原文地址:FinalMLP: A Simple yet Powerful Two-Stream MLP Model for Recommendation Systems
了解 FinalMLP 如何轉變在線推薦:通過尖端 AI 研究解鎖個性化體驗
2024 年 2 月 14 日
介紹
世界正在向數字時代發展,在這個時代,每個人都可以通過點擊距離獲得幾乎所有他們想要的東西。可訪問性、舒適性和大量的產品為消費者帶來了新的挑戰。我們如何幫助他們獲得個性化的選擇,而不是在浩瀚的選擇海洋中搜索?這就是推薦系統的用武之地。
推薦系統可以幫助組織增加交叉銷售和長尾產品的銷售,并通過分析客戶最喜歡什么來改進決策。不僅如此,他們還可以學習過去的客戶行為,給定一組產品,根據特定的客戶偏好對它們進行排名。使用推薦系統的組織在競爭中領先一步,因為它們提供了增強的客戶體驗。
在本文中,我們將重點介紹FinalMLP,這是一個旨在提高在線廣告和推薦系統中點擊率(CTR)預測的新模型。通過將兩個多層感知器(MLP)網絡與門控和交互聚合層等高級功能集成在一起,FinalMLP優于傳統的單流MLP模型和復雜的雙流CTR模型。作者通過基準數據集和現實世界的在線A/B測試測試了它的有效性。
除了提供FinalMLP及其工作原理的詳細視圖外,我們還提供了實現和將其應用于公共數據集的演練。我們在一個圖書推薦設置中測試了它的準確性,并評估了它解釋預測的能力,利用作者提出的兩流架構。
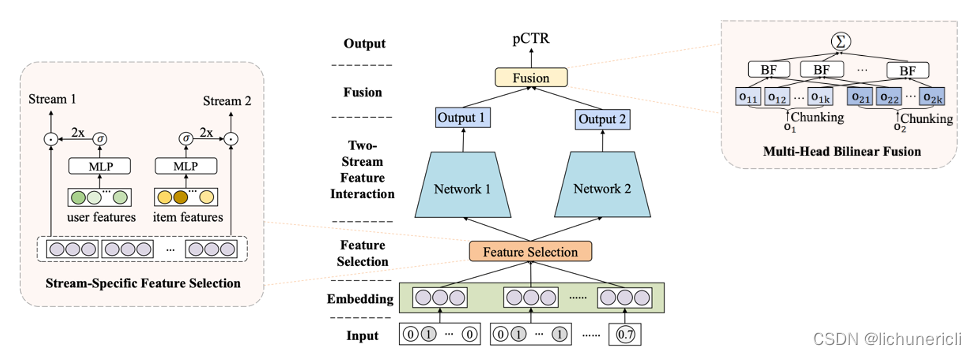
FinalMLP: (F)特征門控層和(IN)交互層(A)聚合層(L)在兩個mlp之上
FinalMLP[1]是建立在DualMLP[2]之上的兩流多層感知器(MLP)模型,通過引入兩個新概念對其進行增強:
- 基于門控的特征選擇增加了兩個流之間的區別,使每個流專注于從不同的特征集學習不同的模式。例如,一個流側重于處理用戶特征,而另一個流側重于處理項目特征。
- 多頭雙線性融合改進了兩個流的輸出如何通過建模特征交互進行組合。使用依賴于求和或串聯等線性操作的傳統方法可能不會發生這種情況。
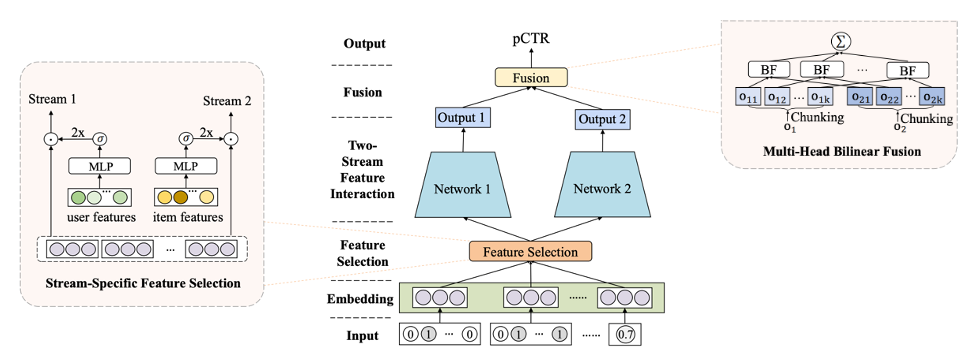
Figure 2: FinalMLP architecture (source)
它是如何工作的?
如前所述,FinalMLP是由兩個簡單并行的MLP網絡組成的兩流CTR模型,從不同的角度學習特征交互,它由以下關鍵組件組成:
特征embedding?層是一種將高維和稀疏的原始特征映射到密集數字表示的常用方法。無論是分類的、數值的還是多值的,每個特征都被轉換成一個embedding向量并連接起來,然后再輸入feature Selection模塊。
將Categorical Features轉換為單熱特征向量,并與詞匯量n、embedding維數d的可學習embedding矩陣相乘,生成其嵌入[3]。
數值特征可以通過以下方式轉換為嵌入:1)將數值存儲為離散特征,然后將它們作為分類特征處理,或者2)給定標準化標量值xj,embedding可以作為xj與vj?的乘法,?vj?是j域中所有特征的共享embedding向量[3].
多值?f特征可以表示為將值序列轉換為長度為k的單熱編碼向量(k為序列的最大長度),然后乘以一個可學習的embedding矩陣來生成其嵌入[3]。
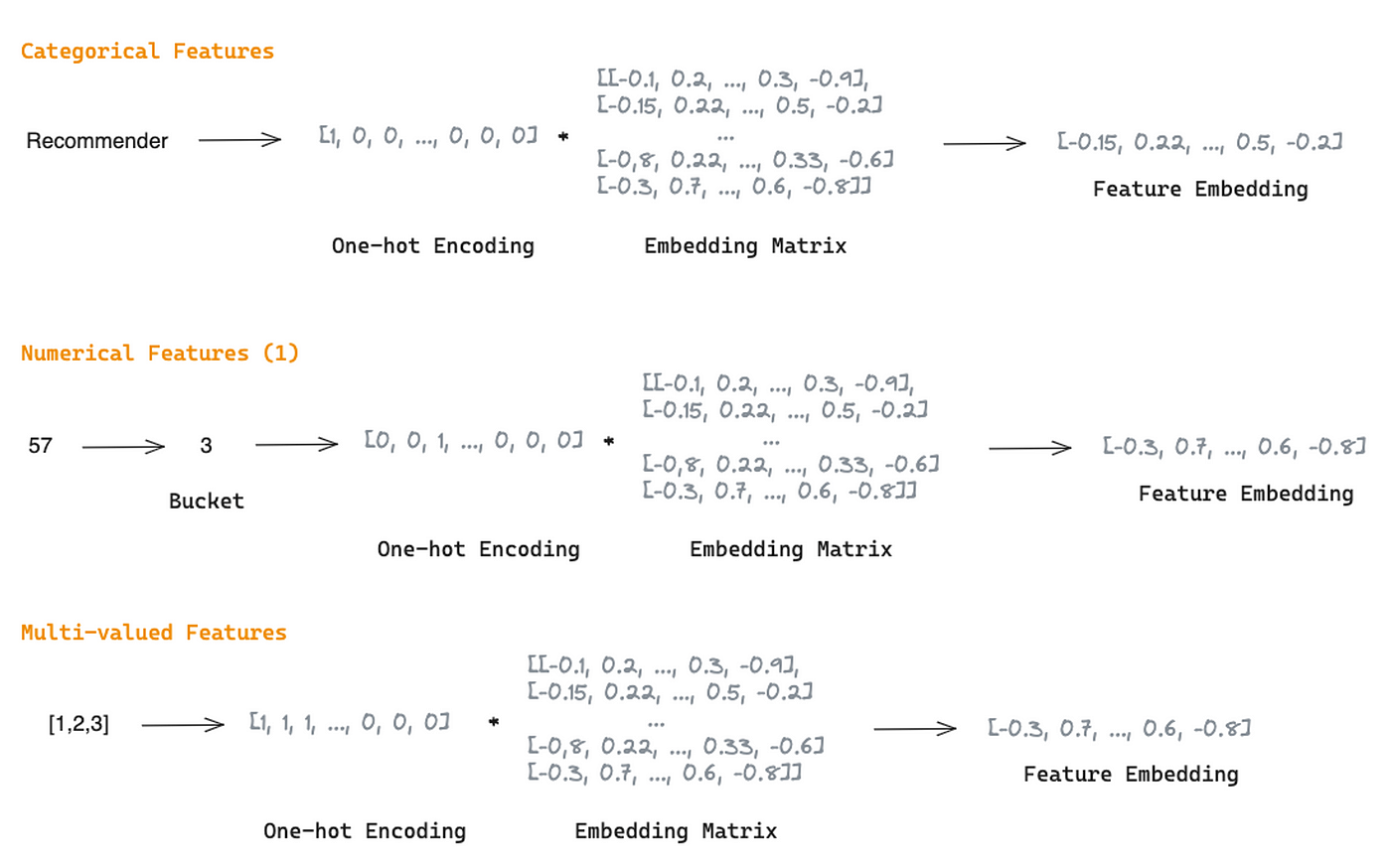
圖3:每種特征類型的embedding創建(由作者提供的圖像)
The feature Selection Layer用于獲取特征重要性權重,以抑制噪聲特征,使重要特征對模型預測的影響更大。
如前所述,FinalMLP使用基于門控的特征選擇,這是一個帶有門控機制的MLP。它接收嵌入作為輸入,并產生與輸入相同維數的權重向量。特征重要性權重是通過對權重向量應用sigmoid函數,然后對乘數2進行乘數,生成一個范圍為[0,2]的向量來獲得的。然后通過特征embedding與特征重要性權重的逐元素積得到加權特征。
這個過程減少了兩個流之間的同質學習,使特征交互的學習更加互補。它被獨立地應用于每個流,以區分每個流的特征輸入,并允許它們專注于用戶或項目維度。
圖4:使用獨立MLP的特征選擇過程,每個流都有一個門控機制(圖片來自作者)
流級融合層需要結合兩個流的輸出,以獲得最終的預測概率。通常,組合兩個輸出依賴于求和或連接操作。然而,FinalMLP的作者提出了一個雙線性交互聚合層,將兩個輸出結合起來,從特征交互中獲得線性組合可能無法獲得的信息。
受transformers結構中的注意力層的啟發,作者將雙線性融合擴展為多頭雙線性融合層。它用于降低計算復雜度和提高模型的可擴展性。
雙線性融合方程包括:
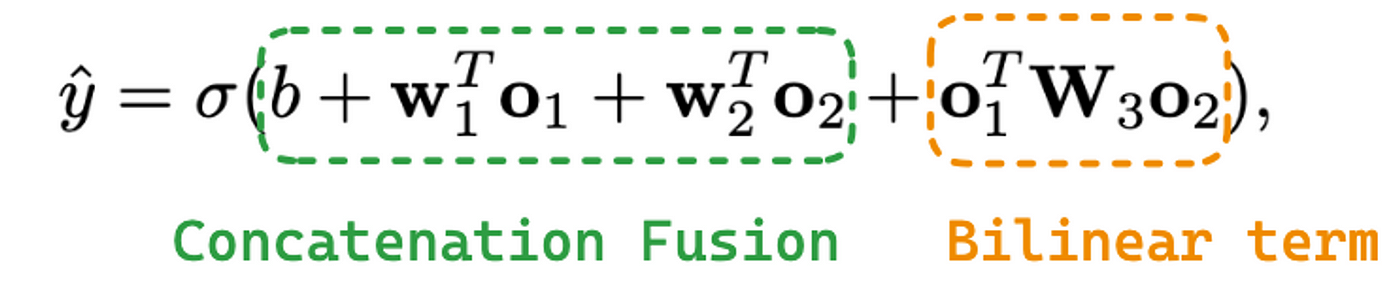
方程1:雙線性融合方程
其中σ是一個s型函數,b是偏置項,01是一個流的輸出。w1是要應用到o1的可學習權值,o2是另一個流的輸出,w2是要應用到o2的可學習權值。最后,w3為提取特征交互信息的雙線性項中的可學習矩陣。如果將w3設置為零矩陣,則退化為傳統的串聯融合。
雙線性融合和多頭雙線性融合的區別在于,它不是使用來自兩個流的整個向量應用雙線性融合,而是將輸出o1和o2chunks到k子空間中。在每個子空間中進行雙線性融合,聚合并饋送s型函數以產生最終概率。
圖5:多頭雙線性融合的實踐(圖片來源:作者)
使用FinalMLP創建圖書推薦模型
在本節中,我們將在許可CC0:公共領域下的Kaggle的公共數據集上實現FinalMLP。該數據集包含有關用戶、圖書以及用戶對圖書的評分的信息。
該數據集由以下內容組成:
User-ID?—用戶標識Location?—以逗號分隔的字符串,包含用戶所在的城市、州和國家Age?— 用戶的年齡ISBN?— 圖書標識符Book-Rating?— 用戶對某本書的評分Book-Title?— 書的標題Book-Author?— 書的作者Year-of-Publication?— 該書出版的年份Publisher?— 出版這本書的編輯
我們將根據與每個用戶的相關性對圖書進行排名。之后,我們使用歸一化貼現累積增益(nDCG)將我們的排名與實際排名進行比較(根據用戶給出的評級對圖書進行排序)。
nDCG是一種評估推薦系統質量的度量標準,它根據結果的相關性來衡量結果的排名。它考慮每個項目的相關性及其在結果列表中的位置,排名越高,重要性越大。nDCG的計算方法是將折扣累積收益(DCG)與理想DCG (iDCG)進行比較,后者是將排名較低的物品的收益進行折扣,而理想DCG是給出完美排名的最高可能DCG。這個標準化分數的范圍在0到1之間,其中1表示理想的排名順序。因此,nDCG為我們提供了一種理解系統如何有效地向用戶呈現相關信息的方法。
我們從導入庫開始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | %matplotlib inline %load_ext autoreload %autoreload 2 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np import random from sklearn.metrics import ndcg_score from sklearn.decomposition import PCA from sentence_transformers import SentenceTransformer import os import logging from fuxictr.utils import load_config, set_logger, print_to_json from fuxictr.features import FeatureMap from fuxictr.pytorch.torch_utils import seed_everything from fuxictr.pytorch.dataloaders import H5DataLoader from fuxictr.preprocess import FeatureProcessor, build_dataset import src import gc import os |
然后,我們加載三個數據集并將它們合并為一個數據集:
1 2 3 4 5 6 | books_df = pd.read_csv('data/book/Books.csv')
users_df = pd.read_csv('data/book/Users.csv')
ratings_df = pd.read_csv('data/book/Ratings.csv')df = pd.merge(users_df, ratings_df, on='User-ID', how='left')
df = pd.merge(df, books_df, on='ISBN', how='left')
|
之后,我們進行一些探索性數據分析,以識別數據中的問題:
- 刪除用戶對書沒有評價的地方。
1 | df = df[df['Book-Rating'].notnull()] |
- 檢查缺失的值并將缺失的
Book-Author和Publisher替換為unknown類別。
1 2 3 4 | print(df.columns[df.isna().any()].tolist())df['Book-Author'] = df['Book-Author'].fillna('unknown')
df['Publisher'] = df['Publisher'].fillna('unknown')
|
- 刪除書中缺失信息的評論。
1 | df = df[df['Book-Title'].notnull()] |
- 將非整數’出版年份’替換為空值。
1 | df['Year-Of-Publication'] = pd.to_numeric(df['Year-Of-Publication'], errors='coerce') |
- 檢查“年齡”、“出版年份”和“圖書評級”分布,以識別異常情況。
1 2 3 4 5 6 7 8 9 10 11 | plt.rcParams["figure.figsize"] = (20,3)
sns.histplot(data=df, x='Age')
plt.title('Age Distribution')
plt.show()sns.histplot(data=df, x='Year-Of-Publication')
plt.title('Year-Of-Publication Distribution')
plt.show()
sns.histplot(data=df, x='Book-Rating')
plt.title('Book-Rating Distribution')
plt.show()
|
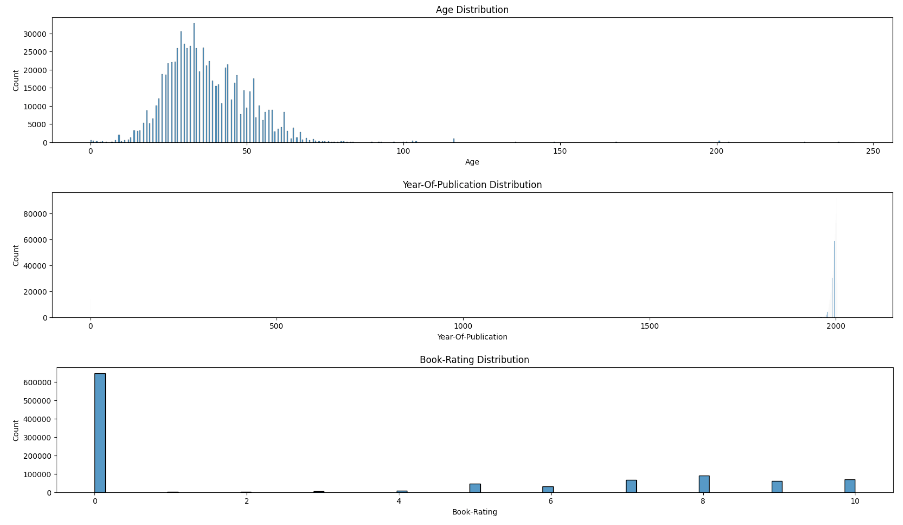
圖6:數據分布(作者圖片)
最后,我們通過以下方式清理數據:
- 替換
age > 100?(這似乎是一個錯誤),丟失的值稍后處理。 - 將上限限制為2021年,因為這是數據集在Kaggle中發布的時間,并將
Year-of-Publication <= 0?替換為稍后處理的缺失值。 - 刪除
rating = 0的觀察,因為這些書被用戶閱讀但沒有評級。 - 從“位置”創建3個新功能(“城市”,“州”,“國家”)。既然城市太吵了,我們就不去了。
- 為FinalMLP創建一個二進制標簽,我們考慮與用戶相關的率高于7的書籍。
1 2 3 4 5 6 7 8 | df['Age'] = np.where(df['Age'] > 100, None, df['Age'])df['Year-Of-Publication'] = np.where(df['Year-Of-Publication'].clip(0, 2021) <= 0, None, df['Year-Of-Publication'])
df = df[df['Book-Rating'] > 0]
df['city'] = df['Location'].apply(lambda x: x.split(',')[0].strip()) # too noisy, we will not use
df['state'] = df['Location'].apply(lambda x: x.split(',')[1].strip())
df['country'] = df['Location'].apply(lambda x: x.split(',')[2].strip())
df['label'] = (df['Book-Rating'] > 7)*1
|
清理數據集后,我們將數據分為訓練、驗證和測試,隨機選擇70%的用戶進行訓練,10%的用戶進行驗證,20%的用戶進行測試。
1 2 3 4 5 6 7 8 9 10 11 12 13 | # create list with unique users users = df['User-ID'].unique()# shuffle list random.shuffle(users) # create list of users to train, to validate and to test train_users = users[:int(0.7*len(users))] val_users = users[int(0.7*len(users)):int(0.8*len(users))] test_users = users[int(0.8*len(users)):] # train, val and test df train_df = df[df['User-ID'].isin(train_users)] val_df = df[df['User-ID'].isin(val_users)] test_df = df[df['User-ID'].isin(test_users)] |
在將數據輸入模型之前,我們將對數據進行一些預處理:
我們使用多語言編碼器為文本特征Book-Title創建嵌入,并使用PCA降低維度,解釋了80%的方差。
我們使用多語言編碼器,因為標題是用不同的語言編寫的。請注意,我們首先提取不同的Book-title,以便在用戶多于另一本書時不影響降維。
1 2 3 4 5 6 7 8 9 10 11 12 13 | # create embeddings train_embeddings = utils.create_embeddings(train_df.copy(), "Book-Title") val_embeddings = utils.create_embeddings(val_df.copy(), "Book-Title") test_embeddings = utils.create_embeddings(test_df.copy(), "Book-Title")# reduce dimensionality with PCA train_embeddings, pca = utils.reduce_dimensionality(train_embeddings, 0.8) val_embeddings = pca.transform(val_embeddings) test_embeddings = pca.transform(test_embeddings) # join embeddings to dataframes train_df = utils.add_embeddings_to_df(train_df, train_embeddings, "Book-Title") val_df = utils.add_embeddings_to_df(val_df, val_embeddings, "Book-Title") test_df = utils.add_embeddings_to_df(test_df, test_embeddings, "Book-Title") |
我們用中值填充數值特征的缺失值,并使用MinMaxScaler對數據進行歸一化。
1 2 3 4 5 6 7 8 | # set numerical columns NUMERICAL_COLUMNS = [i for i in train_df.columns if "Book-Title_" in i] + ['Age', 'Year-Of-Publication']# define preprocessing pipeline and transform data pipe = utils.define_pipeline(NUMERICAL_COLUMNS) train_df[NUMERICAL_COLUMNS] = pipe.fit_transform(train_df[NUMERICAL_COLUMNS]) val_df[NUMERICAL_COLUMNS] = pipe.transform(val_df[NUMERICAL_COLUMNS]) test_df[NUMERICAL_COLUMNS] = pipe.transform(test_df[NUMERICAL_COLUMNS]) |
準備好提供給FinalMLP的所有數據后,我們必須創建兩個yaml配置文件:dataset_config.yaml和model_config.yaml。
dataset_config.yaml負責定義模型中使用的特性。此外,它還定義了它們的數據類型(它們在embedding層中的處理方式不同)以及到訓練集、驗證集和測試集的路徑。你可以看到配置文件的主要部分如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | FinalMLP_book:data_root: ./data/book/feature_cols:- active: truedtype: floatname: [Age, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3, Book-Title_4, Book-Title_5, Book-Title_6, Book-Title_7,Book-Title_8, ...]type: numeric- active: truedtype: strname: [Book-Author, Year-Of-Publication, Publisher, state, country]type: categoricalfill_na: unknownlabel_col: {dtype: float, name: label}min_categr_count: 1test_data: ./data/book/test.csvtrain_data: ./data/book/train.csvvalid_data: ./data/book/valid.csv
|
model_config.yaml負責設置模型的超參數。您還必須定義哪些流將處理用戶特性,哪些流將處理項目特性。該文件應定義如下:
1 2 3 4 5 6 | FinalMLP_book:dataset_id: FinalMLP_bookfs1_context: [Age, state, country]fs2_context: [Book-Author, Year-Of-Publication, Publisher, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3,Book-Title_4, Book-Title_5, ...]model_root: ./checkpoints/FinalMLP_book/ |
我們回到Python并加載最近創建的配置文件。然后,我們創建特征映射(即,每個分類特征中有多少個類別,如果存在,它應該如何替換不同特征中的缺失值,等等)。我們將csv轉換為h5文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # Get model and dataset configurations
experiment_id = 'FinalMLP_book'
params = load_config(f"config/{experiment_id}/", experiment_id)
params['gpu'] = -1 # cpu
set_logger(params)
logging.info("Params: " + print_to_json(params))
seed_everything(seed=params['seed'])# Create Feature Mapping and convert data into h5 format
data_dir = os.path.join(params['data_root'], params['dataset_id'])
feature_map_json = os.path.join(data_dir, "feature_map.json")
if params["data_format"] == "csv":# Build feature_map and transform h5 datafeature_encoder = FeatureProcessor(**params)params["train_data"], params["valid_data"], params["test_data"] = \\build_dataset(feature_encoder, **params)
feature_map = FeatureMap(params['dataset_id'], data_dir)
feature_map.load(feature_map_json, params)
logging.info("Feature specs: " + print_to_json(feature_map.features))
|
之后,我們就可以開始模型的訓練過程了。
1 2 3 4 5 6 | model_class = getattr(src, params['model']) model = model_class(feature_map, **params) model.count_parameters() # print number of parameters used in modeltrain_gen, valid_gen = H5DataLoader(feature_map, stage='train', **params).make_iterator() model.fit(train_gen, validation_data=valid_gen, **params) |
最后,我們可以預測看不見的數據;我們只需要將批大小更改為1就可以對所有觀察值進行評分。
1 2 3 4 | # to score all observations params['batch_size'] = 1 test_gen = H5DataLoader(feature_map, stage='test', **params).make_iterator() test_df['score'] = model.predict(test_gen) |
我們選擇了一個有不止一本書評級的客戶,并且每本書都有不同的評級,以實現沒有關系的適當排名。它的nDCG分數是0.986362,因為我們放錯了2本書,距離為1位。
我們還使用Recall來評估FinalMLP。召回率是一個度量系統從一個集合中識別所有相關項目的能力的度量,表示為從可用的所有相關項目中檢索到的相關項目的百分比。當我們指定Recall@K(比如Recall@3)時,我們關注的是系統在前K個推薦中識別相關項目的能力。這種適應對于評估推薦系統至關重要,因為用戶主要關注的是最熱門的推薦。K的選擇(例如,3)取決于典型的用戶行為和應用程序的上下文。
如果我們看一下這個客戶的Recall@3,我們有100%,因為另外三本相關的書被放在了前3個位置。
1 2 3 4 | true_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['Book-Rating'].tolist()]) y_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['score'].tolist()])ndcg_score(true_relevance, y_relevance) |
我們還計算了剩余測試集的nDCG分數,并將FinalMLP性能與CatBoost Ranker進行了比較,如圖7所示。雖然這兩個模型都表現得很好,但FinalMLP在這個測試集上的表現略好,每個用戶的平均nDCG為0.963298,而CatBoost Ranker *only*達到了0.959977。
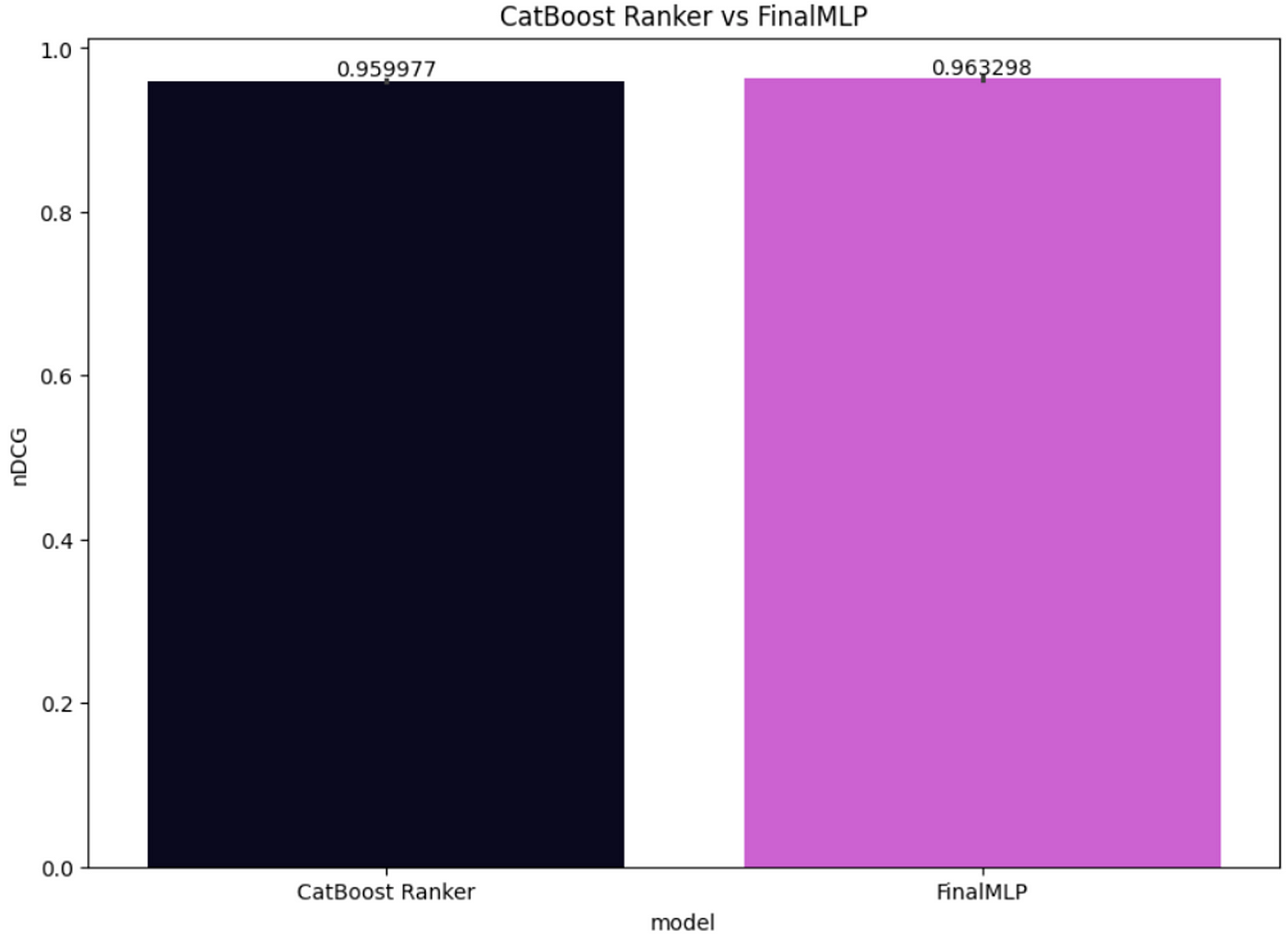
圖7:CatBoost Ranker與FinalMLP的nDCG對比(圖片來源:作者)
在可解釋性方面,該模型執行特征選擇,使我們能夠提取權重向量。然而,解釋和理解每個特性的重要性并不簡單。請注意,在embedding層之后,我們最終得到了一個930維的向量,這使得將其映射回原始特征變得更加困難。盡管如此,我們可以嘗試通過提取每個流的輸出經過線性處理后的絕對值來理解每個流的重要性,這些線性處理由前面提到的線性項給出,如公式2所示。
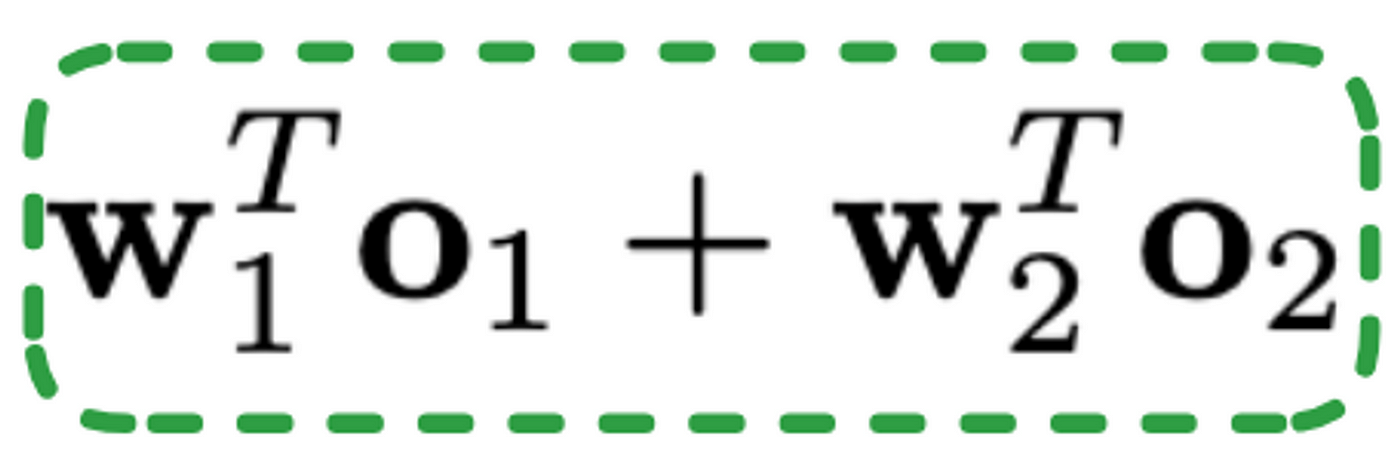
方程2:線性項
為此,我們需要更改?InteractionAggregation模塊,并添加以下代碼行來提取每一步后的線性轉換值:
1 2 3 4 5 6 7 | ... self.x_importance = []self.y_importance = []def forward(self, x, y):self.x_importance.append(torch.sum(torch.abs(self.w_x(x))))self.y_importance.append(torch.sum(torch.abs(self.w_y(y)))) ... |
經過訓練后,我們可以預測并繪制出每個流的線性變換所產生的絕對值。如圖8所示,項目流比用戶流更重要。之所以會出現這種情況,是因為我們有更多關于物品的功能,但也因為用戶功能非常普遍。

圖8:用戶流和項目流的重要性對比(作者圖片)
結論
推薦系統通過提供個性化推薦和授權組織做出驅動增長和創新的數據驅動決策來增強用戶體驗。
在本文中,我們介紹了為推薦系統開發的最新模型之一。最后,mlp是一個具有兩個獨立網絡的深度學習模型。每個網絡都將其學習集中在兩個不同視角中的一個:用戶和項目。然后將從每個網絡學習到的不同模式饋送到一個融合層,該融合層負責將每個網絡的學習結合起來。它創建用戶-項目對交互的單一視圖,以生成最終分數。該模型在我們的用例中表現良好,擊敗了CatBoost Ranker。
請注意,算法的選擇可能取決于您要解決的問題和您的數據集。對幾種方法進行相互比較測試總是好的做法。您還可以考慮測試xDeepFM、AutoInt、hen或DLRM。
參考文獻
[1] Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. arXiv:2304.00902, 2023.
[2] Jiajun Fei, Ziyu Zhu, Wenlei Liu, Zhidong Deng, Mingyang Li, Huanjun Deng, Shuo Zhang. DuMLP-Pin: A Dual-MLP-dot-product Permutation-invariant Network for Set Feature Extraction. arXiv:2203.04007, 2022.
[3] Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, Xiuqiang He. BARS-CTR: Open Benchmarking for Click-Through Rate Prediction. arXiv:2009.05794, 2020.









測評體驗)









的意義)