綱領
🔗代碼隨想錄理論部分
關于哈希表這個數據結構就不再重復講了,下面對幾個關鍵點記錄一下:
- 哈希碰撞
解決方法1:拉鏈法
解決方法2:線性探測法
下面針對做題要用到的三種結構講一下(也是重復造輪子了算是)
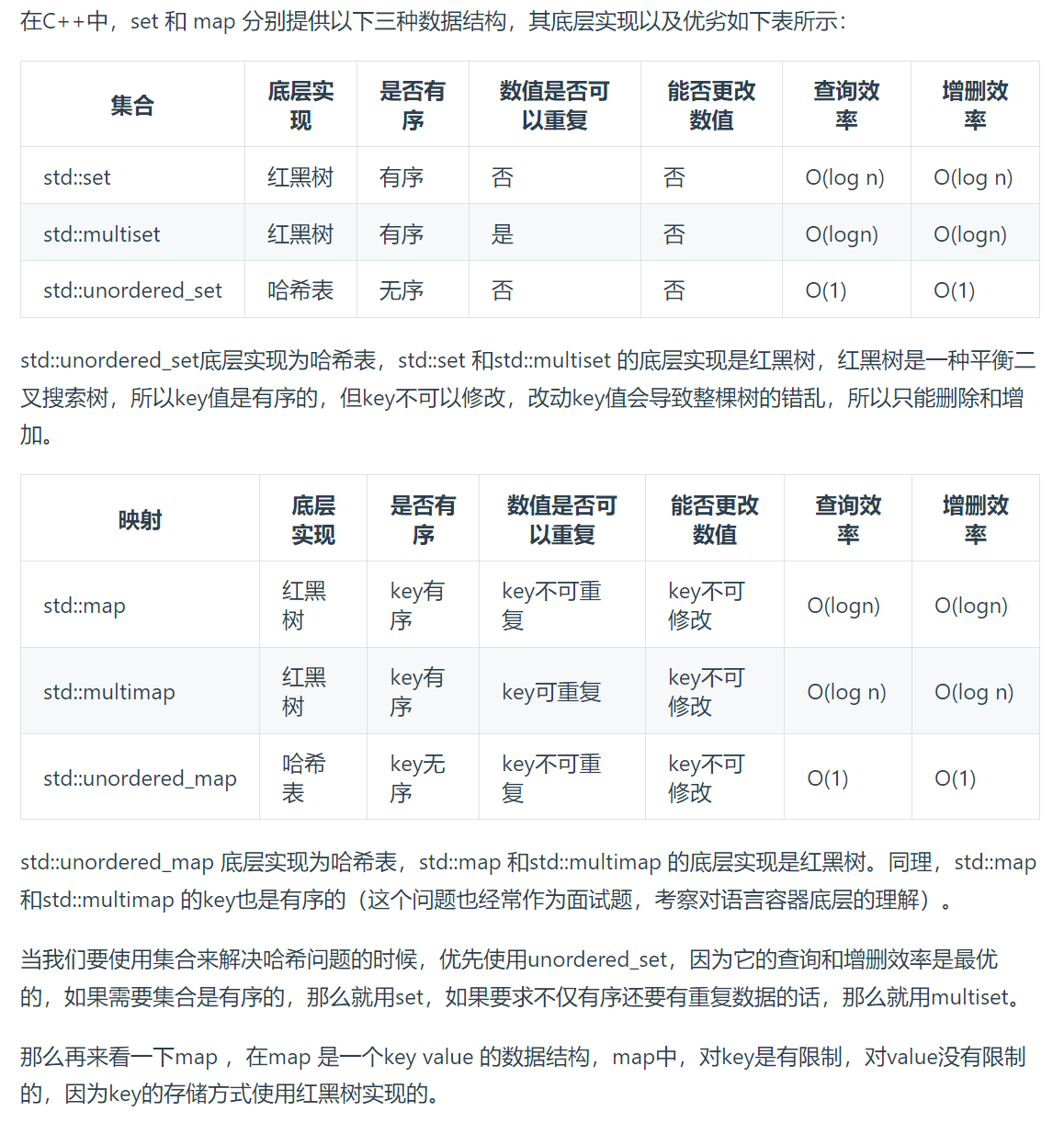
常見的三種哈希結構
當我們想使用哈希法來解決問題的時候,我們一般會選擇如下三種數據結構。
- 數組
- set (集合)(元素不能重復)
- map(映射)
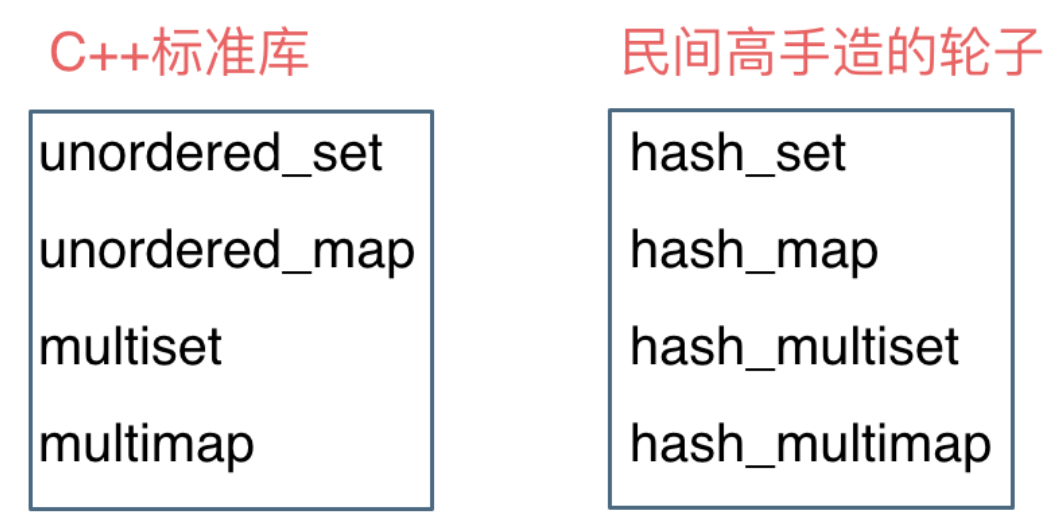
unordered_set在C++11的時候被引入標準庫了,而hash_set并沒有,所以建議還是使用unordered_set比較好,這就好比一個是官方認證的,hash_set,hash_map 是C++11標準之前民間高手自發造的輪子。
?🦄總結一下,當我們遇到了要快速判斷一個元素是否出現集合里的時候,就要考慮哈希法。
但是哈希法也是犧牲了空間換取了時間,因為我們要使用額外的數組,set或者是map來存放數據,才能實現快速的查找。
如果在做面試題目的時候遇到需要判斷一個元素是否出現過的場景也應該第一時間想到哈希法!
242.有效的字母異位詞
力扣題目鏈接

🦄解題思路:
這題很容易看出來是個哈希,把26個字母映射到26長度的數組中,數組中的值表示元素出現的個數。遍歷完兩個字符串完成哈希后,再把兩個字符串的哈希數組進行比較是否一樣即可。
?正確代碼:
class Solution {
public:bool isAnagram(string s, string t) {int a[26] = {0};int b[26] = {0};for(int i = 0; i < s.size(); i++) a[s[i] -'a'] ++ ;for(int i = 0; i < t.size(); i++) b[t[i] -'a'] ++ ;for(int i = 0; i < 26 ;i ++){if (a[i] != b[i]) return false;}return true;}
};
349. 兩個數組的交集
題目鏈接

🦄解題思路:
這題當然也是哈希,但是在數據結構上再用數組就不太合適了;因為key比較分散,稀疏,使用數組用作哈希表浪費空間。這里使用數據結構:set
此時就要使用另一種結構體了,set ,關于set,C++ 給提供了如下三種可用的數據結構:
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底層實現都是紅黑樹,std::unordered_set的底層實現是哈希表, 使用unordered_set 讀寫效率是最高的,并不需要對數據進行排序,而且還不要讓數據重復,所以選擇unordered_set

?正確代碼:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result_set; // 存放結果,之所以用set是為了給結果集去重int hash[1005] = {0}; // 默認數值為0for (int num : nums1) { // nums1中出現的字母在hash數組中做記錄hash[num] = 1;}for (int num : nums2) { // nums2中出現話,result記錄if (hash[num] == 1) {result_set.insert(num);}}return vector<int>(result_set.begin(), result_set.end());}
};
其實呢,Nums1哈布哈希無所謂,只要在nums1中發現nums2元素,則加進不可重復的set即
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result_set; // 存放結果,之所以用set是為了給結果集去重unordered_set<int> nums_set(nums1.begin(), nums1.end());for (int num : nums2) {// 發現nums2的元素 在nums_set里又出現過vector<int>::iterator it = find(nums1.begin(), nums1.end(), num);if (it != nums1.end()) {result_set.insert(num);}}return vector<int>(result_set.begin(), result_set.end());}
};
補充
那有同學可能問了,遇到哈希問題我直接都用set不就得了,用什么數組啊。
直接使用set 不僅占用空間比數組大,而且速度要比數組慢,set把數值映射到key上都要做hash計算的。
不要小瞧 這個耗時,在數據量大的情況,差距是很明顯的。







)

)

)







