1、表空間文件結構
表空間由段「segment」、區「extent」、頁「page」、行「row」組成,InnoDB存儲引擎的邏輯存儲結構大致如下圖:
 行
行
數據庫表中的記錄都是按「行」進行存放的,每行記錄根據不同的行格式,有不同的存儲結構。
頁
記錄是按照行來存儲的,但是數據庫的讀取并不以「行」為單位,否則一次讀取(也就是一次 I/O 操作)只能處理一行數據,效率會非常低。
因此,InnoDB 的數據是按「頁」為單位來讀寫的,也就是說,當需要讀一條記錄的時候,并不是將這個行記錄從磁盤讀出來,而是以頁為單位,將其整體讀入內存。
默認每個頁的大小為 16KB,也就是最多能保證 16KB 的連續存儲空間。
頁是 InnoDB 存儲引擎磁盤管理的最小單元,意味著數據庫每次讀寫都是以 16KB 為單位的,一次最少從磁盤中讀取 16KB 的內容到內存中,一次最少把內存中的 16KB 內容刷新到磁盤中。
區
B+ 樹中每一層都是通過雙向鏈表連接起來的,如果是以頁為單位來分配存儲空間,那么鏈表中相鄰的兩個頁之間的物理位置并不是連續的,可能離得非常遠,那么磁盤查詢時就會有大量的隨機 I/O,隨機 I/O 是非常慢的。
【怎么解決呢?】
在表中數據量大的時候,為某個索引分配空間的時候就不再按照頁為單位分配了,而是按照「區」為單位分配。每個區的大小為 1MB,對于 16KB 的頁來說,連續的 64 個頁會被劃為一個區,這樣就使得鏈表中相鄰的頁的物理位置也相鄰,就能使用順序 I/O 了。
段
表空間是由各個段組成的,段是由多個區組成的。段一般分為「數據段」、「索引段」和「回滾段」等。
- 索引段:存放 B + 樹的非葉子節點的區的集合。
- 數據段:存放 B + 樹的葉子節點的區的集合。
- 回滾段:存放的是回滾數據的區的集合,MVCC 利用了回滾段實現了多版本查詢數據。
2、InnoDB 行格式
有下面 4 種行格式:
- Redundant:MySQL 5.0 版本之前用的行格式,不緊湊。
- Compact:MySQL 5.1 版本之后,行格式默認設置成 Compact。一種緊湊的行格式,可以讓一頁存儲更多行記錄。
- Dynamic 和 Compressed:從 MySQL5.7 版本之后,默認使用 Dynamic 行格式。 兩個都是緊湊的行格式,它們的行格式都和 Compact 差不多,都是基于 Compact 改進一點東西。
COMPACT 行格式
記錄的額外信息
1. 變長字段長度列表
varchar(n)和char(n)的區別:char是定長的,varchar是變長的,變長字段實際存儲的數據的長度(大小)不固定的。
在存儲數據的時候,要把數據占用的大小存起來,存到「變長字段長度列表」里面,讀取數據的時候才能根據這個「變長字段長度列表」去讀取對應長度的數據。其他 TEXT、BLOB 等變長字段也是這么實現的。
【示例】創建下面表進行演示:
假設有下面三條記錄:

第一條記錄「只看變長字段」:
name字段值為a,占 1 字節。phone字段值為123,占 3 字節。
這些變長字段的真實數據占用的字節數會按照列的順序 逆序存放,所以「變長字段長度列表」里的內容是「 03 01」,而不是 「01 03」。
同理,第二條記錄: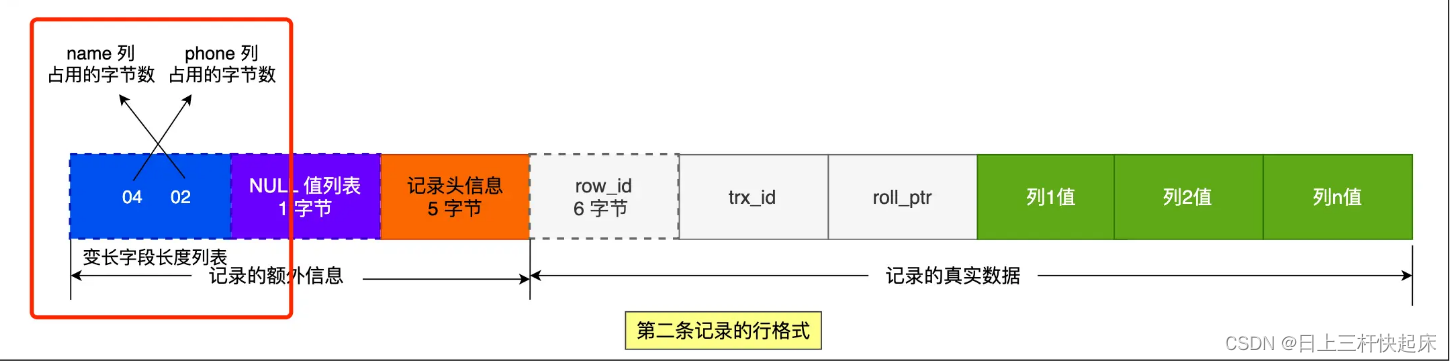
第三條記錄 中 phone 列的值是 NULL,NULL 是不會存放在行格式中記錄的真實數據部分里的,所以「變長字段長度列表」里不需要保存值為 NULL 的變長字段的長度。
【為什么「變長字段長度列表」的信息要按照逆序存放】
因為「記錄頭信息」中指向下一個記錄的指針,指向的是下一條記錄的「記錄頭信息」和「真實數據」之間的位置,這樣的好處是向左讀就是記錄頭信息,向右讀就是真實數據,比較方便。
「變長字段長度列表」中的信息之所以要逆序存放,是因為這樣可以使得位置靠前的記錄的真實數據和數據對應的字段長度信息可以同時在一個 CPU Cache Line 中,這樣就可以提高 CPU Cache 的命中率。
當數據表沒有變長字段的時候,比如全部都是 int 類型的字段,這時候表里的行格式就不會有「變長字段長度列表」了,因為沒必要,不如去掉以節省空間。
所以「變長字段長度列表」只出現在數據表有變長字段的時候。
2. NULL 值列表
表中的某些列可能會存儲 NULL 值,如果把這些 NULL 值都放到記錄的真實數據中會比較浪費空間,所以 Compact 行格式把這些值為 NULL 的列存儲到 NULL 值列表中。
如果存在允許 NULL 值的列,則每個列對應一個二進制位(bit),二進制位按照列的順序逆序排列。
- 二進制位的值為
1時,代表該列的值為 NULL。 - 二進制位的值為
0時,代表該列的值不為 NULL。
另外,NULL 值列表必須用整數個字節的位表示(1字節8位),如果使用的二進制位個數不足整數個字節,則在字節的高位補 0。
當一條記錄有 9 個字段值都是 NULL,那么就會創建 2 字節空間的「NULL 值列表」,以此類推。
當數據表的字段都定義成 NOT NULL 的時候,這時候表里的行格式就不會有 NULL 值列表了。
所以在設計數據庫表的時候,通常都是建議將字段設置為 NOT NULL,這樣可以至少節省 1 字節的空間(NULL 值列表至少占用 1 字節空間)。
【舉例】以上面表舉例:
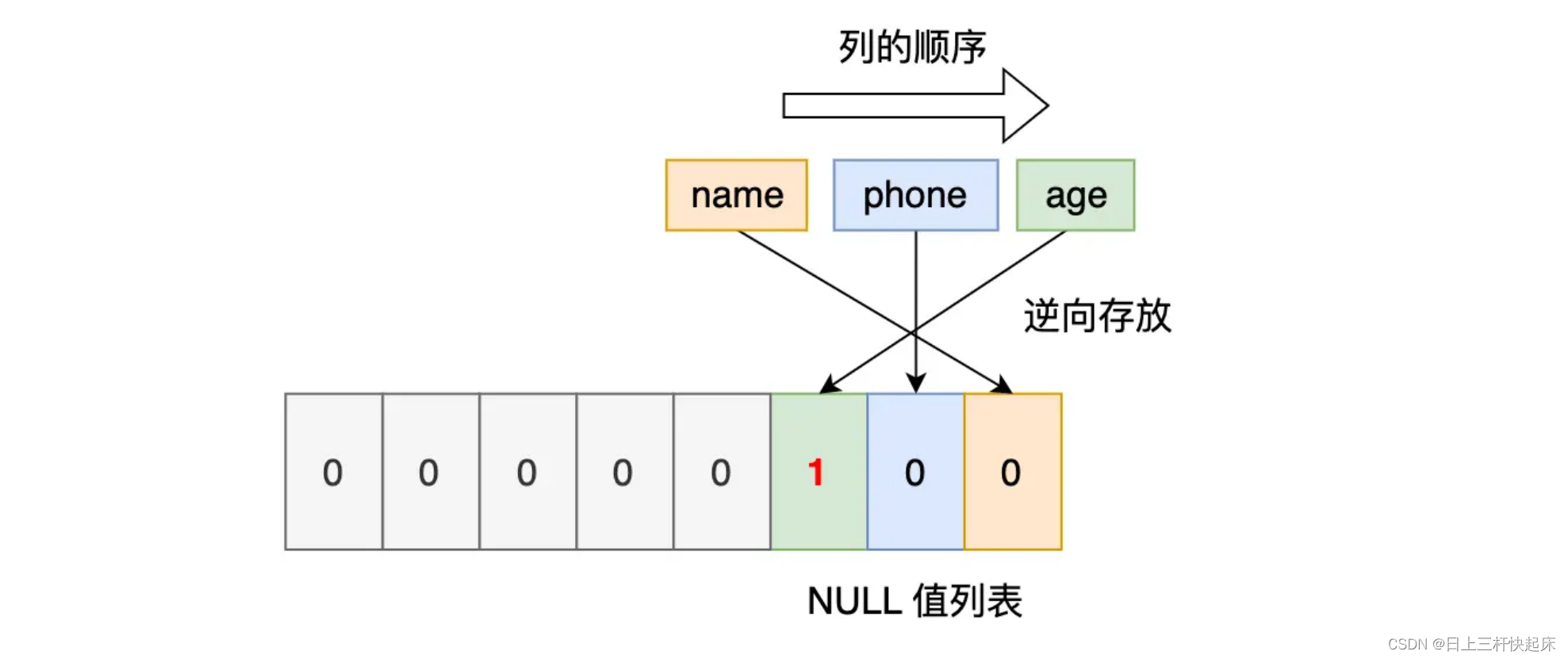
 第一條記錄:
第一條記錄:

但是 InnoDB 是用整數字節的二進制位來表示 NULL 值列表的,現在不足 8 位,所以要在高位補 0,最終用二進制來表示:

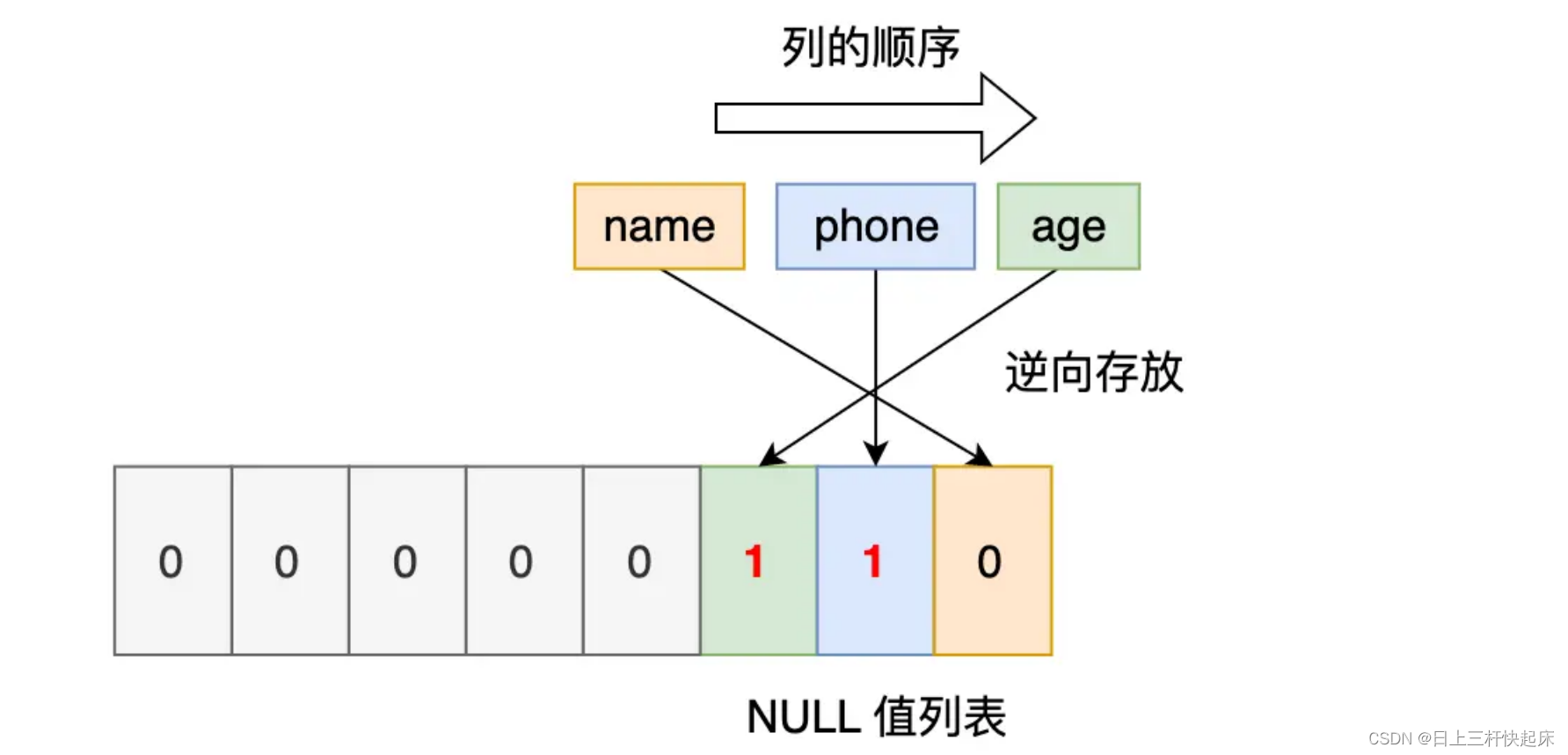
第二條記錄:
第三條記錄 phone 列 和 age 列是 NULL 值,所以,對于第三條數據,NULL 值列表用十六進制表示是 0x06。
?NULL 值列表填充完畢后,行格式為下面這樣:
3. 記錄頭信息
列舉比較重要的幾個:
- delete_mask:標識此條數據是否被刪除。執行
detele刪除記錄的時候,并不會真正的刪除記錄,只是將這個記錄的 「delete_mask」標記為 1 - next_record:下一條記錄的位置。記錄與記錄之間是通過鏈表組織的,指向的是下一條記錄的「記錄頭信息」和「真實數據」之間的位置,這樣的好處是向左讀就是記錄頭信息,向右讀就是真實數據,比較方便。
- record_type:表示當前記錄的類型,0 表示普通記錄,1 表示 B+ 樹非葉子節點記錄,2 表示最小記錄,3 表示最大記錄。
記錄的真實數據
記錄真實數據部分除了自定義的字段,還有三個隱藏字段,分別為:row_id、trx_id、roll_pointer。
-
row_id:建表的時候指定了主鍵或者唯一約束列,那么就沒有 row_id 隱藏字段了。如果既沒有指定主鍵,又沒有唯一約束,那么 InnoDB 就會為記錄添加 row_id 隱藏字段。row_id 不是必需的,占用 6 個字節。
-
trx_id:事務id,表示這個數據是由哪個事務生成的。 trx_id 是必需的,占用 6 個字節。
-
roll_pointer:這條記錄上一個版本的指針。roll_pointer 是必需的,占用 7 個字節。
MVCC 機制就跟 trx_id 和 roll_pointer 的作用有關。
varchar(n) 中的 n 最大取值
MySQL 規定除了 TEXT、BLOBs 這種大對象類型之外,其他所有的列(不包括隱藏列和記錄頭信息)占用的字節長度「加起來」不能超過 65535 個字節。
varchar(n) 字段類型的 n 代表的是最多存儲的字符數量,并不是字節大小。
要算 varchar(n) 最大能允許存儲的字節數,還要看數據庫表的字符集,因為字符集代表著:1個字符要占用多少字節,比如 ascii 字符集, 1 個字符占用 1 字節,那么 varchar(100) 意味著最大能允許存儲 100 字節的數據。
【單字段情況】
在算 varchar(n) 中 n 最大值時,需要減去 「變長字段長度列表」和 「NULL 值列表」所占用的字節數的。
【多字段情況】
如果有多個字段的話,要保證「所有字段的長度 + 變長字段字節數列表所占用的字節數 + NULL值列表所占用的字節數」 <= 65535。
行溢出后,如何存儲數據
如果一個數據頁存不了一條記錄,InnoDB 存儲引擎會自動將溢出的數據存放到「溢出頁」中。
在記錄的真實數據處只會保存該列的一部分數據,而把剩余的數據放在「溢出頁」中,然后「真實數據」處用 20 字節存儲指向溢出頁的地址,從而可以找到剩余數據所在的頁。
?轉載:MySQL 一行記錄是怎么存儲的? | 小林coding (xiaolincoding.com)




)

——Netty入門)












)