一. 前置知識
1.1馮諾依曼體系結構
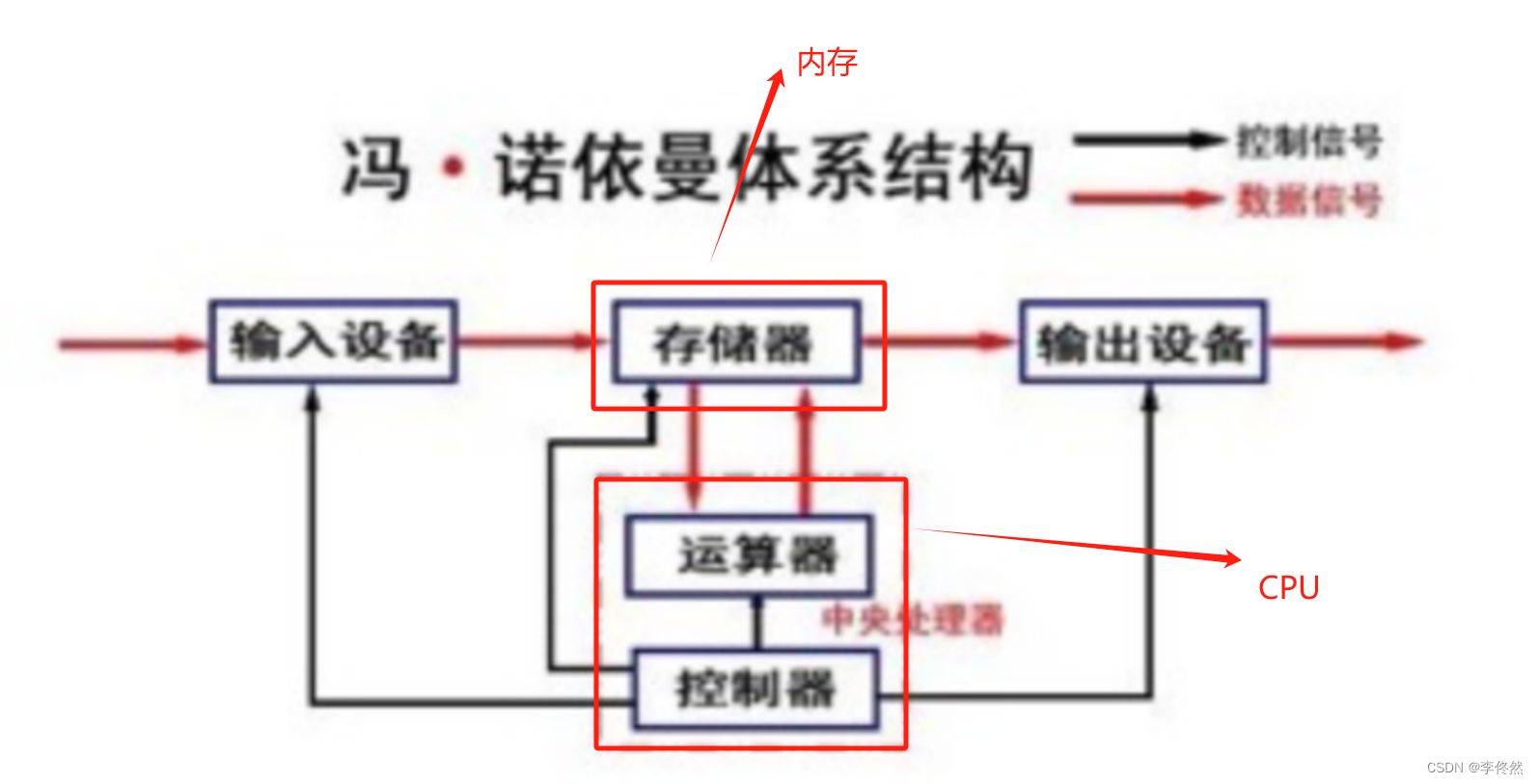
我們常見的計算機,如筆記本。我們不常見的計算機,如服務器,大部分都遵守馮諾依曼體系
為什么計算機要采用馮諾依曼體系呢?
在計算機出現之前有很多人都提出過計算機體系結構,但最終選擇馮諾依曼是因為用比較少的錢就可以做出效率不錯的計算機
截至目前,我們所認識的計算機,都是由一個個的硬件組件組成
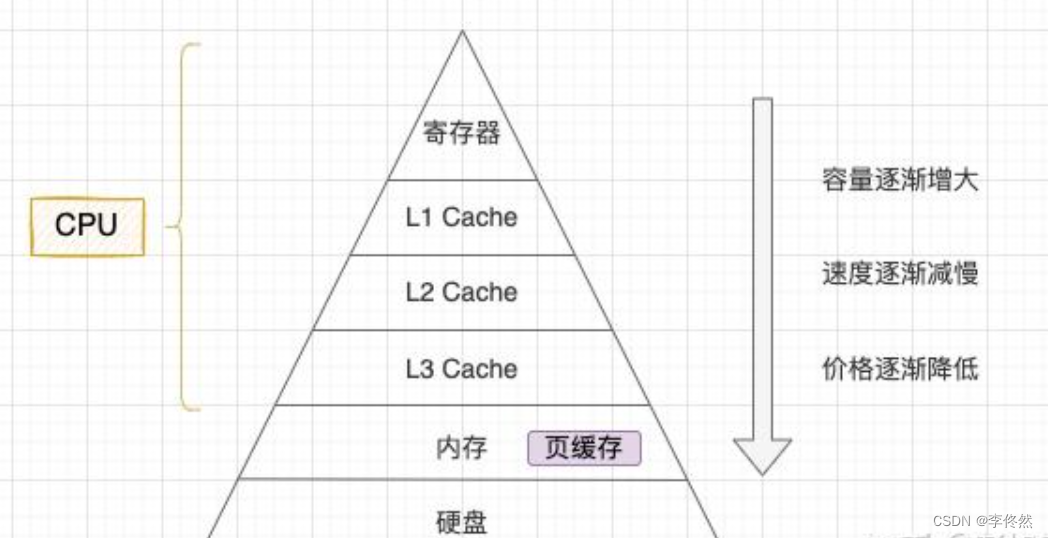
1.2 操作系統 (OS)
1.2.1 簡述操作系統
操作系統是什么?
是軟件,管理軟硬件資源,開機自動再內存啟動
為什么開機自動啟動,為什么用它?
操作系統管理軟硬件資源,為用戶提供良好的體驗,如果沒有它,用戶就得自己手動調試硬件,自己兼顧軟硬件

1.2.2 用戶部分
用戶就是指的是使用者,用戶操作接口就是操作系統給用戶提供的系統調用接口
為什么要提供操作接口?
操作接口分為shell外殼(Linux下的shell,Windows下的圖形化界面),lib(動靜態庫),部分指令(部分指令指的是操作系統提供的一些基本命令或者工具)
1) 用戶直接使用接口,降低了技術門檻
2) 其次是操作系統怕用戶搞破壞,給硬件搞壞
system call就是操作系統向上層提供的系統調用函數
1.2.3 系統軟件部分
這部分就是操作系統管理軟硬件,操作系統對軟硬件資源的管理分為兩步:
1.2.4硬件部分
二.進程
2.1基本概念
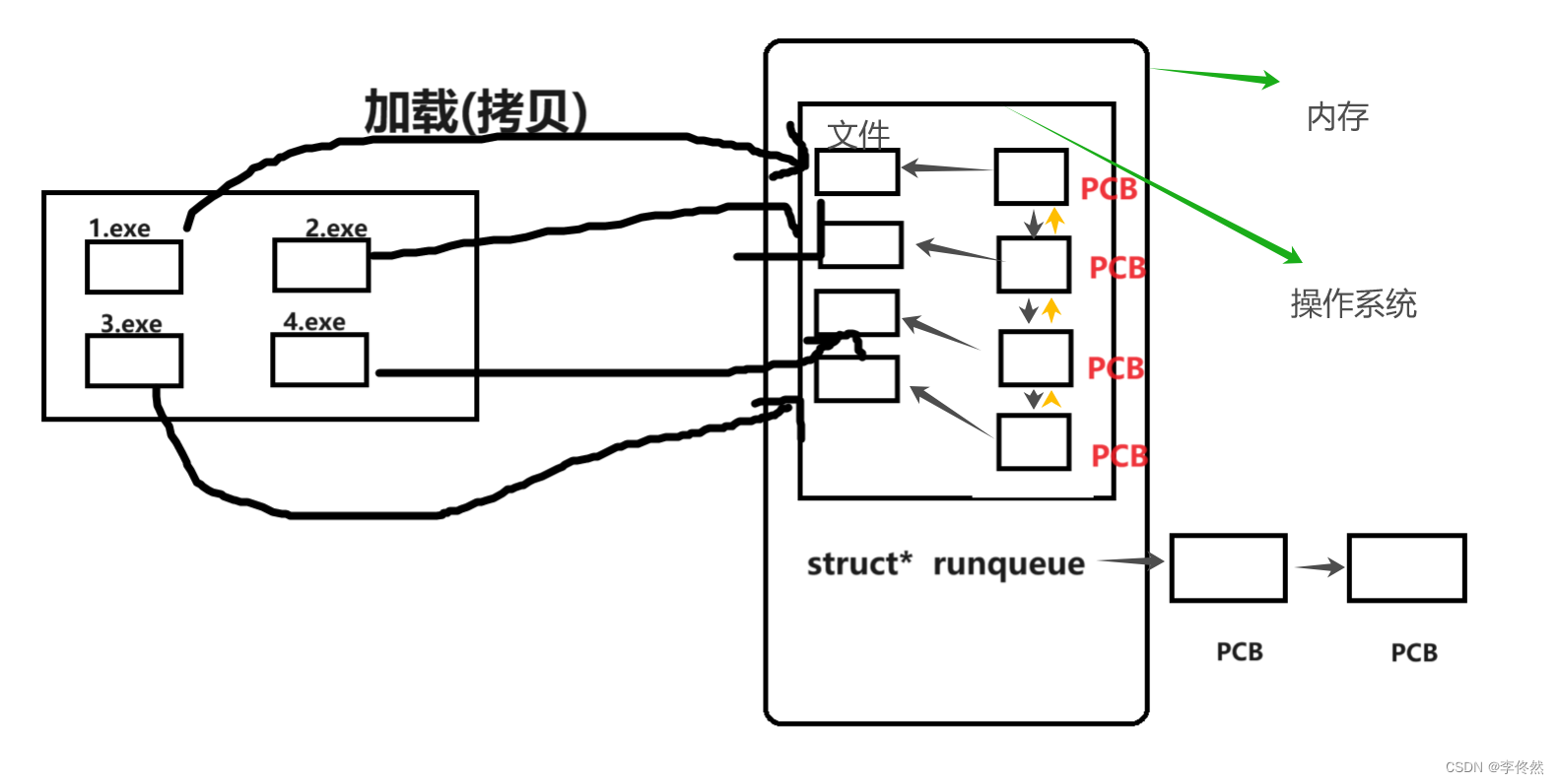
1、已經加載到內存中的程序/正在運行的程序叫做進程,一個操作系統不僅僅只能運行一個進程,可以同時運行多個進程。
2、操作系統,必須將進程管理起來,而管理的過程是先描述,再組織。
3、任何一個進程,在加載到內存的時候,形成真正的進程時,操作系統要先創建描述進程(屬性)的結構體對象PCB(process control block)---進程控制塊(進程屬性的集合)。
4、此結構體包括進程編號,進程的狀態,優先級,代碼和數據相關的指針信息等。
5、根據進程的PCB類型,該進程創建對應的PCB對象。有了PCB結構體對象,在操作系統中對進程進行管理,變成了對單鏈表進行增刪改查。
6、進程=內核數據結構(PCB)+代碼和數據。
7、在linux中描述進程的結構體叫做task_struct,最基本的組織進程task struct方式采用雙向鏈表組織的,里面包含進程的所有屬性。
2.2Linux有關進程的指令

 ?
?

#include<stdio.h>
#include<unistd.h>int main()
{while(1){printf("我的pid是%d,我的ppid是%d\n",getpid(),getppid());sleep(1);}return 0;
}
父進程含義:
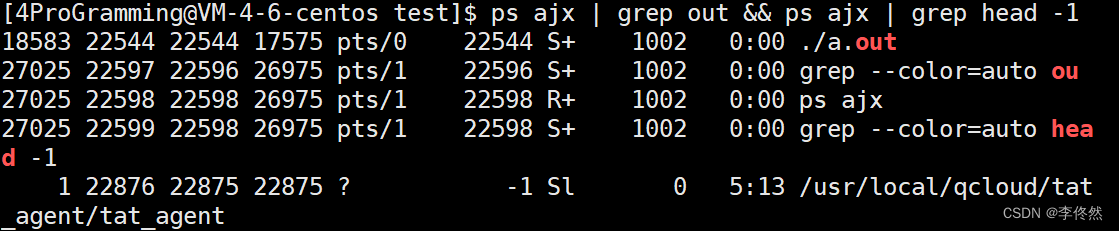
我們登錄xshell時,系統會為我們創建一個bash進程,即命令行解釋的進程,幫我們在顯示器中打印對話框終端。
我們在對話框中輸入的所有的指令都是bash進程的子進程。
bash進程只進行命令行解釋,具體執行出錯只會影響他的子進程。
進程PID會變化,而它的ppid一般在同一個終端下啟動,它都是不變的,而它的所有的進程的父進程都是bash。
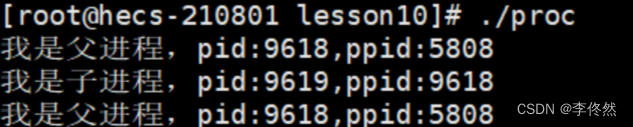
fork:創建子進程:
創建子進程PCB,填充PCB對應的內容,讓子進程和父進程指向相同的代碼,父子進程都是有獨立的task struct,可以被CPU調度運行了。
不同方法創建子進程
①./運行程序---指令級別創建子進程
②fork()?--- 代碼層面創建子進程
為什么fork要給子進程返回零,給父進程返回子進程PID?
fork給父進程返回子進程pid,用來標定子進程的唯一性。而子進程只要調用getpid()就可獲取進程的PID。返回不同的返回值,是為了區分,讓不同的執行流,執行不同的代碼快。(一般而言,fork之后的代碼父子共享)
一個函數是如何做到返回兩次的?一個變量怎么會有不同的內容?如何理解?
任何平臺,進程在運行的時候是具有獨立性的。代碼共享并不影響獨立性,因為代碼不可修改。而數據上互相獨立,子進程理論上要拷貝父進程數據。但創建出來的子進程,對于大部分父進程不會訪問,所以子進程在訪問父進程數據時進行寫時拷貝即可(子進程和父進程訪問的是不同的內存區)。
誰決定把一個進程放到CPU上去運行呢?是由調度器(CPU)去決定的。
如果父子進程被創建好fork()往后誰先進行呢?誰先進行由調度器決定,不確定。
三. 進程的狀態
3.1?概括
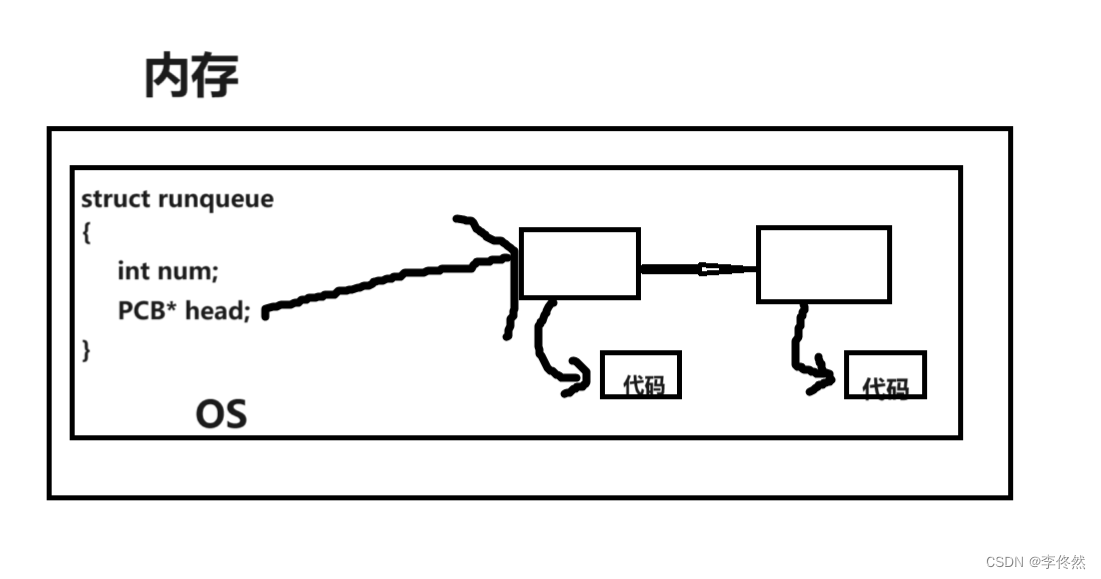
進程狀態其實就是進程PCB中的一個變量,int status,更改狀態就是更改這個變量的
#define NEW 1
#define RUNNING 2
#define BLOCK 3pcb->status = NEW;
if(pcb->status == NEW) //如果狀態是NEW,該放入哪個隊列
else if(pcb->status == RUNNING) //如果是RUNNING,該放入哪個隊列3.2 運行狀態
只要在運行隊列的進程,狀態就是運行狀態
3.3 阻塞狀態
所編寫的代碼中或多或少都會訪問系統的某些資源,比如鍵盤,在調用scanf函數時,就是從鍵盤拿數據,如果一直不輸入,鍵盤上就不會有數據? ?------->? ?進程要訪問的資源就沒有就緒? -------->? 不具備足夠的資源和條件? ?--------->? ?進程代碼就沒法接著執行。
這時候的進程狀態就是阻塞狀態
3.4掛起狀態(阻塞掛起狀態)
如果一個進程被阻塞了,注定了,這個進程需要的資源沒有就緒,如果這時候操作系統的內存資源嚴重不足了怎么辦呢?操作系統會將內存數據進行置換到外設,將所有的阻塞狀態的進程置換到外設的swap分區,( 補充:swap分區時在磁盤的一塊區域,大小和內存大小一樣或者比內存小,不能太大,如果太大,就會很依賴swap分區,就會增加置換次數,置換次數變多,IO操作次數變多,效率就會受到影響 ),被置換到sawp分區的進程的狀態就是掛起,如果不講這些進程置換,計算機就宕機了,所以置換就算非常慢也沒有辦法。這種狀態一般不會出現,出現了就說明計算機快完蛋了。
體現在Linux中,有些差別但是無可厚非
①R運行狀態: 表明進程是在運行中或者在運行隊列里。
②S睡眠狀態: 意味著進程在等待事件完成。
③D磁盤休眠狀態:讓進程在磁盤寫入完畢期間,這個進程不能被任何人殺掉。
④T停止狀態: 可以通過發送 SIGSTOP(kill -19) 信號給進程來停止(T)進程。這個被暫停的進程可以通過發送 SIGCONT 信號(kill -18)讓進程繼續運行。
⑤X死亡狀態:操作系統將該進程的數據全部釋放掉。
⑥Z僵尸進程:進程一般退出的時候,如果父進程,沒有主動回收子進程信息,子進程會一直讓自己出于Z狀態,進程的相關資源尤其是task_struct結構體不能被釋放。
四. 進程優先級
4.1基本概念


4.1 PRI NI
五. 環境變量
5.1基本概念
5.2常見環境變量
5.3查看環境變量方法
5.4和環境變量相關的命令
5.5環境變量的組織方式
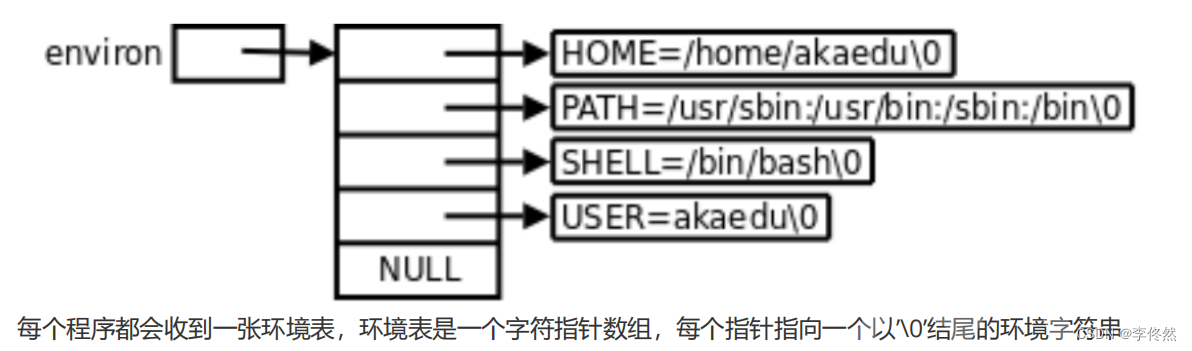
5.6通過代碼如何獲取環境變量
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{int i = 0;for(; env[i]; i++){printf("%s\n", env[i]);}return 0;
}通過第三方變量environ,libc中定義的全局變量environ指向環境變量表,environ沒有包含在任何頭文件中,所以在使用時 要用extern聲明。
#include <stdio.h>
int main(int argc, char *argv[])
{extern char **environ;int i = 0;for(; environ[i]; i++){printf("%s\n", environ[i]);}return 0;
}六. 進程地址空間
6.1程序地址空間分布情況
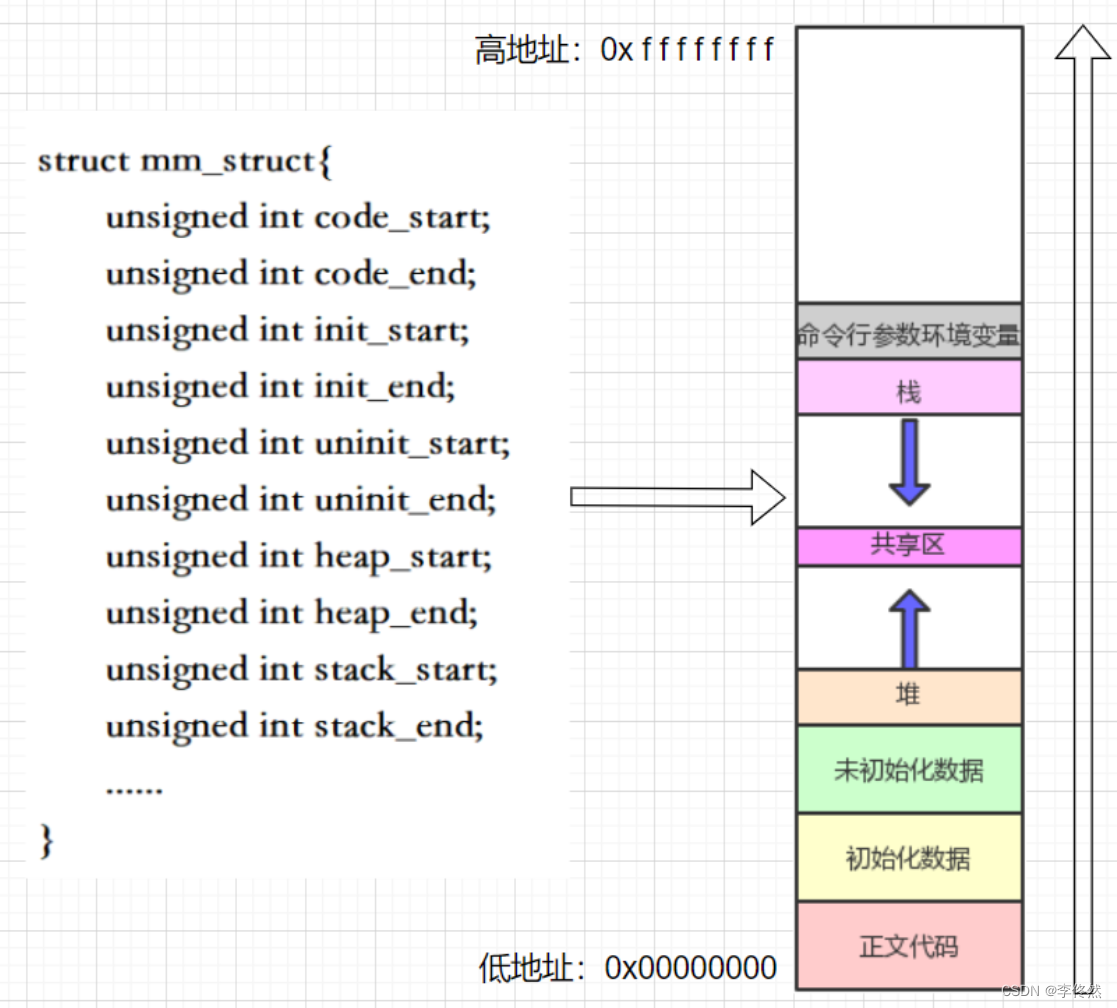
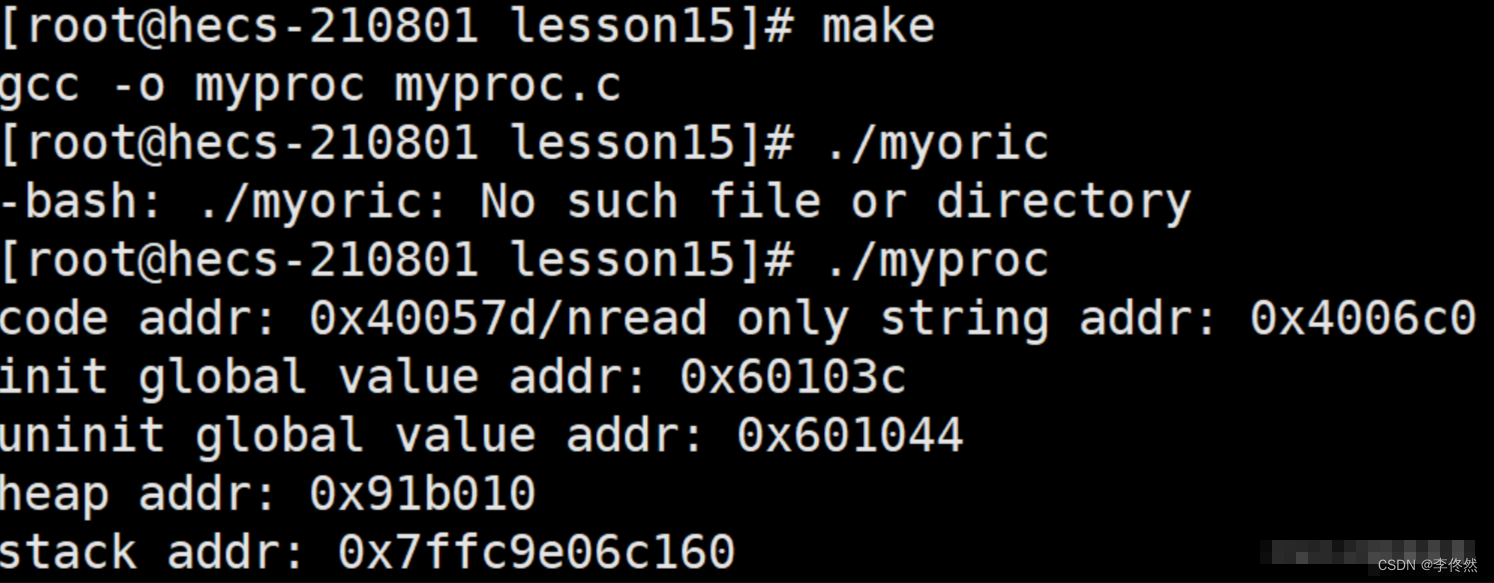
//myproc.c#include <stdio.h>
#include <stdlib.h>int g_val_1;
int g_val_2 = 100;int main()
{printf("code addr: %p/n", main);const char *str = "hello bit";printf("read only string addr: %p\n", str);printf("init global value addr: %p\n", &g_val_2);printf("uninit global value addr: %p\n", &g_val_1);char *mem = (char*)malloc(100);printf("heap addr: %p\n", mem);printf("stack addr: %p\n", &str);return 0;
}
注:static修飾的局部變量,編譯的時候已經被編譯到全局數據區。
6.2地址空間
一個小實驗
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>int g_val = 100;int main()
{pid_t id = fork();if (id == 0){int cnt = 5;//子進程while (1){printf("I am child, pid : %d, ppid : %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);sleep(1);if (cnt) cnt--;else{g_val = 200;printf("子進程change g_val : 100->200\n");cnt--;}}}else{//父進程while (1){printf("I am parent, pid : %d, ppid : %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);sleep(1);}}
}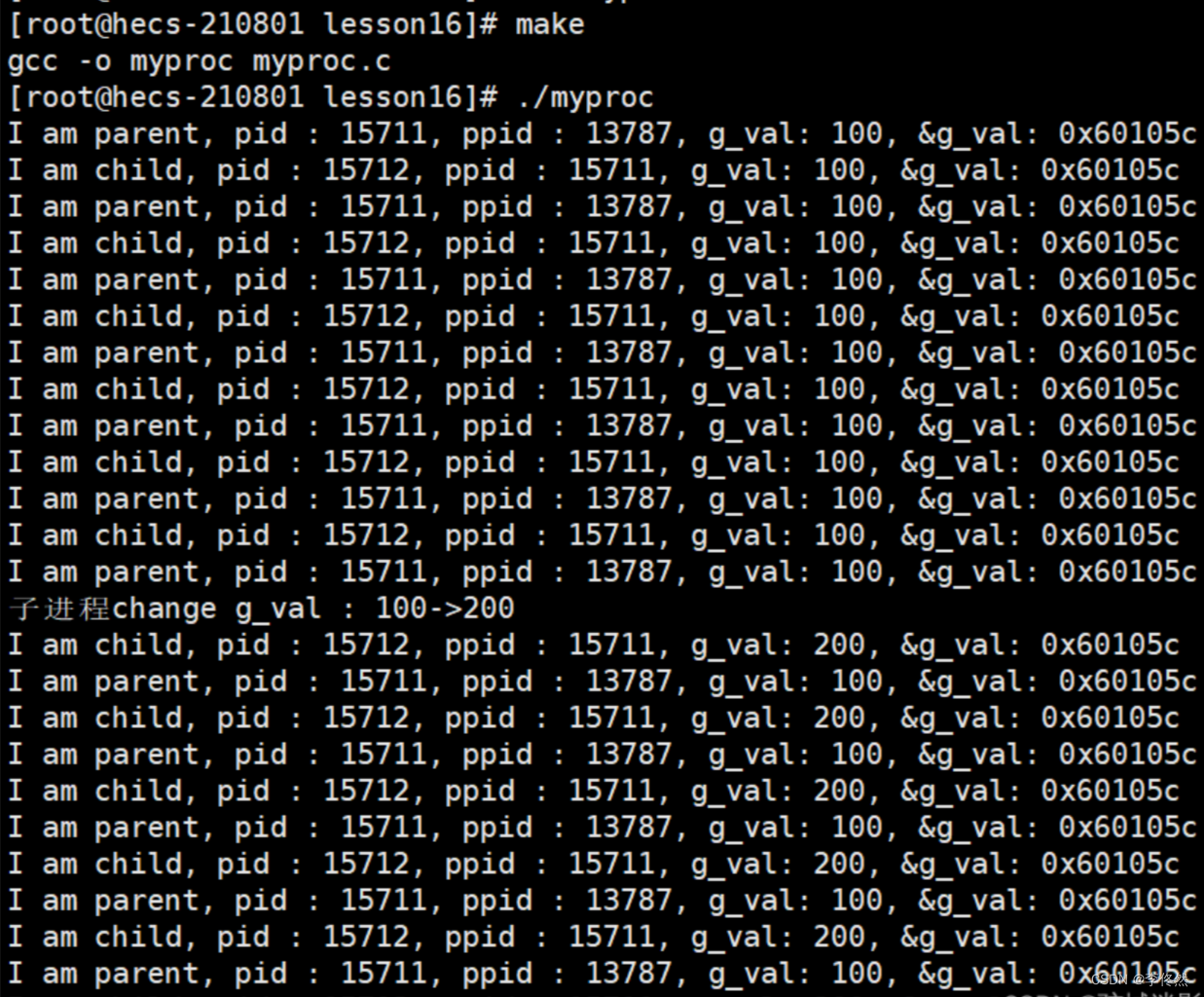
問1:怎么可能同一個變量,同一個地址,同時讀取,讀到了不同的內容結論?
答:
①如果變量的地址是物理地址,不可能存在上面的現象,絕對不是物理地址,是線性地址/虛擬地址。
②子進程的進程地址空間繼承自父進程,但是當實際訪問讀取時,需要根據相同的虛擬地址(映射)查找不同的物理地址。
③修改子進程變量時,先經過寫時拷貝(是由操作系統自動完成的)并重新開辟空間,但是在這個過程中,不會影響虛擬地址。
拓展:在32位計算機中,有32位的地址和數據總線
每一根地址總線只有0、1(32根,2^32種)
(三類線:地址總線,數據總線控制,總線
CPU和內存中連的線叫系統總線
內存和外設中連的線叫IO總線)
問2:什么叫做地址空間?如何理解?
答:
①進程在極端情況下所能訪問的物理內存的最大值。地址,總線,排列組合形成地址范圍[0,2^32]。
②通過定義一個區域的起始和結束來實現地址空間上的區域劃分。
③所謂的進程地址空間,本質上是一個描述進程可視范圍的大小
地址空間內一定要存在各種區域劃分,對線性地址進行start和end即可
在范圍內,連續空間中,每一個最小單位都可以有地址,這個地址可以被對象直接使用。
問3:地址空間本質是內核的一個數據結構對象,類似PCB一樣,地址空間也是要被操作系統管理的:先描述,再組織 。這樣做的目的是什么?
答:
①讓進程以統一的視角看待內存,進程就不需要再維護自己冗余的代碼
②增加進程虛擬地址空間可以讓我們訪問內存的時候,增加一個轉換的過程,在這個轉化的過程中,可以對尋址記請求進行審查,所以一旦異常訪問,直接攔截,該請求不會到達內存,保護物理內存。
6.3頁表
①每個當前正在執行的進程的頁表,在CPU內有一個cr3寄存器,保存當前頁表的起始地址(這是物理地址)。該進程在運行期間cr3寄存器中頁表的地址/當前進程正在運行的臨時數據,本質上屬于進程的硬件上下文。
②代碼區和字符常量區所匹配的頁表所對應的虛擬物理地址映射標志位決定是否只讀。(代碼是只讀的,字符常量區只讀的)
③操作系統對大文件可以實現分批加載,惰性加載的方式。另外有一個標志位標識對你的代碼和數據是否已經被加載到內存。
④如果發現當前代碼和數據并未加載到內存里,此時,操作系統觸發缺頁中斷。將未加載到內存中的代碼和數據,重新加載到內存里,把這段內存的地址填寫到對應的頁表當中,再訪問。
注:寫時拷貝也是缺頁中斷:一旦創建子進程,可讀的內容不變,可寫的內容對應的虛擬內存以及操作系統會把父進程對應的可寫區域內容全部改成只讀,從而子進程繼承下來也為只讀。一旦父進程或子進程嘗試對數據段進行寫入時,會通過觸發讀權限問題進行寫時拷貝。
問:進程在被創建的時候,是先創建內核數據結構呢,還是先加載對應的可執行程序呢?
答:先要創建內核數據結構,即處理好進程維護的PCB地址空間和頁表對應關系,再慢慢加載可執行程序。
⑤掛起:進程對應的代碼和數據全部釋放掉,頁表清空,并且頁表標志位,對應虛擬地址所表征的是否在內存的標志位置為0代表不在內存里。
6.4 Linux的內存管理模塊:進程管理和內存管理,實現軟件層面上的解耦合
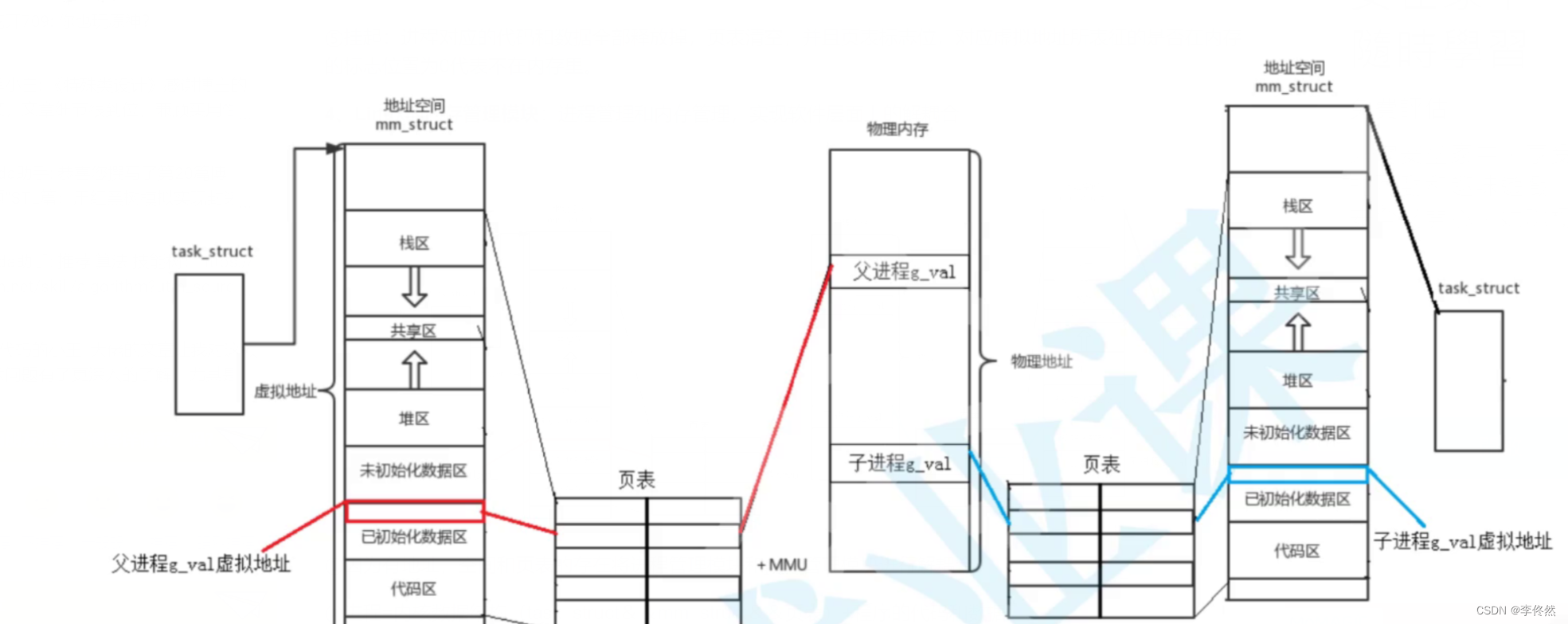
①因為有地址,空間和頁表的存在將進程管理模塊和內存管理模塊進行解耦合
②進程=內核數據結構(task_struct&&mm_struct&&頁表)+程序的代碼和數據
③總結:進程具有獨立性,為什么?怎么做到的?
a.每個進程具有單獨的PCB和進程地址空間頁表,所以在那個數據結構上,每個進程都是互相獨立的。
b.只要將頁表,映射到物理內存的不同區域,每個區域的代碼和數據就會互相解耦。
c.把PCB換了,進程地址空間自然而然就換了。頁表的起始地址屬于進程的下文,進程只要切換,頁表也就切換。
補充:缺頁中斷的好處:缺頁中斷本質上是重新分配內存,改變加載程序的先后順序和單次加載量。提高首次加載速度,局部上加載速度變快。很好的將內存分批釋放,減少內存申請空窗期,加快內存申請釋放,從而變相是我們內存的使用率越來越高。
?

——第5章 語句)







)
![系統學習Python——裝飾器:類裝飾器-[單例類:編寫替代方案]](http://pic.xiahunao.cn/系統學習Python——裝飾器:類裝飾器-[單例類:編寫替代方案])








