目錄
前因
首先的嘗試
解決辦法
導入包
定義一個json配置文件
打開瀏覽器執行操作
注意
提取源代碼并且進行篩選鏈接
執行結果
前因
由于自己要把csdn的博客同步到hugo中,把博客轉為md格式已經搞好了,但是由于csdn的圖片具有防盜鏈,所以打算把所有的圖片爬取下來,然后保存在本地
剛好本人略懂一些python,所以自己先寫了一個腳本用來爬取各個博客的鏈接,如果不想聽我多bb的直接去我的github看源碼
GitHub - mumuhaha487/Get_csdnContribute to mumuhaha487/Get_csdn development by creating an account on GitHub.![]() https://github.com/mumuhaha487/Get_csdn
https://github.com/mumuhaha487/Get_csdn
首先的嘗試
首先的嘗試就是利用簡單好用的request包進行爬取。
但是由于csdn的博客是不顯示全部,滑動底部時更新一部分
request包可能做不了這么復雜的工作QAQ
好像https://blog.csdn.net/你的名字/article/list/鏈接可以用request包進行爬取
解決辦法
那么恰好我有學過一點點的selenium包,所以搞了一個自動化的形式通過模擬鼠標滑動到文章的底部來獲取到所有的文章鏈接
導入包
各個包都有解釋用途
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #用于自動化框架執行動作
import time #延時操作,方便網站加載完全
import json #用于讀取配置信息
import re #從源代碼中提取文章的鏈接定義一個json配置文件
定義一個json配置文件方便管理
現在文件只有用戶名稱,后續可加配置
{"blog_id": "mumuemhaha"
}讀取用戶名稱,并且將其拼接成csdn個人博客鏈接
with open("./config.json",'r') as file_1:data_1=json.load(file_1)blog_id=data_1["blog_id"]
url_1=f"https://blog.csdn.net/{blog_id}?type=blog"打開瀏覽器執行操作
注意
這里由于不知道要下滑多少次,所以可以設定一個很大的數字然后每滑動十次判斷源代碼是否更新,然后源代碼沒有變化則跳出循環即可(
driver = webdriver.Chrome()
driver.get(url_1)
for i in range(10000):time.sleep(0.5)actions = ActionChains(driver)actions.send_keys(Keys.PAGE_DOWN) # 可以多次發送 PAGE_DOWN 來實現滾動的距離actions.perform()if i % 10 == 0: # 每滑動 10 次進行判斷prev_page_source = driver.page_source # 獲取前一次滑動后的頁面源碼time.sleep(2) # 等待頁面加載current_page_source = driver.page_source # 獲取當前頁面源碼if prev_page_source == current_page_source:print("網站滑倒底了,跳出循環...")break提取源代碼并且進行篩選鏈接
req_1=driver.page_source
re_1='<a data-v-6fe2b6a7="" href="(.*?)"'
blog_urls=re.findall(re_1,req_1)執行結果
我加了一個打印鏈接個數的代碼來判斷是否全部爬取下來了
print(f"文章個數為{len(blog_urls)}(看看是不是全爬下來了)")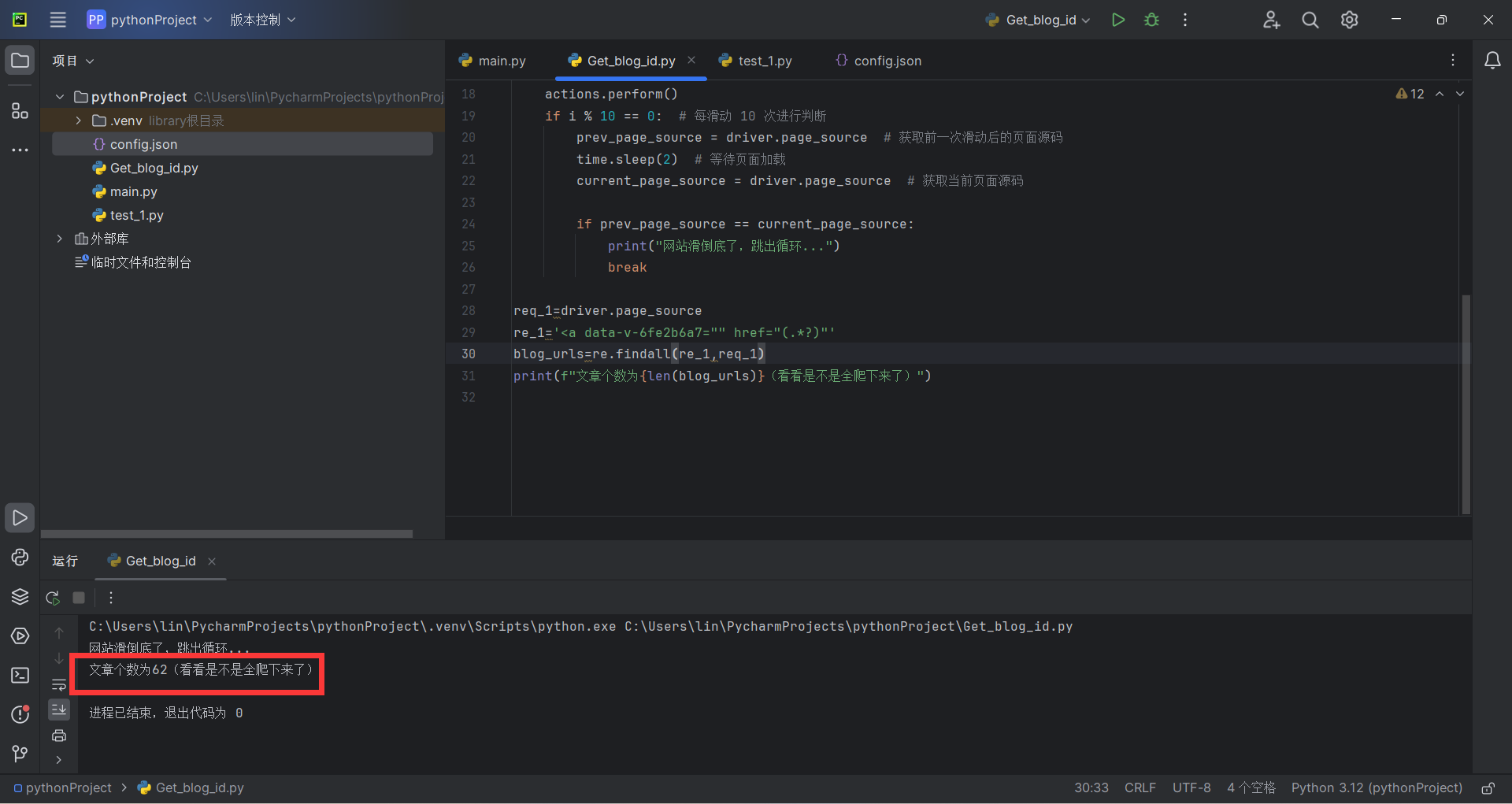
?全部代碼為
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #用于自動化框架執行動作
import time #延時操作,方便網站加載完全
import json #用于讀取配置信息
import re #從源代碼中提取文章的鏈接
with open("./config.json",'r') as file_1:data_1=json.load(file_1)blog_id=data_1["blog_id"]
url_1=f"https://blog.csdn.net/{blog_id}?type=blog"
driver = webdriver.Chrome()
driver.get(url_1)
for i in range(10000):time.sleep(0.5)actions = ActionChains(driver)actions.send_keys(Keys.PAGE_DOWN) # 可以多次發送 PAGE_DOWN 來實現滾動的距離actions.perform()if i % 10 == 0: # 每滑動 10 次進行判斷prev_page_source = driver.page_source # 獲取前一次滑動后的頁面源碼time.sleep(2) # 等待頁面加載current_page_source = driver.page_source # 獲取當前頁面源碼if prev_page_source == current_page_source:print("網站滑倒底了,跳出循環...")breakreq_1=driver.page_source
re_1='<a data-v-6fe2b6a7="" href="(.*?)"'
blog_urls=re.findall(re_1,req_1)
print(f"文章個數為{len(blog_urls)}(看看是不是全爬下來了)")
)

)
















