一首歌,包含作詞作曲兩個部分。擅長作詞or作曲就已經很牛了。比如方文山是周杰倫的御用作詞人,而周杰倫寫過很多耳熟能詳的曲子。而兼具作詞作曲才華的全能創作人卻是難得一見。
最近港中文發布了一款歌曲創作大模型SongComposer,作詞作曲都不在話下。 并且擅長讓歌詞和旋律相互交融,讓整首歌聽起來更加和諧。

先來幾個小demo一起欣賞一下:
根據歌詞編寫旋律:
歌詞:突如其來的那一場 誰在路旁 在路旁 聽見我自由放聲唱 和我一樣 背上行囊 腳步丈量遠方
根據旋律作詞:
給出以下旋律:
生成的歌詞:他們也曾像我一樣 追著風跑著 卻找不到方向 只能像我這樣 停在路上 有一點累 卻也不覺的 有一點心為了追逐夢想 我總是選擇最難的路
最終合成的歌曲:
續寫歌曲:
給出歌曲的開頭
續寫結果
根據文本生成歌曲:
甚至你需要輸入“用悠揚的旋律和緩慢的節奏創作一首關于愛和自由的歌曲”,SongComposer就能根據文本提示生成一首包含詞曲的歌:
怎么樣,是不是聽起來還不錯,有那味了。如果再加上編曲老師的潤色,一首完整度較高的流行歌曲就完成了!

除此之外,作者還發布了用于訓練的歌詞-旋律配對數據集,以及一套評估生成歌曲質量的指標,相信可以推動智能音樂創作往前邁進一大步!
論文標題:
SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation
公眾號「夕小瑤科技說」后臺回復“SongComposer”獲取論文PDF!
SongCompose-PT Dataset
本節概述了SongCompose-PT數據集的編制、創建和結構,其中包括單獨的歌詞、旋律和在單詞級別上將歌詞與旋律同步的歌詞-旋律配對集合。
純歌詞數據集
從兩個在線來源收集純歌詞數據集:
-
Kaggle數據集,包括帶有Spotify Valence標簽的15萬首歌曲的歌詞。
-
Music Lyric Chatbot數據集,包含14萬首中文歌曲的歌詞。從28.3萬首中英文歌曲中刪選而來的高質量的歌詞。
純旋律數據集
為了將旋律數據集組織成基于文本的結構,使用MIDI文件作為純旋律數據集,其結構簡單,能夠在沒有復雜音頻處理的情況下高效提取和操作旋律。
使用pretty midi解析MIDI文件,僅從中提取“旋律”或“人聲”軌道,由于MIDI中的旋律被表示為隨時間推移的一系列音符,每個音符具有特定的音高、開始和結束時間戳,最終獲得一個旋律屬性三元組列表,包括{音符音高、音符持續時間、休止符持續時間}。
其中約4.5萬條條目來自LMD-matched MIDI數據集,約8萬條來自網絡爬蟲。再進行必要的數據過濾以刪除重復和質量不佳的樣本,最終剩下大約2萬個MIDI樣本。
配對歌詞-旋律數據集
大量歌詞和旋律配對數據對于訓練LLM進行歌曲創作非常重要。但是歌曲與旋律的對齊非常困難,需要詳細的注釋和特定的專業知識。它包括確保歌詞與一個或多個旋律音符精確匹配,并標注精確的時間戳,如下圖所示:

本文利用了來自LMD-full數據集的7,998首歌曲,以及來自Reddit數據集的4,199首歌曲。此外,還結合了OpenCpop數據集其中100首中文流行歌曲,以及M4Singer數據集其中700首高質量中文歌曲。
為了進一步豐富配對歌詞-旋律數據,本文還抓取網絡信息創建了一個包含4,000首經典中文歌曲的數據集。收集歌詞-旋律數據的流程如下圖所示:
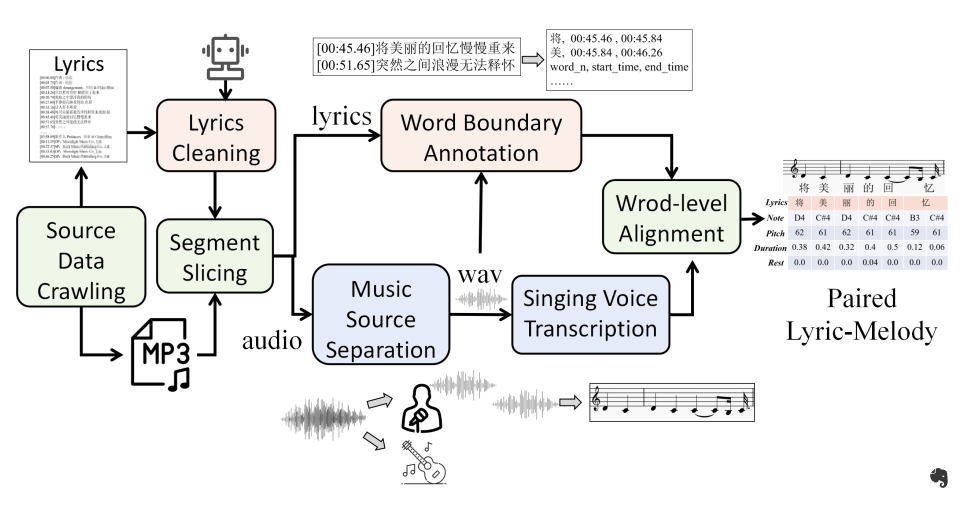
-
數據來源爬取:搜集大量的mp3文件及其對應的歌詞文件,包括句級別的時間戳。
-
歌詞清理:使用GPT-4清理歌詞文本中的不相關細節,如歌曲標題、藝術家姓名和制作信息。
-
分段切片:為了減輕長時間對齊的挑戰和誤差積累,根據歌詞文件中提供的時間戳將音頻和歌詞切片為大約10秒的配對段落(每個段落大約三句)。
-
音樂源分離:利用UVR4這個公開的音樂分離工具,從原始音頻中分離人聲和伴奏部分。
-
歌聲轉錄:使用數字音頻工作站軟件FL Studio5自動生成初步的樂譜,捕捉每個音符的音高和起始-結束時間。
-
詞邊界注釋:通過Pypinyin6將歌詞轉換為音素序列,然后利用音頻對齊工具——Montreal Forced Aligner獲取歌詞中每個詞語的邊界。
-
詞級別對齊:利用動態時間扭曲(DTW)算法,根據起始-結束時間對單詞和音符進行對齊。
最后,本文開發了一個包含約15K個配對歌詞-旋律條目的數據集,其中約5K首為中文,10K首為英文。
SongComposer
LLM友好的歌曲表示
元組數據格式
為了將歌詞和旋律輸入到LLM中,一個直觀的策略是按順序排列它們,從一系列歌詞開始,然后是一系列音符值和時長。然而,由于其順序化方法,模型很難對齊歌詞和旋律,導致產生不對齊的輸出。
作者提出了一種統一的輸入組織方式,利用基于元組的格式,其中每個元組代表一個離散的音樂單元,可以是一個歌詞,一個旋律,或者一個歌詞-旋律對。
具體來說,在純歌詞數據的情況下,在每個元組中插入一個單詞。對于純旋律,在每個元組中包括音調、音符時長和休息時長。對于歌詞-旋律對,將歌詞和相應的音符元素合并在同一個元組內。由于一個單詞可以對應多個音符,一個單元組可能包含一個單詞以及多個音符和它們各自的時長。使用豎線(|)來分隔不同的元組,并將元組序列作為LLM的輸入,如下圖所示。

這種元組格式明確地為模型提供了歌詞和旋律之間的相互映射,有助于掌握元素之間的對應關系。
離散化時長
為了有效處理旋律中的時長信息,采用對數編碼方案將時長分為預定義數量的bin,將連續的時長范圍轉換為一組離散值。這種為LLM提供的組織良好且簡潔的輸入增強了模型捕捉音樂內容的精確時間變化的能力。
具體來說,根據時長的統計分布,將它們截取到 [xmin, xmax]。對于任意時長x,編碼過程定義如下:
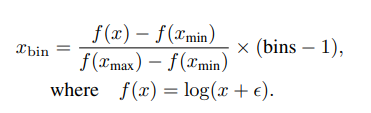
設置 [xmin, xmax] = [-0.3, 6],bins = 512,? = 1,這使得時長可編碼為512個離散整數,最高可達6.3秒。相反,要將離散化值解碼為原始時長:
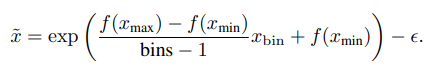
詞匯擴展
為了確保清晰度,通過引入由???符號表示的輔助標記,針對離散化的時間單位和音符值在模型詞匯中推廣表示形式。對于時間離散化,擴展了512個獨特token,表示為。對于音樂音符的表示,標記了十個八度內的12個音高類別,從而添加了120個不同的音樂token。
兩階段訓練
預訓練階段
為了豐富LLM的基礎音樂知識,首先在大量純歌詞和純旋律的語料庫上對模型進行預訓練。
對于旋律,采用音高移調來增強數據集。具體來說,將音高移動高低四個半音,從而將數據集擴大了九倍。
對于歌詞將整首歌曲的數據拆分成基于句子的樣本,每個樣本包含五到十行。這種制定使得模型能夠獲得更加專注和相關的學習上下文,有助于更連貫地生成歌曲。
通過這種純歌詞和旋律的訓練過程,模型已經獲得了扎實的音樂知識基礎,為更加關注歌詞和旋律之間對應關系的高級學習奠定了堅實基礎。隨后,使用配對數據引導模型生成對齊的歌詞-旋律對。根據經驗,為了保留模型處理旋律和歌詞的能力,以1:1:1樣本比例向模型輸入相等數量的純旋律、純歌詞和配對數據。
總共有0.23B個歌詞tokens、0.28B個旋律tokens和0.16B個配對數據tokens。所有數據都是使用元組數據格式輸入的。
監督微調階段
在將大量樂譜和歌詞引入模型后,為歌曲生成制作指令遵循數據,包括給定歌詞創建旋律、為旋律寫歌詞、擴展歌曲部分以及根據文本描述生成歌曲。其中,為前三個任務手動準備了3K個問答對。對于最后一個任務,使用GPT-4生成了1K首歌曲摘要,這些摘要又形成了一個文本到歌曲的數據集,指導了歌曲創作過程。
客觀評價指標
本文還構建了一個包含1188首歌曲的驗證集。其中,415首是中文歌曲,773首是英文歌曲。在后續測試中,將一些歌曲隨機分割成5至10個句子。客觀評估的重點是評估生成的輸出與真實樣本之間的相似性。
旋律生成
對于旋律評估,采用了SongMASS(提出的度量標準。其中包括音高分布相似度(PD)、時長分布相似度(DD)和旋律距離(MD)。由于與SongMASS相比的校準策略的不同,通過加法對齊ground truth和生成音符的平均音高。
歌詞生成
在歌詞生成方面,使用CoSENT模型,評估句子級別的對齊。該模型允許輸入歌詞,并計算生成歌詞與原始歌詞之間的余弦相似性。此外,結合ROUGE-2分數和BERT分數作為另外兩個用于評估歌詞生成的度量標準。ROUGE-2分數關注生成文本和原始文本之間的二元組重疊。BERT分數利用BERT-base multilingual uncased 模型基于上下文嵌入來衡量文本相似度。
主觀評價指標
選取30名參與者對每個任務中有10個案例進行評價。評分范圍為1到5,得分越高表示質量更高。
歌詞到旋律生成
歌詞到旋律生成要求根據給定的歌詞創作出一段合適的旋律。對旋律進行評估包括:(1)和聲(HMY.):評估旋律的整體質量。
(2)旋律-歌詞兼容性(MLC.):檢查生成的旋律與給定歌詞之間的契合程度。
旋律到歌詞生成
旋律到歌詞生成旨在產生與提供的旋律相匹配的歌詞。對歌詞進行評估包括:(1)流暢性(FLN.):考慮生成歌詞的語法正確性和語義連貫性。
(2)旋律-歌詞兼容性(MLC.):檢查生成歌詞與給定旋律的契合程度。
歌曲延續性
歌曲延續涉及在旋律和歌詞方面延長已有歌曲的部分。評估延續的質量包括:(1)整體質量(OVL.):衡量生成歌曲的整體質量,以其音樂吸引力為標準。(2)與歌曲提示的一致性(COH.):分析延續與提供的歌曲提示之間的自然融合,評估旋律、歌詞和其他音樂元素的連貫性。
文本到歌曲生成
歌曲延續根據文本描述生成完整的歌曲,以音樂和歌詞的形式捕捉其本質。評估重點包括:(1)整體質量(OVL.):衡量生成歌曲的整體質量,以其音樂吸引力為標準。(2)與文本輸入相關性(REL.):檢查生成歌曲與輸入文本的對齊度和相關性。
實驗結果
歌詞到旋律生成
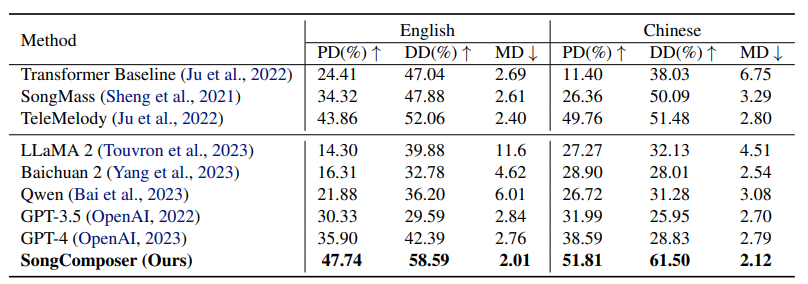
如上表所示,該方法在調性分布相似度(PD)和時長分布相似度(DD)方面優于先進的語言模型,比GPT-4高出10個多點,并在中英雙語中實現了最低的旋律距離(MD)。

▲主觀評估
另外,在主觀評估中發現SongComposer在和聲和旋律-歌詞的搭配方面比GPT-3.5和GPT-4要好很多。這意味SongComposer更擅長讓歌詞和旋律相互配合得更好,讓整首歌聽起來更和諧。
旋律至歌詞生成

該方法在生成與原始歌詞緊密匹配的歌詞方面非常有效。主觀評估顯示,用戶們一致認為SongComposer在產生歌詞方面非常流暢且與旋律高度相關,能夠有效地捕捉并補充底層旋律的節奏。
歌曲延續
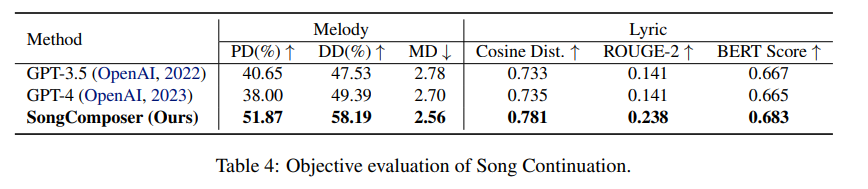
SongComposer不僅能夠獨立產出高質量的歌詞和旋律,還能夠將它們結合起來,使整首歌聽起來更和諧。
文本至歌曲生成

在文本至歌曲生成的主觀評估中,SongComposer可以根據文本提示創作出旋律優美、主題和情感完美契合的歌曲。
消融實驗
在消融研究中本文報告了針對歌詞到旋律和旋律到歌詞任務的旋律距離(MD)和BERT分數。
預訓練數據集
為了探究專門數據集對模型學習的影響,作者使用了不同純歌詞和純旋律數據集的配對數據進行訓練實驗,結果如下表所示:

研究結果顯示,如果省略了純歌詞和純旋律的數據集,模型的性能會明顯下降。這表明在訓練的早期階段,基礎旋律和抒情知識的重要性。純歌詞數據集主要提高了旋律到歌詞任務的性能,而純旋律數據集則更明顯地提高了旋律生成的水平。而結合歌詞和旋律數據集能夠帶來最佳的效果。
旋律知識的擴展詞匯
為了了解專門用于旋律知識的標記是否有利于SongComposer的性能,本文對不同的標記組合進行了消融,評估它們對模型處理和生成音樂內容的影響,如下表所示:
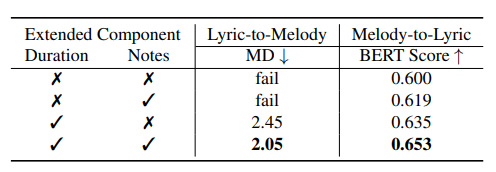
首先,在時長標記方面,直接將原始基于浮點數的秒數輸入到SongComposer中,而非應用離散數字。缺乏特殊時間標記將導致模型無法為歌詞到旋律任務生成正確結果。
相反,引入離散時長標記顯著提高了旋律到歌詞任務的表現,無論是否引入音符標記,BERT分數都提高了超過0.03。這驗證了時長離散化對掌握旋律結構的重要性。
其次,采用音符標記在兩個任務中都帶來了顯著改進,使用音符標記有助于模型更好地理解音符的含義,并提高了學習的效果。
結論
SongComposer利用符號化的歌曲表示法來生成旋律和歌詞,在各種任務中表現出色,如將歌詞轉換為旋律、旋律生成歌詞、歌曲延續和基于文本描述的歌曲創作,甚至在性能上超越了像GPT-4這樣的先進LLM模型。
相信SongComposer可以為LLM在音樂領域的創意應用開辟新的途徑。
公眾號「夕小瑤科技說」后臺回復“SongComposer”獲取論文PDF!






)
梯度消失和梯度爆炸)




射線)





--- 虛函數(virtual))



