準備環境
bash
/root/share/install_conda_env_internlm_base.sh InternLM
升級PIP
# 升級pip
python -m pip install --upgrade pippip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
模型下載
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b
LangChain 相關環境配置
安裝依賴
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
需要使用 huggingface 官方提供的 huggingface-cli 命令行工具。安裝依賴:
pip install -U huggingface_hub
下載:
import os# 下載模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')
使用鏡像下載代碼:
import os# 設置環境變量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下載模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')
下載過程
下載 NLTK 相關資源
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
下載本項目代碼
cd /root/data
git clone https://github.com/InternLM/tutorial
知識庫搭建
我們選擇由上海人工智能實驗室開源的一系列大模型工具開源倉庫作為語料庫來源,包括:
- OpenCompass:面向大模型評測的一站式平臺
- IMDeploy:涵蓋了 LLM 任務的全套輕量化、部署和服務解決方案的高效推理工具箱
- XTuner:輕量級微調大語言模型的工具庫
- InternLM-XComposer:浦語·靈筆,基于書生·浦語大語言模型研發的視覺-語言大模型
- Lagent:一個輕量級、開源的基于大語言模型的智能體(agent)框架
( InternLM:一個開源的輕量級訓練框架,旨在支持大模型訓練而無需大量的依賴
將上述遠程開源倉庫 Clone 到本地
# 進入到數據庫盤
cd /root/data
# clone 上述開源倉庫
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git
接著,為語料處理方便,我們將選用上述倉庫中所有的 markdown、txt 文件作為示例語料庫。注意,也可以選用其中的代碼文件加入到知識庫中,但需要針對代碼文件格式進行額外處理(因為代碼文件對邏輯聯系要求較高,且規范性較強,在分割時最好基于代碼模塊進行分割再加入向量數據庫)。
我們首先將上述倉庫中所有滿足條件的文件路徑找出來,我們定義一個函數,該函數將遞歸指定文件夾路徑,返回其中所有滿足條件(即后綴名為 .md 或者 .txt 的文件)的文件路徑:
import os
def get_files(dir_path):# args:dir_path,目標文件夾路徑file_list = []for filepath, dirnames, filenames in os.walk(dir_path):# os.walk 函數將遞歸遍歷指定文件夾for filename in filenames:# 通過后綴名判斷文件類型是否滿足要求if filename.endswith(".md"):# 如果滿足要求,將其絕對路徑加入到結果列表file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))return file_list
加載數據
from tqdm import tqdm
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoaderdef get_text(dir_path):# args:dir_path,目標文件夾路徑# 首先調用上文定義的函數得到目標文件路徑列表file_lst = get_files(dir_path)# docs 存放加載之后的純文本對象docs = []# 遍歷所有目標文件for one_file in tqdm(file_lst):file_type = one_file.split('.')[-1]if file_type == 'md':loader = UnstructuredMarkdownLoader(one_file)elif file_type == 'txt':loader = UnstructuredFileLoader(one_file)else:# 如果是不符合條件的文件,直接跳過continuedocs.extend(loader.load())return docs
構建向量數據庫
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
接著我們選用開源詞向量模型 Sentence Transformer 來進行文本向量化。LangChain 提供了直接引入 HuggingFace 開源社區中的模型進行向量化的接口:
from langchain.embeddings.huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
同時,考慮到 Chroma 是目前最常用的入門數據庫,我們選擇 Chroma 作為向量數據庫,基于上文分塊后的文檔以及加載的開源向量化模型,將語料加載到指定路徑下的向量數據庫:
from langchain.vectorstores import Chroma# 定義持久化路徑
persist_directory = 'data_base/vector_db/chroma'
# 加載數據庫
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings,persist_directory=persist_directory # 允許我們將persist_directory目錄保存到磁盤上
)
# 將加載的向量數據庫持久化到磁盤上
vectordb.persist()
整體腳本
# 首先導入所需第三方庫
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os# 獲取文件路徑函數
def get_files(dir_path):# args:dir_path,目標文件夾路徑file_list = []for filepath, dirnames, filenames in os.walk(dir_path):# os.walk 函數將遞歸遍歷指定文件夾for filename in filenames:# 通過后綴名判斷文件類型是否滿足要求if filename.endswith(".md"):# 如果滿足要求,將其絕對路徑加入到結果列表file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))return file_list# 加載文件函數
def get_text(dir_path):# args:dir_path,目標文件夾路徑# 首先調用上文定義的函數得到目標文件路徑列表file_lst = get_files(dir_path)# docs 存放加載之后的純文本對象docs = []# 遍歷所有目標文件for one_file in tqdm(file_lst):file_type = one_file.split('.')[-1]if file_type == 'md':loader = UnstructuredMarkdownLoader(one_file)elif file_type == 'txt':loader = UnstructuredFileLoader(one_file)else:# 如果是不符合條件的文件,直接跳過continuedocs.extend(loader.load())return docs# 目標文件夾
tar_dir = ["/root/data/InternLM","/root/data/InternLM-XComposer","/root/data/lagent","/root/data/lmdeploy","/root/data/opencompass","/root/data/xtuner"
]# 加載目標文件
docs = []
for dir_path in tar_dir:docs.extend(get_text(dir_path))# 對文本進行分塊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)# 加載開源詞向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 構建向量數據庫
# 定義持久化路徑
persist_directory = 'data_base/vector_db/chroma'
# 加載數據庫
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings,persist_directory=persist_directory # 允許我們將persist_directory目錄保存到磁盤上
)
# 將加載的向量數據庫持久化到磁盤上
vectordb.persist()
在 /root/data 下新建一個 demo目錄,將該腳本和后續腳本均放在該目錄下運行。運行上述腳本,即可在本地構建已持久化的向量數據庫,后續直接導入該數據庫即可,無需重復構建。
腳本執行過程
InternLM 接入 LangChain
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchclass InternLM_LLM(LLM):# 基于本地 InternLM 自定義 LLM 類tokenizer : AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, model_path :str):# model_path: InternLM 模型路徑# 從本地初始化模型super().__init__()print("正在從本地加載模型...")self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()self.model = self.model.eval()print("完成本地模型的加載")def _call(self, prompt : str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):# 重寫調用函數system_prompt = """You are an AI assistant whose name is InternLM (書生·浦語).- InternLM (書生·浦語) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能實驗室). It is designed to be helpful, honest, and harmless.- InternLM (書生·浦語) can understand and communicate fluently in the language chosen by the user such as English and 中文."""messages = [(system_prompt, '')]response, history = self.model.chat(self.tokenizer, prompt , history=messages)return response@propertydef _llm_type(self) -> str:return "InternLM"
上述類定義中,我們分別重寫了構造函數和 _call 函數:對于構造函數,我們在對象實例化的一開始加載本地部署的 InternLM 模型,從而避免每一次調用都需要重新加載模型帶來的時間過長;_call 函數是 LLM 類的核心函數,LangChain 會調用該函數來調用 LLM,在該函數中,我們調用已實例化模型的 chat 方法,從而實現對模型的調用并返回調用結果。
在整體項目中,我們將上述代碼封裝為 LLM.py,后續將直接從該文件中引入自定義的 LLM 類。
構建檢索問答鏈
加載向量數據庫
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os# 定義 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量數據庫持久化路徑
persist_directory = 'data_base/vector_db/chroma'# 加載數據庫
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embeddings
)
實例化自定義 LLM 與 Prompt Template
from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是誰")
構建檢索問答鏈,還需要構建一個 Prompt Template,該 Template 其實基于一個帶變量的字符串,在檢索之后,LangChain 會將檢索到的相關文檔片段填入到 Template 的變量中,從而實現帶知識的 Prompt 構建。我們可以基于 LangChain 的 Template 基類來實例化這樣一個 Template 對象:from langchain.prompts import PromptTemplate# 我們所構造的 Prompt 模板
template = """使用以下上下文來回答用戶的問題。如果你不知道答案,就說你不知道。總是使用中文回答。
問題: {question}
可參考的上下文:
···
{context}
···
如果給定的上下文無法讓你做出回答,請回答你不知道。
有用的回答:"""# 調用 LangChain 的方法來實例化一個 Template 對象,該對象包含了 context 和 question 兩個變量,在實際調用時,這兩個變量會被檢索到的文檔片段和用戶提問填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
構建檢索問答鏈
from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
得到的 qa_chain 對象即可以實現我們的核心功能,即基于 InternLM 模型的專業知識庫助手。我們可以對比該檢索問答鏈和純 LLM 的問答效果:
# 檢索問答鏈回答效果
question = "什么是InternLM"
result = qa_chain({"query": question})
print("檢索問答鏈回答 question 的結果:")
print(result["result"])# 僅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的結果:")
print(result_2)
運行結果

部署 Web Demo
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQAdef load_chain():# 加載問答鏈# 定義 Embeddingsembeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")# 向量數據庫持久化路徑persist_directory = 'data_base/vector_db/chroma'# 加載數據庫vectordb = Chroma(persist_directory=persist_directory, # 允許我們將persist_directory目錄保存到磁盤上embedding_function=embeddings)# 加載自定義 LLMllm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")# 定義一個 Prompt Templatetemplate = """使用以下上下文來回答最后的問題。如果你不知道答案,就說你不知道,不要試圖編造答案。盡量使答案簡明扼要。總是在回答的最后說“謝謝你的提問!”。{context}問題: {question}有用的回答:"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 運行 chainqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})return qa_chain
接著我們定義一個類,該類負責加載并存儲檢索問答鏈,并響應 Web 界面里調用檢索問答鏈進行回答的動作:
class Model_center():"""存儲檢索問答鏈的對象 """def __init__(self):# 構造函數,加載檢索問答鏈self.chain = load_chain()def qa_chain_self_answer(self, question: str, chat_history: list = []):"""調用問答鏈進行回答"""if question == None or len(question) < 1:return "", chat_historytry:chat_history.append((question, self.chain({"query": question})["result"]))# 將問答結果直接附加到問答歷史中,Gradio 會將其展示出來return "", chat_historyexcept Exception as e:return e, chat_history
然后我們只需按照 Gradio 的框架使用方法,實例化一個 Web 界面并將點擊動作綁定到上述類的回答方法即可:
import gradio as gr# 實例化核心功能對象
model_center = Model_center()
# 創建一個 Web 界面
block = gr.Blocks()
with block as demo:with gr.Row(equal_height=True): with gr.Column(scale=15):# 展示的頁面標題gr.Markdown("""<h1><center>InternLM</center></h1><center>書生浦語</center>""")with gr.Row():with gr.Column(scale=4):# 創建一個聊天機器人對象chatbot = gr.Chatbot(height=450, show_copy_button=True)# 創建一個文本框組件,用于輸入 prompt。msg = gr.Textbox(label="Prompt/問題")with gr.Row():# 創建提交按鈕。db_wo_his_btn = gr.Button("Chat")with gr.Row():# 創建一個清除按鈕,用于清除聊天機器人組件的內容。clear = gr.ClearButton(components=[chatbot], value="Clear console")# 設置按鈕的點擊事件。當點擊時,調用上面定義的 qa_chain_self_answer 函數,并傳入用戶的消息和聊天歷史記錄,然后更新文本框和聊天機器人組件。db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[msg, chatbot], outputs=[msg, chatbot])gr.Markdown("""提醒:<br>1. 初始化數據庫時間可能較長,請耐心等待。2. 使用中如果出現異常,將會在文本輸入框進行展示,請不要驚慌。 <br>""")
gr.close_all()
# 直接啟動
demo.launch()
運行界面
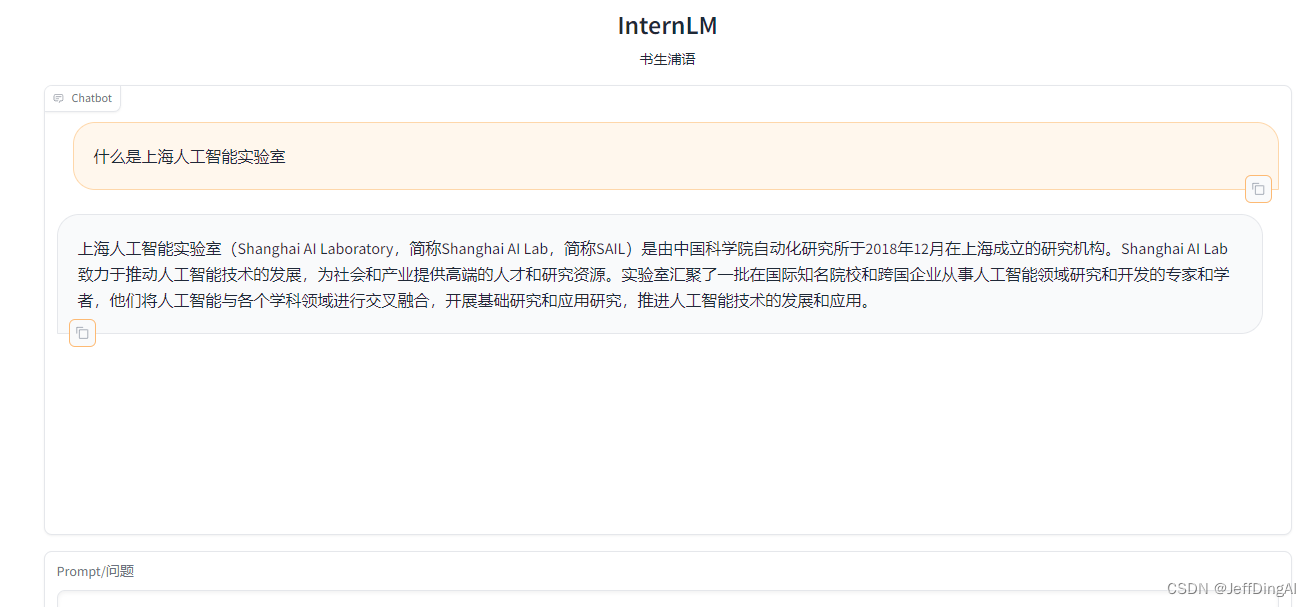









)


)



)

)
