在人工智能(AI)的研究領域中,游戲被視為現實世界的簡化模型,常常是研究的首選平臺。這些研究主要關注游戲代理的決策過程。例如,中國的傳統卡牌游戲“摜蛋”(字面意思是“扔雞蛋”)就是一個挑戰性極強的游戲,在這個游戲中,即使是專業的人類玩家有時也難以做出正確的決策。而在摜蛋游戲中也流傳著這樣一個說法:“摜蛋打得好,適合當領導”,這也是獨屬人類世界的“玩法”,和某種合作行為的體現。本篇研究將探討AI在這類復雜卡牌游戲中的決策能力,特別是它們如何通過蒙特卡洛方法和深度神經網絡來掌握游戲規則,并在游戲中做出合作等復雜行為的決策。
標題:Mastering the Game of Guandan with Deep Reinforcement Learning and Behavior Regulating
公眾號「夕小瑤科技說」后臺回復“摜蛋”獲取論文pdf。
?
背景介紹:摜蛋游戲的特點與挑戰
摜蛋,一種起源于中國江蘇省的四人固定搭檔出牌型攀牌游戲,近年來迅速走紅并登上了第五屆全國智力運動會。游戲使用兩副標準的52張牌加上四張王牌,每位玩家起始持有27張牌。摜蛋的獨特之處在于其多樣的可玩牌型組合,使得游戲富有娛樂性。游戲中的一種強力牌型被稱為“炸彈”,這也是“摜蛋”(直譯為“扔雞蛋”)名稱的由來,因為在中文里“炸彈”與“雞蛋”諧音。掌握如何使用炸彈是游戲的難點之一,因為平均來說,玩家手中不會超過三個炸彈。


摜蛋與另一種撲克游戲斗地主類似,但由于其獨特的級牌系統而有所區別。每隊以二級牌開始比賽,爭先將級牌升至A。
-
級牌不僅作為兩隊的記分系統,還具有強大的特權。例如,當前級牌可以壓制所有牌型,除了王牌,而且兩張紅桃級牌成為百搭牌。
-
百搭牌不能代表任何王牌,但可以代表其他所有牌型,使其成為非常強大的實用牌型。例如,玩家可以利用百搭牌創建強力的牌型組合,如炸彈或同花順,這在缺少特定牌時是不可能的。
摜蛋游戲由多個小局組成。我們將小局定義為在固定級牌下決定每位玩家排名的所有動作序列。當一隊的成員率先打完手中的牌,即成為莊家,該隊便贏得了小局。小局結束后,根據隊員的排名,獲勝隊伍的級牌可以升級至多三級。當獲勝隊伍的級牌為A且最后沒有隊員成為最后一名時,整個游戲結束。
每個小局開始時(除了第一個小局),玩家必須進行一個貢品過程,其中上一小局的最后一名(住戶)必須將其最高級別的牌捐贈給莊家。百搭牌不被視為最高級別的牌。為了平衡每位玩家的牌數,莊家必須返回一張不高于十的牌。
由于貢品過程與實際出牌分開,我們沒有使用強化學習來幫助代理決定捐贈/返回哪張牌,而是采用了通常足夠的基于規則的方法。
GuanZero框架簡介:結合蒙特卡洛方法和深度神經網絡
在本篇論文中研究者們提出了一個名為GuanZero的強化學習框架,旨在讓AI代理不僅掌握摜蛋游戲,還能以高效的方式理解所需的行為。GuanZero框架依賴于深度蒙特卡洛(Deep Monte-Carlo,DMC)方法,利用其出色的可擴展性,同時通過精心設計的神經網絡編碼方案培養合作等所需行為。
蒙特卡洛(MC)方法是一種簡單而有效的估算價值函數的方法,有助于發現最優策略。它們之所以簡單,是因為除了通過與環境的交互獲得的經驗(包括狀態、動作和獎勵)之外,不需要對環境有完整的了解。這種經驗甚至可以通過模擬獲得。MC方法通過平均樣本回報來解決強化學習問題。
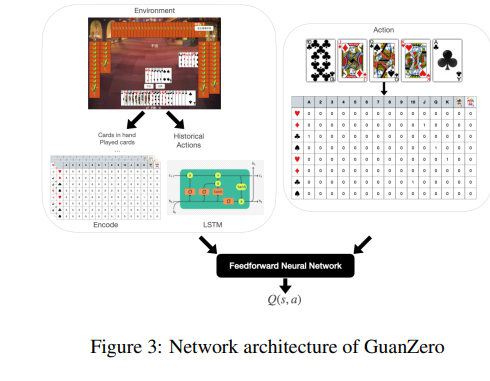
下一節將討論如何編碼狀態和動作,這些將作為輸入饋送到神經網絡中。
狀態表示與行為編碼:如何通過神經網絡編碼游戲狀態和行為
1. 卡牌的獨特編碼方式
在關乎狀態表示的問題上,神經網絡需要能夠理解和處理游戲中的各種卡牌組合。在觀察了摜蛋游戲中卡牌的重要性之后,研究者們決定將每張卡牌視為一個獨特的實體,并為其分配一個介于1到108之間的數字。
這種編碼方式可以通過一個8x15的矩陣來可視化,其中每一行代表一個特定的花色,第四行和第八行還包括了四張王牌。在這個矩陣中,存在于玩家手中的卡牌會被設置為1,其余則為0。這樣的編碼方式不僅考慮了卡牌的花色和等級,還能追蹤剩余卡牌的數量,這對于游戲來說至關重要。在輸入到神經網絡之前,這個矩陣會被展平成一個108維的一熱向量。
2. 代表合作、矮化和協助行為的一熱向量
在摜蛋中,合作行為被定義為玩家在能夠出牌打敗隊友的牌時選擇不出牌。這種行為通常被人類玩家所青睞,因為游戲的目標是盡快打出手中的卡牌,幫助隊友同樣重要。為了衡量代理執行合作行為的頻率,研究者們定義了合作率這一指標。
除此之外,還有矮化行為,即玩家選擇出一個大于對手最小手牌數量的牌組合,使得獲勝的對手難以應對。
最后是協助行為,玩家出的牌組合小于隊友的手牌數量,使得隊友更容易找到應對的牌。這些行為的狀態通過長度為三的一熱向量來表示:
-
當不滿足行為條件時,向量被設置為[1, 0, 0];
-
當滿足條件時,根據玩家的選擇,向量被設置為[0, 1, 0](執行行為)或[0, 0, 1](不執行行為)。
這樣的設計原則為代理提供了一個簡單而邏輯嚴密的機制來學習何時合作,何時不合作。
神經網絡架構:LSTM與前饋網絡的結合
神經網絡的架構旨在接受狀態s和行為a作為輸入,并估計結果的預期累積獎勵Q(s, a)。狀態由一系列特征的豐富組合表示,這些特征已在表1中詳細列出。為了正確處理歷史行為,研究者們采用了長短期記憶網絡(Long Short Term Memory ,LSTM)來捕捉行為、狀態和價值之間的長期依賴性。
LSTM網絡通過學習何時記住和何時忘記相關信息來實現這一點,同時通過允許梯度不變地流動,緩解了梯度消失問題。這些LSTM的屬性反過來又促進了學習過程。在對歷史行為進行特殊處理的同時,所有狀態中的特征以及行為都被串聯起來,輸入到一個由六層密集層組成的前饋神經網絡中,激活函數為修正線性單元(ReLU)。
分布式學習過程:如何通過并行化提高訓練效率
在深度強化學習中,分布式學習過程是提高訓練效率的關鍵策略之一。通過并行化,研究者們能夠在多個環境實例中同時運行多個智能體,這樣可以顯著加快數據收集的速度,從而加速學習過程。
1. 分布式學習的基本原理
分布式學習的核心思想是將學習任務分散到多個計算節點上。在這種設置中,每個節點都運行一個智能體的副本,并與環境進行交互以收集數據。然后,這些數據被用來更新一個共享的全局模型。這種方法的優勢在于,它允許智能體并行地探索狀態空間,而不是順序地進行,這樣可以更快地覆蓋更多的狀態—動作對。
2. GuanZero的分布式學習實現
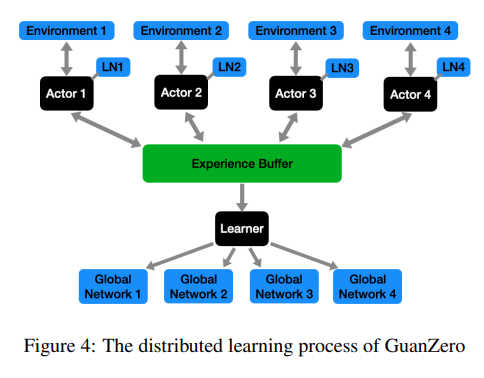
在GuanZero框架中,研究者們采用了類似于A3C(Asynchronous Advantage Actor-Critic)的分布式學習方法。為四名玩家分別設置了四個網絡,分別命名為'p1'、'p2'、'p3'和'p4',并根據第一個小游戲中的出牌順序進行分配。
然后通過將模擬任務分配給四個執行者來并行化學習過程。每個執行者在模擬智能體與環境交互時都維護一個本地網絡(LN)。這些本地網絡會定期與學習過程中維護的四個全局網絡同步。學習過程根據執行者獲得的經驗來更新這些全局網絡。
通過這種分布式學習方法,能夠快速生成大量的樣本,從而減輕了蒙特卡洛方法高方差的問題,并提高了訓練效率。此外還利用了長短期記憶(LSTM)網絡來捕捉動作、狀態和價值之間的長期依賴關系,這進一步增強了模型的學習能力。
實驗設置:對比GuanZero與其他AI代理的性能
為了驗證GuanZero框架的有效性,研究者們設置了一系列實驗來比較GuanZero與其他AI代理的性能。
1. 對手智能體
研究者們使用了多種類型的對手智能體,包括隨機選擇動作的隨機智能體、基于規則的中國關牌AI算法競賽(CGAIAC)冠軍智能體,以及使用DouZero框架訓練的基于強化學習的智能體。所有這些智能體都經過了充分的訓練直到收斂。
2. 性能評估
研究者們通過勝率(WR)作為評估智能體強度的唯一指標。在實驗中將GuanZero智能體與上述所有對手進行對抗,并記錄了勝率。
-
實驗結果顯示,GuanZero智能體在與隨機智能體對抗時取得了壓倒性的勝利,這表明隨機智能體大多數時候無法做出良好的決策。
-
在與基于規則的CGAIAC智能體對抗時,GuanZero智能體面臨了一定的抵抗,但隨著足夠數量的模擬,基于強化學習的智能體開始展現出其優勢,因為它們能夠找到針對規則智能體的反制動作。
-
此外,GuanZero智能體在與DouZero基礎智能體的對抗中最初遇到了激烈的抵抗,但隨著訓練的進行,GuanZero智能體迅速獲得了上風,并且訓練效率令人滿意,不到一周就觀察到了收斂的跡象。
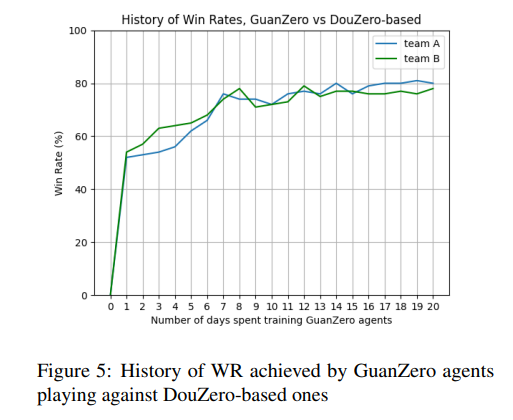
通過這些實驗,研究者們證明了GuanZero框架在關牌游戲中的有效性,并通過行為調節機制進一步提升了智能體的性能。
行為調節的效果分析:合作、矮化和協助行為的學習過程
1. 合作行為的學習與效果
GuanZero通過特定的神經網絡編碼方案,使得代理能夠學習何時合作,何時不合作。合作率的度量標準是代理實際合作的次數與合作條件滿足的次數之比。訓練過程中,GuanZero代理的合作率穩定在一個顯著高于隨機代理基線值的水平,這表明GuanZero代理成功學習了合作行為,并在實踐中有效地應用了這一行為。

2. 矮化行為的學習與效果
GuanZero代理學習矮化行為的過程較為復雜,因為其發生條件較為嚴格,且出現頻率較低。盡管如此,GuanZero代理最終還是學會了何時執行矮化行為。訓練過程顯示,矮化率有較大波動,但最終趨于穩定,代理能夠在適當的時機執行矮化行為。

3. 協助行為的學習與效果
GuanZero代理在訓練過程中學會了何時執行協助行為,協助率的趨勢與矮化行為類似,經歷了一段波動后趨于穩定。這表明GuanZero代理能夠有效地學習并執行協助行為,以提高團隊的整體表現。

結論與未來工作:GuanZero的成就與潛在改進方向
GuanZero通過深度強化學習和行為調節成功地掌握了摜蛋游戲,并在與其他先進算法的比較中展現出了優越的性能。GuanZero代理不僅學會了游戲的基本策略,還通過特別設計的神經網絡編碼方案學會了合作、矮化和協助等行為,這些行為對于團隊勝利至關重要。
未來的工作將集中在進一步提高GuanZero的性能和泛化能力上。盡管GuanZero在摜蛋游戲中取得了顯著的成就,但其特定的行為調節方案可能難以擴展到其他游戲或應用領域。
此外,研究者們還希望探索其他形式的神經網絡結構,因為當前的網絡結構相對基礎,更先進的神經網絡不僅能夠與不斷增強的計算能力相匹配,還可能引導代理發現尚未想象到的新策略。
總結:AI在摜蛋游戲中的突破意義
人工智能(AI)在游戲領域的研究一直是AI研究的熱點,尤其是在棋牌游戲中。近年來,AI在圍棋、國際象棋等完全信息游戲中取得了顯著進展,如AlphaGo和AlphaZero的成功。然而,在不完全信息的游戲中,AI面臨著更大的挑戰。摜蛋游戲就是一個具有巨大狀態空間和復雜性的不完全信息游戲,它對AI研究提出了新的挑戰。
摜蛋游戲的復雜性主要體現在其不完全信息的特性以及龐大的狀態空間。傳統算法如CFR在應用于多玩家設置時需要額外的調整,尤其是在需要鼓勵隊友間合作行為的情況下。此外,Guandan游戲中的信息集數量和合法動作數量都非常龐大,這可能會降低現有算法的效率。
-
例如,與DQN結合使用的動作消除法就是為了減少Q函數中過度估計錯誤的風險,這些錯誤可能導致學習算法收斂到次優策略。
本篇論文提出了一個名為GuanZero的強化學習框架,旨在使AI代理不僅能夠掌握摜蛋游戲,而且還能以高效的方式理解所需的行為。GuanZero框架依賴于DMC的可擴展性,并通過精心設計的神經網絡編碼方案培養合作等所需行為。
GuanZero的神經網絡架構能夠處理狀態和動作的豐富組合,并通過LSTM網絡捕捉動作、狀態和價值之間的長期依賴性。此外,研究者們還建立了一個分布式學習過程,通過并行化模擬任務來加速學習過程,并使用勝率(WR)作為評估代理強度的唯一指標。
實驗結果表明,GuanZero代理在與隨機代理、基于規則的CGAIAC代理以及基于DouZero的代理的對抗中均取得了勝利。特別是在與DouZero基于代理的對抗中,GuanZero代理在訓練過程中迅速占據上風,并且訓練效率令人滿意,不到一周就出現了收斂的跡象。
總的來說,GuanZero在摜蛋游戲中的突破意義在于其能夠處理復雜的狀態空間和不完全信息的挑戰,并通過行為調節機制學習合作等所需行為。這一突破不僅展示了AI在處理復雜棋牌游戲中的潛力,為AI能夠更好模仿人類的思維提供借鑒,也為未來AI在更廣泛領域的應用奠定了基礎。
公眾號「夕小瑤科技說」后臺回復“摜蛋”獲取論文pdf。

Unity自帶的角色控制器)




)











)
)
