?
論文題目: ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
論文鏈接:?https://arxiv.org/abs/2310.04564
參數規模超過十億(1B)的大型語言模型(LLM)已經徹底改變了現階段人工智能領域的研究風向。越來越多的工業和學術研究者開始研究LLM領域中的難題,例如如何降低LLM在推理過程中的計算需求。
本文介紹一篇蘋果發表在人工智能頂會ICLR 2024上的文章,本文針對LLM中激活函數對LLM推理效率的影響展開了研究,目前LLM社區中通常使用GELU和SiLU來作為替代激活函數,它們在某些情況下可以提高LLM的預測準確率。但從節省模型計算量的角度考慮,本文作者認為,經典的ReLU函數對模型收斂和性能的影響可以忽略不計,同時可以顯著減少計算和權重IO量。因此作者主張在LLM社區重新評估ReLU的地位(盡可能多的使用ReLU)。
此外,作者還探索了一種基于ReLU的LLM稀疏模式,該模式可以對已激活的神經元進行重新利用來生成出新的高效token。綜合這些發現和設計,本文實現了基于ReLU的高效LLM計算方案,相比其他激活函數,將LLM的推理計算量大幅減少三倍。
01. 引言
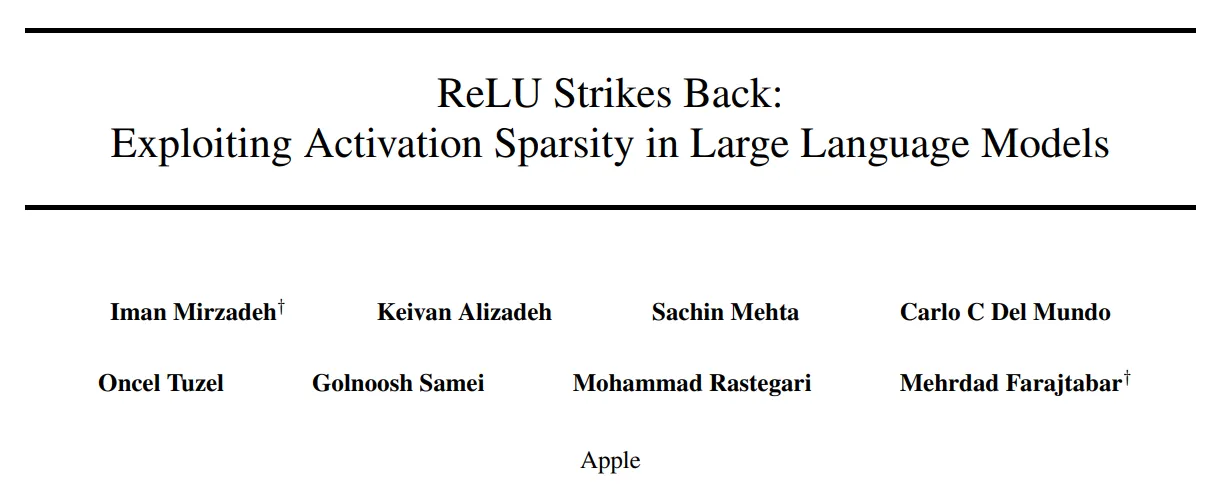
為了提高LLM的推理效率,研究者們提出了包括量化、推測解碼、剪枝和權重稀疏化等多種加速手段。通過引入激活函數的稀疏性可以在LLM的精度和計算量之間實現非常可觀的效率平衡,尤其是在GPU等現代硬件上。在傳統神經網絡中經常使用的ReLU激活函數被認為可以有效誘導模型進行稀疏激活,來提高網絡的推理效率。本文作者對OPT模型(激活函數使用ReLU)中每層神經元的激活稀疏度進行了測量,如下圖(a)所示,所有層的稀疏度均超過90%,這種稀疏度可以在模型訓練時GPU 和 CPU 之間的權重IO節省大量時間。對于 OPT 模型,這種稀疏性將推理所需的計算量從每個token的 6.6G FLOPS 減少到 4.5G FLOPS,從而節省了 32% 的計算量(如下圖c所示)。

?
02. 激活函數對模型綜合性能的影響


?
上圖第二行顯示了LLM在使用不同激活函數時的性能指標曲線。可以看出,當使用不同的激活函數時,模型的性能非常相似。這一現象與LLM縮放定律[2]給出的結論一致,即LLM的性能很大程度上取決于計算和數據,而不是架構細節。但是不同激活函數帶來的激活稀疏性水平明顯不同。上圖c反映了模型中所有層的平均稀疏度級別,當激活函數從SiLU過渡到ReLU(增加了門控權重??)時,模型的稀疏性也在增加。
03. ReLU充當預訓練LLM的潤滑劑
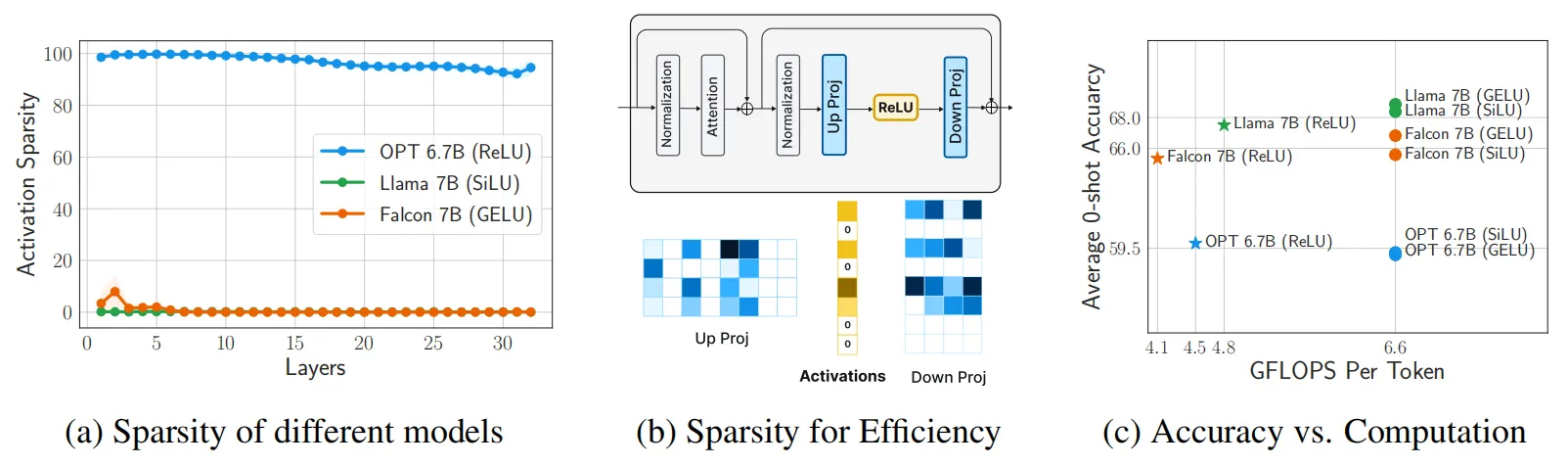
通過上一節的實驗作者已經發現,LLM的預測準確率并不依賴于激活函數的類型。但是現有大多數LLM均是使用ReLU之外的激活函數進行訓練,因此為了在推理階段使這些LLM結合ReLU激活的計算優勢,作者進行了各種架構改進實驗。例如將ReLU合并到預訓練LLM中,作者將這一過程稱為對LLM的“再潤滑”(ReLUfication)。將ReLU插入到預訓練LLM中,模型在微調過程中可能快速的恢復性能,同時提高推理時的稀疏性,可謂是一舉兩得。
3.1 一階段插入ReLU激活
ReLUfication過程的示意圖如下圖所示,這個過程可以分為多個階段完成,一階段是使用ReLU替換到LLM中的其他激活函數,例如在Falcon 和 Llama分別替換 GELU 和 SiLU。由于 OPT 模型已經使用 ReLU 激活,因此這里保持不變。
?
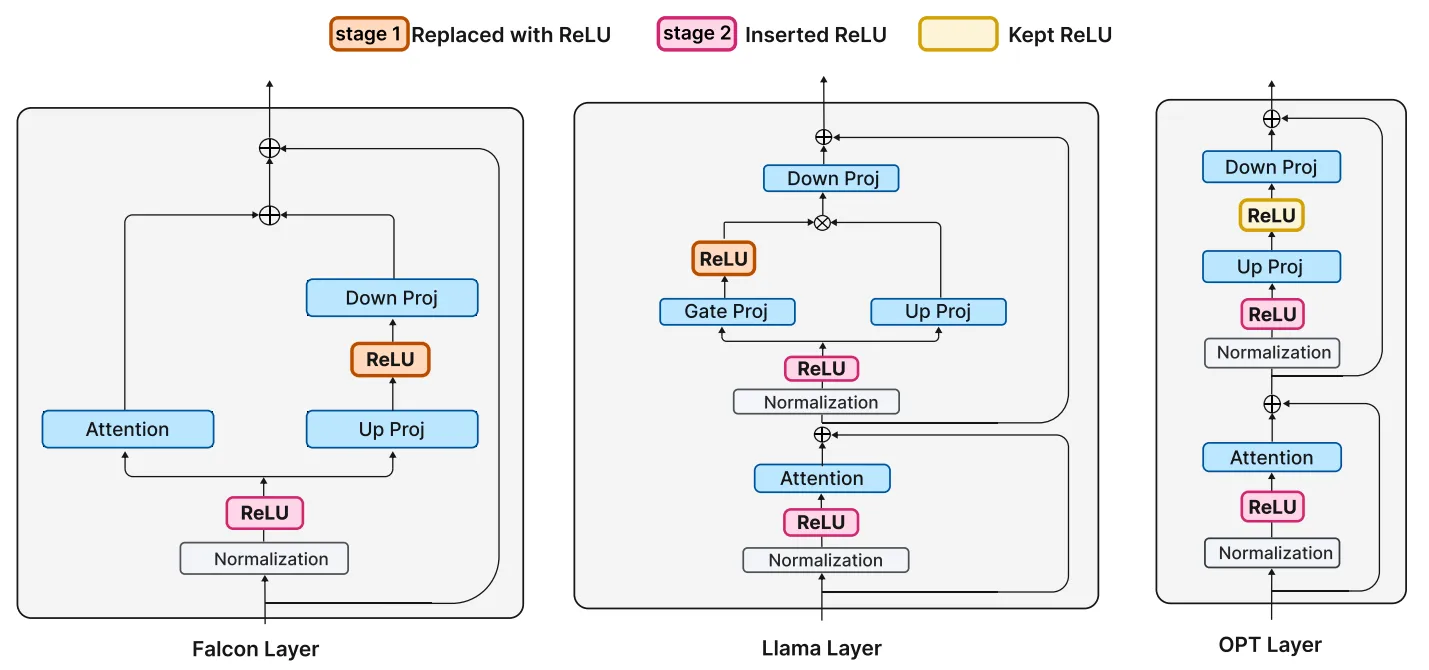
隨后作者將替換ReLU后的模型在RefinedWeb數據集上進行微調,下圖分別展示了Falcon 和 Llama在替換后模型稀疏性的對比效果。
?
除了激活稀疏性的顯著改善之外,作者還觀察到了其他有趣的現象,如下圖所示,作者測量了Falcon 和 Llama 預訓練模型的預激活分布情況,可以看出,在微調階段,這個分布本身的變化并不明顯,這可能表明網絡的預測傾向在引入稀疏性時并不會改變,具有良好的穩定性。
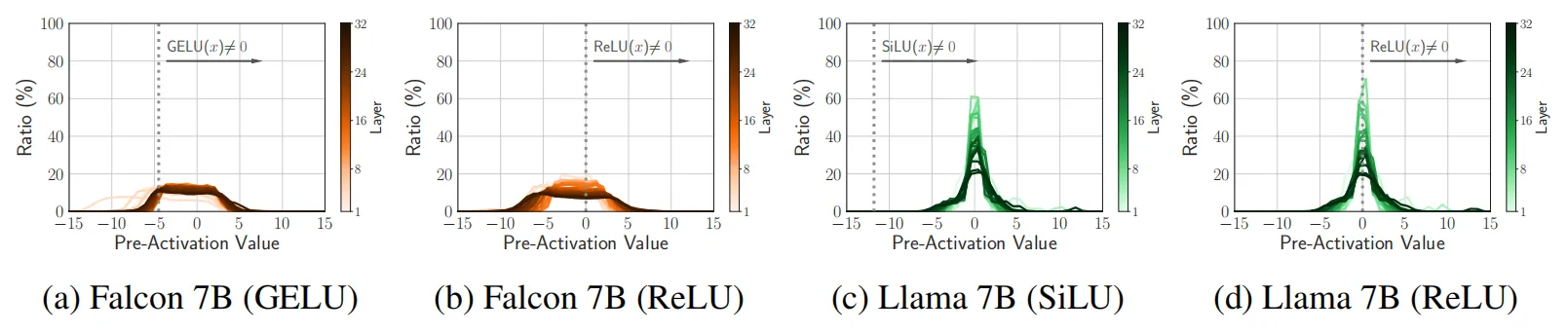
?
下圖展示了模型的預測準確率隨著ReLU的不斷微調的變化情況,模型在微調階段很快恢復了其原本的性能,其中Llama(綠色線條)完美的達到了ReLU插入之前的預測準確率。
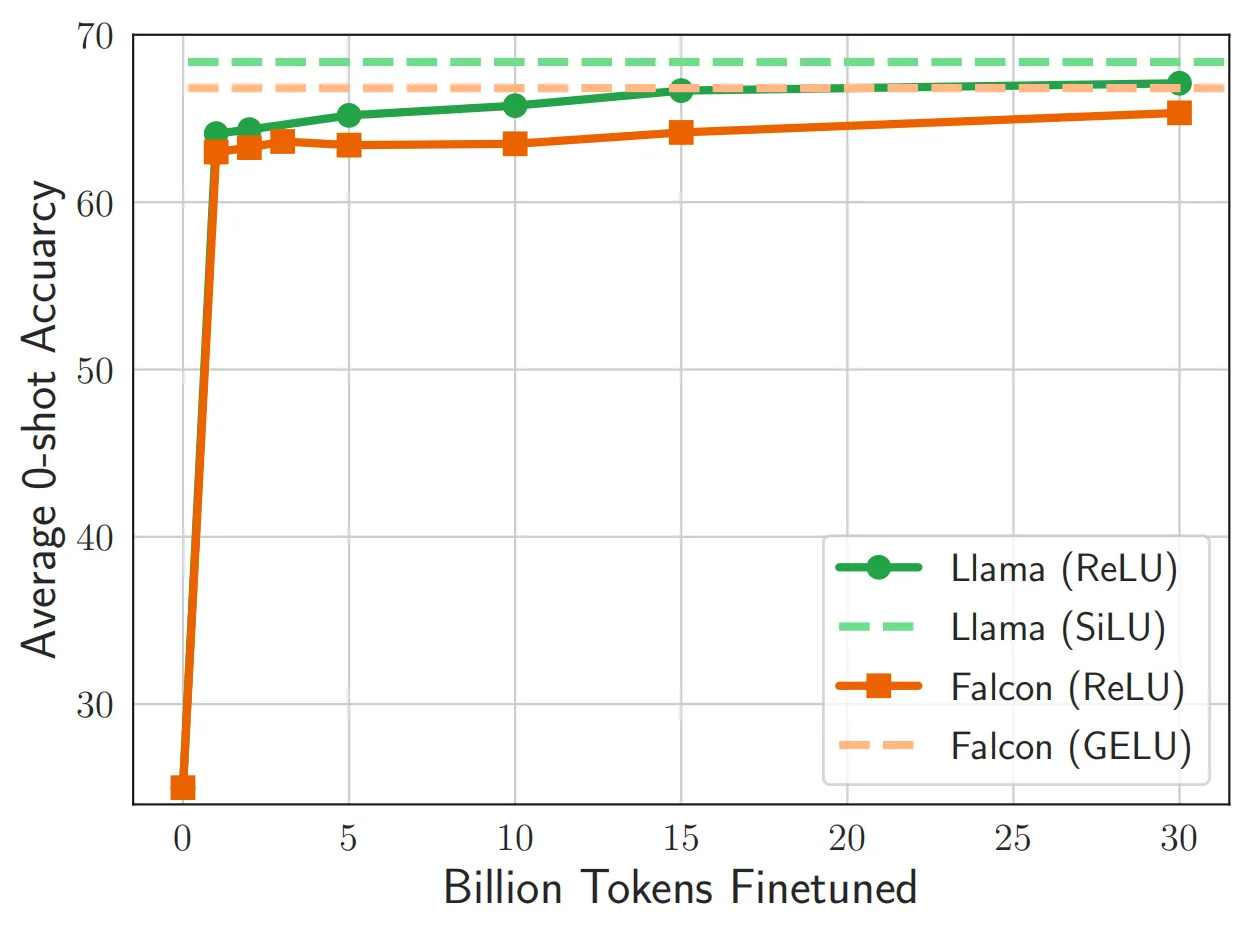
3.2 二階段的進一步稀疏化
在一階段的ReLU融化中,作者插入了ReLU來替代其他激活函數,這會導致模型down projection層的輸入變稀疏,稀疏程度大約占總計算量的30%。然而,除了down projection層之外,transformer的解碼器層中還有其他復雜的矩陣向量乘法,例如注意力層中的QKV projection,這些矩陣向量乘法大約占總計算量的約 55%,因此對這一部分進行二次稀疏也非常重要。作者發現,在現代transformer層中,注意力層和 FFN 層的輸入都來自歸一化層(LayerNorm),這些層可以被視為 MLP 的一種特定形式,因為它們并不是學習參數,而是學習如何對輸入數據進行縮放,因此作者將ReLU接在歸一化層之后來進行二階段的稀疏激活。
?
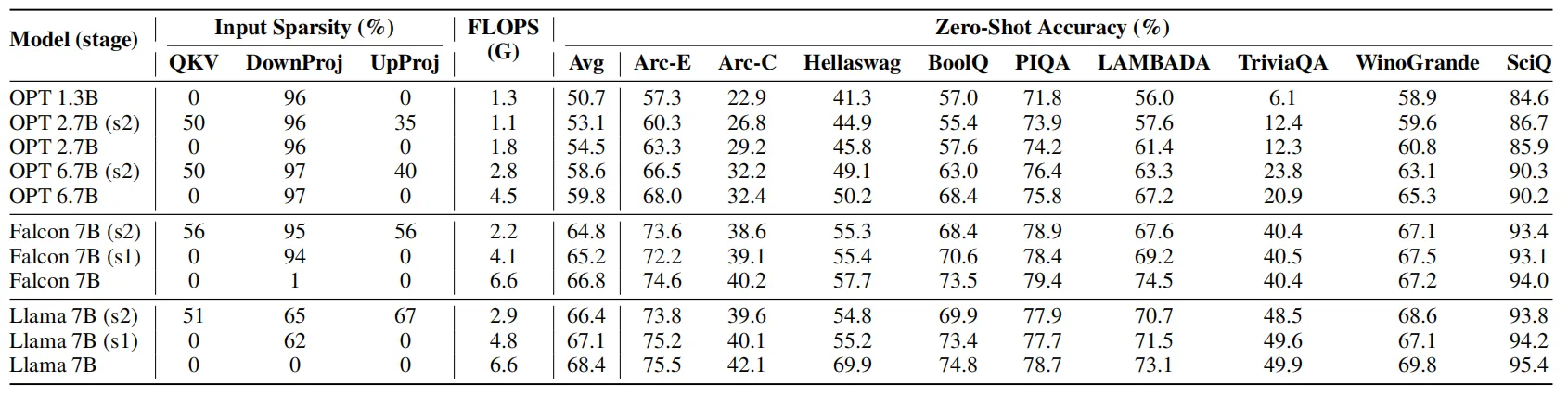
下表展示了ReLUfication調整后,模型的稀疏程度和zero-shot預測精度。其中模型的稀疏性可以分為三種類型:up projection、down projection和QKV projection。可以看到,對LLM的不同部位進行稀疏化后,模型的zero-shot精度變化并不明顯,但是計算量的差異很大。
?
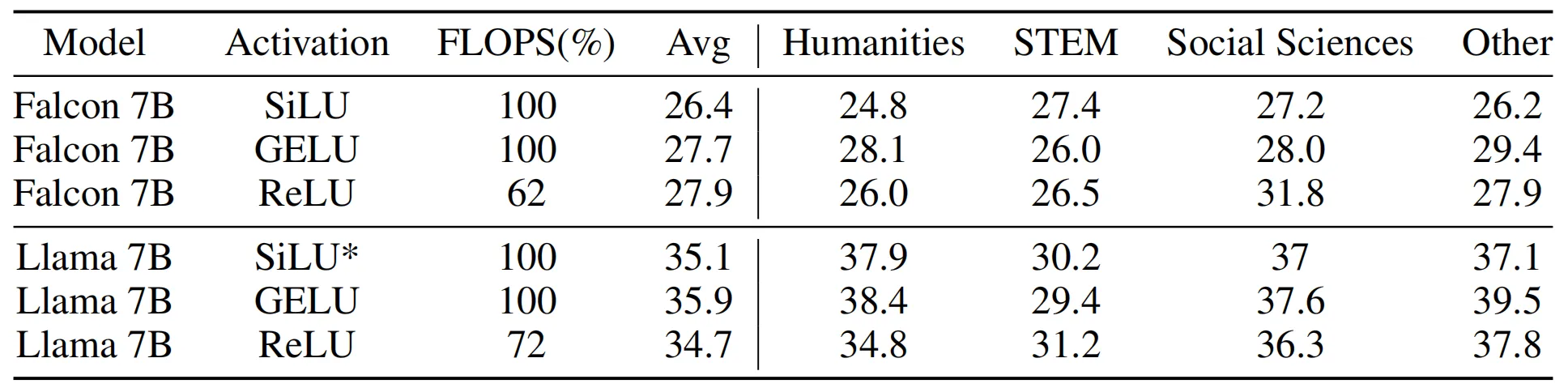
為了綜合評估激活函數對LLM上下文學習能力的影響,作者在下表展示了模型在大規模多任務語言理解(MMLU)任務中的性能,結果表明,當使用不同的激活函數和微調策略來增強原始 LLM 時,模型的zero-shot性能也不會發生顯著變化。此外,在相同的FLOPS情況下,參數規模較大但經過ReLU簡化后的模型相比原始較小模型的性能更好。總體而言,本文提出的ReLUfication可以降低LLM各個階段的推理FLOPS,同時保持各種任務的同等性能。
04. 聚合稀疏性:重用已激活的神經元

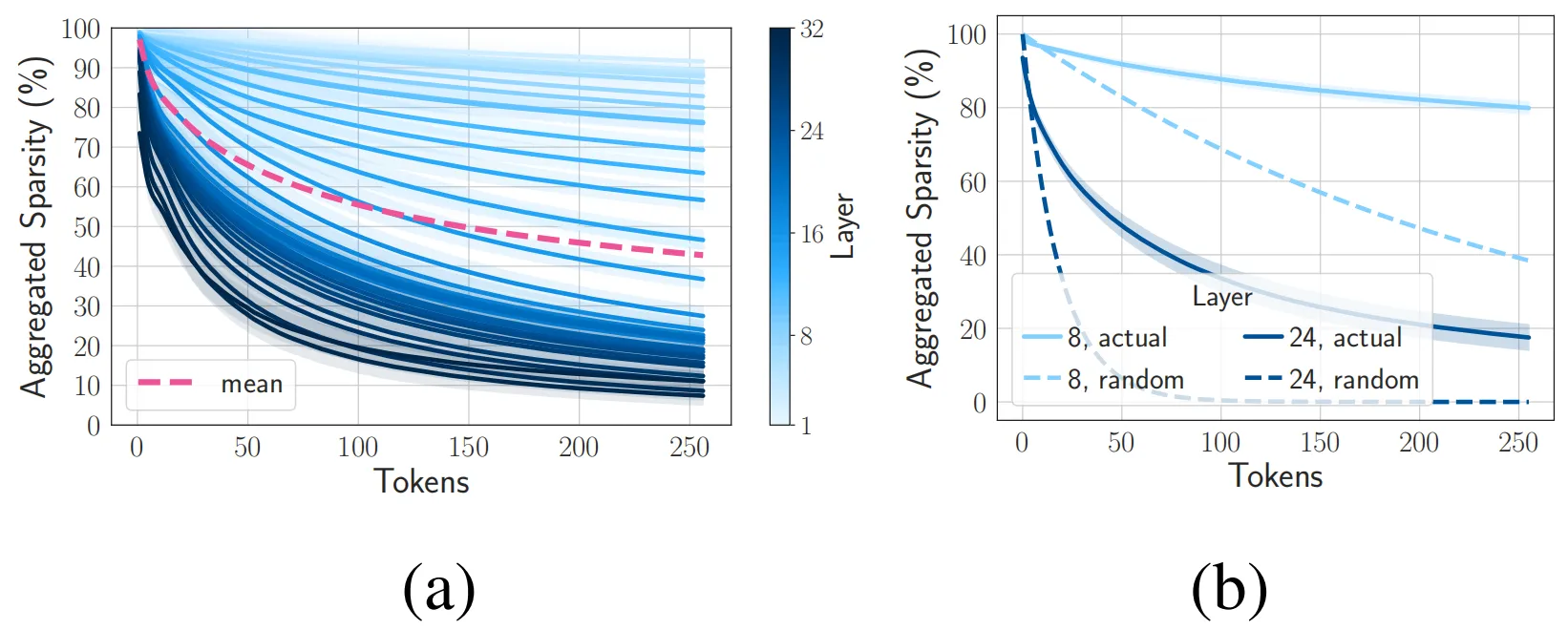

?
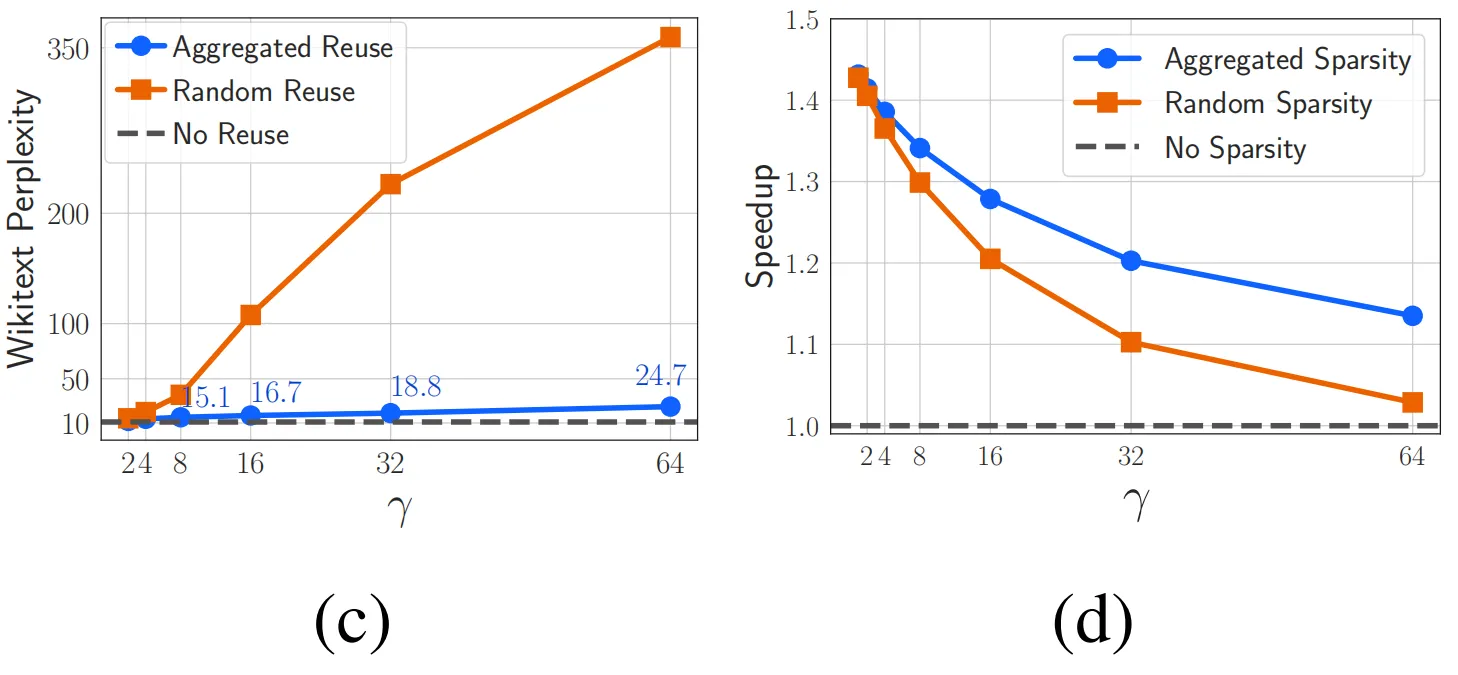
?
可以看出,重用激活方式對模型帶來的困惑負面影響幾乎可以忽略不記,其曲線與基線方法基本吻合,同時在推理加速方面也遠遠優于隨機稀疏性。
05. 總結
本文對LLM中使用的激活函數進行了大規模的研究,作者發現,在LLM預訓練和微調期間激活函數的選擇不會對性能產生顯著影響,而使用經典的 ReLU 可以為LLM提供稀疏性和更高效的推理效率。考慮到現有流行的LLM(例如Llama和Falcon)均已使用非ReLU激活函數進行預訓練,從頭對它們進行訓練耗費的代價太大,因而作者提出了一種將ReLU激活函數合并到現有預訓練LLM中的方法,被稱為ReLUfication,ReLUfication具有即插即用的特點,可以在微調階段快速將模型恢復到與原有狀態相當的性能,同時帶來顯著的推理效率增益。作者在廣泛的基準實驗(包括zero-shot預測和上下文理解)上證明,在LLM中使用稀疏性激活函數具有強大的潛力。
參考
[1] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
[2] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffre Wu, and Dario Amodei. Scaling laws for neural language models. CoRR, abs/2001.08361, 2020.
??關于TechBeat人工智能社區
▼
TechBeat(www.techbeat.net)隸屬于將門創投,是一個薈聚全球華人AI精英的成長社區。
我們希望為AI人才打造更專業的服務和體驗,加速并陪伴其學習成長。
期待這里可以成為你學習AI前沿知識的高地,分享自己最新工作的沃土,在AI進階之路上的升級打怪的根據地!
更多詳細介紹>>TechBeat,一個薈聚全球華人AI精英的學習成長社區









)


 over,dense_rank() over,row_number() over的區別)
)
:Temporal Join)

)
![[pdf]《軟件方法》2024版部分公開-共196頁](http://pic.xiahunao.cn/[pdf]《軟件方法》2024版部分公開-共196頁)

)