ODConv:在卷積核所有維度(數量、空間、輸入、輸出)上應用注意力機制來優化傳統的動態卷積
- 提出背景
- 傳統動態卷積
- 全維動態卷積
- 效果
- 小目標漲點
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
?
論文:https://openreview.net/pdf?id=DmpCfq6Mg39
代碼:https://github.com/OSVAI/ODConv
?
提出背景
在過去的十年里,我們見證了深度卷積神經網絡(CNN)在許多計算機視覺應用中的巨大成功。
構建深度CNN的最常見方法是堆疊多個卷積層以及其他基本層,并預先定義特征連接拓撲。
通過手工工程和自動搜索對CNN架構設計的巨大進步,許多流行的分類骨架已經被提出。
最近的工作表明,將注意力機制融入卷積塊可以進一步提高現代CNN的性能。
問題1:提高CNN性能
- 解法:引入注意力機制。
- 之所以使用這個解法,是因為注意力機制可以加強CNN通過鼓勵有用的特征通道同時抑制不重要的特征通道,從而提高表示能力。
問題2:動態卷積的設計限制
- 子解法1:多維度注意力機制(ODConv)
- 之所以使用ODConv,是因為現有的動態卷積方法只關注卷積核數量的一個維度,而忽略了卷積核空間的其他三個維度(空間大小、輸入通道數和輸出通道數),限制了捕獲豐富上下文線索的能力。
- 子解法2:減少模型大小
- 之所以使用這個子解法,是因為傳統的動態卷積在替換常規卷積時會增加n倍的卷積參數,導致模型大小大幅增加。通過動態卷積分解方法,可以獲得更緊湊且競爭力的模型。
傳統動態卷積
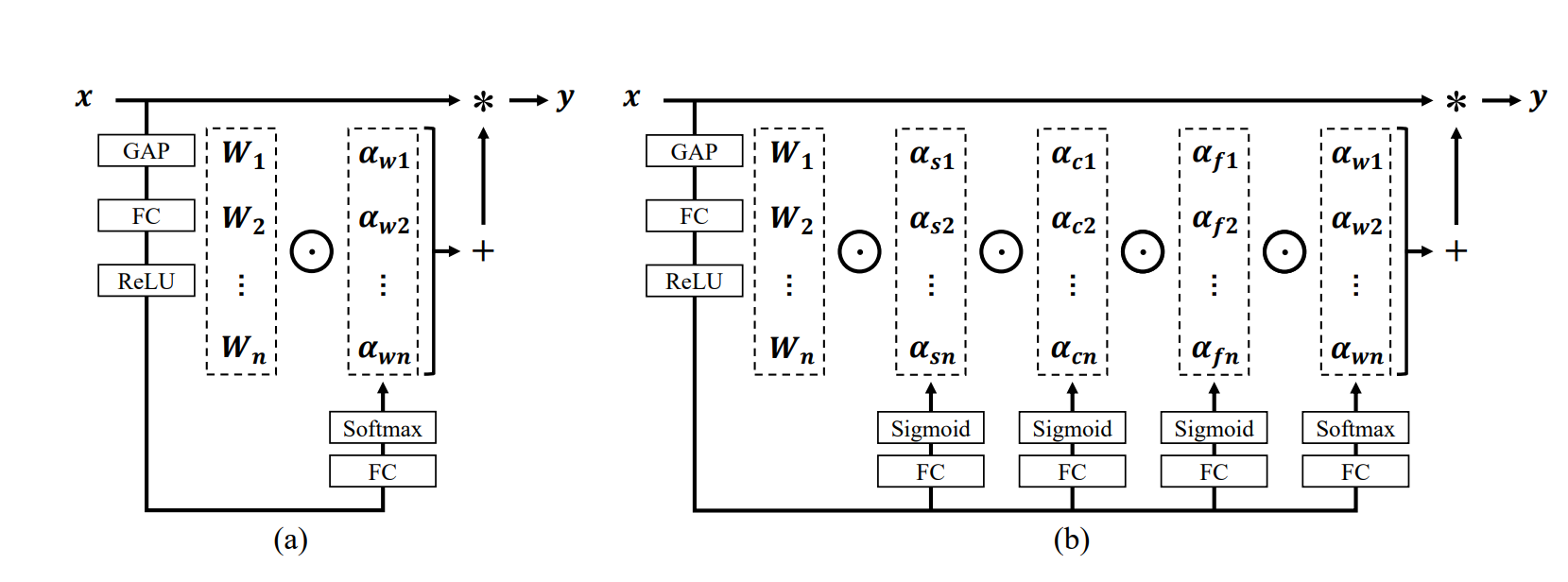
上圖是 DyConv(a 傳統的動態卷積)和ODConv(b 本文的全維動態卷積)的結構圖比較。
在DyConv中,使用全局平均池化(GAP)、全連接層(FC)和Sigmoid激活函數來計算單個注意力標量 α w i αw_i αwi?,這個標量用于加權卷積核 W i W_i Wi?。
相比之下,ODConv采用了更復雜的多維度注意力機制來計算四種類型的注意力( α s i , α c i , α f i , 和 α w i αs_i, αc_i, αf_i, 和 αw_i αsi?,αci?,αfi?,和αwi?),這些注意力分別對應于卷積核空間的不同維度。
四個不同的注意力通過四個分支生成,并通過Sigmoid或Softmax函數進行歸一化。
這些注意力分別沿著卷積核空間的空間維度、輸入通道維度、輸出通道維度和卷積核數量維度被計算出來,并且以并行的方式應用于卷積核。
?
全維動態卷積
ODConv通過在任何卷積層利用新穎的多維度注意力機制來學習卷積核空間所有四個維度上的四種注意力,這些注意力相互補充,逐步應用它們可以顯著增強CNN的基本卷積操作的特征提取能力。
讓我們以ODConv在任何卷積層利用新穎的多維度注意力機制來學習卷積核空間所有四個維度上的四種注意力為例,舉一個具體的應用場景來說明這種方法的有效性。
ODConv解法:
-
子特征1:空間尺寸注意力。ODConv學習不同空間尺寸的卷積核的重要性,從而能夠更好地捕捉圖像的局部和全局特征。之所以使用空間尺寸注意力,是因為不同大小的特征圖對于捕獲圖像中的不同尺度信息至關重要。
-
子特征2:輸入通道注意力。通過調整對不同輸入通道的關注程度,ODConv可以更有效地整合來自不同特征通道的信息。之所以使用輸入通道注意力,是因為不同的特征通道可能包含不同的信息,對最終的識別任務有不同的貢獻。
-
子特征3:輸出通道注意力。ODConv通過學習對輸出通道的不同關注,優化了特征的表示。之所以使用輸出通道注意力,是為了強化模型的能力,以區分和識別圖像數據集中的細粒度類別。
-
子特征4:卷積核數量注意力。通過動態調整不同卷積核的權重,ODConv能夠根據輸入圖像的特征自適應地選擇最適合的卷積核組合。之所以使用卷積核數量注意力,是因為它允許模型根據輸入特征的復雜度動態調整其表示能力,從而在保持效率的同時提高準確性。
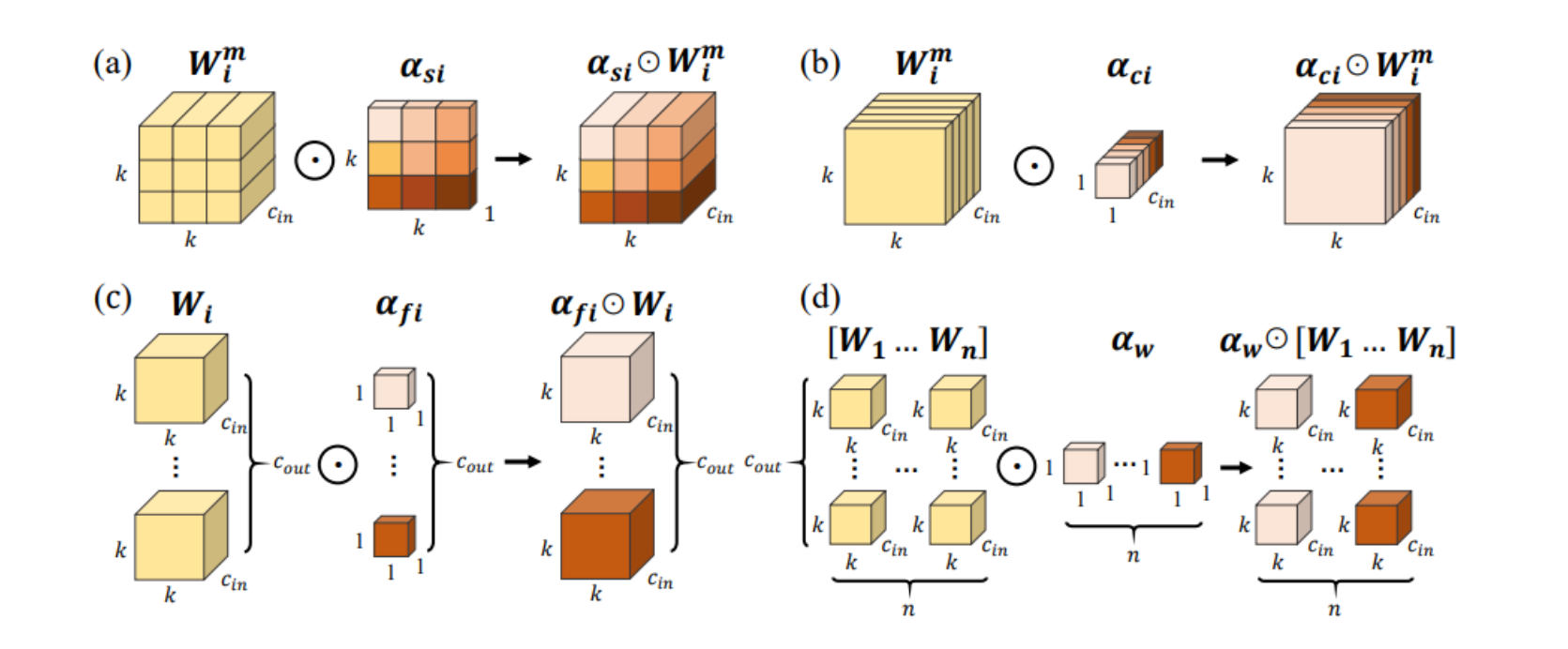
(a) αs_i:空間維度注意力,它將不同的權重分配給卷積核的每個空間位置。
(b) αc_i:輸入通道維度注意力,它將不同的權重分配給卷積核的每個輸入通道。
? αf_i:輸出通道維度注意力,它將不同的權重分配給卷積核的每個輸出濾波器。
(d) αw_i:卷積核維度注意力,它將一個整體的權重分配給整個卷積核集合。
因此,即使是使用單個卷積核的ODConv也能與現有的具有多個卷積核的動態卷積對手競爭或勝出,大大減少了額外的參數。
ODConv可以作為一種插入式設計用于替代許多CNN架構中的常規卷積,與現有的動態卷積設計相比,它在模型準確性和效率之間取得了更好的平衡。
?
在傳統的CNN中,每個卷積層都使用固定的卷積核來處理輸入的圖像或特征圖,這意味著無論輸入數據如何,都會應用相同的卷積核。
然而,這種方法并不總是最優的,因為不同的輸入圖像可能需要不同的特征提取方式來更好地識別物體。
ODConv通過引入一種新穎的多維度注意力機制來解決這個問題。
具體來說,它在任何給定的卷積層中,不僅僅學習一個卷積核,而是學習一組卷積核,每個卷積核都針對卷積核空間的一個特定維度(如卷積核的空間尺寸、輸入通道數、輸出通道數和卷積核數量)。
然后,它使用輸入特征動態地決定這些卷積核的注意力權重,使得網絡能夠根據輸入圖像的不同特征自適應地調整其卷積操作。
例如,如果輸入圖像是一只貓,ODConv可能會賦予識別貓特征(如毛發紋理或尾巴形狀)更有用的卷積核更高的注意力權重。
相反,如果輸入圖像是一只鳥,它可能會增加那些能夠捕捉到鳥的特征(如羽毛或翅膀形狀)的卷積核的權重。
通過這種方式,ODConv能夠為每個輸入圖像動態地優化其卷積操作,從而在不同的圖像分類任務中實現更高的準確性,同時減少了需要的額外參數數量,因為它甚至可以使用單個卷積核與現有的多卷積核動態卷積方法競爭或超越它們的性能。
效果
ODConv的核心原理是引入一種全新的多維度注意力機制,這種機制不僅考慮卷積核的數量維度(如傳統的動態卷積所做的),而且還同時考慮卷積核的空間維度、輸入通道維度和輸出通道維度。
這種方法允許網絡根據輸入數據的具體特點,在多個層面上動態調整其卷積核的權重,從而提高特征提取的能力。
ODConv通過在所有卷積核維度上應用注意力機制來優化傳統的動態卷積,這樣做可以提供更精細的特征處理能力,并提高模型對輸入數據變化的適應性和敏感性。
這種細粒度的動態調整使得ODConv能夠在增加很少或沒有額外計算成本的情況下,提高模型的準確性和效率。
通過在輕量級CNN模型中應用ODConv,我們可以顯著提高模型對圖像的識別準確率,而不會帶來太多的額外計算成本。
例如,將ODConv集成到MobileNetV2中,可能會在ImageNet測試集上獲得比原始模型更高的分類準確率,同時保持模型的輕量級特性。
這種方法通過綜合考慮卷積核的所有維度上的注意力,有效地增強了特征的表達力,解決了輕量級CNN在復雜任務上性能不足的問題。
小目標漲點
更新中…
)
2024.02.29:UCOSIII第二節)












測評體驗)




