Hung-yi Lee 課件整理
文章目錄
- 誤解1
- 誤解2
- ChatGPT真正在做的事情-文字接龍
ChatGPT是在2022年12月7日上線的。
當時試用的感覺十分震撼。
誤解1
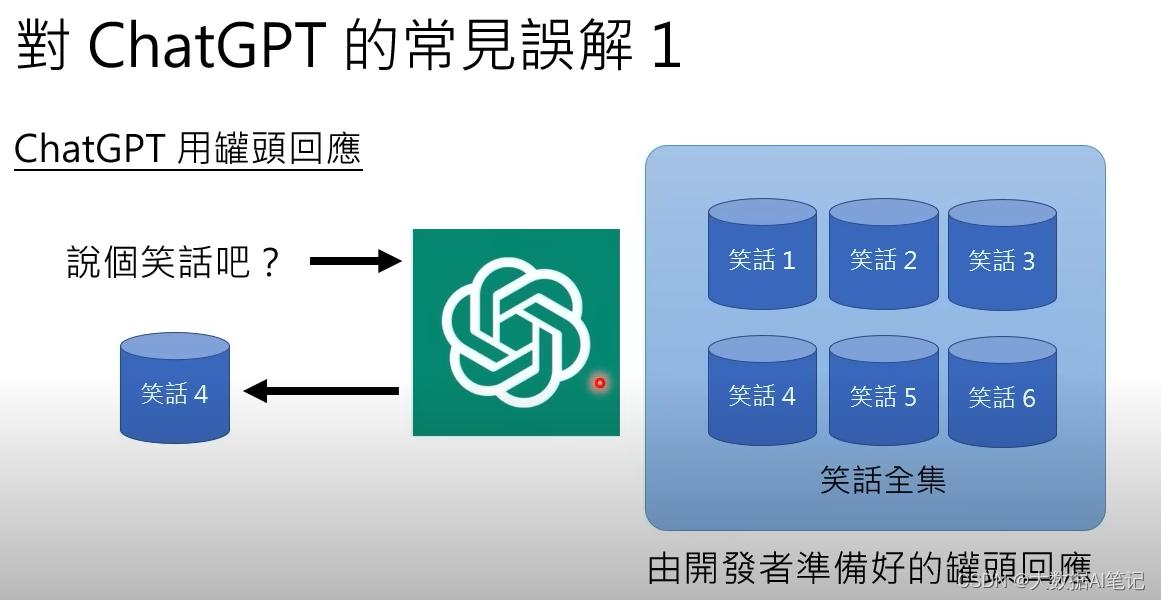
我們想讓chatGPT講個笑話,可能會以為它是在一個笑話的集合里面隨機地找一個笑話出來。
我們做一個測試就知道不是這樣的了。

讀完這個笑話,顯然不是人講出來的笑話,是機器生成的。

還有這樣的,他還要解釋一下這個笑話的笑點在哪里。

這個笑話更神奇。
這顯然不是人想出來的笑話,笑點很奇怪。
誤解2

當我們問chatGPT “什么是Diffusion Model”的時候,可能會以為它是在網絡上搜索了很多相關的文章,然后整理重組出來的。
實際上多數ChatGPT的答案在網絡上都找不到一模一樣的句子,甚至有很多感覺是幻想出來的。
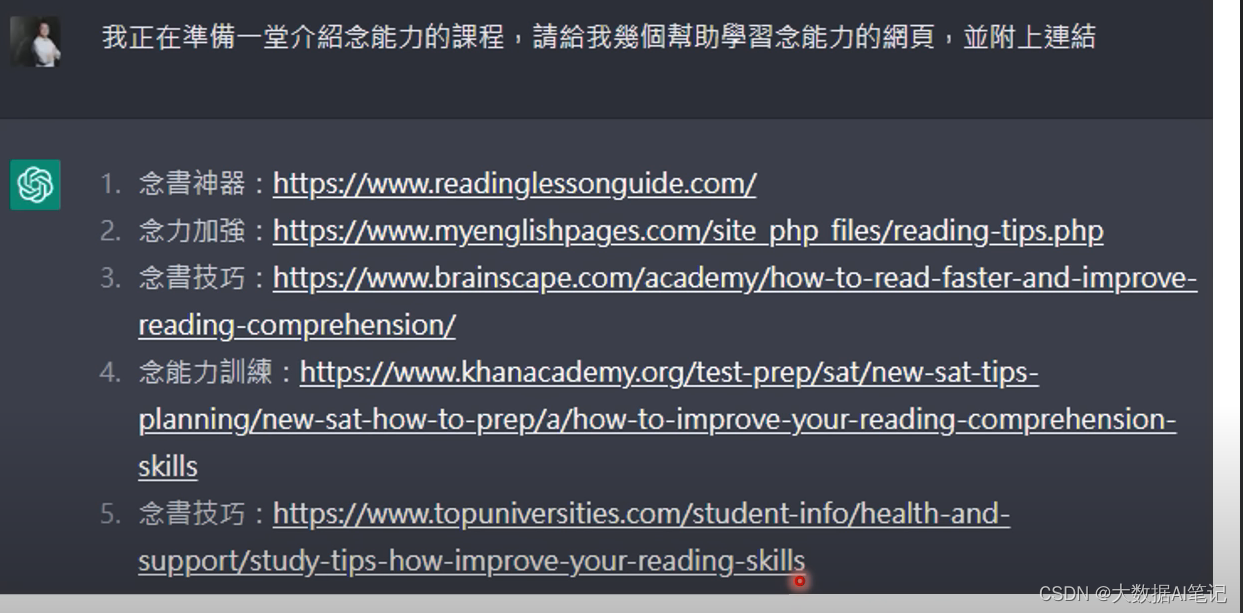
舉一個例子,讓ChatGPT展示“念能力”的網頁,它理解成了念書,而且生成的這些鏈接都是無效鏈接,看著像模像樣,結果是它幻想出來的。

這個是來自OpenAI的官方澄清,講到ChatGPT是沒有聯網的,而且信息來自2021年之前,真假需要自己判斷。
這句話的意思是它的生成內容不是來源于某一篇特定的文章,是它自己學習到的,自己生成的。
ChatGPT真正在做的事情-文字接龍
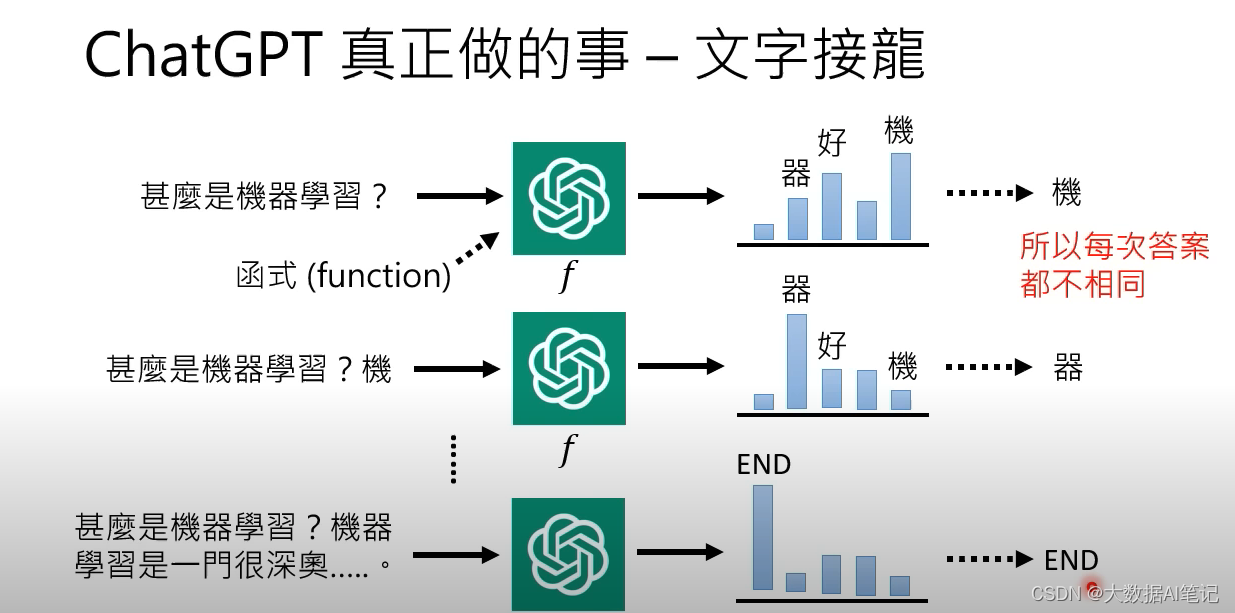
我們把ChatGPT看作一個函數,它的輸入是一個句子,輸出這個句子后面應該接的詞匯的概率。
但是這樣它也只能產生詞,而不是句子。
實際上它會把產生的第一個詞加到原來的句子后面再重新輸入給這個函數,看看這時候概率最大的詞是什么,這時候“機”的后面概率最大的可能就是“器”。
然后把“器”作為輸入丟給函數,這樣反復下去。
在它輸出的所有符號里面會有一個代表結束的符號。
當sample出的符號是結束符號,這個回答就結束了。
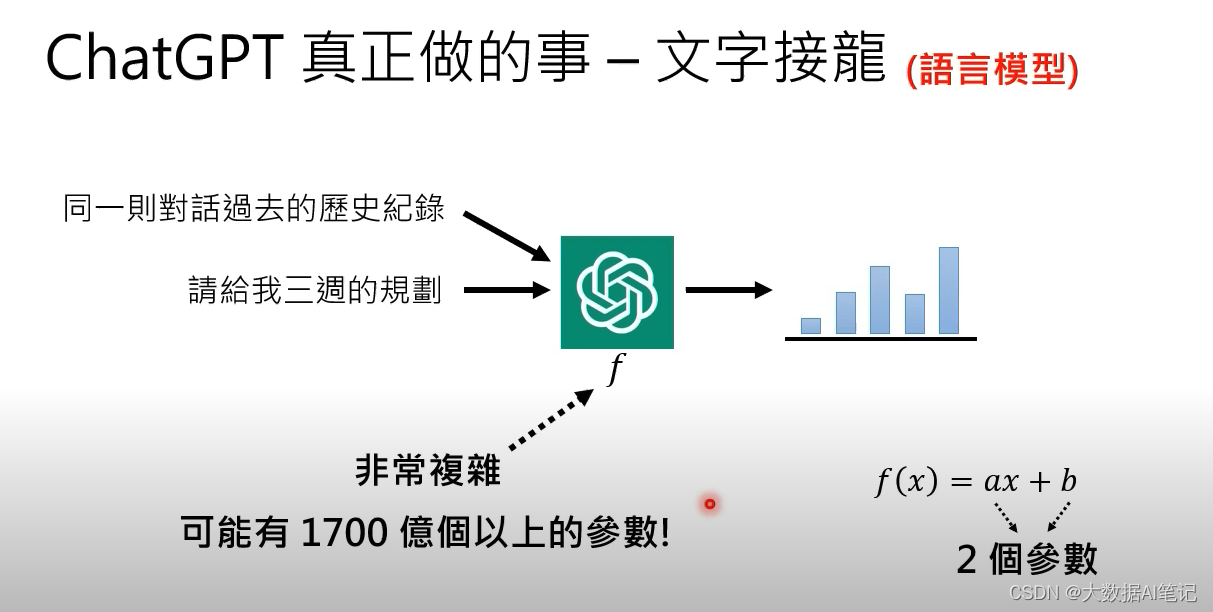
它是怎么考慮過去的歷史對話記錄呢?
原理是一樣的。
同一個對話里面的所有信息都會輸入給這個函數,讓這個函數決定下一步接哪一個詞匯。
這個函數顯然十分復雜,可能有1700億個參數,GPT-3有1700億個參數,ChatGPT的參數應該不會比它少。
當我們說ChatGPT是語言模型的時候實際上就是在說它是一個文字接龍的模型。
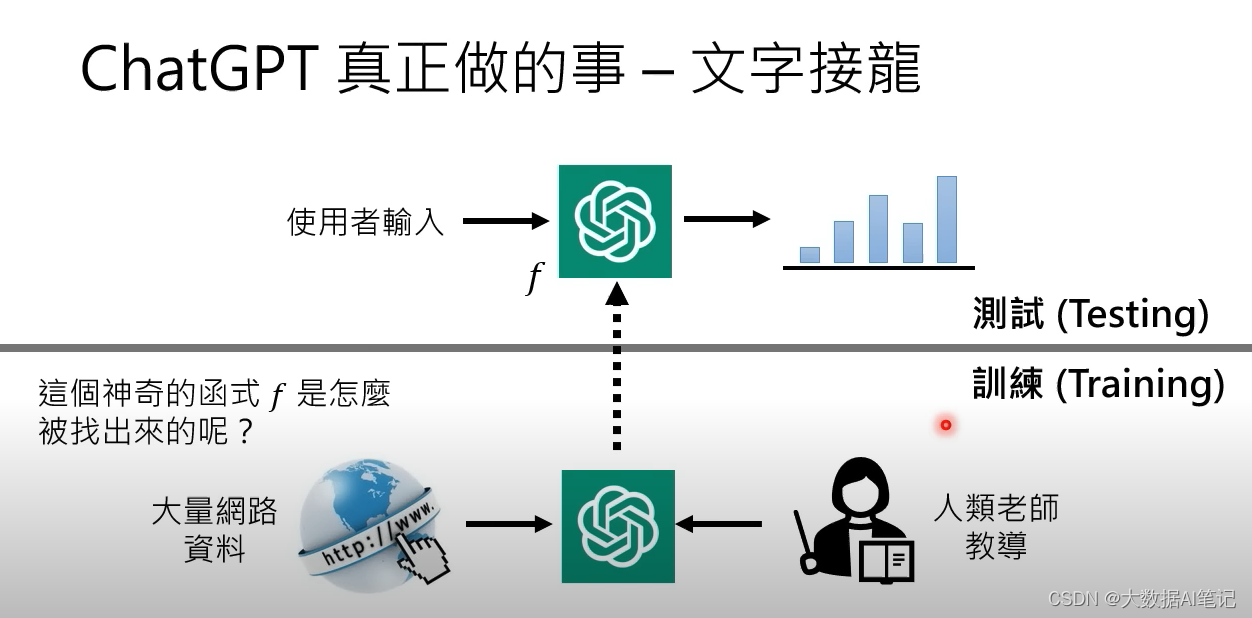
接下來要說的是這個神奇又復雜的函數是怎么被找出來的?
我們說它是通過人類老師和網上大量的資料找出來的。
當這個函數被找出來的時候就不需要網絡資料了。












)



)


