深度學習
深度學習是加深了層的深度神經網絡
加深網絡
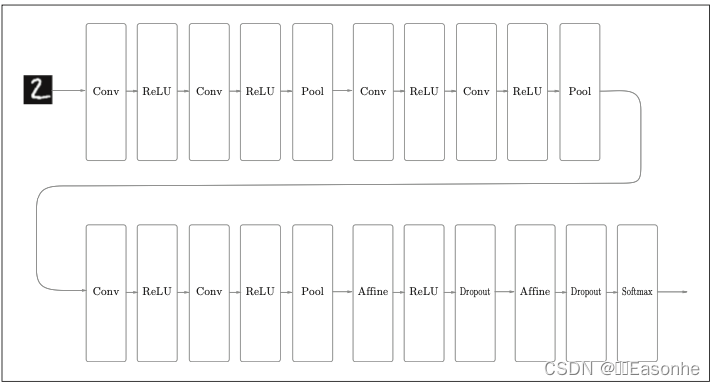
本節我們將這些已經學過的技術匯總起來,創建一個深度網絡,挑戰 MNIST 數據集的手寫數字識別
向更深的網絡出發
- 基于3×3的小型濾波器的卷積層。
- 激活函數是ReLU。
- 全連接層的后面使用Dropout層。
- 基于Adam的最優化。
- 使用He初始值作為權重初始值。
進一步提高識別精度
可以發現進一步提高識別精度的技術和 線索。比如,集成學習、學習率衰減、Data Augmentation(數據擴充)等都有 助于提高識別精度。尤其是Data Augmentation,雖然方法很簡單,但在提高 識別精度上效果顯著,Data Augmentation基于算法“人為地”擴充輸入圖像(訓練圖像)
加深層的動機
這種比賽的結果顯示,最近前幾名 的方法多是基于深度學習的,并且有逐漸加深網絡的層的趨勢。也就是說, 可以看到層越深,識別性能也越高。
加深層的好處:
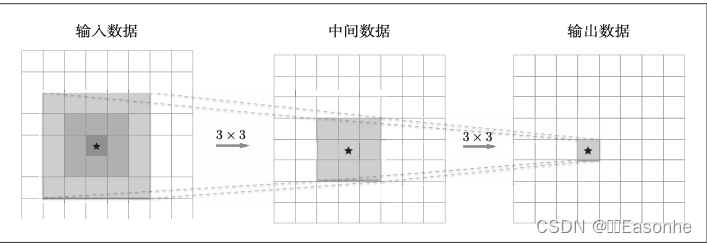
- 可以減少網絡的參數數量。
一次 5 × 5 的卷積運算的區域可以由兩次 3 × 3 的卷積運算抵充。并且, 相對于前者的參數數量 25(5 × 5),后者(反向)一共是 18(2 × 3 × 3),通過疊加卷 積層,參數數量減少了。而且,這個參數數量之差會隨著層的加深而變大。 比如,重復三次 3 × 3 的卷積運算時,參數的數量總共是 27。而為了用一次 卷積運算“觀察”與之相同的區域,需要一個 7 × 7 的濾波器,此時的參數數 量是 49。
- 使學習更加高效。
通過加深層,可以分層次地傳遞信息,這一點也很重要。比如,因為提 取了邊緣的層的下一層能夠使用邊緣的信息,所以應該能夠高效地學習更加 高級的模式。也就是說,通過加深層,可以將各層要學習的問題分解成容易 解決的簡單問題,從而可以進行高效的學習。
深度學習的小歷史
一般認為,現在深度學習之所以受到大量關注,其契機是 2012 年舉辦 的大規模圖像識別大賽ILSVRC(ImageNet Large Scale Visual Recognition Challenge)。在那年的比賽中,基于深度學習的方法(通稱 AlexNet)以壓倒 性的優勢勝出,徹底顛覆了以往的圖像識別方法。2012 年深度學習的這場逆襲成為一個轉折點,在之后的比賽中,深度學習一直活躍在舞臺中央。
ImageNet
ImageNet 是擁有超過 100 萬張圖像的數據集。如圖 8-7 所示,它包含 了各種各樣的圖像,并且每張圖像都被關聯了標簽(類別名)。每年都會舉辦 使用這個巨大數據集的 ILSVRC 圖像識別大賽。

這些年深度學習取得了不斐的成績,其中 VGG、GoogLeNet、ResNet深度學習 已廣為人知,在與深度學習有關的各種場合都會遇到這些網絡
VGG
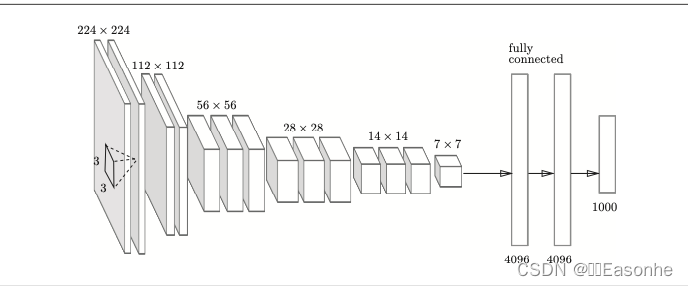
VGG 是由卷積層和池化層構成的基礎的 CNN,它的特點在于將有權重的層(卷積層或者全連接層)疊加至 16 層(或者 19 層), 具備了深度(根據層的深度,有時也稱為“VGG16”或“VGG19”)。
于 3×3 的小型濾波器的卷積層的運算是 連續進行的。重復進行“卷積層重疊 2 次到 4 次,再通過池化 層將大小減半”的處理,最后經由全連接層輸出結果。
GoogLeNet
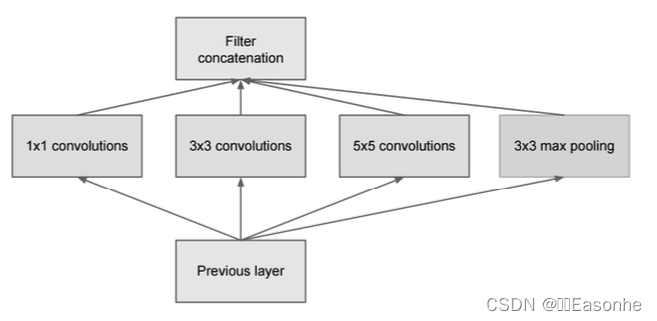
GoogLeNet 的特征是,網絡不僅 在縱向上有深度,在橫向上也有深度(廣度),GoogLeNet 在橫向上有“寬度”,這稱為“Inception 結構”
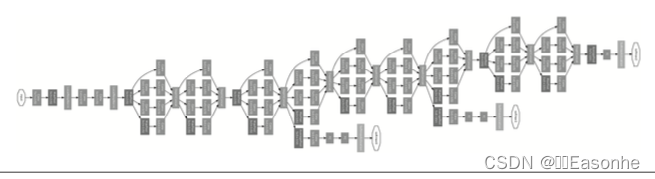
Inception 結構使用了多個大小不同的濾波器(和池化), 最后再合并它們的結果。GoogLeNet 的特征就是將這個 Inception 結構用作 一個構件(構成元素),很多地方都使用了大小為1 × 1 的濾波器的卷積層。這個 1 × 1 的卷積運算通過在通道方向上減小大小,有助于減少參數和實現高速化處理
ResNet
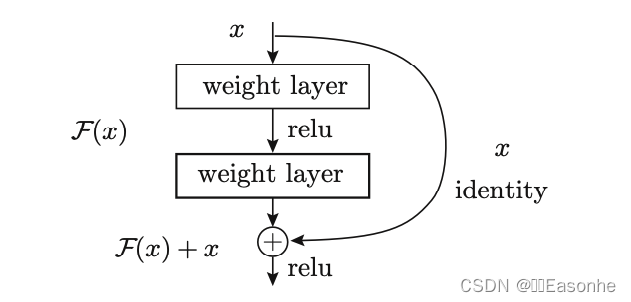
我們已經知道加深層對于提升性能很重要。但是,在深度學習中,過度 加深層的話,很多情況下學習將不能順利進行,導致最終性能不佳。ResNet 中, 為了解決這類問題,導入了“快捷結構”(也稱為“捷徑”或“小路”)。導入這 個快捷結構后,就可以隨著層的加深而不斷提高性能了(當然,層的加深也 是有限度的)。
在連續 2 層的卷積層中,將輸入 x 跳著連接至 2 層后的輸出。 這里的重點是,通過快捷結構,原來的 2 層卷積層的輸出 F(x) 變成了 F(x) + x。 通過引入這種快捷結構,即使加深層,也能高效地學習。這是因為,通過快 捷結構,反向傳播時信號可以無衰減地傳遞。
深度學習的高速化
大多數深度學習的框架都支持 GPU(Graphics Processing Unit),可以高速地處理大量的運算。另外,最 近的框架也開始支持多個 GPU 或多臺機器上的分布式學習
需要努力解決的問題
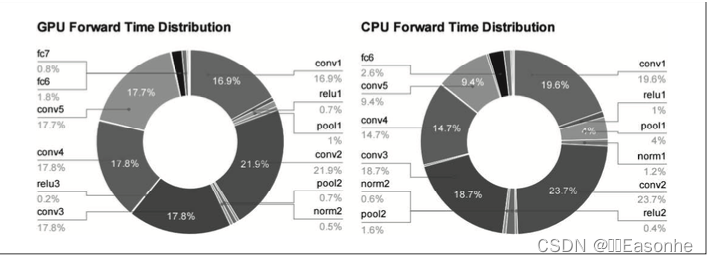
從圖中可知,AlexNex 中,大多數時間都被耗費在卷積層上。實際上, 卷積層的處理時間加起來占 GPU 整體的 95%,占 CPU 整體的 89% !因此, 如何高速、高效地進行卷積層中的運算是深度學習的一大課題
基于 GPU 的高速化
GPU 原本是作為圖像專用的顯卡使用的,但最近不僅用于圖像處理, 也用于通用的數值計算。由于 GPU 可以高速地進行并行數值計算,因此 GPU 計算的目標就是將這種壓倒性的計算能力用于各種用途
分布式學習
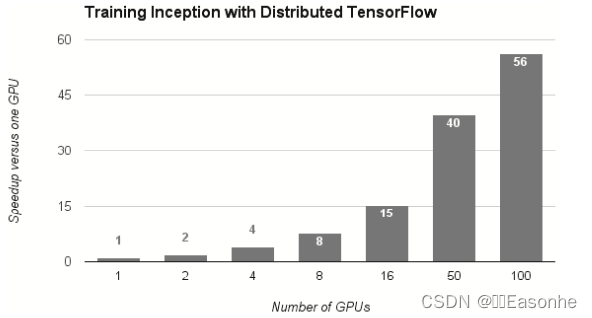
為了進一步提高深度學習所需的計算的速度,可以考慮在多個 GPU 或者多臺機器上進行分布式計算。現在的深度學習框架中,出現了好幾個支持 多 GPU 或者多機器的分布式學習的框架。其中,Google 的 TensorFlow、微 軟的CNTK(Computational Network Toolki)在開發過程中高度重視分布式 學習。以大型數據中心的低延遲·高吞吐網絡作為支撐,基于這些框架的分 布式學習呈現出驚人的效果。
基于TensorFlow的分布式學習的效果:橫軸是GPU的個數,縱軸是與單個 GPU 相比時的高速化率
關于分布式學習,“如何進行分布式計算”是一個非常難的課題。它包 含了機器間的通信、數據的同步等多個無法輕易解決的問題。可以將這些難 題都交給 TensorFlow 等優秀的框架
運算精度的位數縮減
在深度學習的高速化中,除了計算量之外,內存容量、總線帶寬等也有 可能成為瓶頸。關于內存容量,需要考慮將大量的權重參數或中間數據放在 內存中。關于總線帶寬,當流經 GPU(或者 CPU)總線的數據超過某個限制時, 就會成為瓶頸。考慮到這些情況,我們希望盡可能減少流經網絡的數據的位數。計算機中表示小數時,有 32 位的單精度浮點數和 64 位的雙精度浮點數 等格式。根據以往的實驗結果,在深度學習中,即便是 16 位的半精度浮點 數(half float),也可以順利地進行學習,由此可以認為今后半精度浮點數將被作為標準使用。特別是在面向 嵌入式應用程序中使用深度學習時,位數縮減非常重要。
深度學習的應用案例
深度學習在圖像、語音、自然語言等各個不同 的領域,深度學習都展現了優異的性能。以計算機視覺這個領域為中 心,介紹幾個深度學習能做的事情(應用)
物體檢測
物體檢測是從圖像中確定物體的位置,并進行分類的問題
物體檢測是比物體識別更難的問題。之前介紹的物體 識別是以整個圖像為對象的,但是物體檢測需要從圖像中確定類別的位置, 而且還有可能存在多個物體。

在使用 CNN 進行物體檢測的方法中,有一個叫作 R-CNN 的有名的方法
圖像分割
圖像分割是指在像素水平上對圖像進行分類
使用以像 素為單位對各個對象分別著色的監督數據進行學習。然后,在推理時,對輸 入圖像的所有像素進行分類。

要基于神經網絡進行圖像分割,最簡單的方法是以所有像素為對象,對每個像素執行推理處理
有人提出了一個名為FCN(Fully Convolutional Network)[37] 的方法。該方法通過一次 forward 處理,對所有像素進行分類。
FCN 的字面意思是“全部由卷積層構成的網絡”。相對于一般的 CNN 包 含全連接層,FCN 將全連接層替換成發揮相同作用的卷積層。
圖像標題的生成
一個基于深度學習生成圖像標題的代表性方法是被稱為 NIC(Neural Image Caption)的模型,NIC由深層的CNN和處理自然語 言的RNN(Recurrent Neural Network)構成。RNN是呈遞歸式連接的網絡, 經常被用于自然語言、時間序列數據等連續性的數據上。我們將組合圖像和自然語言等多種信息進行的處理稱為多模態處理
深度學習的未來
介紹幾個揭示了深度學習的可能性和未來的研究
圖像風格變換
如果指定將梵高的繪畫風格應用于內容圖像,深度學習 就會按照指示繪制出新的畫作

圖像的生成
DCGAN 中使用了深度學習,其技術要點是使用了 Generator(生成者) 和 Discriminator(識別者)這兩個神經網絡。Generator 生成近似真品的圖 像,Discriminator 判別它是不是真圖像(是 Generator 生成的圖像還是實際 拍攝的圖像)。像這樣,通過讓兩者以競爭的方式學習,Generator 會學習到 更加精妙的圖像作假技術,Discriminator 則會成長為能以更高精度辨別真假 的鑒定師。兩者互相切磋、共同成長,這是GAN(Generative Adversarial Network)這個技術的有趣之處。在這樣的切磋中成長起來的 Generator 最終
會掌握畫出足以以假亂真的圖像的能力(或者說有這樣的可能)。
沒有給出監督數據的問題稱為無監督學習
前面我們學習的神經網絡都有對應的監督數據稱為監督學習
自動駕駛
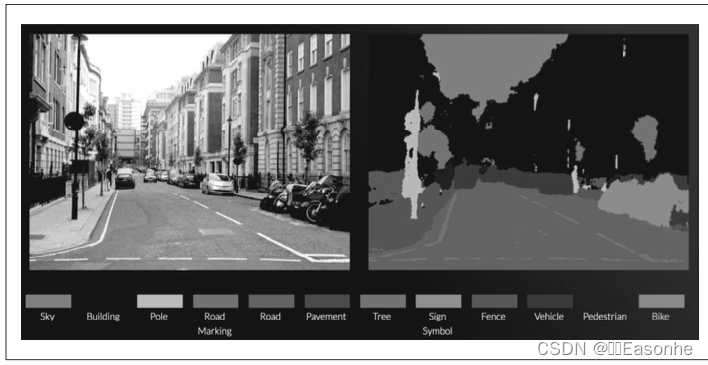
在識別周圍環境的技術中,深度學習的力量備受期待。比如,基于 CNN 的神經網絡 SegNet,可以像圖 8-25 那樣高精度 地識別行駛環境。
基于深度學習的圖像分割的例子:道路、車輛、建筑物、人行道等被高精度地識 別了出來
Deep Q-Network(強化學習)
就像人類通過摸索試驗來學習一樣(比如騎自行車),讓計算機也在摸索 試驗的過程中自主學習,這稱為強化學習(reinforcement learning)。強化學 習和有“教師”在身邊教的“監督學習”有所不同。 強化學習的基本框架是,代理(Agent)根據環境選擇行動,然后通過這 個行動改變環境。根據環境的變化,代理獲得某種報酬。強化學習的目的是 決定代理的行動方針,以獲得更好的報酬。報酬并不是 確定的,只是“預期報酬”。比如,在《超級馬里奧兄弟》這款電子游戲中, 讓馬里奧向右移動能獲得多少報酬不一定是明確的。這時需要從游戲得分(獲 得的硬幣、消滅的敵人等)或者游戲結束等明確的指標來反向計算,決定“預 期報酬”。如果是監督學習的話,每個行動都可以從“教師”那里獲得正確的評價。
在 Q 學習中,為了確定最合適的行動,需要確定一個被稱為最優行動價值函數的函數。為了近似這個函數,DQN 使用了深度學習 (CNN)。
小結
深度學習領域還有很多尚未揭曉的東西,新的研究正一個接一個地出現。 今后,全世界的研究者和技術專家也將繼續積極從事這方面的研究,一定能 實現目前無法想象的技術。
- 對于大多數的問題,都可以期待通過加深網絡來提高性能。
- 在最近的圖像識別大賽ILSVRC中,基于深度學習的方法獨占鰲頭,使用的網絡也在深化。
- VGG、GoogLeNet、ResNet等是幾個著名的網絡。
- 基于GPU、分布式學習、位數精度的縮減,可以實現深度學習的高速化。
- 深度學習(神經網絡)不僅可以用于物體識別,還可以用于物體檢測、圖像分割。
- 深度學習的應用包括圖像標題的生成、圖像的生成、強化學習等。最近,深度學習在自動駕駛上的應用也備受期待。
end
內容來自《深度學習入門:基于Python的理論與實現》



)

)


)





)




