簡述
CloudCanal 最近對于全周期數據流動進行了初步探索,打通了Hive 目標端的實時同步,為實時數倉的構建提供了支持,這篇文章簡要做下分享。
- 基于臨時表的增量合并方式
- 基于 HDFS 文件寫入方式
- 臨時表統一 Schema
- 任務級的臨時表
基于臨時表的增量合并方式
Hive 目標端寫入方式和 Doris 相似,需要在目標表上額外添加一個 __op(0:UPSERT,1:DELETE)字段作為標記位,實際寫入時會先將源端的變更先寫入臨時表,最終合并到實際表中。
CloudCanal 的設計核心在于,每個同步表對應兩張臨時表,通過交替合并的方式,確保在一張臨時表進行合并時,另一張能夠接收新變更,從而提升同步效率和并發性。
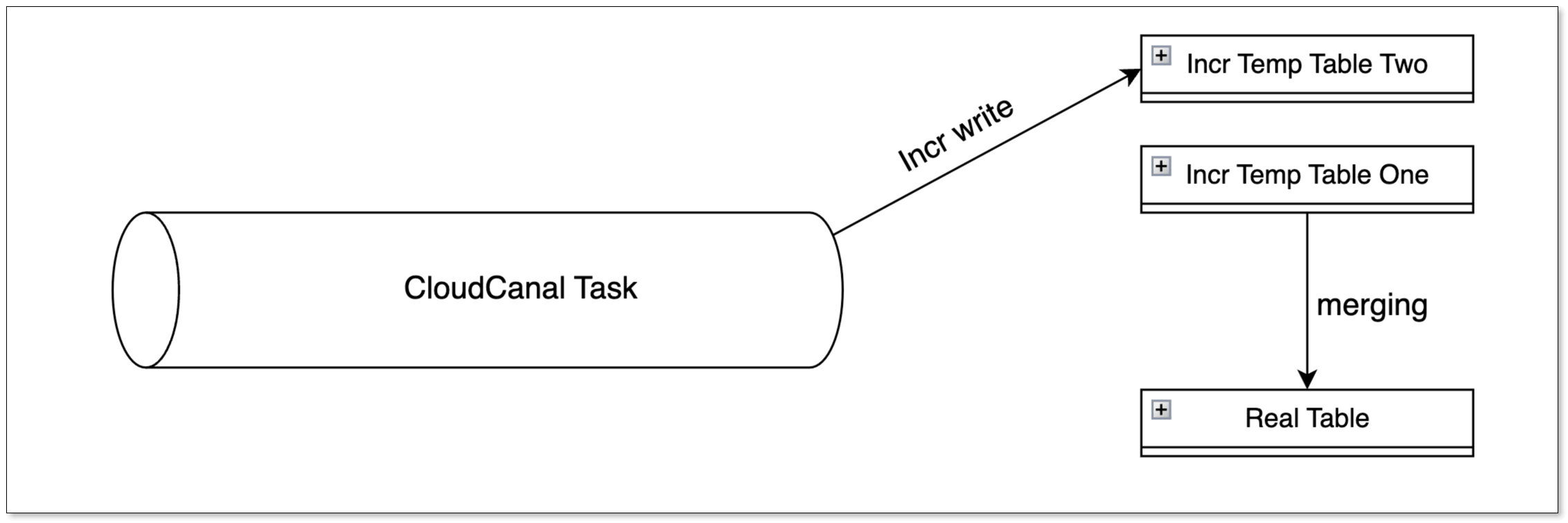
Hive 提供了兩種合并方式:INSERT OVERWRITE(所有版本均支持),MERGE INTO(Hive 2.2.0 之后支持且需要是 ACID 表)
-- INSERT OVERWRITE 語法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...-- MERGE INTO 語法
MERGE INTO <target table > AS T USING < source expression / table > AS S
ON <boolean expression1>WHEN MATCHED [AND <boolean expression2>] THEN
UPDATE SET <set clause list>WHEN MATCHED [AND <boolean expression3>] THEN
DELETEWHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
任務級的臨時表
在大數據場景下,多表匯聚的情況十分普遍,CloudCanal 在構建臨時表時,利用源端的訂閱 Schema Table 信息,創建不同的臨時表。
通過這種方式,無論是相同或不同的任務、相同或不同的 Schema(源端)、相同或不同的 Table(源端),都能將數據寫入不同的臨時表,最終合并到同一個實際表中,互相之間不會產生影響。
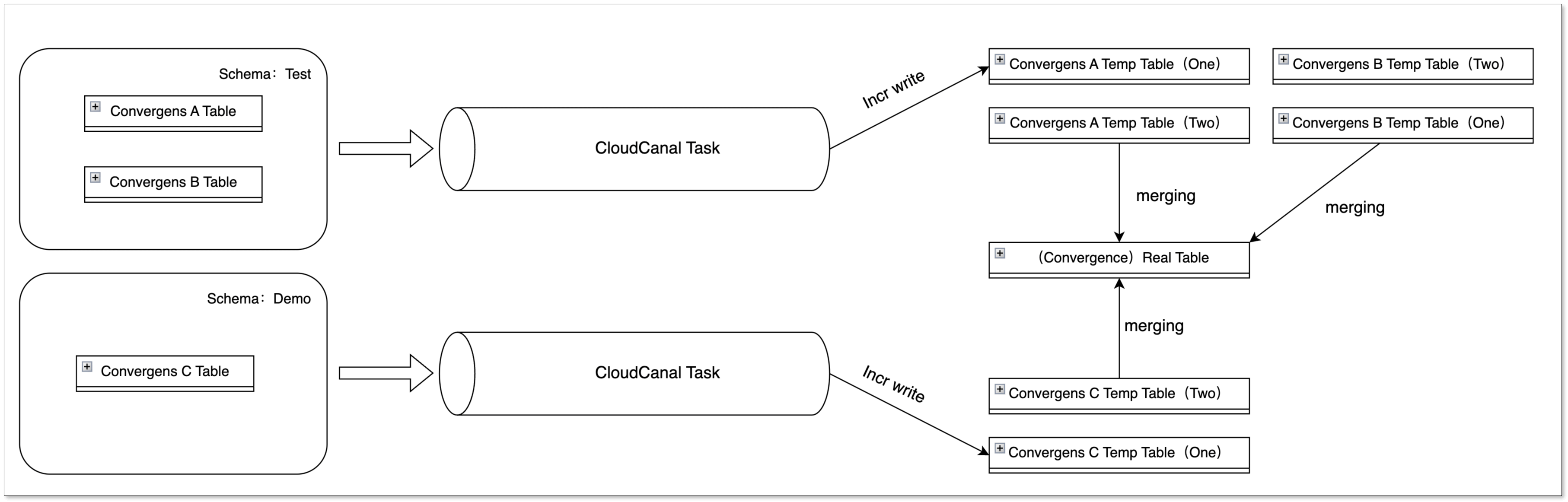
基于 HDFS 文件的寫入方式
Hive 是建立在 Hadoop 體系上的數據倉庫,而實際的數據存儲在 HDFS 中。
如果直接通過 HQL 將增量數據寫入 Hive,Hive 會將 HQL 轉化為 MR Job,由于每一個 MR Job 處理速度相對較慢,這將導致增量性能極其差。
CloudCanal 在進行數據寫入的時候,選擇的是繞過 Hive 這層,直接寫入 HDFS 文件系統。
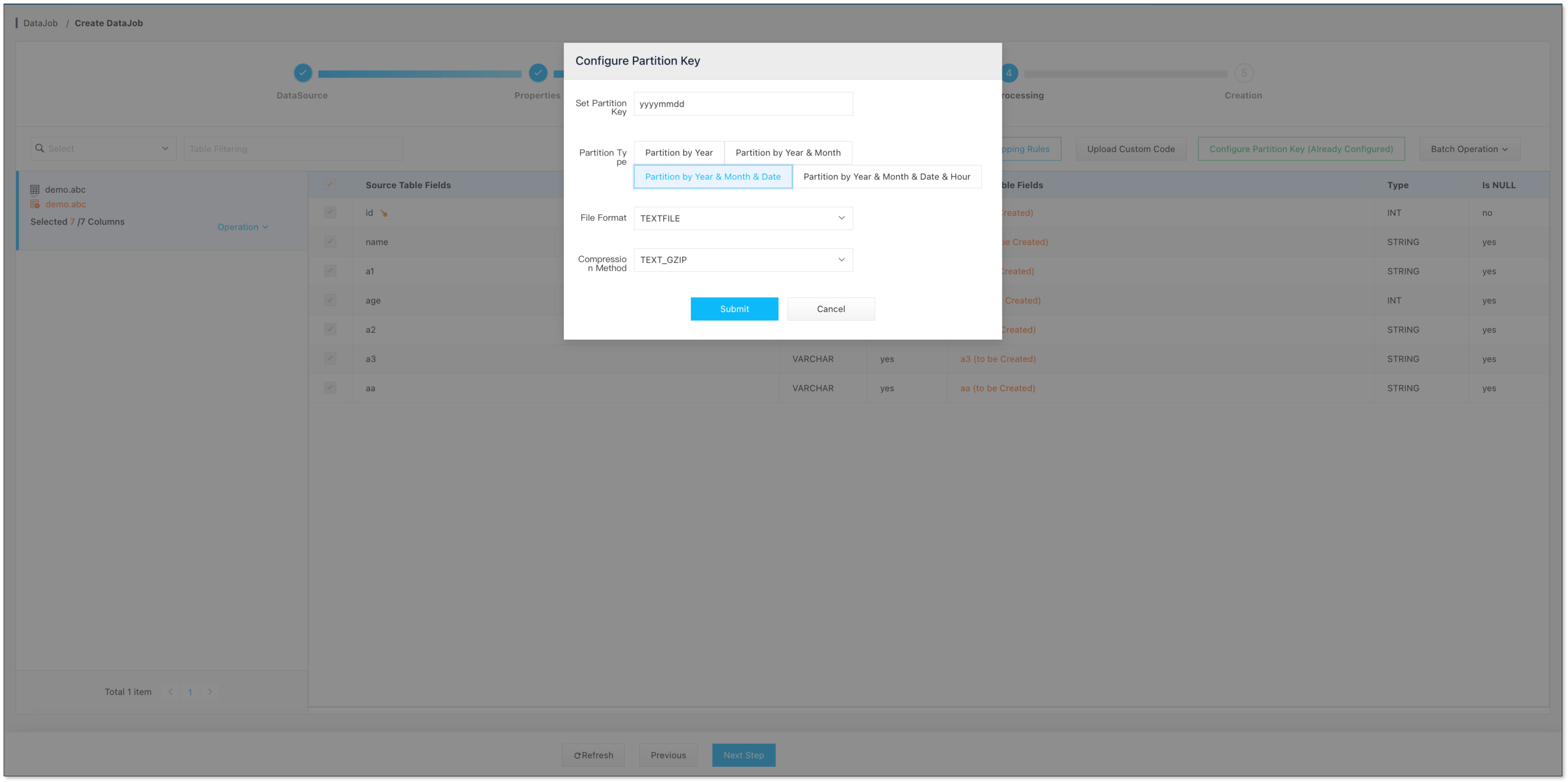
目前支持 HDFS 文件格式:Text、Orc、Parquet。
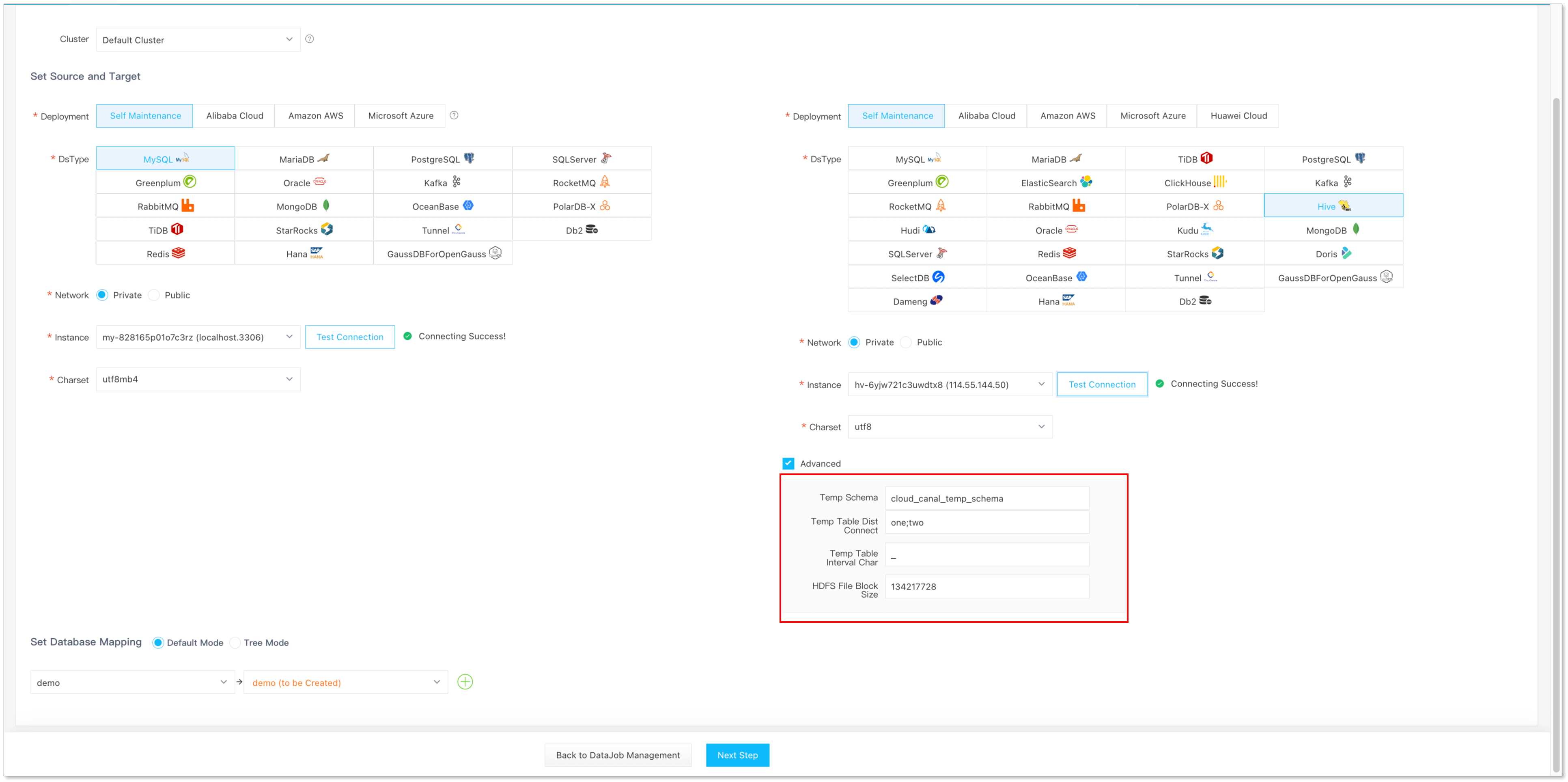
臨時表統一 Schema
基于臨時表構建的增量方式,如果臨時表分散在不同的 Schema 中,將給 DBA 的管理帶來不便。
為了簡化管理,CloudCanal 將所有臨時表構建在統一的 Schema 下,并允許用戶自定義其臨時表路徑。
示例
準備 CloudCanal
- 下載安裝 CloudCanal 私有部署版本
添加數據源
-
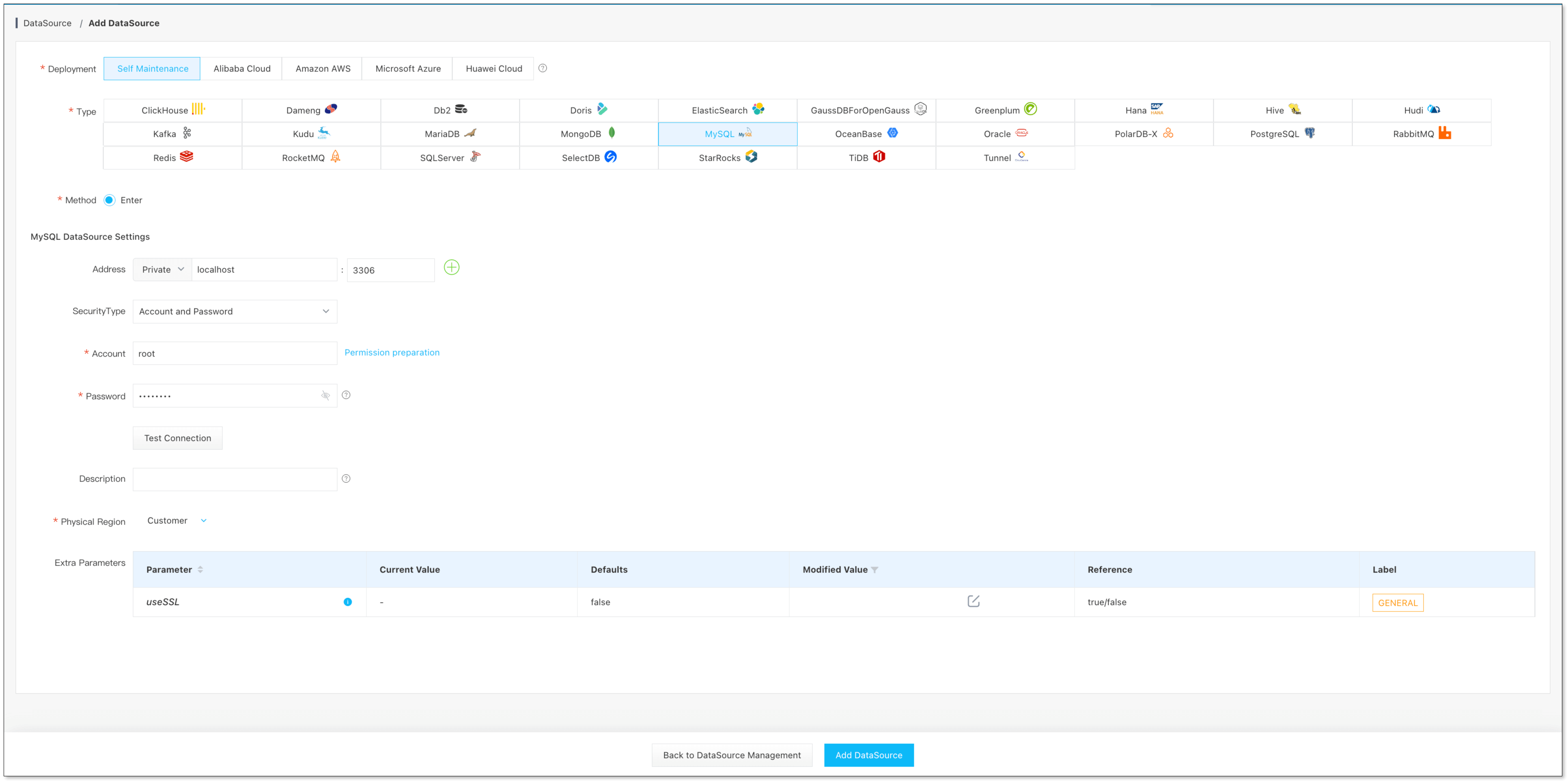
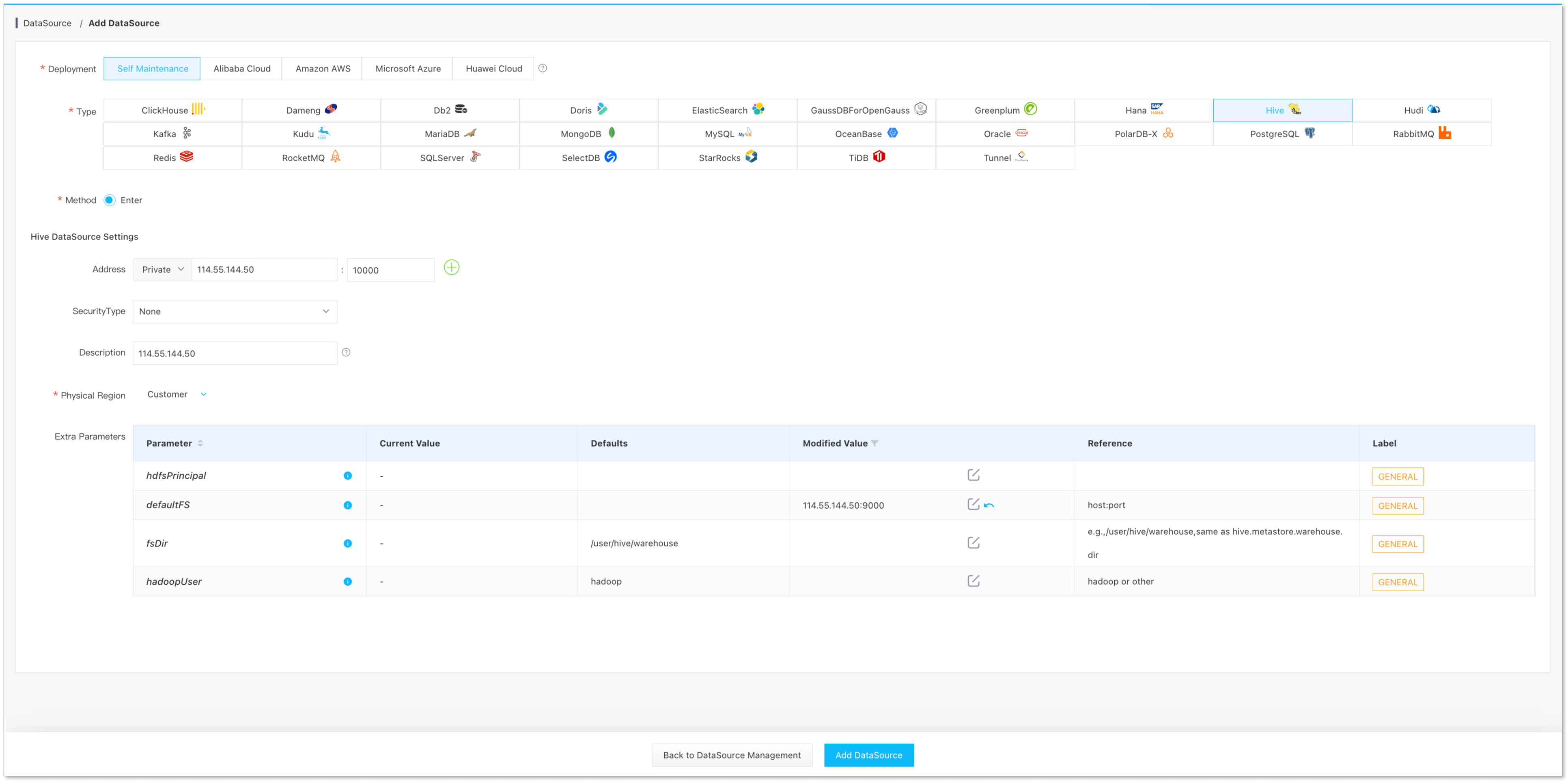
數據源管理 -> 添加數據源, 添加 MySQL、Hive
創建同步任務
-
選擇源端 MySQL 和目標端 Hive,同步的 Schema 和 Table,高級參數含義參考 MySQL -> Hive
-
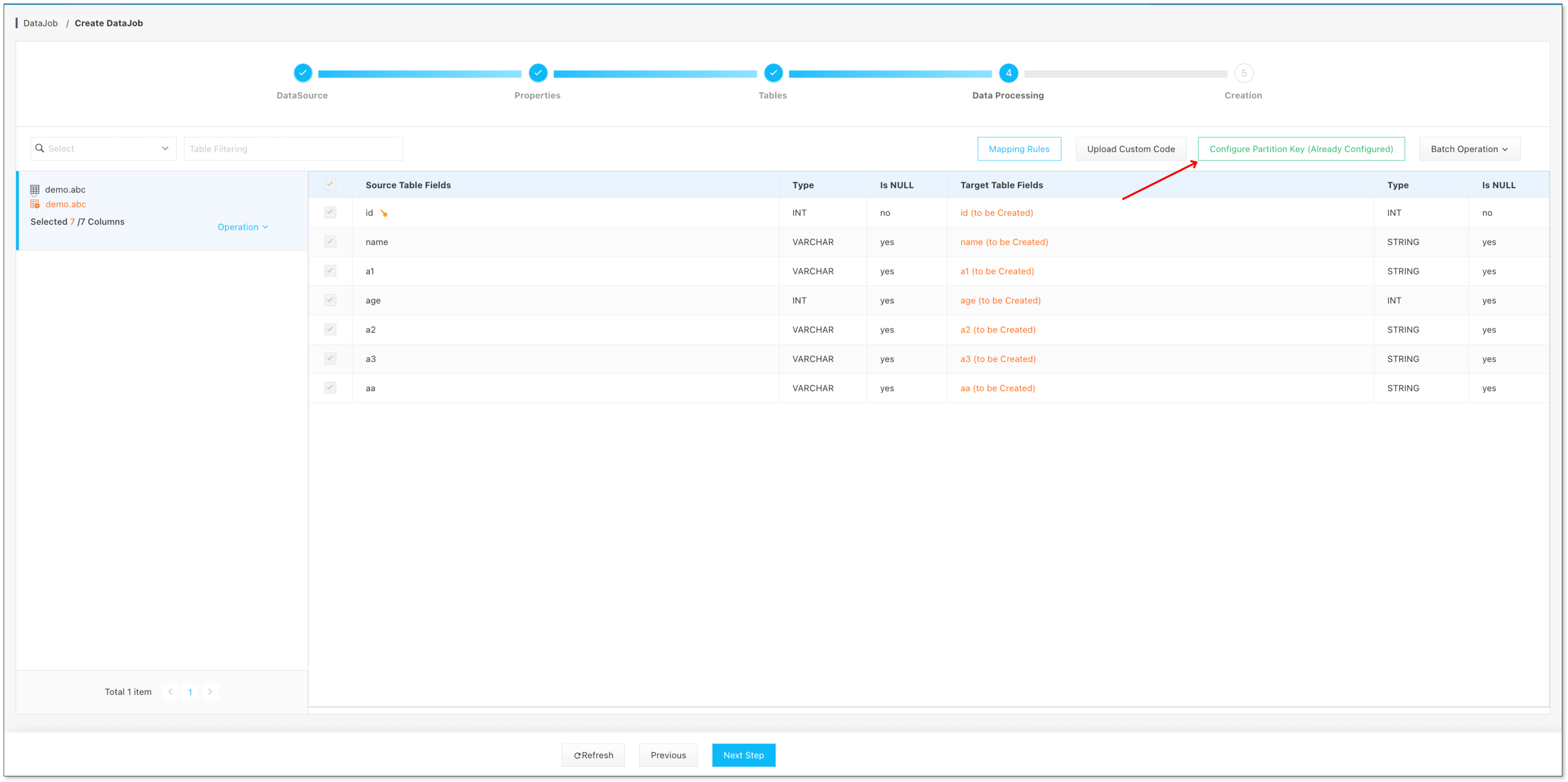
任務創建第四步,點擊 配置分區鍵
-
選擇 分區鍵類型 以及 HDFS 文件類型
-
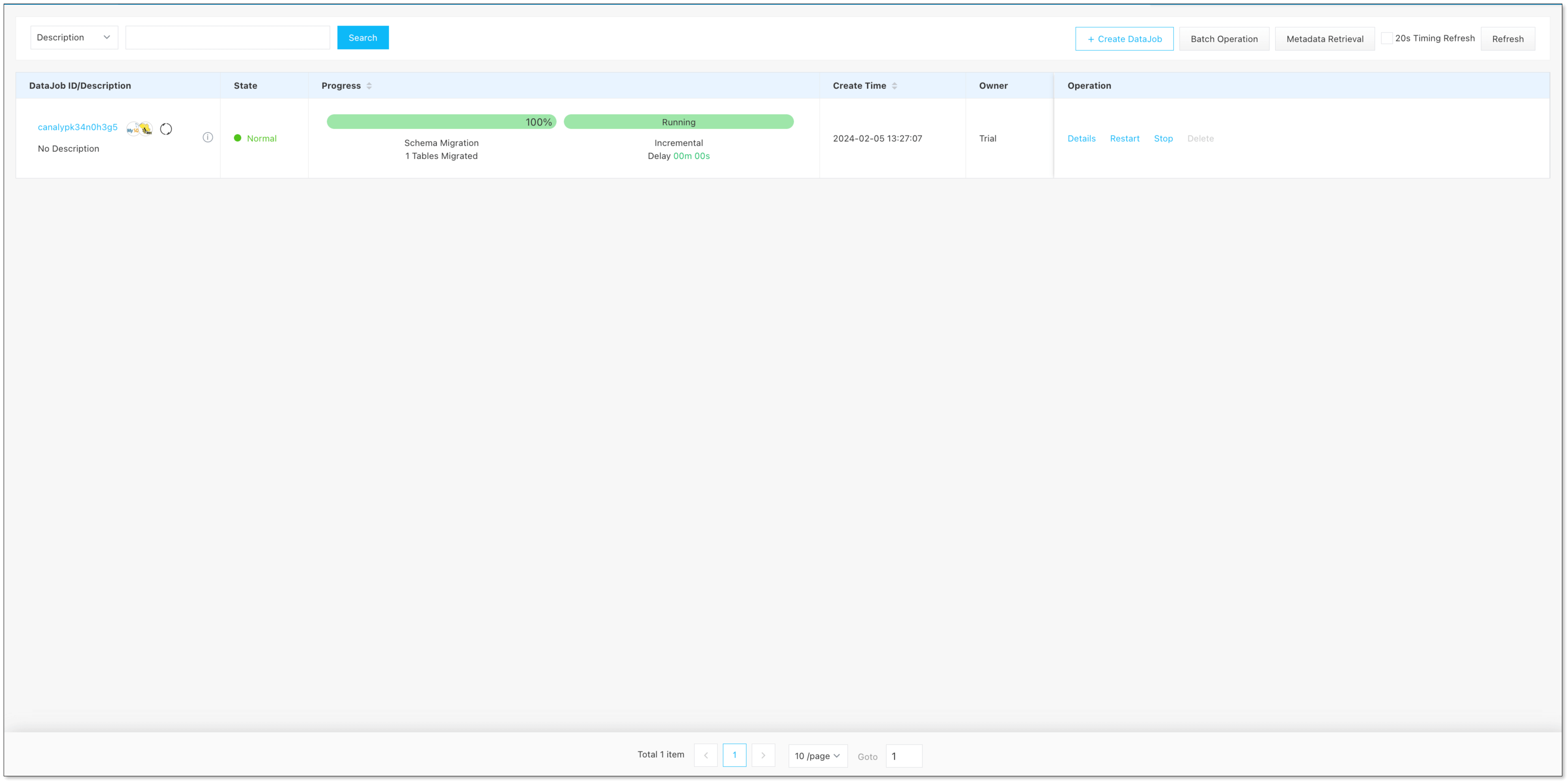
點擊下一步,創建任務即可
未來方向
文件 Append 寫入方式
目前 HDFS 文件寫入處理,是每批數據寫到一個文件中,并不會處理歷史數據文件,更加合理的方式是基于歷史文件進行 Append
追加,寫滿之后再切換為下一個文件。
提供參數優化 MR 處理速度
目前 CloudCanal 并沒有提供參數入口用于優化 MR 處理速度,而是自動使用用戶所配置的,未來 CloudCanal 將提供一個參數入口用于用戶自定義每一個
MR Job 的處理并行度等優化參數。
支持 MERGE INTO 合并方式
目前 CloudCanal 僅支持 INSERT OVERWRITE 的合并方式,這種方式更為通用,而 MERGE INTO 此種合并方式速度更快,但限制較多,未來
CloudCanal 也會支持此種合并方式。
支持自定義分區鍵
目前 CloudCanal 僅支持按照日期選擇分區鍵,目前暫時不支持更多分區鍵的選擇,未來 CloudCanal 會提供更多分區鍵的選擇。
總結
本篇文章簡單介紹 CloudCanal 對于全生命周期的數據流動的初步探索,并通過 MySQL -> Hive 示例介紹其使用。

)







)

——Netty入門)







