??
??個人主頁:日刷百題
系列專欄:〖C/C++小游戲〗〖Linux〗〖數據結構〗?〖C語言〗
🌎歡迎各位→點贊👍+收藏??+留言📝??
?
一、?命名空間
#include<stdio.h>
#include<stdlib.h>int rand = 10;int main()
{printf("%d", rand);return 0;
}// 編譯后會報錯:error C2365: “rand”: 重定義;以前的定義是“函數”
在這段程序中,不引用頭文件#include <stdlib.h>是可以正常運行的,但引用后程序就會報錯,這是什么原因呢?因為?rand?在?<stdlib.h>?中已有了定義,這里報了重定義的錯誤。
1.1 命名空間的定義
命名空間的定義由兩部分構成:首先是關鍵字namespace,后面跟命名空間的名字,然后接一對花括號,花括號中即為命名空間的成員。?
1. 命名空間可以定義變量/函數/類型
2. 命名空間可以嵌套
3. 同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成同一個命名空間中。
namespace A
{// 命名空間中可以定義變量/函數/類型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}//命名空間可以嵌套
namespace a
{namespace b{void push(){cout << 'b' << endl;}}
} 注意:
- 一個命名空間就定義了一個新的作用域,命名空間中的所有內容都局限于該命名空間中
- 用一個工程中允許出現多個相同名稱的命名空間,編譯器最后會將它們合并為一個命名空間。
1.2? 命名空間使用
命名空間的使用三種方式:
1.2.1? 加命名空間名稱及域作用限定符
namespace N
{int a = 10;int b = 5;
}int main()
{printf("%d\n", N::a);return 0;
}
1.2.2? ?使用using將命名空間中某個成員引入
using N::b;
int main()
{printf("%d\n", N::a);printf("%d\n", b);return 0;
}
1.2.3? ?使用using namespace 命名空間名稱 引入(展開命名空間)
namespace N
{int a = 10;int b = 5;
}int a = 20;using namespace N;int main()
{printf("%d\n", a); //a不明確,有二義性printf("%d\n", ::a); //訪問全局的aprintf("%d\n", N::a); //訪問N中的aprintf("%d\n", b);return 0;
}
注意:
如果命名空間沒有展開,編譯器默認是不會搜索命名空間中的變量,去訪問變量是訪問不到的。
訪問的優先級:局部域 > 全局域
1.3? std命名空間的使用
std是C++標準庫的命名空間,如何展開std使用更合理呢?
(1)在日常練習中,建議直接using namespace std;
(2)在項目開發中代碼較多、規模 大,就很容易出現跟庫重名的類型、對象、函數問題。所以建議在項目開發中像std::cout這樣使用,或者using std::cout展開常用的庫對象、類型等方式。
二、C++輸入和輸出
#include<iostream>
using namespace std;int main()
{int a = 0;double b = 0;cin >> a >> b;//流提取運算法cout << a << " " << b << endl;//流插入運算法 endl相當于換行cout << a << " " << b << '\n';return 0;
}
- 使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含< iostream >頭文件 以及按命名空間使用方法使用std。
- ?cout和cin是全局的流對象,endl是特殊的C++符號,表示換行輸出,他們都包含在包含< iostream >頭文件中。
- <<是流插入運算符,>>是流提取運算符。
- 使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣,需要手動控制格式。
? ? ? ? ?C++ 的輸入輸出可以自動識別變量類型。
三、缺省參數
3.1 缺省參數的定義
缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。
#include<iostream>
using namespace std;void Test(int a = 0)
{cout << a << endl;
}int main()
{Test();//沒有傳參時,使用參數的默認值a=0Test(1);//傳參時,使用指定的實參a=1
}
3.2? 缺省參數分類
(1)全缺省參數(全默認參數)–所有參數都給了缺省值
void Test(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a ;cout << " b = " << b ;cout << " c = " << c << endl;
}int main()
{Test(1, 2, 3);Test(1, 2);Test(1);Test();return 0;
}
輸出結果:

注:全缺省參數在傳參時,參數是按照從左往右的順序進行缺省的,不能跳著缺省,例如:Test(1, ,3)?,讓第一個形參和第三個形參都使用傳遞值,而讓第二個參數使用缺省值,這種做法是不被允許的。
(2)半缺省參數 – 部分的參數給了缺省值
void Test(int a , int b = 20, int c = 30)
{cout << "a = " << a ;cout << " b = " << b ;cout << " c = " << c << endl;
}int main()
{Test(1, 2, 3);Test(1, 2);Test(1);return 0;
}
注:
1.?半缺省參數必須從右往左依次來給出,不能跳躍著傳
2.?缺省參數不能在函數聲明和定義中同時出現
3.?缺省值必須是常量或者全局變量
4.?C語言不支持(編譯器不支持)
5. 函數的聲明和定義分離時,必須在聲明給缺省值
四、函數重載
自然語言中,一個詞可以有多重含義,人們可以通過上下文來判斷該詞真實的含義,即該詞被重載了。?
4.1 函數重載的概念
函數重載是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數或類型或類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
4.2 函數重載的種類
(1)參數類型不同
int Add(int left, int right)
{return left + right;
}double Add(double left, double right)
{return left + right;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.23, 7.8) << endl;return 0;
}
?上面的代碼定義了兩個同名的Add函數,但是它們的參數類型不同,第一個函數的兩個參數都是int型,第二個函數的兩個參數都是double型,在調用Add函數的時候,編譯器會根據所傳實參的類型自動判斷調用哪個函數。
(2)參數個數不同
void fun()
{cout << "fun()" << endl;
}void fun(int a)
{cout << "fun(a)" << endl;
}int main()
{fun();fun(8);return 0;
}
?上面的代碼定義了兩個同名的fun函數,但是它們的參數個數不同,第一個函數沒有參數,第二個函數有倆個參數,在調用fun函數的時候,編譯器會根據所傳實參的個數自動判斷調用哪個函數。
(3)參數類型順序不同
void Fun(int a, char b)
{cout << " Fun(int a,char b)" << endl;
}void Fun(char a,int b)
{cout << " Fun(char a,int b)" << endl;
}int main()
{Fun(1, 'i');Fun('i', 1);return 0;
}
(4)有缺省參數的
void Fun()
{cout << "f()" << endl;
}void Fun(int a = 10)
{cout << "f(int a)" << endl;
}int main()
{Fun(); //無參調用會出現歧義Fun(1); //調用的是第二個return 0;
}
上面代碼中的兩個Fun函數構成函數重載,編譯可以通過,因為第一個沒有參數,第二個有一個整型參數,屬于上面的參數個數不同的情況。但是Fun函數存在一個問題:在沒有參數調用的時候會產生歧義,因為有缺省參數,所以對兩個Fun函數來說,都可以不傳參。
注意??:
如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
4.3 C++支持函數重載的原理
在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
我們想理解清楚函數重載,還要了解函數簽名的概念,函數簽名包含了一個函數的信息,包括函數名、它的參數類型、他所在的類和名稱空間以及其他信息。函數簽名用于識別不同的函數。 C++編譯器和鏈接器都使用符號來標識和處理函數和變量,所以對于不同函數簽名的函數,即使函數名相同,編譯器和鏈接器都認為他們是不同的函數。
Linux環境下采用C語言編譯器編譯后結果:
可以看出經過gcc編譯后,函數名字的修飾沒有發生改變。這也就是為什么C語言不支持函數重載,因為同名函數沒辦法區分。
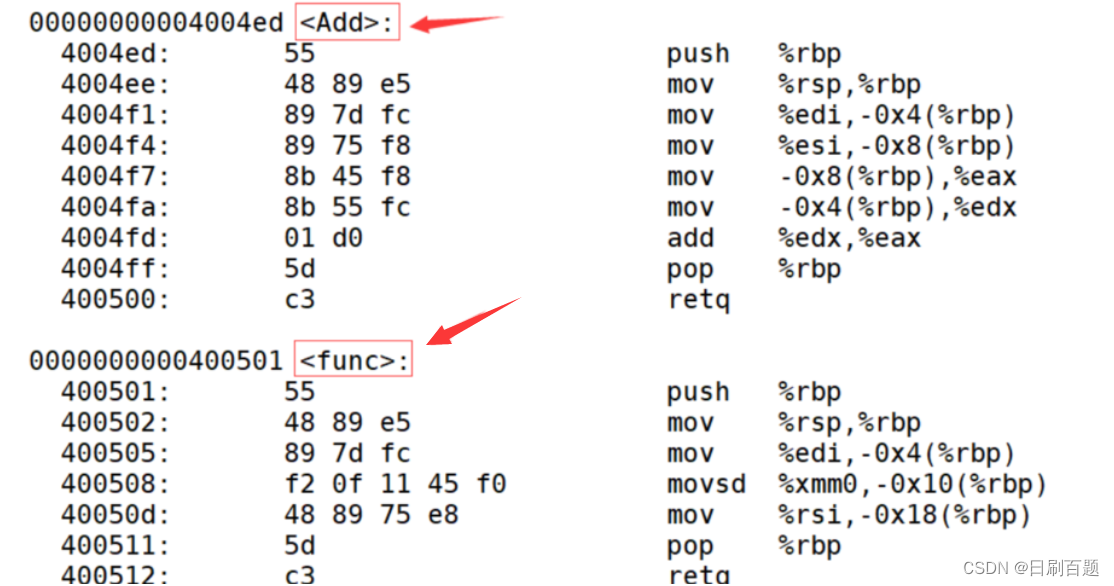
采用C++編譯器編譯后結果:
其中_Z是固定的前綴;3表示函數名的長度;Add就是函數名;i是int的縮寫,兩個i表示兩個參數都是int類型,d是double的縮寫,兩個d表示兩個參數都是double類型。C++就是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。通過分析可以發現,修飾后的名稱中并不包含任何于函數返回值有關的信息,因此也驗證了上面說的返回值的類型與函數是否構成重載無關。

總結:
C語言之所以沒辦法支持重載,鏈接的時候依照函數名去符號表轉換(因為cpu只能看懂二進制的數字--->轉換)來獲取函數地址,結果2個函數名一樣(轉換得到的結果一樣),區分不了。
C++是通過函數修飾規則來區分,只要是參數類型,參數個數,參數順序不同,修飾出來的名字就不一樣,就支持了重載。
如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
五、引用
5.1 引用概念
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空 間,它和它引用的變量共用同一塊內存空間。
語法:
類型& 引用變量名(對象名)=引用實體
int main() {int a = 0;int& b = a;return 0; }注意:引用類型必須和引用實體是同種類型的
5.2 引用特性?
1. 引用在定義時必須初始化
int main()
{int a = 10;int& b; //錯誤的int& b = a;//正確的return 0;
}
在使用引用時,我們必須對變量進行初始化。int& b = a;,這樣的代碼才是被允許的。
2.一個變量可以有多個引用
int main()
{int a = 10;int& b = a;int& c = a;return 0;
}
上面代碼中,b和c都是a的別名。比如:李逵,在家稱為"鐵牛",江湖上人稱"黑旋風"。
3. 引用一旦引用一個實體,再不能引用其他實體
int main()
{int a = 10;int b = 20;int& c = a;c = b;return 0;
}
解析:
a和c的地址相同,c是a的別名;b和c的地址不同,所以c = b表示的不是c是b引用,而是把b變量的值賦值給c引用的實體,c依舊是a的引用,所以引用一旦引用一個實體,再不能引用其他實體,也就是引用不能改變指向。
5.3 常引用
const修飾的變量,只能讀不能寫(這里的權限,指的是讀和寫)
#include<iostream> using namespace std; int main() {int a = 10;//可讀可寫//權限的縮小---允許const int& b = a;//只可讀//權限的放大---不允許const int& c = a;//只可讀//int& d = c;//可讀可寫const int& z = 10;const int& y = a + z;//int& y=a+z;//錯誤的return 0; }取別名原則:對于引用類型,權限只能縮小,不能放大
?臨時變量具有常性
#include <iostream>int main()
{int a = 10;int& b = a;const int& c = 20;//常量也可以取別名double d = 15.3;int f = d;//在這里,相當于d整型提升成臨時變量,臨時變量把值賦給f(臨時變量具有常性)const int& e = d;//這里的e不是d的引用,而是臨時變量的引用return 0;
}
5.4 引用的使用場景
- 做參數
引用做參數的意義:
?(1)做輸出型參數,即要求形參的改變可以影響實參
(2)提高效率,自定義類型傳參,用引用可以避免拷貝構造,尤其是大對象和深拷貝對象
交換兩個整型變量:
void Swap(int& num1, int& num2) {int tmp = num1;num1 = num2;num2 = tmp; }int main() {int a = 5;int b = 10;Swap(a,b);return 0; }如上代碼,我們可以使用引用做參數實現了兩個數的交換,
num1是?a?的引用,和?a?在同一塊空間,對num1的修改也就是對?a?修改,?b?同理,所以在函數體內交換num1和num2實際上就是交換?a?和?b?。以前交換兩個數的值,我們需要傳遞地址,還要進行解引用,相對繁瑣。
交換兩個指針變量:?
void Swap(int*& p1, int*& p2) {int* tmp = p1;p1 = p2;p2 = tmp; }int main() {int a = 5;int b = 10;int* pa = &a;int* pb = &b;Swap(pa,pb);return 0; }?如果用C語言來實現交換兩個指針變量,實參需要傳遞指針變量的地址,那形參就需要用二級指針來接收,這顯然十分容易出錯。有了引用之后,實參直接傳遞指針變量即可,形參用指針類型的引用。
- 做返回值
引用做返回值的意義:
(1)減少拷貝,提高效率。
(2)可以同時讀取和修改返回對象
int Add(int a, int b) {int c = a + b;return c; } int main() {int ret = Add(1, 2);cout << "Add(1, 2) is :"<< ret <<endl;//輸出3Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;//輸出3return 0; }?如上代碼,我們使用傳值返回,調用函數要創建棧幀,c是Add函數中的一個局部變量,存儲在當前函數的棧幀中,函數調用結束棧幀銷毀,c也會隨之銷毀,對于這種傳值返回,會生成一個臨時的中間變量,用來存儲返回值,在返回值比較小的情況下,這個臨時的中間變量一般就是寄存器。
int& Add(int a, int b) {int c = a + b;return c; } int main() {int& ret = Add(1, 2);cout << "Add(1, 2) is :"<< ret <<endl;//輸出3Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;//輸出7return 0; }如上代碼,傳引用就是給
c起了一個別名,返回的值就是c的別名,ret就是c別名的別名,函數調用結束棧幀銷毀,棧幀空間銷毀,但是vs不清理空間內容,訪問ret就是訪問c,為3,由于空間重復利用,Add(3,4)占用該空間,修改空間內容,所以第二次訪問ret為7.
5.5 傳值和引用性能比較
以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直 接返回,而是傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效 率是非常低下的,尤其是當參數或者返回值類型非常大時,效率就更低。
- 以值作和引用為函數參數的性能比較?
#include<iostream>
#include <time.h>
using namespace std;
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{A a;// 以值作為函數參數size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作為函數參數size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分別計算兩個函數運行結束后的時間cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{TestRefAndValue();return 0;
}?
- ?值和引用的作為返回值類型的性能比較?
#include<iostream>
using namespace std;
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{// 以值作為函數的返回值類型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作為函數的返回值類型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestReturnByRefOrValue();return 0;
}
5.6 引用和指針區別
語法概念:
引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。
int main()
{
int a = 10;
int& ra = a;
cout<<"&a = "<<&a<<endl;
cout<<"&ra = "<<&ra<<endl;
return 0;
}
底層實現:
實際是有空間的,因為引用是按照指針方式來實現的。
int main()
{
int a = 10;
int& ra = a;//語法不開空間
ra = 20;int* pa = &a;//語法開空間
*pa = 20;
return 0;
} ?
?
從上面可以看出:
1、引用底層是用指針實現的;
2、語法含義和底層實現是背離的
引用和指針的不同點:
注意??
引用不可以替代指針
1. 引用概念上定義一個變量的別名,指針存儲一個變量地址。
2. 引用在定義時必須初始化,指針沒有要求
3. 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體
4. 沒有NULL引用,但有NULL指針
5. 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4個字節)
6. 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
7. 有多級指針,但是沒有多級引用
8. 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理
9. 引用比指針使用起來相對更安全
? ? ?
六、內聯函數
6.1 概念
以 inline 修飾的函數叫做內聯函數 , 編譯時C++ 編譯器會在調用內聯函數的地方展開 ,沒有函數調用建立棧幀的開銷,內聯函數提升程序運行的效率。
在函數前增加 inline 關鍵字將其改成內聯函數,在編譯期間編譯器會用函數體替換函數的調用。
inline存在的意義:
- 解決宏函數晦澀難懂、容易寫錯
- 宏不支持調試
優點:
- debug支持調試
- 不易寫錯,就是普通函數的寫法
- 提升程序的效率
6.2 特性
- inline是一種以空間換時間的做法,如果編譯器將函數當成內聯函數處理,在編譯階段,會用函數體替換函數調用,缺陷:可能會使目標文件(可執行程序)變大,優勢:少了調用開銷,提高程序運行效率。
- inline 對于編譯器而言 只是一個建議 ,編譯器會自動優化,如果定義為 inline 的函數體內有循環 / 遞歸等等,編譯器優化時會忽略掉內聯。
- inline 不建議聲明和定義分離 (頭文件中,兩個都寫),分離會導致鏈接錯誤。因為 inline 被展開,就沒有函數地址了,鏈接就會找不到。
注:C++ 有哪些技術替代宏 ?1. 常量定義 換用 const enum2. 短小函數定義 換用內聯函數
七、auto關鍵字(C++11)
7.1 類型別名思考
隨著程序越來越復雜,程序中用到的類型也越來越復雜,經常體現在:
-
類型難于拼寫
-
含義不明確導致容易出錯
#include<iostream>
using namespace std;
int TestAuto()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;//查看類型cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;return 0;
}
auto可以自動定義類型,根據等號后面的變量
C++中,typeid(A).name();可以知道A的類型是什么
7.2 auto簡介
在早期 C/C++ 中 auto 的含義是:使用 auto 修飾的變量,是具有自動存儲器的局部變量
C++11 中,標準委員會賦予了 auto 全新的含義即: auto 不再是一個存儲類型指示符,而是作為一個新的類型 指示符來指示編譯器, auto 聲明的變量必須由編譯器在編譯時期推導而得 。
使用 auto 定義變量時必須對其進行初始化 ,在編譯階段編譯器需要根據初始化表達式來推導 auto 的實際類 型 。因此 auto 并非是一種 “ 類型 ” 的聲明,而是一個類型聲明時的 “占位符” ,編譯器在編譯期會將 auto 替換為 變量實際的類型 。
7.3? auto的使用細則
- ???auto與指針和引用結合起來使用
用 auto 聲明指針類型?時,用 auto 和 auto* 沒有任何區別,但用 auto 聲明引用類型時則必須加 &(auto*定義的必須是指針類型)
#include<iostream>
using namespace std;
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;return 0;
}
- ?在同一行定義多個變量
當在同一行聲明多個變量時,這些變量必須是?相同的類型?,否則編譯器將會報錯,因為編譯器實際只對 第一個類型進行推導,然后用推導出來的類型定義其他變量 。?
void TestAuto()
{auto a = 1, b = 2; auto c = 3, d = 4.0; ?// 該行代碼會編譯失敗,因為c和d的初始化表達式類型不同
}7.4 auto不能推導的場景
- ?auto?不能作為函數的參數以及函數的返回
// 此處代碼編譯失敗,auto不能作為形參類型,因為編譯器無法對a的實際類型進行推導
void TestAuto(auto a)
{}- auto?不能直接用來聲明數組
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}八、?基于范圍的for循環(C++11)
for循環后的括號由冒號“?:”分為兩部分:第一部分是范圍內用于迭代的變量,第二部分則表示被迭代的范圍。
int main()
{int array[] = { 1, 2, 3, 4, 5 };for (auto e : array)cout << e << " ";cout << endl;for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";return 0;
}?![]()
九、指針空值---nullptr(C++11)
void f(int)
{cout<<"f(int)"<<endl;
}
void f(int*)
{cout<<"f(int*)"<<endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
程序本意是想通過f(NULL)調用指針版本的f(int*)函數,但是由于NULL被定義成0,因此與程序的
初衷相悖。
在 C++98 中,字面常量 0 既可以是一個整形數字,也可以是無類型的指針 (void*) 常量,但是編譯器默認情況下將其看成是一個整形常量,如果要將其按照指針方式來使用,必須對其進行強轉(void *)0 。
注意:
- 在使用 nullptr 表示指針空值時,不需要包含頭文件,因為 nullptr 是 C++11 作為新關鍵字引入的。
- 在 C++11 中, sizeof(nullptr) 與 sizeof((void)*0) 所占的字節數相同。
- 為了提高代碼的健壯性,在后續表示指針空值時建議最好使用 nullptr


)


)



)

)


)




