文章目錄
- 0. Contents
- 1. Multi-Agent Path Finding (MAPF)
- 1.1 HCA*
- 1.2 Single-Agent A*
- 1.3 ID
- 1.4 M*
- 1.5 Conflict-Based Search(CBS)
- 1.6 ECBS
- 1.6.1 heuristics
- 1.6.2 Focal Search
- 2. Velocity Obstacle (VO,速度障礙物)
- 2.1 VO
- 2.2. RVO
- 2.3 ORCA
- 3. Flocking model(群落模型)
- 4. Trajectory Planning for Swarms(集群軌跡規劃)
- 4.1 Background
- 4.2 Methods
- 4.2.1 Search/Sampling Based
- 4.2.2 Optimization Based
- 4.2.2.1 Formulation
- 4.2.2.2 Solving
- 5. Formation(編隊)
- 5.1 Preliminary
- 5.2 Consensus-based Control(基于共識的控制)
- 5.3 Potential Field
- 5.4 Shape Vector
- 5.5 Formation Rearrangement
- 5.6 Similarity Metric(相似性度量)
- 6. Summary
- X. Reference
0. Contents

1. Multi-Agent Path Finding (MAPF)
本節主要講解多智能體路徑規劃,轉化為圖搜索問題進行求解。

主要是考慮固定節點和圖上的路徑規劃問題。
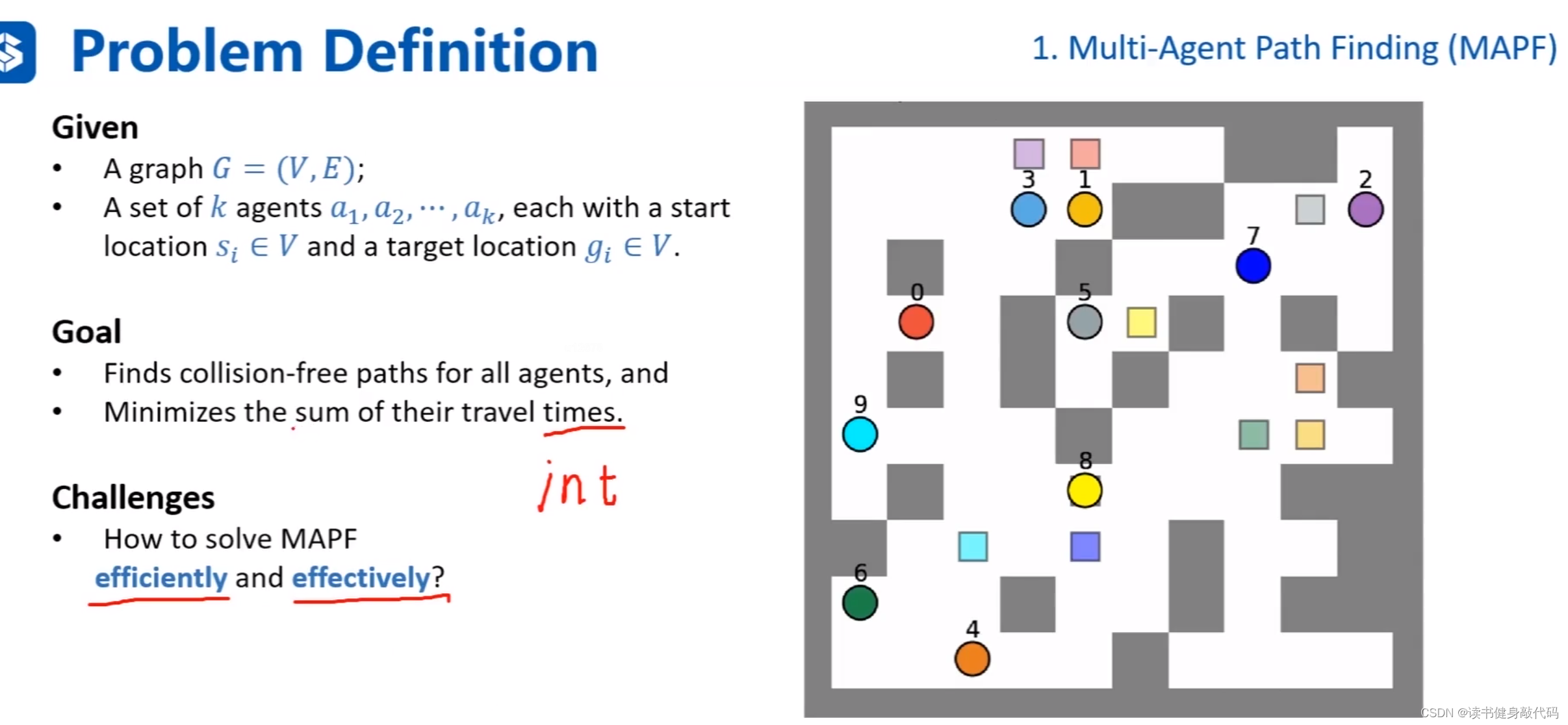
課程中的agents和robotics所指相同。
Givens:一張地圖和圖上的節點。
Goal:尋找到所有agents的路徑,并且最小化cost
times指的就是cost,如果是one-unit grid map,則這種times一般是整數,如果類似于或者時刻表規劃,則可能是double。
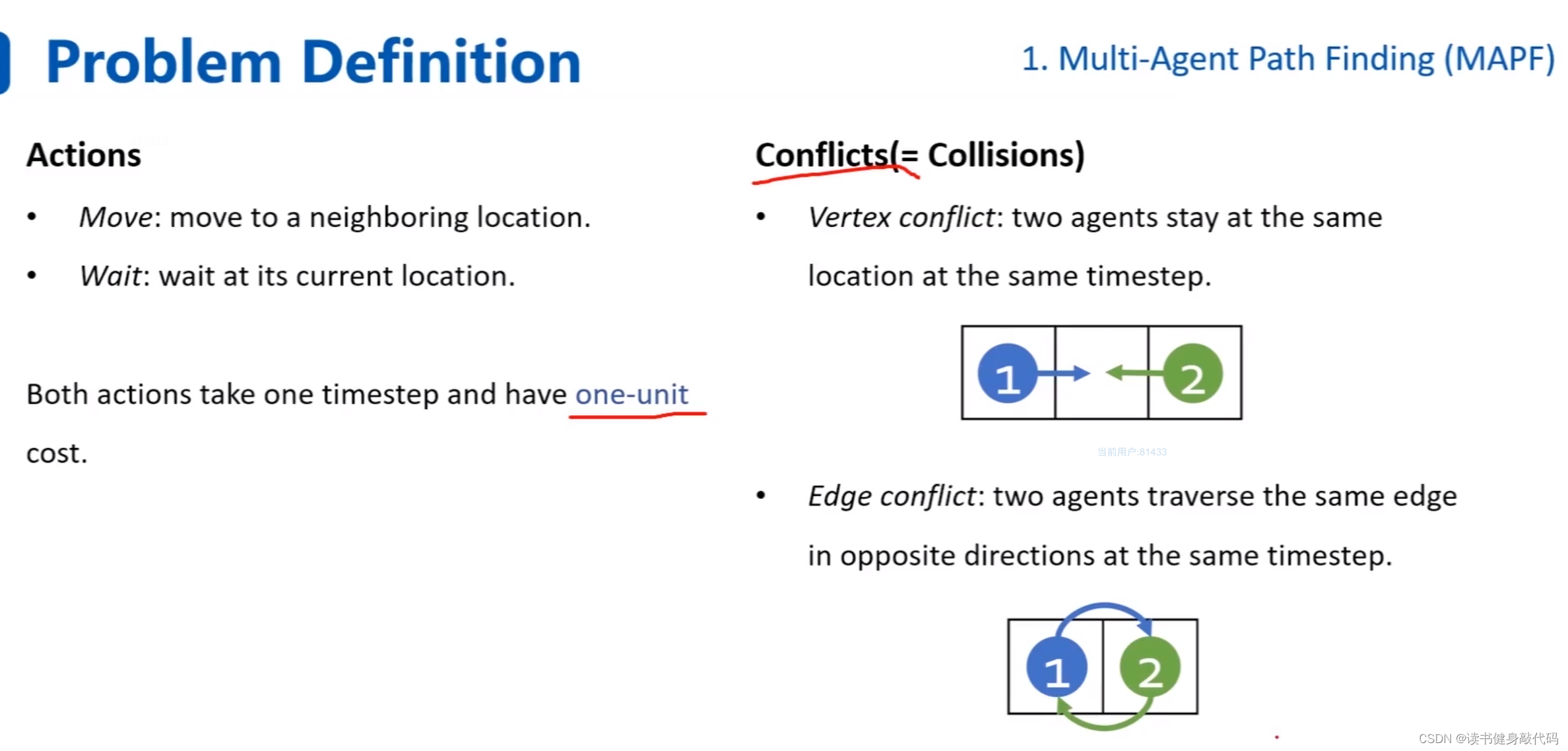
定義動作:移動,等待。
沖突:1. 頂點沖突同時想進入同一個grid,2. 邊沖突:兩個agents同時以相反的方向通過同一條邊。(即想交換位置)。
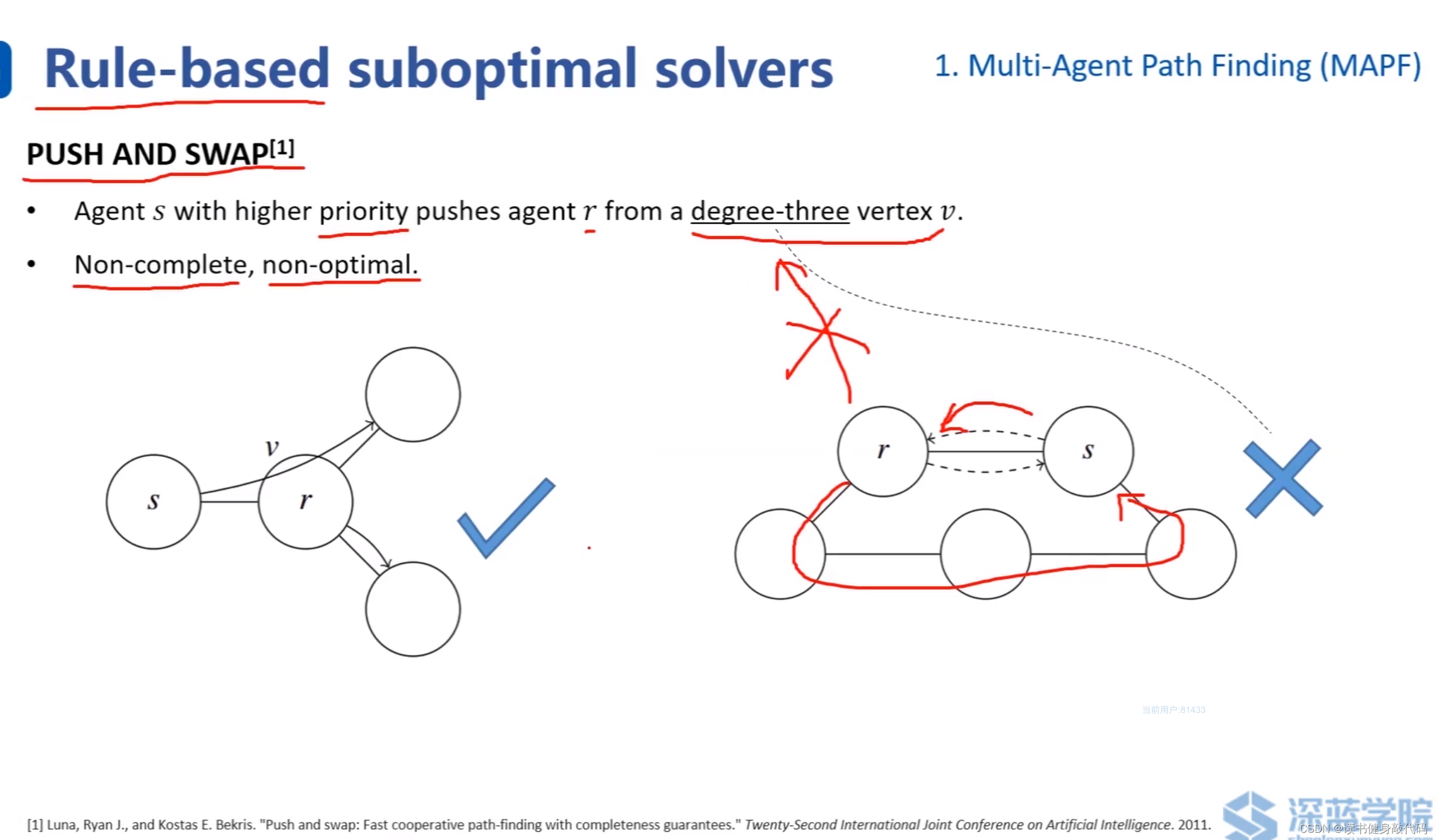
一些人工定義的規則:
最著名的是:push and swap, ref[1]
push:優先級高的可以推開優先級低的節點,低的節點度必須 ≥ 3 \geq 3 ≥3(即連接低優先級的邊不少于3條)。上左 s s s優先級高于 r r r,要去右上角的節點,可以把r往右下推開,然后經過 r r r的原有位置,到達右上。
人工定義的規則較難適應真實的復雜場景,會出現non-complete(找不到解)和non-optimal(解不是最優)的情況。
complete:如果解存在,那么一定可以找到一個解。
optimal:如果有多個解存在,可以找到全局cost最低的那個。
1.1 HCA*
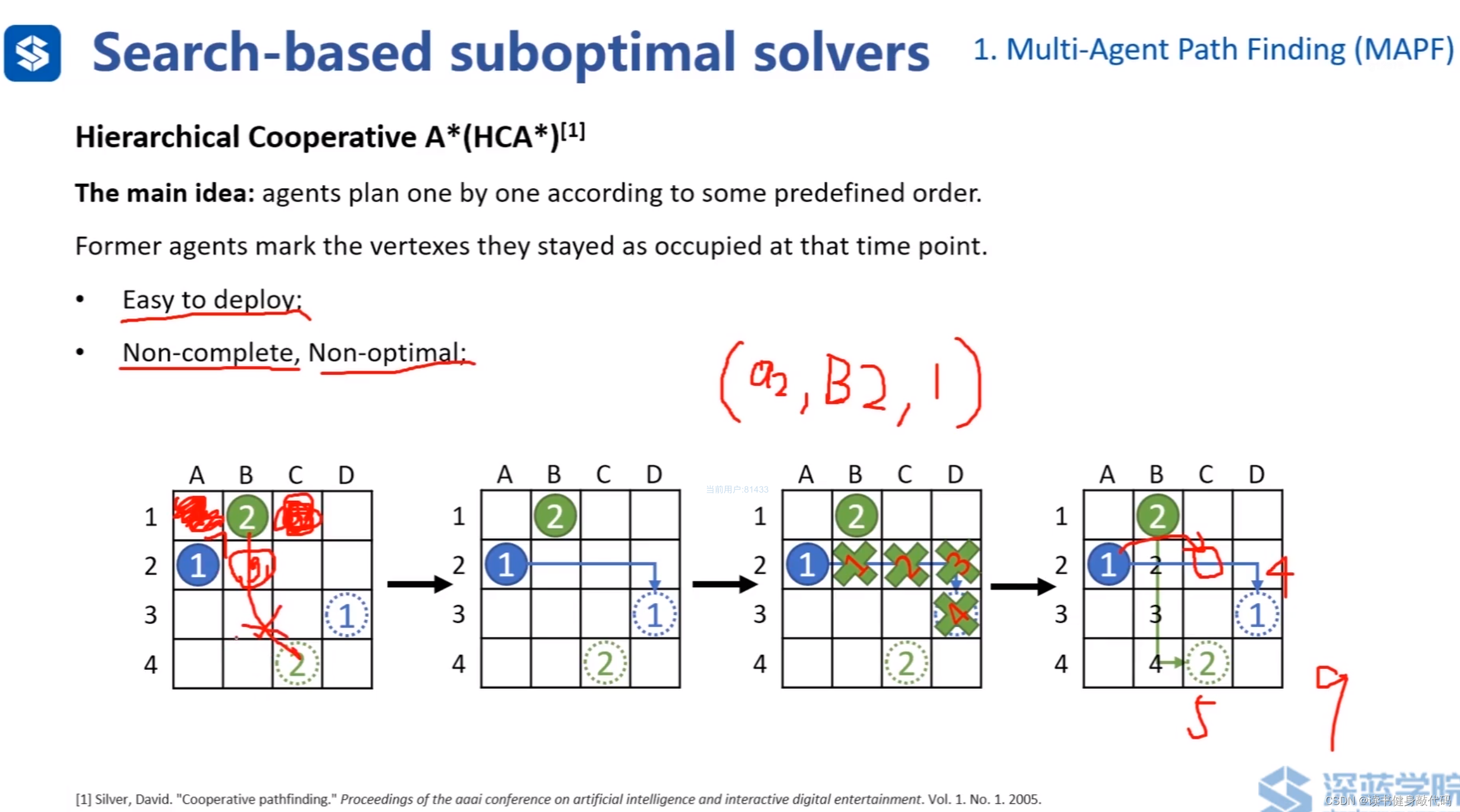
基于搜索的suboptimal solvers:HCA*(層次化合作A*),ref[2]。
高優先級agent在規劃時無需考慮低優先級的agent,反之,低優先級在規劃時需要考慮高優先級agent的存在。
上圖①比②優先級高,①先規劃出路徑,為了避免碰撞,①的路徑在②在規劃時對②產生了如第3個圖所示的約束,分別表示②在第1,2,3,4時刻不能在該處,以第1時刻的約束為例: ( a 2 , B 2 , 1 ) (a_2,B_2,1) (a2?,B2?,1)代表是對 a g e n t 2 agent_2 agent2?的,在 B _ 2 B\_2 B_2格子的,在1時刻的約束。該表示法后面會用到。
上例最終時間cost:①4單位+②5單位=9單位
HCA* pros:容易實施,在傳統A*的collision check中添加對其他agent的判斷即可。
cons:Non-complete, Non-optimal。如上第1個圖所示,若②左右均為障礙物,在第1時刻,①位于 B _ 2 B\_2 B_2格子,此時②找不到解,所以non-complete。
1.2 Single-Agent A*
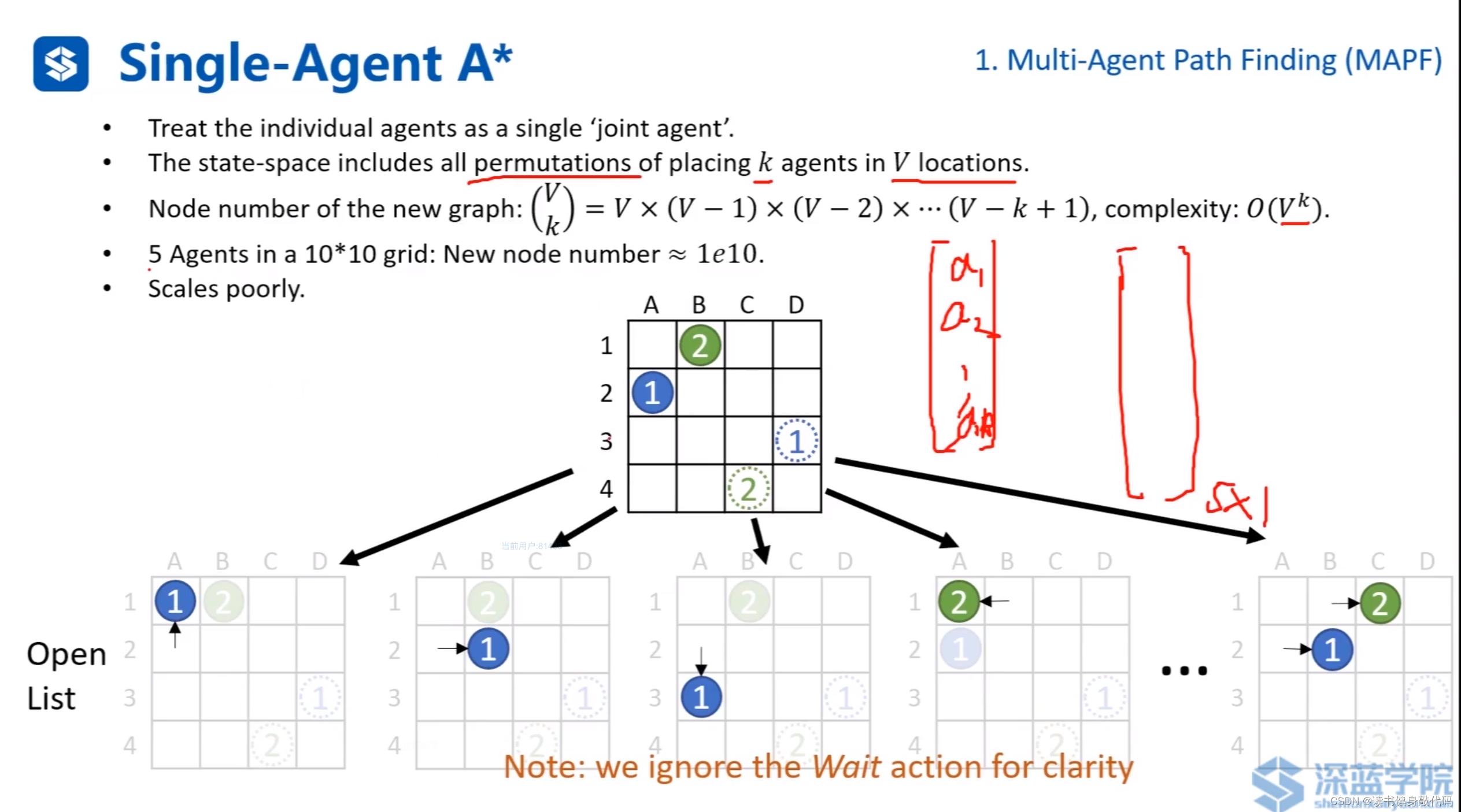
基于A* 的更加完備和最優的算法:Single-Agent A*。
把每個agent看做一個聯合agent,構造k個agents的V個位置的狀態空間的排列組合,復雜度為 O ( V k ) O(V^k) O(Vk),比如:①往任一可行方向單獨移動一格為一個狀態,②也是,①②同時往任一方向移動一格也是一個狀態…對所有agent都使用這樣的排列組合,最終構成大向量。
顯然這種方法復雜度非常高,大規模問題無法使用。
1.3 ID

ref[3] 每個agent當做一個單獨的group,各自找自己的最優路徑,如果發生碰撞,嘗試找相同cost的不碰撞的path,如果找不到,則將發生碰撞的兩個agents則合并為一個group,然后使用Single-Agent A*。
ID算法的思想和之前PRM的lazy collision checking有些類似,先搜出一條path,然后對path進行collision checking。
Independence Detection (ID)仍然是完備且最優的。
1.4 M*
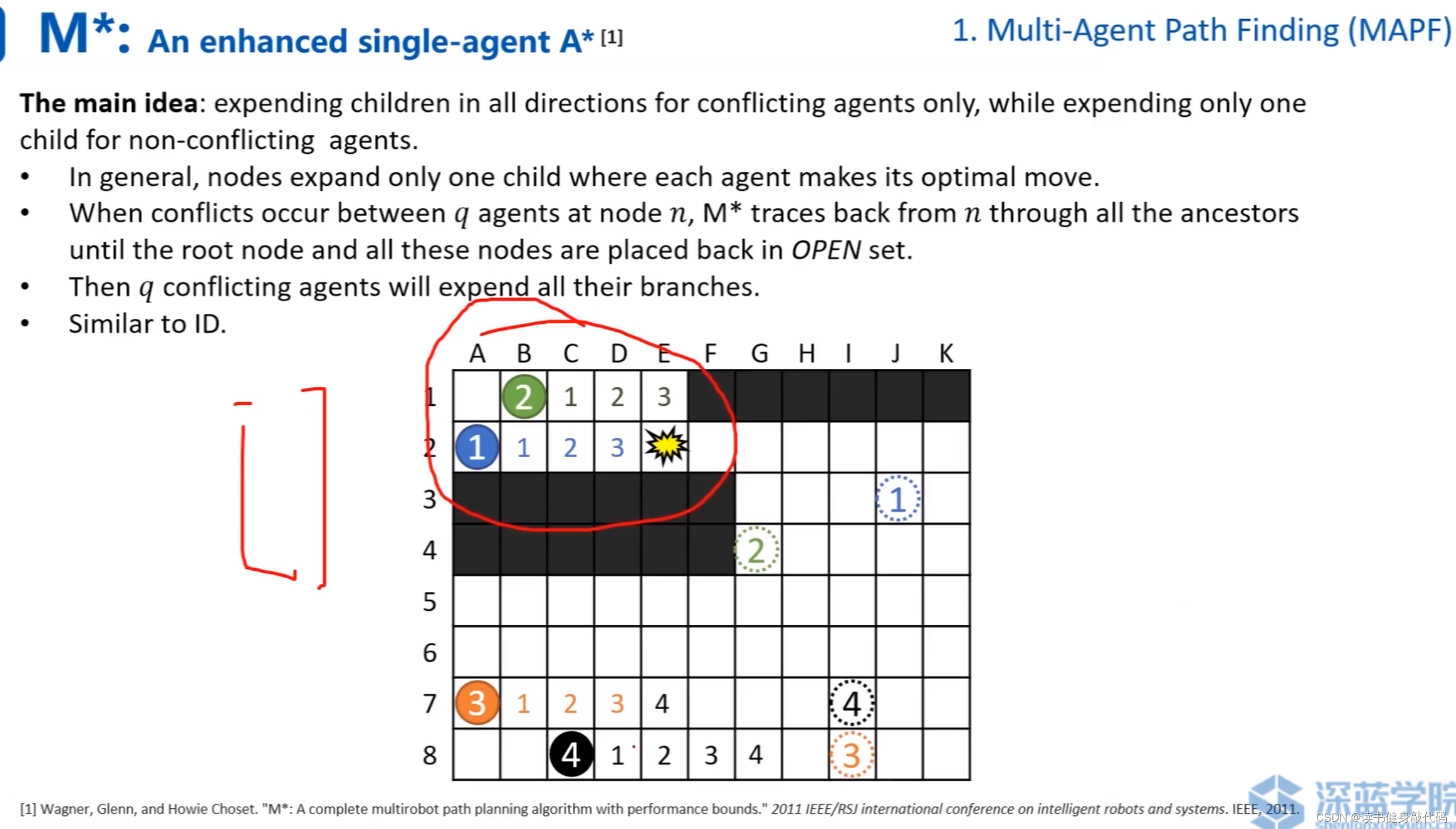
M*(ref [4])相對于ID的改進:在每個group單獨進行搜索時,邊搜邊進行collision checking,發現collision時,將group進行合并。
1.5 Conflict-Based Search(CBS)
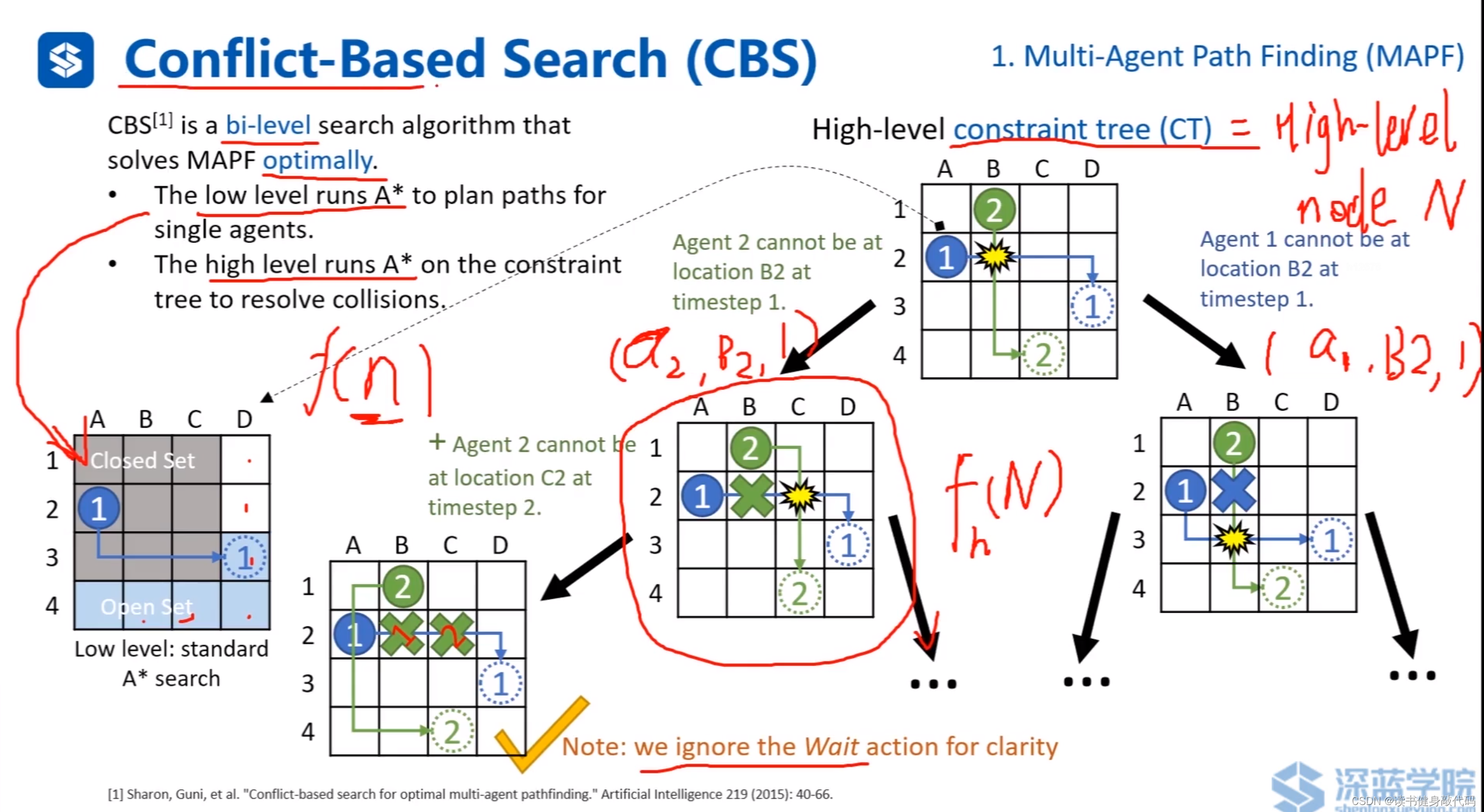
CBS是雙層次的A*(ref [5]),low level A*對每個agent進行搜索,遇到conflict時,進行high level的搜索,讓碰撞的兩個agent分別通過碰撞點,衍生出兩個case,在兩個case中繼續進行拓展,重復此步驟,如此產生的樹結構稱為constaint tree(CT)。
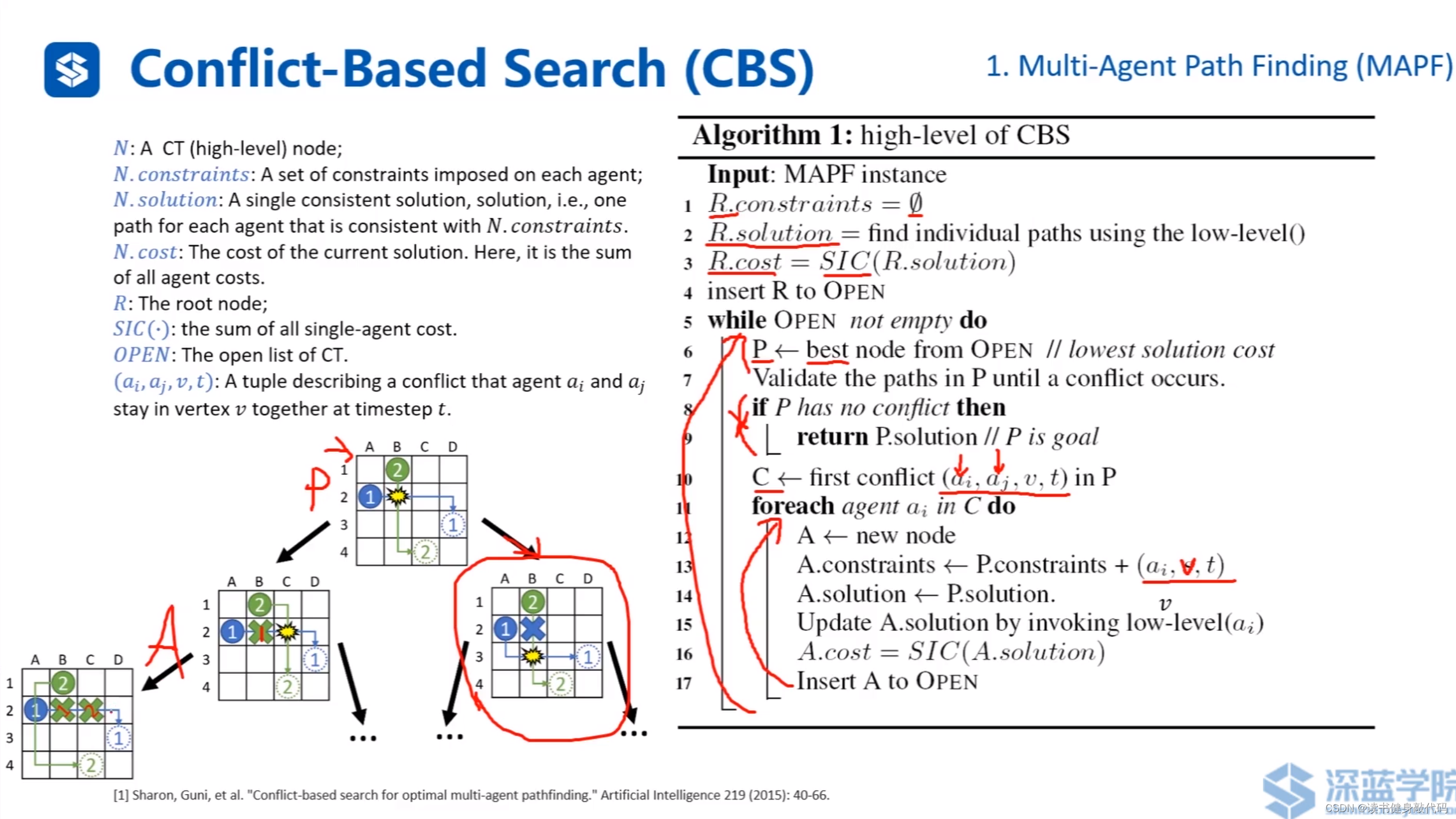
CBS的具體算法流程。
R R R:根節點,開始時約束為空。
對所有agent進行low-level的A*
算出當前的cost
把 R R R insert 到open-set中
while open-set非空:
在open-set中找cost最低的node
如果發生碰撞且所有agent均到達自己的目標節點,
返回 目標節點。
如果在P中是首次碰撞,則加入到碰撞集中
遍歷碰撞集每個agnet:
分別對另一個agent施加約束,并對其進行low-level A*,更新cost,并加入到open-set中
1.6 ECBS

上面講的方法均可以歸類到optimal solvers或suboptimal solvers中,在二者中間還存在一種bounded suboptimal solvers,它的cost不是最優的 C ? C^* C?,但是小于其上界 ω C ? ( ω > 1 ) \omega C^*(\omega>1) ωC?(ω>1)。接下來講解一種方法:ECBS。而BCBS更多的意義是為了推導ECBS。
1.6.1 heuristics
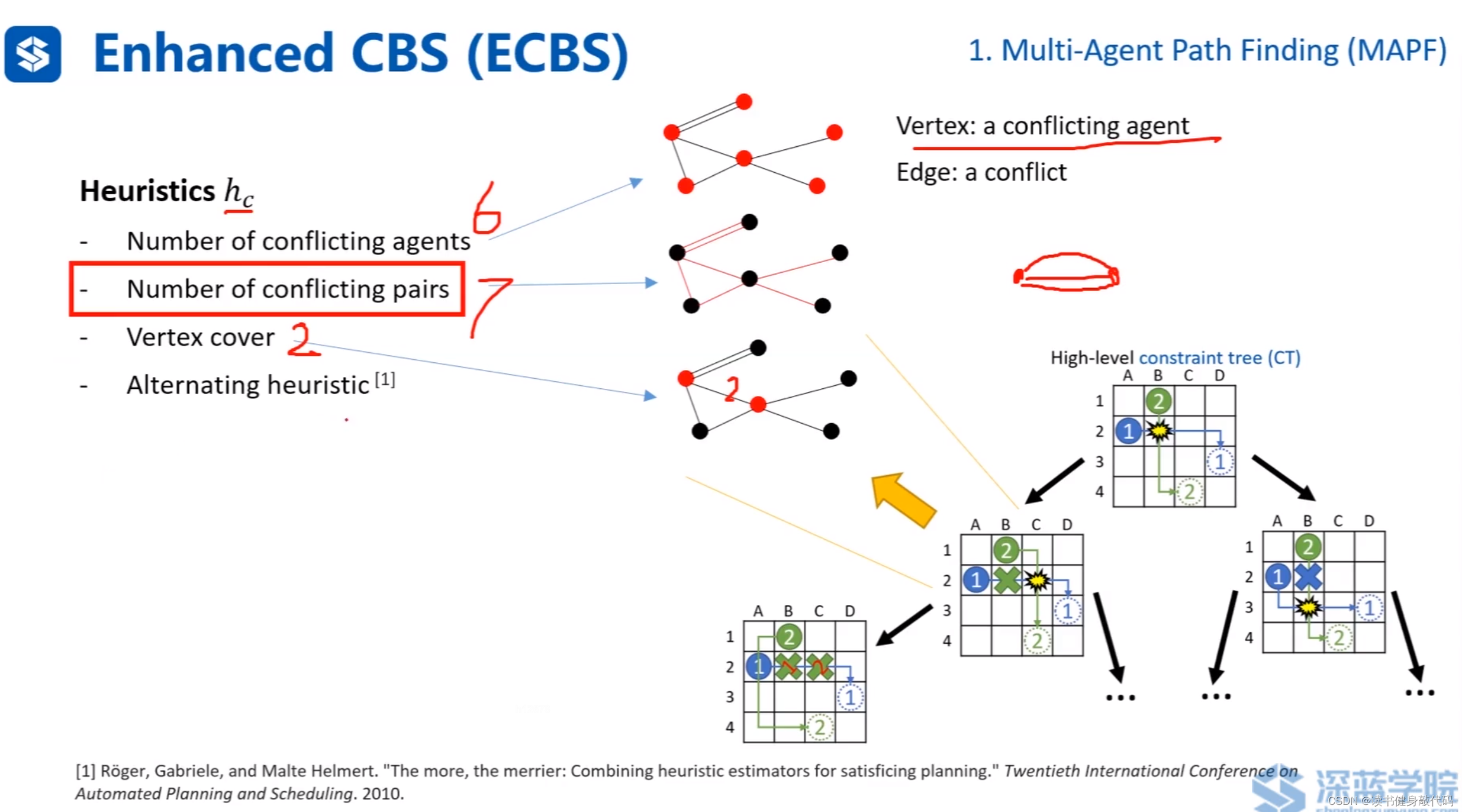
與A* 中構造heuristic的構造方式不同,這里引入碰撞圖的概念,
碰撞圖中,每個節點代表發生碰撞的agent,每條邊代表這兩個agent發生了一次碰撞。
有幾種heuristics(ref[6]):
- 發生碰撞的agents的數量(上例為6)
- 碰撞的次數(邊的條數,上例為7)
- vertex cover:碰撞圖中的每個節點都至少與選擇的節點有連接邊(上例為2個)
- 上面幾種heuristics交替使用
1.6.2 Focal Search
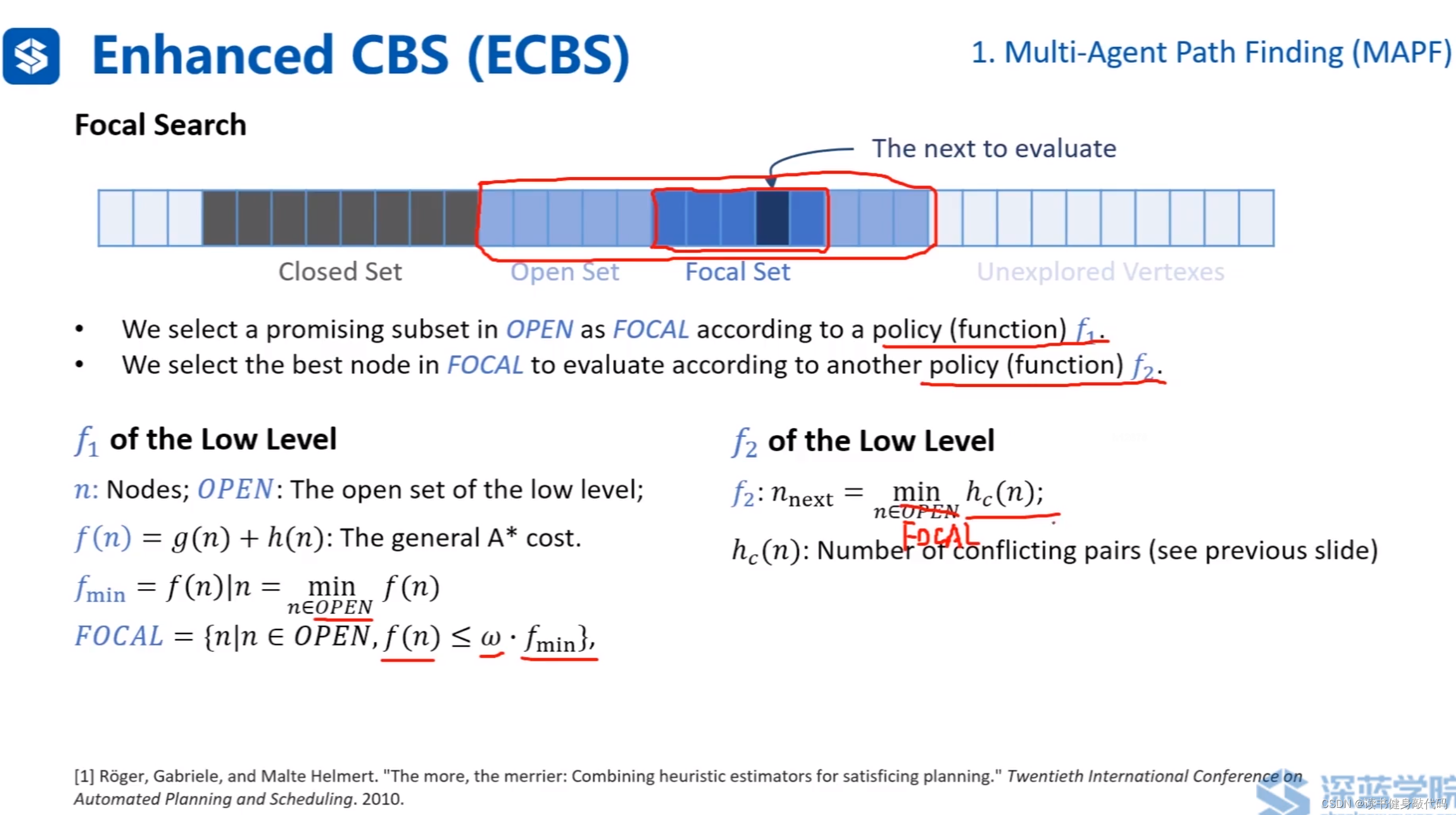

在open set中利用policy function f 1 f_1 f1?(一個規則)選擇一個子集Focal set,再使用policy function f 2 f_2 f2?(另一個規則)選擇一個node進行下一次evaluate。(對應到A*中,在open set中直接選擇cost最小的進行evaluate,這里定義了兩個選擇規則)。
分low-level和high-level講解:
- low-level的選取:
f 1 \bm{f_1} f1?:按照A*算法 f = g + h f=g+h f=g+h計算 f f f,在open set中取 f f f最小的node對應的cost f m i n f_{min} fmin?,將open set中cost小于 ω f m i n \omega f_{min} ωfmin?的node取出來,作為FOCAL集。
f 2 \bm{f_2} f2?:在FOCAL集內,按照1.6.1節選取的heuristics方法計算heuristics h c ( n ) h_c(n) hc?(n)
- high-level選取:
high-level就是針對發生碰撞的nodes組成的group。
f 1 \bm{f_1} f1?:由于high-level每個node對應很多agent,每個node都有自己的 f m i n f_{min} fmin?。
對每個node內的所有agent的 f m i n f_{min} fmin?求和, L B LB LB指和最小的high-level的node, L B ( N ) LB(N) LB(N)是對應的最小和。
high-level的FOCAL就是open-set中滿足 N . c o s t ≤ ω L B N.cost\leq \omega \bm{LB} N.cost≤ωLB的所有high-level node。
f 2 \bm{f_2} f2?:在high-level的FOCAL中取heuristics最小的high-level node。
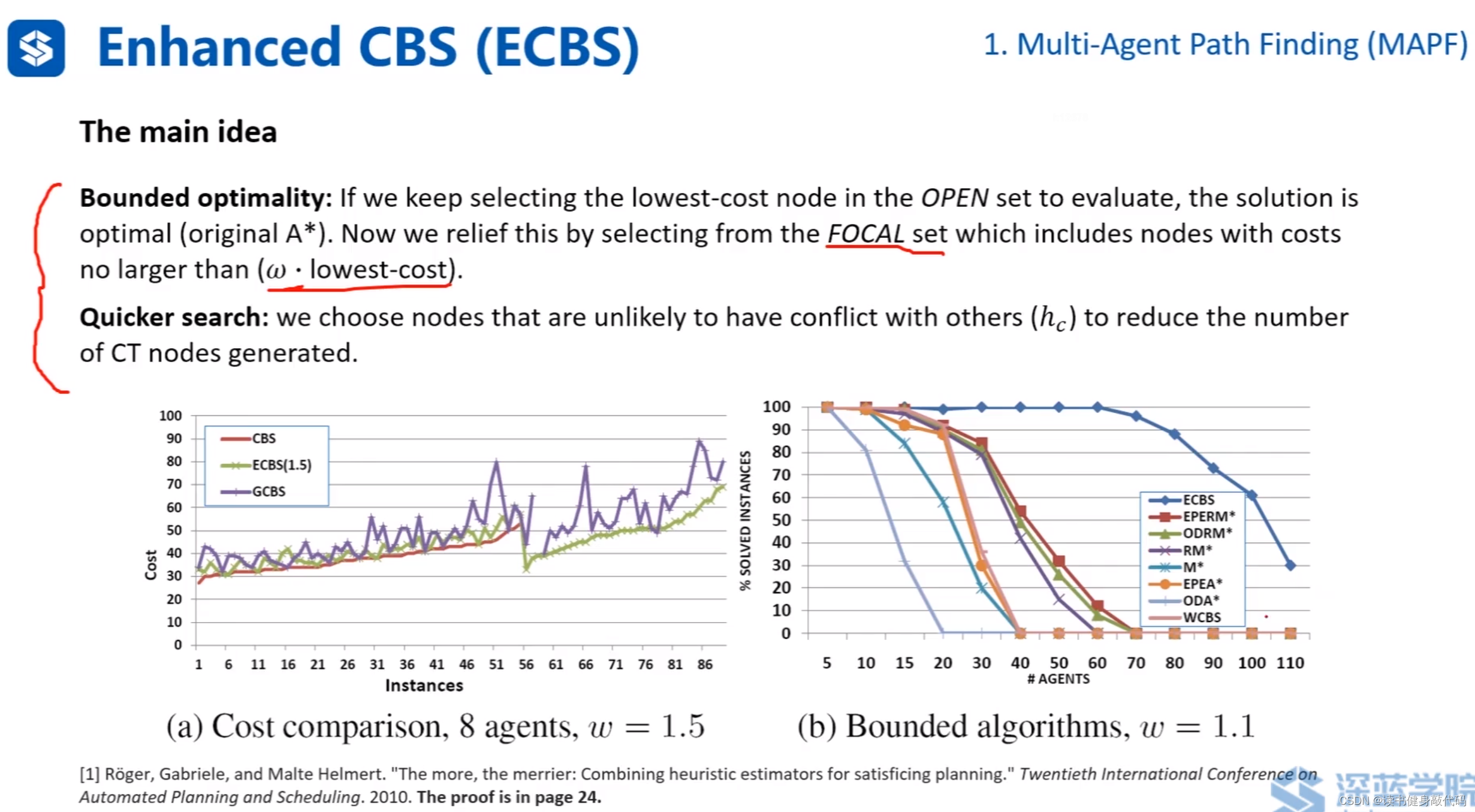
ECBS的main idea:
- relief搜索的條件,不僅僅找 f m i n f_{min} fmin?的node,而是以 f m i n f_{min} fmin?框定一個范圍,在該范圍內搜索能保證bounded optimality.
- 在FOCAL中進行擴展,由于選擇的是碰撞較少的節點進行擴展,縮小了擴展節點所帶來的新的碰撞節點的產生,降低了潛在擴展次數,加快了搜索。
實驗表明ECBS的cost和CBS(最優)的cost較為接近,且搜索較快。
2. Velocity Obstacle (VO,速度障礙物)
2.1 VO
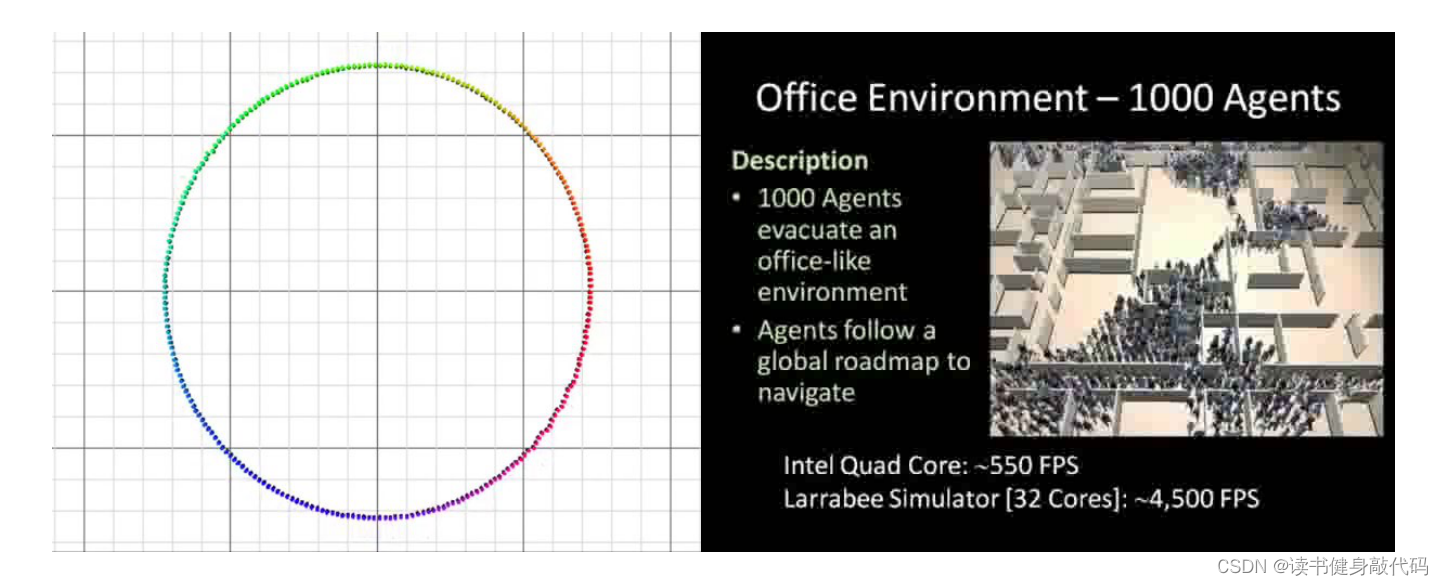
VO的仿真實驗:智能體排成圓和1000個智能體從辦公室場景撤退。

上個世紀提出VO(ref[7]),后來RVO(ref[8]),ORCA(ref[9])對VO進行了改進。
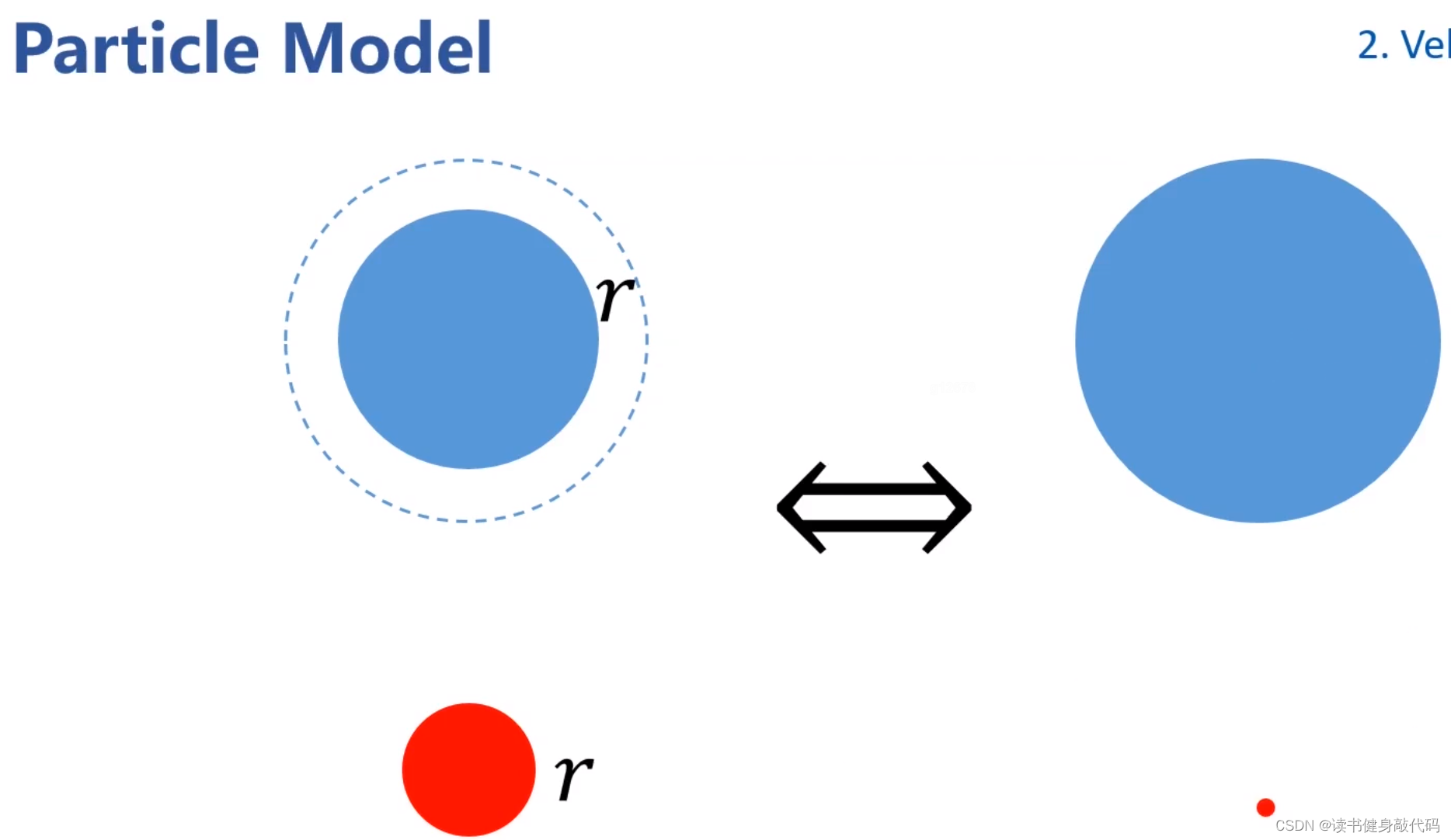
將機器人質點化,對障礙物進行膨脹。
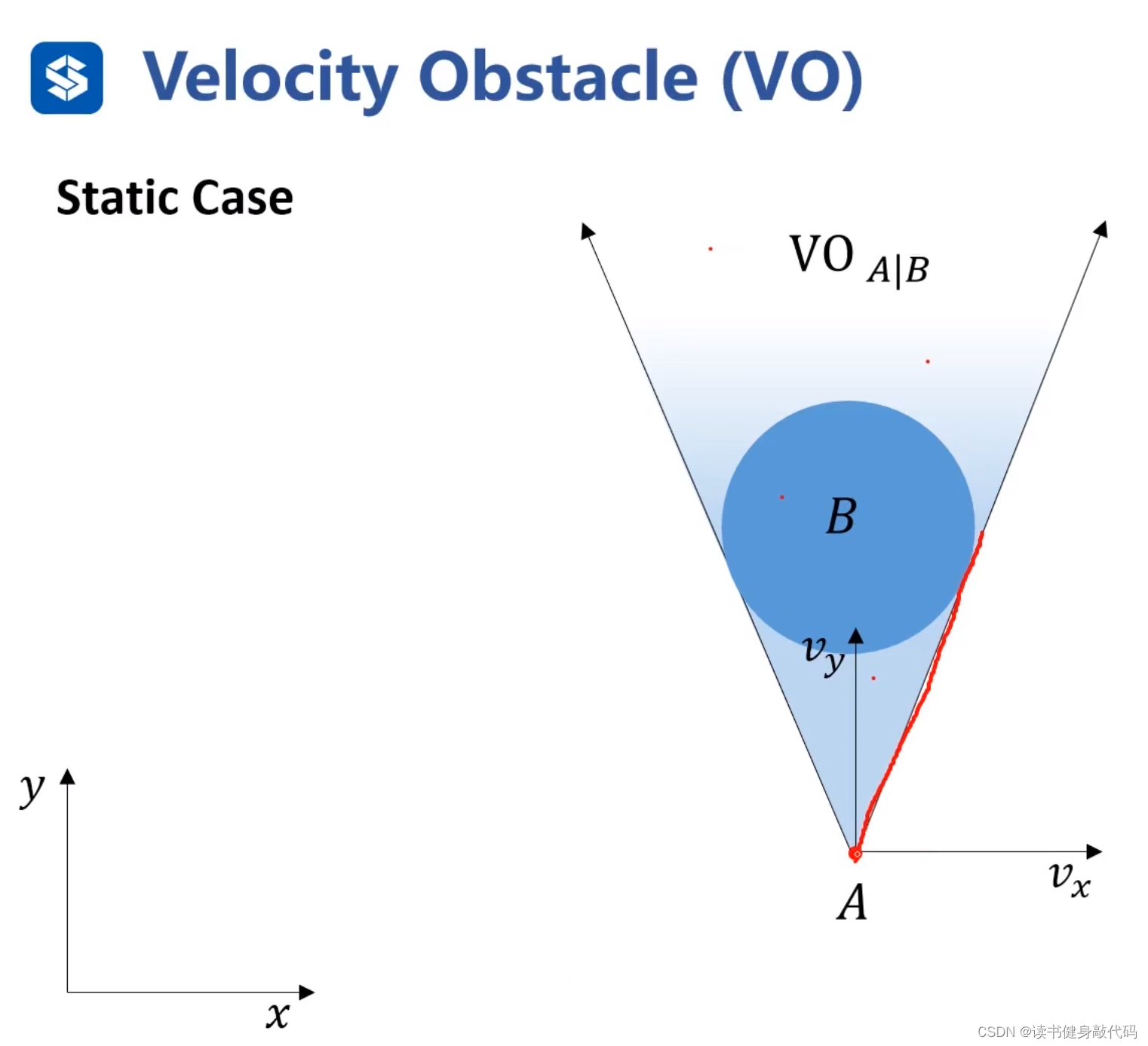
靜態情況(障礙物不動):
速度取在扇形區域內時會撞到障礙物,所以扇形區域就是VO。 V O A ∣ B VO_{A|B} VOA∣B?是 B B B相對于 A A A的速度障礙物。VO區域是定義在速度空間內的區域,在該區域內的速度會撞到障礙物。速度空間的障礙物,所以叫速度障礙物。速度坐標系和位置坐標系是畫在同一個平面的,速度坐標系的原點是agent所處的位置,而位置坐標系原點不一定與速度坐標系相同。
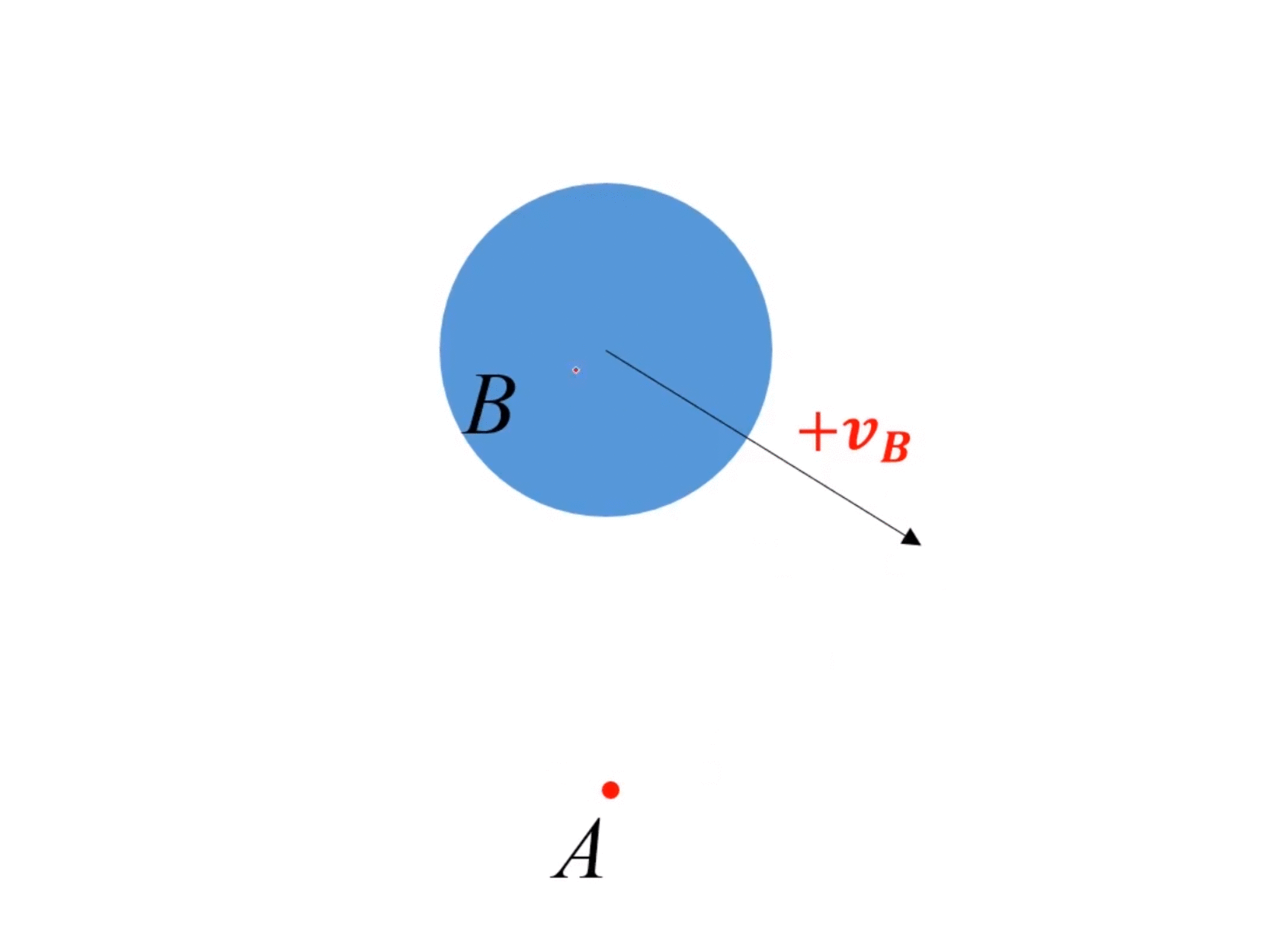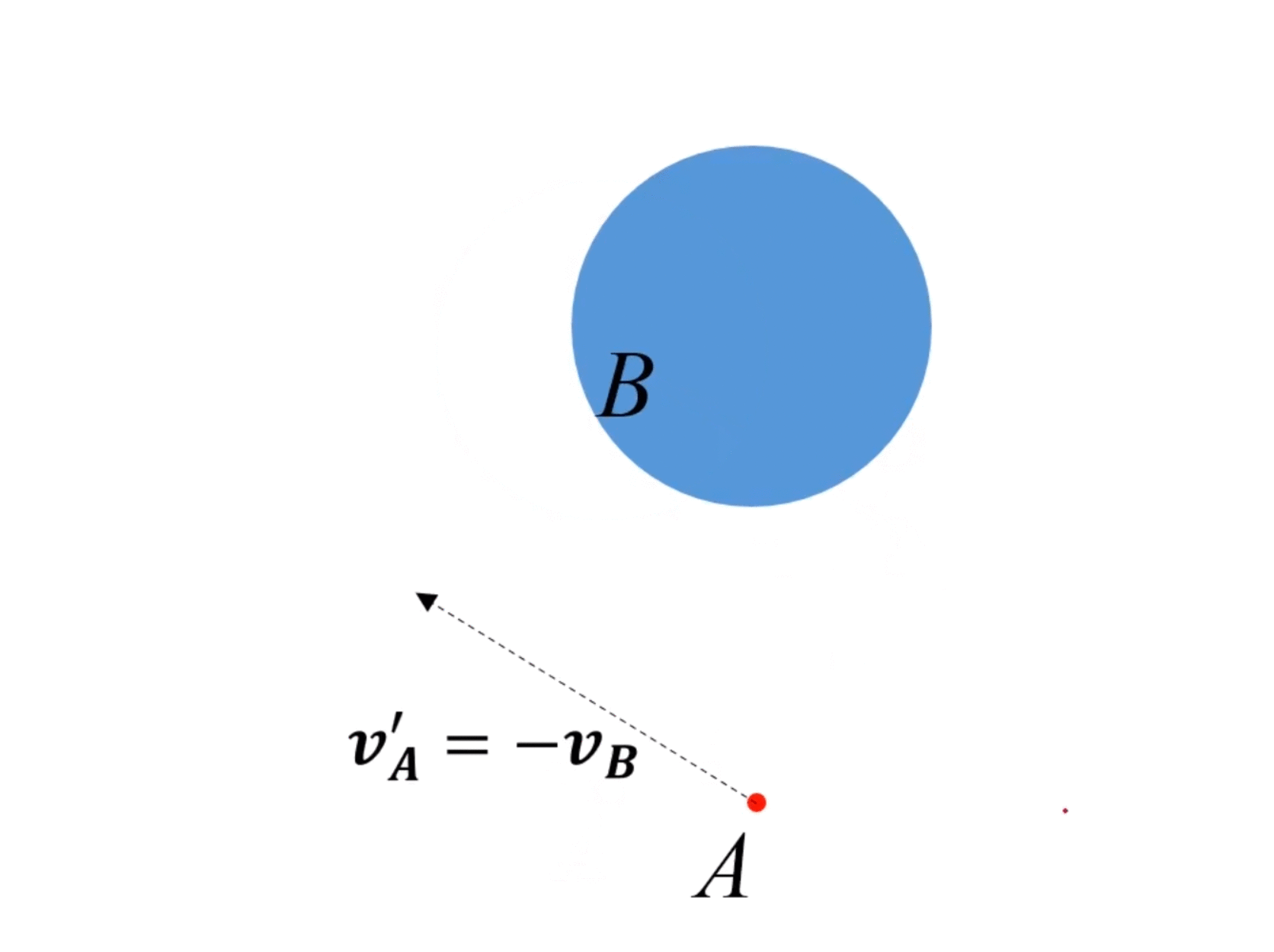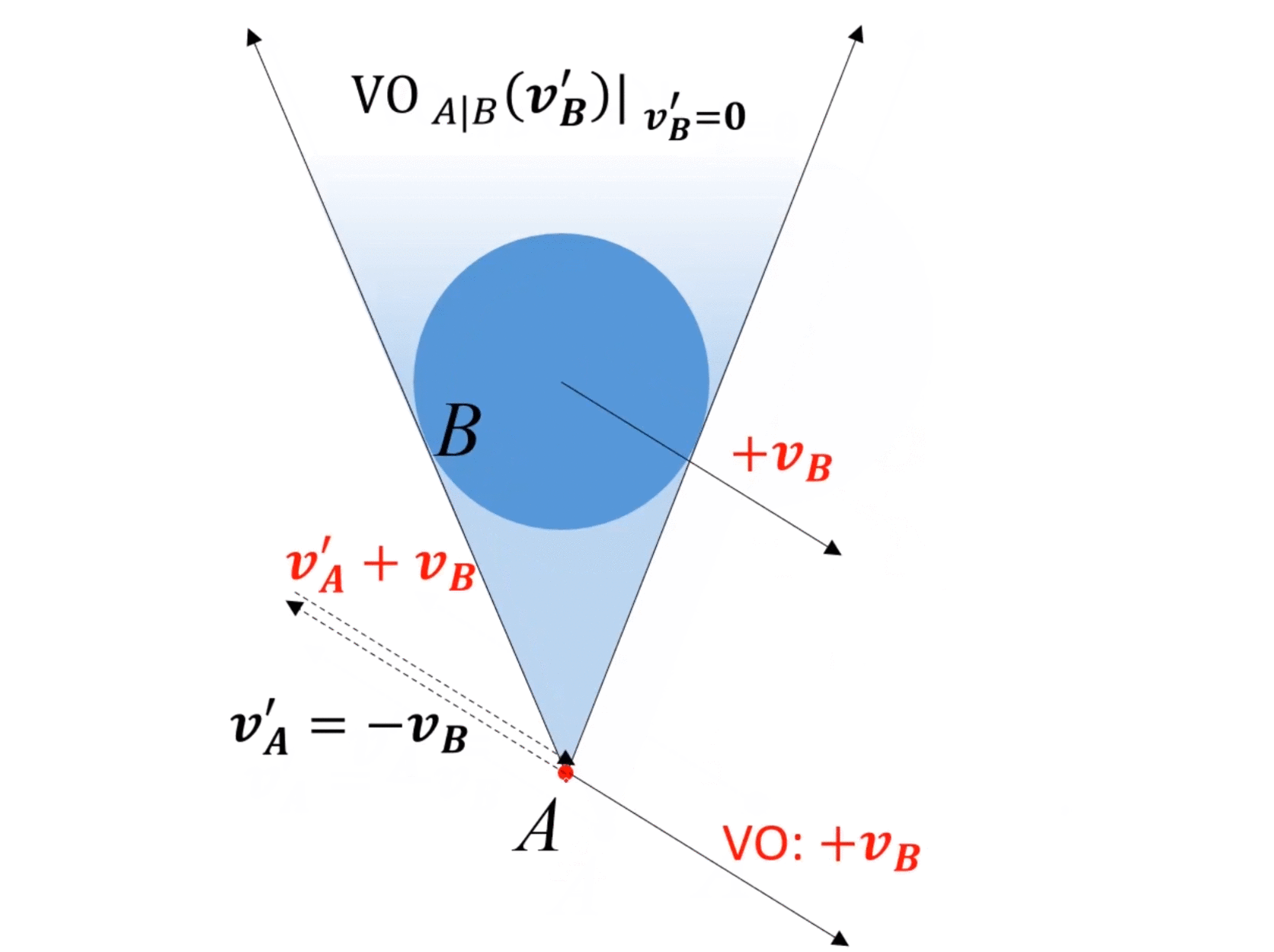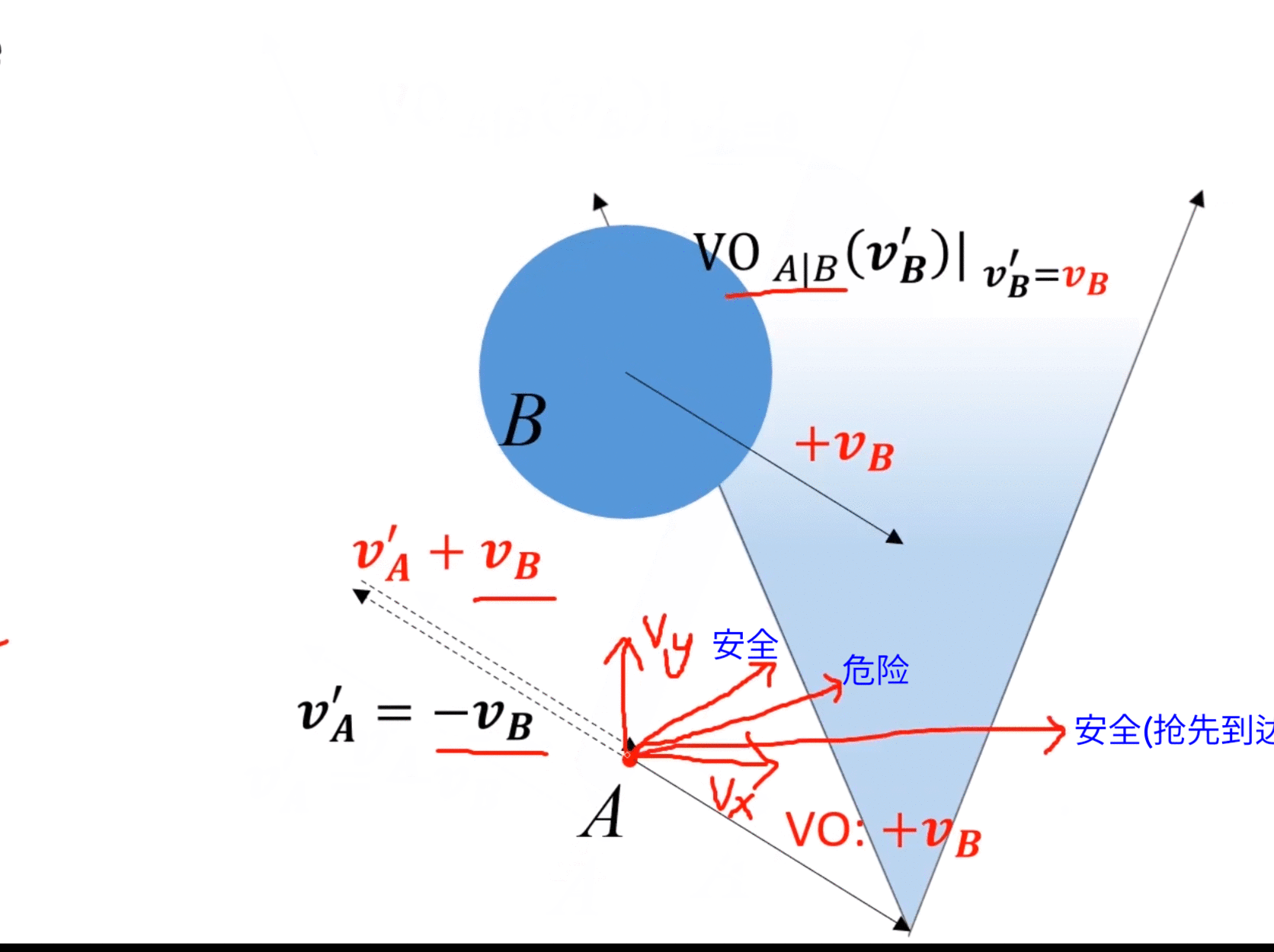
動態情況(障礙物運動):
- 假設障礙物 B B B速度為 v B v_B vB?,那么等價于速度系內所有其他對象的速度都是 ? v B -v_B ?vB?。
- 因為速度是相對的,所以在速度系內,對所有對象速度都加 v B v_B vB?,所有對象速度不變。
- 但是在速度系內,VO的位置發生改變,變到 v B v_B vB?的速度終點。
- 對于新的VO,如果A的速度終點在VO內,則會發生碰撞,否則是安全。
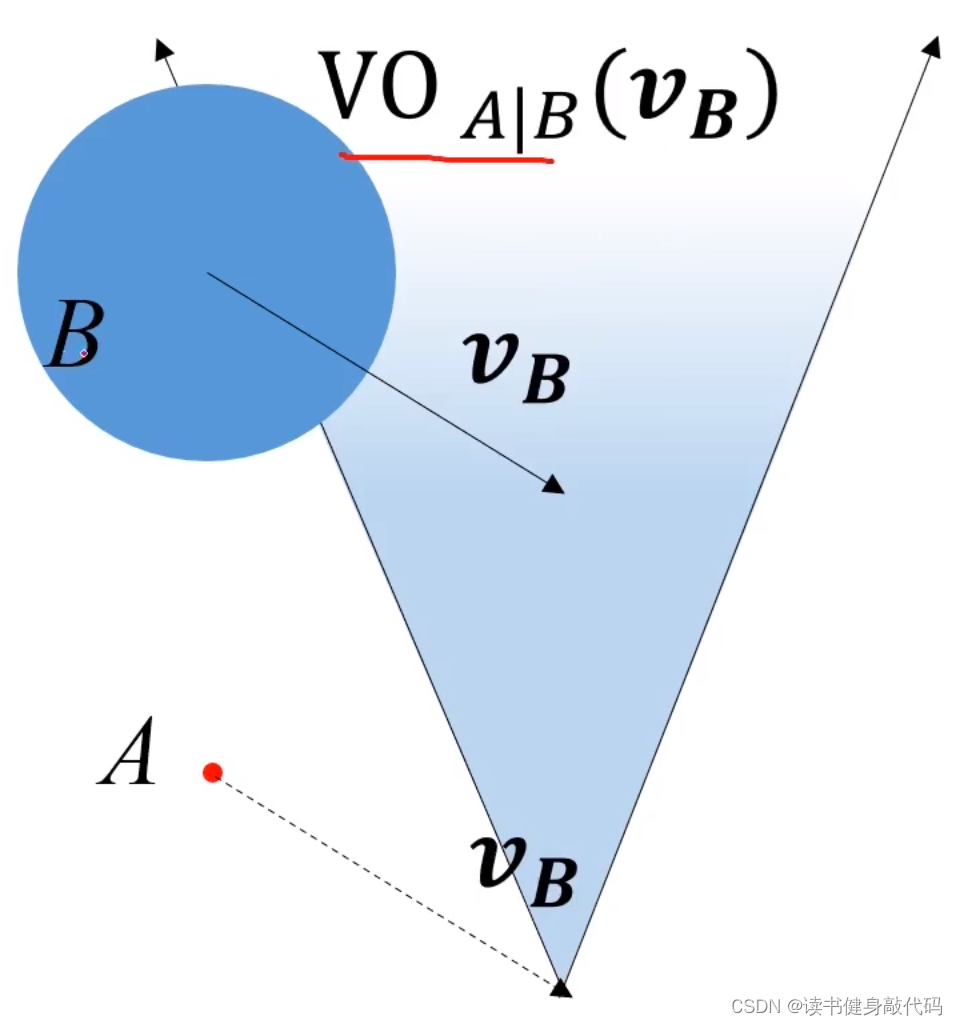
實際情況中可直接將 v B v_B vB?平移至A,然后做VO區域 V O A ∣ B ( v B ) VO_{A|B}(\bm{v_B}) VOA∣B?(vB?),即B相對于A的,與 v B \bm{v_B} vB?相關的VO區域。
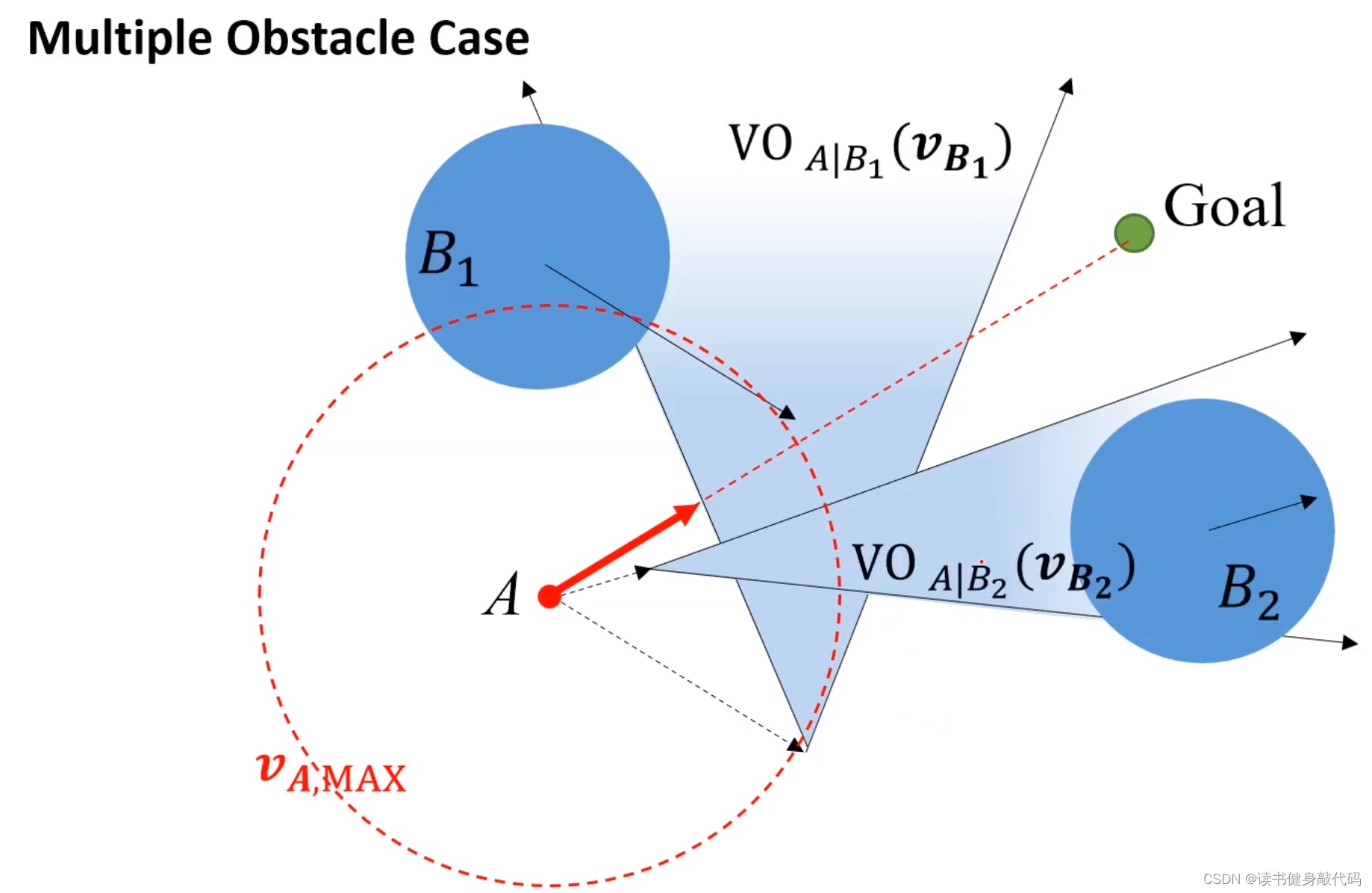
多障礙物情況:
對多個障礙物的速度做平移和各自的VO區域,只要A的速度終點不落在這些VO區域的并集內則為安全,如果考慮上圖所示的A的最大速度范圍,為了到達Goal,選擇紅色實線箭頭的速度最佳。
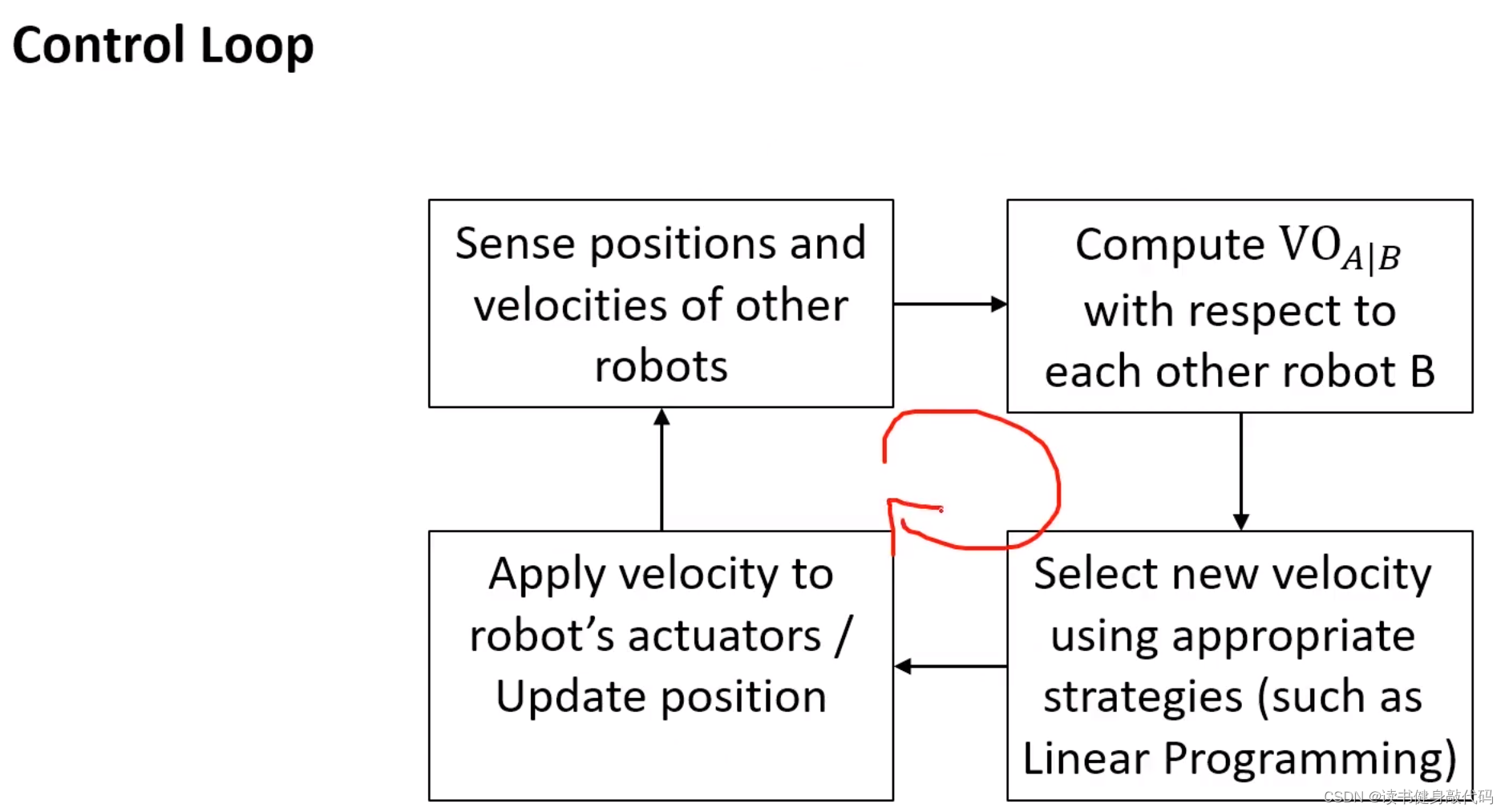
VO實際使用時的控制回路:
- agents廣播各自的速度和位置
- 各個VO計算其他agents相對于自己的 V O A ∣ B VO_{A|B} VOA∣B?(對于自己來說,其他的agents都是障礙物)
- 使用合適的策略選擇速度
- 自己執行該速度,更新狀態
2.2. RVO

“Reciprocal” 這個詞可以根據不同的語境有多種意思。
- 在數學和工程學中,它通常指的是倒數,即一個數與它的乘積等于1的另一個數。
- 在人際交往或社會科學中,“reciprocal” 描述的是互相交換的、相互的行為或關系,比如說,“reciprocal agreement”(相互協議)指的是兩方都有給予和接受的協議。
在“Reciprocal Avoidance”這個詞組可以翻譯為“相互避讓”或“互避”。“reciprocal” 通常指的是雙向的或者相互的行動,意味著每個個體都在考慮對方的動作來調整自己的行為,以此實現共同的目標,比如避免碰撞。
VO會存在軌跡zigzag的現象,因為軌跡在下個不考慮其他agents的速度,為了解決這個問題,提出了RVO
(ref[8])
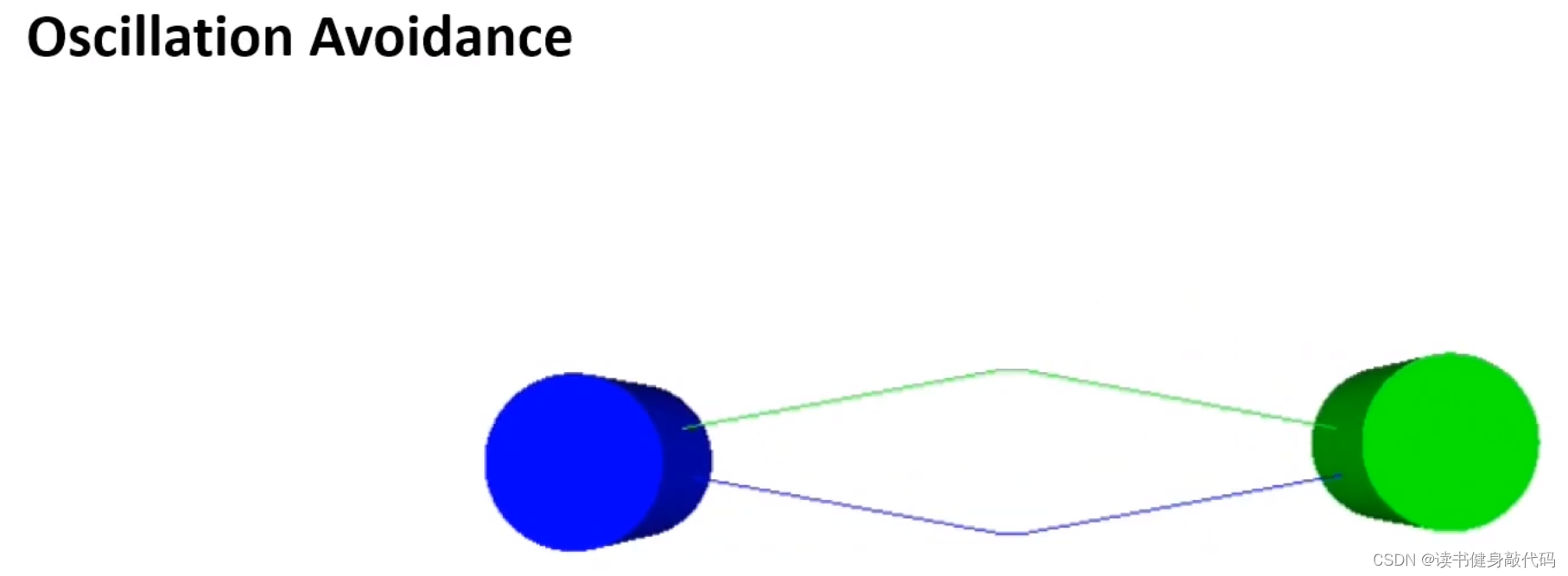
RVO比VO順滑很多。
更加直觀的例子。

main idea:兩個agents都運動,都相互避讓,本來避讓一個身位即可完成避障,但是由于對方也在避障,所以總共避障了2個身位,相對了調整2個身位,調整較大,造成了zigzag。如果每個agents只調整半個身位(或者不嚴格一半,但二者加起來為一個身位),則也可完成避障,于是就有了下圖所示的“共同承擔避障責任”的RVO。
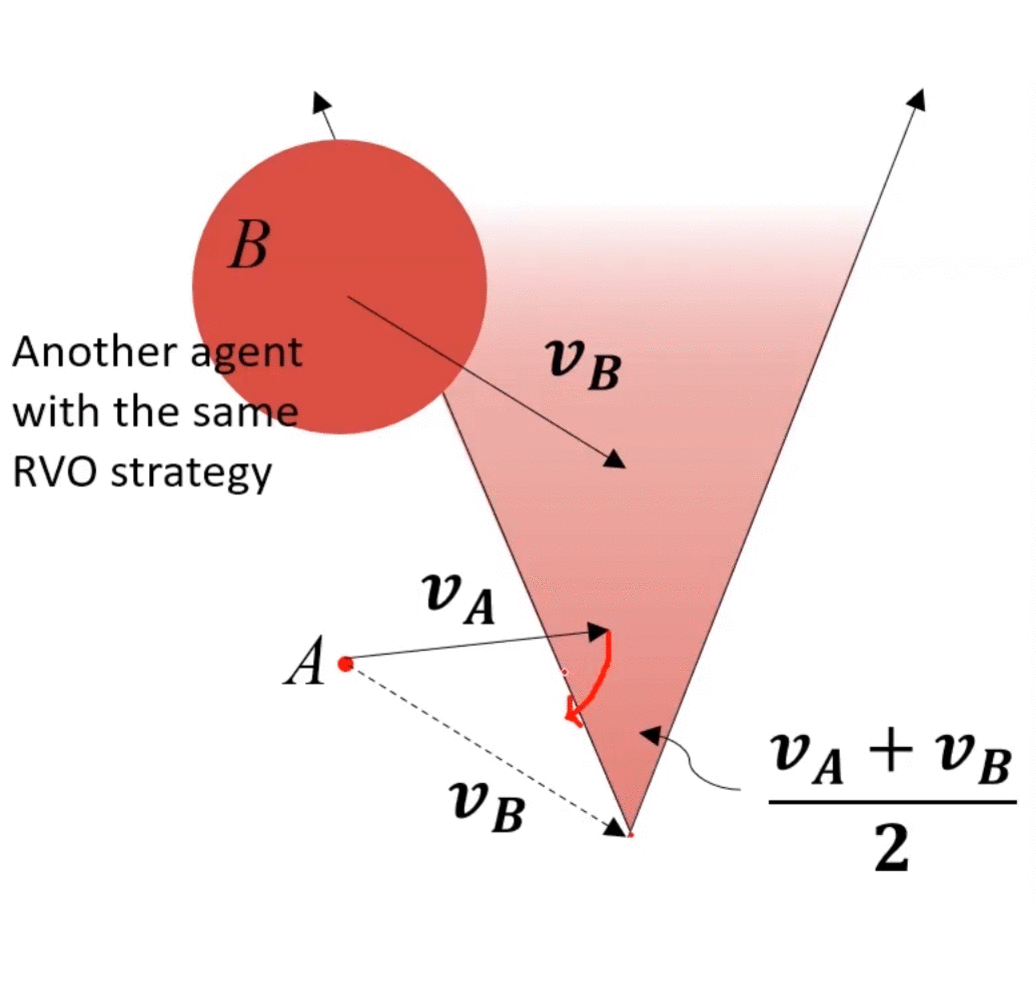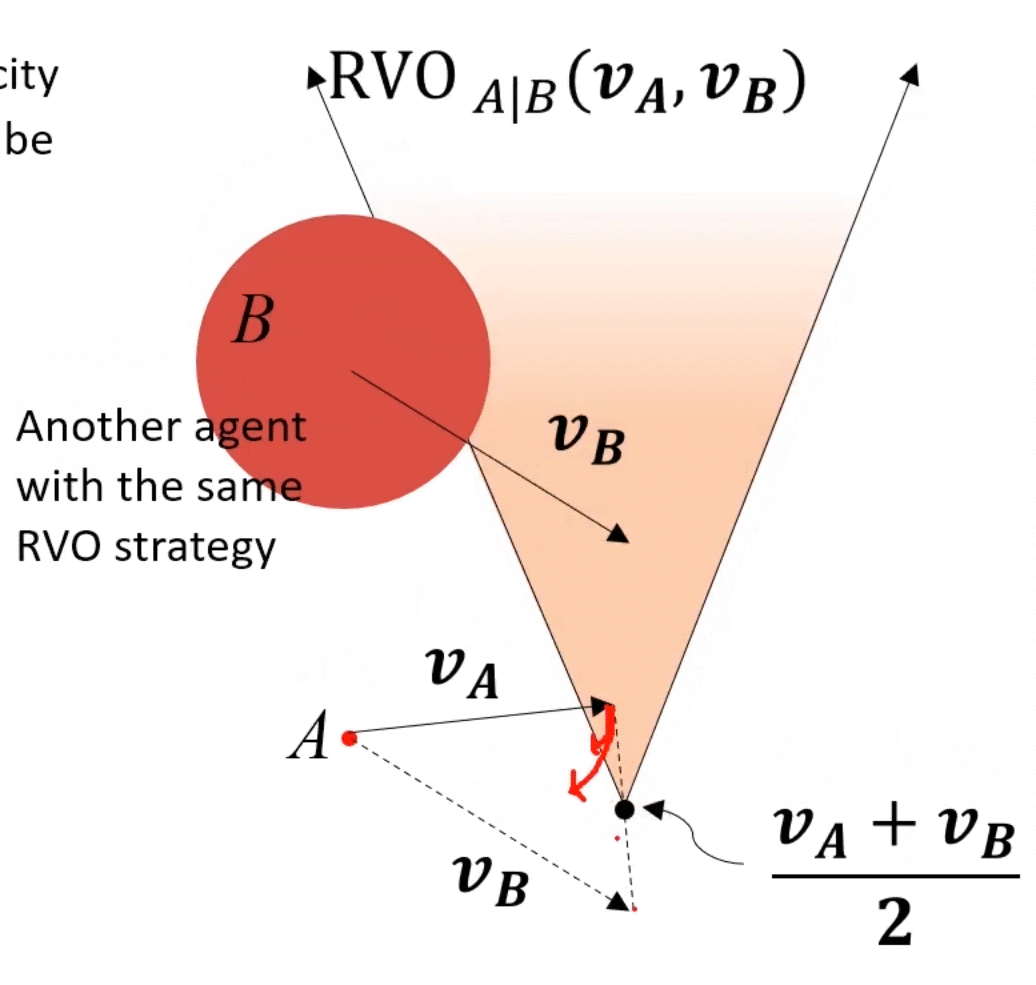
如上圖,A的VO上移前,為了保證安全,A需要調整一個較大角度才能避免碰撞,而將A的VO上移之后,A僅需調整一個較小角度即可保證安全。
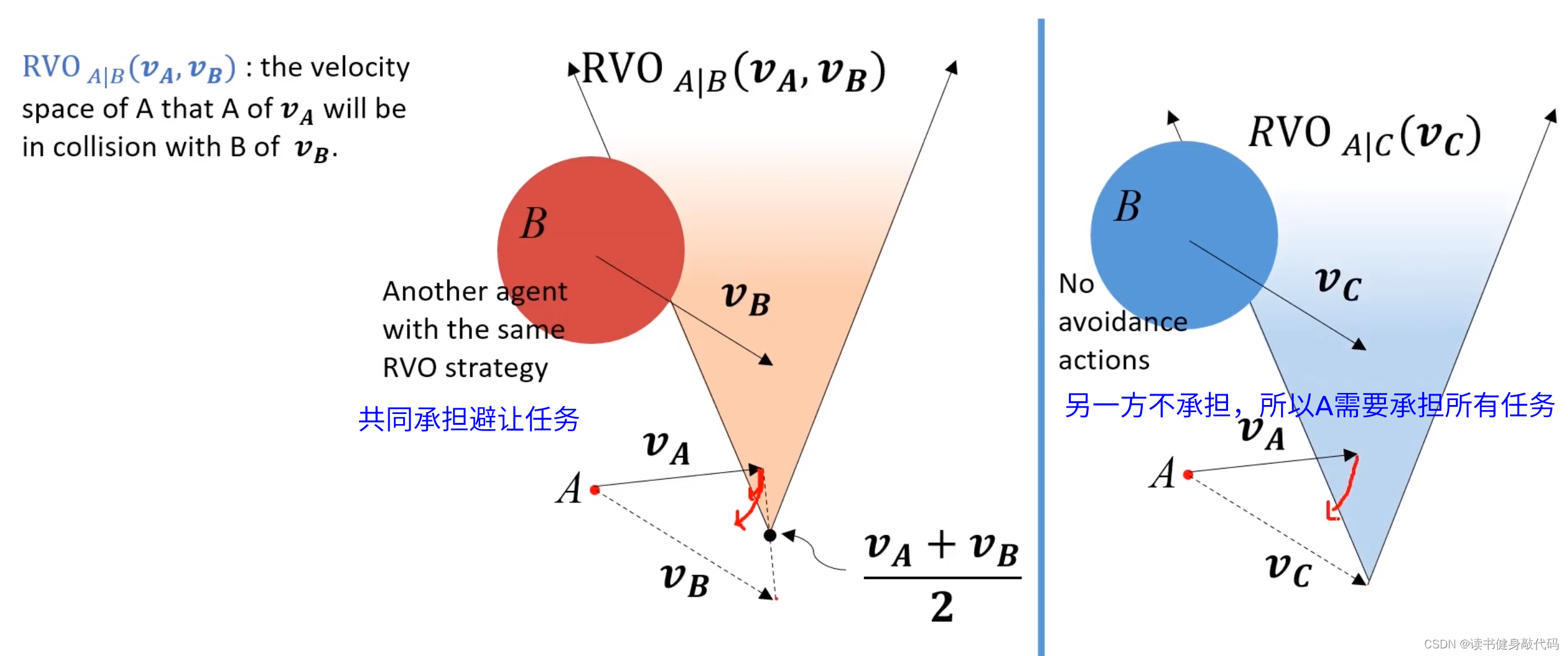
另一方不承擔任務時,對于該agent,還與VO一樣承擔所有任務。
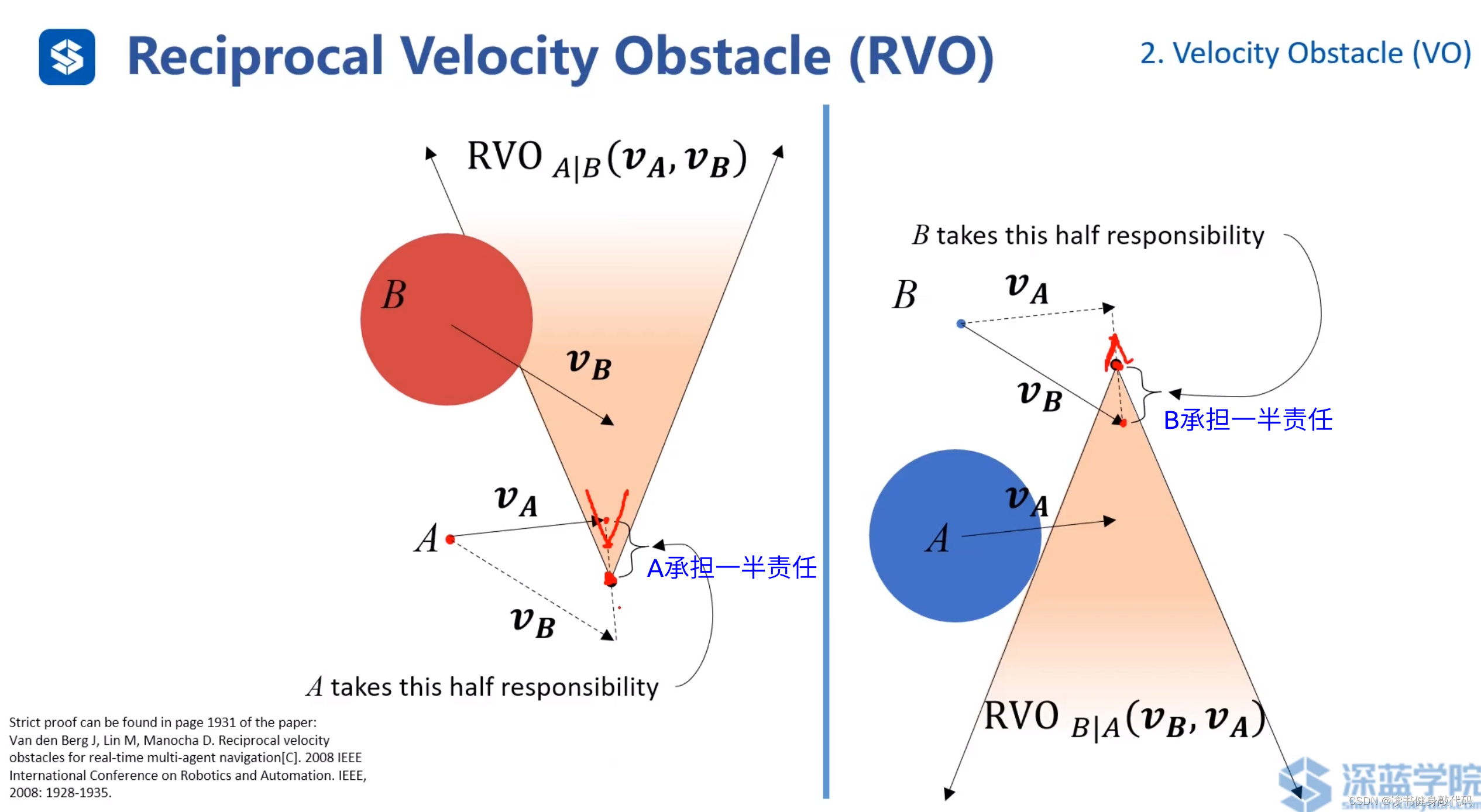
若雙方均承擔避讓任務,可減小zigzag的情況。
上圖為了說明速度,對原問題的位置進行了旋轉。
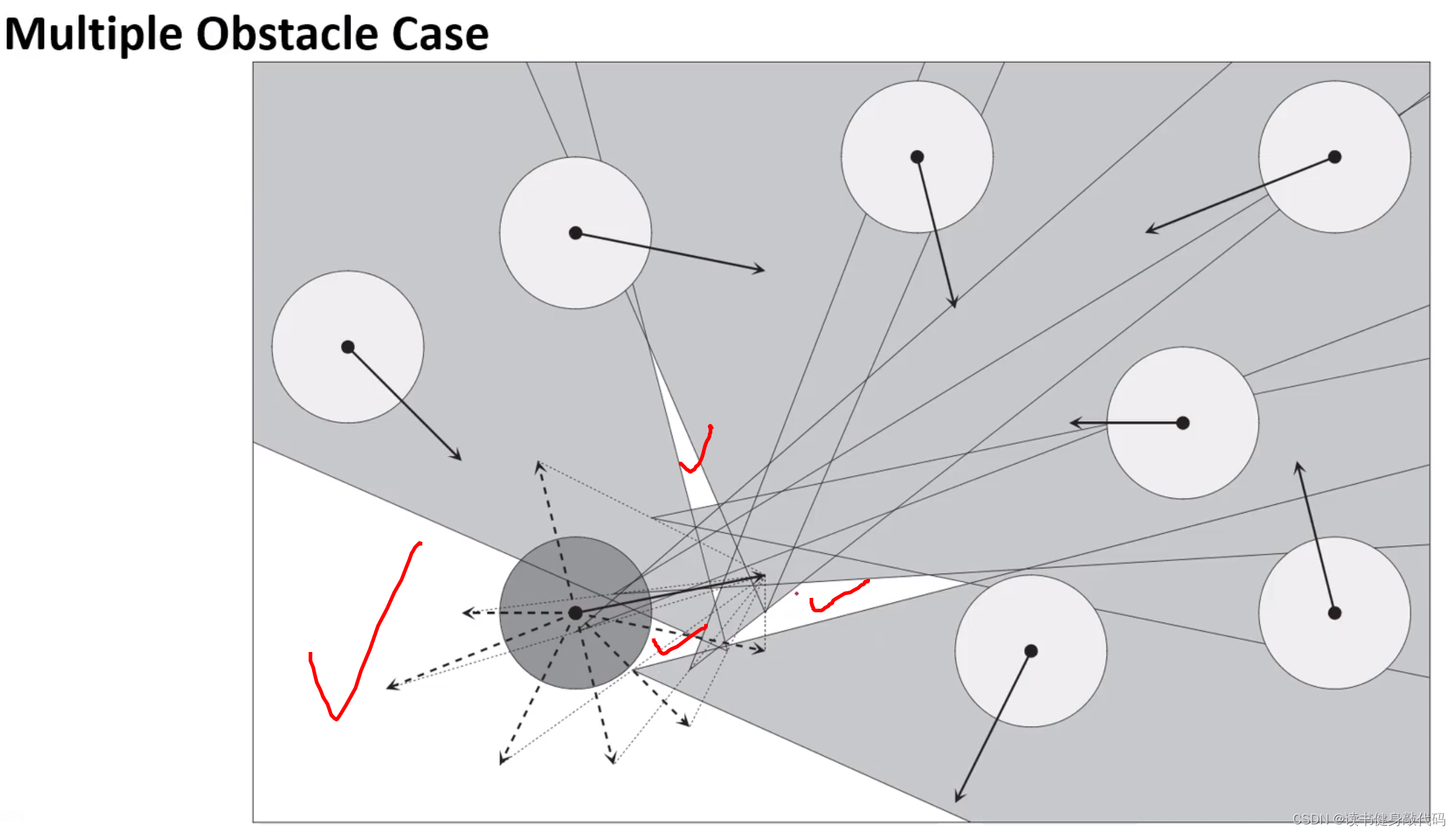
如上圖,在白色區域內選擇速度則不會與任何agents發生碰撞。
2.3 ORCA
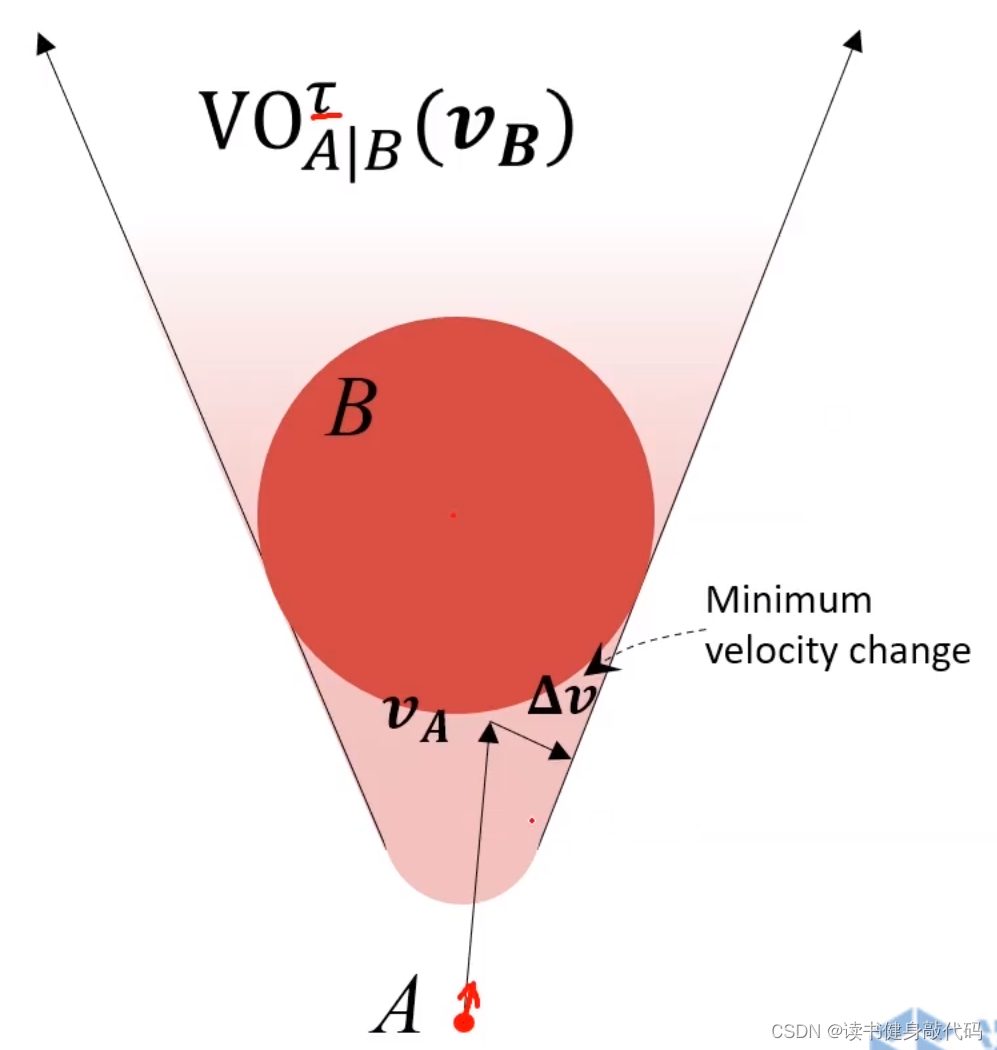
考慮上述情況,A為了避免碰撞,需要對速度 v A \bm{v_A} vA?進行 Δ v \bm{\Delta v} Δv的改變才能保證安全,那么取 Δ v \bm{\Delta v} Δv的中垂線,取靠近free space側的半平面,記作 O R C A A ∣ B τ ORCA^{\tau}_{A|B} ORCAA∣Bτ?,如下圖所示,其中 τ \tau τ是避障有效時間,只關心在 τ \tau τ時間內不會碰撞,所以VO是圓頭的,具體細節此處不深究,可參考ref[9](Optimality definition and proof can be found in pages 6-9 of the paper)。

上圖即為ORCA半平面
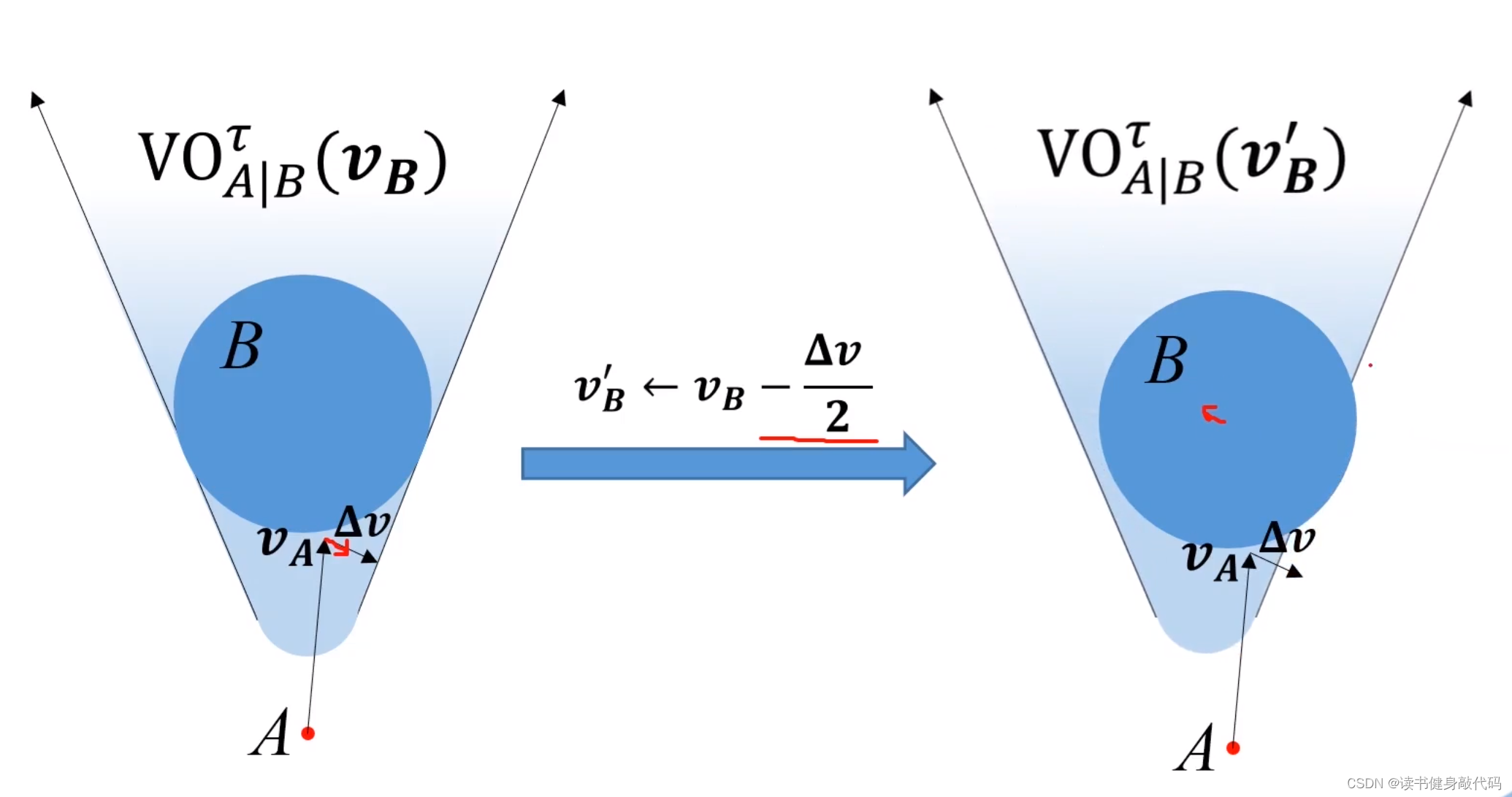
上圖中,總該變量為 Δ v \bm{\Delta v} Δv,A往右下改變 1 2 Δ v \frac{1}{2}\bm{\Delta v} 21?Δv,B往左上改變 1 2 Δ v \frac{1}{2}\bm{\Delta v} 21?Δv,動圖如下所示:
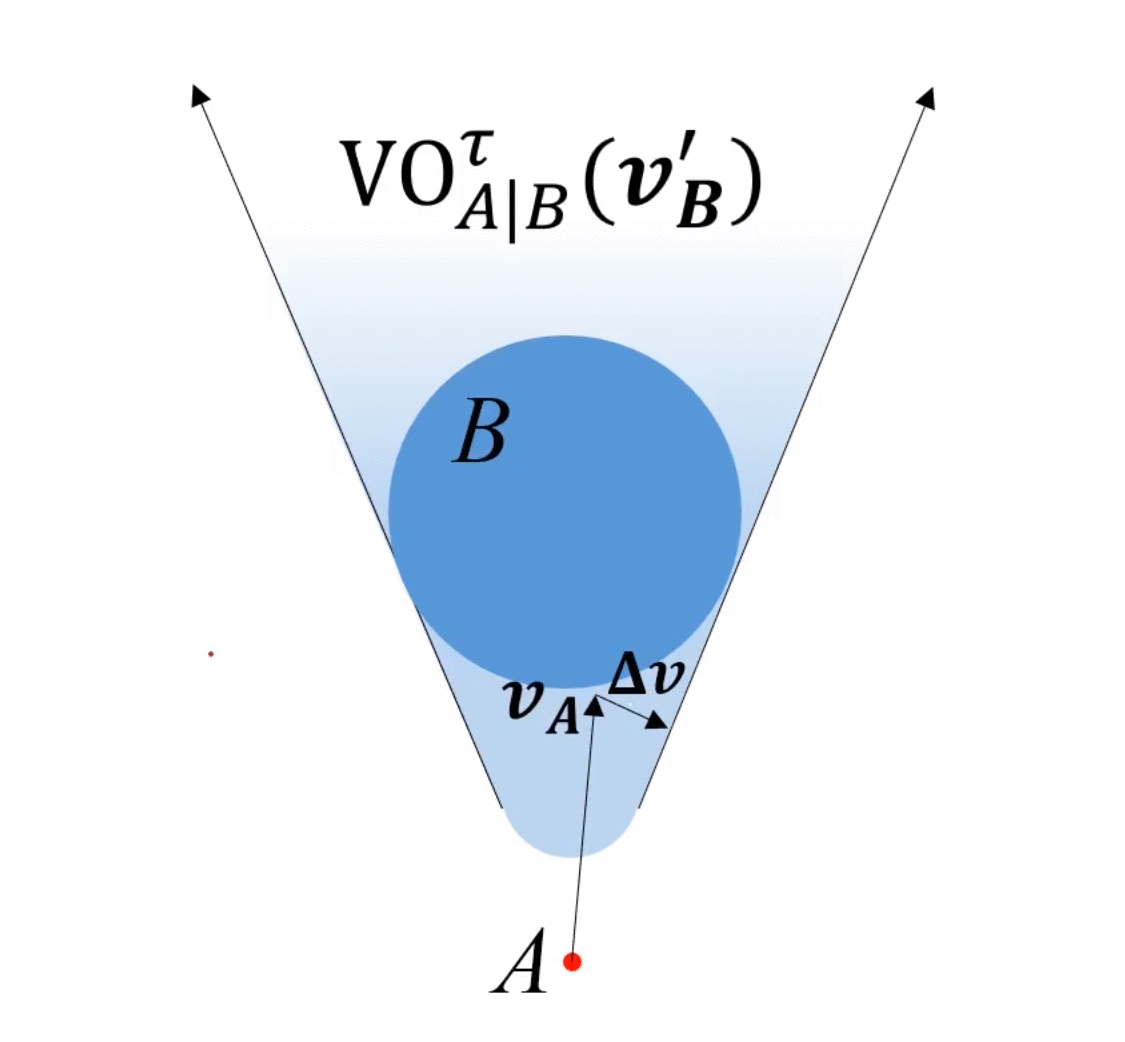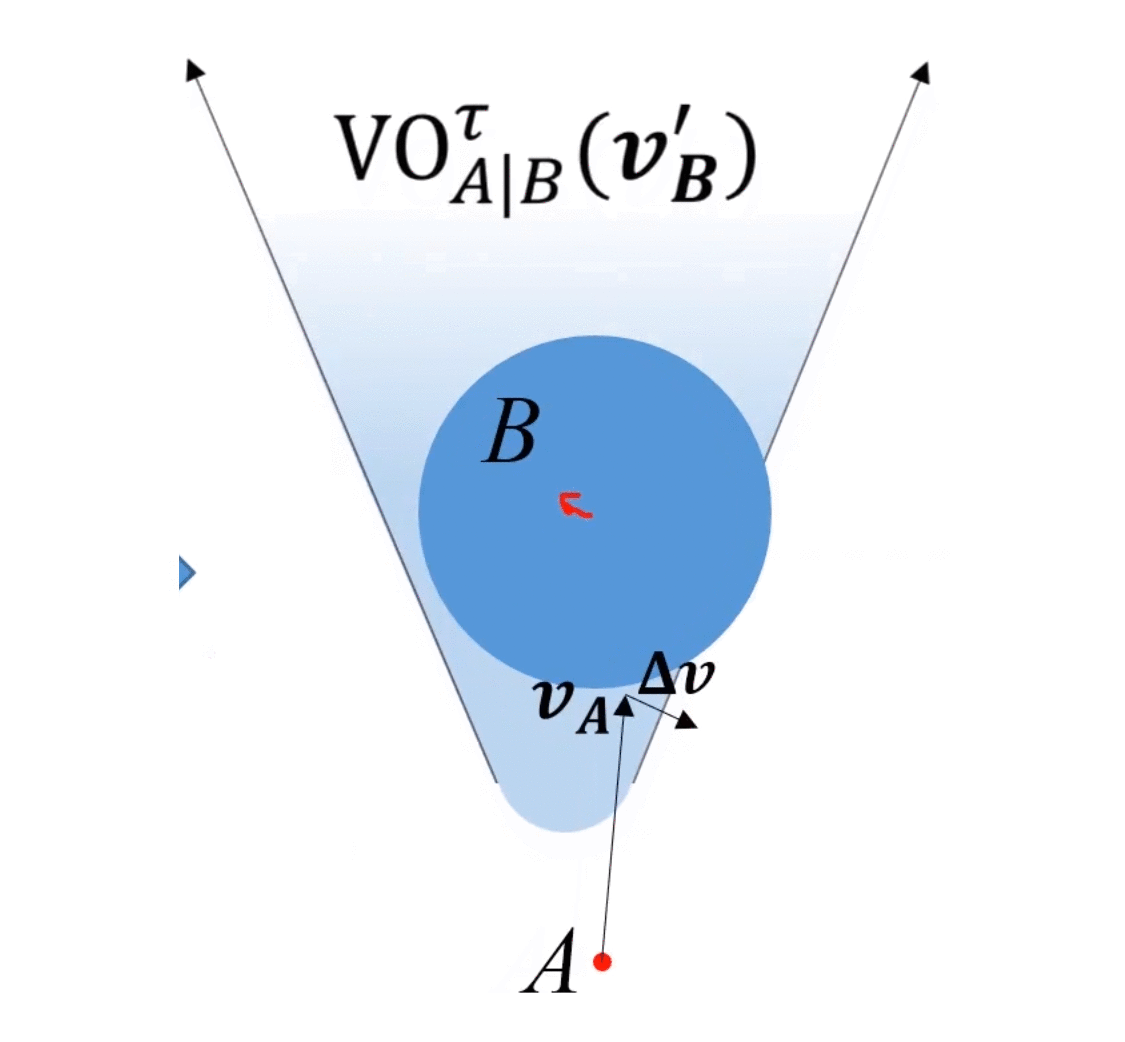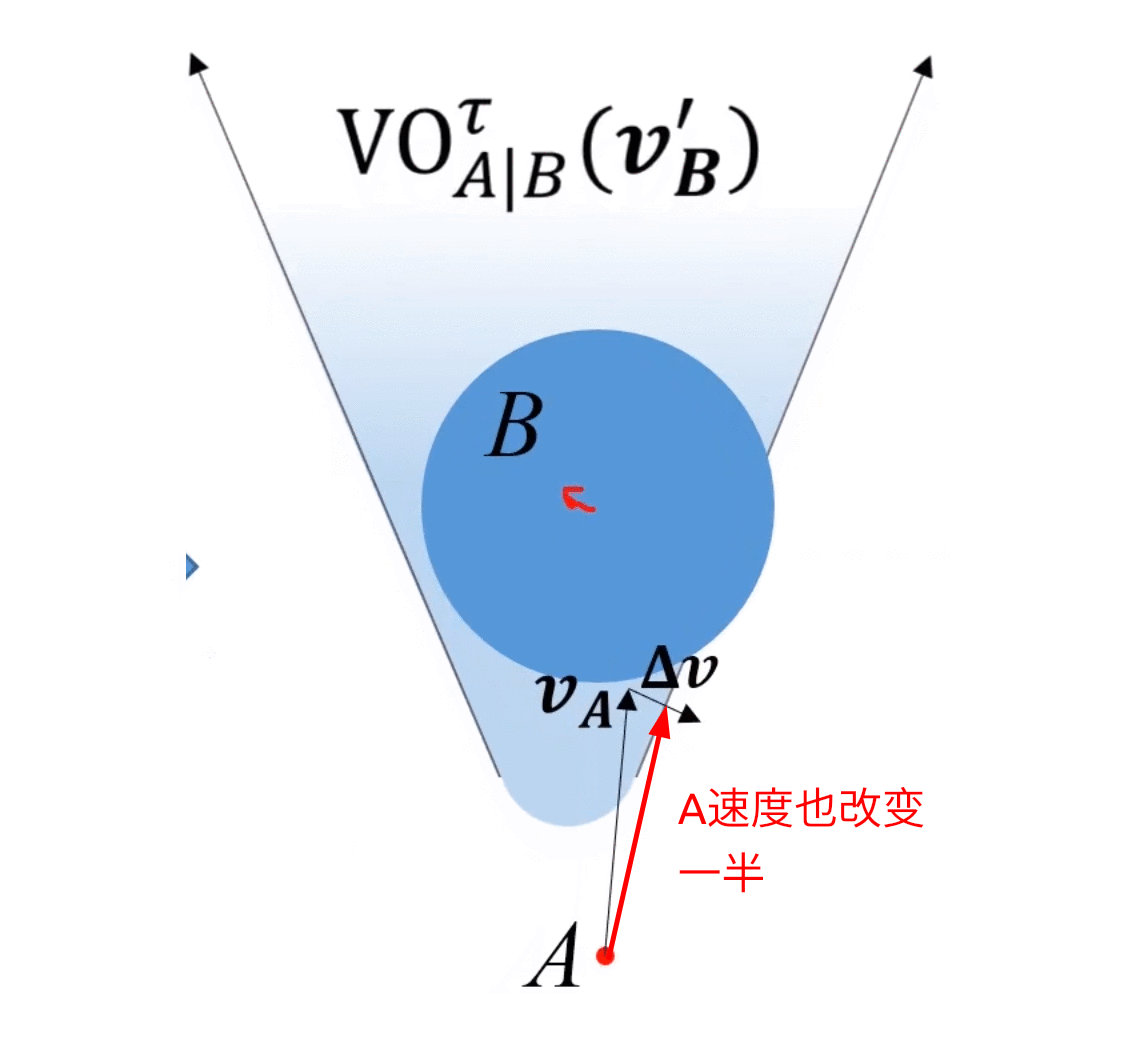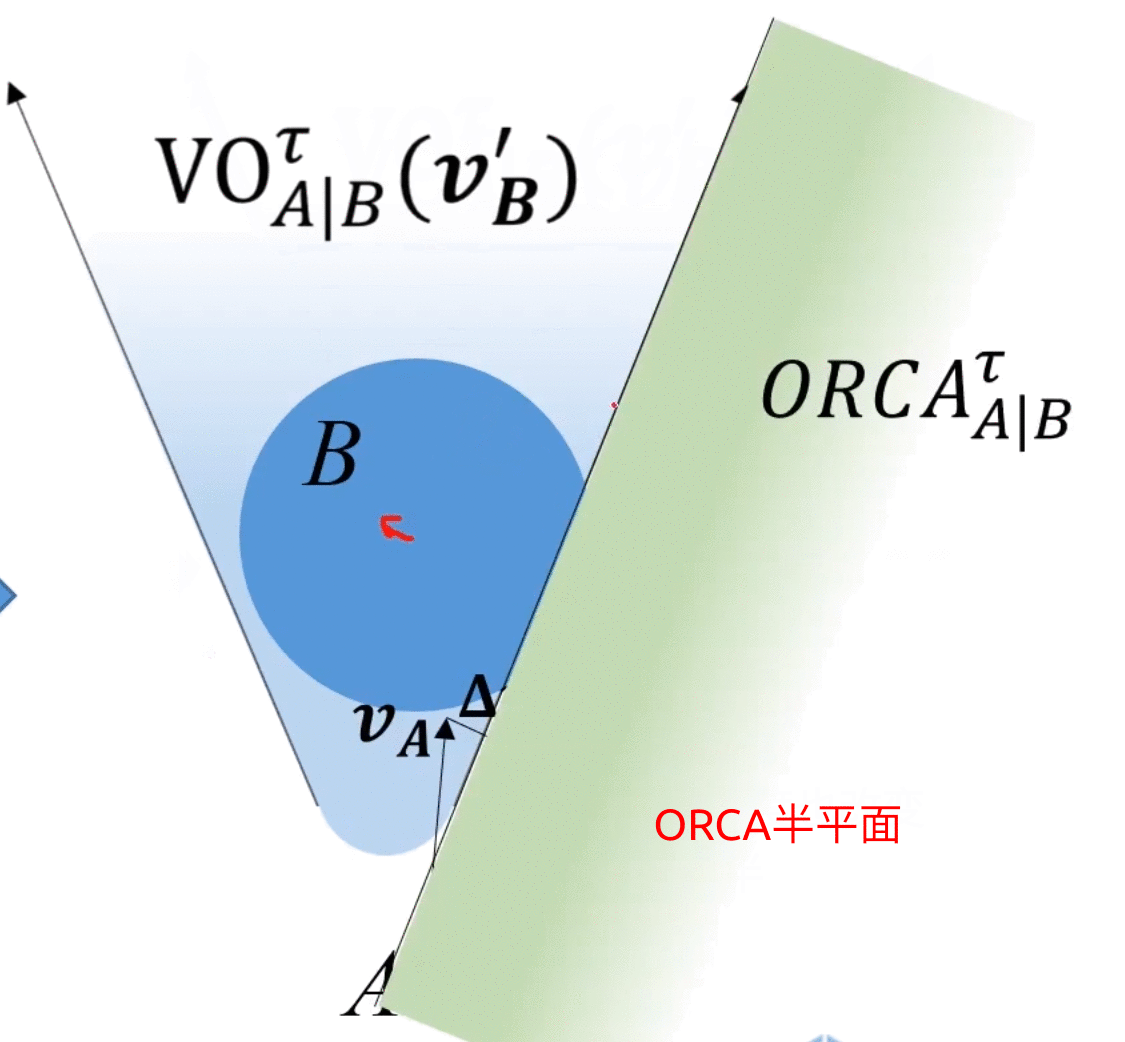
ORCA的精髓:二者以最小速度該變量為基準,分別承擔 1 2 \frac{1}{2} 21?的改變量。
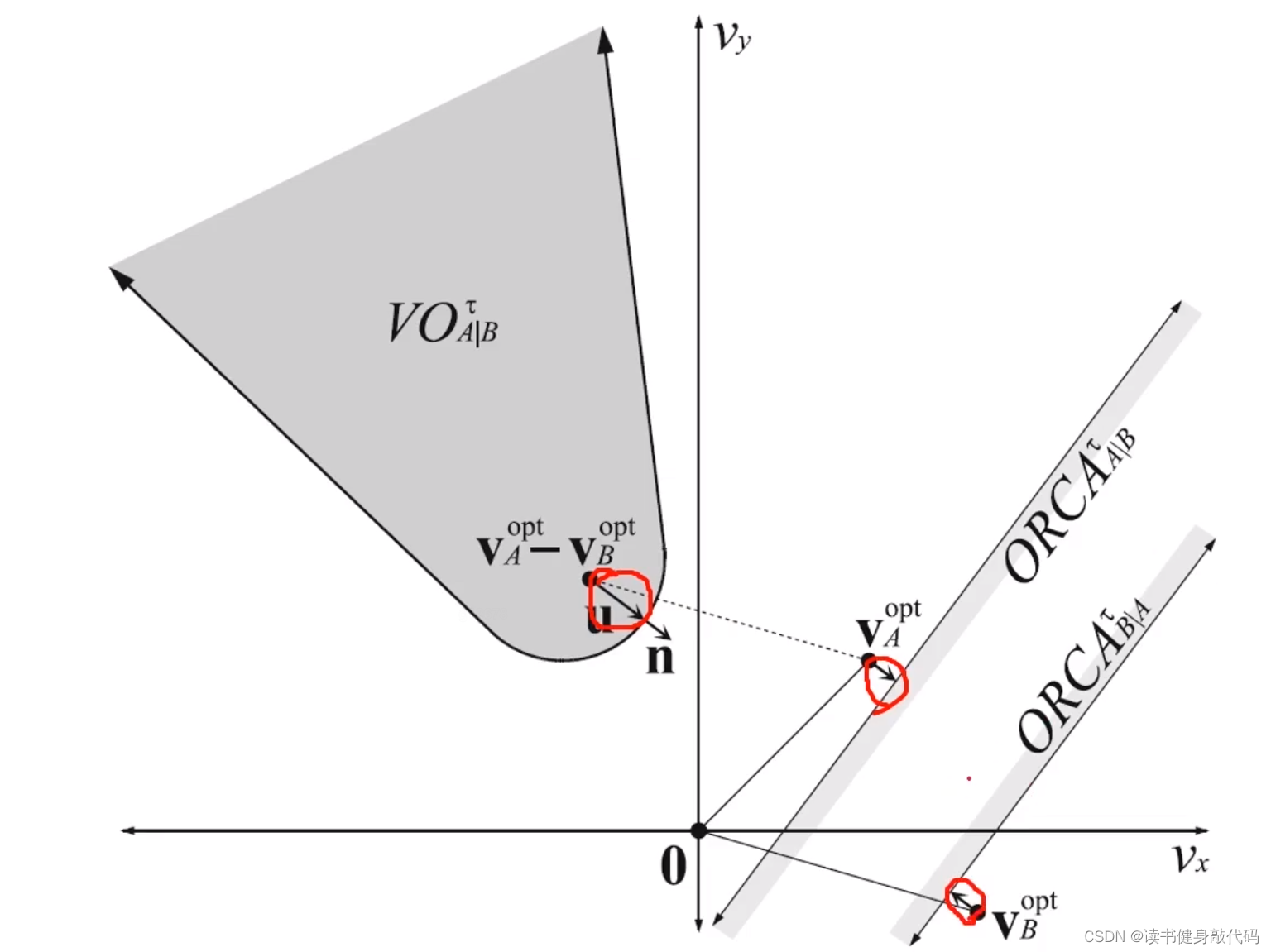
論文中例子, O R C A A ∣ B τ ORCA^{\tau}_{A|B} ORCAA∣Bτ?和 O R C A B ∣ A τ ORCA^{\tau}_{B|A} ORCAB∣Aτ?的陰影部分是做出改變的部分(按照我的理解)
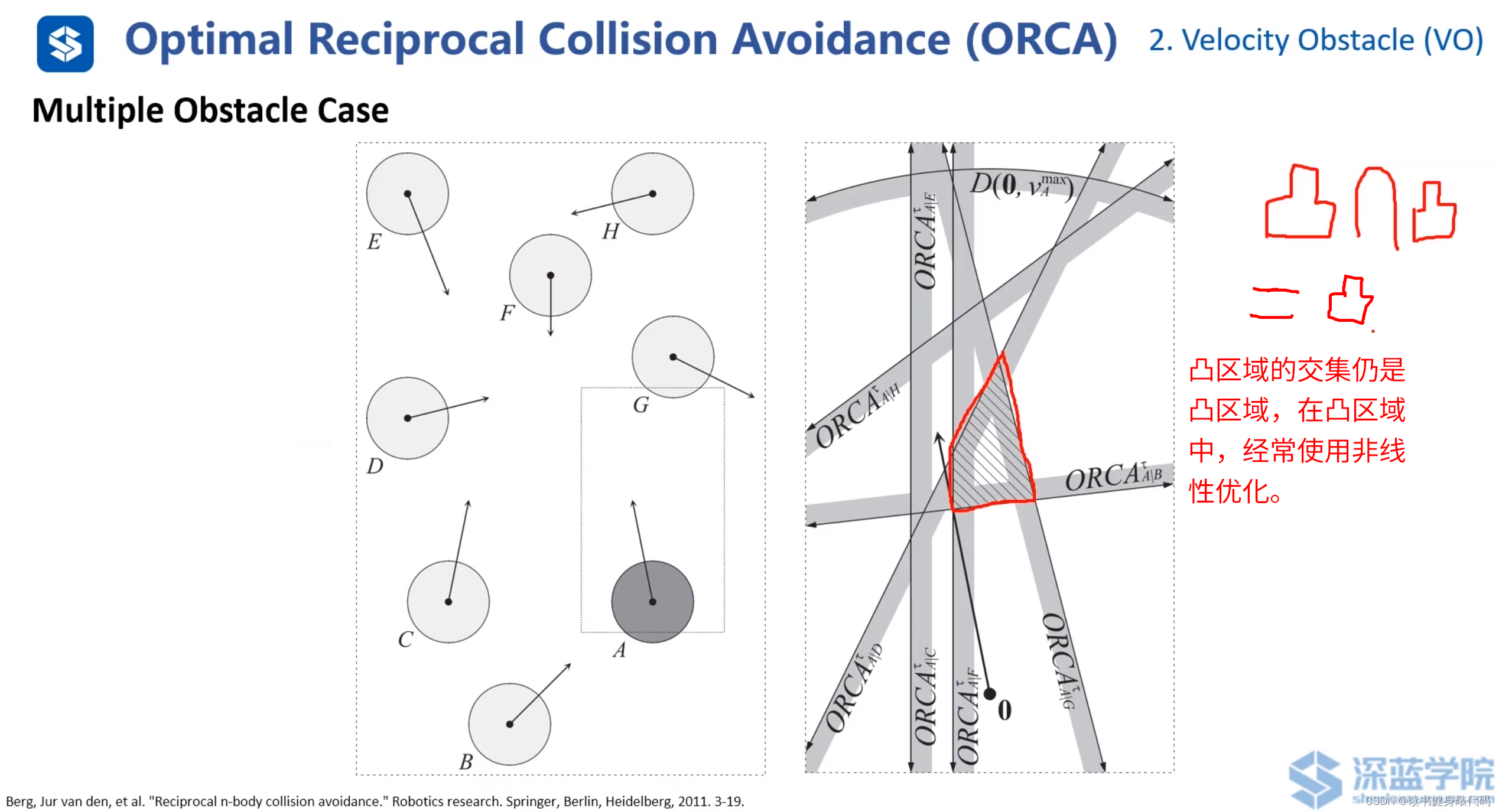
多障礙物避障,取ORCA的交集圍成的區域,半平面為凸區域,其交集仍為凸區域。
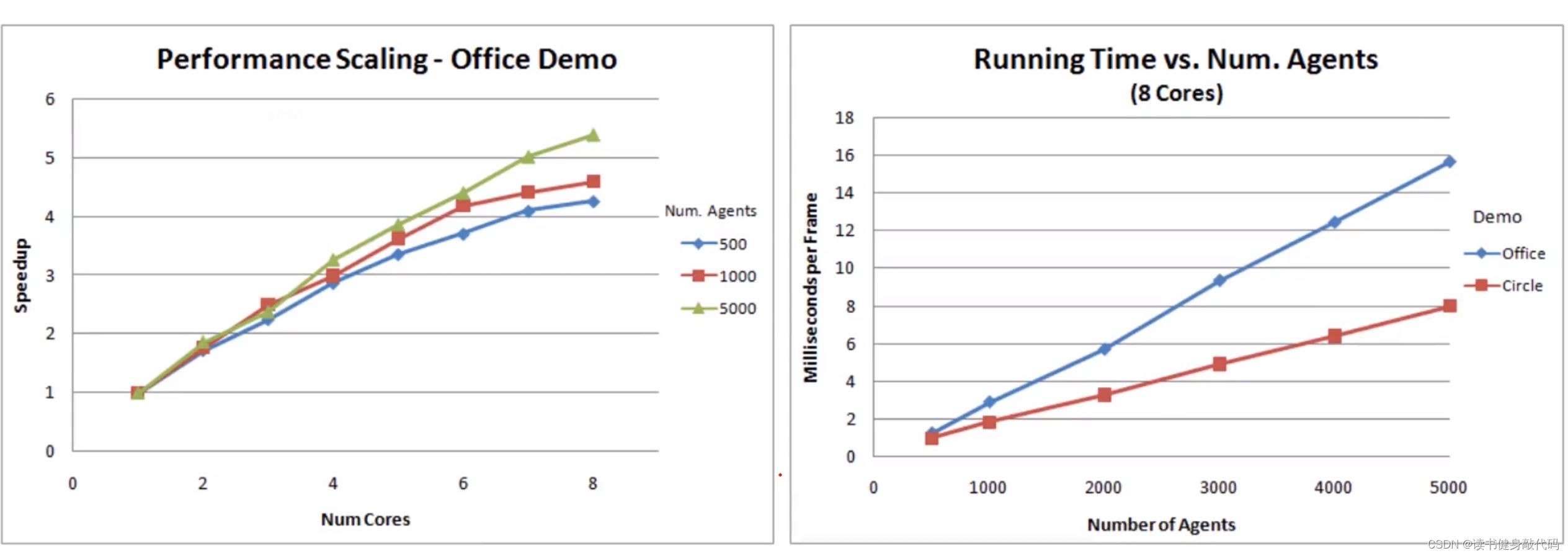
尤其在agents數量多時,ORCA的復雜度和計算消耗較低。
3. Flocking model(群落模型)

ref[10],主要是參考鳥類等種群開發的算法。

main idea:每個agent有短期,中期和長期的速度。
短期: 防止與障礙物和周圍其他agent碰撞。(凸如上圖的曲線,當距離另外的agent較遠的時候,此項為0,較近的時候有速度)
中期:和周圍的agents保持大致相同的速度。
長期:整體朝著目標前進。
三個速度(或推力)加權求和,算出總速度(推力)。
優點:模擬自然界的動物群落。
缺點:參數很多,對調參要求高。
解決方法:一些自動調參的策略等。
4. Trajectory Planning for Swarms(集群軌跡規劃)
本章主要講解集群機器人軌跡規劃的相關原理和應用(應該和Ch5講的trajectory generation對應)
4.1 Background
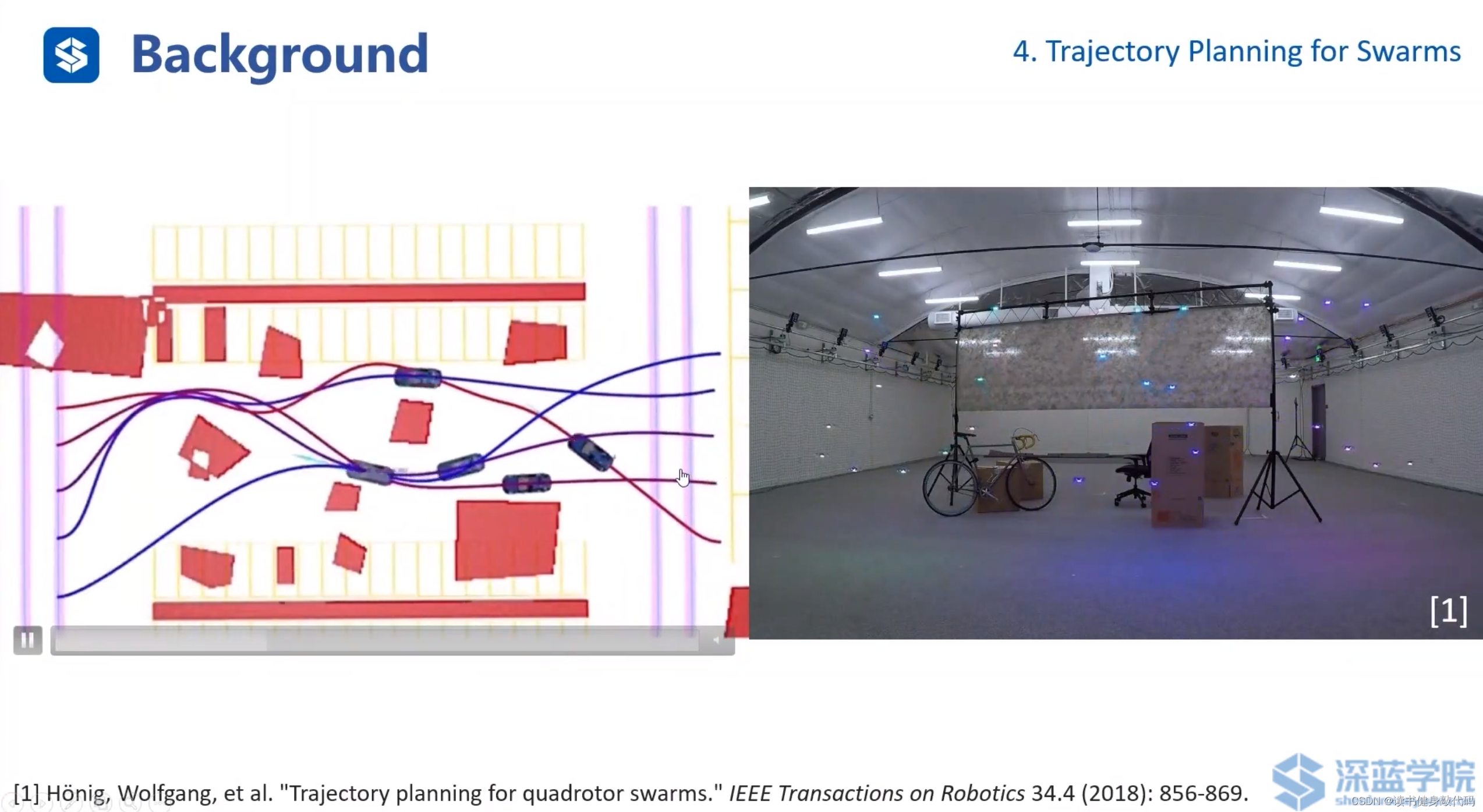
考慮車輛/無人機動力學模型的,多輛車輛的traj生成。ref[11]
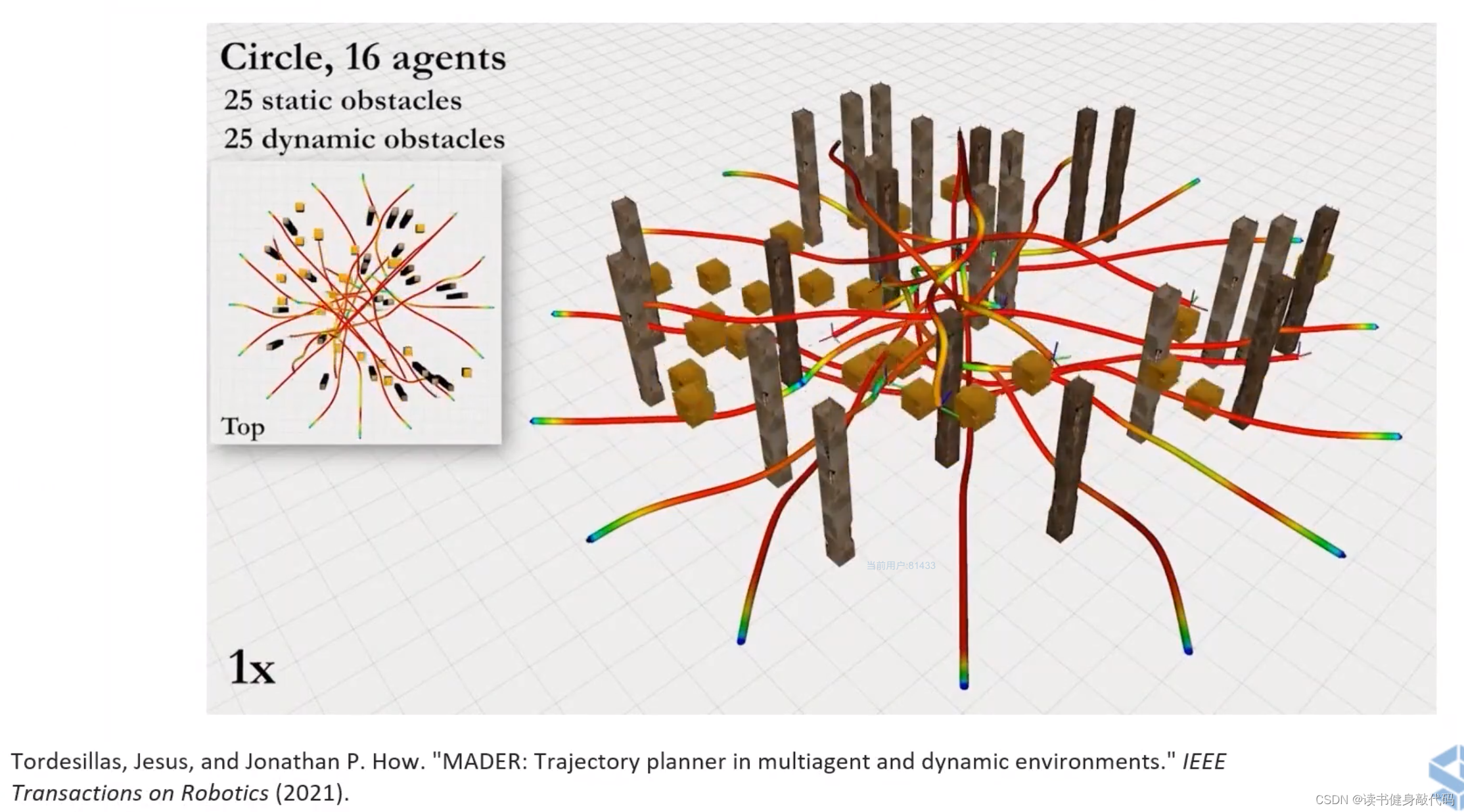
有靜態和動態障礙物的軌跡規劃控制。

ZJU FAST LAB的工作。
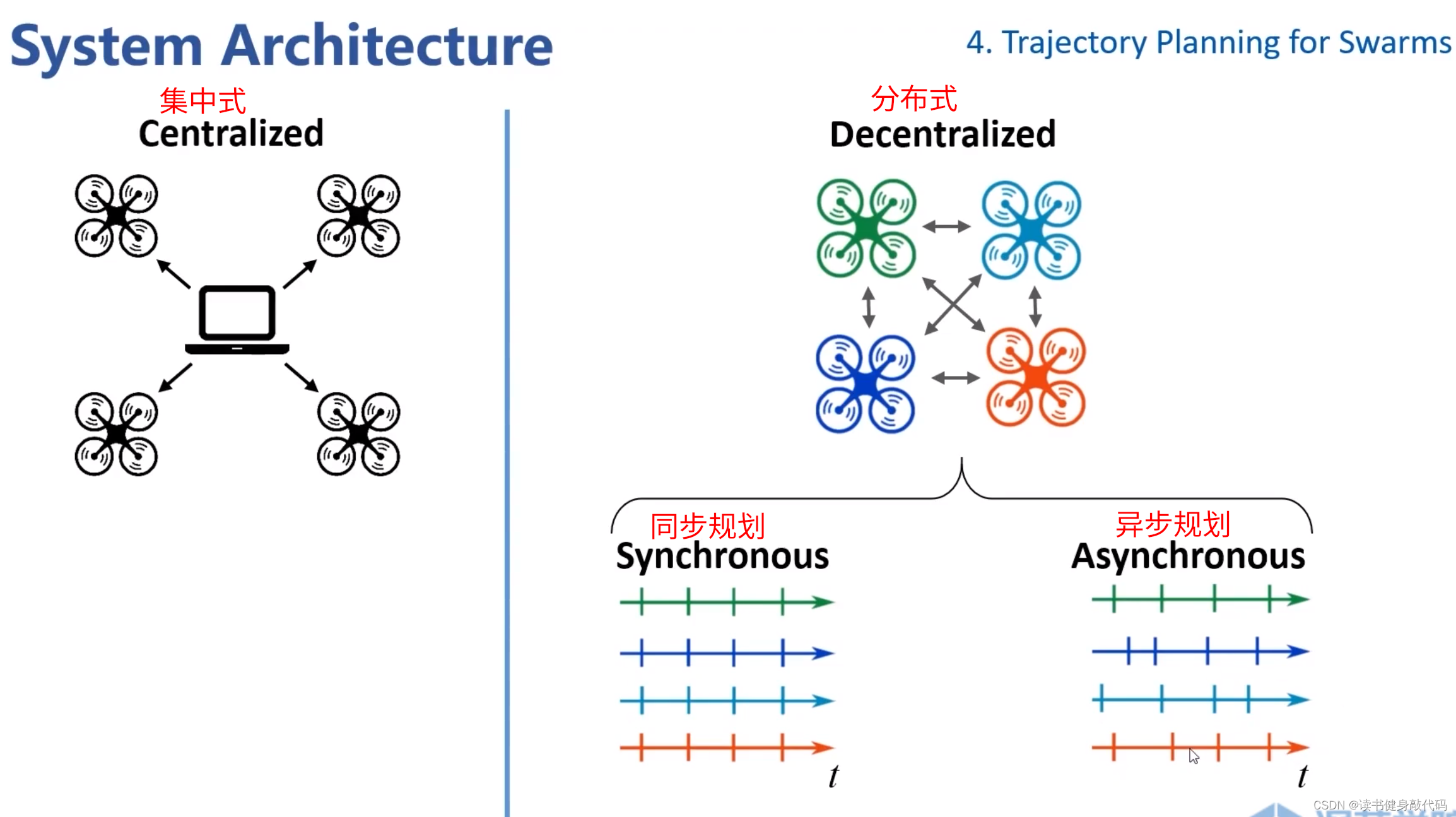
系統結構分為 集中式 和 分布式。
- 集中式:如無人機空中表演,提前算好軌跡發給各個agents執行。
- 分布式:如實時感知并各自進行規劃。又分為同步規劃和異步規劃。
- 同步:按時間觸發規劃,到時間統一規劃。
- 異步:各個agents單獨進行感知和規劃,同時可以接受各自規劃的消息等。(上面ZJU的工作屬于這種)
4.2 Methods
4.2.1 Search/Sampling Based
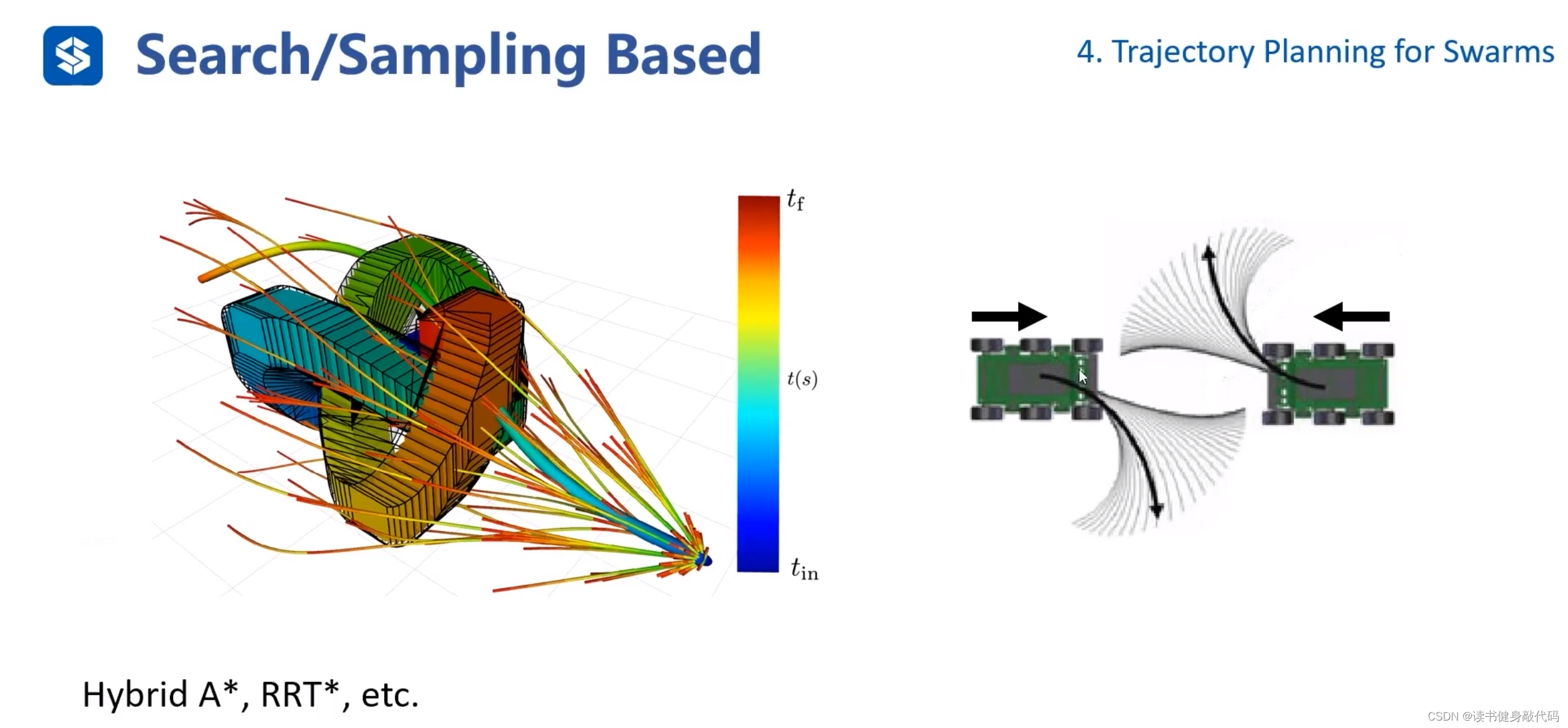
Hybrid A* 是search based method,Kinodynamic RRT*是sampling based method。
- 回顧之前的Hybrid A*(search based kinodynamic planning具體算法)main idea:在control space中sample的lattice graph太過稠密,且采樣出的traj不夠diverge,一條traj發生collision之后,neighbors也容易發生。結合A*和lattice graph的思想,在lattice graph構建過程中每個grid中只保留一個feasiable connection node,通過一種方法計算計算cost,如果當前grid中node的cost比之前node的小,替換之前的node,此做法稱為prune剪枝。
- 右側對應Kinodynamic RRT*(KRRT*),KRRT* 與傳統的RRT* 相比:
- cost不同:RRT使用傳統的cost,如歐式距離,KRRT 考慮動力學約束,定義新的cost function。
- 采樣方式不同:RRT* 直接采樣,KRRT* 需要在full state space中采樣,包括p,v,a等。
- near的定義不同:RRT* 尋找x_near只在低維畫個圓,在圓內找,圓的半徑實際上就是距離采樣點x_new的cost相同的流形,而KRRT* 需要考慮高維的near,此處定義距離x_new的cost相同,“半徑”取為r rr,引申出正向可達集(forward reachable set,我到哪),反向可達集(backward reachable set,哪到我)。
- ChooseParent和rewire不同:ChooseParent時需要計算backward reachable set(哪到我),進行rewire時需要計算forward reachable set(我到哪)。
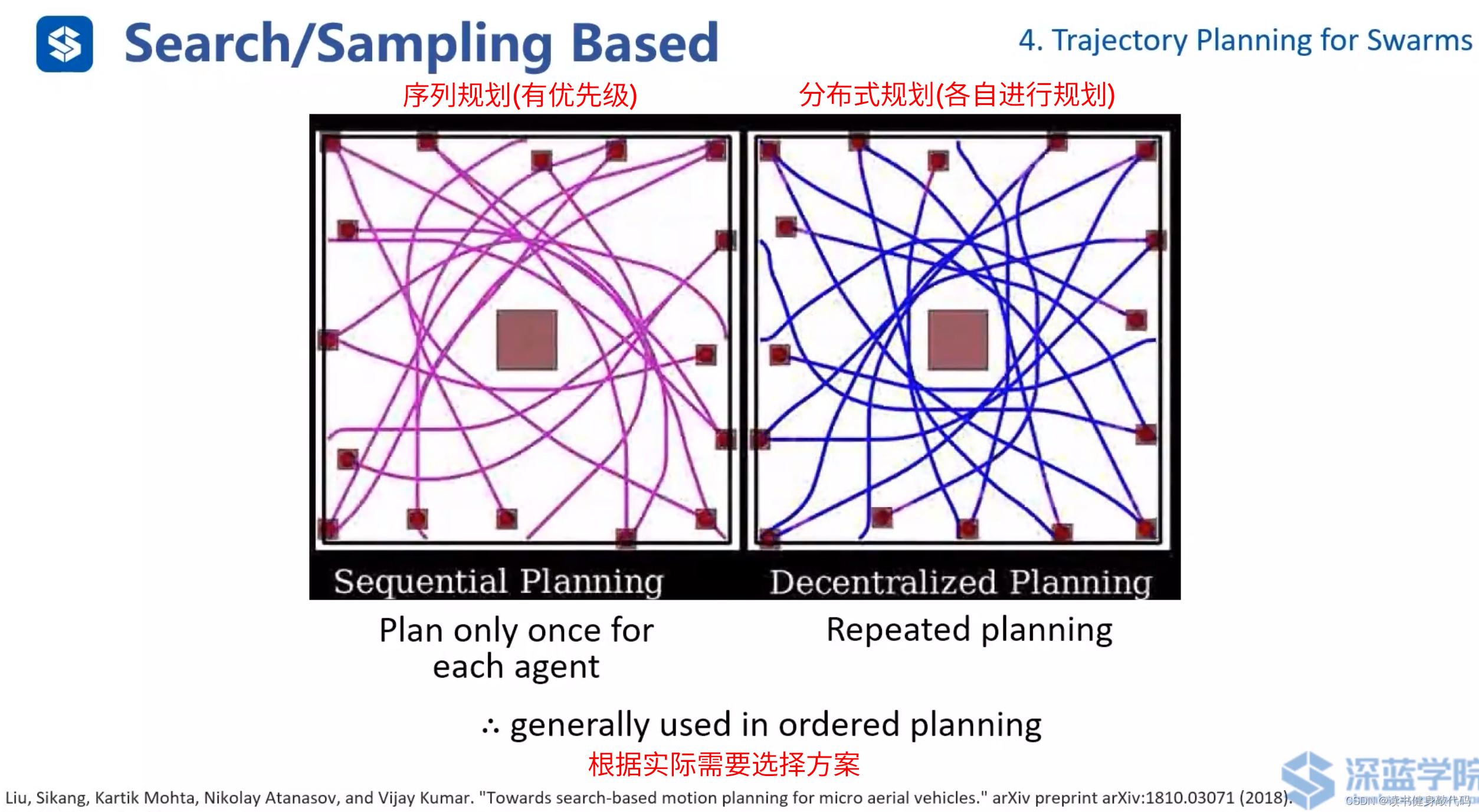
序列規劃和分布式規化(ref[13])。
4.2.2 Optimization Based
4.2.2.1 Formulation

基于優化的方法(這里應該指后端),通常是構造cost function,并對其最小化,考慮環境約束,動力學約束,針對集群機器人運動規劃,還需要考慮agents之間的碰撞約束。
一個經典的碰撞約束如上圖所示構建:
x \bm x x為軌跡的參數, d i j d_{ij} dij?是兩個agent間的距離, i , j i,j i,j分別是agent的編號,在 [ T 0 , T m ] [T_0,T_m] [T0?,Tm?]是規劃有效的時間范圍,約束為
C ? d i , j ( t ) ≤ 0 \mathcal{C}-d_{i,j}(t)\leq 0 C?di,j?(t)≤0其中, C \mathcal{C} C為clearance,允許兩個agents距離的最小值,上式表示兩個agents間的距離 d i , j d_{i,j} di,j?需要大于 C \mathcal{C} C,即保證不碰撞。
其他類型的約束構造方式這里不做講解。
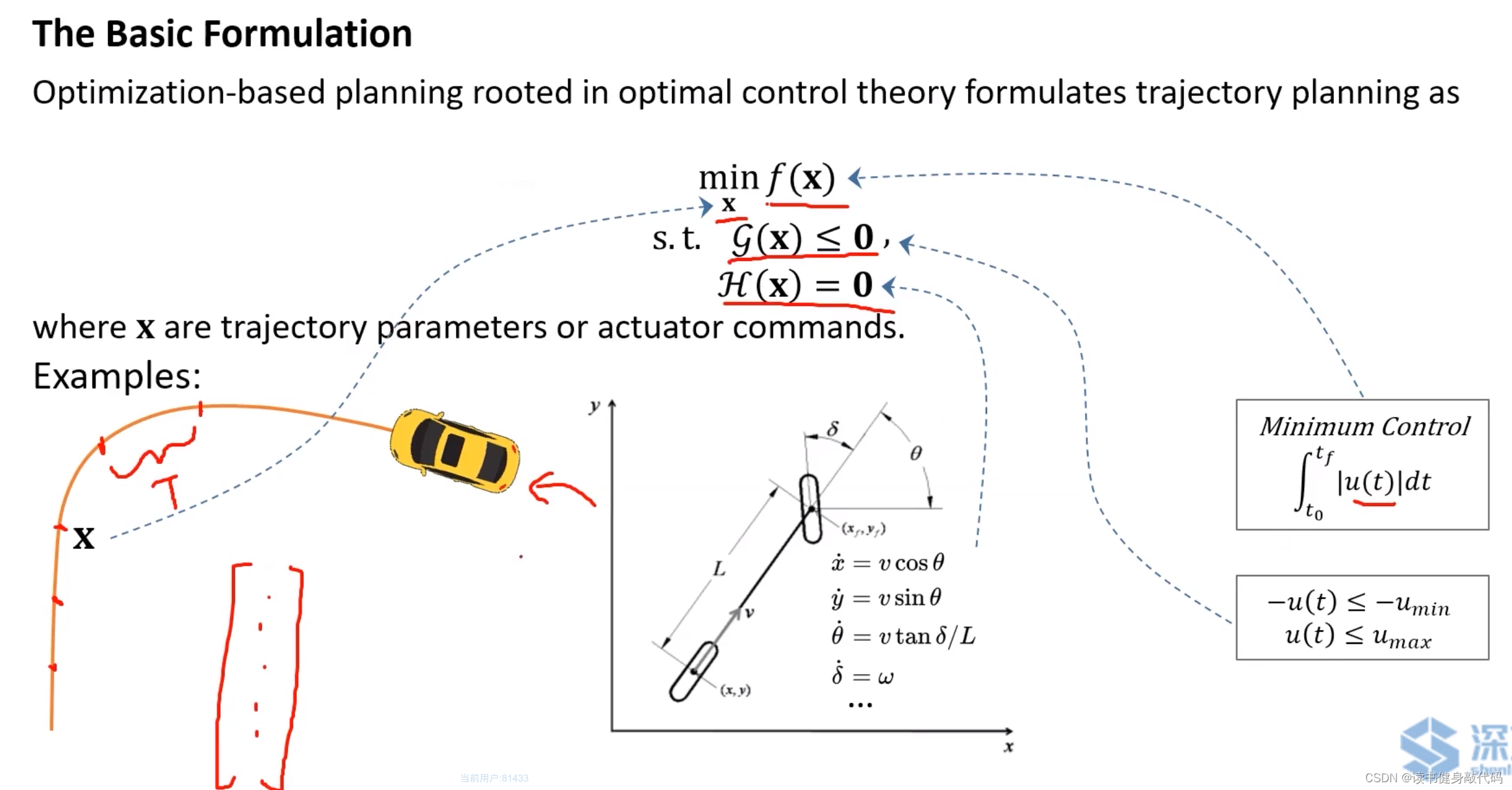
一個簡單的例子:
- cont fucntion可以是minimum control的函數(如minimum jerk等)。
- 軌跡參數 x \bm x x可看做一個向量,代表trajectory需要經過的waypoints或者每個piece所持續的時間 T T T。
- 不等式約束如輸入最值的約束。
- 等式約束如系統動力學約束。
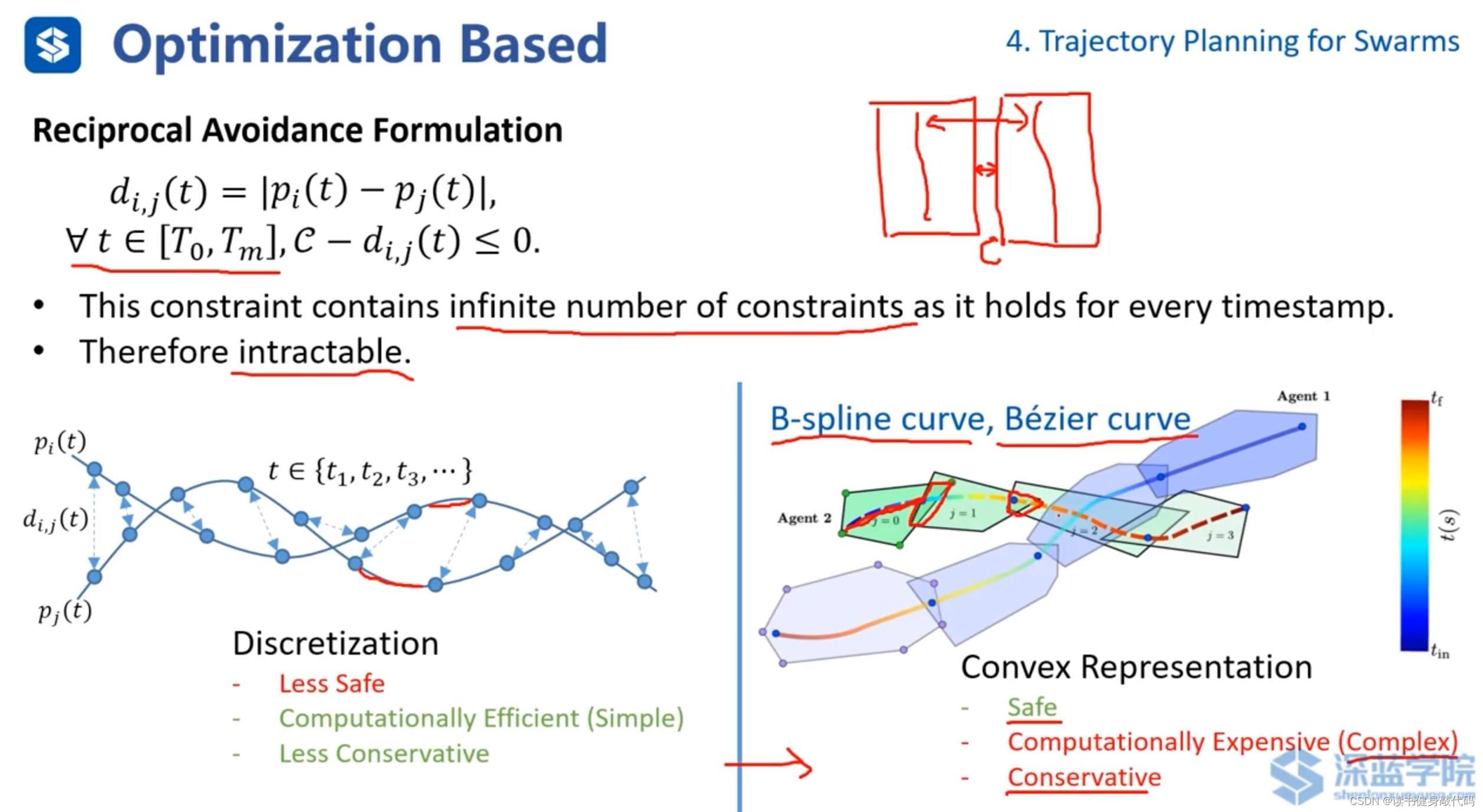
針對前述的避碰約束的構造,由于在 [ T 0 , T m ] [T_0,T_m] [T0?,Tm?]內的時間有無數多個,而構造無數多個約束對于一個問題而言是無解的,所以有兩種方法:
- 離散采樣:在各個trajectory上進行離散采樣,利用采樣點構造避碰約束。
優點:簡單,計算效率高;Less Conservative更不保守(相對于Convex Representation方法而言)。
缺點:安全性低。 - Convex Representation凸包表示:使用B樣條曲線或者Bezier曲線對軌跡進行凸表示,使用凸多面體進行包裹,計算各個trajectory的凸多面體之間的最小距離,如果大于clearance則不會發生碰撞(計算該距離也是難點,下面會進行討論)。
優點:安全。
缺點:計算量大;Conservative保守(如上圖所示,凸包間的距離已經優化到最小值了,但實際的兩條trajectory的距離遠大于clearance,實際上trajectory遠沒有發生碰撞)。
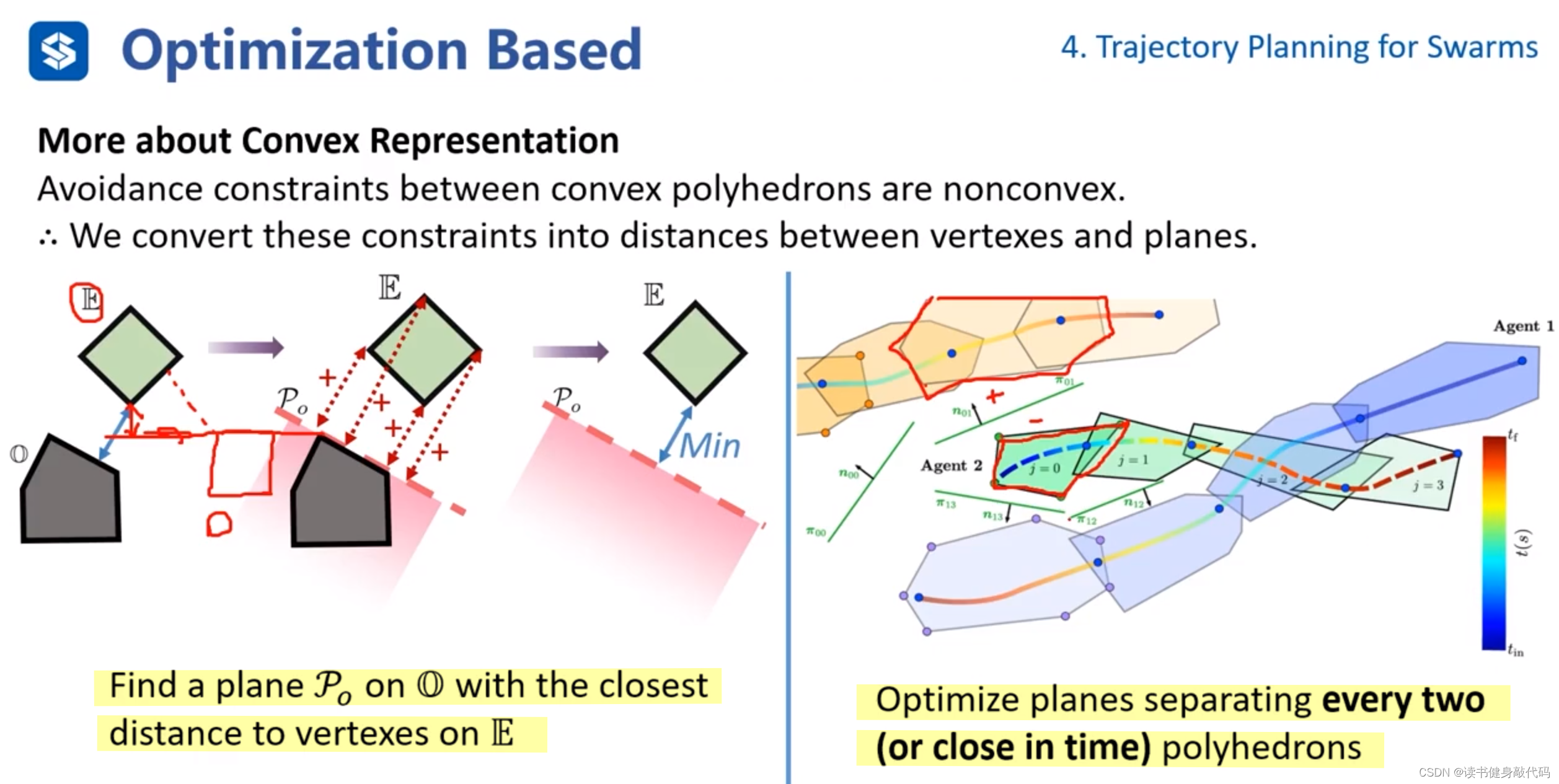
- 法1:在其中一個凸包上找一個平面(平面有方向,平面法線正方側向為+,平面法線反方向側為-),計算另一個凸包距離該平面的最小距離作為這兩個凸包的最短距離。(該方法不完備,因為如上圖左所示,求出的最短距離總比實際的最短距離更短,所以也更保守)
- 法2:分離平面法。在兩個凸包間求取一個分割平面(在中間即平面一個方向凸包為+,另一方向凸包為-),使得兩個凸包距離分離平面有一定的距離,將平面參數也加入到優化問題中進行優化。為了減少待優化平面的個數,只計算時間接近的trajectory的凸包間的分離平面。
更多時候,問題是非凸的,需要轉化,下面介紹兩種方法:Sequential Convex Programming和Penalty Method。需要指出,對于general的問題,下面兩種方法均不能保證找到全局最優解。
4.2.2.2 Solving

使用"Sequential Convex Programming" (“序貫凸規劃”):
序貫凸規劃是一種數學優化方法,它用于解決非凸優化問題。這種方法的基本思想是將非凸問題分解成一系列凸子問題,然后順序地求解這些凸子問題。每次解決一個凸子問題后,都會更新問題的參數,然后解決下一個凸子問題,如此迭代,直到滿足某些收斂條件。序貫凸規劃在工程優化設計、控制系統、機器學習等多個領域都有應用。
具體到問題:
使用仿射變換(Affine transformation)和凸變換(Convex transformation)
- 對于cost function和不等式約束,使用二階Taylor展開進行凸變換。
- 對于等式約束,使用一階Taylor展開進行仿射變換(即轉換為Ax+B的形式)。
需要注意,Sequential Convex Programming是有損的。
轉化完成之后,可借助 mosek,gurobi等求解器完成求解。

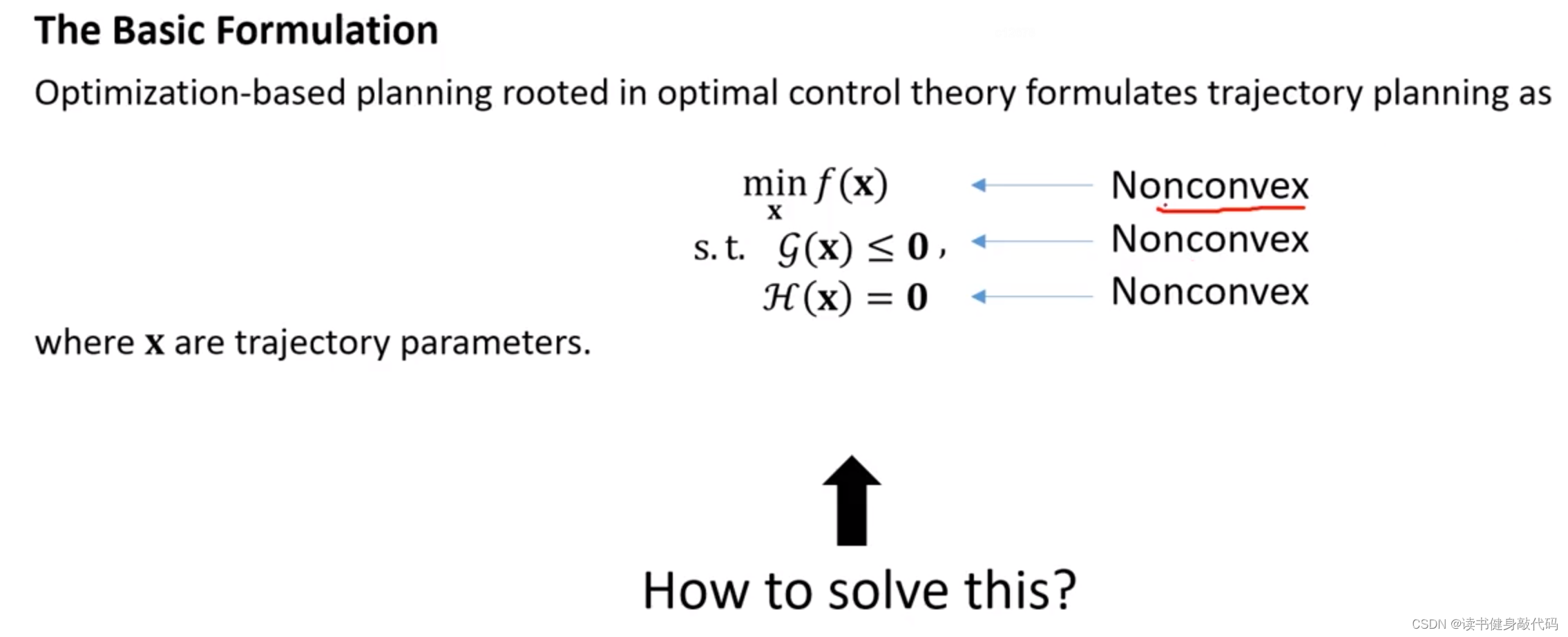
將帶約束的問題轉化為無約束問題。通過將約束轉化為懲罰項加入到cost funtion中進行優化,該方法不保證問題為凸問題,通過迭代數值求解(如G-N,LM等),得到local minimum。
- 把不等式約束轉化為等式約束,數學上喜歡 G ( x ) + s 2 \mathcal{G}(\bm x)+\bm s^2 G(x)+s2以保證連續性,而工程上常使用 m a x ( G ( x ) , 0 ) \mathop{max}(\mathcal{G}(\bm x),0) max(G(x),0)
- 為等式約束和不等式約束分別添加權值 μ 1 , μ 2 \mu_1,\mu_2 μ1?,μ2?,隨著迭代的進行,不斷增大權值,使得約束收斂至0。要求從較為合適的初值( x ( 0 ) , s ( 0 ) \bm{x}^{(0)},\bm{s}^{(0)} x(0),s(0))開始迭代。
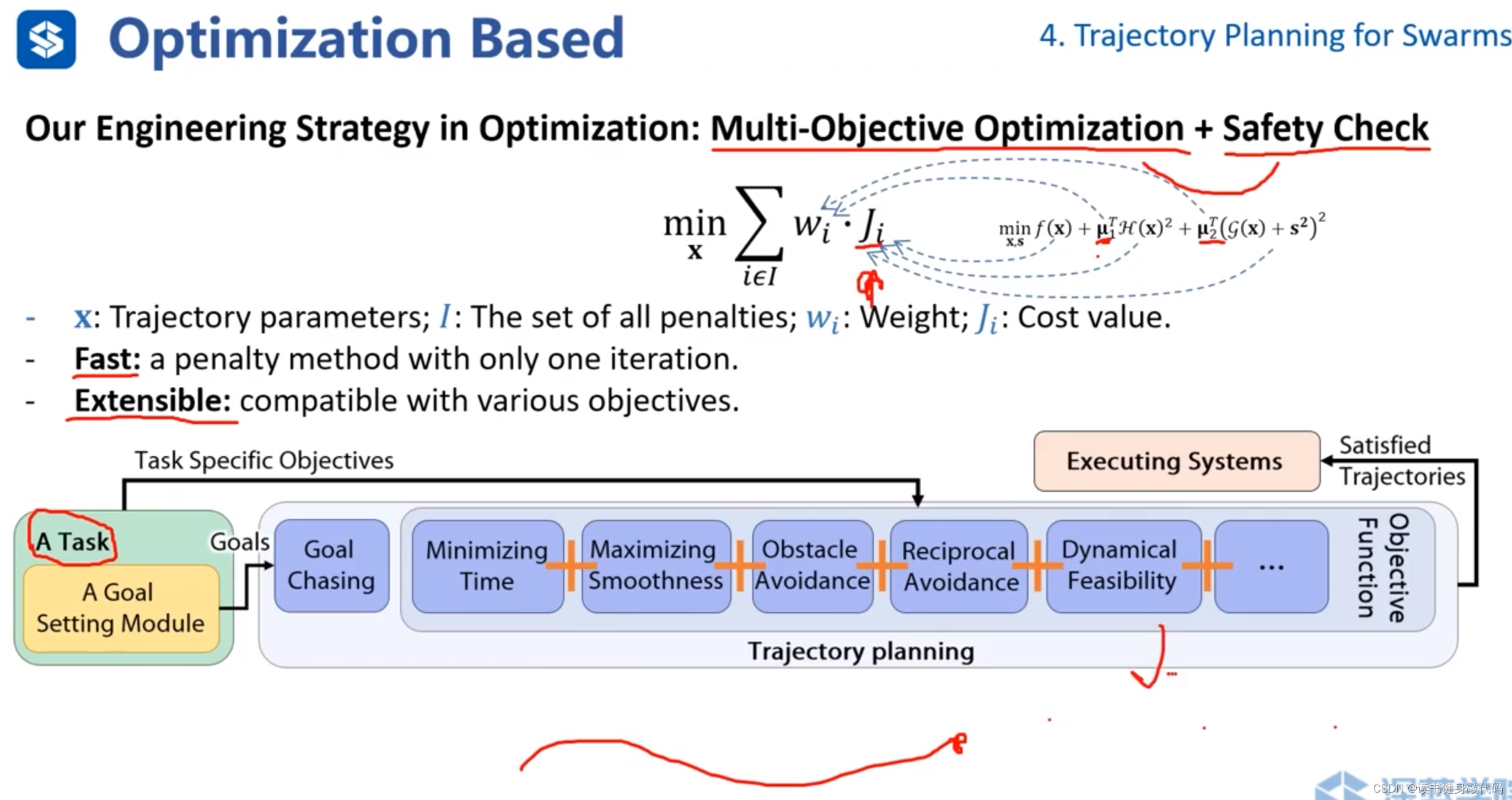
ZJU的工作(偏工程的方法)
轉化為“多目標優化問題+safety check”的框架。(類似于Ch4作業中的ref[1]的動力學約束的多旋翼軌跡生成的框架)
權值 μ 1 , μ 2 \mu_1,\mu_2 μ1?,μ2?事先給定,在優化過程中不進行調整。
整個框架先生成軌跡再進行safety check。把cost fucntion和各種約束都轉化為 ω i ? J i \omega_i \cdot J_i ωi??Ji?的形式,整個框架不斷地生成一小段一小段軌跡,goal不斷往前移動。
框架優點:1. 快速;2. 可拓展(新的約束也可轉化為 ω i ? J i \omega_i \cdot J_i ωi??Ji?的形式)
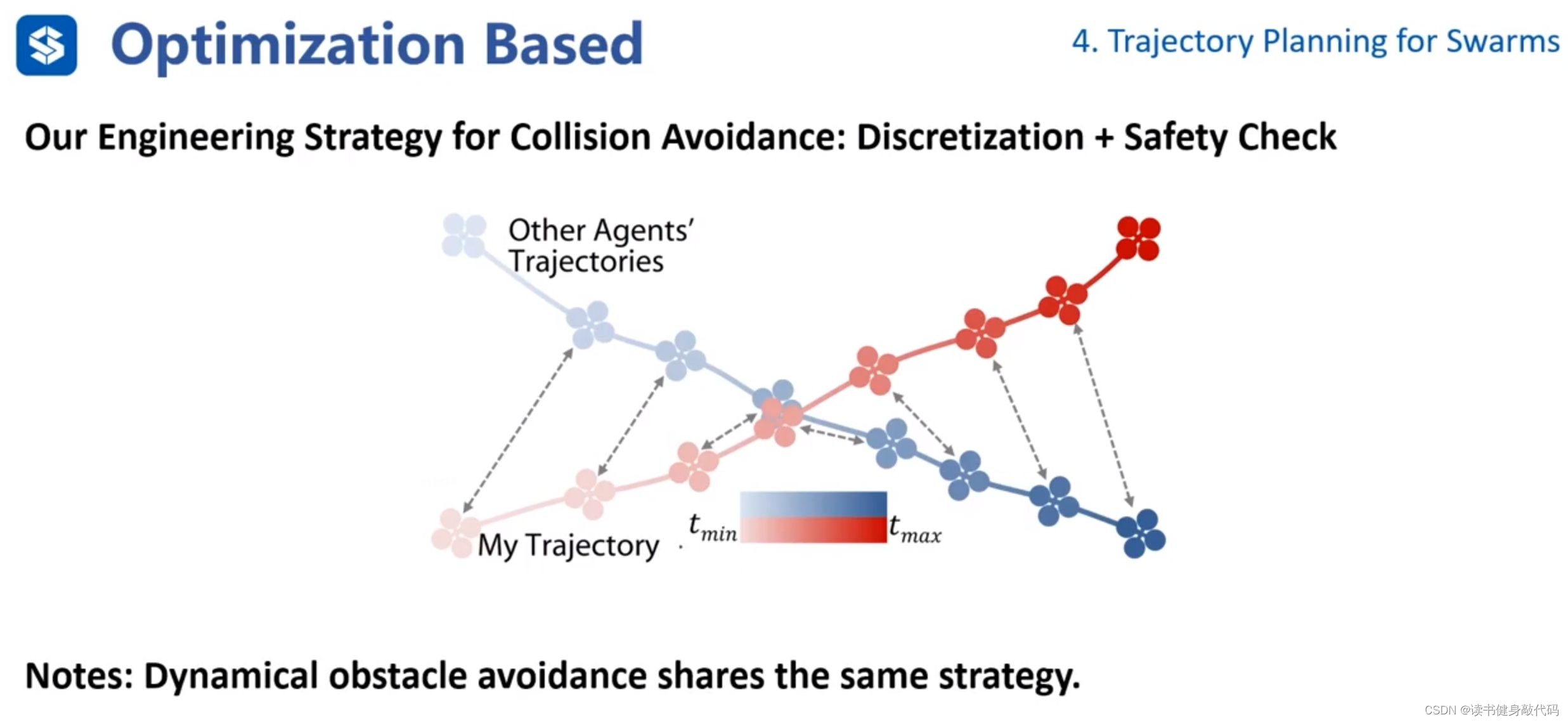
關于多個無人機如何避障,使用采樣的方式,通過safety check保證安全,采樣點處安全即可。多個無人機可以共享相同策略。
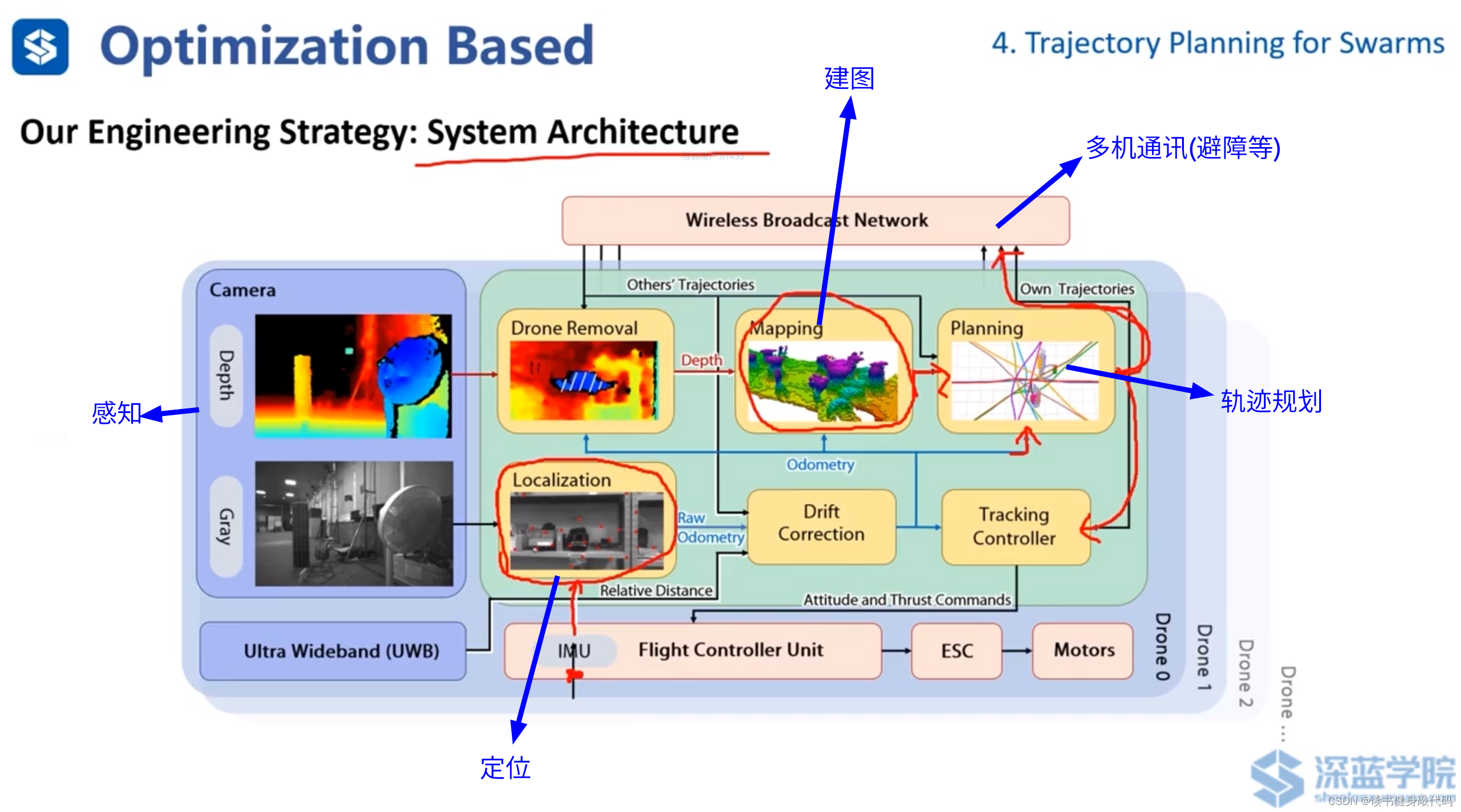
ZJU工作的整個系統框架,發表于Science Robotics期刊,ref[16]。
5. Formation(編隊)
在運動規劃領域中,“formation” 通常指的是一組自主體(可以是機器人、無人機、車輛等)按照某種特定的空間排列進行移動。這種排列可以是為了各種目的,比如提高效率、增強穩定性或者完成特定的任務(如搜索和救援、軍事編隊、農業作業等)。
有序的"formation"有助于協調集體行動,確保安全距離,提高集體感應能力,并且可以根據環境或任務需求動態調整。在設計這樣的系統時,需要考慮個體之間的通信、同步、避障和路徑規劃等問題。
Formation通常和數學聯系較為緊密。
5.1 Preliminary

首先介紹拉普拉斯矩陣:
- 定義無向圖 G = ( v , ? ) \mathcal{G}=(\mathcal{v},\epsilon) G=(v,?), v v v頂點和 ? \epsilon ?邊。
- 度矩陣 D \bm D D是對角陣,對角線元素是各頂點邊的權值之和。
- 鄰接矩陣 A i j \bm A_{ij} Aij?:主對角線為0,上下三角分別是對應邊的權值。
- 拉普拉斯矩陣 L = D ? A \bm L=\bm D-\bm A L=D?A, D \bm D D和 A \bm A A沒有實際的數值計算,都是與0加減,主對角線元素是該列其他所有元素之和的相反數。
5.2 Consensus-based Control(基于共識的控制)
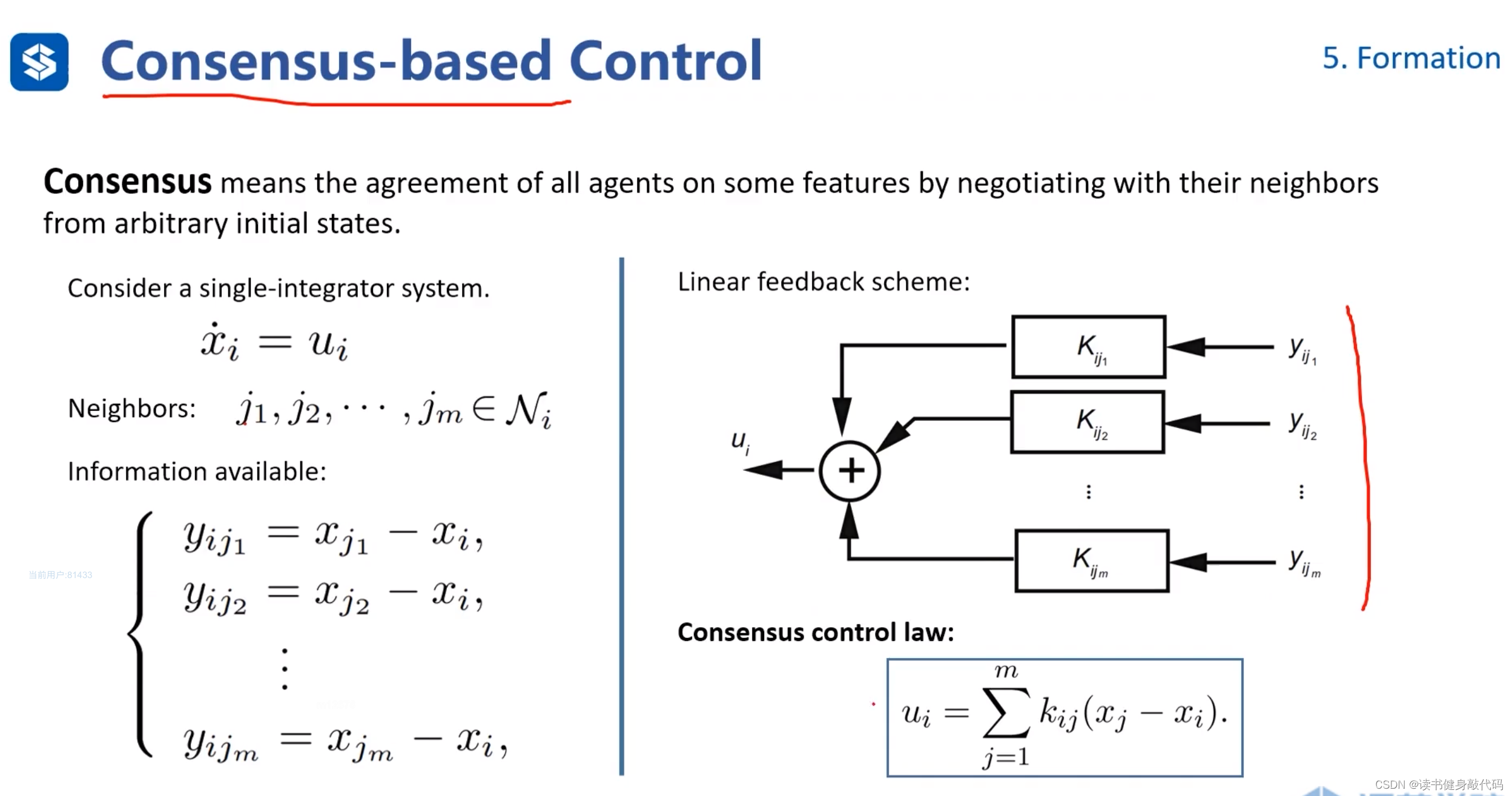
對于單積分系統 x i ˙ = u i \dot{x_i}=u_i xi?˙?=ui?,
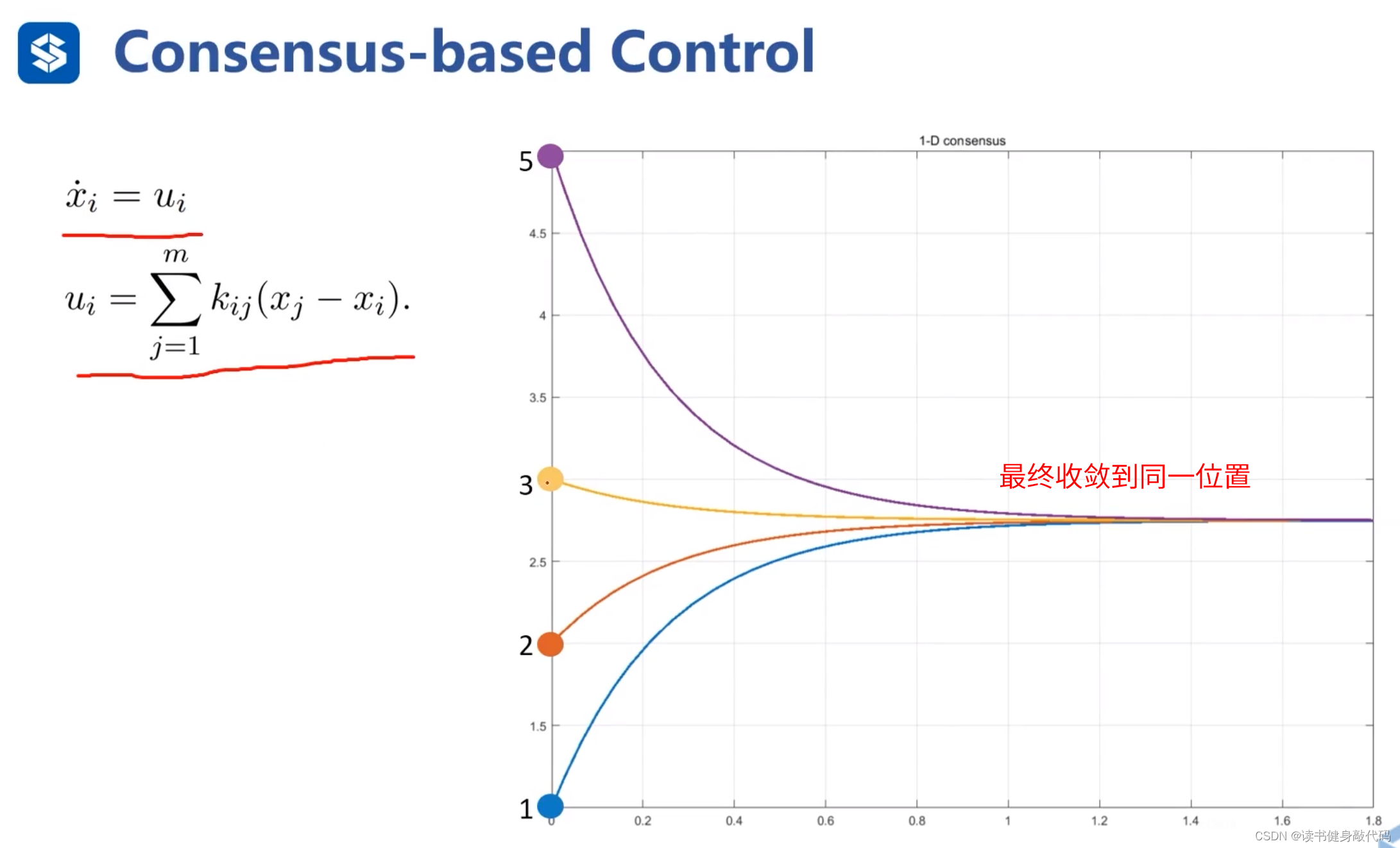
定義反饋量 y i j y_{ij} yij?,表示 x i x_i xi?周圍的鄰居agents分別到我的距離,最終目的是讓所有鄰居agents匯聚到同一點,可以證明這種控制規則是收斂的。
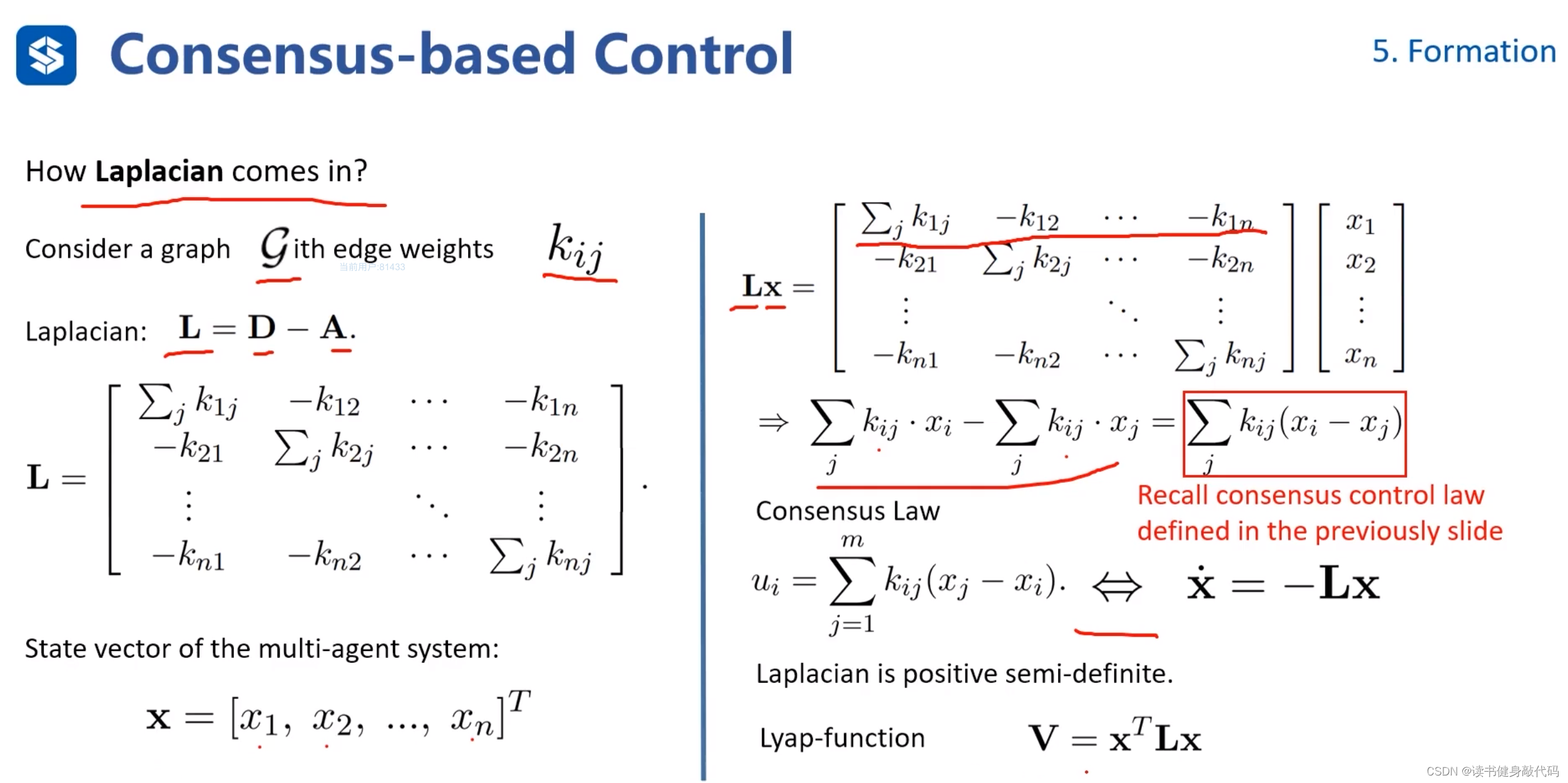
將Laplacian Matrix與狀態量相乘,我們發現相乘結果和前面定義的Consensus control law非常相似
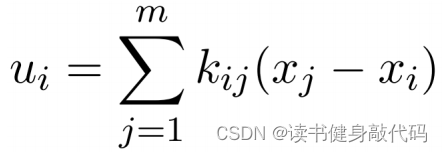
所以系統方程可整理為
x ˙ = L x \bm{\dot{x}}=\bm L \bm x x˙=Lx
可構造典型的李雅普諾夫函數 V = x T L x \bm V=\bm x^T \bm L \bm x V=xTLx該函數是半正定的。
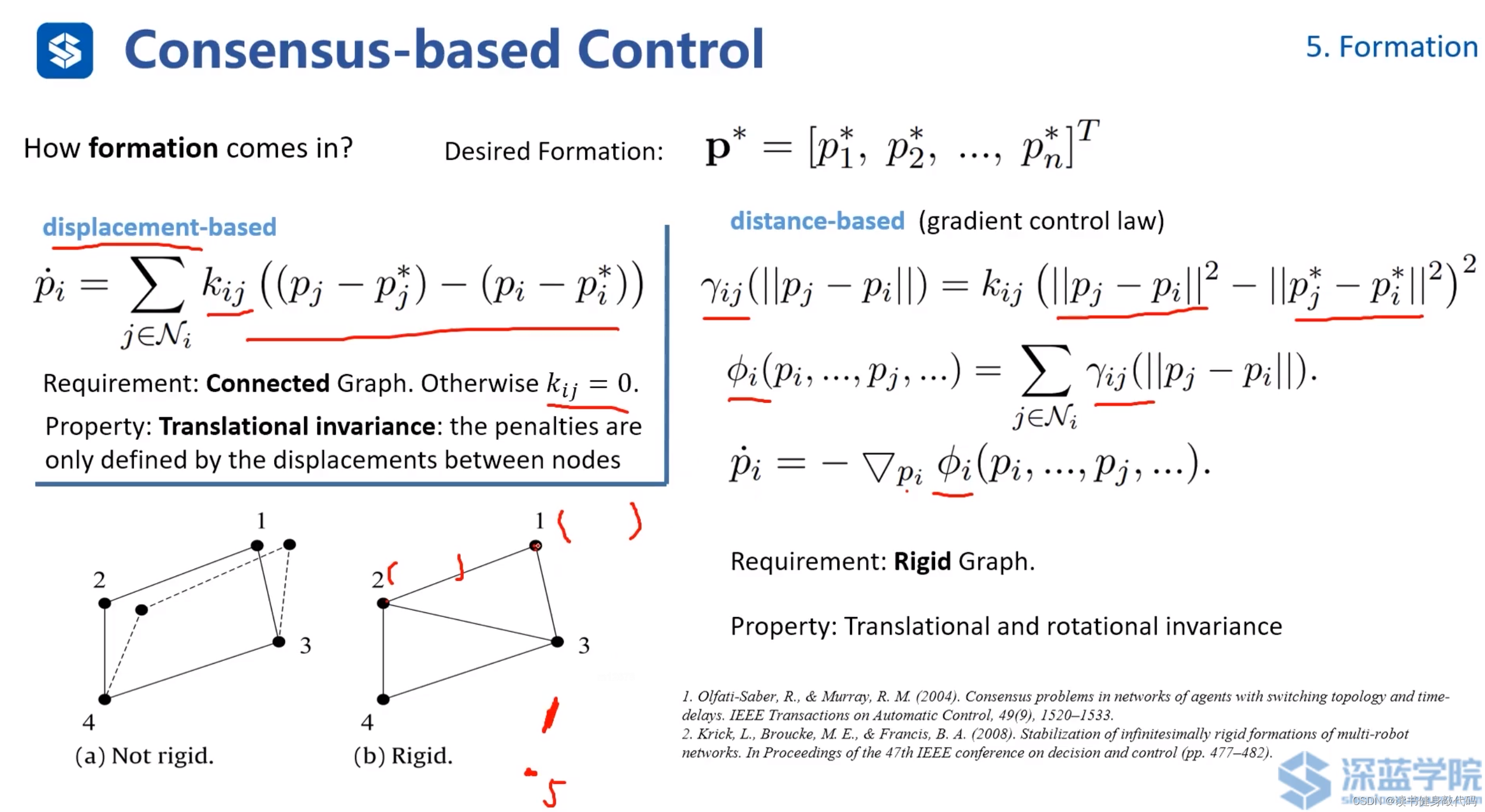
編隊的構造,講兩種方法:
- 基于偏移的編隊(ref[14]):為每個agent增加,一個平移偏移,最終為每個agents添加的偏移就成為了隊形。
要求:圖是connected的,即沒有孤立的節點。
特性:Translational invariance,整體平移并不改變隊形。 - 基于distance的編隊(ref[15]):根據其他agents到該agents的距離二范數構造 γ i j \gamma_{ij} γij?,將所有agents的 γ i j \gamma_{ij} γij?求和,構造目標函數,分別對各個agents求偏導得到一階導數,然后可以使用數值優化等方法(G-N等)求解。
5.3 Potential Field
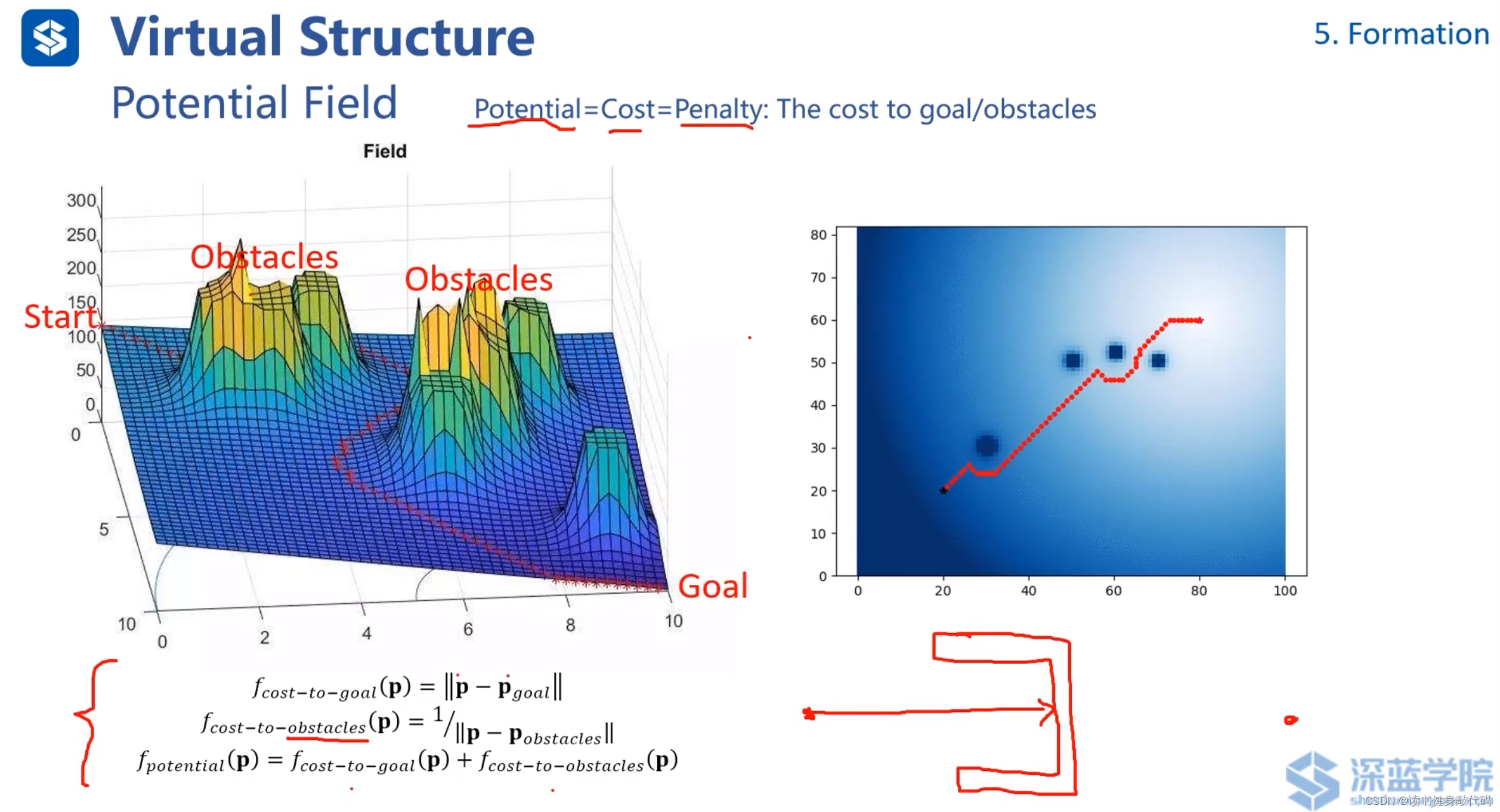
Potential Field 勢場法:是一種用于路徑規劃和避障的數學模型和算法,它通過模擬物理世界中的電磁場或重力場的概念來引導機器人或者其他自主體從起點移動到終點。
在勢場法中,目標位置被賦予吸引勢能,而障礙物則被賦予排斥勢能。移動的自主體(如機器人)被看作是在勢能場中的一點,它會受到力的作用,這些力是由其在空間中的位置所處的勢能梯度產生的。通過這種方法,自主體被勢能場引導,同時盡可能避開障礙物,最終到達目的地。
上圖的f也就是potential=cost=penalty, f c o s t ? t o ? g o a l f_{cost-to-goal} fcost?to?goal?代表從當前位置到達goal所需的cost, f c o s t ? t o ? o b s t a c l e s f_cost-to-obstacles fc?ost?to?obstacles代表距離障礙物的cost,距離障礙物越近,該項越大。
該方法的一個缺陷是容易陷入local minimum,如上圖的U形障礙物所示。
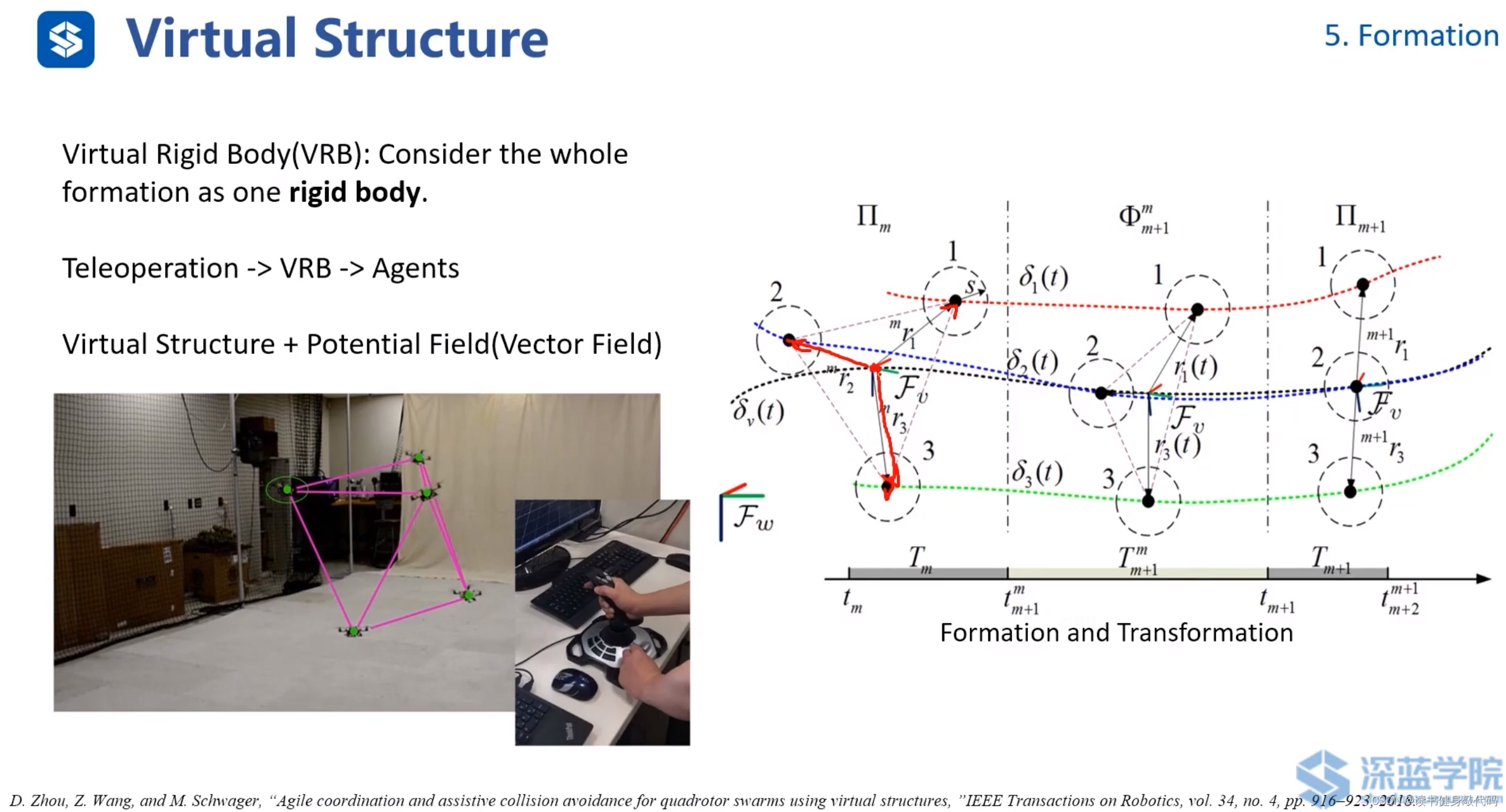
虛擬剛體VRB,不是直接操縱無人機,而是操縱虛擬的formation的中心,ref[17]。
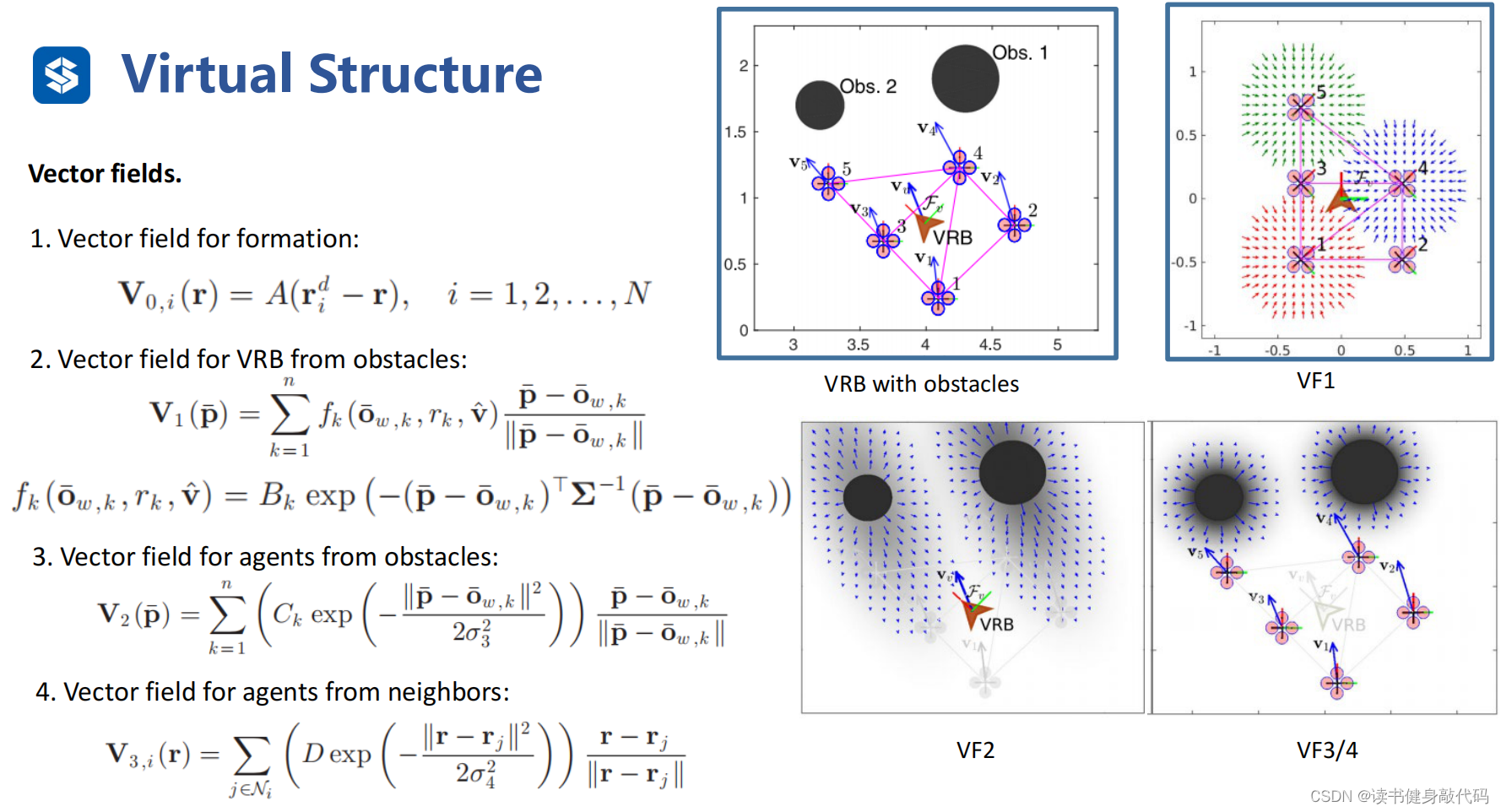
該方法的勢場(VF)由4部分組成:(公式可以不用仔細理解,需要時再看,此處僅做定性說明)
- VF1:Formation的勢場,如果勢場的中心發生偏移,該勢場會把中西往回拉。
- VF2:障礙物勢場,該勢場有方向,沿著速度方向,勢場較大,垂直速度方向勢場較小。
- VF3:agents到障礙物的勢場,大小均勻。
- VF4:agents之間的勢場,避免agents之間發生碰撞。
該方法和flocking model非常相近,特點也是對參數較為敏感,如果調參不好可能震蕩或者整個formation發散。
5.4 Shape Vector
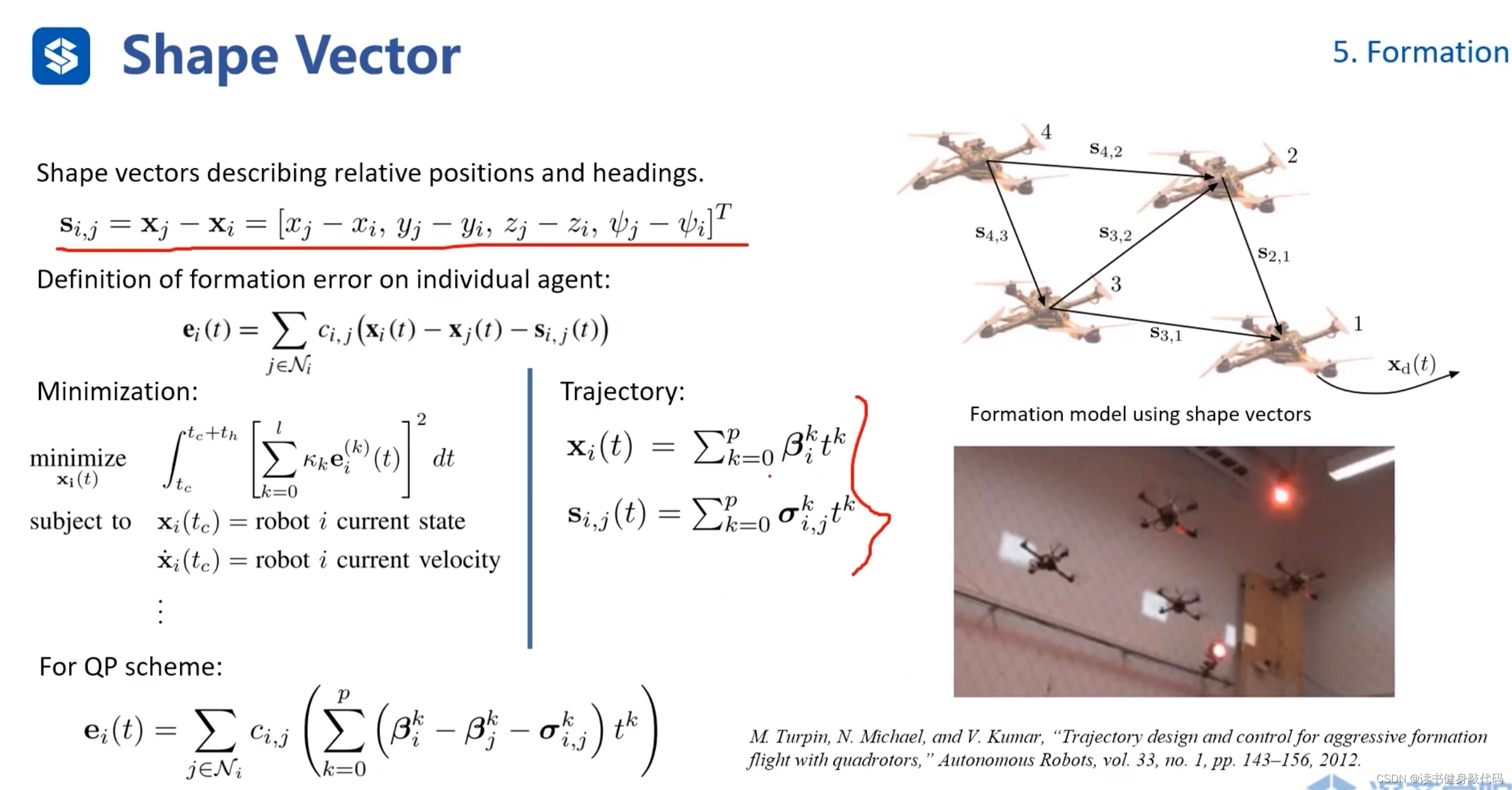
主要是定義方式上的差別,此處state定義為各個agents之間的位置和yaw角的差,然后把問題Formulation為QP問題進行求解,最終的trajectory的 x ( t ) , s ( t ) x(t),s(t) x(t),s(t)均為多項式。(ref[18])
5.5 Formation Rearrangement
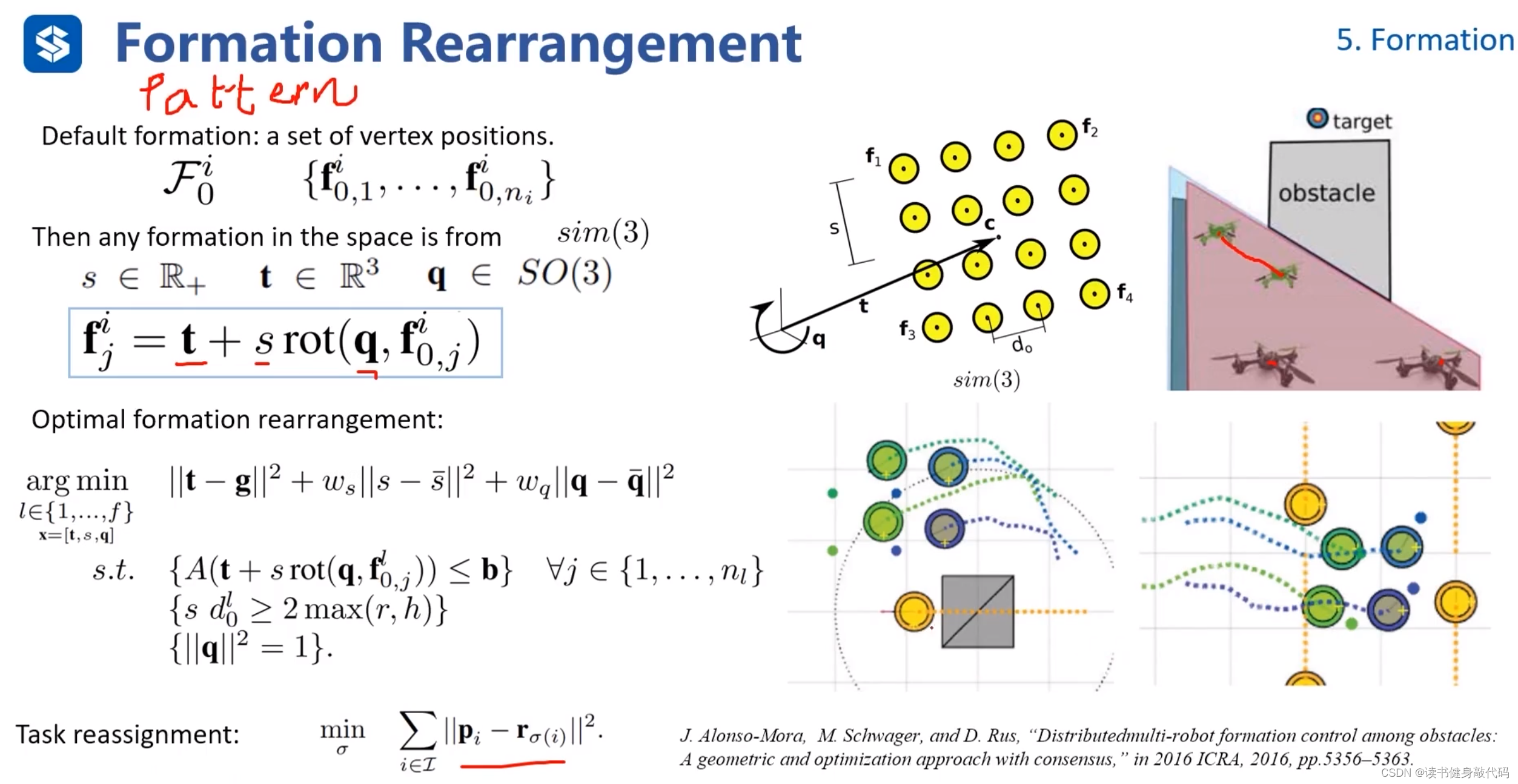
ref[19]
講的不太清楚,大致思路是:
把formation當做pattern,有了一個新的pattern,思考如何調整旋轉q,平移t,縮放s,來使得當前的pattern滿足新pattern。
中間的arg min是在定義一個調整上述q,t,s的優化框架,
task assignment是一個優化問題,指的是在formation過程中,所有的agents都是等價的,并不care哪架飛機在哪里,只考慮通過什么分配方式使得變為新formation整體的cost最小,該問題可使用旅行商問題等方法來求解。
5.6 Similarity Metric(相似性度量)
用于評估兩個運動、路徑或配置之間的相似度(ref[20])
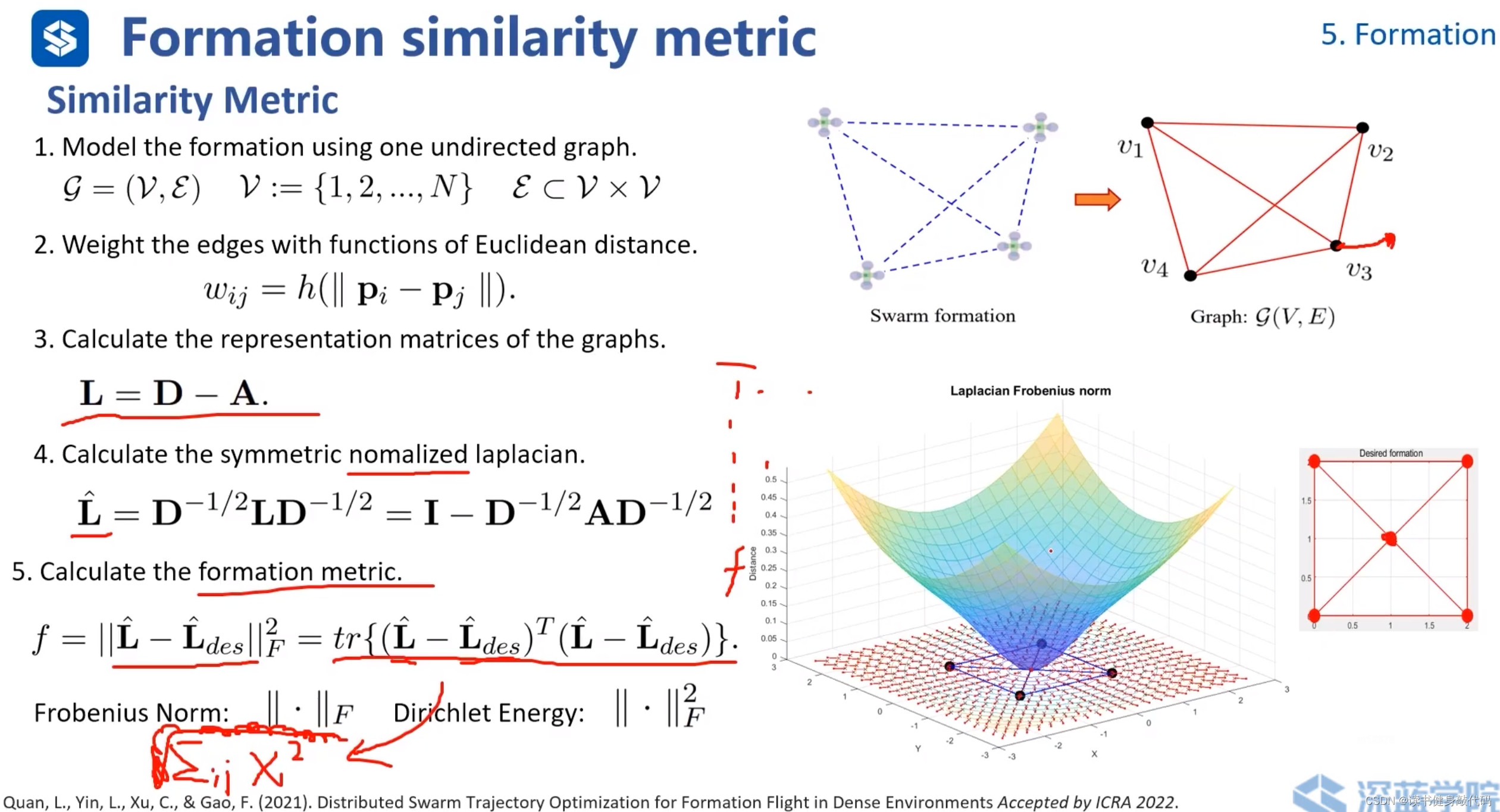
- formation以圖的形式表示。
- 以每個agents之間的歐氏距離作為圖的邊。
- 計算拉普拉斯矩陣。
- 對拉普拉斯矩陣進行歸一化,目的是降低由于主對角線元素數量級的差異而帶來的矩陣問題,避免某些大元素dominate整個矩陣。(使對角線元素變為1,剩下元素按照上圖第4點所示進行變換)
- 計算相似性度量指標 f f f, L ^ \bm{\hat{L}} L^為實際formation的拉普拉斯矩陣,期望的formation也可表示為圖的形式, L ^ d e s \bm{\hat{L}}_{des} L^des?為期望的formation的拉普拉斯矩陣,二者作差求F范數的平方,即某個運算的跡(數學可證明)。
上圖右側彩圖表示已有4個agents,關于第5個agent位置與 f f f的圖,可以看出,梯度都向外,按照梯度下降的準則,第5個agent最終落在正中間的才能使得 f f f最小,即與desired formation最相似。
方法特性:
- 平移,旋轉,縮放不變性
- translation invariance:在5.2節已經講解過平移不變形。
- rotation invariance:基于距離的formation對于ratation也是存在不變性的。
- scaling invariance:由于之前對拉普拉斯矩陣進行了normalization,對角線元素都為1,所以具有scaling invariance。
- 對于每一個agents都是可導的。這使得可以使用梯度下降等方法進行優化,使得問題收斂到一個較優的值。
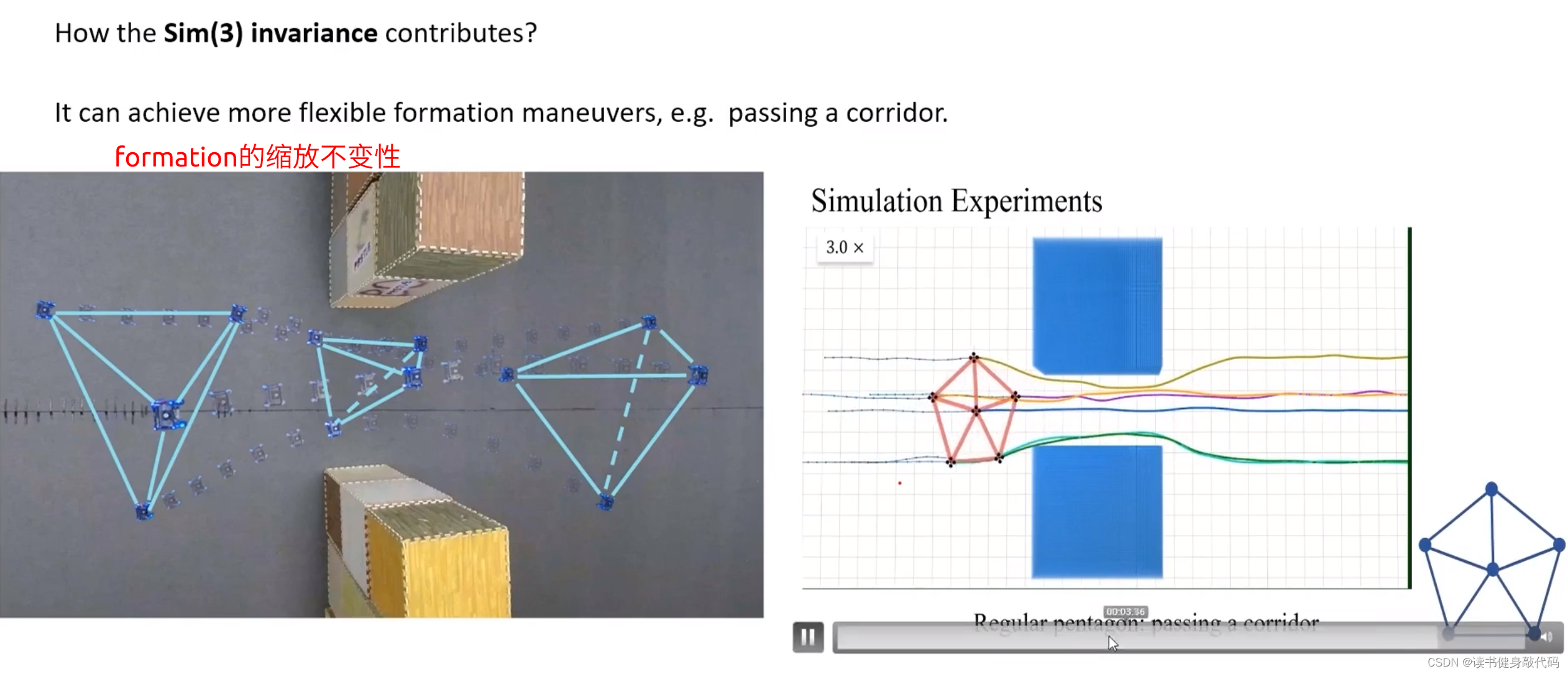
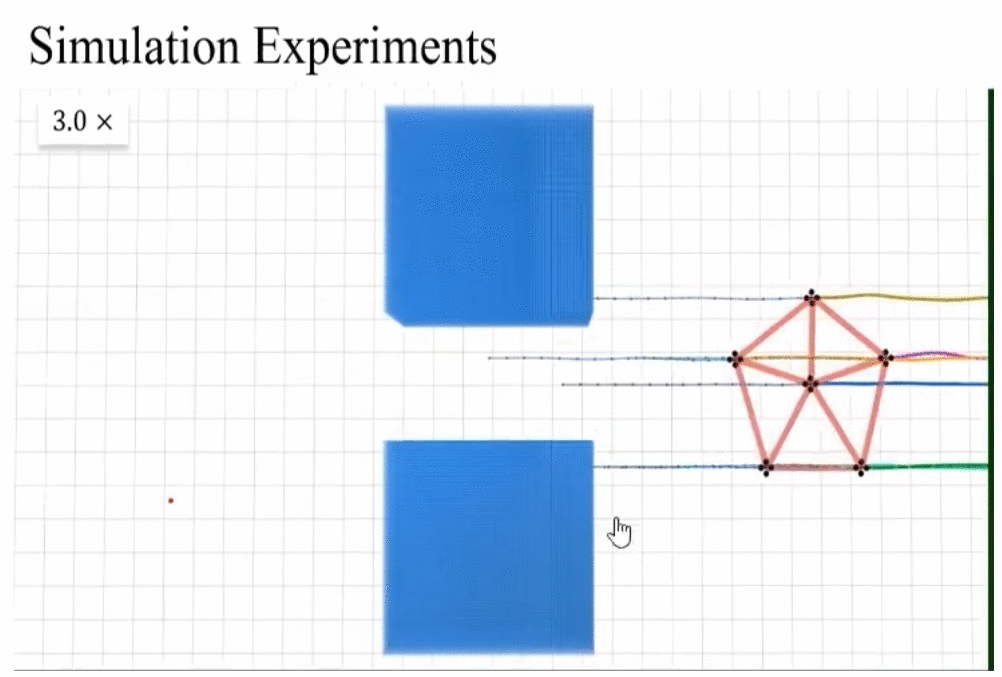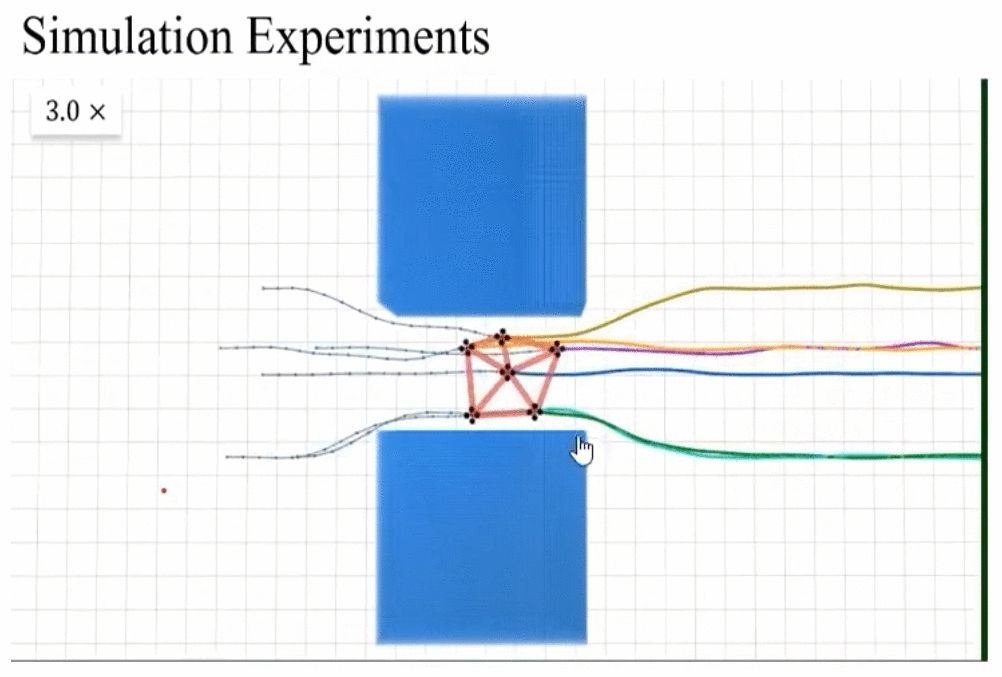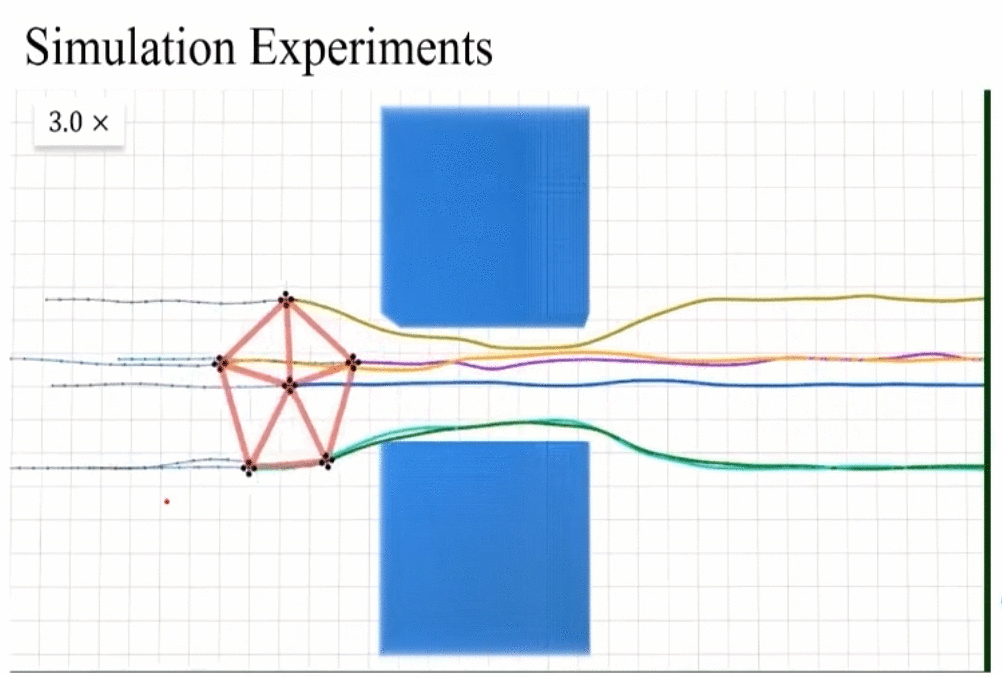
rescaling invariance實際測試和動圖展示。
6. Summary
- MAPF:圖搜索算法,有最優性保證,但是計算較慢,如果規模較小,可以使用圖表示,則ECBS是不錯的選擇。
- VO:連續的算法。輕量化,常用于游戲中。但控制量是速度,對于現實中無人機,汽車等擁有自身動力學模型的對象來說不太適用,因為無法做到速度跳變。
- Flocking Model(群落模型):用于模仿群落行為,是一種rule-based的方法,缺點是如果控制某個agent,對于整個群落可能產生不可預料的影響。
- Trajectory Planning for Swarms:能夠把約束等進行參數化,具有較高的自由度(ZJU Science工作在此部分,發展潛力較大)。缺點:計算量較大(如果是分布式計算,且問題復雜度確實較高,可能該方法也是個不錯的選擇)。
- Formation:關于集群的應用,處理多智能體系統的編隊運行。(講的比較粗略,如果有興趣可以閱讀原文)
后兩個方面屬于比較新的研究領域,所以講的也比較科普化,比較粗略,如果后需要深入研究,可從后兩個領域入手。
X. Reference
[1] Luna, Ryan J., and Kostas E. Bekris. “Push and swap: Fast cooperative path-finding with completeness guarantees.” Twenty-Second International Joint Conference on Artificial Intelligence. 2011.
[2] Silver, David. “Cooperative pathfinding.” Proceedings of the aaai conference on artificial intelligence and interactive digital entertainment. Vol. 1. No. 1. 2005.
[3] Standley, Trevor. “Finding optimal solutions to cooperative pathfinding problems.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 24. No. 1. 2010.
[4] Wagner, Glenn, and Howie Choset. “M*: A complete multirobot path planning algorithm with performance bounds.” 2011 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2011.
[5] Sharon, Guni, et al. “Conflict-based search for optimal multi-agent pathfinding.” Artificial Intelligence 219 (2015): 40-66.
[6] R?ger, Gabriele, and Malte Helmert. “The more, the merrier: Combining heuristic estimators for satisficing planning.” Twentieth International Conference on Automated Planning and Scheduling. 2010.
[7] Fiorini P, Shiller Z. Motion planning in dynamic environments using velocity obstacles[J]. The International Journal of Robotics Research, 1998, 17(7): 760-772.
[8] Van den Berg J, Lin M, Manocha D. Reciprocal velocity obstacles for real-time multi-agent navigation[C]. 2008 IEEE International Conference on Robotics and Automation. IEEE, 2008: 1928-1935.
[9] Van Den Berg J, Guy S J, Lin M, et al. Reciprocal n-body collision avoidance[M]. Robotics research. Springer, Berlin, Heidelberg, 2011: 3-19.
[10] Vásárhelyi, Gábor, et al. “Optimized flocking of autonomous drones in confined environments.” Science Robotics 3.20 (2018): eaat3536.
[11] H?nig, Wolfgang, et al. “Trajectory planning for quadrotor swarms.” IEEE Transactions on Robotics 34.4 (2018): 856-869.
[12] Tordesillas, Jesus, and Jonathan P. How. “MADER: Trajectory planner in multiagent and dynamic environments.” IEEE Transactions on Robotics (2021).
[13] Liu, Sikang, Kartik Mohta, Nikolay Atanasov, and Vijay Kumar. “Towards search-based motion planning for micro aerial vehicles.” arXiv preprint arXiv:1810.03071 (2018).
[14] Olfati-Saber, R., & Murray, R. M. (2004). Consensus problems in networks of agents with switching topology and timedelays. IEEE Transactions on Automatic Control, 49(9), 1520–1533.
[15] Krick, L., Broucke, M. E., & Francis, B. A. (2008). Stabilization of infinitesimally rigid formations of multi-robot networks. In Proceedings of the 47th IEEE conference on decision and control (pp. 477–482).
[16] Zhou, X., Wen, X., Wang, Z., Gao, Y., Li, H., Wang, Q., Yang, T., Lu, H., Cao, Y., Xu, C., & Gao, F. (2022). Swarm of micro flying robots in the wild. Science Robotics, 7.
[17] D. Zhou, Z. Wang, and M. Schwager, “Agile coordination and assistive collision avoidance for quadrotor swarms using virtual structures, ”IEEE Transactions on Robotics, vol. 34, no. 4, pp. 916–923, 2018.
[18] M. Turpin, N. Michael, and V. Kumar, “Trajectory design and control for aggressive formation
flight with quadrotors,” Autonomous Robots, vol. 33, no. 1, pp. 143–156, 2012.
[19] J. Alonso-Mora, M. Schwager, and D. Rus, “Distributedmulti-robot formation control among obstacles:
A geometric and optimization approach with consensus,” in 2016 ICRA, 2016, pp.5356–5363.
[20] Quan, L., Yin, L., Xu, C., & Gao, F. (2021). Distributed Swarm Trajectory Optimization for Formation Flight in Dense Environments Accepted by ICRA 2022.










)


)





