一、引言
? ? ? ? 最近SORA火爆刷屏,我也忍不住找來官方報告分析了一下,本文將深入探討OpenAI最新發布的Sora模型。Sora模型不僅僅是一個視頻生成器,它代表了一種全新的數據驅動物理引擎,能夠在虛擬世界中模擬現實世界的復雜現象。本文將重點分析Sora模型的創新之處,以及它是如何通過大規模數據訓練和先進的算法技術,實現對視頻內容的高質量生成。
????????Sora模型的出現,標志著AI在視頻生成領域的一次重大飛躍。它不僅能夠生成逼真的視頻內容,還能夠模擬物理世界中的物體運動和交互,這對于電影制作、游戲開發、虛擬現實以及未來可能的通用人工智能(AGI)研究都有著深遠的影響。
????????文中將根據官方報告詳細介紹Sora模型的架構、關鍵技術特點以及它在模擬數字世界中的應用。還將討論Sora模型的訓練過程,以及根據最近的一些論文推測一下可行性。

二、Sora模型概述
Sora模型是由OpenAI開發的一種先進的視頻生成模型,它采用了擴散型變換器(diffusion transformer)架構,這是一種基于深度學習的模型,能夠將隨機噪聲逐漸轉化為有意義的圖像或視頻內容。Sora模型的核心在于其能夠處理和生成具有復雜動態和空間關系的高質量視頻,這在以往的視頻生成技術中是難以實現的。
與傳統的視頻生成模型相比,Sora模型在以下幾個方面展現出了顯著的優勢:
????????多模態輸入處理:Sora能夠理解和處理文本提示,將用戶的描述轉化為視頻內容,這使得模型能夠生成與用戶意圖高度一致的視頻。
????????空間和時間的統一表示:通過將視頻分解為時空補丁(Spacetime Patches),Sora模型能夠在一個統一的框架下處理不同分辨率、持續時間和寬高比的視頻,這大大增強了模型的靈活性和可擴展性。
????????大規模訓練數據:Sora模型的訓練基于大規模的視頻數據集,這使得它能夠學習到豐富的視覺和運動模式,從而生成更加逼真和多樣化的視頻內容。
????????物理世界模擬:Sora模型展現出了模擬物理世界的能力,例如,它能夠生成具有連貫三維空間運動的視頻,以及模擬物體之間的物理交互。
????????長期依賴關系處理:Sora模型能夠有效地處理視頻中的長期依賴關系,這對于生成連貫且具有邏輯性的視頻內容至關重要。
三、關鍵技術特點
????????Sora模型的技術特點體現了其在視頻生成領域的創新和突破。以下是Sora模型的一些關鍵技術亮點:
三維空間連貫性
????????動態相機運動:Sora能夠生成包含動態相機運動的視頻,這意味著視頻中的人物和場景元素能夠在三維空間中保持連貫的運動。例如,當相機移動或旋轉時,視頻中的物體會相應地改變位置,就像在現實世界中一樣。
????????空間一致性:Sora能夠確保視頻中的物體在空間上保持一致性,即使在復雜的場景變換中也能保持正確的相對位置和運動軌跡。
模擬數字世界
????????Minecraft游戲模擬:Sora能夠模擬人工過程,如視頻游戲。通過提及“Minecraft”的提示,Sora能夠零樣本地激發其模擬游戲世界的能力,包括控制游戲中的角色和渲染游戲環境。
????????高保真渲染:Sora在模擬數字世界時,能夠實現高保真的渲染效果,使得生成的視頻內容看起來就像真實游戲畫面一樣。
長期連續性和物體持久性
????????角色和物體的一致性:Sora能夠在視頻中保持角色和物體的長期一致性,即使在視頻中出現遮擋或離開畫面的情況,Sora也能保持其存在和外觀。
????????視頻內容的連貫性:Sora能夠生成具有連貫故事線的視頻,確保視頻中的事件和動作在時間上是連續的,沒有突兀的跳躍。
與世界互動
????????簡單影響行為模擬:Sora能夠模擬一些簡單的與世界互動的行為,如畫家在畫布上留下筆觸,或者人物在吃食物時留下痕跡。這些行為不是預設的規則,而是模型通過學習大量數據后自然涌現的能力。
????????這些技術特點不僅展示了Sora模型在視頻生成方面的高級能力,也預示著AI在理解和模擬復雜物理世界方面的巨大潛力。
四、訓練過程與方法
????????Sora模型的訓練過程是其技術實現的核心部分,涉及多種創新方法和策略,以確保模型能夠學習和生成高質量的視頻內容。以下是Sora模型訓練的關鍵步驟和方法:
擴散型變換器模型(Diffusion Transformer)
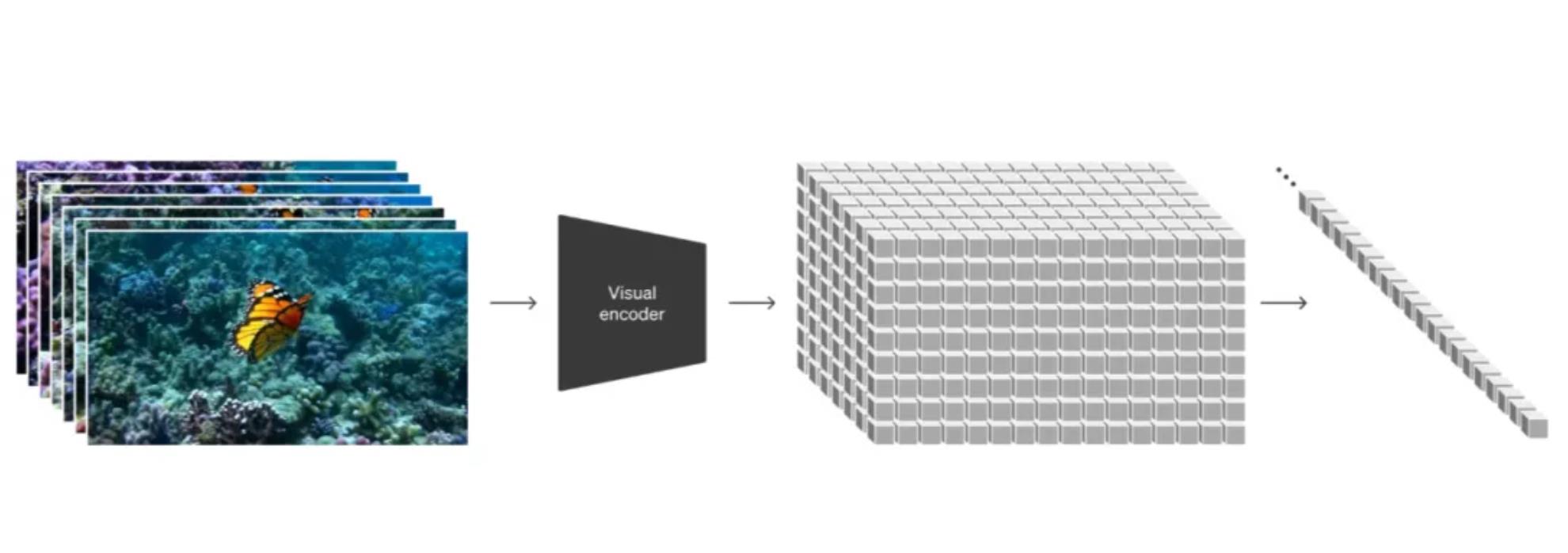
????????視頻壓縮與潛在空間:Sora模型首先將視頻數據壓縮到一個低維潛在空間,這個空間包含了視頻的基本信息。在這個空間中,模型通過學習如何從噪聲中恢復出清晰的視頻內容,從而實現視頻生成。
????????時空補丁(Spacetime Patches):視頻被分解為一系列時空補丁,這些補丁在變換器模型中充當標記(tokens)。這種表示方法允許模型處理不同分辨率、持續時間和縱橫比的視頻和圖像。
訓練網絡與解碼器
????????視覺數據維度降低:Sora訓練了一個網絡,該網絡將原始視頻輸入并輸出在時間和空間上壓縮的潛在表示。同時,還訓練了一個解碼器模型,將生成的潛在表示映射回像素空間,從而生成視頻。
????????大規模訓練:Sora模型在大規模數據集上進行訓練,這些數據集包含了多樣化的視頻內容和相應的文本描述。這種大規模訓練使得模型能夠學習到豐富的視覺和運動模式。
語言理解與字幕生成
????????重字幕技術:Sora利用了DALL·E 3中的重字幕技術,為訓練集中的所有視頻生成高度描述性的文本字幕。這提高了視頻內容的文本保真度,使得生成的視頻更加符合用戶的描述。
????????GPT技術應用:Sora還利用了GPT技術,將用戶的簡短提示轉換成更詳細的字幕,然后發送給視頻模型。這使得Sora能夠更準確地遵循用戶的意圖生成視頻。
可變持續時間與分辨率訓練
????????原生縱橫比支持:Sora在訓練時沒有對素材進行裁剪,而是直接在原始大小的數據上進行訓練。這使得Sora能夠直接為其原生縱橫比為不同設備創建內容,提高了構圖和取景的質量。
涌現模擬能力
????????大規模訓練的成果:隨著訓練計算量的增加,Sora展現出了三維一致性、長序列連貫性和物體持久性等新能力。這些能力是模型在大規模訓練后自然涌現的,而非通過預設規則實現。
????????這些內容是根據官方報告給出的,但是事實上的這些描述并沒有細化到可以作為方法論層面的操作解釋。最多只能作為一個方向性的闡述,有點像大概描述的步驟。頗有售前工程師忽悠甲方的味道。不過,OpenAI的牌子在,還是讓人不得不仔細地思考與討論。正好最近掃過一篇論文,標題是《WORLD MODEL ON MILLION-LENGTH VIDEO AND LANGUAGE WITH RINGATTENTION》,作者是Hao Liu、Wilson Yan、Matei Zaharia和Pieter Abbeel,來自加州大學伯克利分校。詳細地闡述了一個7B參數的長視頻與環形注意力的多模態大模型訓練方法。如果Sora能夠有這樣的論文披露,那么可能我們的討論與思考會更有效一些。
五、應用場景與潛力
????????Sora模型的應用場景廣泛,其潛力在于能夠為多個行業帶來革命性的變化。以下是Sora模型的一些潛在應用:
電影與娛樂產業:
????????特效制作:Sora可以用于生成逼真的特效場景,減少對實際拍攝和后期制作的依賴,降低成本。
????????故事板與預覽:導演和制片人可以利用Sora快速生成電影場景的預覽,幫助決策和創意發展。
游戲開發:
????????游戲內容生成:Sora能夠為游戲開發者提供豐富的視覺素材,加速游戲內容的創作過程。
????????交互式故事講述:在角色扮演游戲(RPG)中,Sora可以生成與玩家互動的動態視頻,增強游戲體驗。
教育與培訓:
????????模擬訓練:Sora可以生成各種模擬場景,用于醫學、軍事、航空等領域的專業培訓。
????????語言學習:通過生成與語言學習相關的視頻內容,Sora可以幫助學習者更好地理解和記憶新詞匯和語法。
廣告與營銷:
????????創意內容生成:Sora可以快速生成吸引人的廣告視頻,幫助品牌在競爭激烈的市場中脫穎而出。
????????個性化營銷:利用Sora生成定制化的視頻內容,滿足不同用戶群體的需求。
虛擬現實(VR)與增強現實(AR):
????????虛擬環境構建:Sora可以為VR和AR應用生成逼真的虛擬環境,提供沉浸式體驗。
????????交互式內容:在AR應用中,Sora可以生成與現實世界互動的視頻內容,增強用戶體驗。
科學研究與模擬:
????????物理模擬:Sora可以用于模擬復雜的物理現象,如流體動力學、天體運動等,輔助科學研究。
????????歷史重現:通過生成歷史事件的視頻,Sora可以幫助學者和公眾更好地理解歷史。
????????Sora模型的潛力在于其能夠模擬和生成多樣化、高質量的視頻內容,這為創意產業、教育、科研等領域提供了新的可能性。隨著技術的不斷進步,Sora模型的應用范圍將不斷擴大,為人類社會帶來更多的便利和創新。
六、局限性與未來展望
????????Sora模型雖然在視頻生成領域取得了顯著的進展,但它仍然存在一些局限性,這些局限性主要體現在以下幾個方面:
物理交互的準確性:盡管Sora能夠模擬一些基本的物理交互,如物體的運動和相機的移動,但它在處理更復雜的物理現象時可能會遇到困難。例如,模型可能無法準確模擬玻璃破碎、液體流動等復雜物理過程。
長期依賴關系的處理:在生成長視頻時,Sora可能在保持時間上的一致性和邏輯性方面存在挑戰。這可能導致視頻中出現不連貫的事件或者物體狀態的突變。
空間細節的精確性:Sora在處理空間細節方面可能不夠精確,例如在區分左右或者描述隨時間變化的事件時可能會出現錯誤。這可能影響到視頻內容的準確性和可信度。
模型的可解釋性:Sora模型的內部工作機制相對復雜,這使得理解模型如何生成特定視頻內容變得困難。提高模型的可解釋性對于其在關鍵領域的應用至關重要。
計算資源的需求:Sora模型的訓練和運行需要大量的計算資源,這限制了其在資源有限環境下的應用。特別是在實時視頻生成或移動設備上的應用,計算資源的需求可能成為一個瓶頸。
數據偏差和倫理問題:Sora模型的訓練數據可能存在偏差,這可能導致生成的視頻內容反映出這些偏差。此外,生成的視頻可能被用于不道德或有害的目的,如制造虛假新聞或誤導性內容。
創意和藝術表達的限制:雖然Sora能夠根據文本提示生成視頻,但它可能無法完全捕捉到人類藝術家的創意和情感表達。在藝術創作領域,AI生成的內容可能缺乏深度和個性化。
交互性和反饋:Sora模型目前主要側重于單向的視頻生成,缺乏與用戶交互和根據反饋進行調整的能力。這限制了模型在需要實時互動和個性化定制的應用場景中的潛力。
為了克服這些局限性,未來的研究需要在提高物理模擬的準確性、增強長期依賴關系的處理能力、優化計算效率、提高模型可解釋性、處理數據偏差以及增強交互性等方面進行深入探索。隨著技術的不斷進步,Sora模型有望在視頻生成領域實現更多的突破。
七、結論與分析
????????Sora模型作為OpenAI在視頻生成領域的一次重要嘗試,展示了AI在理解和模擬復雜視覺內容方面的巨大潛力。它的出現不僅為視頻內容創作提供了新工具,也為AI技術在其他領域的應用提供了新思路。隨著技術的不斷進步,可以期待Sora模型能夠克服現有局限性,為人類社會帶來更多的創新和價值。
????????根據官方報告展示出來的Sora特性,尤其是對于三維空間連貫性,延伸思考一下就會有些問題。
????????報告解讀中Sora模型確實展現出了三維空間連貫性的能力,這意味著它能夠生成具有正確空間關系和動態相機運動的視頻內容。然而,這并不意味著Sora模型可以直接生成三維建模軟件中使用的參數。Sora模型的主要目標是生成二維視頻幀,而不是直接創建三維模型的參數。
????????盡管Sora能夠模擬三維空間中的物體運動和相機視角變化,但它生成的仍然是視頻序列,這些視頻序列在視覺上呈現出三維效果,但實際上仍然是二維圖像序列。在這些視頻中,物體和場景元素的三維位置和運動是通過二維圖像的連續變化來模擬的,而不是通過實際的三維模型數據。要生成三維建模的參數,通常需要使用專門的三維建模軟件,如Blender、Maya或3ds Max等,這些軟件能夠創建和編輯三維對象、場景和動畫。在這些軟件中,用戶可以精確地定義物體的形狀、紋理、材質以及在三維空間中的位置和運動軌跡。
????????當然,Sora模型的三維空間連貫性能力還是為未來可能的三維內容生成提供了有趣的研究方向。例如,研究者可以探索如何將Sora模型與三維建模軟件結合,利用Sora生成的二維視頻幀作為參考,輔助三維模型的創建和動畫制作。這樣的結合可能會簡化三維內容的創作過程,提高效率,并為藝術家和設計師提供新的創作工具。
????????但是對于二維視頻的仿3D形態,這又需要進行復雜的真實性校驗。就好像盜夢空間里的視角無法平移到真實世界中去一樣。所以這個世界模擬器的局限性還是挺明顯的。這一點,單純依賴視頻和語料的模態組合可能很難有突破,如果采用真三維的點云數據也許是個不錯的方向。
????????還有,就是關于世界模擬器和世界模型的辨析。世界模型的設計需要有客觀的角度,將大模型作為具身形態在其中進行交互,進而形成接近于真實的訓練學習過程。而世界模擬器,僅僅是模擬視頻反饋,并通過大量語料結合反饋閉環。這樣的體系也許還需要像我之前列出的那篇世界模型多模態訓練的論文一樣,做出更多的基礎工作。但不管怎樣,我都不希望Sora像Gemini的官方報告一樣事后出現反轉。這是OpenAI的一小步,卻真的有可能是人類的一大步……
參考文獻
SORA的官方報告解讀與思考:SORA的官方報告解讀與思考_風聞
以上內容僅代表個人的一些看法與觀點。
![[力扣 Hot100]Day33 排序鏈表](http://pic.xiahunao.cn/[力扣 Hot100]Day33 排序鏈表)


與reactive())






)




與神經網絡中的激活函數)

)

