前言:
1.訓練在windows進行,因為電腦沒有顯卡,所以純cpu訓練,生成pt后轉onnx
2.onnx轉需要在Ubuntu虛擬機上運行
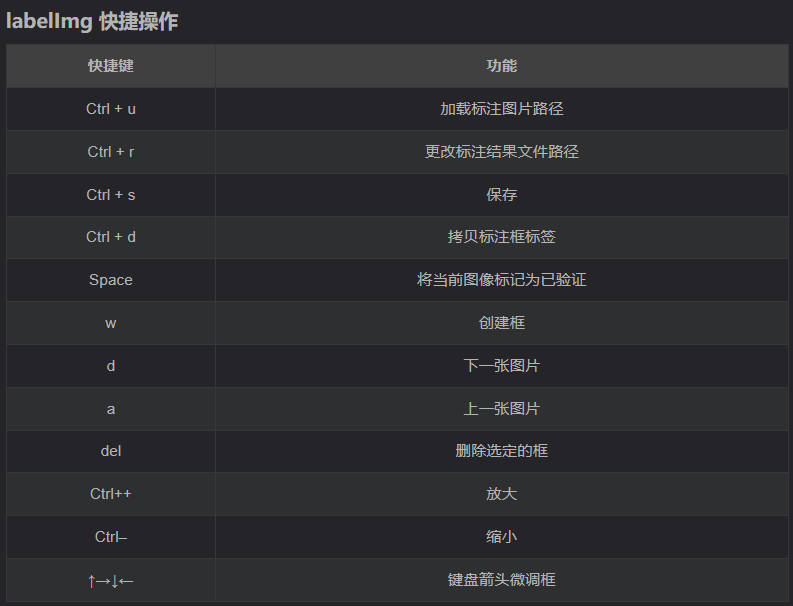
3.數據集標定快捷鍵
(模型訓練時不需要)官方地址和下載pt權重:鏈接:https://github.com/ultralytics/ultralytics/tree/v8.0.4?tab=readme-ov-file
必須要下載模型,在源碼頁面找到模型點擊下載,推薦下載yolov8n.pt
環境配置
參考鏈接:(32 封私信 / 80 條消息) yolov8環境配置加訓練自己的數據集保姆級教程(2024) - 知乎
yolov8訓練自己的目標檢測數據集詳細介紹版-騰訊云開發者社區-騰訊云
1.安裝anaconda Index of /archive
打開anaconda prompt(管理員運行)
conda create -n yolov8 python=3.8 -y 創建環境,建議3.8
conda activate yolov8 激活環境
conda deactivate 退出環境
conda env remove --name yolov8
conda remove --name yolov8 --all 刪除環境然后安裝pytorch如果安裝GPU版本可以用下面命令:pip install torch2.0.0+cu118 torchvision0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118如果安裝CPU版本pytorch可以用下面命令:conda install pytorch torchvision torchaudio cpuonly -c pytorch安裝yolov8:pip install ultralytics測試 下載yolov8n.pt和隨機圖片yolo predict model=yolov8n.pt source=test.jpgpip install labelimg //安裝labelimg,會自動安裝pyqt5,或者在pycharm命令行安裝和打開labelimg制作自己的數據集(本人是訓練航空發動機劃痕和缺陷)
1.新建文件夾
在data文件夾里面新建一個datasets再在里面新建四個文件夾分別是
Annotations(存放xml的文件夾)
images(用來存放原始的需要訓練的數據集圖片,圖片格式為jpg格式)
ImageSets(用來存放將數據集劃分后的用于訓練、驗證、測試的文件)
labels(存放yolo轉換的txt文件)。
我用了兩個分類
scratch (劃痕)
fracture 斷裂
使用說明:
(1)Open Dir就是打開需要標注的圖片的文件夾,這里就選擇images文件夾
(2)change save dir就是標注后保存標記文件的位置,選擇需要保存標注信息的文件夾,這里就選擇Annotations文件夾
(3)特別注意需要選擇好所需要的標注文件的類型。有yolo(txt), pascalVOC (xml)兩種類型。yolo需要txt文件格式的標注文件,但是這里我們選擇pascalVOC,后面再將xml格式的標注文件轉化為所需的txt格式。
(4)按W鍵或點擊Create\nRectBox開始創建矩形框,把要進行識別訓練的區域標記出來就行,選好框后我們選是什么類別(predefined_classes文件,在里面提前寫好要訓練的類型的原因),整張圖片的所有目標都標記好了之后按Ctrl+S或點擊Save保存 ,然后切換下一張繼續,快捷鍵為按D鍵,每一張圖片標記后都要保存,這個過程是一個比較繁瑣的過程
2.標注
如何預設標簽
1.找到anaconda安裝的根目錄:D:\anaconda
2.進入路徑D:\anaconda\Lib\site-packages\labelImg
注意如果你安裝其他環境需要對應自己環境,比如我的是py38環境里面則需進去D:\anaconda3\envs\yolov8\Lib\site-packages\labelImg。
3.在此路徑里面創建data文件夾,并將自己的predefined_classes.txt文件放入到data文件夾中。
labelImg如何設置多個預設標簽
labelImg如何設置多個預設標簽_51CTO博客_labelimg標簽怎么設置
劃分數據集進行訓練
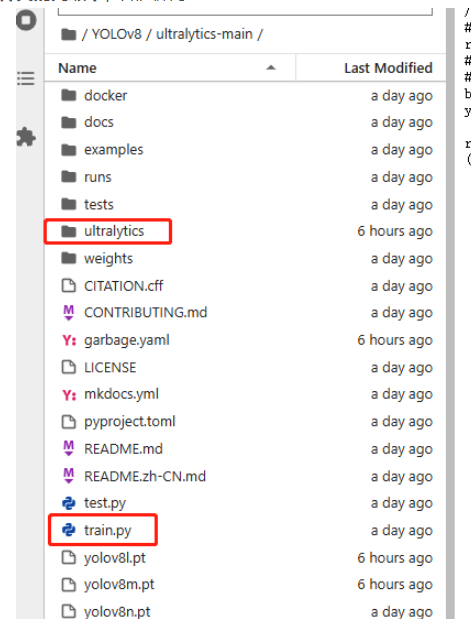
博主建議將腳本放在ultralytics文件夾的同級下(我第一次操作沒有放到同級目錄,一樣沒問題)
因為在YOLOv8的項目中,存在一個ultralytics文件夾,而我們在配置環境的時候,又有名為ultralytics的環境包,二者存在歧義,導致我們在ultralytics文件夾中進行參數修改后卻不生效的情況,(這時如果仍要通過命令行進行訓練,必須要在環境配置文件中進行相應修改),比如更改激活函數后,發現得到的PT模型仍為最初的SiLU激活函數,這是因為命令行會優先調用環境配置文件中的參數,所以在ultralytics文件夾中修改激活函數后并不會生效(博主自己踩坑,請大家避免)。
3.最重要的一點:要改激活函數為ReLU(問deepseek說可以不用改,我也沒改),
改激活函數流程如下:把ultralytics/nn/modules/conv.py中的Conv類進行修改,將
default_act = nn.SiLU() # default activation改為
default_act = nn.ReLU() # default activation
對數據集進行劃分
import os
import shutil
import randomdef make_yolo_dataset(images_folder, labels_folder, output_folder, train_ratio=0.8):# 創建目標文件夾images_train_folder = os.path.join(output_folder, 'images/train')images_val_folder = os.path.join(output_folder, 'images/val')labels_train_folder = os.path.join(output_folder, 'labels/train')labels_val_folder = os.path.join(output_folder, 'labels/val')os.makedirs(images_train_folder, exist_ok=True)os.makedirs(images_val_folder, exist_ok=True)os.makedirs(labels_train_folder, exist_ok=True)os.makedirs(labels_val_folder, exist_ok=True)# 獲取圖片和標簽的文件名(不包含擴展名)image_files = [f for f in os.listdir(images_folder) if f.endswith('.jpg')]label_files = [f for f in os.listdir(labels_folder) if f.endswith('.txt')]image_base_names = set(os.path.splitext(f)[0] for f in image_files)label_base_names = set(os.path.splitext(f)[0] for f in label_files)# 找出圖片和標簽都存在的文件名matched_files = list(image_base_names & label_base_names)# 打亂順序并劃分為訓練集和驗證集random.shuffle(matched_files)split_idx = int(len(matched_files) * train_ratio)train_files = matched_files[:split_idx]val_files = matched_files[split_idx:]# 移動文件到對應文件夾for base_name in train_files:img_src = os.path.join(images_folder, f"{base_name}.jpg")lbl_src = os.path.join(labels_folder, f"{base_name}.txt")img_dst = os.path.join(images_train_folder, f"{base_name}.jpg")lbl_dst = os.path.join(labels_train_folder, f"{base_name}.txt")shutil.copyfile(img_src, img_dst)shutil.copyfile(lbl_src, lbl_dst)for base_name in val_files:img_src = os.path.join(images_folder, f"{base_name}.jpg")lbl_src = os.path.join(labels_folder, f"{base_name}.txt")img_dst = os.path.join(images_val_folder, f"{base_name}.jpg")lbl_dst = os.path.join(labels_val_folder, f"{base_name}.txt")shutil.copyfile(img_src, img_dst)shutil.copyfile(lbl_src, lbl_dst)print("數據集劃分完成!")# 使用示例
images_folder = r'E:\Projects\ultralytics_yolov8-main\data\images' # 原始圖片文件夾路徑
labels_folder = r'E:\Projects\ultralytics_yolov8-main\data\Annotations' # 原始標簽文件夾路徑
output_folder = r'E:\Projects\ultralytics_yolov8-main\data\ImageSets' # 存放結果數據集的文件夾路徑
make_yolo_dataset(images_folder, labels_folder, output_folder)開始訓練模型
在yolov8根目錄下(也就是官方源碼的ultralytics-main目錄下)創建一個新的data.yaml文件,也可以是其他名字的例如mydata.yaml文件,文件名可以變但是后綴需要為.yaml,內容如下
train: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\train # train images (relative to 'path') 128 images
val: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\val # val images (relative to 'path') 128 images
test: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\testnc: 2# Classes
names: ['scratch','fracture']訓練模型
這是使用官方提供的預訓練權重進行訓練,使用yolov8n.pt,也可以使用yolov8s.pt,模型大小n
新建個train.py文件
from ultralytics import YOLO
#多線程添加代碼
if __name__ == '__main__': model = YOLO('yolov8n.yaml').load('yolov8n.pt')# # 訓練模型 GPU#results = model.train(data='data.yaml', epochs=100, imgsz=640, device=0, workers=2, batch=16, optimizer='SGD', amp=False)# 訓練模型 CPUresults = model.train(data='data.yaml', epochs=100, imgsz=640, device='cpu', workers=2, batch=16, optimizer='SGD',amp=False)epochs是訓練輪數,可以由少變多看訓練效果,workers和batch根據電腦性能來,如果運行不起來則相應降低,最好為2的n次方。
也可以使用命令行執行訓練 yolo task=detect mode=train model=yolov8n.yaml pretrained=yolov8n.pt data=data.yaml epochs=100 imgsz=640 device=0 workers=2 batch=16 訓練完成后會在源碼目錄runs里面有模型生成,可以進去weights文件夾找到best.pt或者last.pt模型
查看模型激活函數方法如下所示:
from ultralytics import YOLO# 加載自定義訓練的模型
model = YOLO("runs/detect/train/weights/best.pt")# 打印模型結構(查找激活函數)
print(model.model)首先羅列一下官網提供的全部參數:Model Training with Ultralytics YOLO - Ultralytics YOLO Docs
一些比較常用的傳參:
| key | 解釋 |
| model | 傳入的model.yaml文件或者model.pt文件,用于構建網絡和初始化,不同點在于只傳入yaml文件的話參數會隨機初始化 |
| data | 訓練數據集的配置yaml文件 |
| epochs | 訓練輪次,默認100 |
| patience | 早停訓練觀察的輪次,默認50,如果50輪沒有精度提升,模型會直接停止訓練 |
| batch | 訓練批次,默認16 |
| imgsz | 訓練圖片大小,默認640 |
| save | 保存訓練過程和訓練權重,默認開啟 |
| save_period | 訓練過程中每x個輪次保存一次訓練模型,默認-1(不開啟) |
| cache | 是否采用ram進行數據載入,設置True會加快訓練速度,但是這個參數非常吃內存,一般服務器才會設置 |
| device | 要運行的設備,即cuda device =0或Device =0,1,2,3或device = cpu |
| workers | 載入數據的線程數。windows一般為4,服務器可以大點,windows上這個參數可能會導致線程報錯,發現有關線程報錯,可以嘗試減少這個參數,這個參數默認為8,大部分都是需要減少的 |
| project | 項目文件夾的名,默認為runs |
| name | 用于保存訓練文件夾名,默認exp,依次累加 |
| exist_ok | 是否覆蓋現有保存文件夾,默認Flase |
| pretrained | 是否加載預訓練權重,默認Flase |
| optimizer | 優化器選擇,默認SGD,可選[SGD、Adam、AdamW、RMSProP] |
| verbose | 是否打印詳細輸出 |
| seed | 隨機種子,用于復現模型,默認0 |
| deterministic | 設置為True,保證實驗的可復現性 |
| single_cls | 將多類數據訓練為單類,把所有數據當作單類訓練,默認Flase |
| image_weights | 使用加權圖像選擇進行訓練,默認Flase |
| rect | 使用矩形訓練,和矩形推理同理,默認False |
| cos_lr | 使用余弦學習率調度,默認Flase |
| close_mosaic | 最后x個輪次禁用馬賽克增強,默認10 |
| resume | 斷點訓練,默認Flase |
| lr0 | 初始化學習率,默認0.01 |
| lrf | 最終學習率,默認0.01 |
| label_smoothing | 標簽平滑參數,默認0.0 |
| dropout | 使用dropout正則化(僅對訓練進行分類),默認0.0 |
模型測試
找到之前訓練的結果保存路徑,創建一個predict.py文件,內容如下
from ultralytics import YOLO
# 加載訓練好的模型,改為自己的路徑
model = YOLO('runs/detect/train/weights/best.pt')
# 修改為自己的圖像或者文件夾的路徑
source = 'test.jpg' #修改為自己的圖片路徑及文件名
# 運行推理,并附加參數
model.predict(source, save=True)模型轉換
參考鏈接:【YOLOv8部署至RK3588】模型訓練→轉換RKNN→開發板部署_yolov8轉rknn-CSDN博客
需要以下工具:ultralytics_yolov8、rknn_model_zoo、rknn-toolkit2,現在詳細介紹這三者的關系。
以上三個文件均與模型訓練無關,而是用于模型轉換的,其中,ultralytics_yolov8文件不是必需的,但最好還是下載一份,原因后面會講;在此,先將以上三個文件的鏈接放在這:
ultralytics_yolov8:https://github.com/airockchip/ultralytics_yolov8
rknn_model_zoo:https://github.com/airockchip/rknn_model_zoo
rknn-toolkit2:https://github.com/airockchip/rknn-toolkit2
另外說一下這三個文件的版本,全用最新的,rknn_model_zoo用v2.3.2,rknn-toolkit2也用v2.3.2,ultralytics_yolov8只有一個main版本,直接用即可
轉換步驟:
1.修改ultralytics_yolov8項目中的ultralytics/cfg/default.yaml,將其中的model參數路徑改成你訓練得到的的best.pt模型路徑
在虛擬環境下,裝轉換需要的環境
cd ultralytics-main
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e .
pip install onnx新建一個腳本文件:運行后會在?runs\detect\train\weights下生成best.onnx文件
#這里好像是后期轉換rknn,需要導出這樣的
from ultralytics import YOLO# Load a model
model = YOLO(r'E:\Projects\ultralytics_yolov8-main\data\runs\detect\train\weights\best.pt')
# Export the model
model.export(format='rknn',opset=12)#后期直接用onnx,好像用下面的
from ultralytics import YOLO# Load a model
model = YOLO(r'E:\Projects\ultralytics_yolov8-main\data\runs\detect\train\weights\best.pt')# 2. 導出為 ONNX
model.export(format="onnx", opset=12, dynamic=False, simplify=True, imgsz=640)
print("ONNX 模型導出完成!")同時生成onnx文件,這樣生成的模型output是4維的,后面可以直接轉換成rknn。
如果不在rk3588上用,只用onnx文件,之前測試和使用的模型是output都是三維的,所以上面的代碼是可以生成兩種不同的額模型
onnx轉rknn需要再Ubuntu虛擬機下轉換,篇幅限制,下節再講
?/替換模型,一般除了注意輸入輸出一致,還有其他要修改的嗎?)



:解密 SPI—— 從定義到核心特性)



)







)


