數據中心GPU集群組網技術是指將多個GPU設備連接在一起,形成一個高性能計算的集群系統。通過集群組網技術,可以實現多個GPU設備之間的協同計算,提供更大規模的計算能力,適用于需要大規模并行計算的應用場景。
常用的組網技術:
1.InfiniBand(簡稱IB):
InfiniBand是一種高性能計算和數據中心互連技術,具有低延遲和高帶寬的特點。它支持點對點和多播通信模式,并提供高效的遠程直接內存訪問(RDMA)功能。InfiniBand通常用于大規模GPU集群的互連。
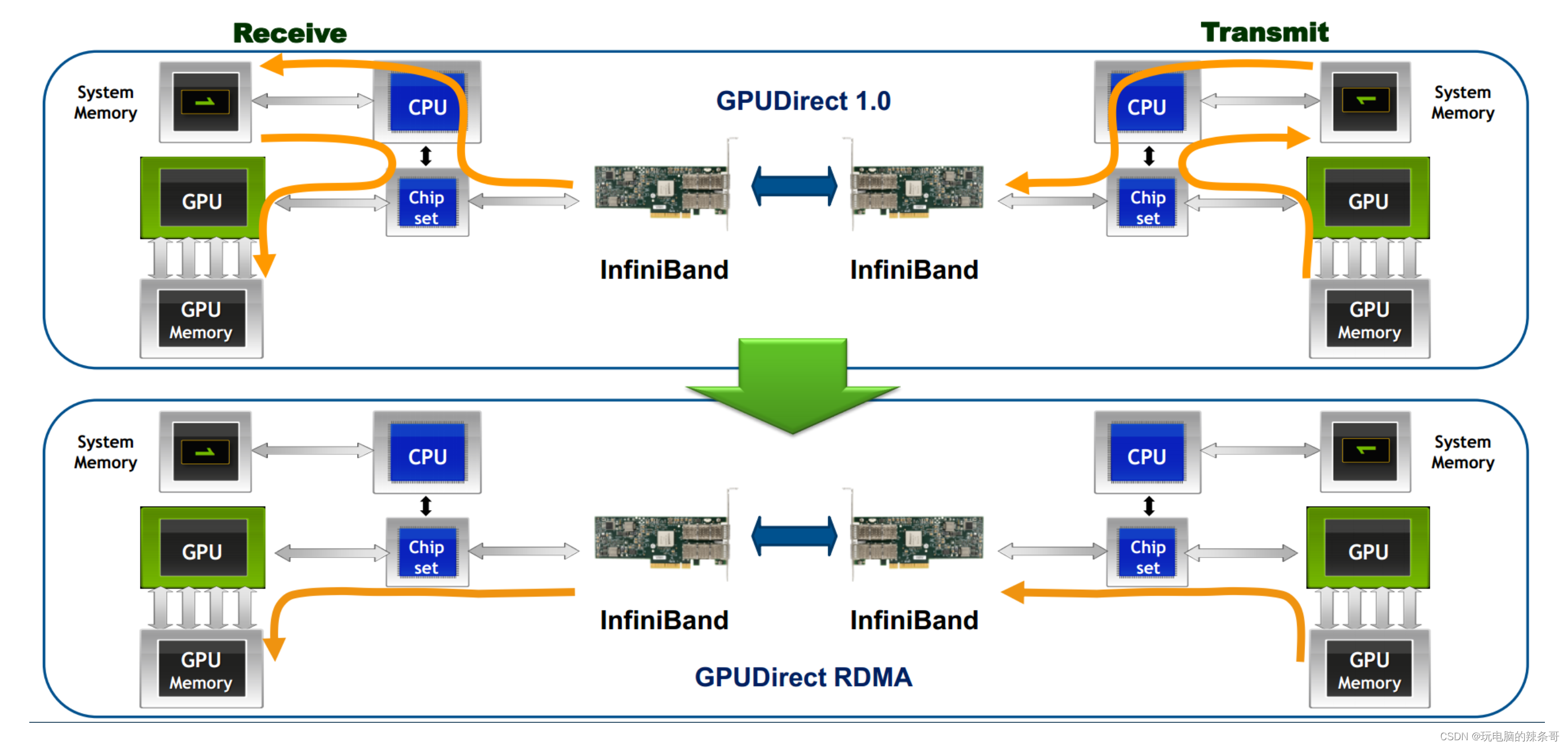
InfiniBand網絡的一些特點和功能:
低延遲:InfiniBand網絡通過在硬件和協議棧中采用一些優化技術,實現了非常低的傳輸延遲。這對于需要實時數據傳輸和低延遲響應的應用非常重要,如高性能計算、金融交易和實時數據分析等。高帶寬:InfiniBand網絡提供了非常高的數據傳輸帶寬,通常以吉比特或每秒更高的速度進行通信。這使得它適用于大規模數據傳輸和并行計算任務,能夠滿足對大吞吐量的需求。RDMA支持:InfiniBand網絡通過支持RDMA技術,實現了高效的遠程內存訪問。RDMA允許數據在主機之間直接傳輸,而無需通過CPU的干預。這種直接內存訪問方式可以提供更低的處理延遲和更高的數據吞吐量。點對點和多播通信:InfiniBand網絡支持點對點和多播通信模式。點對點通信意味著兩個節點之間可以直接通信,而無需經過交換機或路由器。多播通信可以將數據同時傳輸到多個節點,適用于廣播和集體通信操作。可擴展性:InfiniBand網絡可以支持數千個節點的集群規模,并提供可擴展性的設計。它包括交換機、網關、適配器等設備,可以靈活地構建各種規模的網絡拓撲。
InfiniBand網絡通常用于構建高性能計算集群、大規模存儲系統、高頻交易平臺等需要低延遲和高帶寬的應用。它提供了一種高效的數據傳輸解決方案,并在科學研究、金融、能源等領域發揮重要作用。
目前,Nvidia是唯一一家提供高端IB交換機供HPC和AI GPU集群使用的供應商。例如,OpenAI在Microsoft Azure云中使用了10,000個Nvidia A100 GPU和IB交換網絡來訓練他們的GPT-3模型。而Meta最近構建了一個包含16K GPU的集群,該集群使用Nvidia A100 GPU服務器和Quantum-2 IB交換機(英偉達GTC 2021大會上發布全新的InfiniBand網絡平臺,具有25.6Tbps的交換容量和400Gbps端口)。這個集群被用于訓練他們的生成式人工智能模型,包括LLaMA。值得注意的是,當連接10,000個以上的GPU時,服務器內部GPU之間的切換是通過服務器內的NVswitches完成的,而IB/以太網網絡則負責將服務器連接在一起。

為了應對更大參數量的訓練需求,超大規模云服務提供商正在尋求構建具有32K甚至64K GPU的GPU集群。在這種規模上,從經濟角度來看,使用以太網網絡可能更有意義。這是因為以太網已經在許多硅/系統和光模塊供應商中形成了強大的生態系統,并且以開放標準為目標,實現了供應商之間的互操作性
2.Ethernet:
以太網是一種常見的網絡技術,也可以用于GPU集群的組網。通過使用高速以太網(如10GbE、40GbE、100GbE),可以提供足夠的帶寬和低延遲,以滿足GPU集群的需求。一些高性能計算網絡技術,如RDMA over Converged Ethernet(RoCE)和Data Center Bridging(DCB),可以進一步提高以太網在GPU集群中的性能。
RDMA over Converged Ethernet (RoCE)
RoCE讀音類似Ráo kì
是一種基于以太網的遠程直接內存訪問(RDMA)技術。它允許在以太網上實現高性能、低延遲的數據傳輸,同時保持以太網的通用性和可擴展性。
RoCE通過在以太網協議棧上引入RDMA功能,實現了RDMA在以太網上的使用。RDMA是一種數據傳輸方式,它允許數據在內存之間直接傳輸,而無需通過CPU進行數據拷貝和處理。這種直接內存訪問方式可以提供低延遲、高帶寬和高效能的數據傳輸。
RoCE技術的主要特點包括以下幾點:
無損以太網:RoCE在以太網上實現了無損傳輸,即保證數據的可靠性和完整性。它通過使用帶有流量控制和擁塞管理機制的數據包傳輸,確保數據在傳輸過程中不會丟失或損壞。
網絡內部的一個丟包,這個端到端的通信的時延,沒有損失,以前的網絡,是可能會丟包,然后他這個時延,也有有各種的樣的一個損失。0丟包低時延,高吞吐
基于標準以太網:RoCE技術基于標準以太網協議棧,不需要額外的硬件或專用網絡設備。這使得RoCE可以在現有以太網基礎設施上部署,無需進行大規模的網絡改造。低延遲和高帶寬:RoCE利用RDMA技術的特性,在以太網上實現了低延遲和高帶寬的數據傳輸。它可以提供與傳統InfiniBand類似的性能水平,適用于對延遲和帶寬要求較高的應用場景。
RoCE通常用于數據中心和云計算環境中構建高性能計算和存儲系統。它可以與現有的以太網設備和協議兼容,并提供低延遲、高帶寬的數據傳輸能力。通過采用RoCE技術,可以在以太網上實現高效能的遠程直接內存訪問,提高數據傳輸效率和系統性能。
高端以太網交換機ASIC的主要供應商可以提供高達51.2Tbps的交換容量,配備800Gbps端口,其性能是Quantum-2((英偉達GTC 2021大會上發布全新的InfiniBand網絡平臺,具有25.6Tbps的交換容量和400Gbps端口))的兩倍。這意味著,如果交換機的吞吐量翻倍,構建GPU網絡所需的交換機數量可以減少一半。
以太網還能提供無丟包傳輸服務,通過優先流量控制(PFC)實現。PFC支持8個服務類別,每個類別都可以進行流量控制,其中一些類別可以指定為無丟包類別。在處理和通過交換機時,無丟包流量的優先級高于有丟包流量。在發生網絡擁塞時,交換機或網卡可以通過流量控制來管理上游設備,而不是簡單地丟棄數據包。
此外,以太網還支持RDMA(遠程直接內存訪問)通過RoCEv2(RDMA over Converged Ethernet)實現,其中RDMA幀被封裝在IP/UDP內。當RoCEv2數據包到達GPU服務器中的網絡適配器(NIC)時,NIC可以直接將RDMA數據傳輸到GPU的內存中,無需CPU介入。同時,可以部署如DCQCN等強大的端到端擁塞控制方案,以降低RDMA的端到端擁塞和丟包。
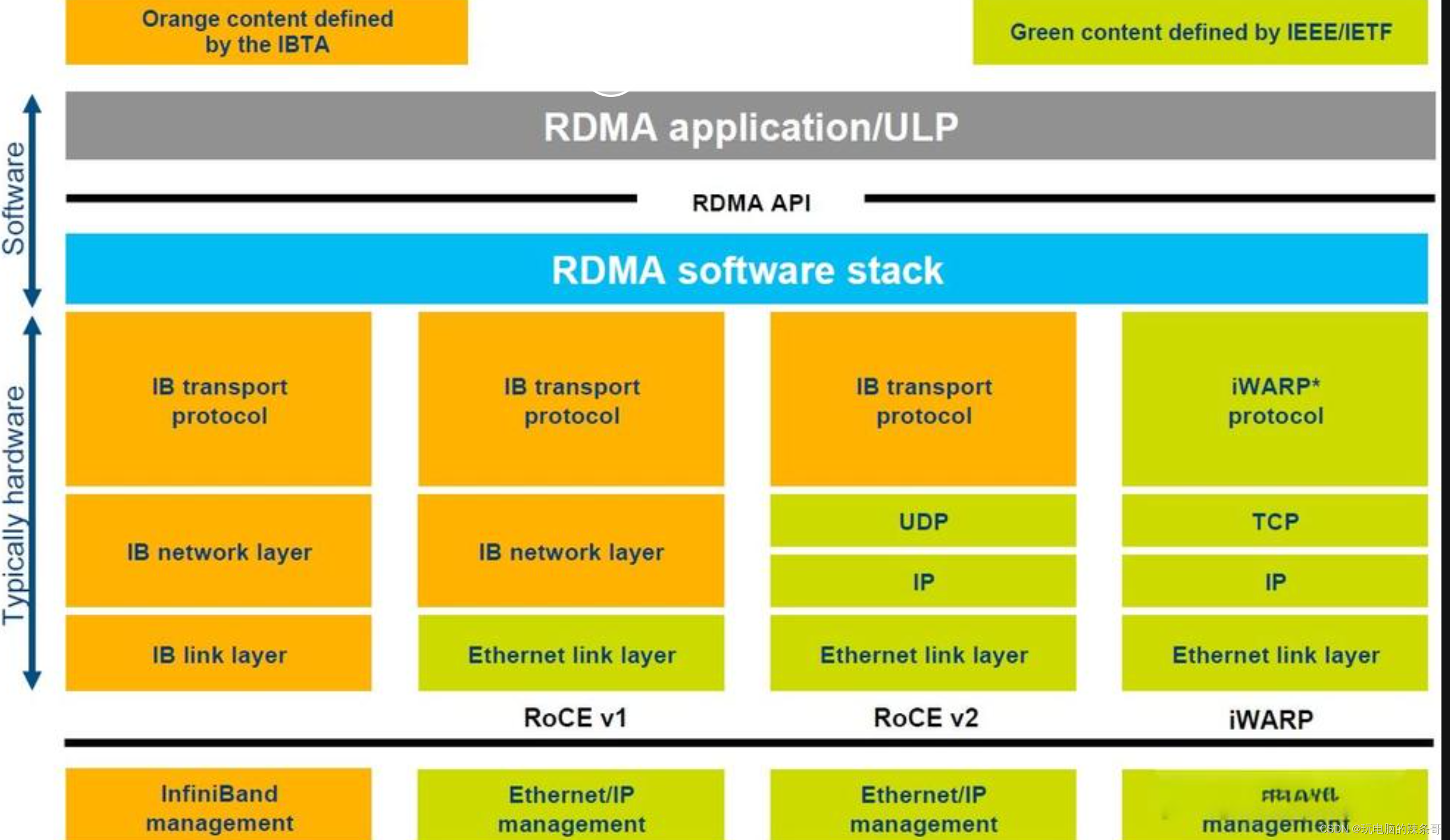
RDMA over Converged Ethernet (RoCE)和RoCEv2都是基于以太網的遠程直接內存訪問(RDMA)技術,用于在以太網上實現高性能、低延遲的數據傳輸。它們之間的主要區別在于以下幾個方面:協議版本:RoCE和RoCEv2是不同的協議版本。RoCE是早期的協議版本,而RoCEv2是對RoCE協議進行改進和擴展后的新版本。IP支持:RoCE和RoCEv2在IP支持方面有所不同。RoCEv2可以在IP網絡中運行,支持使用IPv4或IPv6地址進行通信。而RoCE則需要在以太網之上建立專用的InfiniBand子網,不直接使用IP。網絡層:RoCE和RoCEv2在網絡層的實現方式上有所區別。RoCE在以太網上直接封裝InfiniBand的傳輸層協議(IBTA RDMA)進行數據傳輸。而RoCEv2使用UDP/IP封裝RDMA數據,從而在IP網絡上實現RDMA。擴展性:RoCEv2在擴展性方面有所改進。RoCEv2引入了更靈活的路由和多路徑功能,可以支持更大規模的網絡拓撲和部署。它還提供了更多的配置選項,如網址控制信息(GID)和服務級別(SL),以支持不同應用需求。需要注意的是,RoCE和RoCEv2雖然有一些區別,但它們的基本原理和目標都是實現在以太網上的高性能、低延遲的RDMA。具體選擇使用哪個版本取決于具體應用的需求、網絡環境和設備兼容性等因素。iWARP(Internet Wide Area RDMA Protocol)是一種基于以太網的遠程直接內存訪問(RDMA)協議。它允許在以太網上實現低延遲、高帶寬的數據傳輸,提供了與傳統的基于 InfiniBand 的 RDMA 相似的性能和效果。
iWARP 是通過在以太網上的 TCP/IP 協議棧上添加 RDMA 支持來實現的。它在以太網的傳輸層以上添加了 RDMA 協議,通過在數據傳輸過程中繞過操作系統內核的數據拷貝和處理,實現了零拷貝和低延遲的數據傳輸。這使得應用程序可以直接在遠程主機的內存中讀寫數據,從而提供了高效的數據交換。
iWARP 提供了多種功能和特性,包括傳輸層卸載(TOE),數據完整性保護,流量控制,錯誤恢復等。它使用標準的以太網硬件和協議,無需專用的高速網絡設備,因此更容易部署和使用。
iWARP 技術的優勢在于它可以在現有的以太網基礎設施上實現高性能和低延遲的數據傳輸。它被廣泛應用于需要大數據量、低延遲、高吞吐量的應用場景,如數據中心、云計算、存儲系統、高性能計算等領域。
iWARP和RoCE(RDMA over Converged Ethernet)都是基于以太網的遠程直接內存訪問(RDMA)協議,但它們在實現和特性上有一些區別:
技術實現:iWARP使用TCP/IP協議棧來實現RDMA,而RoCE使用UDP/IP協議棧。因此,iWARP利用TCP的可靠性和流量控制機制,而RoCE則利用UDP的低延遲和多播特性。軟硬件支持:iWARP通常需要特定的網卡和驅動程序來實現,而RoCE可以在標準的以太網硬件上實現,但需要支持RDMA的網絡適配器。性能和延遲:iWARP通常在吞吐量和延遲方面具有更好的性能。它使用了更復雜的協議堆棧和流量控制機制,可以提供更穩定和可預測的性能。RoCE則更加注重低延遲,可以實現更快的數據傳輸速度。部署和兼容性:由于iWARP使用TCP/IP協議棧,它可以與現有的以太網基礎設施兼容,并且易于部署。RoCE需要支持RDMA的網絡適配器,并且對交換機和路由器的支持有一定的要求。
選擇使用iWARP還是RoCE取決于具體的應用需求和環境條件。如果你的應用需要更好的吞吐量和穩定性,或者正在使用現有的以太網基礎設施,那么iWARP可能是一個更好的選擇。如果你的應用對低延遲有更高的要求,并且有適當的硬件支持,那么RoCE可能更適合你的需求。
Data Center Bridging(DCB)
是一組標準和技術,旨在提供在數據中心網絡中傳輸數據時的高可靠性、低延遲和帶寬保證。
DCB 主要解決了在傳統以太網網絡中面臨的一些挑戰,包括數據傳輸的可靠性、帶寬利用率和延遲控制等問題。DCB 引入了以下關鍵技術和標準:
Priority-based Flow Control(PFC):PFC 用于解決數據包丟失和擁塞的問題。它基于 IEEE 802.1Qbb 標準,允許交換機根據流的優先級進行流量控制,確保高優先級的流量不會被低優先級的流量阻塞。Enhanced Transmission Selection(ETS):ETS 用于提供帶寬保證。它基于 IEEE 802.1Qaz 標準,允許網絡管理員將可用帶寬分配給不同的流量類別,并根據優先級和帶寬需求進行流量管理。Data Center Bridging Exchange(DCBX):DCBX 是一種交換機和終端設備之間的協議,用于在連接建立時交換關于 DCB 支持和配置的信息。DCBX 可以確保網絡中的所有設備都能夠遵守相同的 DCB 配置,從而實現更好的互操作性和一致性。
DCB 技術通常用于數據中心網絡中的存儲交換機、以太網交換機、服務器和存儲設備之間的連接。它可以為關鍵應用程序提供低延遲、高可靠性和帶寬保證的網絡環境,從而提高數據中心的性能和可靠性。
3.NVLink:
NVLink是NVIDIA開發的一種高速互連技術,專門用于連接多個GPU設備。它提供高帶寬、低延遲的點對點連接,并支持共享內存和直接內存訪問。NVLink通常用于構建NVIDIA GPU的集群系統,以實現更高的GPU計算性能和數據傳輸效率。
NVLink 交換系統
用于連接 GPU 服務器中的 8 個 GPU 的 NVLink 交換機也可以用于構建連接 GPU 服務器之間的交換網絡。Nvidia 在 2022 年的 Hot Chips 大會上展示了使用 NVswitch 架構連接 32 個節點(或 256 個 GPU)的拓撲結構。由于 NVLink 是專門設計為連接 GPU 的高速點對點鏈路,所以它具有比傳統網絡更高的性能和更低的開銷。
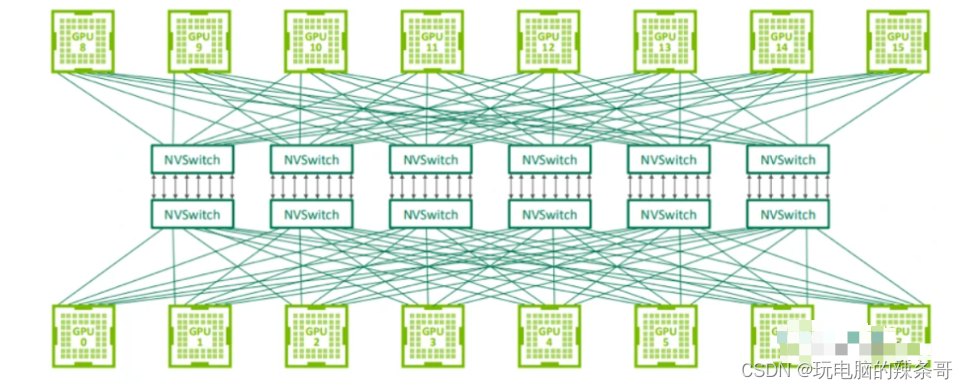
第三代 NVswitch 配備 64 個 NVLink 端口,提供高達 12.8Tbps 的交換容量,同時支持多播和網絡內聚合功能。網絡內聚合能夠在 NVswitches 內部匯集所有工作 GPU 生成的梯度,并將更新后的梯度反饋給 GPU,以便進行下一次迭代。這一特點有助于減少訓練迭代過程中 GPU 之間的數據傳輸量。
據 Nvidia 介紹,在訓練 GPT-3 模型時,NVswitch 架構的速度是 InfiniBand 交換網絡的 2 倍,展現出了令人矚目的性能。然而,值得注意的是,這款交換機的帶寬相較于高端交換機供應商提供的 51.2Tbps 交換機來說,要少 4 倍。
若嘗試使用 NVswitches 構建包含超過 1000 個 GPU 的大規模系統,不僅成本上不可行,還可能受到協議本身的限制,從而無法支持更大規模的系統。此外,Nvidia 不單獨銷售 NVswitches,這意味著如果數據中心希望通過混合搭配不同供應商的 GPU 來擴展現有集群,他們將無法使用 NVswitches,因為其他供應商的 GPU 不支持這些接口。
4.PCIe:
PCI Express(PCIe)是一種常見的計算機總線技術,也可以用于GPU集群的組網。通過將多個GPU設備插入到主機上的不同PCIe插槽中,可以將它們連接在一起,并通過軟件和驅動程序進行協同計算。然而,相比于其他高性能互連技術,PCIe的帶寬和延遲較高,適合中小規模的GPU集群。
GPU集群組網技術的選擇取決于具體的應用需求、預算和可用資源。不同的技術對網絡拓撲、設備支持和軟件兼容性等方面有不同的要求,因此在選擇和部署GPU集群組網技術時,需要綜合考慮各種因素,并結合具體需求做出決策。
5.DDC全調度網絡
DDC(Distributed Data Center)全調度網絡是一種用于數據中心互連的網絡架構。它是基于全調度算法的網絡設計,旨在提供高性能、低延遲的數據傳輸和資源調度能力。
在傳統的數據中心網絡架構中,通常采用分層結構,例如經典的三層結構(核心層、匯聚層和接入層)。這種分層結構可能導致數據傳輸的延遲較高和資源利用率較低的問題。
DDC全調度網絡通過將網絡交換機配置為全調度模式,即所有交換機都能直接通信,消除了分層結構帶來的瓶頸和延遲。它采用集中式的全局調度算法,根據數據中心內的實時負載情況和通信需求,動態地分配網絡資源和優化數據流。
DDC全調度網絡的關鍵特點包括:
低延遲:由于所有交換機都能直接通信,DDC全調度網絡可以減少數據傳輸的跳數和排隊延遲,從而實現低延遲的數據傳輸。高帶寬:DDC全調度網絡提供高帶寬的數據傳輸能力,可以滿足大規模數據中心的高吞吐量需求。靈活性:DDC全調度網絡具有靈活的資源調度能力,可以根據實際需求動態分配網絡帶寬和處理能力,實現資源的最優利用。可擴展性:DDC全調度網絡設計為可擴展的結構,支持逐步擴展和添加更多的交換機和節點,以適應不斷增長的數據中心規模。
DDC全調度網絡是一種新型的數據中心網絡架構,它通過全調度算法和直接通信的方式提供了高性能、低延遲的數據傳輸和資源調度能力。這種網絡架構被廣泛應用于大規模數據中心、云計算和超級計算等領域,以提升系統性能和應用效率。
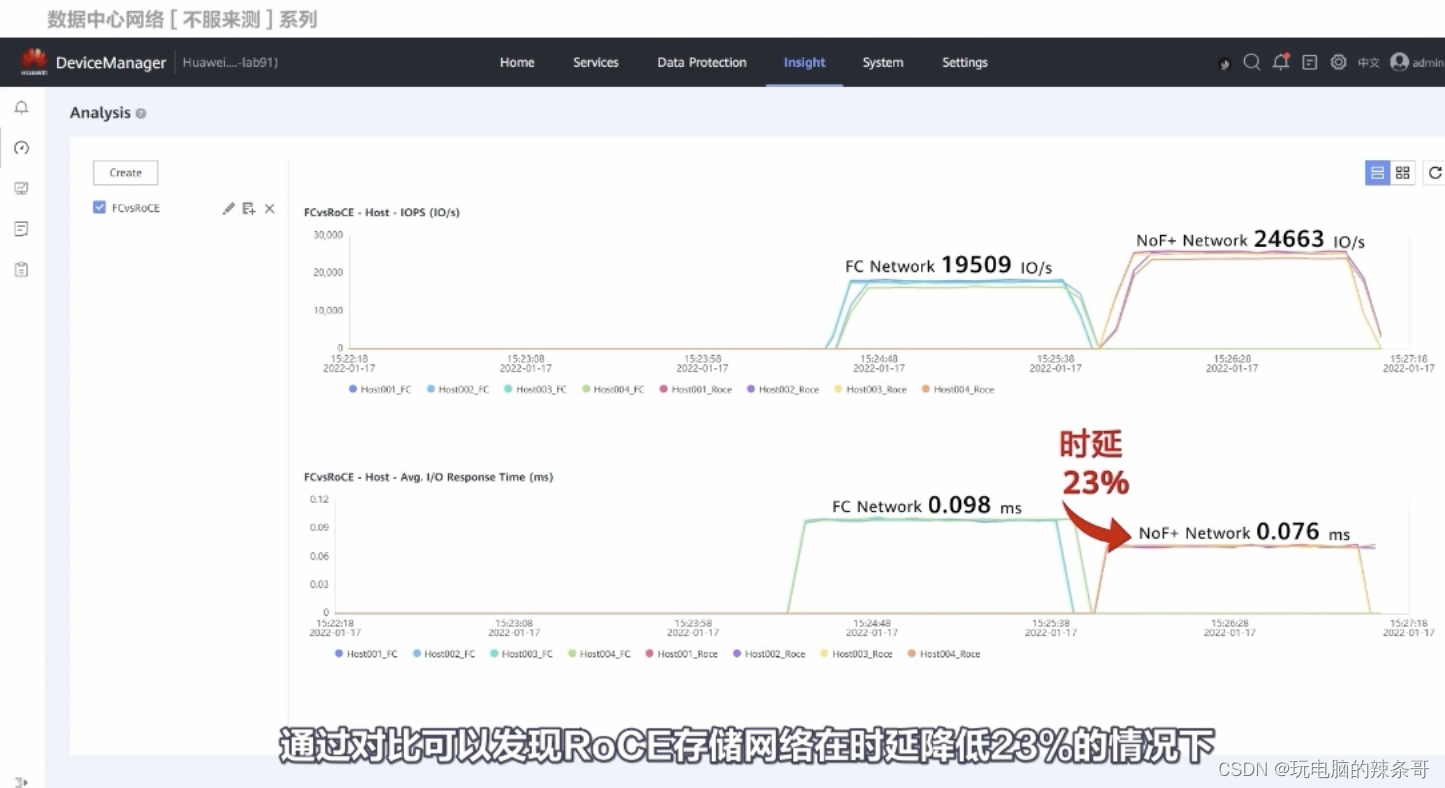
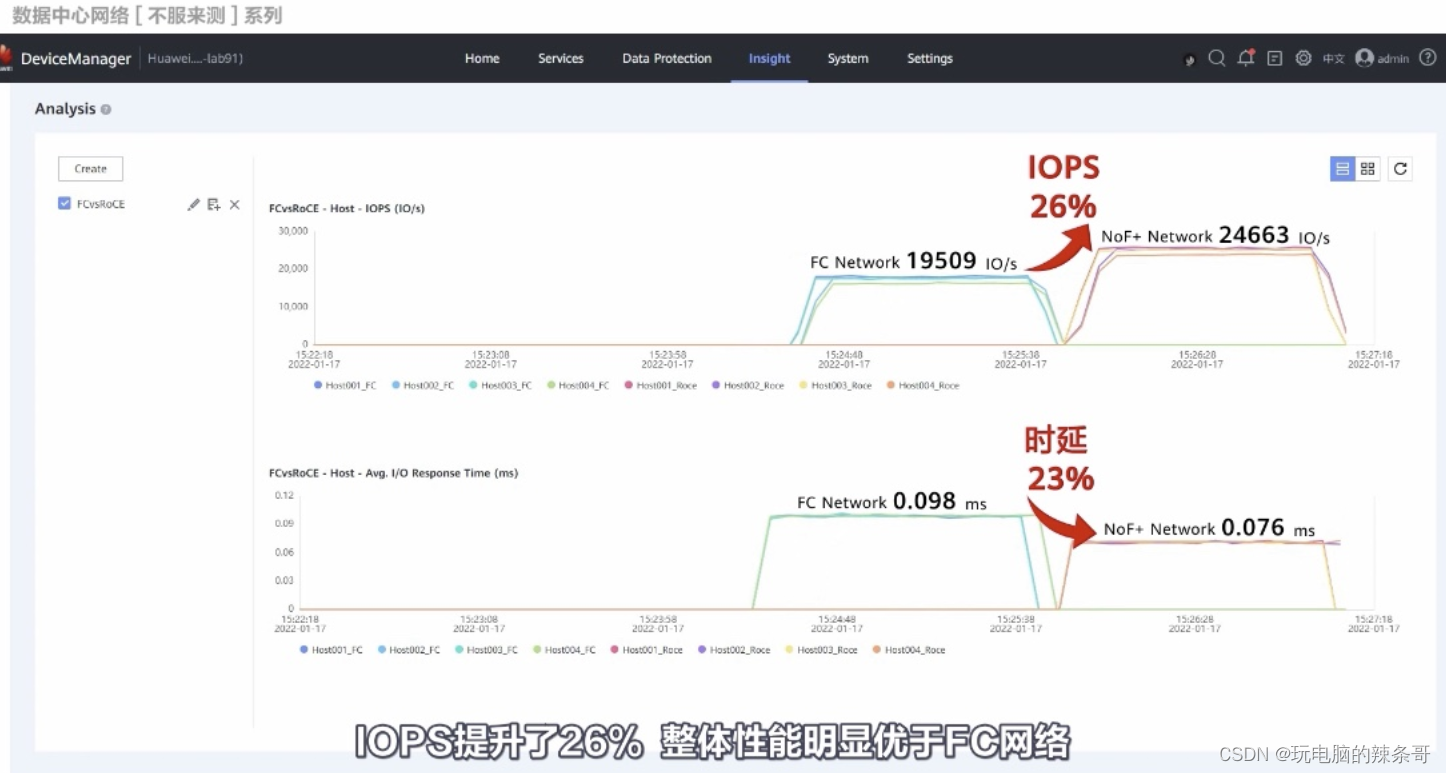
RoCE 和 FC測試對比
測試來自華為






)









——點對點傳輸場景方案)



)
