目錄
多線程
介紹一下線程的生命周期及狀態?
線程的sleep、wait、join、yield如何使用?
sleep與yield方法的區別在于,
進程調度算法
創建線程有哪些方式?
什么是守護線程?
ThreadLocal的原理是什么,使用場景有哪些?
ThreadLocal有哪些內存泄露問題,如何避免?
AQS
內置的FIFO隊列和狀態變量
AQS實現加鎖和解鎖
加鎖(acquire)過程:
解鎖(release)過程:
AQS 狀態的介紹
獨占模式(Exclusive mode):
AQS是如何實現reentrantLock、CountDownLatch、Semaphore 這三種功能的
ReentrantLock:
CountDownLatch:
Semaphore:
對線程安全的理解
如何預防死鎖?
為什么要使用線程池?
線程池種類
線程池的7大核心參數是什么?
線程池線程復用的原理是什么?
描述一下線程安全活躍態問題?
線程安全的競態條件有哪些?
程序開多少線程合適?
線程池拒絕策略
線程池的隊列滿了之后
創建多少線程呢?
線程池execute提交任務做了什么事? 線程池的狀態
Java線程池(一):運行階段可以修改參數嗎
調整核心線程數
ReentrantLock和synchronized的區別
synchronized和lock有哪些區別?
ABA問題遇到過嗎,詳細說一下?
?Synchronized原理
Synchronized修飾靜態變量和普通變量的區別
volatile和Synchronized
除了Synchronized,還能怎么保證線程安全
volatile的可見性和禁止指令重排序怎么實現的?
Happens-Before規則是什么?
分布式系統
處理分布式常用的方法
分布式id生成方案有哪些?
雪花算法生成的ID由哪些部分組成?
分布式鎖在項目中有哪些應用場景?
分布鎖有哪些解決方案?
基于 ZooKeeper 的分布式鎖實現原理是什么?
ZooKeeper和Reids做分布式鎖的區別?
zookeeper的watcher特性
MySQL如何做分布式鎖?
計數器算法是什么?
滑動時間窗口算法是什么?
漏桶限流算法是什么?
令牌桶限流算法是什么?
你設計微服務時遵循什么原則?
CAP定理是什么?
BASE理論是什么?
2PC提交協議是什么?
2PC提交協議有什么缺點?
3PC提交協議是什么?
2PC和3PC的區別是什么?
TCC解決方案是什么?
TCC空回滾是解決什么問題的?
如何解決TCC冪等問題?
如何解決TCC中懸掛問題?
可靠消息服務方案是什么?
最大努力通知方案的關鍵是什么?
什么是分布式系統中的冪等?
冪等有哪些技術解決方案?
對外提供的API如何保證冪等?
分布式系統如何設計
分布式微服務項目你是如何設計的?
認證 (Authentication) 和授權 (Authorization)的區別是什么?
Cookie 和 Session 有什么區別?如何使用Session進行身份驗證?
為什么Cookie 無法防止CSRF攻擊,而token可以?
什么是 Token?什么是 JWT?如何基于Token進行身份驗證?
單體架構的缺陷
分布式架構下,Session 共享有什么方案?
seata是什么
它如何保證分布式事務問題
多線程
介紹一下線程的生命周期及狀態?
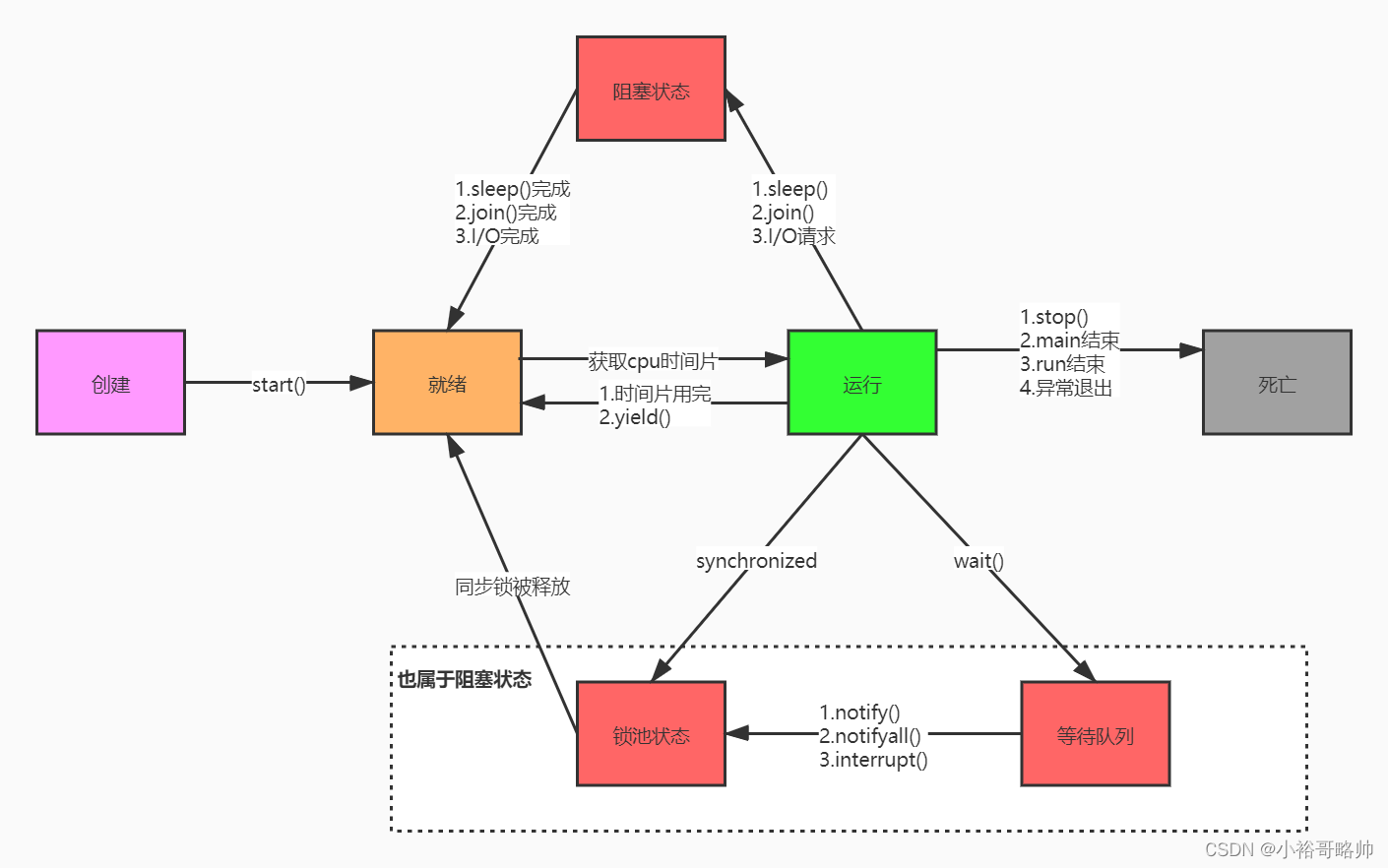
1.創建 當程序使用new關鍵字創建了一個線程之后,該線程就處于一個新建狀態(初始狀態),此時它和其他Java對象一樣,僅僅由Java虛擬機為其分配了內存,并初始化了其成員變量值。此時的線程對象沒有表現出任何線程的動態特征,程序也不會執行線程的線程執行體。 2.就緒 當線程對象調用了Thread.start()方法之后,該線程處于就緒狀態。Java虛擬機會為其創建方法調用棧和程序計數器,處于這個狀態的線程并沒有開始運行,它只是表示該線程可以運行了。從start()源碼中看出,start后添加到了線程列表中,接著在native層添加到VM中,至于該線程何時開始運行,取決于JVM里線程調度器的調度(如果OS調度選中了,就會進入到運行狀態)。 3.運行 當線程對象調用了Thread.start()方法之后,該線程處于就緒狀態。添加到了線程列表中,如果OS調度選中了,就會進入到運行狀態 4.阻塞 阻塞狀態是線程因為某種原因放棄CPU使用權,暫時停止運行。直到線程進入就緒狀態,才有機會轉到運行狀態。阻塞的情況大概三種:
-
1、等待阻塞:運行的線程執行wait()方法,JVM會把該線程放入等待池中。(wait會釋放持有的鎖)
-
2、同步阻塞:運行的線程在獲取對象的同步鎖時,若該同步鎖被別的線程占用,則JVM會把該線程放入鎖池中。
-
3、其他阻塞:運行的線程執行sleep()或join()方法,或者發出了I/O請求時,JVM會把該線程置為阻塞狀態。當sleep()狀態超時、join()等待線程終止或者超時、或者I/O處理完畢時,線程重新轉入就緒狀態。(注意,sleep是不會釋放持有的鎖)。
-
線程睡眠:Thread.sleep(long millis)方法,使線程轉到阻塞狀態。millis參數設定睡眠的時間,以毫秒為單位。當睡眠結束后,就轉為就緒(Runnable)狀態。sleep()平臺移植性好。
-
線程等待:Object類中的wait()方法,導致當前的線程等待,直到其他線程調用此對象的 notify() 方法或 notifyAll() 喚醒方法。這個兩個喚醒方法也是Object類中的方法,行為等價于調用 wait(0) 一樣。喚醒線程后,就轉為就緒(Runnable)狀態。
-
線程讓步:Thread.yield() 方法,暫停當前正在執行的線程對象,把執行機會讓給相同或者更高優先級的線程。
-
線程加入:join()方法,等待其他線程終止。在當前線程中調用另一個線程的join()方法,則當前線程轉入阻塞狀態,直到另一個進程運行結束,當前線程再由阻塞轉為就緒狀態。
-
線程I/O:線程執行某些IO操作,因為等待相關的資源而進入了阻塞狀態。比如說監聽system.in,但是尚且沒有收到鍵盤的輸入,則進入阻塞狀態。
-
線程喚醒:Object類中的notify()方法,喚醒在此對象監視器上等待的單個線程。如果所有線程都在此對象上等待,則會選擇喚醒其中一個線程,選擇是任意性的,并在對實現做出決定時發生。類似的方法還有一個notifyAll(),喚醒在此對象監視器上等待的所有線程。
5.死亡 線程會以以下三種方式之一結束,結束后就處于死亡狀態:
-
run()方法執行完成,線程正常結束。
-
線程拋出一個未捕獲的Exception或Error。
-
直接調用該線程的stop()方法來結束該線程——該方法容易導致死鎖,通常不推薦使用
線程的sleep、wait、join、yield如何使用?
sleep:讓線程睡眠,期間會出讓cpu,在同步代碼塊中,不會釋放鎖,thread類的方法,時間到后不用去爭奪鎖
wait(必須先獲得對應的鎖才能調用):讓線程進入等待狀態,釋放當前線程持有的鎖資源線程只有在notify 或者notifyAll方法調用后才會被喚醒,然后去爭奪鎖.Object類中的wait()方法,
join:線程之間協同方式,使用場景: 線程A必須等待線程B運行完畢后才可以執行,那么就可以在線程A的代碼中加入ThreadB.join();
yield:讓當前正在運行的線程回到可運行狀態(就緒狀態),以允許具有相同優先級的其他線程獲得運行的機會。因此,使用yield()的目的是讓具有相同優先級的線程之間能夠適當的輪換執行。但是,實際中無法保證yield()達到讓步的目的,因為,讓步的線程可能被線程調度程序再次選中。
sleep與yield方法的區別在于,
當線程調用sleep方法時調用線程會被阻塞掛起指定的時間,在這期間線程調度器不會去調度該線程。而調用yield方法時,線程只是讓出自己剩余的時間片,并沒有被阻塞掛起,而是處于就緒狀態,線程調度器下一次調度時就有可能調度到當前線程執行。
進程調度算法


創建線程有哪些方式?
1)繼承Thread類創建線程 2)實現Runnable接口創建線程 3)使用Callable和Future創建線程 4)使用線程池例如用Executor框架
什么是守護線程?
在Java中有兩類線程:User Thread(用戶線程)、Daemon Thread(守護線程)? 任何一個守護線程都是整個JVM中所有非守護線程的保姆: 只要當前JVM實例中尚存在任何一個非守護線程沒有結束,守護線程就全部工作;只有當最后一個非守護線程結束時,守護線程隨著JVM一同結束工作。Daemon的作用是為其他線程的運行提供便利服務,守護線程最典型的應用就是 GC (垃圾回收器),它就是一個很稱職的守護者。 User和Daemon兩者幾乎沒有區別,唯一的不同之處就在于虛擬機的離開:如果 User Thread已經全部退出運行了,只剩下Daemon Thread存在了,虛擬機也就退出了。 因為沒有了被守護者,Daemon也就沒有工作可做了,也就沒有繼續運行程序的必要了。 注意事項: (1) thread.setDaemon(true)必須在thread.start()之前設置,否則會出現一個IllegalThreadStateException異常。只能在線程未開始運行之前設置為守護線程。 (2) 在Daemon線程中產生的新線程也是Daemon的。 (3) 不要認為所有的應用都可以分配給Daemon來進行讀寫操作或者計算邏輯,因為這會可能回到數據不一致的狀態。
ThreadLocal的原理是什么,使用場景有哪些?
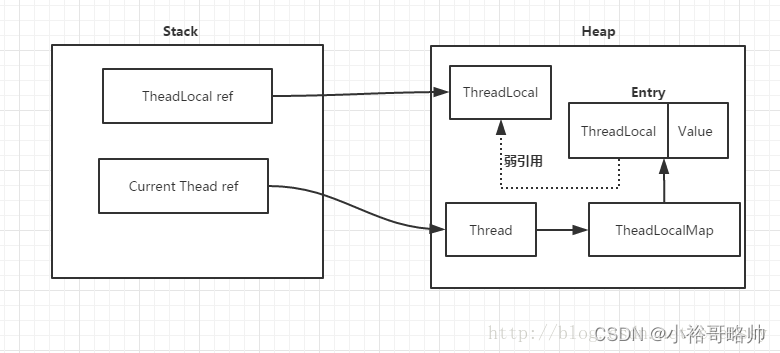
Thread類中有兩個變量threadLocals和inheritableThreadLocals,二者都是ThreadLocal內部類ThreadLocalMap類型的變量,我們通過查看內部內ThreadLocalMap可以發現實際上它類似于一個HashMap。在默認情況下,每個線程中的這兩個變量都為null:
ThreadLocal.ThreadLocalMap threadLocals = null; ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
只有當線程第一次調用ThreadLocal的set或者get方法的時候才會創建他們。
public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;return result;}}return setInitialValue();
}ThreadLocalMap getMap(Thread t) {return t.threadLocals;
}
除此之外,每個線程的本地變量不是存放在ThreadLocal實例中,而是放在調用線程的ThreadLocals變量里面。也就是說,ThreadLocal類型的本地變量是存放在具體的線程空間上,其本身相當于一個裝載本地變量的載體,通過set方法將value添加到調用線程的threadLocals中,當調用線程調用get方法時候能夠從它的threadLocals中取出變量。如果調用線程一直不終止,那么這個本地變量將會一直存放在他的threadLocals中,所以不使用本地變量的時候需要調用remove方法將threadLocals中刪除不用的本地變量,防止出現內存泄漏。
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}
public void remove() {ThreadLocalMap m = getMap(Thread.currentThread());if (m != null)m.remove(this);
}
ThreadLocal有哪些內存泄露問題,如何避免?
ThreadLocal 是 Java 中的一個線程本地變量工具類,它允許我們在每個線程中存儲和訪問特定于該線程的數據。雖然 ThreadLocal 提供了一種方便的方式來在多線程環境下共享數據,但同時也會帶來一些潛在的內存泄漏問題。
ThreadLocal 出現內存泄漏的根本原因可以歸結為以下兩點:
-
弱引用的鍵:ThreadLocal 內部使用線程對象作為鍵來存儲每個線程的值。當線程結束時,其對應的 ThreadLocal 實例仍然保留了對線程對象的引用,由于 ThreadLocal 實例是被 ThreadLocalMap(ThreadLocal 的內部數據結構)引用的,這就導致了線程對象無法被垃圾回收。如果在長時間的運行過程中,線程一直存在而沒有被正確清理,那么就會導致 ThreadLocalMap 中的鍵(即線程對象)一直存在,從而造成內存泄漏。
-
外部強引用持有:ThreadLocal 對象本身可能會被外部強引用持有,導致 ThreadLocal 對象本身無法被垃圾回收。如果在長時間的運行過程中不再需要使用 ThreadLocal 對象但仍然持有對其的強引用,那么 ThreadLocal 對象就無法被釋放,其中包含的 ThreadLocalMap 也無法被釋放,從而導致相關值無法釋放。
這兩個原因共同導致了 ThreadLocal 內存泄漏的問題。當沒有及時清理 ThreadLocal 的引用時,ThreadLocalMap 中的鍵和對應的值會一直存在,并且無法被垃圾回收,從而造成內存泄漏。
為避免 ThreadLocal 內存泄漏問題,需要手動調用 remove() 方法清理對應的值,并確保在不再需要使用 ThreadLocal 對象時解除對其的強引用。合理的管理和生命周期控制對每個 ThreadLocal 對象非常重要,以確保它們能夠被垃圾回收并釋放相關內存。
內存泄漏問題主要出現在以下情況下:
-
長時間不清理:如果一個 ThreadLocal 對象被設置了值,但在不再需要時忘記進行清理,那么該線程中存儲的對象可能會一直存在內存中,導致內存泄漏。
-
線程池使用不當:在使用線程池的情況下,如果沒有手動清理或重用 ThreadLocal 對象,在線程池中的線程結束后,ThreadLocal 對象并不會自動清理,可能導致內存泄漏。
為避免 ThreadLocal 內存泄漏問題,我們可以采取以下幾種措施:
-
及時清理:在使用完 ThreadLocal 對象后,手動調用其
remove()方法將對應的值清除。盡量在能夠確定值不再需要的時候進行清理操作。 -
使用弱引用:可以使用
java.lang.ref.WeakReference來包裝 ThreadLocal 對象,這樣在線程結束后,ThreadLocal 對象會被垃圾回收器回收。 -
手動解除引用:當線程使用完 ThreadLocal 對象后,可以通過
ThreadLocal.set(null)將 ThreadLocal 對象與值的引用解除,這樣可以提醒垃圾回收器回收 ThreadLocal 對象。 -
使用 InheritableThreadLocal:如果在使用線程池并且希望將 ThreadLocal 的值從父線程傳遞到子線程時,可以考慮使用 InheritableThreadLocal,它可以自動繼承父線程中的 ThreadLocal 值并傳遞給子線程。但要注意,InheritableThreadLocal 會帶來一定的性能開銷。
總之,在使用 ThreadLocal 時,要保證正確地清理和及時釋放資源,以避免內存泄漏問題的發生。合理使用 ThreadLocal 可以帶來很大的便利,但也需要在代碼中仔細處理,以確保資源的正常釋放。
AQS
AQS(AbstractQueuedSynchronizer)是Java并發包中的一個抽象基類,提供了一種實現同步器(synchronizer)的框架。AQS以隊列的方式管理線程,通過內置的FIFO隊列和狀態變量,提供了一種簡化、可擴展的機制,用于構建各種高性能的同步器,如ReentrantLock、CountDownLatch、Semaphore等。
AQS的核心思想是基于狀態的獲取和釋放。每個AQS子類都維護一個表示狀態的整數變量,線程在嘗試獲取資源時,首先通過檢查狀態來判斷是否可以獲取。如果狀態符合獲取條件,則線程可以獲取到資源;否則,線程會被加入等待隊列,暫時阻塞等待。當釋放資源時,狀態會被修改,并且被阻塞的線程會根據某種策略(如FIFO)被喚醒,繼續競爭資源。
AQS框架主要由以下幾個核心方法組成:
-
acquire(int arg):嘗試獲取資源,若獲取失敗則進入等待隊列,一直阻塞直到被喚醒并成功獲取資源。 -
release(int arg):釋放資源,將狀態變量修改,并喚醒等待隊列中的線程。 -
tryAcquire(int arg):嘗試獲取資源,成功返回true,失敗返回false。 -
tryRelease(int arg):嘗試釋放資源,成功返回true,失敗返回false。 -
tryAcquireShared(int arg):嘗試以共享模式獲取資源。 -
tryReleaseShared(int arg):嘗試以共享模式釋放資源。 -
isHeldExclusively():判斷當前線程是否獨占資源。
通過繼承AQS類,并實現自定義的同步器,可以靈活地構建各種并發操作。通常,自定義同步器需要重寫上述方法來實現特定的并發控制策略。AQS提供了內部隊列和狀態變量的基本操作方法,簡化了同步器的實現。
總結起來,AQS框架是Java并發包中的一個重要組件,通過提供內置的隊列和狀態變量,為構建各種高性能同步器提供了一種簡潔、可擴展的框架。通過繼承AQS類,并實現自定義的同步器,可以根據業務需求實現不同的并發控制策略。
內置的FIFO隊列和狀態變量
內置的FIFO隊列和狀態變量是 AQS(AbstractQueuedSynchronizer)中的兩個核心組件,用于管理線程的等待和喚醒。
-
FIFO隊列: AQS內部通過一個雙向鏈表來實現FIFO隊列。該隊列用于存儲等待獲取資源的線程,按照線程的等待順序進行排隊。在AQS中,隊列中的每個節點都會持有一個線程對象的引用,并通過
prev和next指針與其他節點相連。當線程嘗試獲取資源時,如果獲取失敗,線程會被封裝成一個節點并被插入到隊列的尾部。等到資源被釋放時,隊列頭部的節點會被喚醒,并嘗試重新獲取資源。FIFO隊列的設計保證了等待獲取資源時間較長的線程先被喚醒,實現了公平性。
-
狀態變量: AQS通過一個整型變量來表示同步器的狀態。狀態變量一般用于表達可獲取資源的數量或控制同步行為的狀態。
在獲取和釋放資源的過程中,線程會基于狀態變量進行判斷。例如,一個計數器型的同步器可以使用狀態變量來表示當前可用的資源數量。線程在嘗試獲取資源時,會根據狀態變量判斷是否可以獲取。當一個線程成功獲取資源時,狀態變量會相應減少;當線程釋放資源時,狀態變量會相應增加。
狀態變量的修改一般通過CAS(Compare-and-Swap)原子操作來實現,保證了并發環境下的正確性。
通過內置的FIFO隊列和狀態變量,AQS能夠實現并發控制的核心功能。FIFO隊列管理等待獲取資源的線程,保證了公平性;狀態變量用于表示同步器的狀態,并在獲取和釋放資源時進行狀態的更新和控制。這兩個組件共同協作,實現了線程的等待和喚醒機制,提供了強大的同步能力。
AQS實現加鎖和解鎖
-在 AQS(AbstractQueuedSynchronizer)中,實現加鎖和解鎖的核心方法是 acquire 和 release。這兩個方法會被子類進行重寫,以實現具體同步器的加鎖和解鎖邏輯。下面詳細介紹一下在 AQS 中加鎖和解鎖的實現方式:
加鎖(acquire)過程:
-
嘗試獲取資源(tryAcquire):在加鎖過程中,首先會調用自定義的
tryAcquire方法嘗試獲取資源。如果成功獲取資源,則直接返回,線程可以繼續執行臨界區代碼;如果獲取失敗,則進入阻塞狀態。 -
阻塞并入隊(enqueue):如果
tryAcquire失敗,當前線程會將自己加入 AQS 維護的阻塞隊列中,同時會以一種 node 節點的形式表示線程的狀態,并最終以 FIFO(先進先出)的方式將線程排隊等待獲取資源。 -
自旋與阻塞:在隊列中等待的線程可能采用自旋(spin)方式或者使用阻塞的方式來等待資源,具體的策略由具體的同步器決定。
-
狀態記錄:AQS 內部會根據線程的狀態和隊列中的順序,記錄和維護資源的狀態,以便后續恢復和協調資源的分配。
解鎖(release)過程:
-
嘗試釋放資源(tryRelease):在釋放鎖時,會調用自定義的
tryRelease方法來嘗試釋放資源。這個方法通常會更新同步器的狀態和狀態隊列,并喚醒可能正在等待資源的線程。 -
線程喚醒:如果成功釋放資源,會喚醒阻塞隊列中等待資源的線程,讓它們有機會再次嘗試獲取資源。
-
狀態更新:在加鎖和解鎖的過程中,同步器的狀態會被更新和維護,以確保線程的正確同步和競爭。狀態的更新可能包括資源的數量、線程狀態等。
通過以上加鎖和解鎖的過程,AQS 通過內部的隊列和狀態記錄,實現了多線程對資源的協調和同步控制。通過合理實現這些方法,可以定制出適應不同場景需求的高效同步器,幫助開發者實現復雜的并發控制邏輯。
AQS 狀態的介紹
在 AQS(AbstractQueuedSynchronizer)中,狀態的作用非常重要,它通常用來表示同步器所管理的資源的狀態或可用數量,以及線程的獲取和釋放狀態。具體來說,狀態的作用包括:
-
資源狀態標識:狀態可以用來標識同步器管理的資源的狀態,例如一個鎖管理的是獨占資源時,狀態可以表示被鎖住的狀態。這個狀態的具體含義可以根據具體的同步器來定義,比如 0 表示未被占用,1 表示已被占用。
-
線程等待判斷:通過狀態,可以判斷線程是否可以獲取資源。在加鎖時,線程會通過狀態的值來決定是否可以獲取資源,從而決定是繼續執行還是被阻塞。在解鎖時,更新狀態可能會喚醒正在等待的線程。
-
協調線程操作:狀態的改變會影響到同步器內部隊列的操作,進而影響到線程的等待和喚醒。狀態的變化通常會觸發隊列中線程的喚醒和重新競爭資源的過程,從而實現多線程之間的協調和競爭。
-
實現特定的同步語義:狀態的設計可以使得同步器實現特定的同步語義,比如可重入鎖的狀態表示當前鎖被重復獲取的次數,讀寫鎖的狀態可以表明讀線程和寫線程的數量等。
綜上所述,AQS 中的狀態起著非常關鍵和核心的作用,通過狀態的維護和更新,AQS 可以實現多線程間的同步協調和資源管理。開發者可以根據具體的需求和場景來合理設計和使用狀態,從而實現高效的同步控制和并發處理。
在 AQS(AbstractQueuedSynchronizer)中,一般情況下可以將狀態分為兩種:獨占模式(Exclusive mode)和共享模式(Shared mode)。這些狀態通常是通過一個整型變量來表示的,具體取值和含義可能會根據實際使用情況而定。以下是常見情況下狀態的表示和含義:
獨占模式(Exclusive mode):
-
0:表示當前資源未被任何線程占用,可以被當前線程獲取。
-
>0:表示當前資源已經被占用,值通常表示占用資源的線程個數或者深度。
-
-1:表示當前資源已經被占用,且當前線程已經獲取了資源(通常用于可重入鎖)。
共享模式(Shared mode):
-
0:表示當前沒有任何線程占用資源,可以被多個線程同時獲取。
-
>0:表示當前資源已經被占用,值通常表示占用資源的線程個數或者深度。
-
-1:表示當前資源已經被占用,并且當前線程已經獲取了資源(通常用于計數信號量)。
以上狀態僅供參考,具體同步器的實現中,這些狀態的含義和取值可能會有所差異。在使用 AQS 或者自定義同步器時,需要根據具體場景和需求來理解和使用狀態,確保狀態的變化和含義符合預期,從而實現正確的多線程同步和協調。
AQS是如何實現reentrantLock、CountDownLatch、Semaphore 這三種功能的
在 Java 中,ReentrantLock、CountDownLatch 和 Semaphore 三種功能的實現都是基于 AQS(AbstractQueuedSynchronizer)的。下面簡單介紹一下它們是如何利用 AQS 實現的:
ReentrantLock:
ReentrantLock 是一個可重入的互斥鎖,在 AQS 的基礎上實現了鎖的功能。ReentrantLock 內部通過繼承 AbstractQueuedSynchronizer 并重寫其 tryAcquire 和 tryRelease 方法來實現獨占鎖的功能。具體實現中,tryAcquire 在獲取鎖的時候會判斷鎖的重入次數,tryRelease 在釋放鎖的時候會減少重入次數,直到重入次數為 0 才會真正釋放鎖。
CountDownLatch:
CountDownLatch 是一種同步工具,等待一個或多個線程執行完畢后才能繼續執行。CountDownLatch 內部利用 AQS 的狀態實現等待線程數量的計數功能,當計數為零時釋放阻塞線程。主要是通過繼承 AbstractQueuedSynchronizer,并在其中實現 tryAcquireShared 和 tryReleaseShared 方法來實現計數和等待的邏輯。
Semaphore:
Semaphore 是一種控制同時訪問特定資源的線程數量的同步工具,它可以用來實現資源池或者限流。Semaphore 內部也是基于 AQS 進行實現的,通過狀態變量表示可用資源的數量,當獲取資源時會嘗試獲取許可,當釋放資源時會釋放許可。重點是實現 tryAcquireShared 和 tryReleaseShared 方法以實現資源數量的控制和線程等待邏輯。
總的來說,ReentrantLock、CountDownLatch 和 Semaphore 這三種功能的實現都是建立在 AQS 的基礎上,通過重寫 AQS 的相關方法,實現了不同類型的同步功能。開發者在使用這些類時,無需關注具體的實現細節,只需要了解其提供的功能及如何正確使用即可。
對線程安全的理解
不是線程安全、應該是內存安全,堆是共享內存,可以被所有線程訪問 堆是進程和線程共有的空間,分全局堆和局部堆。全局堆就是所有沒有分配的空間,局部堆就是用戶分 配的空間。堆在操作系統對進程初始化的時候分配,運行過程中也可以向系統要額外的堆,但是用完了 要還給操作系統,要不然就是內存泄漏。 在Java中,堆是Java虛擬機所管理的內存中最大的一塊,是所有線程共享的一塊內存區域,在虛 擬機啟動時創建。堆所存在的內存區域的唯一目的就是存放對象實例,幾乎所有的對象實例以及 數組都在這里分配內存。 棧是每個線程獨有的,保存其運行狀態和局部自動變量的。棧在線程開始的時候初始化,每個線程的棧 互相獨立,因此,棧是線程安全的。操作系統在切換線程的時候會自動切換棧。棧空間不需要在高級語 言里面顯式的分配和釋放。 目前主流操作系統都是多任務的,即多個進程同時運行。為了保證安全,每個進程只能訪問分配給自己 的內存空間,而不能訪問別的進程的,這是由操作系統保障的。 在每個進程的內存空間中都會有一塊特殊的公共區域,通常稱為堆(內存)。進程內的所有線程都可以 訪問到該區域,這就是造成問題的潛在原因。
如何預防死鎖?
-
首先需要將死鎖發生的是個必要條件講出來:
-
互斥條件 同一時間只能有一個線程獲取資源。
-
不可剝奪條件 一個線程已經占有的資源,在釋放之前不會被其它線程搶占
-
請求和保持條件 線程等待過程中不會釋放已占有的資源
-
循環等待條件 多個線程互相等待對方釋放資源
-
-
死鎖預防,那么就是需要破壞這四個必要條件
-
由于資源互斥是資源使用的固有特性,無法改變,我們不討論
-
破壞不可剝奪條件
-
一個進程不能獲得所需要的全部資源時便處于等待狀態,等待期間他占有的資源將被隱式的釋放重新加入到系統的資源列表中,可以被其他的進程使用,而等待的進程只有重新獲得自己原有的資源以及新申請的資源才可以重新啟動,執行
-
-
-
破壞請求與保持條件
-
第一種方法靜態分配即每個進程在開始執行時就申請他所需要的全部資源
-
第二種是動態分配即每個進程在申請所需要的資源時他本身不占用系統資源
-
-
破壞循環等待條件
-
采用資源有序分配其基本思想是將系統中的所有資源順序編號,將緊缺的,稀少的采用較大的編號,在申請資源時必須按照編號的順序進行,一個進程只有獲得較小編號的進程才能申請較大編號的進程。
-
為什么要使用線程池?
為了減少創建和銷毀線程的次數,讓每個線程可以多次使用,可根據系統情況調整執行的線程數量,防止消耗過多內存,所以我們可以使用線程池.
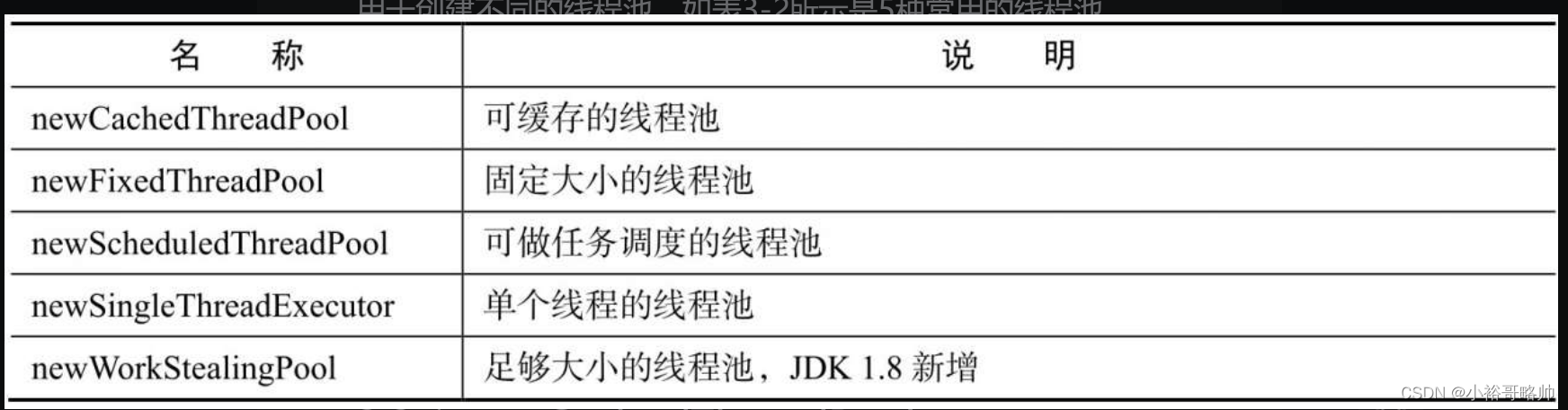
線程池種類
線程池的7大核心參數是什么?
-
corePoolSize 核心線程數目 - 池中會保留的最多線程數。
-
maximumPoolSize 最大線程數目 - 核心線程+救急線程的最大數目。
-
keepAliveTime 生存時間 - 救急線程的生存時間,生存時間內沒有新任務,此線程資源會釋放。
-
unit 時間單位 - 救急線程的生存時間單位,如秒、毫秒等。
-
workQueue - 當沒有空閑核心線程時,新來任務會加入到此隊列排隊,隊列滿會創建救急線程執行任務。
-
threadFactory 線程工廠 - 可以定制線程對象的創建,例如設置線程名字、是否是守護線程等。
-
handler 拒絕策略 - 當所有線程都在繁忙,workQueue 也放滿時,會觸發拒絕策略。
(1)拋異常 java.util.concurrent.ThreadPoolExecutor.AbortPolicy。
(2)由調用者執行任務 java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy。
(3)丟棄任務 java.util.concurrent.ThreadPoolExecutor.DiscardPolicy。
(4)丟棄最早排隊任務 java.util.concurrent.ThreadPoolExecutor.DiscardOldestPolicy。
線程池線程復用的原理是什么?
思考這么一個問題:任務結束后會不會回收線程? 答案是:allowCoreThreadTimeOut控制
/java/util/concurrent/ThreadPoolExecutor.java:1127
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {while (task != null || (task = getTask()) != null) {...執行任務...}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}}
首先線程池內的線程都被包裝成了一個個的java.util.concurrent.ThreadPoolExecutor.Worker,然后這個worker會馬不停蹄的執行任務,執行完任務之后就會在while循環中去取任務,取到任務就繼續執行,取不到任務就跳出while循環(這個時候worker就不能再執行任務了)執行 processWorkerExit方法,這個方法呢就是做清場處理,將當前woker線程從線程池中移除,并且判斷是否是異常的進入processWorkerExit方法,如果是非異常情況,就對當前線程池狀態(RUNNING,shutdown)和當前工作線程數和當前任務數做判斷,是否要加入一個新的線程去完成最后的任務(防止沒有線程去做剩下的任務).
那么什么時候會退出while循環呢?取不到任務的時候(getTask() == null).下面看一下getTask方法
?
private Runnable getTask() {boolean timedOut = false; // Did the last poll() time out?
?for (;;) {int c = ctl.get();int rs = runStateOf(c);
?//(rs == SHUTDOWN && workQueue.isEmpty()) || rs >=STOP//若線程池狀態是SHUTDOWN 并且 任務隊列為空,意味著已經不需要工作線程執行任務了,線程池即將關閉//若線程池的狀態是 STOP TIDYING TERMINATED,則意味著線程池已經停止處理任何任務了,不在需要線程if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {//把此工作線程從線程池中刪除decrementWorkerCount();return null;}
?int wc = workerCountOf(c);
?//allowCoreThreadTimeOut:當沒有任務的時候,核心線程數也會被剔除,默認參數是false,官方推薦在創建線程池并且還未使用的時候,設置此值//如果當前工作線程數 大于 核心線程數,timed為trueboolean timed = allowCoreThreadTimeOut || wc > corePoolSize;//(wc > maximumPoolSize || (timed && timedOut)):當工作線程超過最大線程數,或者 允許超時并且超時過一次了//(wc > 1 || workQueue.isEmpty()):工作線程數至少為1個 或者 沒有任務了//總的來說判斷當前工作線程還有沒有必要等著拿任務去執行//wc > maximumPoolSize && wc>1 : 就是判斷當前工作線程是否超過最大值//或者 wc > maximumPoolSize && workQueue.isEmpty():工作線程超過最大,基本上不會走到這,// 如果走到這,則意味著wc=1 ,只有1個工作線程了,如果此時任務隊列是空的,則把最后的線程刪除//或者(timed && timedOut) && wc>1:如果允許超時并且超時過一次,并且至少有1個線程,則刪除線程//或者 (timed && timedOut) && workQueue.isEmpty():如果允許超時并且超時過一次,并且此時工作 隊列為空,那么妥妥可以把最后一個線程(因為上面的wc>1不滿足,則可以得出來wc=1)刪除if ((wc > maximumPoolSize ?|| (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))//如果減去工作線程數成功,則返回null出去,也就是說 讓工作線程停止while輪訓,進行收尾return null;continue;}
?try {//判斷是否要阻塞獲取任務Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}}//綜上所述,如果allowCoreThreadTimeOut為true,并且在第1次阻塞獲取任務失敗了,那么當前getTask會返回null,不管是不是核心線程;那么runWorker中將推出while循環,也就意味著當前工作線程被銷毀
?
通過上面這個問題可以得出一個結論:當你的線程池參數配置合理的時候,執行完任務的線程是不會被銷毀的,而是會從任務隊列中取出任務繼續執行!
描述一下線程安全活躍態問題?
線程安全的活躍性問題可以分為 死鎖、活鎖、饑餓
-
活鎖 就是有時線程雖然沒有發生阻塞,但是仍然會存在執行不下去的情況,活鎖不會阻塞線程,線程會一直重復執行某個相同的操作,并且一直失敗重試
-
我們開發中使用的異步消息隊列就有可能造成活鎖的問題,在消息隊列的消費端如果沒有正確的ack消息,并且執行過程中報錯了,就會再次放回消息頭,然后再拿出來執行,一直循環往復的失敗。這個問題除了正確的ack之外,往往是通過將失敗的消息放入到延時隊列中,等到一定的延時再進行重試來解決。
-
解決活鎖的方案很簡單,嘗試等待一個隨機的時間就可以,會按時間輪去重試
-
-
饑餓 就是 線程因無法訪問所需資源而無法執行下去的情況
-
饑餓 分為兩種情況:
-
一種是其他的線程在臨界區做了無限循環或無限制等待資源的操作,讓其他的線程一直不能拿到鎖進入臨界區,對其他線程來說,就進入了饑餓狀態
-
另一種是因為線程優先級不合理的分配,導致部分線程始終無法獲取到CPU資源而一直無法執行
-
-
解決饑餓的問題有幾種方案:
-
保證資源充足,很多場景下,資源的稀缺性無法解決
-
公平分配資源,在并發編程里使用公平鎖,例如FIFO策略,線程等待是有順序的,排在等待隊列前面的線程會優先獲得資源
-
避免持有鎖的線程長時間執行,很多場景下,持有鎖的線程的執行時間也很難縮短
-
-
-
死鎖 線程在對同一把鎖進行競爭的時候,未搶占到鎖的線程會等待持有鎖的線程釋放鎖后繼續搶占,如果兩個或兩個以上的線程互相持有對方將要搶占的鎖,互相等待對方先行釋放鎖就會進入到一個循環等待的過程,這個過程就叫做死鎖
線程安全的競態條件有哪些?
-
同一個程序多線程訪問同一個資源,如果對資源的訪問順序敏感,就稱存在競態條件,代碼區成為臨界區。 大多數并發錯誤一樣,競態條件不總是會產生問題,還需要不恰當的執行時序
-
最常見的競態條件為
-
先檢測后執行執行依賴于檢測的結果,而檢測結果依賴于多個線程的執行時序,而多個線程的執行時序通常情況下是不固定不可判斷的,從而導致執行結果出現各種問題,見一種可能 的解決辦法就是:在一個線程修改訪問一個狀態時,要防止其他線程訪問修改,也就是加鎖機制,保證原子性
-
延遲初始化(典型為單例)
-
程序開多少線程合適?
-
CPU 密集型程序,一個完整請求,I/O操作可以在很短時間內完成,CPU還有很多運算要處理,也就是說 CPU 計算的比例占很大一部分,線程等待時間接近0
-
單核CPU: 一個完整請求,I/O操作可以在很短時間內完成, CPU還有很多運算要處理,也就是說 CPU 計算的比例占很大一部分,線程等待時間接近0。單核CPU處理CPU密集型程序,這種情況并不太適合使用多線程。
-
多核 : 如果是多核CPU 處理 CPU 密集型程序,我們完全可以最大化的利用 CPU 核心數,應用并發編程來提高效率。CPU 密集型程序的最佳線程數就是:理論上線程數量 = CPU 核數(邏輯),但是實際上,數量一般會設置為 CPU 核數(邏輯)+ 1(經驗值),計算(CPU)密集型的線程恰好在某時因為發生一個頁錯誤或者因其他原因而暫停,剛好有一個“額外”的線程,可以確保在這種情況下CPU周期不會中斷工作
-
-
I/O 密集型程序,與 CPU 密集型程序相對,一個完整請求,CPU運算操作完成之后還有很多 I/O 操作要做,也就是說 I/O 操作占比很大部分,等待時間較長,線程等待時間所占比例越高,需要越多線程;線程CPU時間所占比例越高,需要越少線程
-
I/O 密集型程序的最佳線程數就是: 最佳線程數 = CPU核心數 (1/CPU利用率) = CPU核心數 (1 + (I/O耗時/CPU耗時))
-
如果幾乎全是 I/O耗時,那么CPU耗時就無限趨近于0,所以純理論你就可以說是 2N(N=CPU核數),當然也有說 2N + 1的,1應該是backup
-
一般我們說 2N + 1 就即可
-
線程池拒絕策略
的任務緩存隊列已滿并且線程池中的線程數目達到maximumPoolSize時,如果還有任務到來就會采取任務拒絕策略,通常有以下四種策略: 線程池拒絕策略是在線程池無法繼續接受新任務時,如何拒絕新任務并告知調用者的一種策略。當線程池的工作隊列已滿且線程數達到上限時,可以采用以下幾種拒絕策略:
-
AbortPolicy(默認策略): 這是線程池默認的拒絕策略。當線程池無法接受新任務時,會拋出RejectedExecutionException異常給調用者。
-
CallerRunsPolicy: 當線程池無法接受新任務時,新任務會由提交任務的線程執行。這樣做可以一定程度上降低對系統的壓力,但也會影響提交任務的線程的性能。
-
DiscardOldestPolicy: 當線程池無法接受新任務時,會丟棄工作隊列中最舊的任務(即最先加入隊列的任務)。然后嘗試添加新任務。
-
DiscardPolicy: 當線程池無法接受新任務時,會默默地丟棄新任務,不給任何提示和告知。
除了上述內置的拒絕策略,也可以自定義拒絕策略,實現RejectedExecutionHandler接口,并實現其中的rejectedExecution()方法,根據具體需求進行拒絕策略的定制。
選擇合適的拒絕策略需要根據實際應用場景和需求。例如,如果對任務提交的性能要求較高,可以使用CallerRunsPolicy;如果對任務的可靠性要求較高,可以使用DiscardOldestPolicy;如果不希望丟失任務,可以自定義拒絕策略進行記錄和處理。
線程池的隊列滿了之后
瞬間任務特別多,你可以無限制的不停地創建額外的線程出來,一臺機器上可能有很多很多很多線程,每個線程都有自己的棧內存,占用一定的內存資源,會導致內存資源耗盡,系統也會崩潰。
即使內存沒有崩潰,也會導致機器的cpu load(cpu負載)特別高。
假設【maximumPoolSize】最大線程數,設置為200。可能會導致任務被拒絕掉,很多任務無法被執行。
無界隊列用的比較多,實際情況下得看系統業務的具體負載。具體情況具體分析
可以自定義一個拒絕策略:
自定義一個reject策略,如果線程池無法執行更多的任務了,此時建議你可以把這個任務信息持久化寫入磁盤里去,后臺專門啟動一個線程,后續等待你的線程池的工作負載降低了,他可以慢慢的從磁盤里讀取之前持久化的任務,重新提交到線程池里去執行
8核16G的內存 一般可以
創建多少線程呢?
根據你的業務場景來去設計,核心線程數=CPU核數*(執行時間/(執行時間+等待時間))
執行時間:代碼中運算
等待時間:比如調用dubbo接口等待響應
2、如果使用無界隊列,那么可能會導致OOM甚至宕機。 如果使用有界隊列,然后設置max線程數=max那么會導致創建很多線程,也可能導致服務器崩潰。 所以要根據具體的場景以及具體的壓測數據,來設定這些參數。最后就是我們可以手動去實現一個拒絕策略,將請求持久化一下,然后后臺線程去等線程池負載降下來了后再讀出來繼續執行。
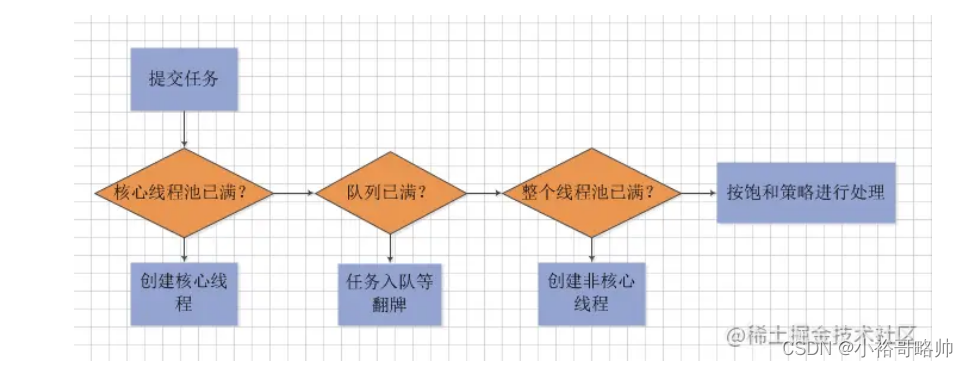
線程池execute提交任務做了什么事? 線程池的狀態
這個問題,有一張很經典的圖可以說明execute的執行流程:(為任務分配線程)
Java線程池(一):運行階段可以修改參數嗎
可以
poolExecutor.execute(() -> { // 執行修改 poolExecutor.setCorePoolSize(10); poolExecutor.setMaximumPoolSize(cpuSize * 5); poolExecutor.setKeepAliveTime(60, TimeUnit.SECONDS); poolExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy()); });
調整核心線程數
上硬核代碼:
public void setCorePoolSize(int corePoolSize) {if (corePoolSize < 0)throw new IllegalArgumentException();int delta = corePoolSize - this.corePoolSize;this.corePoolSize = corePoolSize;// case 1. 如果當前正在使用的核心線程數多余修改后的核心線程數,中斷一部分線程if (workerCountOf(ctl.get()) > corePoolSize)interruptIdleWorkers();else if (delta > 0) {// case 2. 如果是增大核心線程的數量,視情況則增加工作線程int k = Math.min(delta, workQueue.size());while (k-- > 0 && addWorker(null, true)) {if (workQueue.isEmpty())break;}}
}
復制代碼
細說一下,首先,核心線程數量corePoolSize的數量肯定會設置成為我們想要的數值,就case 1來說,調用interruptIdleWorkers來中斷線程,但是中斷是有條件的,如果當前線程在執行任務,此時是不可中斷的,我理解這樣的線程最終會在keepAliveTime時間內結束處理的任務,不管有沒有正確完成,在后面的某一個時間點內核心線程會調整到我們具體設置的值上:
private void interruptIdleWorkers() {interruptIdleWorkers(false);
}
?
private void interruptIdleWorkers(boolean onlyOne) {// 只可有一個線程操作final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 循環線程集合,將處于空閑狀態的線程中斷掉for (Worker w : workers) {Thread t = w.thread;if (!t.isInterrupted() && w.tryLock()) {try {t.interrupt();} catch (SecurityException ignore) {} finally {w.unlock();}}if (onlyOne)break;}} finally {mainLock.unlock();}
}
?
// 其中workers定義:
private final HashSet<Worker> workers = new HashSet<Worker>();
復制代碼
如果是調大核心線程數,比如由5個調整到10個,框架并不是立馬又啟動5個線程,而是結合觀察阻塞隊列里面的任務數,根據代處理的任務數來創建新的worker線程:如果阻塞隊列里面有兩個任務代處理,那么會新增兩個核心線程,如果為0個,那一個都不創建。
ReentrantLock和synchronized的區別
廢話區別:單詞不一樣。。。
核心區別:ReentrantLock是個類,synchronized是關鍵字,當然都是在JVM層面實現互斥鎖的方式
效率區別:如果競爭比較激烈,推薦ReentrantLock去實現,不存在鎖升級概念。而synchronized是存在鎖升級概念的,如果升級到重量級鎖,是不存在鎖降級的。
底層實現區別:實現原理是不一樣,ReentrantLock基于AQS實現的,synchronized是基于ObjectMonitor
功能向的區別:ReentrantLock的功能比synchronized更全面。ReentrantLock支持公平鎖和非公平鎖ReentrantLock可以指定等待鎖資源的時間。
選擇哪個:如果你對并發編程特別熟練,推薦使用ReentrantLock,功能更豐富。如果掌握的一般般,使用synchronized會更好
synchronized和lock有哪些區別?
| 區別類型 | synchronized | Lock |
|---|---|---|
| 存在層次 | Java的關鍵字,在jvm層面上 | 是JVM的一個接口 |
| 鎖的獲取 | 假設A線程獲得鎖,B線程等待。如果A線程阻塞,B線程會一直等待 | 情況而定,Lock有多個鎖獲取的方式,大致就是可以嘗試獲得鎖,線程可以不用一直等待(可以通過tryLock判斷有沒有鎖) |
| 鎖的釋放 | 1、以獲取鎖的線程執行完同步代碼,釋放鎖2、線程執行發生異常,jvm會讓線程釋放 | 在finally中必須釋放鎖,不然容易造成線程死鎖 |
| 鎖類型 | 鎖可重入、不可中斷、非公平 | 可重入、可判斷 可公平(兩者皆可) |
| 性能 | 少量同步 | 適用于大量同步 |
| 支持鎖的場景 | 1. 獨占鎖 | 1. 公平鎖與非公平鎖 |
Lock對比Synchronized 支持以非阻塞方式獲取鎖 可以響應中斷 可以限時
ABA問題遇到過嗎,詳細說一下?
-
有兩個線程同時去修改一個變量的值,比如線程1、線程2,都更新變量值,將變量值從A更新成B。
-
首先線程1獲取到CPU的時間片,線程2由于某些原因發生阻塞進行等待,此時線程1進行比較更新(CompareAndSwap),成功將變量的值從A更新成B。
-
更新完畢之后,恰好又有線程3進來想要把變量的值從B更新成A,線程3進行比較更新,成功將變量的值從B更新成A。
-
線程2獲取到CPU的時間片,然后進行比較更新,發現值是預期的A,然后有更新成了B。但是線程1并不知道,該值已經有了A->B->A這個過程,這也就是我們常說的ABA問題。
?Synchronized原理
synchronized塊是Java提供的一種原子性內置鎖,Java中的每個對象都可以把它當作一個同步鎖來使用,這些Java內置的使用者看不到的鎖被稱為內部鎖,也叫作監視器鎖。線程的執行代碼在進入synchronized代碼塊前會自動獲取內部鎖,這時候其他線程訪問該同步代碼塊時會被阻塞掛起。拿到內部鎖的線程會在正常退出同步代碼塊或者拋出異常后或者在同步塊內調用了該內置鎖資源的wait系列方法時釋放該內置鎖。內置鎖是排它鎖,也就是當一個線程獲取這個鎖后,其他線程必須等待該線程釋放鎖后才能獲取該鎖。另外,由于Java中的線程是與操作系統的原生線程一一對應的,所以當阻塞一個線程時,需要從用戶態切換到內核態執行阻塞操作,這是很耗時的操作,而synchronized的使用就會導致上下文切換。




講解synchronized的一個內存語義,這個內存語義就可以解決共享變量內存可見性問題。進入synchronized塊的內存語義是把在synchronized塊內使用到的變量從線程的工作內存中清除,這樣在synchronized塊內使用到該變量時就不會從線程的工作內存中獲取,而是直接從主內存中獲取。退出synchronized塊的內存語義是把在synchronized塊內對共享變量的修改刷新到主內存。
Synchronized修飾靜態變量和普通變量的區別
這里主要涉及到類對象(static方法),對象方法(非static方法)
我們知道,當synchronized修飾一個static方法時,多線程下,獲取的是類鎖(即Class本身,注意:不是實例);
當synchronized修飾一個非static方法時,多線程下,獲取的是對象鎖(即類的實例對象)
所以,當synchronized修飾一個static方法時,創建線程不管是new JoinThread()還是new Thread(new JoinThread()),在run方法中執行inc()方法都是同步的;
相反,當synchronized修飾一個非static方法時,如果用new JoinThread()還是new Thread(new JoinThread())方式創建線程,就無法保證同步操作,因為這時
inc()是屬于對象方法,每個線程都執有一個獨立的對象實例new JoinThread(),所以多線程下執行inc()方法并不會產生互斥,也不會有同步操作
1.Synchronized修飾非靜態方法,實際上是對調用該方法的對象加鎖,俗稱“對象鎖”。
? Java中每個對象都有一個鎖,并且是唯一的。假設分配的一個對象空間,里面有多個方法,相當于空間里面有多個小房間,如果我們把所有的小房間都加鎖,因為這個對象只有一把鑰匙,因此同一時間只能有一個人打開一個小房間,然后用完了還回去,再由JVM 去分配下一個獲得鑰匙的人。
情況1:同一個對象在兩個線程中分別訪問該對象的兩個同步方法
結果:會產生互斥。
解釋:因為鎖針對的是對象,當對象調用一個synchronized方法時,其他同步方法需要等待其執行結束并釋放鎖后才能執行。
情況2:不同對象在兩個線程中調用同一個同步方法
結果:不會產生互斥。
解釋:因為是兩個對象,鎖針對的是對象,并不是方法,所以可以并發執行,不會互斥。形象的來說就是因為我們每個線程在調用方法的時候都是new 一個對象,那么就會出現兩個空間,兩把鑰匙,
2.Synchronized修飾靜態方法,實際上是對該類對象加鎖,俗稱“類鎖”。
情況1:用類直接在兩個線程中調用兩個不同的同步方法
結果:會產生互斥。
解釋:因為對靜態對象加鎖實際上對類(.class)加鎖,類對象只有一個,可以理解為任何時候都只有一個空間,里面有N個房間,一把鎖,因此房間(同步方法)之間一定是互斥的。
注:上述情況和用單例模式聲明一個對象來調用非靜態方法的情況是一樣的,因為永遠就只有這一個對象。所以訪問同步方法之間一定是互斥的。
情況2:用一個類的靜態對象在兩個線程中調用靜態方法或非靜態方法
結果:會產生互斥。
解釋:因為是一個對象調用,同上。
情況3:一個對象在兩個線程中分別調用一個靜態同步方法和一個非靜態同步方法
結果:不會產生互斥。
volatile和Synchronized


除了Synchronized,還能怎么保證線程安全
1 Lock 和 ReadWriteLock,主要實現類分別為 ReentrantLock 和 ReentrantReadWriteLock 2 atomic 原子性+1 3 threadlocal 注意復雜對象及集合的clear,防止內存溢出 4 volatile 內存可見(不要將volatile用在getAndOperate場合(這種場合不原子,需要再加鎖),僅僅set或者get的場景是適合volatile的)
5 可重入讀寫鎖 ReentrantReadWriteLock(1、只有一個線程可以獲取到寫鎖。在獲取寫鎖時,只有沒有任何線程持有任何鎖才能獲取成功; 2、如果有線程正持有寫鎖,其他任何線程都獲取不到任何鎖; 3、沒有線程持有寫鎖時,可以有多個線程獲取到讀鎖。)
volatile的可見性和禁止指令重排序怎么實現的?
-
可見性: volatile的功能就是被修飾的變量在被修改后可以立即同步到主內存,被修飾的變量在每次是用之前都從主內存刷新。本質也是通過內存屏障來實現可見性 寫內存屏障(Store Memory Barrier)可以促使處理器將當前store buffer(存儲緩存)的值寫回主存。讀內存屏障(Load Memory Barrier)可以促使處理器處理invalidate queue(失效隊列)。進而避免由于Store Buffer和Invalidate Queue的非實時性帶來的問題。
-
禁止指令重排序: volatile是通過內存屏障來禁止指令重排序 JMM內存屏障的策略
-
在每個 volatile 寫操作的前面插入一個 StoreStore 屏障。
-
在每個 volatile 寫操作的后面插入一個 StoreLoad 屏障。
-
在每個 volatile 讀操作的后面插入一個 LoadLoad 屏障。
-
在每個 volatile 讀操作的后面插入一個 LoadStore 屏障。
-
Happens-Before規則是什么?
Happens-Before 規則是并發編程中的一個重要概念,用來描述不同操作之間的先后順序關系。在 Java 內存模型中,Happens-Before 規則定義了一組規則,用于確定一個操作是否能觀察到另一個操作的結果,從而確保多線程程序的正確性和一致性。
具體來說,Happens-Before 規則包括以下幾個方面:
-
程序順序規則:一個線程中的每一個操作,happens-before于該線程中的任意后續操作。
-
監視器規則:對一個鎖的解鎖,happens-before于隨后對這個鎖的加鎖。
-
volatile規則:對一個volatile變量的寫,happens-before于任意后續對一個volatile變量的讀。
-
傳遞性:若果A happens-before B,B happens-before C,那么A happens-before C。
-
線程啟動規則:Thread對象的start()方法,happens-before于這個線程的任意后續操作。
-
線程終止規則:線程中的任意操作,happens-before于該線程的終止監測。我們可以通過Thread.join()方法結束、Thread.isAlive()的返回值等手段檢測到線程已經終止執行。
-
線程中斷操作:對線程interrupt()方法的調用,happens-before于被中斷線程的代碼檢測到中斷事件的發生,可以通過Thread.interrupted()方法檢測到線程是否有中斷發生。
-
對象終結規則:一個對象的初始化完成,happens-before于這個對象的finalize()方法的開始。
Happens-Before 規則幫助程序員理解并發程序中操作之間的執行順序,確保在多線程環境中操作能夠按照預期順序執行,避免出現數據不一致或不確定的結果。合理地遵循 Happens-Before 規則可以減少競態條件(Race Condition)等并發編程中常見的問題,提高程序的穩定性和可靠性。
分布式系統
處理分布式常用的方法
作為一個 Java 開發工程師,處理分布式事務是一個常見的挑戰。以下是一些處理分布式事務的常見方法:
-
兩階段提交(Two-Phase Commit,2PC):2PC 是一種常見的分布式事務協議,它包括協調器和參與者兩個角色。在該協議中,協調器協調所有參與者的提交或回滾操作。盡管 2PC 有效地保證了數據的一致性,但它依賴于協調器的單點故障和網絡延遲的問題。
-
補償事務(Compensating Transaction):補償事務是通過反向操作來撤銷之前已經執行的操作。當一個操作無法成功提交時,可以執行相應的補償操作來回滾已經執行的操作。這種方法要求開發人員預先定義補償操作,并確保補償操作的一致性和正確性。
-
消息隊列(Message Queue):使用消息隊列來處理分布式事務可以提高系統的可靠性和性能。將事務操作封裝為消息并將其發送到消息隊列中,然后由后續的消費者進行處理。如果某個消費者失敗,可以重新消費該消息或者將其發送到死信隊列以便進行后續處理。
-
分布式數據庫:選擇合適的分布式數據庫可以簡化事務處理。一些分布式數據庫系統具有內置的分布式事務管理功能,例如 Google Spanner、Apache Cassandra 或 TiDB 等。它們能夠處理分布式事務并提供一致性和可用性保證。
-
基于消息的最終一致性(Eventual Consistency):在某些場景下,可以接受一定的數據不一致性,并基于最終一致性來處理分布式事務。通過異步更新數據副本,最終達到一致的狀態。這種方式可以提高系統的吞吐量和性能,但需要在業務邏輯上進行妥善處理。
需要根據具體需求選擇合適的事務處理方法。每種方法都有其優缺點,需要權衡各個方面的因素來做出決策。此外,還可以考慮使用一些分布式事務管理框架,如 Seata、HumiFly 等,來簡化分布式事務的處理過程。
分布式id生成方案有哪些?
UUID,數據庫主鍵自增,Redis自增ID,雪花算法。
| 描述 | 優點 | 缺點 | |
|---|---|---|---|
| UUID | UUID是通用唯一標識碼的縮寫,其目的是讓分布式系統中的所有元素都有唯一的辨識信息,而不需要通過中央控制器來指定唯一標識。 | 1. 降低全局節點的壓力,使得主鍵生成速度更快; 2. 生成的主鍵全局唯一; 3. 跨服務器合并數據方便。 | 1. UUID占用16個字符,空間占用較多; 2. 不是遞增有序的數字,數據寫入IO隨機性很大,且索引效率下降 |
| 數據庫主鍵自增 | MySQL數據庫設置主鍵且主鍵自動增長 | 1. INT和BIGINT類型占用空間較小; 2. 主鍵自動增長,IO寫入連續性好; 3. 數字類型查詢速度優于字符串 | 1. 并發性能不高,受限于數據庫性能; 2. 分庫分表,需要改造,復雜; 3. 自增:數據和數據量泄露 |
| Redis自增 | Redis計數器,原子性自增 | 使用內存,并發性能好 | 1. 數據丟失; 2. 自增:數據量泄露 |
| 雪花算法(snowflake) | 大名鼎鼎的雪花算法,分布式ID的經典解決方案 | 1. 不依賴外部組件; 2. 性能好 | 時鐘回撥 |
雪花算法生成的ID由哪些部分組成?
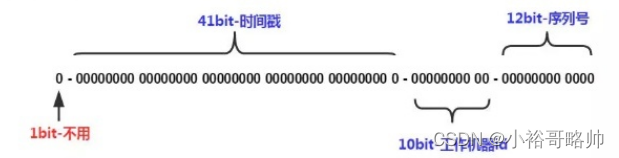
-
符號位,占用1位。
-
時間戳,占用41位,可以支持69年的時間跨度。
-
機器ID,占用10位。
-
序列號,占用12位。一毫秒可以生成4095個ID。
分布式鎖在項目中有哪些應用場景?
使用分布式鎖的場景一般需要滿足以下場景:
-
系統是一個分布式系統,集群集群,java的鎖已經鎖不住了。
-
操作共享資源,比如庫里唯一的用戶數據。
-
同步訪問,即多個進程同時操作共享資源。
分布鎖有哪些解決方案?
-
Reids的分布式鎖,很多大公司會基于Reidis做擴展開發。setnx key value ex 10s,Redisson。
watch dog.
-
基于Zookeeper。臨時節點,順序節點。
-
基于數據庫,比如Mysql。主鍵或唯一索引的唯一性。
基于 ZooKeeper 的分布式鎖實現原理是什么?
順序節點特性:
使用 ZooKeeper 的順序節點特性,假如我們在/lock/目錄下創建3個節點,ZK集群會按照發起創建的順序來創建節點,節點分別為/lock/0000000001、/lock/0000000002、/lock/0000000003,最后一位數是依次遞增的,節點名由zk來完成。
臨時節點特性:
ZK中還有一種名為臨時節點的節點,臨時節點由某個客戶端創建,當客戶端與ZK集群斷開連接,則該節點自動被刪除。EPHEMERAL_SEQUENTIAL為臨時順序節點。
根據ZK中節點是否存在,可以作為分布式鎖的鎖狀態,以此來實現一個分布式鎖,下面是分布式鎖的基本邏輯:
-
客戶端1調用create()方法創建名為“/業務ID/lock-”的臨時順序節點。
-
客戶端1調用getChildren(“業務ID”)方法來獲取所有已經創建的子節點。
-
客戶端獲取到所有子節點path之后,如果發現自己在步驟1中創建的節點是所有節點中序號最小的,就是看自己創建的序列號是否排第一,如果是第一,那么就認為這個客戶端1獲得了鎖,在它前面沒有別的客戶端拿到鎖。
-
如果創建的節點不是所有節點中需要最小的,那么則監視比自己創建節點的序列號小的最大的節點,進入等待。直到下次監視的子節點變更的時候,再進行子節點的獲取,判斷是否獲取鎖。
ZooKeeper和Reids做分布式鎖的區別?
Reids:
-
Redis只保證最終一致性,副本間的數據復制是異步進行(Set是寫,Get是讀,Reids集群一般是讀寫分離架構,存在主從同步延遲情況),主從切換之后可能有部分數據沒有復制過去可能會 「丟失鎖」 情況,故強一致性要求的業務不推薦使用Reids,推薦使用zk。
-
Redis集群各方法的響應時間均為最低。隨著并發量和業務數量的提升其響應時間會有明顯上升(公網集群影響因素偏大),但是極限qps可以達到最大且基本無異常
ZooKeeper:
-
使用ZooKeeper集群,鎖原理是使用ZooKeeper的臨時順序節點,臨時順序節點的生命周期在Client與集群的Session結束時結束。因此如果某個Client節點存在網絡問題,與ZooKeeper集群斷開連接,Session超時同樣會導致鎖被錯誤的釋放(導致被其他線程錯誤地持有),因此ZooKeeper也無法保證完全一致。
-
ZK具有較好的穩定性;響應時間抖動很小,沒有出現異常。但是隨著并發量和業務數量的提升其響應時間和qps會明顯下降。
總結:
-
Zookeeper每次進行鎖操作前都要創建若干節點,完成后要釋放節點,會浪費很多時間;
-
而Redis只是簡單的數據操作,沒有這個問題。
zookeeper的watcher特性
ZooKeeper的Watcher(觀察者)特性是其分布式協調服務中非常重要的一部分。Watcher允許客戶端能夠接收和處理ZooKeeper服務端上節點的變化事件,實現實時的數據同步和協調。
具體來說,ZooKeeper的Watcher特性有以下幾個重要點:
-
監聽節點變化:在創建ZooKeeper客戶端時,可以注冊一個Watcher對象,用于監聽指定節點的變化。當該節點的數據發生變化、被創建、被刪除或其子節點發生變化時,ZooKeeper服務端會將這些事件通知給注冊了Watcher的客戶端。
-
一次性觸發:每個Watcher只能被觸發一次,也就是說,當一個Watcher接收到節點變化的通知后,它就會被移除,需要重新注冊才能繼續監聽。
-
順序性:ZooKeeper保證了Watcher的有序性。具體來說,如果在一個節點上注冊了多個Watcher,那么這些Watcher將按照注冊的先后順序被通知。這樣可以確保處理節點變化事件的順序一致,避免不一致的問題。
-
實現實時同步:通過Watcher,客戶端可以實時地感知到節點的變化,從而能夠及時地更新自己的數據或采取相應的行動。這對于分布式系統中需要實現數據同步和協調的場景非常重要。
Watcher特性的作用是實現分布式系統中的實時數據同步和協調。通過注冊Watcher,客戶端能夠及時地獲取節點變化的通知,從而可以根據實際業務需求進行相應的處理。Watcher在ZooKeeper中廣泛應用于分布式鎖、配置管理、命名服務等場景,為分布式應用程序的開發和運維提供了便利。
Watcher在ZooKeeper中被設計為一種輕量級的通知機制。它的輕量性表現在以下幾個方面:
-
建立和維護開銷較低:當客戶端注冊Watcher時,它們只需要發送一個請求給ZooKeeper服務端,在服務端進行注冊即可。客戶端在接收到節點變化通知后,不需要保持持久的連接,因此不需要額外的資源用于維護連接狀態。
-
數據傳輸量低:Watcher通知中只包含發生變化的節點的相關信息,如節點路徑、變化類型等,并不包含節點的具體數據內容。因此,Watcher通知的數據傳輸量通常非常小,可以在網絡中快速傳輸。
但需要注意以下幾點:
-
Watcher的觸發是異步的:當節點發生變化時,并不能保證Watcher能夠立即被觸發。ZooKeeper服務端會將通知推送給客戶端,但觸發的時間可能會受到網絡延遲等因素的影響。
-
Watcher的處理應盡快完成:由于Watcher在同一個會話中只能觸發一次,因此客戶端在處理Watcher通知時應盡快完成相應的邏輯,以保持及時的響應能力。
客戶端注冊 Watcher 實現
-
創建ZooKeeper連接: 首先,需要創建一個ZooKeeper連接對象,并指定ZooKeeper服務端的地址和會話超時時間。例如:
ZooKeeper zooKeeper = new ZooKeeper("localhost:2181", 5000, null); -
注冊Watcher: 在需要監聽節點變化的地方,可以通過調用ZooKeeper對象的方法來注冊Watcher。例如,注冊一個用于監聽指定節點"/myNode"的變化的Watcher:
zooKeeper.exists("/myNode", new Watcher() {@Overridepublic void process(WatchedEvent event) {// 處理節點變化事件的邏輯System.out.println("Node changed: " + event.getPath());} }); -
處理Watcher事件: 定義Watcher的process()方法中,可以編寫具體的邏輯來處理節點變化事件。例如,在上述的Watcher中,當指定的節點發生變化時,會打印出節點路徑。 可以根據實際需求進行相應的數據更新、業務操作等。
需要注意的是,注冊Watcher的方法中通常還會包含其他參數,用于控制Watcher的行為,如是否觸發默認的Watch(設為true時,會在節點變化時收到通知)、指定Watcher的路徑是否存在等。
-
MySQL如何做分布式鎖?
在Mysql中創建一張表,設置一個 主鍵或者UNIQUE KEY 這個 KEY 就是要鎖的 KEY(商品ID),所以同一個 KEY 在mysql表里只能插入一次了,這樣對鎖的競爭就交給了數據庫,處理同一個 KEY 數據庫保證了只有一個節點能插入成功,其他節點都會插入失敗。
DB分布式鎖的實現:通過主鍵id 或者 唯一索性 的唯一性進行加鎖,說白了就是加鎖的形式是向一張表中插入一條數據,該條數據的id就是一把分布式鎖,例如當一次請求插入了一條id為1的數據,其他想要進行插入數據的并發請求必須等第一次請求執行完成后刪除這條id為1的數據才能繼續插入,實現了分布式鎖的功能。
這樣 lock 和 unlock 的思路就很簡單了,偽代碼:
def lock :exec sql: insert into locked—table (xxx) values (xxx)if result == true :return trueelse :return false ? def unlock :exec sql: delete from lockedOrder where order_id='order_id'
計數器算法是什么?
計數器算法,是指在指定的時間周期內累加訪問次數,達到設定的閾值時,觸發限流策略。下一個時間周期進行訪問時,訪問次數清零。此算法無論在單機還是分布式環境下實現都非常簡單,使用redis的incr原子自增性,再結合key的過期時間,即可輕松實現。
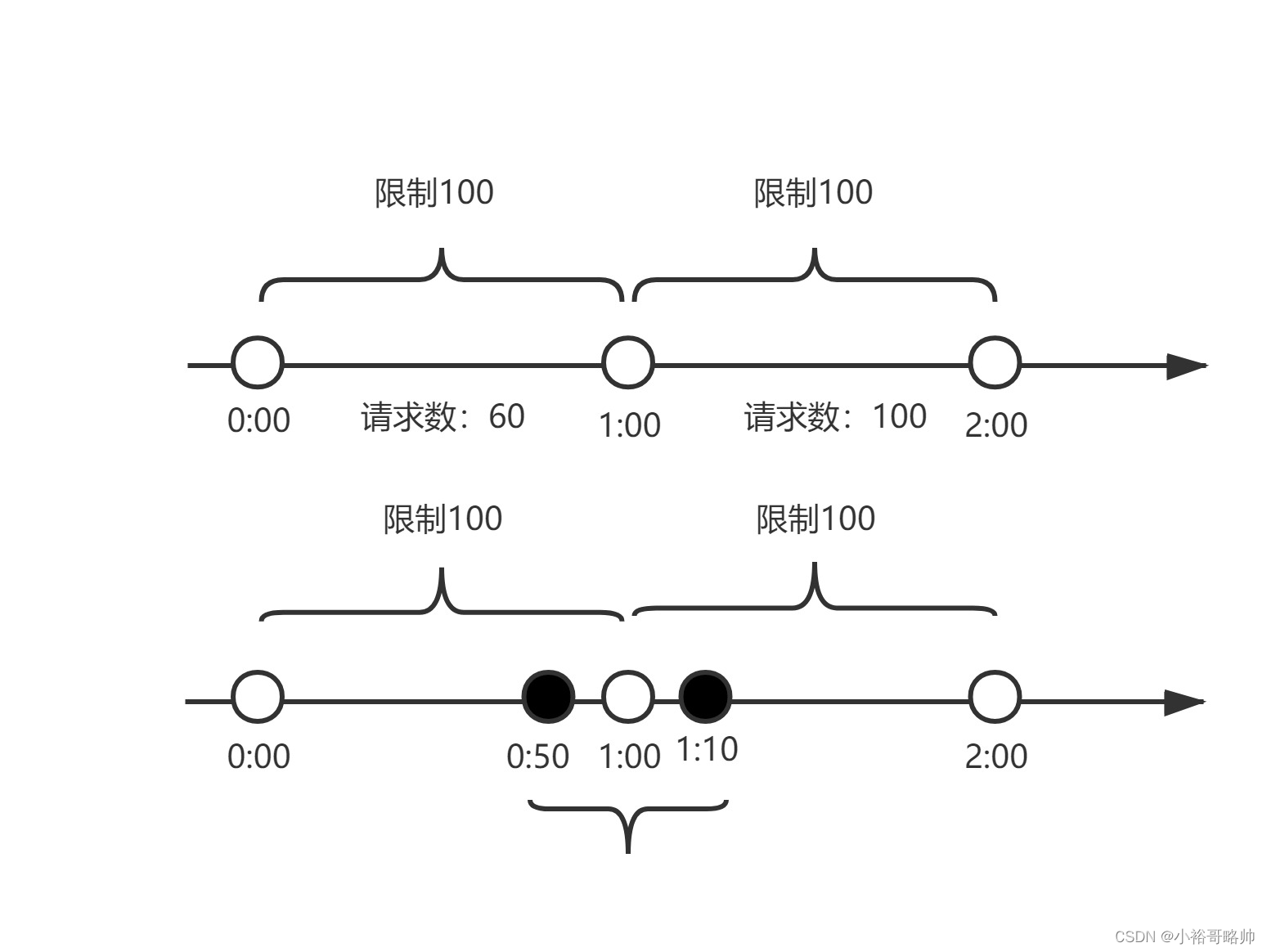
從上圖我們來看,我們設置一分鐘的閾值是100,在0:00到1:00內請求數是60,當到1:00時,請求數清零,從0開始計算,這時在1:00到2:00之間我們能處理的最大的請求為100,超過100個的請求,系統都拒絕。
這個算法有一個臨界問題,比如在上圖中,在0:00到1:00內,只在0:50有60個請求,而在1:00到2:00之間,只在1:10有60個請求,雖然在兩個一分鐘的時間內,都沒有超過100個請求,但是在0:50到1:10這20秒內,確有120個請求,雖然在每個周期內,都沒超過閾值,但是在這20秒內,已經遠遠超過了我們原來設置的1分鐘內100個請求的閾值。
滑動時間窗口算法是什么?
為了解決計數器算法的臨界值的問題,發明了滑動窗口算法。在TCP網絡通信協議中,就采用滑動時間窗口算法來解決網絡擁堵問題。
滑動時間窗口是將計數器算法中的實際周期切分成多個小的時間窗口,分別在每個小的時間窗口中記錄訪問次數,然后根據時間將窗口往前滑動并刪除過期的小時間窗口。最終只需要統計滑動窗口范圍內的小時間窗口的總的請求數即可。
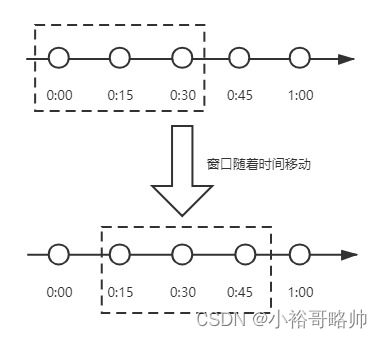
在上圖中,假設我們設置一分鐘的請求閾值是100,我們將一分鐘拆分成4個小時間窗口,這樣,每個小的時間窗口只能處理25個請求,我們用虛線方框表示滑動時間窗口,當前窗口的大小是2,也就是在窗口內最多能處理50個請求。隨著時間的推移,滑動窗口也隨著時間往前移動,比如上圖開始時,窗口是0:00到0:30的這個范圍,過了15秒后,窗口是0:15到0:45的這個范圍,窗口中的請求重新清零,這樣就很好的解決了計數器算法的臨界值問題。
在滑動時間窗口算法中,我們的小窗口劃分的越多,滑動窗口的滾動就越平滑,限流的統計就會越精確。
漏桶限流算法是什么?
漏桶算法的原理就像它的名字一樣,我們維持一個漏斗,它有恒定的流出速度,不管水流流入的速度有多快,漏斗出水的速度始終保持不變,類似于消息中間件,不管消息的生產者請求量有多大,消息的處理能力取決于消費者。
漏桶的容量=漏桶的流出速度*可接受的等待時長。在這個容量范圍內的請求可以排隊等待系統的處理,超過這個容量的請求,才會被拋棄。
在漏桶限流算法中,存在下面幾種情況:
-
當請求速度大于漏桶的流出速度時,也就是請求量大于當前服務所能處理的最大極限值時,觸發限流策略。
-
請求速度小于或等于漏桶的流出速度時,也就是服務的處理能力大于或等于請求量時,正常執行。
漏桶算法有一個缺點:當系統在短時間內有突發的大流量時,漏桶算法處理不了。
令牌桶限流算法是什么?
令牌桶算法,是增加一個大小固定的容器,也就是令牌桶,系統以恒定的速率向令牌桶中放入令牌,如果有客戶端來請求,先需要從令牌桶中拿一個令牌,拿到令牌,才有資格訪問系統,這時令牌桶中少一個令牌。當令牌桶滿的時候,再向令牌桶生成令牌時,令牌會被拋棄。
在令牌桶算法中,存在以下幾種情況:
-
請求速度大于令牌的生成速度:那么令牌桶中的令牌會被取完,后續再進來的請求,由于拿不到令牌,會被限流。
-
請求速度等于令牌的生成速度:那么此時系統處于平穩狀態。
-
請求速度小于令牌的生成速度:那么此時系統的訪問量遠遠低于系統的并發能力,請求可以被正常處理。
令牌桶算法,由于有一個桶的存在,可以處理短時間大流量的場景。這是令牌桶和漏桶的一個區別。
你設計微服務時遵循什么原則?
-
單一職責原則:讓每個服務能獨立,有界限的工作,每個服務只關注自己的業務。做到高內聚。
-
服務自治原則:每個服務要能做到獨立開發、獨立測試、獨立構建、獨立部署,獨立運行。與其他服務進行解耦。
-
輕量級通信原則:讓每個服務之間的調用是輕量級,并且能夠跨平臺、跨語言。比如采用RESTful風格,利用消息隊列進行通信等。
-
粒度進化原則:對每個服務的粒度把控,其實沒有統一的標準,這個得結合我們解決的具體業務問題。不要過度設計。服務的粒度隨著業務和用戶的發展而發展。
總結一句話,軟件是為業務服務的,好的系統不是設計出來的,而是進化出來的。
CAP定理是什么?
CAP定理,又叫布魯爾定理。指的是:在一個分布式系統中,最多只能同時滿足一致性(Consistency)、可用性(Availability)和分區容錯性(Partition tolerance)這三項中的兩項。
-
C:一致性(Consistency),數據在多個副本中保持一致,可以理解成兩個用戶訪問兩個系統A和B,當A系統數據有變化時,及時同步給B系統,讓兩個用戶看到的數據是一致的。
-
A:可用性(Availability),系統對外提供服務必須一直處于可用狀態,在任何故障下,客戶端都能在合理時間內獲得服務端非錯誤的響應。
-
P:分區容錯性(Partition tolerance),在分布式系統中遇到任何網絡分區故障,系統仍然能對外提供服務。網絡分區,可以這樣理解,在分布式系統中,不同的節點分布在不同的子網絡中,有可能子網絡中只有一個節點,在所有網絡正常的情況下,由于某些原因導致這些子節點之間的網絡出現故障,導致整個節點環境被切分成了不同的獨立區域,這就是網絡分區。
我們來詳細分析一下CAP,為什么只能滿足兩個。看下圖所示:
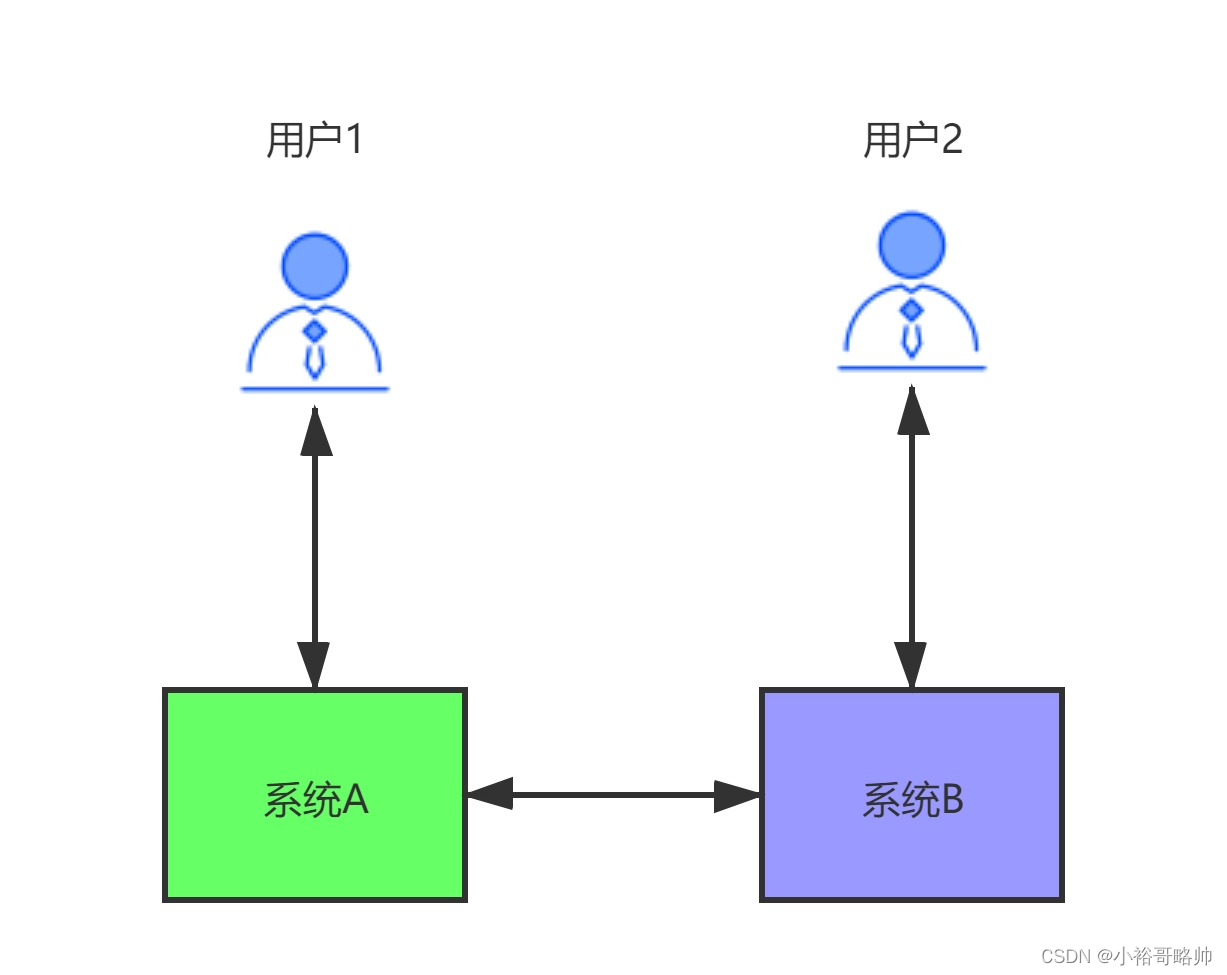
用戶1和用戶2分別訪問系統A和系統B,系統A和系統B通過網絡進行同步數據。理想情況是:用戶1訪問系統A對數據進行修改,將data1改成了data2,同時用戶2訪問系統B,拿到的是data2數據。
但是實際中,由于分布式系統具有八大謬論:
-
網絡相當可靠
-
延遲為零
-
傳輸帶寬是無限的
-
網絡相當安全
-
拓撲結構不會改變
-
必須要有一名管理員
-
傳輸成本為零
-
網絡同質化
我們知道,只要有網絡調用,網絡總是不可靠的。我們來一一分析。
-
當網絡發生故障時,系統A和系統B沒法進行數據同步,也就是我們不滿足P,同時兩個系統依然可以訪問,那么此時其實相當于是單機系統,就不是分布式系統了,所以既然我們是分布式系統,P必須滿足。
-
當P滿足時,如果用戶1通過系統A對數據進行了修改將data1改成了data2,也要讓用戶2通過系統B正確的拿到data2,那么此時是滿足C,就必須等待網絡將系統A和系統B的數據同步好,并且在同步期間,任何人不能訪問系統B(讓系統不可用),否則數據就不是一致的。此時滿足的是CP。
-
當P滿足時,如果用戶1通過系統A對數據進行了修改將data1改成了data2,也要讓系統B能繼續提供服務,那么此時,只能接受系統A沒有將data2同步給系統B(犧牲了一致性)。此時滿足的就是AP。
-
我們在前面學過的注冊中心Eureka就是滿足 的AP,它并不保證C。而Zookeeper是保證CP,它不保證A。在生產中,A和C的選擇,沒有正確的答案,是取決于自己的業務的。比如12306,是滿足CP,因為買票必須滿足數據的一致性,不然一個座位多賣了,對鐵路運輸都是不可以接受的。
BASE理論是什么?
由于CAP中一致性C和可用性A無法兼得,eBay的架構師,提出了BASE理論,它是通過犧牲數據的強一致性,來獲得可用性。它由于如下3種特征:
-
Basically Available(基本可用):分布式系統在出現不可預知故障的時候,允許損失部分可用性,保證核心功能的可用。
-
Soft state(軟狀態):軟狀態也稱為弱狀態,和硬狀態相對,是指允許系統中的數據存在中間狀態,并認為該中間狀態的存在不會影響系統的整體可用性,即允許系統在不同節點的數據副本之間進行數據同步的過程存在延時。、
-
Eventually consistent(最終一致性):最終一致性強調的是系統中所有的數據副本,在經過一段時間的同步后,最終能夠達到一個一致的狀態。因此,最終一致性的本質是需要系統保證最終數據能夠達到一致,而不需要實時保證系統數據的強一致性。
BASE理論并沒有要求數據的強一致性,而是允許數據在一定的時間段內是不一致的,但在最終某個狀態會達到一致。在生產環境中,很多公司,會采用BASE理論來實現數據的一致,因為產品的可用性相比強一致性來說,更加重要。比如在電商平臺中,當用戶對一個訂單發起支付時,往往會調用第三方支付平臺,比如支付寶支付或者微信支付,調用第三方成功后,第三方并不能及時通知我方系統,在第三方沒有通知我方系統的這段時間內,我們給用戶的訂單狀態顯示支付中,等到第三方回調之后,我們再將狀態改成已支付。雖然訂單狀態在短期內存在不一致,但是用戶卻獲得了更好的產品體驗。
2PC提交協議是什么?
二階段提交(Two-phaseCommit)是指,在計算機網絡以及數據庫領域內,為了使基于分布式系統架構下的所有節點在進行事務提交時保持一致性而設計的一種算法(Algorithm)。通常,二階段提交也被稱為是一種協議(Protocol))。在分布式系統中,每個節點雖然可以知曉自己的操作時成功或者失敗,卻無法知道其他節點的操作的成功或失敗。當一個事務跨越多個節點時,為了保持事務的ACID特性,需要引入一個作為協調者的組件來統一掌控所有節點(稱作參與者)的操作結果并最終指示這些節點是否要把操作結果進行真正的提交(比如將更新后的數據寫入磁盤等等)。因此,二階段提交的算法思路可以概括為:參與者將操作成敗通知協調者,再由協調者根據所有參與者的反饋情報決定各參與者是否要提交操作還是中止操作。
所謂的兩個階段是指:第一階段:準備階段(投票階段)和第二階段:提交階段(執行階段)。
準備階段
事務協調者(事務管理器)給每個參與者(資源管理器)發送Prepare消息,每個參與者要么直接返回失敗(如權限驗證失敗),要么在本地執行事務,寫本地的redo和undo日志,但不提交,到達一種“萬事俱備,只欠東風”的狀態。
可以進一步將準備階段分為以下三個步驟:
1)協調者節點向所有參與者節點詢問是否可以執行提交操作(vote),并開始等待各參與者節點的響應。
2)參與者節點執行詢問發起為止的所有事務操作,并將Undo信息和Redo信息寫入日志。(注意:若成功這里其實每個參與者已經執行了事務操作)
3)各參與者節點響應協調者節點發起的詢問。如果參與者節點的事務操作實際執行成功,則它返回一個”同意”消息;如果參與者節點的事務操作實際執行失敗,則它返回一個”中止”消息。
提交階段
如果協調者收到了參與者的失敗消息或者超時,直接給每個參與者發送回滾(Rollback)消息;否則,發送提交(Commit)消息;參與者根據協調者的指令執行提交或者回滾操作,釋放所有事務處理過程中使用的鎖資源。(注意:必須在最后階段釋放鎖資源)
接下來分兩種情況分別討論提交階段的過程。
當協調者節點從所有參與者節點獲得的相應消息都為”同意”時:

1)協調者節點向所有參與者節點發出”正式提交(commit)”的請求。
2)參與者節點正式完成操作,并釋放在整個事務期間內占用的資源。
3)參與者節點向協調者節點發送”完成”消息。
4)協調者節點受到所有參與者節點反饋的”完成”消息后,完成事務。
如果任一參與者節點在第一階段返回的響應消息為”中止”,或者 協調者節點在第一階段的詢問超時之前無法獲取所有參與者節點的響應消息時:
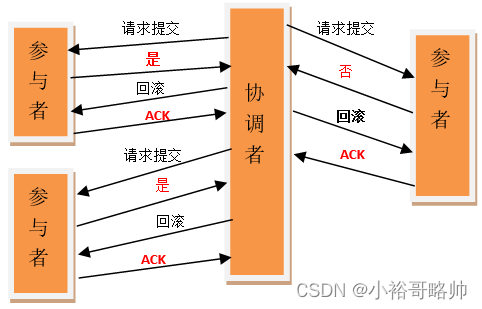
1)協調者節點向所有參與者節點發出”回滾操作(rollback)”的請求。
2)參與者節點利用之前寫入的Undo信息執行回滾,并釋放在整個事務期間內占用的資源。
3)參與者節點向協調者節點發送”回滾完成”消息。
4)協調者節點受到所有參與者節點反饋的”回滾完成”消息后,取消事務。
不管最后結果如何,第二階段都會結束當前事務。
2PC提交協議有什么缺點?
-
同步阻塞問題。執行過程中,所有參與節點都是事務阻塞型的。當參與者占有公共資源時,其他第三方節點訪問公共資源不得不處于阻塞狀態。
-
單點故障。由于協調者的重要性,一旦協調者發生故障。參與者會一直阻塞下去。尤其在第二階段,協調者發生故障,那么所有的參與者還都處于鎖定事務資源的狀態中,而無法繼續完成事務操作。(如果是協調者掛掉,可以重新選舉一個協調者,但是無法解決因為協調者宕機導致的參與者處于阻塞狀態的問題)
-
數據不一致。在二階段提交的階段二中,當協調者向參與者發送commit請求之后,發生了局部網絡異常或者在發送commit請求過程中協調者發生了故障,這回導致只有一部分參與者接受到了commit請求。而在這部分參與者接到commit請求之后就會執行commit操作。但是其他部分未接到commit請求的機器則無法執行事務提交。于是整個分布式系統便出現了數據部一致性的現象。
-
二階段無法解決的問題:協調者再發出commit消息之后宕機,而唯一接收到這條消息的參與者同時也宕機了。那么即使協調者通過選舉協議產生了新的協調者,這條事務的狀態也是不確定的,沒人知道事務是否被已經提交。
3PC提交協議是什么?
CanCommit階段
3PC的CanCommit階段其實和2PC的準備階段很像。協調者向參與者發送commit請求,參與者如果可以提交就返回Yes響應,否則返回No響應。
1.事務詢問 協調者向參與者發送CanCommit請求。詢問是否可以執行事務提交操作。然后開始等待參與者的響應。
2.響應反饋 參與者接到CanCommit請求之后,正常情況下,如果其自身認為可以順利執行事務,則返回Yes響應,并進入預備狀態。否則反饋No
PreCommit階段
協調者根據參與者的反應情況來決定是否可以進行事務的PreCommit操作。根據響應情況,有以下兩種可能。
假如協調者從所有的參與者獲得的反饋都是Yes響應,那么就會執行事務的預執行。
1.發送預提交請求 協調者向參與者發送PreCommit請求,并進入Prepared階段。
2.事務預提交 參與者接收到PreCommit請求后,會執行事務操作,并將undo和redo信息記錄到事務日志中。
3.響應反饋 如果參與者成功的執行了事務操作,則返回ACK響應,同時開始等待最終指令。
假如有任何一個參與者向協調者發送了No響應,或者等待超時之后,協調者都沒有接到參與者的響應,那么就執行事務的中斷。
1.發送中斷請求 協調者向所有參與者發送abort請求。
2.中斷事務 參與者收到來自協調者的abort請求之后(或超時之后,仍未收到協調者的請求),執行事務的中斷。
pre階段參與者沒收到請求,rollback。
doCommit階段
該階段進行真正的事務提交,也可以分為以下兩種情況。
執行提交
1.發送提交請求 協調接收到參與者發送的ACK響應,那么他將從預提交狀態進入到提交狀態。并向所有參與者發送doCommit請求。
2.事務提交 參與者接收到doCommit請求之后,執行正式的事務提交。并在完成事務提交之后釋放所有事務資源。
3.響應反饋 事務提交完之后,向協調者發送Ack響應。
4.完成事務 協調者接收到所有參與者的ack響應之后,完成事務。
中斷事務 協調者沒有接收到參與者發送的ACK響應(可能是接受者發送的不是ACK響應,也可能響應超時),那么就會執行中斷事務。
1.發送中斷請求 協調者向所有參與者發送abort請求
2.事務回滾 參與者接收到abort請求之后,利用其在階段二記錄的undo信息來執行事務的回滾操作,并在完成回滾之后釋放所有的事務資源。
3.反饋結果 參與者完成事務回滾之后,向協調者發送ACK消息
4.中斷事務 協調者接收到參與者反饋的ACK消息之后,執行事務的中斷。
2PC和3PC的區別是什么?
1、引入超時機制。同時在協調者和參與者中都引入超時機制。
2、三階段在2PC的第一階段和第二階段中插入一個準備階段。保證了在最后提交階段之前各參與節點的狀態是一致的。
-
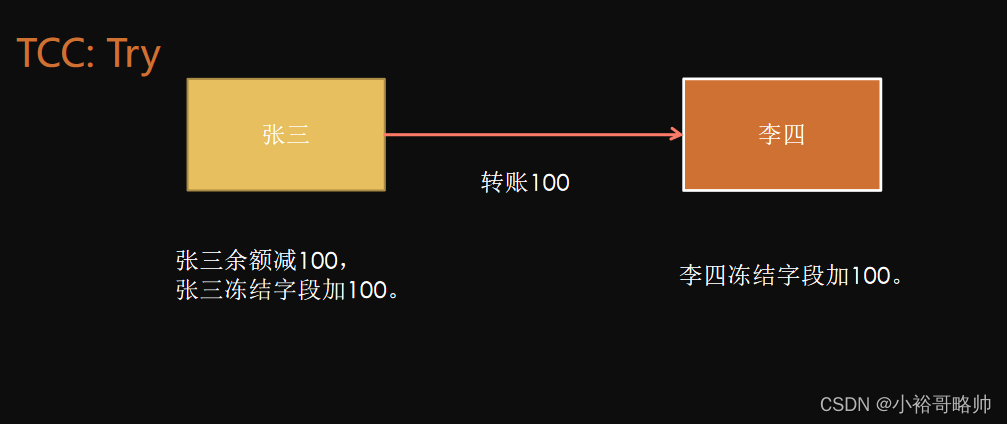
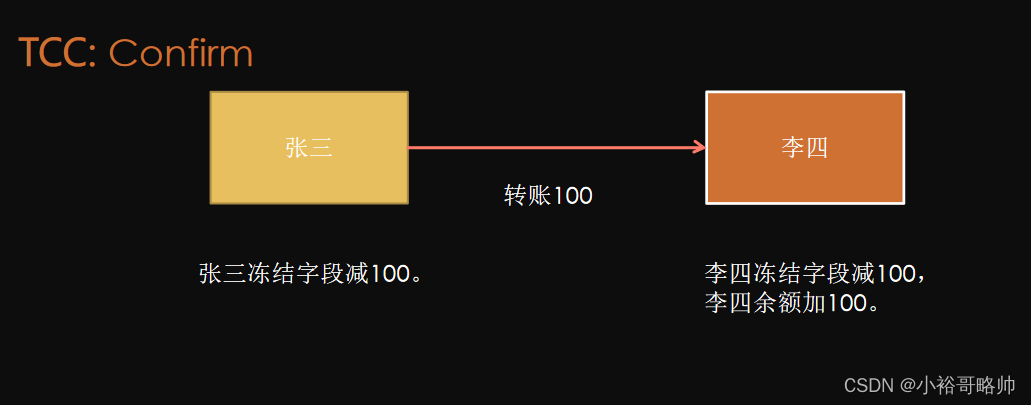
TCC解決方案是什么?
TCC(Try-Confirm-Cancel)是一種常用的分布式事務解決方案,它將一個事務拆分成三個步驟:
-
T(Try):業務檢查階段,這階段主要進行業務校驗和檢查或者資源預留;也可能是直接進行業務操作。
-
C(Confirm):業務確認階段,這階段對Try階段校驗過的業務或者預留的資源進行確認。
-
C(Cancel):業務回滾階段,這階段和上面的C(Confirm)是互斥的,用于釋放Try階段預留的資源或者業務。
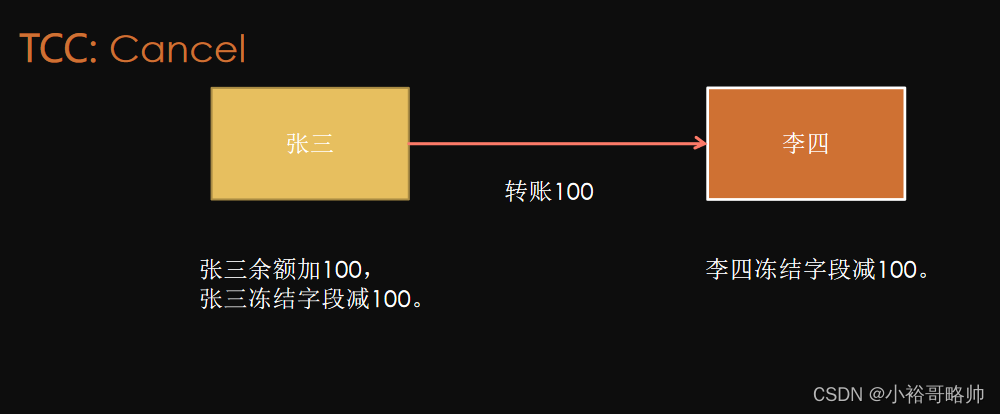
-
TCC空回滾是解決什么問題的?
在沒有調用TCC資源Try方法的情況下,調用了二階段的Cancel方法。比如當Try請求由于網絡延遲或故障等原因,沒有執行,結果返回了異常,那么此時Cancel就不能正常執行,因為Try沒有對數據進行修改,如果Cancel進行了對數據的修改,那就會導致數據不一致。 ? 解決思路是關鍵就是要識別出這個空回滾。思路很簡單就是需要知道Try階段是否執行,如果執行了,那就是正常回滾;如果沒執行,那就是空回滾。建議TM在發起全局事務時生成全局事務記錄,全局事務ID貫穿整個分布式事務調用鏈條。再額外增加一張分支事務記錄表,其中有全局事務ID和分支事務ID,第一階段Try方法里會插入一條記錄,表示Try階段執行了。Cancel接口里讀取該記錄,如果該記錄存在,則正常回滾;如果該記錄不存在,則是空回滾。
如何解決TCC冪等問題?
為了保證TCC二階段提交重試機制不會引發數據不一致,要求TCC的二階段Confirm和Cancel接口保證冪等,這樣不會重復使用或者釋放資源。如果冪等控制沒有做好,很有可能導致數據不一致等嚴重問題。 解決思路在上述 分支事務記錄中增加執行狀態,每次執行前都查詢該狀態。
分布式鎖。
如何解決TCC中懸掛問題?
懸掛就是對于一個分布式事務,其二階段Cancel接口比Try接口先執行。 出現原因是在調用分支事務Try時,由于網絡發生擁堵,造成了超時,TM就會通知RM回滾該分布式事務,可能回滾完成后,Try請求才到達參與者真正執行,而一個Try方法預留的業務資源,只有該分布式事務才能使用,該分布式事務第一階段預留的業務資源就再也沒有人能夠處理了,對于這種情況,我們就稱為懸掛,即業務資源預留后無法繼續處理。 解決思路是如果二階段執行完成,那一階段就不能再繼續執行。在執行一階段事務時判斷在該全局事務下,判斷分支事務記錄表中是否已經有二階段事務記錄,如果有則不執行Try。
可靠消息服務方案是什么?
可靠消息最終一致性方案指的是:當事務的發起方(事務參與者,消息發送者)執行完本地事務后,同時發出一條消息,事務參與方(事務參與者,消息的消費者)一定能夠接受消息并可以成功處理自己的事務。
這里面強調兩點:
-
可靠消息:發起方一定得把消息傳遞到消費者。
-
最終一致性:最終發起方的業務處理和消費方的業務處理得完成,達成最終一致。

最大努力通知方案的關鍵是什么?
-
有一定的消息重復通知機制。因為接收通知方(上圖中的我方支付系統)可能沒有接收到通知,此時要有一定的機制對消息重復通知。
-
消息校對機制。如果盡最大努力也沒有通知到接收方,或者接收方消費消息后要再次消費,此時可由接收方主動向通知方查詢消息信息來滿足需求。
什么是分布式系統中的冪等?
冪等(idempotent、idempotence)是一個數學與計算機學概念,常見于抽象代數中。
在編程中,一個冪等操作的特點是其任意多次執行所產生的影響均與一次執行的影響相同。冪等函數,或冪等方法,是指可以使用相同參數重復執行,并能獲得相同結果的函數。這些函數不會影響系統狀態,也不用擔心重復執行會對系統造成改變。
例如,“getUsername()和 setTrue()”函數就是一個冪等函數. 更復雜的操作冪等保證是利用唯一交易號(流水號)實現. 我的理解:冪等就是一個操作,不論執行多少次,產生的效果和返回的結果都是一樣的。
操作:查詢,set固定值。邏輯刪除。set 固定值。
流程:分布式系統中,網絡調用,重試機制。
冪等有哪些技術解決方案?
1.查詢操作
查詢一次和查詢多次,在數據不變的情況下,查詢結果是一樣的。select 是天然的冪等操作;
2.刪除操作
刪除操作也是冪等的,刪除一次和多次刪除都是把數據刪除。(注意可能返回結果不一樣,刪除的數據不存在,返回 0,刪除的數據多條,返回結果多個。
3.唯一索引
防止新增臟數據。比如:支付寶的資金賬戶,支付寶也有用戶賬戶,每個用戶只能有一個資金賬戶,怎么防止給用戶創建多個資金賬戶,那么給資金賬戶表中的用戶 ID 加唯一索引,所以一個用戶新增成功一個資金賬戶記錄。要點:唯一索引或唯一組合索引來防止新增數據存在臟數據(當表存在唯一索引,并發時新增報錯時,再查詢一次就可以了,數據應該已經存在了,返回結果即可。
4.token 機制
防止頁面重復提交。
業務要求:頁面的數據只能被點擊提交一次;
發生原因:由于重復點擊或者網絡重發,或者 nginx 重發等情況會導致數據被重復提交;
解決辦法:集群環境采用 token 加 redis(redis 單線程的,處理需要排隊);單 JVM 環境:采用 token 加 redis 或 token 加 jvm 鎖。
處理流程:
-
數據提交前要向服務的申請 token,token 放到 redis 或 jvm 內存,token 有效時間;
-
提交后后臺校驗 token,同時刪除 token,生成新的 token 返回。
token 特點:要申請,一次有效性,可以限流。
注意:redis 要用刪除操作來判斷 token,刪除成功代表 token 校驗通過。
-
traceId
操作時唯一的。
對外提供的API如何保證冪等?
舉例說明: 銀聯提供的付款接口:需要接入商戶提交付款請求時附帶:source 來源,seq 序列號。
source+seq 在數據庫里面做唯一索引,防止多次付款(并發時,只能處理一個請求) 。重點:對外提供接口為了支持冪等調用,接口有兩個字段必須傳,一個是來源 source,一個是來源方序列號 seq,這個兩個字段在提供方系統里面做聯合唯一索引,這樣當第三方調用時,先在本方系統里面查詢一下,是否已經處理過,返回相應處理結果;沒有處理過,進行相應處理,返回結果。
注意,為了冪等友好,一定要先查詢一下,是否處理過該筆業務,不查詢直接插入業務系統,會報錯,但實際已經處理。
分布式系統如何設計
從嚴格意義上來說,一個系統由多個獨立的進程組成,而且進程之間有數據交互的邏輯,那么,不管這幾個進程是否被部署在一臺主機上,這樣的系統都可以叫作分布式系統。
分布式微服務項目你是如何設計的?
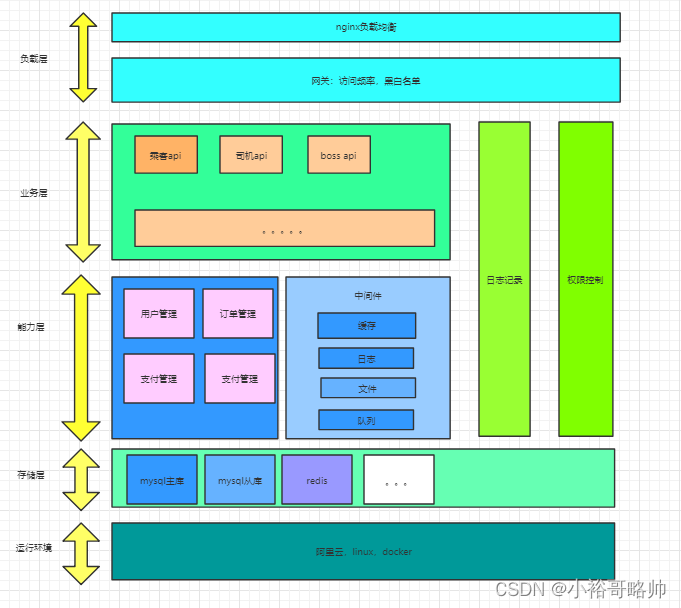
我一般設計成兩層:業務層和能力層(中臺),業務層接受用戶請求,然后通過調用能力層來完成業務邏輯。
認證 (Authentication) 和授權 (Authorization)的區別是什么?
Authentication(認證) 是驗證您的身份的憑據(例如用戶名/用戶ID和密碼),通過這個憑據,系統得以知道你就是你,也就是說系統存在你這個用戶。所以,Authentication 被稱為身份/用戶驗證。 Authorization(授權) 發生在 Authentication(認證) 之后。授權,它主要掌管我們訪問系統的權限。比如有些特定資源只能具有特定權限的人才能訪問比如admin,有些對系統資源操作比如刪除、添加、更新只能特定人才具有。 這兩個一般在我們的系統中被結合在一起使用,目的就是為了保護我們系統的安全性。
Cookie 和 Session 有什么區別?如何使用Session進行身份驗證?
Session 的主要作用就是通過服務端記錄用戶的狀態。 典型的場景是購物車,當你要添加商品到購物車的時候,系統不知道是哪個用戶操作的,因為 HTTP 協議是無狀態的。服務端給特定的用戶創建特定的 Session 之后就可以標識這個用戶并且跟蹤這個用戶了。
Cookie 數據保存在客戶端(瀏覽器端),Session 數據保存在服務器端。相對來說 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要寫入 Cookie 中,最好能將 Cookie 信息加密然后使用到的時候再去服務器端解密。
那么,如何使用Session進行身份驗證?
很多時候我們都是通過 SessionID 來實現特定的用戶,SessionID 一般會選擇存放在 Redis 中。舉個例子:用戶成功登陸系統,然后返回給客戶端具有 SessionID 的 Cookie,當用戶向后端發起請求的時候會把 SessionID 帶上,這樣后端就知道你的身份狀態了。關于這種認證方式更詳細的過程如下:
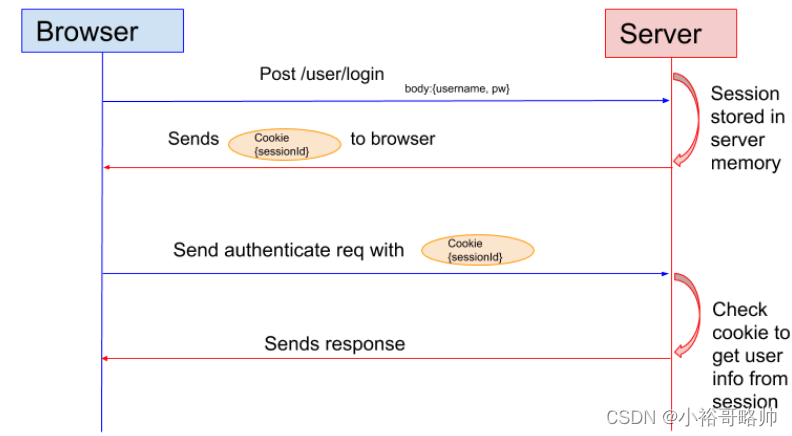
用戶向服務器發送用戶名和密碼用于登陸系統。 服務器驗證通過后,服務器為用戶創建一個 Session,并將 Session信息存儲 起來。 服務器向用戶返回一個 SessionID,寫入用戶的 Cookie。 當用戶保持登錄狀態時,Cookie 將與每個后續請求一起被發送出去。 服務器可以將存儲在 Cookie 上的 Session ID 與存儲在內存中或者數據庫中的 Session 信息進行比較,以驗證用戶的身份,返回給用戶客戶端響應信息的時候會附帶用戶當前的狀態。 使用 Session 的時候需要注意下面幾個點:
依賴Session的關鍵業務一定要確保客戶端開啟了Cookie。 注意Session的過期時間
為什么Cookie 無法防止CSRF攻擊,而token可以?
CSRF(Cross Site Request Forgery)一般被翻譯為 跨站請求偽造 。那么什么是 跨站請求偽造 呢?說簡單用你的身份去發送一些對你不友好的請求。舉個簡單的例子:
小壯登錄了某網上銀行,他來到了網上銀行的帖子區,看到一個帖子下面有一個鏈接寫著“科學理財,年盈利率過萬”,小壯好奇的點開了這個鏈接,結果發現自己的賬戶少了10000元。這是這么回事呢?原來黑客在鏈接中藏了一個請求,這個請求直接利用小壯的身份給銀行發送了一個轉賬請求,也就是通過你的 Cookie 向銀行發出請求。
<a src=http://www.mybank.com/Transfer?bankId=11&money=10000>科學理財,年盈利率過萬</> 進行Session 認證的時候,我們一般使用 Cookie 來存儲 SessionId,當我們登陸后后端生成一個SessionId放在Cookie中返回給客戶端,服務端通過Redis或者其他存儲工具記錄保存著這個Sessionid,客戶端登錄以后每次請求都會帶上這個SessionId,服務端通過這個SessionId來標示你這個人。如果別人通過 cookie拿到了 SessionId 后就可以代替你的身份訪問系統了。
Session 認證中 Cookie 中的 SessionId是由瀏覽器發送到服務端的,借助這個特性,攻擊者就可以通過讓用戶誤點攻擊鏈接,達到攻擊效果。
但是,我們使用 token 的話就不會存在這個問題,在我們登錄成功獲得 token 之后,一般會選擇存放在 local storage 中。然后我們在前端通過某些方式會給每個發到后端的請求加上這個 token,這樣就不會出現 CSRF 漏洞的問題。因為,即使有個你點擊了非法鏈接發送了請求到服務端,這個非法請求是不會攜帶 token 的,所以這個請求將是非法的。
什么是 Token?什么是 JWT?如何基于Token進行身份驗證?
我們知道 Session 信息需要保存一份在服務器端。這種方式會帶來一些麻煩,比如需要我們保證保存 Session 信息服務器的可用性、不適合移動端(依賴Cookie)等等。
有沒有一種不需要自己存放 Session 信息就能實現身份驗證的方式呢?使用 Token 即可!JWT (JSON Web Token) 就是這種方式的實現,通過這種方式服務器端就不需要保存 Session 數據了,只用在客戶端保存服務端返回給客戶的 Token 就可以了,擴展性得到提升。
JWT 本質上就一段簽名的 JSON 格式的數據。由于它是帶有簽名的,因此接收者便可以驗證它的真實性。
下面是 RFC 7519 對 JWT 做的較為正式的定義。
JSON Web Token (JWT) is a compact, URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object that is used as the payload of a JSON Web Signature (JWS) structure or as the plaintext of a JSON Web Encryption (JWE) structure, enabling the claims to be digitally signed or integrity protected with a Message Authentication Code (MAC) and/or encrypted. ——JSON Web Token (JWT)
JWT 由 3 部分構成:
Header :描述 JWT 的元數據。定義了生成簽名的算法以及 Token 的類型。 Payload(負載):用來存放實際需要傳遞的數據 Signature(簽名):服務器通過Payload、Header和一個密鑰(secret)使用 Header 里面指定的簽名算法(默認是 HMAC SHA256)生成。 在基于 Token 進行身份驗證的的應用程序中,服務器通過Payload、Header和一個密鑰(secret)創建令牌(Token)并將 Token 發送給客戶端,客戶端將 Token 保存在 Cookie 或者 localStorage 里面,以后客戶端發出的所有請求都會攜帶這個令牌。你可以把它放在 Cookie 里面自動發送,但是這樣不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization字段中:Authorization: Bearer Token。
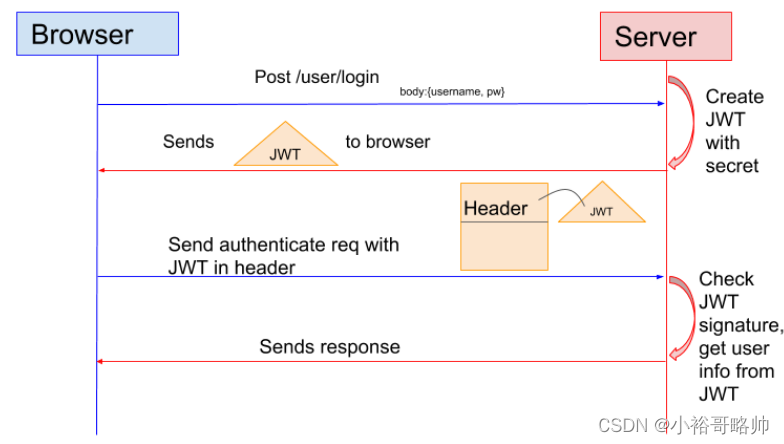
用戶向服務器發送用戶名和密碼用于登陸系統。 身份驗證服務響應并返回了簽名的 JWT,上面包含了用戶是誰的內容。 用戶以后每次向后端發請求都在Header中帶上 JWT。 服務端檢查 JWT 并從中獲取用戶相關信息。
單體架構的缺陷
好處顯而易見:通常只建立一個Project工程即可,當系統比較小時,開發、部署、測試等工作都更加簡單快捷,容易實現項目上線的目標。但隨著系統的快速迭代,就會產生一些難以調和的矛盾和發現先天的缺陷。
● 過高耦合的風險:服務越來越多,不停地變化,由于都在一個進程中,所以一個服務的失敗或移除,都將導致整個系統無法啟動或正常運行的系統性風險越來越大。
● 新語言與新技術引入的阻力:單體架構通常只使用一種開發語言,并且完全使用一種特定的框架,運行在一個進程內,從而導致新語言和新技術很難被引入。在互聯網應用時代,多語言協作開發是主流,特別是對于復雜的大系統、大平臺。各種新技術層出不窮,拒絕新技術就意味著技術上的落后,從而可能逐步被市場拋棄。
● 水平擴展的問題:單體架構從一開始就沒有考慮分布式問題,或者即使考慮了但仍然開發為單體架構,所以遇到單機性能問題時,通常難以水平擴展,往往需要推倒重來,代價比較大。
● 難以可持續發展:隨著業務范圍的快速拓展,單體架構通常難以復用原有的服務,一個新業務的上線,通常需要重新開發新服務、新接口,整個團隊長期被迫加班是必然的結果,老板則懷疑技術團隊及Leader的能力。
分布式架構下,Session 共享有什么方案?
-
不要有session:但是確實在某些場景下,是可以沒有session的,其實在很多接口類系統當中,都提倡【API無狀態服務】;也就是每一次的接口訪問,都不依賴于session、不依賴于前一次的接口訪問;
-
存入cookie中:將session存儲到cookie中,但是缺點也很明顯,例如每次請求都得帶著session,數據存儲在客戶端本地,是有風險的;
-
session同步:對個服務器之間同步session,這樣可以保證每個服務器上都有全部的session信息,不過當服務器數量比較多的時候,同步是會有延遲甚至同步失敗;
-
使用Nginx(或其他復雜均衡軟硬件)中的ip綁定策略,同一個ip只能在指定的同一個機器訪問,但是這樣做風險也比較大,而且也是去了負載均衡的意義;
-
我們現在的系統會把session放到Redis中存儲,雖然架構上變得復雜,并且需要多訪問一次Redis,但是這種方案帶來的好處也是很大的:實現session共享,可以水平擴展(增加Redis服務器),服務器重啟session不丟失(不過也要注意session在Redis中的刷新/失效機制),不僅可以跨服務器session共享,甚至可以跨平臺(例如網頁端和APP端)。
seata是什么
Seata(原名 Fescar)是一個開源的分布式事務解決方案,旨在解決分布式事務問題。Seata 提供了一套高性能、高可靠性的分布式事務服務,可以確保分布式系統中的多個微服務參與的業務操作要么全部成功,要么全部失敗(即 ACID 特性)。
Seata 的核心設計思想是將分布式事務劃分為全局事務(Global Transaction) 和分支事務(Branch Transaction)。全局事務負責協調所有分支事務的提交或回滾,從而保證分布式系統中數據的一致性。
Seata 提供了四種事務模式:
1. AT 模式(Automatic Transfer):原子操作,即自動參與式的分布式事務,需要業務代碼進行相應注解處理。
2. TCC 模式(Try-Confirm-Cancel):嘗試、確認、取消模式,需要業務代碼實現對應的 try、confirm、cancel 接口。
3. SAGA 模式:面向服務的SAGA模式,通過補償事務來確保最終一致性。
4. XA 模式:對業務支持X/Open XA接口的存儲服務。
Seata 可以與各種數據庫、消息中間件和框架集成,支持 Spring Cloud、Dubbo、RestTemplate 等常見微服務框架。通過使用 Seata,開發者可以更方便地實現分布式事務管理,確保業務數據的一致性和完整性。
總而言之,Seata 是一個功能強大的開源分布式事務解決方案,為開發者提供了可靠的手段來管理復雜的分布式事務。希望這個簡要介紹能夠幫助你了解 Seata。如果有任何進一步的問題,請隨時提出。
它如何保證分布式事務問題
Seata 通過以下機制來保證分布式事務問題:
1. **全局事務協調**:Seata 將分布式事務分為全局事務和分支事務,全局事務由事務協調器負責協調管理。事務協調器協調各個參與者的分支事務的提交和回滾,以確保全局事務的一致性。
2. **事務日志**:Seata 使用事務日志來記錄全局事務的提交和回滾狀態,以便在故障發生時進行恢復。通過日志記錄,Seata 可以保證全局事務的狀態可追溯和一致性。
3. **分布式事務補償**:
? ?- **TCC 模式**:利用 "Try-Confirm-Cancel" 模式,Seata 要求業務需要實現 try、confirm、cancel 三個接口來實現分布式事務的嘗試、確認和取消操作,以確保最終一致性。
? ?- **SAGA 模式**:SAGA 模式通過一系列的補償事務來確保最終一致性,即在出現異常情況時,通過執行逆向操作來補償前一步操作,從而保證數據的完整性。
4. **分支事務超時機制**:Seata 支持配置全局事務和分支事務的超時時間,確保在一定時間內能夠正常完成事務提交或回滾,避免懸掛事務。
5. **可靠性設計**:Seata 各個組件的設計考慮了高可用和容錯性,例如注冊中心采用高可用的方式部署,事務協調器具備集群和故障轉移能力。
通過以上機制和設計,Seata 能夠有效保證分布式事務的一致性和可靠性,解決了跨多個微服務的業務操作中可能出現的分布式事務問題。開發者可以利用 Seata 提供的各種模式和機制來管理分布式事務,確保各個微服務節點之間的數據操作符合 ACID 特性。希望這些信息能幫助你理解 Seata 是如何保證分布式事務問題的。如果還有其他問題,請隨時提出。





)
學習)










)

