推理速度。
- 支持多種硬件平臺:YOLOv8-ONNXRuntime可以在不同的硬件平臺上運行,包括CPU、GPU和專用加速器等。
- 靈活的部署方式:由于采用了ONNX格式作為模型的表示方式,YOLOv8-ONNXRuntime可以方便地在不同的框架和平臺上進行部署。
YOLOv8-ONNXRuntime-CPP:是一個基于ONNX Runtime和C++的YOLOv8目標檢測模型的實現。ONNX Runtime是一個高性能的推理引擎,它支持在多種硬件平臺上運行深度學習模型。通過使用ONNX Runtime,我們可以將YOLOv8模型部署到不同的設備上,如CPU、GPU和邊緣設備。YOLOv8-ONNXRuntime-CPP提供了一個C++接口,使得我們可以方便地使用YOLOv8模型進行目標檢測。它提供了加載模型、預處理輸入數據、執行推理以及后處理結果的功能。通過使用這個庫,我們可以快速地將YOLOv8模型集成到我們的應用程序中。
YOLOv8-ONNXRuntime-Rust:是一個基于YOLOv4和ONNXRuntime的目標檢測算法的Rust語言實現。ONNXRuntime是一個用于高性能推理的開源深度學習推理引擎,它支持多種深度學習框架和硬件平臺。YOLOv8-ONNXRuntime-Rust的實現使用了Rust語言,Rust是一種系統級編程語言,具有內存安全和并發性能的優勢。該項目利用Rust的高性能和并發特性,結合YOLOv8和ONNXRuntime,實現了一個快速且可靠的目標檢測算法。
該項目的主要特點包括:
- 高性能:利用Rust語言的性能優勢,實現了快速的目標檢測算法。
- 可擴展性:基于YOLOv8和ONNXRuntime,可以輕松地集成到其他項目中,并進行二次開發和擴展。
- 簡潔易用:提供了簡單易用的API接口,方便用戶進行目標檢測任務。
YOLOv8-OpenCV-int8-tflite-Python:是一個用于目標檢測的深度學習模型和工具鏈的組合。下面是對每個部分的介紹:
- YOLOv8:YOLO(You Only Look Once)是一種實時目標檢測算法,YOLOv8是YOLO系列的第八個版本。它通過將圖像劃分為網格,并在每個網格上預測邊界框和類別,實現了高效的目標檢測。
- OpenCV:OpenCV是一個開源計算機視覺庫,提供了許多用于圖像處理和計算機視覺任務的函數和工具。在YOLOv8-OpenCV-int8-tflite-Python中,OpenCV用于圖像的讀取、預處理和后處理等任務。
- int8:int8是指使用8位整數進行推理的技術。通過將模型參數和輸入數據轉換為8位整數,可以減少模型的存儲空間和計算量,從而提高推理速度。
- tflite:tflite是TensorFlow Lite的縮寫,是一種用于在移動設備和嵌入式系統上進行推理的輕量級模型格式。在YOLOv8-OpenCV-int8-tflite-Python中,模型會被轉換為tflite格式,以便在資源受限的設備上進行目標檢測。
- Python:Python是一種流行的編程語言,廣泛應用于機器學習和深度學習領域。在YOLOv8-OpenCV-int8-tflite-Python中,Python用于編寫整個目標檢測的工作流程,包括模型加載、圖像處理和結果展示等。
YOLOv8-OpenCV-ONNX-Python:是一個用于目標檢的深度學習模型和工具鏈的組合。下面是對每個部分的簡要介紹:
-
YOLOv8:YOLO(You Only Look Once)是一種實時目標檢測算法,YOLOv8是YOLO系列的第八個版本。它通過將圖像劃分為網格,并在每個網格上預測邊界框和類別,實現了高效的目標檢測。YOLOv8在準確性和速度之間取得了很好的平衡。
-
OpenCV:OpenCV是一個開源計算機視覺庫,提供了豐富的圖像處理和計算機視覺算法。它支持多種編程語言,包括Python。在YOLOv8-OpenCV-ONNX-Python中,OpenCV用于圖像的讀取、預處理和后處理等任務。
-
ONNX:ONNX(Open Neural Network Exchange)是一個開放的深度學習模型交換格式。它允許不同的深度學習框架之間共享和使用模型,使得模型的部署更加靈活。在YOLOv8-OpenCV-ONNX-Python中,ONNX用于將YOLOv8模型從訓練框架(如PyTorch或TensorFlow)轉換為可在OpenCV中使用的格式。
-
Python:Python是一種流行的編程語言,具有簡潔易讀的語法和豐富的生態系統。在YOLOv8-OpenCV-ONNX-Python中,Python用于編寫整個工具鏈的代碼,包括模型轉換、圖像處理和目標檢測等功能。
綜上所述,YOLOv8-ONNX-Python是一個使用YOLOv8模型、OpenCV庫和ONNX格式,在Python環境下進行目標檢測的工具鏈。
YOLOv8-Region-Counter:是一個基于YOLOv4和YOLOv5的目標檢測算法,用于實時檢測圖像或視頻中的物體,并計數特定區域內的目標數量。它是YOLO系列算法的一個變種,通過使用更深的網絡結構和一些改進的技術來提高檢測性能。YOLOv8-Region-Counter的核心思想是將目標檢測任務轉化為一個回歸問題,通過在圖像上劃分網格并預測每個網格中是否存在目標以及目標的位置和類別。
YOLOv8-SAHI-Inference-Video:在YOLOv8的基礎上進行了改進,引入了SAHI(Spatial Attention and Hierarchical Inference)機制。SAHI機制通過引入空間注意力和分層推理來提高目標檢測的性能。空間注意力機制可以幫助網絡更好地關注目標的重要區域,提高檢測的準確性。分層推理機制則可以在不同的網絡層次上進行目標檢測,從而提高檢測的效率和精度。YOLOv8-SAHI-Inference-Video主要應用于視頻目標檢測任務,可以實時地檢測視頻中的多個目標,并給出它們的類別和位置信息。它在目標檢測領域具有較高的性能和效率。
YOLOv8-Segmentation-ONNXRuntime-Python:是一個用于目標檢測和語義分割的深度學習模型。它結合了YOLOv3和語義分割網絡,使用ONNXRuntime庫在Python環境中進行推理。
YOLOv8-Segmentation-ONNXRuntime-Python的主要特點包括:
- 目標檢測和語義分割:該模型可以同時進行目標檢測和語義分割任務。目標檢測用于檢測圖像中的物體位置和類別,而語義分割則用于將圖像分割成不同的語義區域。
- YOLOv3和語義分割網絡的結合:該模型基于YOLOv3和語義分割網絡的結構進行設計,綜合了兩種任務的優勢,可以同時獲得目標檢測和語義分割的結果。
- 使用ONNXRuntime進行推理:ONNXRuntime是一個高性能的推理引擎,可以在多種硬件平臺上進行快速的模型推理。YOLOv8-Segmentation-ONNXRuntime-Python利用ONNXRuntime庫來加載和運行模型,提供了高效的推理能力。
- Python編程環境:該模型使用Python作為主要的編程語言,方便用戶在Python環境中進行模型的加載、推理和結果的處理。
🚀6. test
本文件夾所包含的內容如下圖所示:👇
解析:
在YOLOv8中,tests文件夾是用于存放測試相關的代碼和數據的文件夾。它包含了一些用于驗證YOLOv8模型性能和功能的測試腳本和測試數據。
conftest.py:包含測試配置選項或共享的測試助手函數。
test_cli.py:是一個Python文件,通常用于測試令行界面(CLI)應用程序的功能和行為。它是通過使用Python的unittest或其他測試框架編寫的測試代碼。該文件中的測試代碼主要用于模擬用戶輸入和檢查程序輸出,以確保CLI應用程序按預期工作。這些測試可以包括輸入參數的驗證、命令的執行、輸出結果的檢查等。
test_cuda.py:是一個用于測試CUDA功能的Python腳本。CUDA是NVIDIA提供的一種并行計算平臺和編程模型,可以利用GPU的強大計算能力加速計算任務。該文件的主要功能是檢測系統中是否安裝了CUDA,并測試CUDA在GPU上的運行情況。它會執行一些基本的CUDA操作,如初始化CUDA環境、創建CUDA設備、分配GPU內存、在GPU上執行計算等。通過運行該文件,您可以了解系統中是否支持CUDA,以及CUDA在您的GPU上的性能表現。這對于開發使用CUDA加速的應用程序或進行深度學習等計算密集型任務非常有用。
test_explorer.py:是一個用于測試的Python腳本,它通常用于執行單元測試或集成測試。該腳本可以幫助開發人員自動運行測試用例,并提供測試結果的匯總和報告。
test_engine.py:是一個測試引擎的Python腳本,用于執行動化測試。它可以幫助開發人員在開發過程中驗證代碼的正確性和穩定性。
test_integrations.py:是一個測試集成的Python文件,用于測試模塊之間的集成是否正常工作。它通常用于測試軟件系統的整體功能和交互。
test_python.py:是一個Python腳本文件,用于進行Python代碼的單元測試。在軟件開發中,單元測試是一種測試方法,用于驗證代碼的正確性和功能是否按照預期工作。
這些測試腳本確保大家在改進了文件之后更新或添加的新功能后仍能運行的文件,總之,tests文件夾是YOLOv8項目中用于測試模型性能和功能的重要組成部分,它包含了測試腳本、測試數據、模型配置文件和權重文件等。你可以使用這些工具來驗證YOLOv8模型在不同圖像上的目標檢測效果。
🚀7.?ultralytics(重點)
本文件夾所包含的內容如下圖所示:👇
上面講的大部分文件其實對于大部分讀者都用不上,這里的utralytics文件才是重點,包含了YOLOv8的所有功能都集成在這個文件目錄下面。
🍀(1)assets
本文件夾所包含的內容如下圖所示:

解析:
這個文件下面保存了YOLO歷史上可以說最最最經典的兩張圖片了,這個是大家用來基礎推理時候的圖片,給大家測試用的。
🍀(2)cfg
本文件夾所包含的內容如下圖所示:
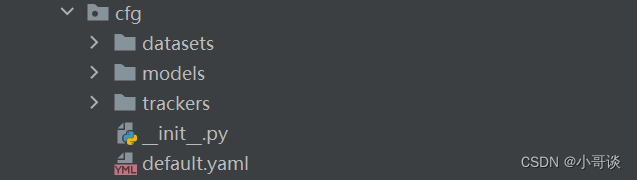
解析:
這個文件下面保存了我們的模型配置文件,cfg目錄是項目配置的集中地,其中包括:
datasets文件夾:包含數據集的配置文件,如數據路徑、類別信息等(就是我們訓練YOLO模型的時候需要一個數據集,這里面就保存部分數據集的yaml文件,如果我們訓練的時候沒有指定數據集則會自動下載其中的數據集文件,但是很容易失敗!)。
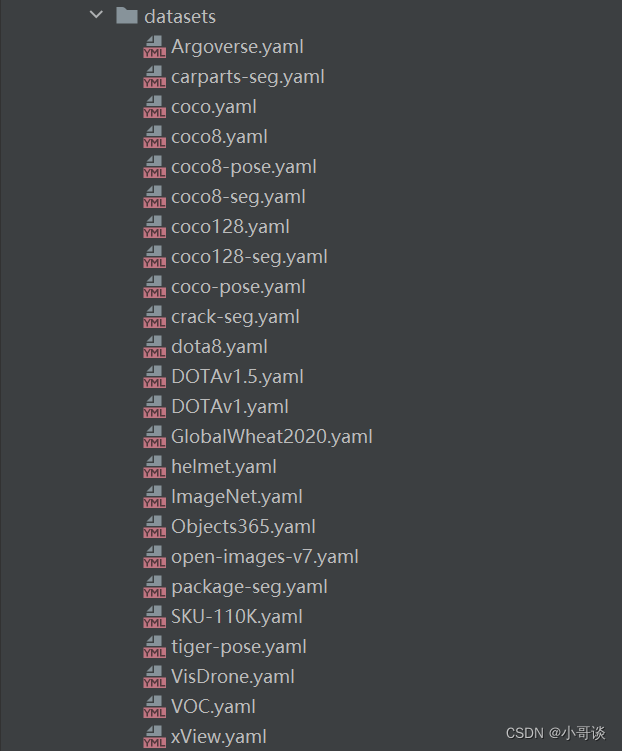
models文件夾:存放模型配置文件,定義了模型結構和訓練參數等,這個是我們改進或者就基礎版本的一個yaml文件配置的地方。
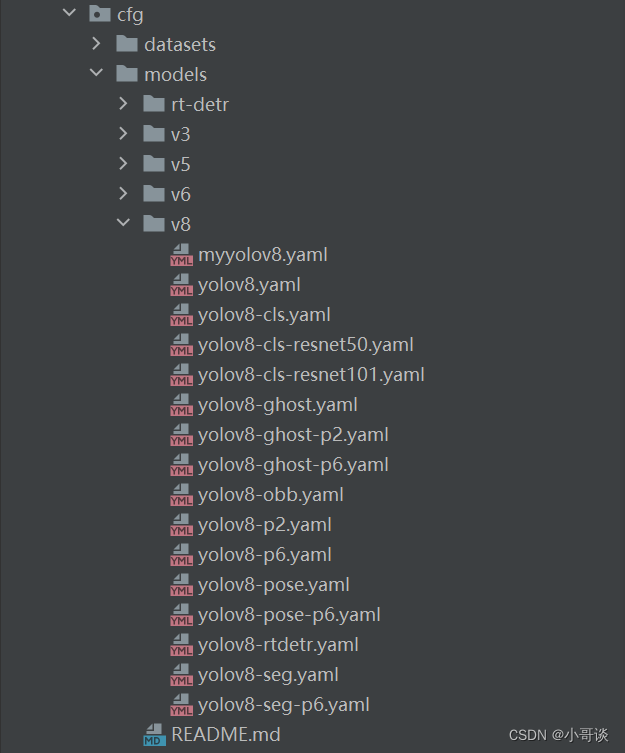
models文件夾中的每個.yaml文件代表了不同的YOLOv8模型配置,具體包括:
- yolov8.yaml:這是YOLOv8模型的標準配置文件,定義了模型的基礎架構和參數。
- yolov8-cls.yaml:配置文件調整了YOLOv8模型,專門用于圖像分類任務。
- yolov8-ghost.yaml:應用Ghost模塊的YOLOv8變體,旨在提高計算效率。
- yolov8-ghost-p2.yaml/yolov8-ghost-p6.yaml:這些文件是針對特定大小輸入的Ghost模型變體配置。
- yolov8-p2.yaml/yolov8-p6.yaml:針對不同處理級別(例如不同的輸入分辨率或模型深度)的YOLOv8模型配置。
- yolov8-pose.yaml:為姿態估計任務定制的YOLOv8模型配置。
- yolov8-pose-p6.yaml:針對更大的輸入分辨率或更復雜的模型架構姿態估計任務。
- yolov8-rtdetr.yaml:可能表示實時檢測和跟蹤的YOLOv8模型變體。
- yolov8-seg.yaml/yolov8-seg-p6.yaml:這些是為語義分割任務定制的YOLOv8模型配置。
這些配置文件是模型訓練和部署的核心,同時大家如果進行改進也是修改其中的對應文件來優化網絡結構。
trackers文件夾:用于追蹤算法的配置。
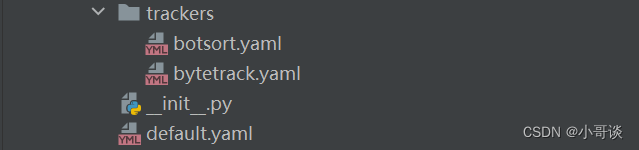
__init__.py:表明`cfg`是一個Python包。
default.yaml:項目的默認配置文件,包含了被多個模塊共享的通用配置項。
🍀(3)data
本文件夾所包含的內容如下圖所示:
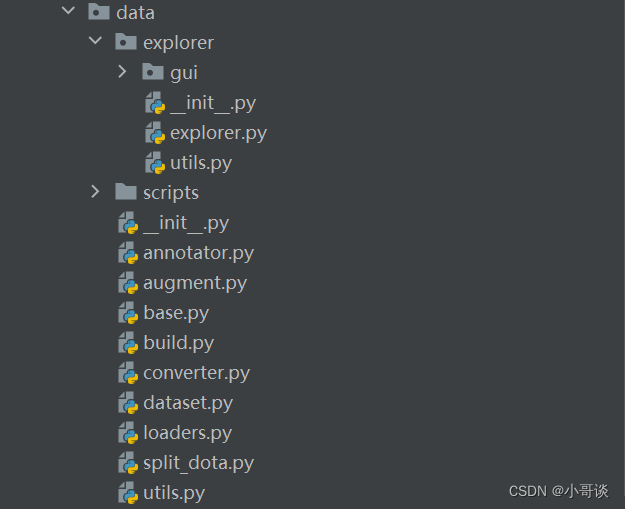
解析:
在data/scripts文件夾中,包括了一系列腳本和Python文件:
download_weights.sh:用來下載預訓練權重的腳本。
get_coco.sh/get_coco128.sh/get_imagenet.sh:用于下載COCO數據集完整版、128張圖片版以及ImageNet數據集的腳本。
在data文件夾中,包括:
annotator.py:用于數據注釋的工具。
augment.py:數據增強相關的函數或工具。
base.py/build.py/converter.py:包含數據處理的基礎類或函數,構建數據集的腳本以及數據格式轉換工具。
dataset.py:數據集加載和處理的相關功能。
Ioaders.py:定義加載數據的方法。
utils.py:各種數據處理相關的通用工具函數。
🍀(4)engine
本文件夾所包含的內容如下圖所示:
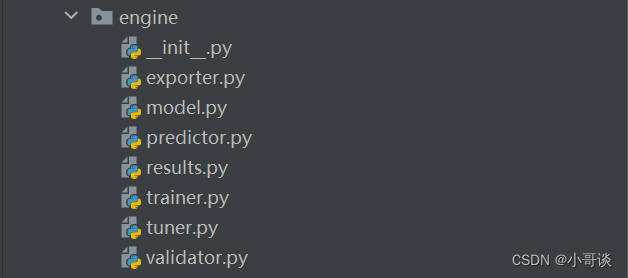
解析:
engine文件夾包含與模型訓練、評估和推理有關的核心代碼:
exporter.py:用于將訓練好的模型導出到其他格式,例如ONNX或TensorRT。
model.py:包含模型定義,還包括模型初始化和加載的方法。
predictor.py:包含推理和預測的邏輯,如加載模型并對輸入數據進行預測。
results.py:用于存儲和處理模型輸出的結果。
trainer.py:包含模型訓練過程的邏輯。
tuner.py:用于模型超參數調優。
validator.py:包含模型驗證的邏輯,如在驗證集上評估模型性能。
🍀(5)hub
本文件夾所包含的內容如下圖所示:

解析:
hub文件夾通常用于處理與平臺或服務集成相關的操作,包括:
auth.py:處理認證流程,如API密鑰驗證或OAuth流程。
session.py:管理會話,包括創建和維護持久會話。
utils.py:包含一些通用工具函數,可能用于支持認證和會話管理功能。
🍀(6)models
本文件夾所包含的內容如下圖所示:
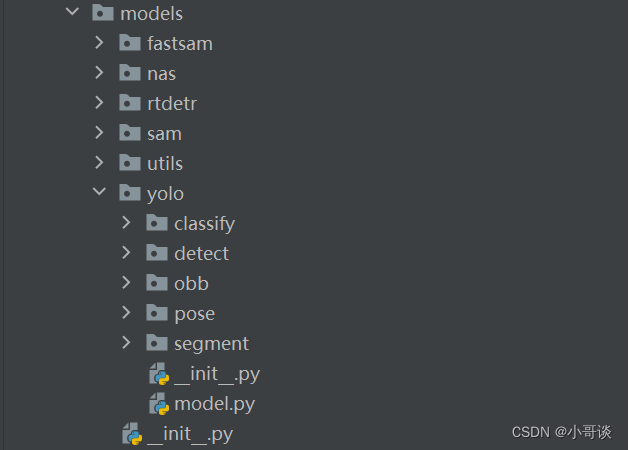
解析:
這個目錄下面是YOLO倉庫包含的一些模型的方法實現,我們這里只說YOLO的,同時這里只是簡單介紹,后面的博客針對于其中的任意一個都會進行單獨的講解。
這個models/yolo目錄中包含了YOLO模型的不同任務特定實現:
classify:這個目錄包含用于圖像分類的YOLO模型。
detect:包含用于物體檢測的YOLO模型。
pose:包含用于姿態估計任務的YOLO模型。
segment:包含用于圖像分割的YOLO模型。
🍀(7)nn
本文件夾所包含的內容如下圖所示:
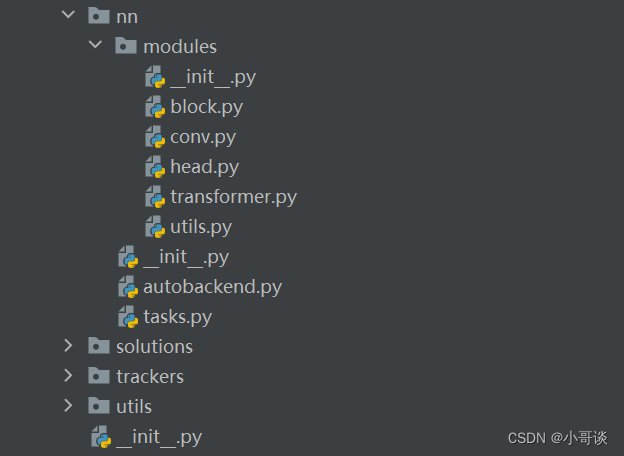
解析:
這個文件目錄下的所有文件,就是定義我們模型中的一些組成構建,之后我們進行改進和優化,增加其它結構的時候都要在對應的文件下面進行改動。
modules文件夾:
- __init__py:表明此目錄是Python包。
- block.py:包含定義神經網絡中的基礎塊,如殘差塊或瓶頸塊。
- conv.py:包含卷積層相關的實現。
- head.py:定義網絡的頭部,用于預測。
- transformer.py:包含Transformer模型相關的實現
- utils.py:提供構建神經網絡時可能用到的輔助函數。
autobackend.py:用于自動選擇最優的計算后端。
tasks.py:定義了使用神經網絡完成的不同任務的流程,例如分類、檢測或分割,所有的流程基本上都定義在這里,定義模型前向傳播都在這里。
🍀(8)solutions
本文件夾所包含的內容如下圖所示:
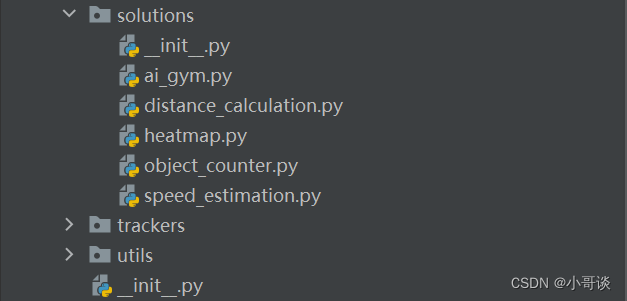
解析:
關于該文件夾中的相關文件解析如下:
__init__py:標識這是一個Python包。
ai_gym.py:與強化學習相關,例如在OpenAl Gym環境中訓練模型的代碼。
heatmap.py:用于生成和處理熱圖數據,這在物體檢測和事件定位中很常見。
object_counter.py:用于物體計數的腳本,包含從圖像中檢測和計數實例的邏輯.
🍀(9)trackers
本文件夾所包含的內容如下圖所示:
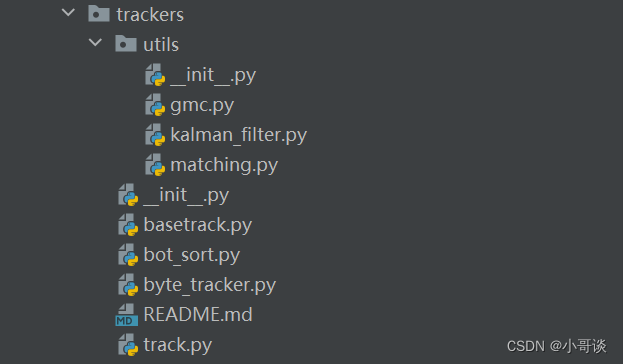
解析:
trackers文件夾包含了實現目標跟蹤功能的腳本和模塊:
__init__py: 指示該文件夾是一個Python包。
basetrack.py:包含跟蹤器的基礎類或方法。
bot_sort.py:實現了SORT算法(Simple Online and Realtime Tracking)的版本。
byte_tracker.py:是一個基于深度學習的跟蹤器,使用字節為單位跟蹤目標。
track.py:包含跟蹤單個或多個目標的具體邏輯。
README.md:提供該目錄內容和用法的說明。
🍀(10)utils
本文件夾所包含的內容如下圖所示:
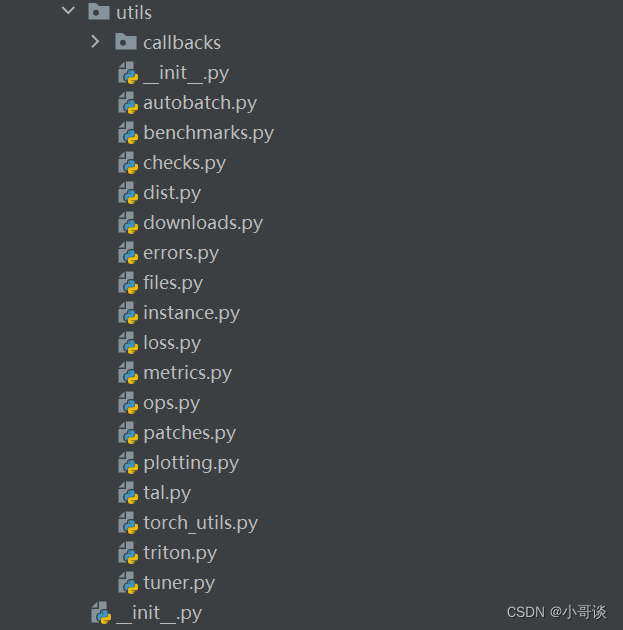
解析:
這個utils目錄包含了多個Python腳本,每個腳本都有特定的功能:
autobatch.py:是一個Python腳本,用于自動化批處理文件的操作。它可以幫助你快速、高效地處理大量的文件。
該腳本的主要功能包括:
- 批量重命名文件:可以按照指定的規則對文件進行批量重命名,例如添加前綴、后綴、替換特定字符等。
- 批量移動文件:可以將指定目錄下的文件批量移動到其他目錄中。
- 批量復制文件:可以將指定目錄下的文件批量復制到其他目錄中。
- 批量刪除文件:可以刪除指定目錄下的一組文件。
- 批量壓縮文件:可以將指定目錄下的文件批量壓縮成一個壓縮包。
使用autobatch.py可以極大地提高文件處理的效率,特別適用于需要對大量文件進行相同操作的場景。
benchmarks.py:是一個常用的Python腳本,用于對計算機系統或軟件進行性能測試和基準測試。它通常用于評估系統的性能、比較不同系統或軟件的性能,并幫助開發人員進行性能優化。其可以執行各種測試,包括CPU性能測試、內存性能測試、磁盤性能測試、網絡性能測試等。它可以測量計算機系統在不同負載下的響應時間、吞吐量、延遲等指標,從而評估系統的性能表現。
使用benchmarks.py可以幫助開發人員發現系統中的性能瓶頸,優化代碼和配置,提高系統的性能和響應能力。
checks.py:是一個Python腳本文件,用于執行各種檢查和驗證操作。它通常用于軟件開發過程中,以確保代碼的正確性、一致性和可靠性。
具體來說,checks.py可以包含以下類型的檢查:
- 語法檢查:檢查代碼是否符合Python語法規范,例如檢查縮進、括號匹配等。
- 代碼風格檢查:檢查代碼是否符合特定的編碼風格規范,例如PEP 8規范。
- 代碼質量檢查:檢查代碼是否符合良好的編碼實踐,例如變量命名規范、函數長度等。
- 依賴檢查:檢查代碼所依賴的外部庫或模塊是否已正確安裝和配置。
- 單元測試:執行單元測試用例,驗證代碼的功能是否按預期工作。
- 集成測試:執行集成測試用例,驗證不同組件之間的交互是否正常。
- 安全性檢查:檢查代碼是否存在潛在的安全漏洞或易受攻擊的風險。
通過運行checks.py腳本,開發人員可以自動化執行這些檢查,并及時發現和修復潛在問題,從而提高代碼的質量和可維護性。
dist.py:是一個Python腳本文件,涉及分布式計算相關的工具。
downloads.py:包含下載數據或模型等資源的腳本。
errors.py:是一個常見的Python文件,通常用定義自定義的錯誤類或異常類。Python中,我們可以通過繼承內置的Exception類來創建定義的錯誤類以便在程序中處理特定的錯誤情況在errors.py文件,我們可以定義多個自定義的錯誤類,每個錯誤類代表一個定的錯誤情況。這些錯誤類可以包含自定義的屬性和方法,以便更好地描述和處理錯誤。
files.py:包含文件操作相關的工具函數。它提供了一些常用的文件處理函數和方法。通過導入files.py模塊,你可以在Python程序中輕松地進行文件的讀取、寫入、復制、移動等操作。
instance.py:是一個Python文件,用于創建和管理類的實例(對象)。在面向對象編程中,類是一種抽象的概念,而實例則是類的具體化。通過實例化一個類,我們可以創建一個具體的對象,并使用該對象調用類中定義的方法和屬性。
loss.py:是一個常見的用于計算損失函數的Python文件。在機器學習和深度學習中,損失函數用于衡量模型預測結果與真實標簽之間的差異程度。通過最小化損失函數,我們可以優化模型的參數,使其能夠更好地擬合訓練數據。在loss.py文件中,通常會定義多個損失函數的實現,以供選擇使用。
metrics.py:包含評估模型性能的指標計算函數,是一個常用的Python模塊,用于計算和評估機器學習模型的性能指標。它提供了一系列函數和類,可以幫助我們計算分類、回歸和聚類等任務的各種指標。
ops.py:包含自定義操作,如特殊的數學運算或數據轉換。
patches.py:用于實現修改或補丁應用的工具。
plotting.py:包含數據可視化相關的繪圖工具,它提供了一些函數和工具,可以幫助用戶創建各種類型的圖表,包括線圖、散點圖、柱狀圖、餅圖等。該模塊通常用于科學計算、數據分析和機器學習等領域,可以幫助用戶更好地理解和展示數據。
下面是一些plotting.py中常用的功能和方法:
-
繪制線圖:plotting.py提供了plot函數,可以繪制線圖。用戶可以通過傳入x軸和y軸的數據來創建線圖,并可以自定義線條的顏色、樣式和標簽等。
-
繪制散點圖:plotting.py中的scatter函數可以用于繪制散點圖。用戶可以傳入x軸和y軸的數據,并可以設置散點的大小、顏色和標簽等。
-
繪制柱狀圖:使用plotting.py的bar函數可以創建柱狀圖。用戶可以傳入x軸和y軸的數據,并可以設置柱子的寬度、顏色和標簽等。
-
繪制餅圖:plotting.py提供了pie函數,用于創建餅圖。用戶可以傳入餅圖的數據和標簽,并可以設置餅圖的顏色、陰影和偏移等。
-
設置坐標軸和標題:plotting.py還提供了一些方法來設置坐標軸的范圍、刻度和標簽,以及設置圖表的標題和圖例等。
-
保存圖表:用戶可以使用plotting.py中的savefig函數將繪制的圖表保存為圖片文件,方便后續使用或分享。
tal.py:一些損失函數的功能應用
torch_utils.py:提供PyTorch相關的工具和輔助函數,包括GFLOPs的計算。它包含了一些常用的函數和類,用于簡化模型訓練和評估的過程。
以下是torch_utils.py中可能包含的一些功能:
-
數據加載和預處理:torch_utils.py可能包含用于加載和預處理數據的函數,例如讀取圖像數據集、數據增強等。
-
模型定義:torch_utils.py可能包含用于定義神經網絡模型的函數或類。這些函數或類可以幫助用戶快速定義自己的模型結構。
-
模型訓練:torch_utils.py可能包含用于訓練神經網絡模型的函數或類。這些函數或類可以幫助用戶設置訓練參數、優化器、損失函數等,并提供訓練過程中的一些輔助功能,如學習率調整、模型保存等。
-
模型評估:torch_utils.py可能包含用于評估神經網絡模型性能的函數或類。這些函數或類可以幫助用戶計算模型在測試集上的準確率、精確率、召回率等指標。
-
輔助函數:torch_utils.py可能還包含一些輔助函數,用于處理模型保存和加載、可視化訓練過程等。
triton.py:可能與NVIDlA Triton Inference Server集成相關。
tuner.py:包含模型或算法調優相關的工具。它通常與機器學習算法一起使用,通過自動化地搜索不同的超參數組合來找到最佳的模型配置。
到這里重點的ultralytics文件目錄下的所有功能都介紹完畢了,這里只是簡單的介紹,后面的博客會詳細的介紹一些重要的功能。
🚀8. 其他文件
該部分所包含的內容如下圖所示:
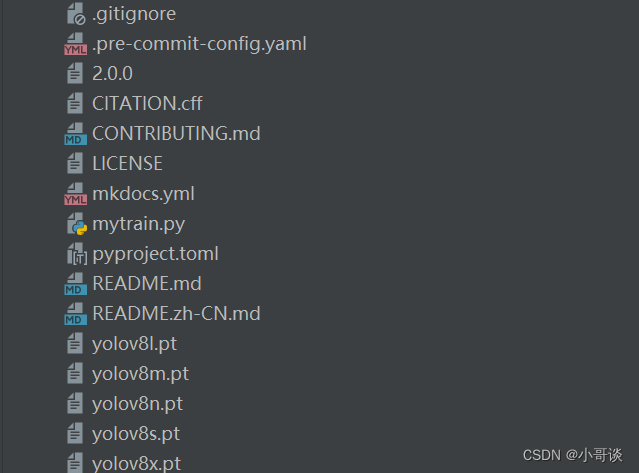
這個里是項目的根本配置和文檔文件:
.gitignore:Git配置文件,指定了Git版本控制要忽略的文件。
.pre-commit-config.yaml:是一個用于配置pre-commit工具的文件。pre-commit是一個開源的Git鉤子框架,它可以在代碼提交前運行一系列的代碼檢查和格式化工具,以確保代碼質量和一致性。該文件定義了pre-commit工具需要運行的各種檢查和格式化工具,以及它們的配置參數。該文件通常位于項目的根目錄下,并且使用YAML格式進行編寫。
CITATION.Cff:是一種用于描述科學研究的引用信息的文件格式。它是一種文本文件,通常位于項目的根目錄下,用于提供關于項目的引用信息,包括作者、標題、版本、DOI等。該文件的目的是幫助其他人正確引用和引用您的項目。
CONTRIBUTING.md:說明如何為項目貢獻代碼的指南。
LICENSE:包含了項目的許可證信息。
README.md/README.zh-CN.md:項目的說明文件,分別為英文和中文版本。
到此,本文就結束了,后面會根據源碼的項目目錄結構及其文件進行改進,歡迎關注后面更多精彩文章~!🍉 🍓 🍑 🍈 🍌 🍐



)

)





![[c++] 繼承和多態整理一](http://pic.xiahunao.cn/[c++] 繼承和多態整理一)

——TCP數據發送與接收并行)






