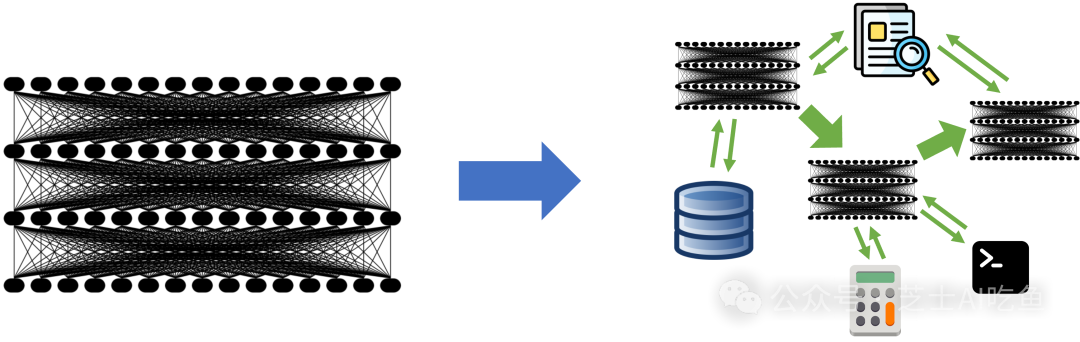
2023年,大型語言模型(LLM)吸引了所有人的注意力,它可以通過提示來執行通用任務,例如翻譯或編碼。這自然導致人們將模型作為AI應用開發的主要成分而密切關注,所有人都在想新的LLM將帶來什么能力。然而,隨著越來越多的開發者開始使用LLM構建,我們認為這種關注正在迅速改變:最先進的AI結果越來越多地來自具有多個組件的復合系統,而不僅僅是單一的模型。
例如,谷歌的AlphaCode 2通過精心設計的系統設置了編程的最新狀態,該系統使用LLM為一個任務生成多達100萬個可能的解決方案,然后過濾和評分。同樣,AlphaGeometry將LLM與傳統的符號求解器相結合,以解決奧林匹克問題。在企業中,我們在Databricks的同事發現,60%的LLM應用使用某種形式的檢索增強生成(RAG),30%使用多步鏈。即使研究傳統語言模型任務的研究人員,以前只報告單個LLM調用的結果,現在也開始報告越來越復雜的推理策略的結果:微軟寫了一種鏈接策略,在醫學考試中超過GPT-4的準確率9%,谷歌發布Gemini時使用新的CoT@32推理策略在MMLU基準測試中調用模型32次,這引發了與單次調用GPT-4進行比較的問題。向復合系統的轉變開啟了許多有趣的設計問題,但這也令人興奮,因為這意味著領先的AI結果可以通過巧妙的工程實現,而不僅僅是訓練規模的擴大。
在這篇文章中,我們分析了復合AI系統的趨勢及其對AI開發者的意義。為什么開發人員要構建復合系統?隨著模型的改進,這個范式是否會持續下去?又有哪些新興的工具可以開發和優化這樣的系統——這是一個比模型訓練研究要少得多的領域?我們認為,復合AI系統在未來可能是最大化AI結果的最佳方式,并且可能是2024年AI中最重要的趨勢之一。
查看原文:《從模型到復合AI系統的轉變》
)

、WebDriverWait()))




)











