文章目錄
前言
一、Encoder 家族
1. BERT
2. DistilBERT
3. RoBERTa
4. XML
5. XML-RoBERTa
6. ALBERT
7. ELECTRA
8. DeBERTa
二、Decoder 家族
1. GPT
2. GPT-2
3. CTRL
4. GPT-3
5. GPT-Neo / GPT-J-6B
三、Encoder-Decoder 家族
1. T5
2. BART
3. M2M-100
4. BigBird
前言
最初的Transformer是基于廣泛應用在機器翻譯領域的Encoder-Decoder架構:
Encoder:
將由 token 組成的輸入序列轉成由稱為隱藏狀態(hidden state)或者上下文(context)的embedding向量組成的序列。
Decoder:
根據 Encoder 的隱藏狀態迭代生成組成輸出序列的 token。

從上圖我們可以看到:
- 輸入文本被?tokenized 成 token embedding。由于注意力機制不知道 token 的相對位置,因此我們需要一種方法將一些有關 token 位置的信息注入到輸入中,以對文本的順序性質進行建模。因此,token embedding 與包含每個 token? 的位置信息的 position embedding 相組合。
- encoder 由一堆 encoder 層組成,類似于計算機視覺中堆疊的卷積層。decoder也是如此,它有自己的 decoder 層塊。
- encoder 的輸出被饋送到每隔 decoder 層,然后 decoder 生成序列中最可能的下一個 token 的預測。然后,此步驟的輸出被反饋到 decoder 以生成下一個 token,依次類推,直到到達特殊的序列結束(End of Sequence,EOS)token。以上圖為例,想象一下 decoder 已經預測了“Die”和“Zeit”。現在,它將根據這兩個預測 token 以及所有 encoder 的輸出來預測下一個 token “fliegt”。在下一步中,decoder 繼續將“fliegt”作為附加輸入。我們重復這個過程,直到 decoder 預測出 EOS token 或者達到最大輸出長度限制。
Transformer 架構最初是為機器翻譯等序列到序列任務而設計的,但 encoder 和 decoder 塊很快就被改編為獨立模型。盡管現在有數千種不同的?Transformer 模型,但大多數屬于以下三種類型之一:
(1)Encoder-only
這些模型將文本輸入序列轉換為豐富的數字表示,非常適合文本分類或命名實體識別等任務。BERT(Bidirectional Encoder Representation Transformers)及其變體,例如 RoBERTa 和 DistilBERT,都屬于此類架構。在該架構中為給定 token 計算的表示取決于左側(token之前)和右側(token之后)的上下文。所以通常稱為雙向注意力(bidirectional attention)。
(2)Decoder-only
用戶給定一段文本提示,這些模型將通過迭代預測最可能出現的下一個單詞來自動補充余下的文本。GPT(Generative Pretrained Transformer)模型系列屬于此類。在該架構中為給定 token 計算的表示僅取決于左側上下文。所以通常稱為因果注意力(causal attention)或自回歸注意力(autoregression attention)。
(3)Encoder-Decoder
它們用于對從一個文本序列到另一個文本序列的復雜映射進行建模,比如機器翻譯和文本摘要。除了我們所看到的結合了 encoder 和 decoder 的Transformer 架構之外,BART(Bidirectional Auto-Regressive Transformers)和 T5(Text-To-Text Transfer Transformer)模型也屬于此類。
實際上,decoder-only 架構和 encoder-only 架構的應用程序之間的區別有點模糊。例如,GPT 系列中的純 decoder 模型可以為翻譯等任務做好準備,這些任務通常被認為是序列到序列的任務。類似地,像 BERT 這樣的純 encoder 模型可以應用于通常與 encoder-decoder 或純 decoder 模型相關的摘要任務。
隨著時間的推移,三種主要架構都經歷了自己的演變。
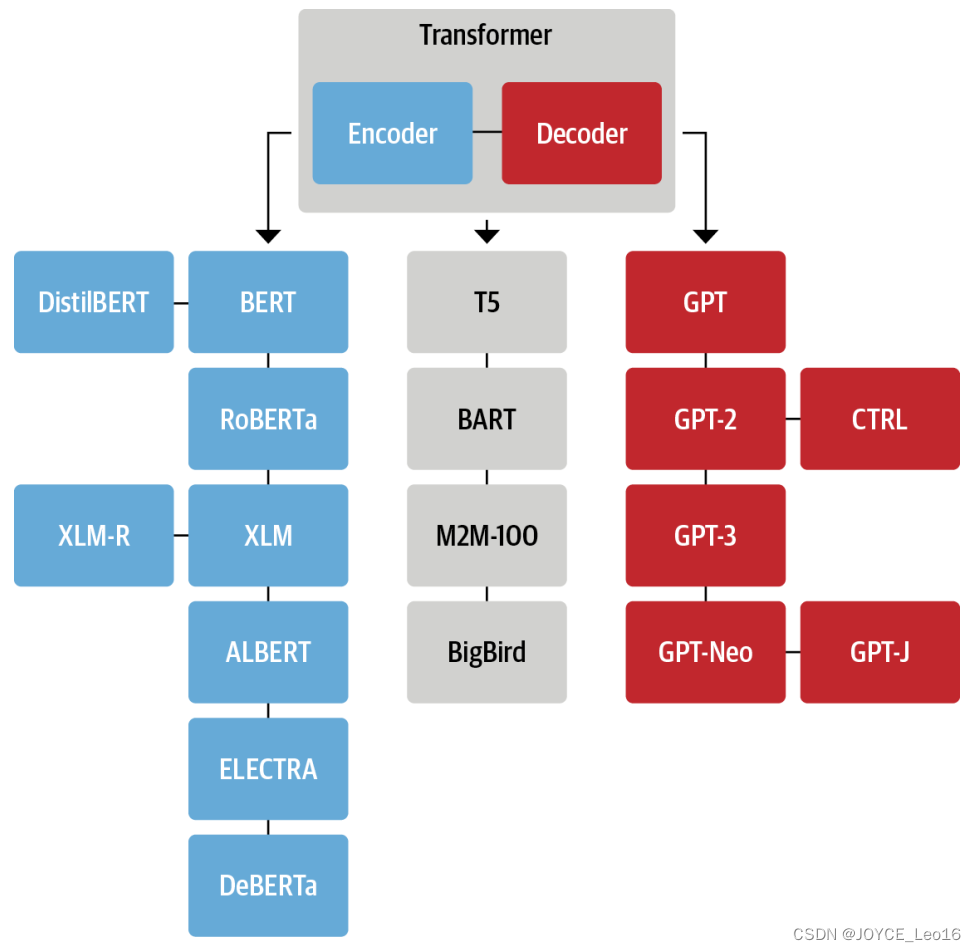
上圖這個家譜只是突出顯示了一些架構里程碑。
一、Encoder 家族
第一個基于 Transformer 架構的 encoder-only 模型是 BERT。encoder-only?模型仍然主導著 NLU(Natural Language Understanding)任務(例如文本分類、命名實體識別和問題解答)的研究和行業。接下來簡單介紹一下 BERT 模型及其變體:
1. BERT
BERT?的預訓練目標有兩個:預測文本中的 mask token;確定一個文本段落是否緊跟著另一個文本段落。前一個任務稱為 Masked Language Modeling(MLM),后一個稱為?Next Sentence Prediction(NSP)。
2. DistilBERT
盡管BERT的預測能力很強,但是由于其龐大的尺寸,我們無法在低延遲要求的生產環境中部署。通過在預訓練過程中使用知識蒸餾(knowledge distillation)技術,DistilBERT 可以達到BERT 97% 的性能,但是體積僅有BERT的 40%,速度比BERT快60%。
3. RoBERTa
BERT 發布后的一項研究表明,通過修改預訓練方案可以進一步提高其性能。RoBERTa 的訓練時間更長、批次更大、訓練數據更多,并且它放棄了 NSP 任務。總之,與原始 BERT 模型相比,這些變化顯著提高了其性能。
4. XML
在跨語言語言模型 (cross-lingual language model,XLM) 的工作中,探索了構建多語言模型的幾個預訓練目標,包括來自類 GPT 模型的自回歸語言建模和來自 BERT 的 MLM。此外,XLM 預訓練論文的作者介紹了翻譯語言模型(translation language modeling,TLM),它是 MLM 對多語言輸入的擴展。通過對這些預訓練任務進行實驗,他們在多個多語言 NLU 基準測試以及翻譯任務上取得了領先成績。
5. XML-RoBERTa
繼 XLM 和 RoBERTa 的工作之后,XLM-RoBERTa 或 XLM-R 模型通過大規模升級訓練數據,使多語言預訓練更進一步。使用?Common Crawl?語料庫,其開發人員創建了一個包含 2.5TB 文本的數據集;然后他們在這個數據集上用 MLM 訓練了一個 encoder。由于數據集僅包含沒有并行文本(即翻譯)的數據,因此 XLM 的 TLM 目標被刪除。這種方法大幅擊敗了 XLM 和多語言 BERT 變體,尤其是在缺乏足夠語料的語言上。
6. ALBERT
ALBERT模型引入了三個變化,使encoder 架構更加高效。首先,它將 token embedding 維度與隱藏維度解耦,從而允許 embedding 維度較小,從而節省參數,尤其是當詞匯量變大時。其次,所有層共享相同的參數,這進一步減少了有效參數的數量。最后,NSP目標被句子排序預測取代:模型需要預測兩個連續句子的順序是否交換,而不是預測它們是否屬于在一起。這些變化使得用更少的參數訓練更大的模型成為可能,并在NLU任務上達到卓越的性能。
7. ELECTRA
標準MLM預訓練目標的一個限制是,在每個訓練步驟中,僅更新 mask token 的表示,而其他輸入token則不更新。為了解決這個問題,ELECTRA使用雙模型方法:第一個模型(通常很小)的工作原理類似于標準 masked language model,并預測 mask token。第二個模型稱為鑒別器,然后負責預測第一個模型輸出中的哪些 token是最初的 mask token。因此,判別器需要對每個 token進行二分類,這使得訓練效率提高了30倍。對于下游任務,鑒別器像標準 BERT 模型一樣進行微調。
8. DeBERTa
DeBERTa 模型引入了兩個架構變化。首先,每個 token 都表示為兩個向量:一個表示內容,另一個表示相對位置。通過將 token 的內容與其相對位置分開,自注意力層可以更好地對附近 token 對的依賴性進行建模。另一方面,單詞的絕對位置也很重要,尤其是對于解碼而言。因此,在 token 解碼頭的 softmax 層之前添加了絕對 position embedding。DeBERTa 是第一個在 SuperGLUE 基準測試上擊敗人類基線的模型,SuperGLUE 基準測試是 GLUE 的更困難版本,由多個用于衡量 NLU 性能的子任務組成。
二、Decoder 家族
Transformer decoder 模型的進展在很大程度上是由OpenAI引領的。這些模型非常擅長預測序列中的下一個單詞,因此主要用于文本生成任務。它們的進步是通過使用更大的數據集并將語言模型擴展到越來越大的尺寸來推動的。
1. GPT
GPT的引入結合了NLP中的兩個關鍵思想:新穎高效的Transformer decoder 架構和遷移學習。在該設置中,通過 根據先前的單詞預測下一個單詞來對模型進行預訓練。該模型在 BookCorpus 上進行訓練,并在分類等下游任務上取得了很好的效果。
2. GPT-2
受到簡單且可擴展的預訓練方法成功的啟發,通過升級原始模型和訓練集誕生了 GPT-2。該模型能夠生成連貫文本的長序列。由于擔心可能被濫用,該模型以分階段的方式發布,先發布較小的模型,然后發布完整的模型。
3. CTRL
像GPT-2這樣的模型可以繼續輸入序列(也稱為提示:prompt)。然而,用戶對生成序列的樣式幾乎沒有控制權。CTRL(Conditional Transformer Language)模型通過在序列開頭添加“控制 token”來解決此問題。這些允許控制生成文本的樣式,從而允許多樣化的生成。
4. GPT-3
成功將 GPT 擴展到 GPT-2 后,對不同規模的語言模型行為的全面分析表明,存在簡單的冪律來控制計算、數據集大小、模型大小和語言模型性能之間的關系。受這些見解的啟發,GPT-2 被放大了 100 倍,生成了具有 1750 億(175B)個參數的 GPT-3。除了能夠生成令人印象深刻的真實文本段落之外,該模型還表現出少量學習能力:通過一些新穎任務的示例(例如將文本翻譯為代碼),該模型能夠在新示例上完成該任務。OpenAI 并沒有開源這個模型,我們只能通過 OpenAI API 提供接口來訪問 GPT-3。
5. GPT-Neo / GPT-J-6B
GPT-Neo 和 GPT-J-6B 是類似 GPT 的模型,由 EleutherAI 訓練,EleutherAI 是一個旨在重新創建和發布 GPT-3 規模模型的研究人員社區。當前模型是完整 175B 模型的較小變體,具有 1.3B、2.7B 和 6B 個參數,與 OpenAI 提供的較小 GPT-3 模型具有競爭力。
三、Encoder-Decoder 家族
盡管使用單個 encoder 或 decoder 堆棧構建模型已變得很常見,但 Transformer 架構有多種 encoder-decoder 變體,它們在 NLU 和 NLG 領域都有新穎的應用:
1. T5
T5 模型通過將所有 NLU 和 NLG 任務轉換為文本到文本任務來統一它們。所有任務都被構建為序列到序列的任務,其中采用?encoder-decoder?架構是很自然的。例如,對于文本分類問題,這意味著文本用作encoder 輸入,并且 decoder 必須將標簽生成為普通文本而不是類別。T5 架構采用原有的 Transformer 架構。使用大型爬網 C4 數據集,通過將所有這些任務轉換為文本到文本任務,使用 MLM 以及 SuperGLUE 任務對模型進行預訓練。11B 模型在多個基準測試中產生了領先的結果。
2. BART
BART 在?encoder-decoder?架構中結合了 BERT 和 GPT 的預訓練過程。輸入序列會經歷幾種可能的轉換之一,從簡單的 mask token 到句子排列、刪除 token 和文檔旋轉。這些修改后的輸入通過 encoder 傳遞,decoder 必須重建原始文本。這使得模型更加靈活,因為可以將其用于 NLU 和 NLG 任務,并且在這兩個任務上都實現了領先的性能。
3. M2M-100
通常,翻譯模型是針對一種語言對和翻譯方向構建的。當然,這并不能擴展到許多語言,此外,語言對之間可能存在共享知識,可用于稀有語言之間的翻譯。M2M-100 是第一個可以在 100 種語言之間進行翻譯的翻譯模型。這可以在稀有語言和代表性不足的語言之間進行高質量翻譯。該模型使用前綴 token(類似于特殊的 [CLS] token)來指示源語言和目標語言。
4. BigBird
由于注意力機制的二次內存要求,Transformer 模型的一個主要限制是最大上下文大小。BigBird 通過使用線性擴展的稀疏注意力形式來解決這個問題。這允許上下文從大多數 BERT 模型中的 512 個 token 大幅擴展至 BigBird 中的 4096 個。這在需要保留長依賴性的情況下特別有用,例如在文本摘要中。
參考:PyTorch研習社
)








丟雞蛋問題(Egg Dropping Puzzle)的三種算法與源代碼)




)




)