文章目錄
- (提供數據集下載)基于大語言模型LangChain與ChatGLM3-6B本地知識庫調優:數據集優化、參數調整、提示詞Prompt優化
- 本地知識庫目標
- 操作步驟
- 問答測試的預設問題
- 原始數據情況
- 數據集優化:預處理,先后準備了三份數據集
- PreData1:極簡數據集,txt格式
- PreData2:按json結構處理的數據集,txt格式
- PreData3:整理成文檔章節的PDF數據集
- 從1到3是一個逐步優化數據集的過程
- Tip:每次優化重新對話測試時,建議重啟模型。本人GPU冒煙了,才重啟。
- 創建本地知識庫時文件處理參數調整
- 對話時知識庫配置參數調整
- Prompt提示詞優化
- Round 1
- Round 2
- Round 3
- Round 4
- 數據集地址
(提供數據集下載)基于大語言模型LangChain與ChatGLM3-6B本地知識庫調優:數據集優化、參數調整、提示詞Prompt優化
本地知識庫目標
- 創建“神經內科典型病例目錄”數據集,一共3個病例信息,包括基本信息、癥狀、體格檢查、輔助檢查、診斷、診斷依據等信息。
- LangChain+ChatGLM3-6B WebUI中加載“神經內科典型病例目錄”數據集作為本地知識庫。
- 在“對話”中進行神經內科典型病例相關問答。
操作步驟
- 數據集預處理
- 建立本地知識庫后,進行問答測試
- 調優:數據集優化、本地知識庫問答參數調整、Prompt提示詞優化
問答測試的預設問題
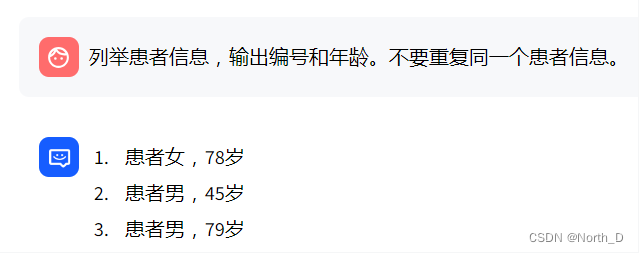
- Q:有幾個病例?
- Q:輸出病例編號、性別、年齡。
- Q:神經內科確診疾病有哪些,輸出名稱。
原始數據情況
#神經內科典型病例目錄
##病例一
###病史摘要 患者女,78歲。 入院前四小時突然覺得頭痛,同時發現左側肢體乏力,左上肢不能持物,左下肢不能行走,惡心伴嘔吐胃內容物數次。無意識喪失,無四肢抽搐,無大小便失禁,即送醫院急診。體格檢查:神清,BP 185/95mmHg,HR
80次/分,律齊,EKG示竇性心律.對答切題,雙眼向右凝視,雙瞳孔等大等圓,對光反射存在,左鼻唇溝淺,伸舌略偏左。左側肢體肌張力增高,左側腱反射略亢進,左側肌力III0,右側肢體肌張力正常,肌力V0。左側巴氏征(+),右側病理癥(-)。頸軟,克氏征(-)。
輔助檢查:頭顱CT示右側顳葉血腫。
數據集優化:預處理,先后準備了三份數據集
PreData1:極簡數據集,txt格式
- 收集資料:原始數據是從網上爬的病例神經內科典型病例,復制、粘貼到的txt文件。只有3個病例。
- 格式處理:統一標點符號,包括換行符號;處理好段落內容邏輯,處理段落內出現的換行情況。
- 刪除冗余:刪除序號,如1、2、3或a、b、c等。刪除多余的空格。

PreData2:按json結構處理的數據集,txt格式
將數據集按json處理
曾經嘗試過進行以下這一步的操作,由于沒有工具輔助,非常繁瑣,尤其是key值的生成。放棄了。
段落內處理:確保段落內是類似于KV結構,如“癥狀”:“頭疼”。
處理成了偷懶模式:
{ [“癥狀:頭疼”],
[“體格檢檢:口齒欠清”] ,
[“體格檢查:神志朦朧”] }

PreData3:整理成文檔章節的PDF數據集

從1到3是一個逐步優化數據集的過程
- 從PreData1開始進行對話測試,回答讓人一臉黑線,無法溝通交流。

- PreData2能溝通交流,也有驚喜,但是不穩定
“有幾個病例”重復問幾遍,只回答對過一次。而且基于Json嘗試過幾種修改方案,繁瑣,而且新的json文件導入本地知識庫報錯(懶,不想正面面對報錯的問題),遂放棄了,改用PDF。
- PreData3按照文章章節編輯,插入目錄,貌似很順利
相對來說比較穩定,但是對話測試也是那么完美。這讓我想起需要從對話參數、Prompt提示詞解決問題。
Tip:每次優化重新對話測試時,建議重啟模型。本人GPU冒煙了,才重啟。
創建本地知識庫時文件處理參數調整
FAISS
bge-large-zh
以下兩項默認值需要修改:
段落文本最大長度:250
相鄰文本重合長度:50
改成:
段落文本最大長度:50
相鄰文本重合長度:5
對話時知識庫配置參數調整
以下兩項需要調整:
匹配知識條數:3
知識匹配分數閾值:1
修改成:
匹配知識條數:20
知識匹配分數閾值:1可以先不改,根據回答適當調整到0.8左右,試試效果再決定。
Prompt提示詞優化
直接看多輪對話下來,對話是如何有序展開的吧。
Round 1
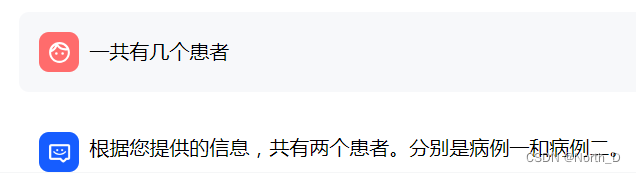
Round 2
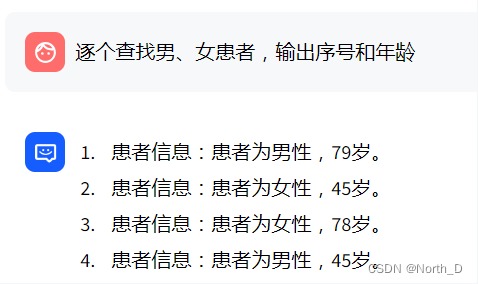
Round 3
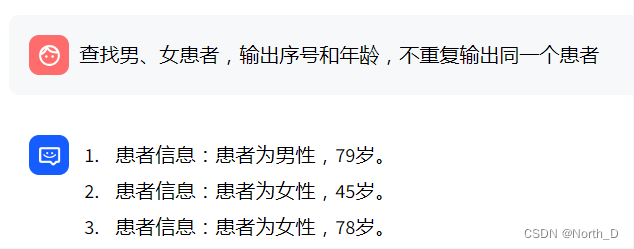
Round 4

完畢!
數據集地址
神經內科典型病例目錄PreData1.txt
神經內科典型病例目錄PreData2.txt
神經內科典型病例目錄PreData3.pdf
Enjoy!!!
















--兩個多項式的和)


)