文章目錄
- 前記
- Paper6:Raft
- LEC5、6:Raft
- LAB2
- 2A
- task
- Hint
- locking
- structure
- guide
- 設計與編碼
- 2B
- task
- Hint
- 設計與編碼
- 2C
- task
- Hint
- question
- 后記
- LEC5:GO, Threads, and Raft
- go threads技巧
- raft實驗易錯點
- debug技巧
前記
- 趁著研一考完期末有點點空余時間,把Raft的實驗補了
- 記錄著看視頻、論文和實驗過程中的一些想法
Paper6:Raft
概述(來自NewBing):
raft算法是一種用于分布式一致性的共識算法,旨在解決分布式系統中的領導者選舉和日志復制等問題。它的設計目標是易于理解和實現,并且能夠提供強一致性保證。raft算法的核心原理包括三個關鍵組件:領導者選舉、日志復制和安全性。
- 領導者選舉:raft算法將時間劃分為一個個的任期(term),每個任期的開始都是一次選舉,一個或多個候選者(candidate)會嘗試成為領導者(leader)。如果一個候選者贏得了大多數節點的投票,它就會成為新的領導者,并在該任期內管理整個集群。如果沒有選出領導者,就會開始下一個任期,并重新進行選舉。raft算法保證在任意時刻最多只有一個領導者。
- 日志復制:領導者選出后,就開始接收客戶端的請求,并將請求作為日志條目(log entry)加入到它的日志中,然后并行地向其他節點發送附加日志請求(AppendEntries RPC)復制日志條目。當這條日志被復制到大多數節點上,領導者就將這條日志應用到它的狀態機,并向客戶端返回執行結果。領導者會不斷地重試附加日志請求,直到所有的節點都存儲了所有的日志條目。
- 安全性:raft算法增加了一些限制來保證安全性,即只有擁有最新的已提交的日志條目的節點才有資格成為領導者,而且領導者只能提交當前任期的日志條目,舊任期的日志條目要等到提交當前任期的日志條目來間接提交。這樣可以避免已提交的日志條目被覆蓋的情況。
有一個經驗:要想在Raft中假設A情況,你首先得考慮A情況是否有可能發生。
細節點:
-
Raft Basic
- Figure 2是非常重要的一個圖。
- follower只接受請求,不主動發起請求
- 當client發送請求到follower時,會轉發給ld處理
- ld會通過發送AE來抑制其他server發起選舉。也就是說,ld不出錯的話,它永遠是ld。
- 當ld提交時,會通知follower
- term會通過包的發送來交換。如果接受者發現有更大的任期,那么它會更新自己的任期。如果發現更小term的包,那么會拒絕。如果ld或candidate發現自己的任期更小了,那么會立刻轉變為follower
- 時序:client request -> ld -> 將log entry復制到半數以上服務器,并得到回復 -> ld commited、apply -> 返回響應給client ->后面心跳檢測(AE)時,隨便告訴其他服務器自己已經commited并apply
-
Leader election
- 當election timer計時結束,還沒有ld發請求,那么follower會認為ld死了,會變成candicate,發起選舉
- 如果split votes發生了,那么term會增加,并再次發起選舉
- timer計時器,是隨機的
- 注意:每一個新ld的產生,由于它要獲得多數server的認可,在請求投票時會把最新的term同步給多數的server!因此term也是一個“多數共識”的標識。
-
Log replication
- 當ld 接收到log entry時,它會保證大多數server都接受到這個log entry,才會繼續自己的下一步操作(如返回響應給client)
- 如果一個server對接受log entry沒有響應,ld會無限地嘗試
- 如果ld認為LE(log entry)是足夠安全的了,那么這個時候叫作committed;注意,apply和committed是不一樣的
- 在之后,ld會通過AE來將已經committed的index告知給各個follower
- 當ld發送AE給follower時,如果follower發現日志沖突,那么ld會decrements nextIndex,直到兩者保持一致。注意:ld永遠不會重寫/刪除自己的日志。(decrements nextIndex,不會把follower上的日志刪除嗎?會的,但是ld一定有了所有能被commited的日志,因此以ld為準。)
-
Safety
-
raft保證,被選舉出的ld,一定會存有所有已經commited的日志(這個最難理解了。沒有commited的entry又怎么處理呢?這樣理解,要想commited,那么日志一定是被復制到“半數以上的服務器”。而新ld一定是“半數以上的服務器”中的一個。因此,只要是新ld,那么一定有能保證被commited的日志 。)。:the voter denies its vote if its own log is more up-to-date than that of the candidate。也就是說,要被投票的candidate的日志,要比半數以上的voter的日志要more up-to-date。(什么叫more up-to-date?更大term;如果term相同,則更大index)
leader的前提是majority,因此leader肯定擁有majority的log(這就是為什么叫做共識)
上面說法有問題:更正一下:raft保證,被選舉出的ld,一定會存有比大多數server更up-to-date的日志。
leader的前提是majority都同意,因此leader肯定擁有majority都同意的更up-to-date的log(這就是為什么叫做共識)
總結一下:大多數server都認為A服務器有比自己more up-tp-date的log**(共識)**,那么A就可以是ld。
-
ld只允許commited自己任期內的日志?為什么:
-
新ld上線時,不能夠確定舊的entry是否已經被commited(如重啟后,commitedIndex被重置),舊的entry是否已經被大多數server所有。
當能commite自己任期內的log entry時,就已經說明前面任期的所有日志一定已經復制到大多數server了。
因此,只能通過提交自己任期內的log entry,來間接說明之前的日志可以提交。
同時,能commited自己任期內的日志,說明已經通知到了半數以上服務器,這個時候,半數以上的服務器的日志中的term是和ld一樣是最新的。
-
圖8,描述了,log即使存儲在大多數的server上,仍然可能被后面的新ld覆蓋(圖8的d)。
因此不能夠直接通過復制的數量來判斷之前任期的日志條目是否提交(圖8的c)。
所以才出現下下面的解決方案:ld只允許提交自己任期內的log entry。這樣保證,當 圖8的e 的S1的任期4日志被提交時,任期為3的自然也算被提交了。
-
-
-
Timing and availability:broadcastTime ? electionTimeout ? MTBF(平均故障時間)
- broadcastTime ? electionTimeout ,如果不能保證這個,那么會頻繁出現選舉失敗
- electionTimeout ? MTBF,保證這個是因為,讓選舉平穩進行。這個用腦子想想就知道~,為了保證系統平衡運行,肯定這種定時器要小于故障時間的。
-
Cluster membership changes
- 使用了joint consensus,兩階段轉變。首先轉為joint狀態(中間態),然后再轉變為new configuration狀態
- raft的實現中,在中間態依然可以正常進行選舉和處理client的請求
-
Log compaction
- 使用了快照。這個好像在lab3用得到。
-
Client interaction
- 初始時,client會隨機挑選一個server進行連接
- client發送的請求,都會帶有一個 唯一的id
- 如果重復請求,那么server會通過請求的id,直接返回之前已經執行過的請求的響應
文章的假設:
- 應用程序狀態是易失的
- 當一個機器死掉后,通過心跳確認自己的apply位置,并重演一次操作(先不考慮日志壓縮)
問題:
-
如何避免腦裂?
- majority voting system。這個是整個機制的基石
- odd servers
- 當出現網絡partition時,絕不可能有超過一邊擁有一半以上的服務器
- 大多數投票機制保證:在每一步要投票時,保證投票的“大多數”機器中,一定有一部分會和上次投票重疊。
-
如何知道“半數以上”?
- raft算法中,每個服務器(節點)都會保存一些關于集群的信息,其中就包括集群的總數目(server count)。這個信息可以在集群初始化的時候,由配置文件或者命令行參數來指定,也可以在集群運行的過程中,由領導者節點來動態更新。
- 總數目是固定的,不會因為機器的故障而減少!!!
-
要是因網絡故障,完全將raft的服務器分區成兩半,怎么辦?
- 絕不可能有超過一邊擁有一半以上的服務器
-
Raft集群最大能忍受的故障server數目是多少?
- 假設一共有2f + 1臺機器,那么最多允許f臺機器故障。底層原理是因為投票機制是多數機制
- 如果是有n臺機器,那么就是 2f+1=n,f = (n - 1) / 2
-
有不確定性操作的命令怎么辦?
-
為什么需要log entry?
- 為了保證操作順序
- 暫存操作。因為操作到來不確定是否一被要執行。
- 保存副本,當網絡故障時,可以重發給follower
-
Raft為什么需要要ld?(比如Paxos就沒有ld)
- 加速系統應答
- 讓系統更加容易理解
-
如果因為網絡故障分裂成兩個partition,舊ld在一半,但另一半有超過半數的server并且選舉出了新ld,這個時候如何處理?為什么舊ld不會導致錯誤發生?
- 因為舊ld不會得到多數server的回應,因此不會成功執行任何命令
-
如果一個server的term跑得太快怎么辦?
- 快就快。有投票機制的保證,沒有關系的。
-
那么這些entry在舊ld執行后返回給client時失敗了怎么辦?新上任的ld還會再執行再給返回client嗎?
- 請求是有帶id的,可以通過id來尋找已經執行的結果。
-
如果一個ld已經把log復制給大多數server了,但是在commited之前掛掉了。那么這個log算是commited嗎?
- 還是Figure8?。不算的。只有當前ld將自己任期內的log提交了,之前的所有log才算是commited!
-
不能夠通過“已經復制日志給大多數server”,來判斷“是否已經commited”
- 還是Figure8?
-
為什么不選有最長日志的,作為領導人?
- 最長不代表最up-to-date 。最長不代表能復制給多數server。也就是沒有共識。
-
什么是線性化語義?
在Raft協議中,“linearizable semantics”(線性化語義)是一個重要的概念。這意味著,對于任何兩個操作,如果在實際執行中,操作A在操作B之前完成,那么在系統的狀態中,操作A就應該在操作B之前
在Raft協議中,為了實現線性化語義,通常會在服務器端維護一個關于已經執行過的請求的記錄。這個記錄通常包括每個客戶端的最后一個請求的ID以及對應的響應。當收到一個新的請求時,服務器首先會檢查這個請求的ID是否已經存在于記錄中。如果存在,說明這個請求是重復的,服務器就會直接返回之前的響應,而不會再次執行這個請求
總的來說,"linearizable semantics"是Raft協議中保證一致性的重要機制,它能夠確保所有的操作都能按照一定的順序執行,并且每個操作只執行一次
LEC5、6:Raft
隨便記記:
- mapReduce、GFS、VM-FT都單一實體來決定誰是ld
- 最詳細對raft的資料:https://raft.github.io/
- 教學動畫:https://thesecretlivesofdata.com/raft/
LAB2
注意點:
- Raft will continue to operate as long as at least a majority of the servers are alive and can talk to each other. If there is no such majority, Raft will make no progress, but will pick up where it left off as soon as a majority can communicate again.
- the service expects your implementation to send an
ApplyMsgfor each newly committed log entry to theapplyChchannel argument toMake() - Your Raft peers should exchange RPCs using the labrpc Go package (source in
src/labrpc).:因為測試器會模擬丟包等網絡故障
2A
http://nil.csail.mit.edu/6.824/2020/labs/lab-raft.html
task
- 實現ld選舉 及 心跳檢測。當舊ld死掉時(當follower收不到舊ld的心跳時),要有接管機制
Hint
- 只關注你當前的任務(但是應該也要考慮到后面的擴展)
- 本實驗中:the number of Raft peers (usually 3 or 5)
- Add the Figure 2 state for leader election to the
Raftstruct inraft.go. - Modify
Make()to create a background goroutine that will kick off leader election periodically by sending outRequestVoteRPCs when it hasn’t heard from another peer for a while. This way a peer will learn who is the leader, if there is already a leader, or become the leader itself. Implement theRequestVote()RPC handler so that servers will vote for one another. 就是要有一個機制,心跳超時后要發起選舉。 - The tester requires that the leader send heartbeat RPCs no more than ten times per second.每秒不得多于10次的心跳檢測
- 舊ld死掉后,要求5秒內就要完成新ld的選舉。因為要求選舉時間和心跳間隔選得盡可能短
- The paper’s Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds. Because the tester limits you to 10 heartbeats per second, you will have to use an election timeout larger than the paper’s 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.(?) 總的來說,這個是說election timer的時間,應該設置超過150~300 milSecond。(gpt建議300到500)。但是不知道原理。。
- 使用loop+time.Sleep()來完成周期性任務
- You may find this guide useful, as well as this advice about locking and structure for concurrency.
- The tester calls your Raft’s
rf.Kill()when it is permanently shutting down an instance. You can check whetherKill()has been called usingrf.killed(). You may want to do this in all loops, to avoid having dead Raft instances print confusing messages. 就是test發送信號要永久殺死一個server,但是不是通過進程強制殺死。要處理這個信號。周期性任務要通過這個標志判斷,是否要繼續。 - debug:
- 可以用print語句,然后使用
go test -run 2A > out. 查看 - You might find
DPrintfinutil.gouseful to turn printing on and off as you debug different problems.
- 可以用print語句,然后使用
- 要通過RPC發送的字段,必須大寫
- 使用go test -race,來保證代碼沒有race
- 測試時間限制: For all of labs 2, 3, and 4, the grading script will fail your solution if it takes more than 600 seconds for all of the tests (
go test), or if any individual test takes more than 120 seconds.
locking
- 不論讀寫,如果要保證一致性的,一定要加鎖
- Code that waits should first release locks. If that’s not convenient, sometimes it’s useful to create a separate goroutine to do the wait.
- 等待的代碼,要釋放鎖。但是等待的代碼執行完畢后,要重新獲得鎖,并判斷自己的assumption是否還和當前的環境相同(將當時主線程的參數復制到goroutine中)。
structure
- 長時間運行的 activities ,應該在不同的線程運行。不同activities 應該也要分割開
- 處理timeout的通用思路:存儲一個最后時間a,睡眠,然后在某個時間b,判斷 b - a > timeout?
- 在將log送入到applych時,必須保證順序。因此這個操作只能在一個goroutine執行
- 推進
commitIndex的代碼需要觸發應用 Goroutine。為了實現這一點,建議使用條件變量(如 Go 中的sync.Cond):就是signal機制。 - 每個RPC的發送和處理,應該在同一個goroutine.
guide
-
figure2是絕對權威的總指導
-
hearbeat返回時,如果返回true,是隱式地告訴ld,當前follower的日志和ld完全同步。因此即使是hearbeat,也要檢測里面的term等狀態。
-
什么時候重置election timer?
- 從當前ld接受到AE
- 自己開始一個選舉期
- 投票給其他peer的時候。
-
一個任期內,只能投票一次!但是由于這個規則的存在:If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower。這會改變當前follower的term,因此可以再次投票
-
Check 2 for the
AppendEntriesRPC handler should be executed even if the leader didn’t send any entries. 也就是說,heartbeat應該同正常的AE同等對待。 -
nextIndex 和matchIndex的不同:
- nextIndex:是極其樂觀的,初始化為 index+1。ld用來指導FO從哪里開始復制日志
- matchIndex:是保守、安全的,初始化為-1。用來指示FO已經復制的最高索引。只有在FO對AE請求返回true時,這個matchIndex才更新。
-
對于過期響應的怎么處理:應該在args的參數中保留你發送時的term,然后在返回響應時,比較當前term和當前發送的term是否一樣。如果不一樣,直接丟了。
-
matchIndex的更新:如果在收到響應后,已經check過assumption了,那么應該將matchIndex=prevLogIndex+len(entrites[]),而不是直接 matchIndex=nextIndex-1 or matchIndex = len(log)。因為在發送請求的期間,nextIndex可能已經改變了(比如故障重啟),len(log)更會改變,比如有Client請求拼接。
-
快速恢復的nextIndex:https://thesquareplanet.com/blog/students-guide-to-raft/#an-aside-on-optimizations
在AE的reply時,返回多兩個字段:conflictIndex和conflitTerm
- 如果FO沒有prevLogIndex的日志,那么直接返回 conflictIndex=len(FO自己的所有log), conflictTerm=None
- 如果FO有prevLogIndex的日志,但是term不匹配(設FO的沖突的Term為termA)。則返回 conflictTerm=log[prevLogIndex].Term=termA。并把 conflictIndex設置為termA的第一個log
- 當LD收到沖突響應時,首先查找自己是否有 conflictTerm=termA的日志。如果有,將nextIndex設置為termaA的最后一個日志的下一個位置。
- 如果沒有termA的日志,則直接將nextIndex=conflictIndex
簡單折中實現就是只用conflictIndex不用conflictTerm,但這樣在某些情況下會多發送些log entry。
conflictIndex的作用:
- 跳過所有FO自己沒有的日志
- 跳過一個term的日志(這里就是把所有沖突的termA全部跳過)
conflitTerm的作用:
- 輔助,讓 LD 的nextIndex不要把所有的termA日志都跳過
-
If the leader has no new entries to send to a particular peer, the
AppendEntriesRPC contains no entries, and is considered a heartbeat. 也就是說,同步日志的頻率至少和hearbeat一樣!或者說,直接把同步日志這個功能做成heartbeat。如果有需要同步的日志,那么直接同步。如果沒有需要同步的日志,則看成是一個heartBeat(entries=null)。遇到的問題:在hearbeat實現的時候,沒有按AE的規則來嚴格設置prevLogIndex和相應的entries[],導致一些bug出現。比如一個hearbeat過來,帶了最新的leadercommit,把FO的rf.commit更新了,但hearbeat并沒有攜帶最新的log。
因此,在實現的時候,直接把同步日志做成心跳檢測。邏輯上統一了。并設置條件變量,在需要的時候手動觸發一次同步日志。(也就是設置死循環,用和heartBeat一樣的頻率觸發這個條件變量。然后這個條件變量也可以在其他地方手動觸發)
所以是把 AE看成是hearbeat… 有點奇怪的感覺
設計與編碼
有哪些周期性activity:
- ld的心跳檢測
- FO的election timeout
要加哪些額外的狀態?
- 當前ld的id
動作有哪些?
- ld發送心跳
- FO變成CA,并發起選舉,請求多數投票
- 被killed()了,那么剩下的已經啟動的goRoutine怎么辦?難道說每一個動作后面都要加killed()判斷?,那也太麻煩了吧。目前看來,只要在各個函數頭加上killed()判斷就行,即使剩下的go routine被執行了,也不會造成實質性的傷害。 然后每一個動作后加上killed()判斷,更直觀點,畢竟killed()也是assumption之一。
- 注意:rf.dead變量雖然是原子的,但這種原子性是為了保護這個變量。所以判斷killed()的時候,最好也當成關鍵性代碼,用mutex包裹起來。
- 小心!defer如果放在一個死循環里面,會執行不了!
2B
task
Implement the leader and follower code to append new log entries, so that the
go test -run 2Btests pass.
Hint
- 實現Start()函數拼接日志,并同步
- One way to fail to reach agreement in the early Lab 2B tests is to hold repeated elections even though the leader is alive. Look for bugs in election timer management, or not sending out heartbeats immediately after winning an election
設計與編碼
- 當service調用Start()時,拼接日志到log[],signal條件變量cond1
- 當ld的 last log index >= nextIndex時,要發送同步日志 syncLogToPeer。成功則更新nextIndex和matchIndex。失敗的話,減少nextIndex,繼續嘗試,signal一下條件變量cond1。然后剛成為LD的時候,應該也要啟動一下這個。
- 如何確認能commited?當 N > commitIndex,并且N大于大多數的matchIndex,并且log[N].term == rf.currentTerm,那么就能commit到這里。什么時候檢查?先定期吧,簡單點。
2C
task
- Complete the functions
persist()andreadPersist() - Insert calls to
persist()at the points where your implementation changes persistent state
Hint
- You will probably need the optimization that backs up nextIndex by more than one entry at a time
question
實現中疑惑的點:
- 同步日志的時候,如果用條件變量來實現,那么當一個server crash的時候,沒有時機去觸發這個條件變量。后面我還是用了for+sleep來實現。有什么好的辦法?
- 條件變量的用處似乎不大?因為都是周期性任務。而且如果用觸發來做,有些情況又觸發不了。不過實現的時候,apply log用了條件變量。這個是一定可以被觸發的。
- 代碼中還有比較多的todo偷懶沒搞hh,那些都是可以優化的點
后記
全部代碼寫完后,重新運行三個test。均通過。
由于1次實驗有偶然性,再運行10次 go test -run 2,也均通過。(要多運行幾次,小概率的bug才會出現)
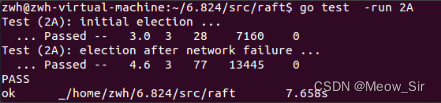
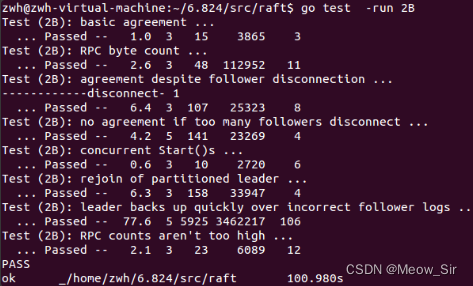
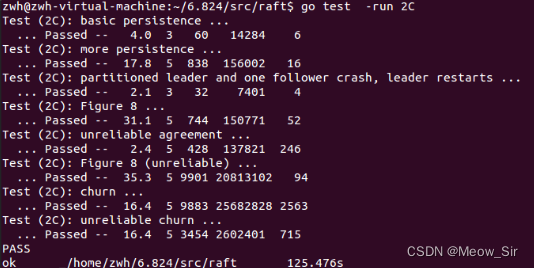
-
寫代碼前,還是得弄清楚需求(這里是看大量lab相關的文檔)。寫代碼加調試花了2~3天(周日下午到周三早上,期間還幫師兄改了論文),但看論文和文檔遠遠不止。
-
寫完后,看了別人的代碼,差別還是挺大的hh,自己實現得比較亂,別人可以這么優雅
-
而且要遵守建議和論文中的規則,自己創造性地“亂寫”(沒有被證明對),那么debug之路會很漫長
-
RPC調用與assumption
-
日志索引從1開始,確實很妙,省去了非常多的代碼判斷。
LEC5:GO, Threads, and Raft
- 在寫實驗的時候,用大粒度鎖就行,別trick.去想著從cpu層面優化~
- The Go Memory Model:If you must read the rest of this document to understand the behavior of your program, you are being too clever. Don’t be clever.
- 如果你的代碼中出現了常數,要想想為什么可以是常數?為什么是這個常數,其他常數不行?
go threads技巧
waitGroup、閉包(能訪問到創建該線程的上下文)
//1.可以作為投票的一種實現
func main() {var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func(x int) {sendRPC(x)wg.Done()}(i) //2.i要傳遞}wg.Wait()
}func sendRPC(i int) {println(i)
}周期性任務
func periodic() {for {println("tick")time.Sleep(1 * time.Second)mu.Lock() //如果不加鎖,無法保證能馬上見到其他人作的改變if done {return}mu.Unlock()}
}
條件變量 (signal):建議實驗中直接用broadcast
func main() {rand.Seed(time.Now().UnixNano())count := 0finished := 0var mu sync.Mutexcond := sync.NewCond(&mu)for i := 0; i < 10; i++ {go func() {vote := requestVote()mu.Lock()defer mu.Unlock()if vote {count++}finished++cond.Broadcast()}()}mu.Lock() //注意。要先獲得lock才能wait。相當于java中,synchorized 這個功能放進了Object中了for count < 5 && finished != 10 {cond.Wait()}if count >= 5 {println("received 5+ votes!")} else {println("lost")}mu.Unlock()
}func requestVote() bool {time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)return rand.Int() % 2 == 0
}
mu.Lock()
// do something that might affect the condition
cond.Broadcast()
mu.Unlock()----mu.Lock()
while condition == false {cond.Wait()
}
// now condition is true, and we have the lock
mu.Unlock()
channel(無緩沖channel):
- 是一種沒有容量的隊列。當發送時,如果沒有接收方,發送線程會被阻塞。相反地,如果沒有人發送,接收方也會被阻塞
- 可用于生產者消費者
- waitGroup效果
func main() {done := make(chan bool)for i := 0; i < 5; i++ {go func(x int) {sendRPC(x)done <- true}(i)}//和waitGroup的效果一樣for i := 0; i < 5; i++ {<-done}
}func sendRPC(i int) {println(i)
}
raft實驗易錯點
- 不應該在調用RPC時,持有鎖。1影響效率,2容易死鎖。可以通過傳遞assumption消除
debug技巧
- cirt + /,可以打印堆棧





利用腳本進行區塊鏈系統監控)



之SpringCloud Gateway)
 Object Pascal 學習筆記---第5章第3節(自定義托管記錄))






】AkkaRpcActor設計與實現:接收RPC消息以及處理邏輯)

