本篇文章將圍繞Java中的編譯器,深入淺出的解析前端編譯的流程、泛型、條件編譯、增強for循環、可變長參數、lambda表達式等語法糖原理
編譯器與執行引擎
編譯器
Java中的編譯器不止一種,Java編譯器可以分為:前端編譯器、即時編譯器和提前編譯器
最為常見的就是前端編譯器javac,它能夠將Java源代碼編譯為字節碼文件,它能夠優化程序員使用起來很方便的語法糖
即時編譯器是在運行時,將熱點代碼直接編譯為本地機器碼,而不需要解釋執行,提升性能
提前編譯器將程序提前編譯成本地二進制代碼
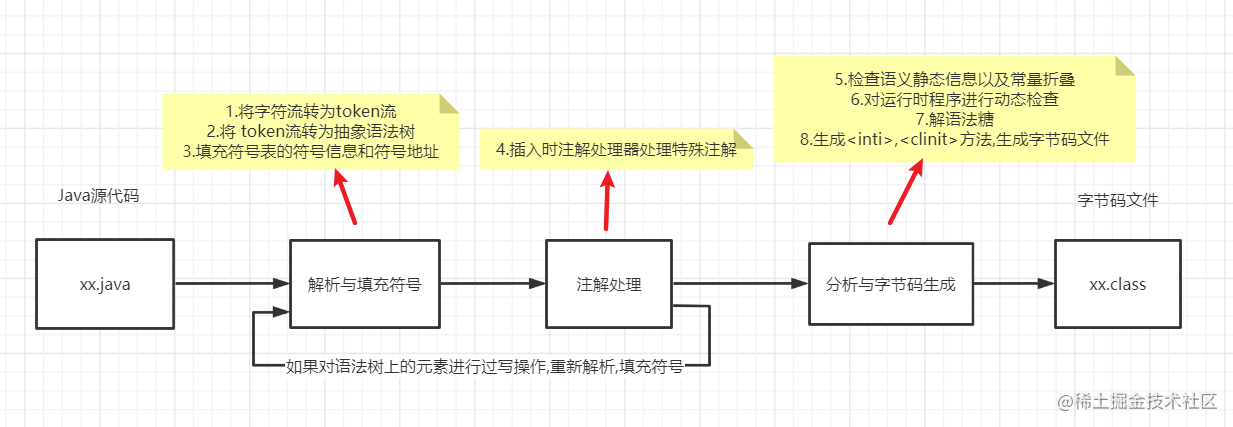
前端編譯過程
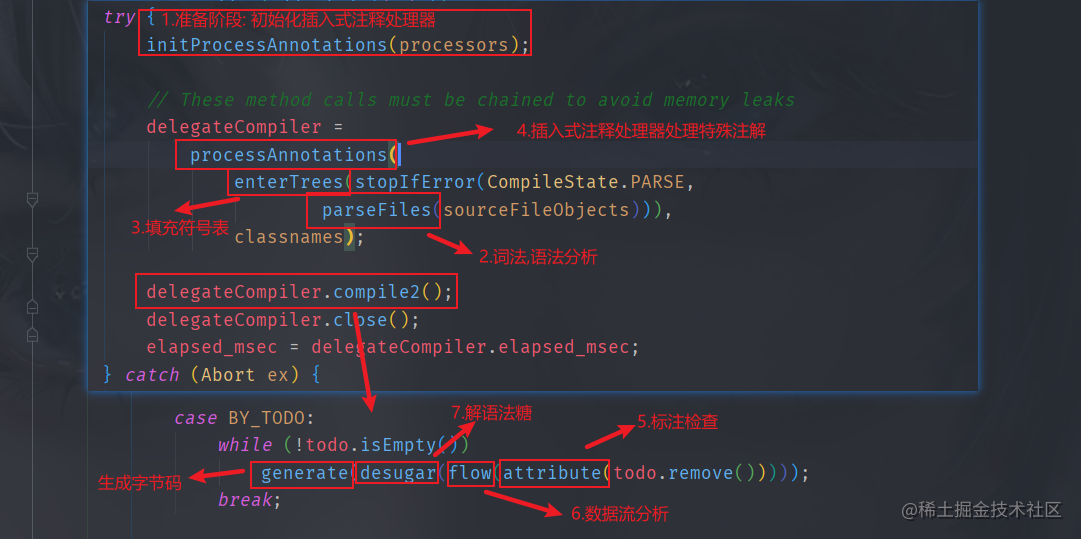
準備階段: 初始化插入式注解處理器
處理階段
解析與填充符號表
詞法分析: 將Java源代碼的字符流轉變為token(標記)流
- 字符: 程序編寫的最小單位
- 標記(token) : 編譯的最小單位
- 比如 關鍵字 static 是一個標記 / 6個字符
語法分析: 將token流構造成抽象語法樹
填充符號表: 產生符號信息和符號地址
- 符號表是一組符號信息和符號地址構成的數據結構
- 比如: 目標代碼生成階段,對符號名分配地址時,要查看符號表上該符號名對應的符號地址
插入式注解處理器的注解處理
注解處理器處理特殊注解: 在編譯器允許注解處理器對源代碼中特殊注解作處理,可以讀寫抽象語法樹中任意元素,如果發生了寫操作,就要重新解析填充符號表
- 比如: Lombok通過特殊注解,生成get/set/構造器等方法
語義分析與字節碼生成
標注檢查: 對語義靜態信息的檢查以及常量折疊優化
?int i = 1;char c1 = 'a';int i2 = 1 + 2;//編譯成 int i2 = 3 常量折疊優化char c2 = i + c1; //編譯錯誤 標注檢查 檢查語法靜態信息
數據及控制流分析: 對程序運行時動態檢查
- 比如方法中流程控制產生的各條路是否有合適的返回值
解語法糖: 將(方便程序員使用的簡潔代碼)語法糖轉換為原始結構
字節碼生成: 生成
<init>,<clinit>方法,并根據上述信息生成字節碼文件
前端編譯流程圖
源碼分析
 代碼位置在JavaCompiler的compile方法中
代碼位置在JavaCompiler的compile方法中
Java中的語法糖
泛型
將操作的數據類型指定為方法簽名中一種特殊參數,作用在方法、類、接口上時稱為泛型方法、泛型類、泛型接口
Java中的泛型是類型擦除式泛型,泛型只在源代碼中存在,在編譯期擦除泛型,并在相應的地方加上強制轉換代碼
與具現化式泛型(不會擦除,運行時也存在泛型)對比
優點: 只需要改動編譯器,Java虛擬機和字節碼指令不需要改變
- 因為泛型是JDK5加入的,為了滿足對以前版本代碼的兼容采用類型擦除式泛型
缺點: 性能較低,使用沒那么方便
為提供基本類型的泛型,只能自動拆裝箱,在相應的地方還會加速強制轉換代碼,所以性能較低
運行期間無法獲取到泛型類型信息
比如書寫泛型的List轉數組類型時,需要在方法的參數中指定泛型類型
?public static <T> T[] listToArray(List<T> list,Class<T> componentType){T[] instance = (T[]) Array.newInstance(componentType, list.size());return instance;}
增強for循環與可變長參數

增強for循環 -> 迭代器
可變長參數 -> 數組裝載參數
泛型擦除后會在某些位置插入強制轉換代碼
自動拆裝箱
自動裝箱、拆箱的錯誤用法
? Integer a = 1;Integer b = 2;Integer c = 3;Integer d = 3;Integer e = 321;Integer f = 321;Long g = 3L;//trueSystem.out.println(c == d);//范圍小,在緩沖池中//falseSystem.out.println(e == f);//范圍大,不在緩沖池中,比較地址因此為false//trueSystem.out.println(c == (a + b));//trueSystem.out.println(c.equals(a + b));//falseSystem.out.println(g == (b + a));//trueSystem.out.println(g.equals(a + b));注意:
包裝類重寫的equals方法中不會自動轉換類型

包裝類的 == 就是去比較引用地址,不會自動拆箱
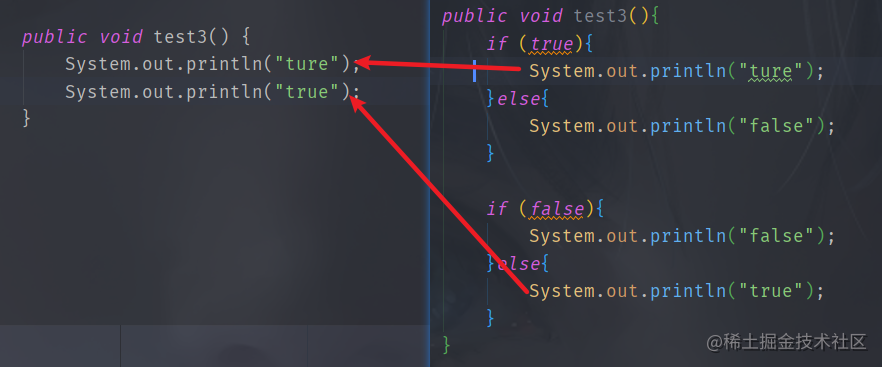
條件編譯
布爾類型 + if語句 : 根據布爾值類型的真假,編譯器會把分支中不成立的代碼塊消除(解語法糖)
Lambda原理
編寫函數式接口
?@FunctionalInterfaceinterface LambdaTest {void lambda();}編寫測試類
?public class Lambda {private int i = 10;?public static void main(String[] args) {test(() -> System.out.println("匿名內部類實現函數式接口"));}?public static void test(LambdaTest lambdaTest) {lambdaTest.lambda();}}使用插件查看字節碼文件
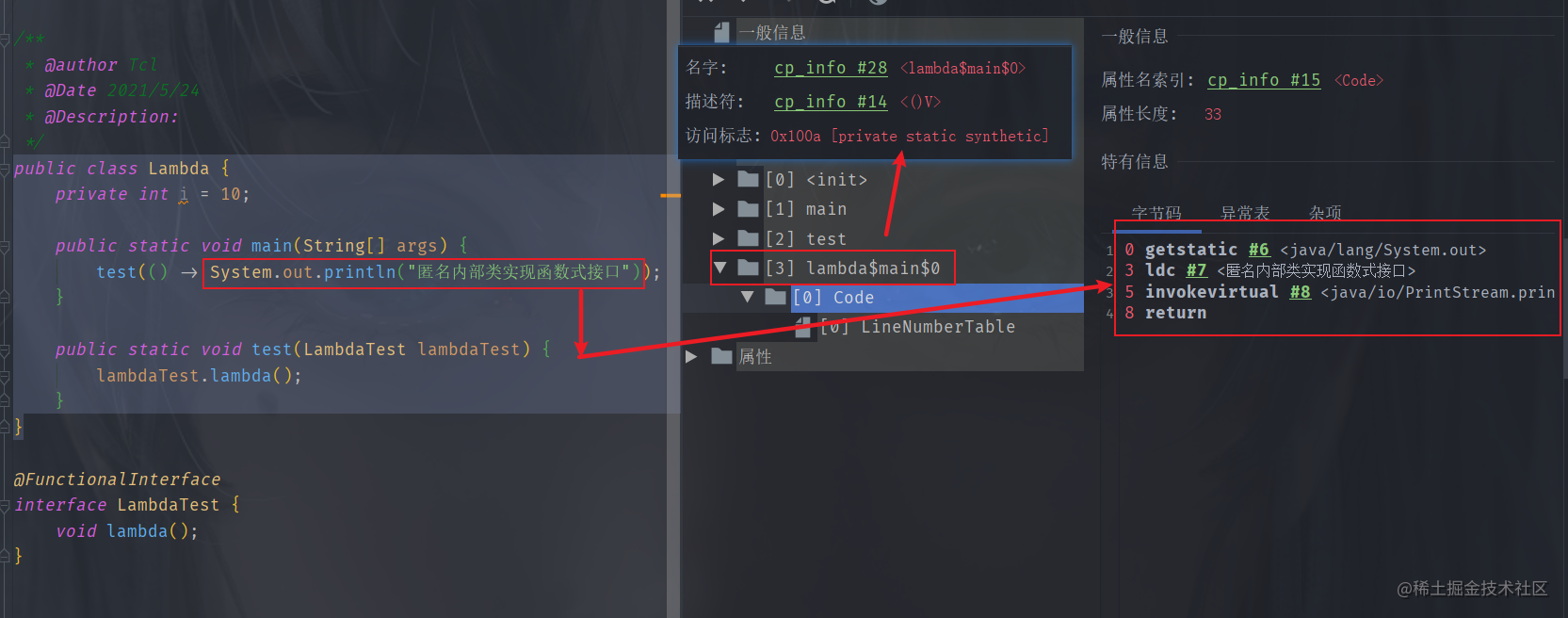 生成了一個私有靜態的方法,這個方法中很明顯就是lambda中的代碼
生成了一個私有靜態的方法,這個方法中很明顯就是lambda中的代碼
在使用lambda表達式的類中隱式生成一個靜態私有的方法,這個方法代碼塊就是lambda表達式中寫的代碼
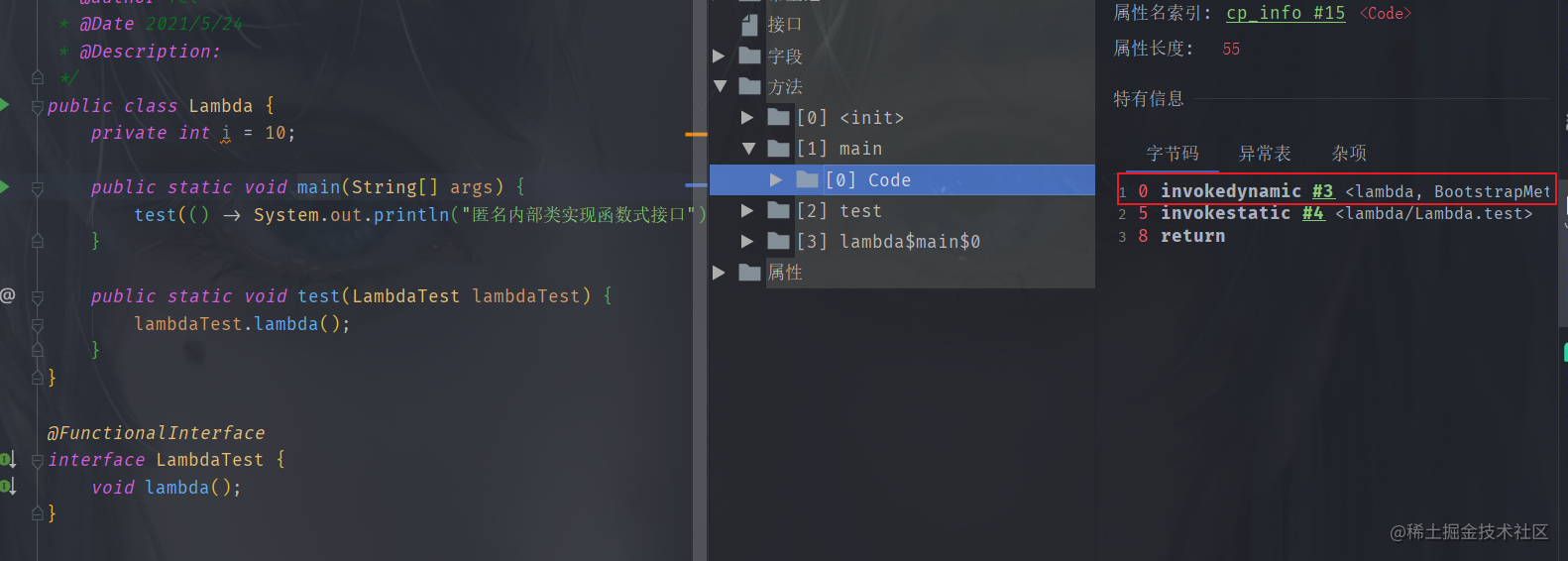 執行class文件時帶上參數
執行class文件時帶上參數java -Djdk.internal.lambda.dumpProxyClasses 包名.類名即可顯示出這個匿名內部類
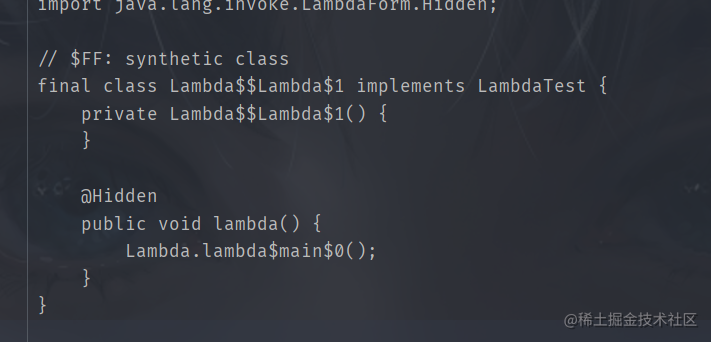
使用invokedynamic生成了一個實現函數式接口的匿名內部類對象,在重寫函數式接口的方法實現中調用使用lambda表達式類中隱式生成的靜態私有方法
總結
本篇文章以Java中編譯器的分類為開篇,深入淺出的解析前端編譯的流程,Java中泛型、增強for循環、可變長參數、自動拆裝箱、條件編譯以及Lambda等語法糖的原理
前端編譯先將字符流轉換為token流,再將token流轉換為抽象語法樹,填充符號表的符號信息、符號地址,然后注解處理器處理特殊注解(比如Lombok生成get、set方法),對語法樹發生寫改動則要重新解析、填充符號,接著檢查語義靜態信息以及常量折疊,對運行時程序進行動態檢查,再解語法糖,生成init實例方法、clinit靜態方法,最后生成字節碼文件
Java中為了兼容之前的版本使用類型擦除式的泛型,在編譯期間擦除泛型并在相應位置加上強制轉換,想為基本類型使用泛型只能搭配自動拆裝箱一起使用,性能有損耗且在運行時無法獲取泛型類型
增加for循環則是使用迭代器實現,并在適當位置插入強制轉換;可變長參數則是創建數組進行裝載參數
自動拆裝箱提供基本類型與包裝類的轉換,但包裝類盡量不使用==,這是去比較引用地址,同類型比較使用equals
條件編譯會在if-else語句中根據布爾類型將不成立的分支代碼塊消除
lambda原理則是通過invokeDynamic指令動態生成實現函數式接口的匿名對象,匿名對象重寫函數時接口方法中調用使用lambda表達式類中隱式生成的靜態私有的方法(該方法就是lambda表達式中的代碼內容)
最后(不要白嫖,一鍵三連求求拉~)
本篇文章筆記以及案例被收入 gitee-StudyJava、 github-StudyJava 感興趣的同學可以stat下持續關注喔~
有什么問題可以在評論區交流,如果覺得菜菜寫的不錯,可以點贊、關注、收藏支持一下~
關注菜菜,分享更多干貨,公眾號:菜菜的后端私房菜
本文由博客一文多發平臺 OpenWrite 發布!
基于大語言模型LangChain與ChatGLM3-6B本地知識庫調優:數據集優化、參數調整、Prompt提示詞優化實戰)
















--兩個多項式的和)

