文章目錄
- 概述
- kafaka架構
- Kafka的設計時什么樣的
- Zookeeper 在 Kafka 中的作用知道
概述
Apache Kafka 是分布式發布 - 訂閱消息系統,在 kafka 官網上對 kafka 的定義:一個分布式發布 - 訂閱消息傳遞系統。
Kafka 最初由 LinkedIn 公司開發,Linkedin 于 2010 年貢獻給了 Apache 基金會并成為頂級開源項目。Kafka 的主要應用場景有:日志收集系統和消息系統。
kafaka架構
kafaka架構比較簡單,是顯式分布式架構,主要由producer(生產者),broker(kafka集群)和 er(生產者)consumer(消費者)組成。
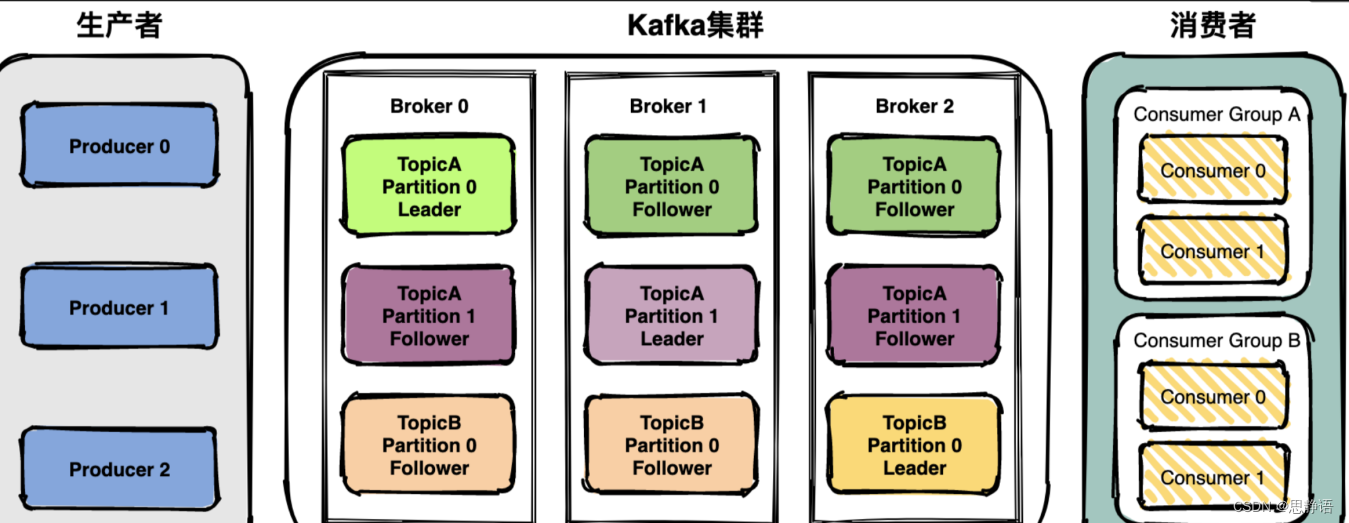
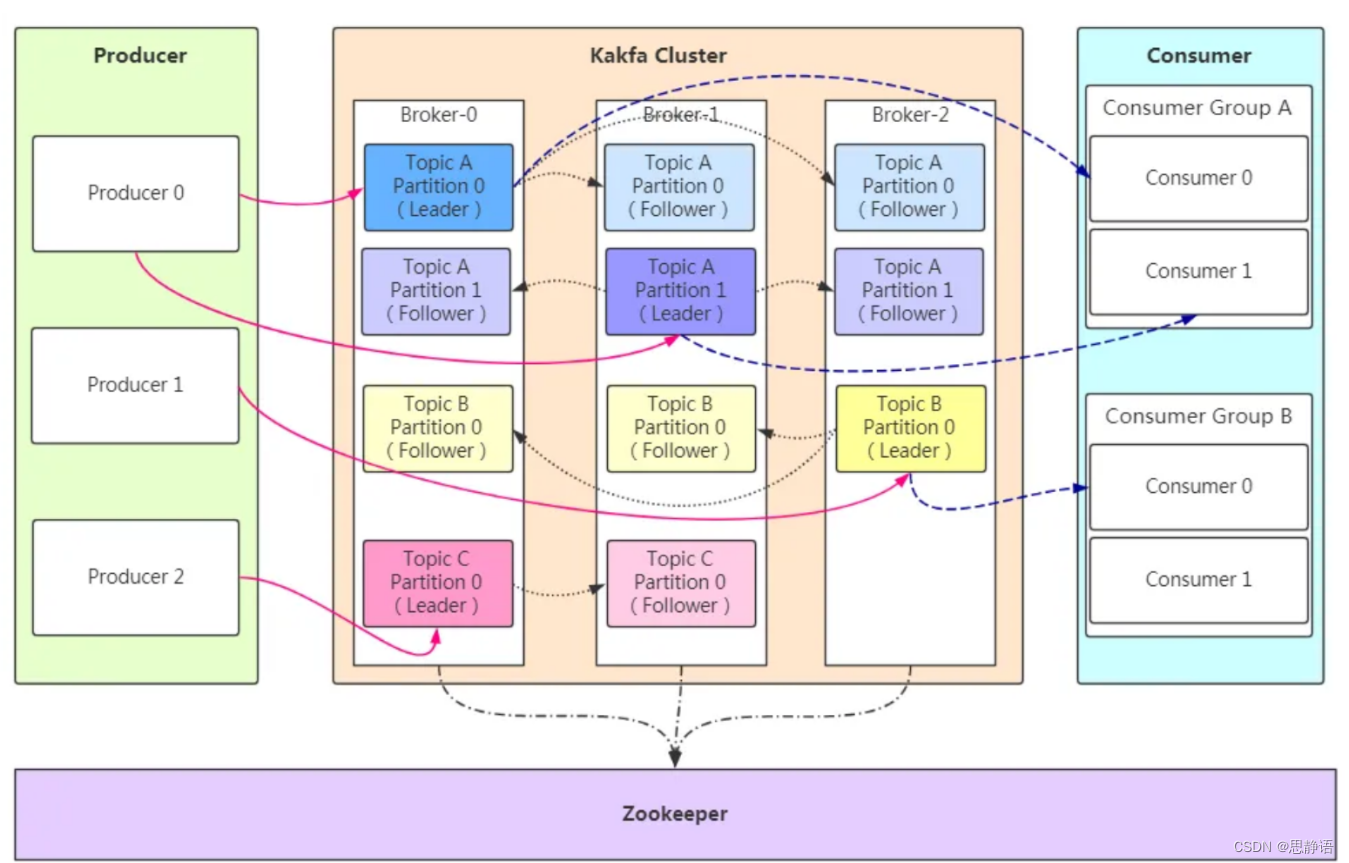
整個架構中包括三個角色。
生產者(Producer):消息和數據生產者。
代理(Broker):緩存代理,Kafka 的核心功能。
消費者(Consumer):消息和數據消費者。
Kafka 給 Producer 和 Consumer 提供注冊的接口,數據從 Producer 發送到 Broker,
Broker 承擔一個中間緩存和分發的作用,負責分發注冊到系統中的 Consumer。
Producer :消息生產者,就是向 kafka broker 發消息的客戶端。
Consumer :消息消費者,向 kafka broker 取消息的客戶端。
Topic :可以理解為一個隊列,一個 Topic 又分為一個或多個分區,
Consumer Group:這是 kafka 用來實現一個 topic 消息的廣播(發給所有的 consumer)和單播(發給任意一個 consumer)的手段。一個 topic 可以有多個 Consumer Group。
Broker :一臺 kafka 服務器就是一個 broker。一個集群由多個 broker 組成。一個broker 可以容納多個 topic。
Partition:為了實現擴展性,一個非常大的 topic 可以分布到多個 broker上,每個 partition 是一個有序的隊列。partition 中的每條消息都會被分配一個有序的id(offset)。將消息發給 consumer,kafka 只保證按一個 partition 中的消息的順序,不保證一個 topic 的整體(多個 partition 間)的順序。
Offset:kafka 的存儲文件都是按照 offset.kafka 來命名,用 offset 做名字的好處是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。當然 the first offset 就是 00000000000.kafka。
Kafka的設計時什么樣的
Kafka將消息以topic為單位進行歸納
將向Kafka topic發布消息的程序成為producers.
將預訂topics并消費消息的程序成為consumer.
Kafka以集群的方式運行,可以由一個或多個服務組成,每個服務叫做一個broker.
producers通過網絡將消息發送到Kafka集群,集群向消費者提供消息
Kafka 將消息以 topic 為單位進行歸納
將向 Kafka topic 發布消息的程序成為 producers.
將預訂 topics 并消費消息的程序成為 consumer.
Kafka 以集群的方式運行,可以由一個或多個服務組成,每個服務叫做一個 broker
producers 通過網絡將消息發送到 Kafka 集群,集群向消費者提供消息
1.消息分類按不同類別,分成不同的Topic,Topic?拆分成多個partition,每個partition均衡分散到不同的服務器(提?并發訪問的能?)
2.消費者按順序從partition中讀取,不?持隨機讀取數據,但可通過改變保存到zookeeper中的offset位置實現從任意位置開始讀取
3.服務器消息定時清除(不管有沒有消費)
4.每個partition還可以設置備份到其他服務器上的個數以保證數據的可?性。通過Leader,Follower?式
5.zookeeper保存kafka服務器和客戶端的所有狀態信息.(確保實際的客戶端和服務器輕量級)
6.在kafka中,?個partition中的消息只會被group中的?個consumer消費;每個group中consumer消息消費互相獨?;我們可以認為?個group是?個"訂閱"者,?個Topic中的每個partions,只會被?個"訂閱者"中的?個consumer消費,不過?個consumer可以消費多個partitions中的消息
7.如果所有的consumer都具有相同的group,這種情況和queue模式很像;消息將會在consumers之間負載均衡.
8.如果所有的consumer都具有不同的group,那這就是"發布-訂閱";消息將會?播給所有的消費者
9.持久性,當收到的消息時先buffer起來,等到了?定的閥值再寫?磁盤?件,減少磁盤IO.在?定程度上依賴OS的?件系統(對?件系統本身優化幾乎不可能)
10.除了磁盤IO,還應考慮?絡IO,批量對消息發送和接收,并對消息進行壓縮。
11.在JMS實現中,Topic模型基于push?式,即broker將消息推送給consumer端.不過在kafka中,采用了pull?式,即consumer在和broker建?連接之后,主動去pull(或者說fetch)消息;這種模式有些優點,?先consumer端可以根據自己的消費能力適時的去fetch消息并處理,且可以控制消息消費的進度(offset);此外,消費者可以良好的控制消息消費的數量,batch fetch.
12.kafka無需記錄消息是否接收成功,是否要重新發送等,所以kafka的producer是?常輕量級的,consumer端也只需要將fetch后的offset位置注冊到zookeeper,所以也是?常輕量級的.
Zookeeper 在 Kafka 中的作用知道
Apache Kafka 的一個關鍵依賴是 Apache Zookeeper,它是一個分布式配置和同步服務。Zookeeper 是 Kafka 代理和消費者之間的協調接口。Kafka 服務器通過 Zookeeper 集群共享信息。Kafka 在 Zookeeper 中存儲基本元數據,例如關于主題,代理,消費者偏移(隊列讀取器)等的信息。
由于所有關鍵信息存儲在 Zookeeper 中,并且它通常在其整體上復制此數據,因此Kafka代理/ Zookeeper 的故障不會影響 Kafka 集群的狀態。Kafka 將恢復狀態,一旦 Zookeeper 重新啟動。 這為Kafka帶來了零停機時間。Kafka 代理之間的領導者選舉也通過使用 Zookeeper 在領導者失敗的情況下完成。
kafka 不能脫離 zookeeper 單獨使用,因為 kafka 使用 zookeeper 管理和協調 kafka 的節點服務器。
Broker 注冊 :在 Zookeeper 上會有一個專門用來進行 Broker 服務器列表記錄的節點。
每個 Broker 在啟動時,都會到 Zookeeper 上進行注冊,即到 /brokers/ids 下創建屬于
自己的節點。每個 Broker 就會將自己的 IP 地址和端口等信息記錄到該節點中去
Topic 注冊 : 在 Kafka 中,同一個 Topic 的消息會被分成多個分區并將其分布在多個
Broker 上,這些分區信息及與 Broker 的對應關系也都是由 Zookeeper 在維護。比如我
創建了一個名字為 my-topic 的主題并且它有兩個分區,對應到 zookeeper 中會創建這
些文件夾:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my
topic/Partitions/1
負載均衡 :上面也說過了 Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition
可以分布在不同的 Broker 上, 這樣便能提供比較好的并發能力。 對于同一個 Topic 的不
同 Partition,Kafka 會盡力將這些 Partition 分布到不同的 Broker 服務器上。當生產者
產生消息后也會盡量投遞到不同 Broker 的 Partition 里面。當 Consumer 消費的時候,
Zookeeper 可以根據當前的 Partition 數量以及 Consumer 數量來實現動態負載均衡








)





:點云基礎)




