研究背景與動機?
- ?問題?:傳統目標檢測器(封閉集)需預定義所有類別,無法適應動態開放環境。現有研究多獨立解決開放詞匯檢測(OVD)或開放世界檢測(OWOD),未結合兩者優勢:
- ?OVD?:通過文本-視覺嵌入匹配實現零樣本泛化,但無法主動發現未知對象。
- ?OWOD?:可主動檢測未知對象并通過增量學習逐步優化,但缺乏零樣本能力。
- ?目標?:提出統一框架 ?OW-OVD,兼具OVD的零樣本泛化能力和OWOD的主動發現與持續學習能力。

?核心方法?
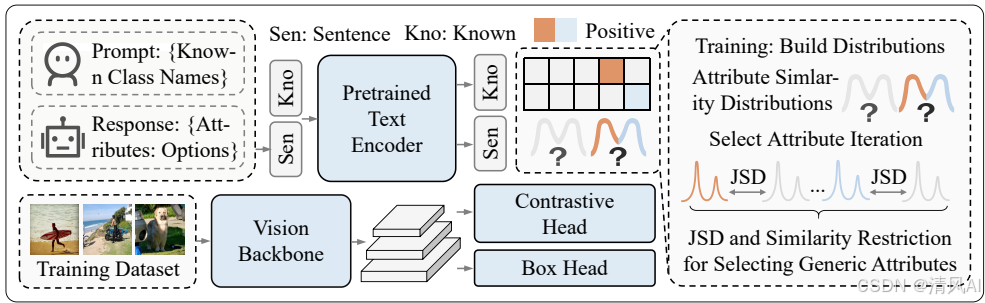
1. ?模型架構?
- 基于標準OVD檢測器(YOLO-World),包含視覺編碼器(提取圖像特征)和文本編碼器(生成類別/屬性嵌入)。
- 訓練流程分兩步:
- ?分布構建?:計算屬性與正/負樣本區域的相似性分布。
- ?屬性選擇?:通過迭代選擇最具泛化性的屬性。


)







)








