????????在一臺計算機中,我們可以同時打開多個軟件,例如同時瀏覽網頁、聽音樂、打字等,這是再正常不過的事情。但仔細想想,為什么計算機可以同時運行這么多軟件呢? 這就涉及計算機中的兩個名詞:多進程和多線程。
????????同樣,在編寫爬蟲程序的時候,為了提高爬取效率,我們可能會同時運行多個爬蟲任務,其中同樣涉及多進程和多線程。
目錄
一、多線程的概念
二、并發和并行
三、多線程的應用場景?
四、Python多線程用途
五、threading模塊
六、多線程共享全局變量的問題
(1)鎖機制和threading.Lock類
(2)Condition鎖
(3)Queue隊列?
一、多線程的概念
????????說起多線程,就不得不先說什么是線程。說起線程,又不得不先說什么是進程。
????????進程可以理解為一個可以獨立運行的程序單位,例如打開一個瀏覽器,就開啟了一個瀏覽器進程;打開一個文本編輯器,就開啟了一個文本編輯器進程。在一個進程中,可以同時處理很多事情,例如在瀏覽器進程中,可以在多個選項卡中打開多個頁面,有的頁面播放音樂,有的頁面播放視頻,有的網頁播放動畫,這些任務可以同時運行,互不干擾。為什么能做到同時運行這么多任務呢? 這便引出了線程的概念,其實一個任務就對應一個線程。
????????進程就是線程的集合,進程是由一個或多個線程構成的,線程是操作系統進行運算調度的最小單位,是進程中的最小運行單元。以上面說的瀏覽器進程為例,其中的播放音樂就是一個線程,播放視頻也是一個線程。當然,瀏覽器進程中還有很多其他線程在同時運行,這些線程并發或并行執行使得整個瀏覽器可以同時運行多個任務。
????????了解了線程的概念,多線程就很容易理解了。多線程就是一個進程中同時執行多個線程,上面的瀏覽器進程就是典型的多線程。
二、并發和并行
????????我們知道,在計算機中運行一個程序,底層是通過處理器運行一條條指令來實現的。
????????處理器同一時刻只能執行一條指令,并發(concurrency)是指多個線程對應的多條指令被快速輪換地執行。例如一個處理器,它先執行線程A的指令一段時間,再執行線程B的指令一段時間,然后再切回線程A 執行一段時間。處理器執行指令的速度和切換線程的速度都非常快,人完全感知不到計算機在這個過程中還切換了多個線程的上下文,這使得多個線程從宏觀上看起來是同時在運行。從微觀上看,處理器連續不斷地在多個線程之間切換和執行,每個線程的執行都一定會占用這個處理器的一個時間片段,因此同一時刻其實只有一個線程被執行。
????????并行(parallel)指同一時刻有多條指令在多個處理器上同時執行,這意味著并行必須依賴多個處理器。不論是從宏觀還是微觀上看,多個線程都是在同一時刻一起執行的。
????????并行只能存在于多處理器系統中,因此如果計算機處理器只有一個核,就不可能實現并行。而并發在單處理器和多處理器系統中都可以存在,因為僅靠一個核,就可以實現并發。例如,系統處理器需要同時運行多個線程。如果系統處理器只有一個核,那它只能通過并發的方式來運行這些線程。而如果系統處理器有多個核,那么在一個核執行一個線程的同時,另一個核可以執行另一個線程,這樣這兩個線程就實現了并行執行。當然,其他線程也可能和另外的線程在同一個核上執行,它們之間就是并發執行。具體的執行方式,取決于操作系統如何調度。

三、多線程的應用場景?
????????在一個程序的進程中,有一些操作是比較耗時或者需要等待的,例如等待數據庫查詢結果的返回、等待網頁的響應。這時如果使用單線程,處理器必須等這些操作完成之后才能繼續執行其他操作,但在這個等待的過程中,處理器明顯可以去執行其他操作。如果使用多線程,處理器就可以在某個線程處于等待態的時候,去執行其他線程,從而提高整體的執行效率。
????????很多情況和上述場景一樣,線程在執行過程中需要等待。網絡爬蟲就是一個非常典型的例子,爬蟲在向服務器發起請求之后,有一段時間必須等待服務器返回響應,這種任務就屬于IO密集型任務。對于這種任務,如果我們啟用多線程,那么處理器就可以在某個線程等待的時候去處理其他線程,從而提高整體的爬取效率。

????????但并不是所有任務都屬于IO密集型任務,還有一種任務叫作計算密集型任務,也可以稱為CPU密集型任務。顧名思義,就是任務的運行一直需要處理器的參與。假設我們開啟了多線程,處理器從一個計算密集型任務切換到另一個計算密集型任務,那么處理器將不會停下來,而是始終忙于計算,這樣并不會節省整體的時間,因為需要處理的任務的計算總量是不變的。此時要是線程數目過多,反而還會在線程切換的過程中耗費更多時間,使得整體效率變低。

????????綜上所述,如果任務不全是計算密集型任務,就可以使用多線程來提高程序整體的執行效率。尤其對于網絡爬蟲這種 IO密集型任務,使用多線程能夠大大提高程序整體的爬取效率。
四、Python多線程用途
????????Python自帶的解釋器是Cpython,并不支持真正意義上的多線程。Cpython提供了多線程包,包含一個叫Global Interpreter Lock(GIL)鎖,它能確保你的代碼中永遠只有一個線程在執行。經過GL的處理,會增加執行的開銷。這就意味著如果你先要提高代碼執行效率,使用threading不是一個明智的選擇,當然如果你的代碼是IO密集型,比如爬蟲,多線程可以明顯提高效率,相反如果你的代碼是CPU密集型,比如大量計算類型,這種情況下多線程反而沒有優勢,建議使用多進程。?
五、threading模塊
????????threading模塊是python中專門提供用來做多線程編程的模塊。thrcading模塊中最常用的類是Thread。
? ? ? ? 1.用thrcading模塊直接寫一個多線程程序
????????2.threading模塊下的Thrcad類,繼承自這個類,然后實現run方法,線程就會自動運行run方法中的代碼?
代碼實例:
# 多線程案例1
import threading
import timedef singing(name,delay):print(f'{name}開始唱歌')time.sleep(delay)print('結束唱歌')def dacning(name,delay):print(f'{name}開始跳舞')time.sleep(delay)print('結束跳舞')def single_thread():singing('學友',2)dacning('潘潘',3)def multi_thread():task = []th1 = threading.Thread(target=singing,args=('學友',2))th1.start()for i in range(3):th2 = threading.Thread(target=dacning,args=('潘潘',3))th2.start()task.append(th2)task.append(th1)for t in task:t.join()if __name__ == '__main__':start_time = time.time()# single_thread()multi_thread()print(threading.enumerate())end_time = time.time()print(f'總共消耗時間:{end_time-start_time}')
結果如下:
學友開始唱歌
潘潘開始跳舞
潘潘開始跳舞
潘潘開始跳舞
結束唱歌
結束跳舞
結束跳舞
結束跳舞
[<_MainThread(MainThread, started 21676)>]
總共消耗時間:3.022017002105713? ? ? ? ?這里使用了4個線程,一個線程用于打印唱歌并計時,三個線程用于打印跳舞并計時。最終消耗3秒多鐘,因為使用最長時間的線程所花費的時間為3秒鐘,其中還存在一些調用等之類的方法所耗費時間,一共加起來為3秒多種的時間。
六、多線程共享全局變量的問題
????????問題:多線程都是在同一個進程中運行的。因此在進程中的全局變量所有線程都是可共享的。這就造成了一個問題,因為線程執行的順序是無序的,有可能會造成數據錯誤。
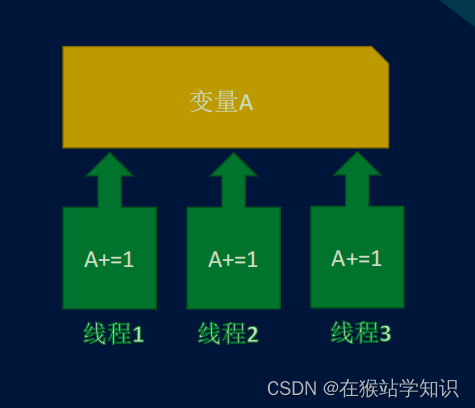
解決方法:
(1)鎖機制和threading.Lock類
????????為了解決共享全局變量的問題。thrcading提供了一個Lock類,這個類可以在某個線程訪問某個變量的時候加鎖,其他線程此時就不能進來,直到當前線程處理完后,把鎖釋放了,其他線程才能進來處理。實例如下:
# 多線程共享全局變量
import threading
lock = threading.Lock()
a = 0
def add_value(num):global alock.acquire()for i in range(num):a += 1lock.release()print(f'A的值是:{a}')def main():for i in range(10):th = threading.Thread(target=add_value,args=(1000000,))th.start()if __name__ == '__main__':main()結果如下:
A的值是:1000000
A的值是:2000000
A的值是:3000000
A的值是:4000000
A的值是:5000000
A的值是:6000000
A的值是:7000000
A的值是:8000000
A的值是:9000000
A的值是:10000000? ? ? ? ?如果不使用鎖機制,則會出現A計算出的值不是按照1000000相加的得到的結果。
生產者和消費者模式
????????生產者和消費者模式是多線程開發中經常見到的一種模式。生產者的線程專門用來生產一些數據,然后存放到一個中間的變量中。消費者再從這個中間的變量中取出數據進行消費。通過生產者和消費者模式,程序分工更加明確,線程更加方便管理。?
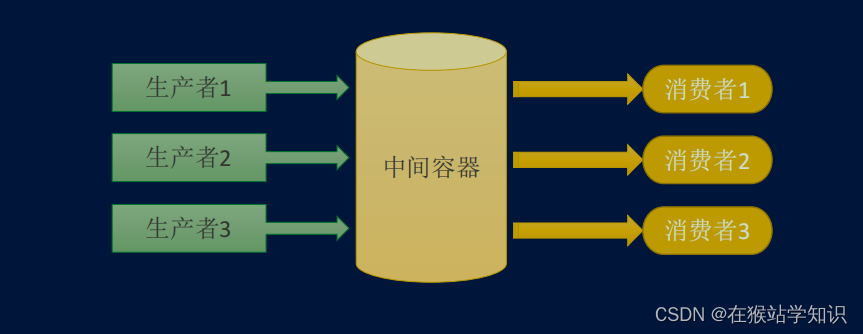
# 多線程L4-生產者和消費者-Lock版
import threading
import random
import timelock = threading.Lock()
cycle_time = 10
count = 0
total_money = 0
class Producer(threading.Thread):def run(self) -> None:global total_money,cycle_time,countwhile True:lock.acquire()if count > cycle_time:print('生產者已經完成工作了')lock.release()breakmoney = random.randint(100,5000)total_money += moneycount += 1print(f'{threading.current_thread().name}賺了{money}元')lock.release()time.sleep(0.5)class Consumer(threading.Thread):def run(self) -> None:global total_money,countwhile True:lock.acquire()money = random.randint(100,5000)if total_money >= money:total_money -= moneyprint(f'{threading.current_thread().name}消費了{money}元')else:if count > cycle_time:print(f'{threading.current_thread().name}想消費{money}元,但是余額不足,并且生產者不再生產了')lock.release()breakprint(f'{threading.current_thread().name}想消費{money}元,但是余額不足,只有{total_money}')lock.release()time.sleep(0.5)def main():for i in range(5):th1 = Producer(name=f'生產者{i}號')th1.start()for t in range(5):th2 = Consumer(name=f'消費者{t}號')th2.start()if __name__ == '__main__':main()結果如下:
生產者0號賺了2243元
生產者1號賺了1043元
生產者2號賺了1706元
生產者3號賺了3515元
生產者4號賺了1278元
消費者0號消費了4066元
消費者1號消費了4953元
消費者2號想消費3077元,但是余額不足,只有766
消費者3號想消費1452元,但是余額不足,只有766
消費者4號想消費4889元,但是余額不足,只有766
生產者2號賺了2290元
生產者1號賺了460元
生產者4號賺了2376元
生產者3號賺了3128元
生產者0號賺了4567元
消費者4號消費了1347元
消費者3號消費了4373元
消費者2號消費了3644元
消費者0號消費了2307元
消費者1號想消費3447元,但是余額不足,只有1916
生產者2號賺了1046元
生產者已經完成工作了
生產者已經完成工作了
生產者已經完成工作了
生產者已經完成工作了
消費者1號消費了2568元
消費者0號想消費2265元,但是余額不足,并且生產者不再生產了
消費者2號消費了235元
消費者3號想消費4350元,但是余額不足,并且生產者不再生產了
消費者4號想消費1287元,但是余額不足,并且生產者不再生產了
生產者已經完成工作了
消費者2號想消費3451元,但是余額不足,并且生產者不再生產了
消費者1號想消費3857元,但是余額不足,并且生產者不再生產了(2)Condition鎖
?????????threading.Condition可以在沒有數據的時候處于阻塞等待狀態。?一旦有合適的數據了,還可
以使用notify相關的函數來通知其他處于等待狀態的線程。這樣就可以不用做一些無用的上
鎖和解鎖的操作。可以提高程序的性能。
常用函數如下:
- acquire:???上鎖。
- release: ??解鎖。
- wait:??將當前線程處于等待狀態,并且會釋放鎖。可以被其他線程使用notify和notify_all函數
????????喚醒。被喚醒后會繼續等待上鎖,上鎖后繼續執行下面的代碼。
- notify: ??通知某個正在等待的線程,默認是第1個等待的線程。
- notify_all: ??通知所有正在等待的線程。notify?和notfy_all?不會釋放鎖。并且需要在release之前
????????調用。?
下面案例使用??threading.Condition來解決生產者和消費者問題:
# 多線程L5-生產者和消費者-Condition版import threading
import random
import timelock = threading.Condition()
cycle_time = 10
count = 0
total_money = 0class Producer(threading.Thread):def run(self) -> None:global total_money,cycle_time,countwhile True:lock.acquire()if count > cycle_time:print('生產者已經完成工作了')lock.release()breakmoney = random.randint(100,5000)total_money += moneylock.notify_all()count += 1print(f'{threading.current_thread().name}賺了{money}元')lock.release()time.sleep(0.5)class Consumer(threading.Thread):def run(self) -> None:global total_money,countwhile True:lock.acquire()money = random.randint(100,5000)while total_money < money:if count > cycle_time:print(f'{threading.current_thread().name}想消費{money}元,但是余額不足,并且生產者不再生產了')lock.release()returnlock.wait()total_money -= moneyprint(f'{threading.current_thread().name}消費了{money}元')lock.release()time.sleep(0.5)def main():for i in range(5):th1 = Producer(name=f'生產者{i}號')th1.start()for t in range(5):th2 = Consumer(name=f'消費者{t}號')th2.start()if __name__ == '__main__':main()結果如下:?
生產者0號賺了1782元
生產者1號賺了4000元
生產者2號賺了174元
生產者3號賺了4387元
生產者4號賺了4438元
消費者0號消費了4504元
消費者1號消費了4909元
消費者2號消費了3572元
生產者3號賺了2507元
生產者0號賺了391元
消費者4號消費了3385元
生產者2號賺了3058元
生產者4號賺了3922元
消費者2號消費了3263元
消費者0號消費了4646元
生產者1號賺了4092元
消費者1號消費了549元
消費者3號消費了2709元
生產者3號賺了1972元
生產者已經完成工作了
消費者2號消費了1771元
生產者已經完成工作了
消費者4號想消費3128元,但是余額不足,并且生產者不再生產了
生產者已經完成工作了
消費者0號想消費3515元,但是余額不足,并且生產者不再生產了
消費者3號想消費2024元,但是余額不足,并且生產者不再生產了
消費者1號消費了863元
生產者已經完成工作了
生產者已經完成工作了
消費者2號想消費1832元,但是余額不足,并且生產者不再生產了
消費者1號想消費2619元,但是余額不足,并且生產者不再生產了(3)Queue隊列?
?????????Queue是python標準庫中的線程安全的隊列(FIFO)實現,提供了一個適用于多線程編程的先進先出的數據結構。隊列可以完美解決線程間的數據交換,保證線程間數據的安全性和一致性。
初始化Queue(maxsize):創建一個先進先出的隊列。
- qsize():返回隊列的大小。
- empty():判斷隊列是否為空。
- full():判斷隊列是否滿了。
- get():從隊列中取最后一個數據。
- put():將一個數據放到隊列中。
????????下面這篇帖子就是采取隊列的方式來防止亂序問題的出現:
Python高級進階--多線程爬取下載小說(基于筆趣閣的爬蟲程序)_python多線程爬取小說-CSDN博客


)


之SpringCloud Consul)










)


)