? ? ? ?有沒有想過今天的一些應用程序是如何看起來幾乎神奇地智能的?這種魔力很大一部分來自于一種叫做RAG和LLM的東西。把RAG(Retrieval Augmented Generation)想象成人工智能世界里聰明的書呆子,它會挖掘大量信息,準確地找到你的問題所需要的信息。然后,還有LLM(大型語言模型),就像著名的GPT系列一樣,它將基于其令人印象深刻的文本生成功能生成平滑的答案。把這兩者結合在一起,你就得到了一個人工智能,它不僅智能,而且具有超強的相關性和上下文感知能力。這就像是把一個超快速的研究助理和一個機智的健談者結合在一起。這個組合非常適合任何事情,從幫助你快速找到特定信息到進行令人驚訝的真實聊天。
? ? ? ?但問題是:我們如何知道我們的人工智能是否真的很有幫助,而不僅僅是在說花里胡哨的胡話?這就是評估的意義所在。我們需要確保我們的人工智能不僅準確,而且相關、有用,不會偏離奇怪的軌道。畢竟,如果智能助手不能理解你的需求,或者給你的答案太離譜,它有什么用?
? ? ? ?在這篇文章中,我們將深入探討如何評估我們的人工智能系統。
一、開發階段
? ? ? ?在開發階段,必須按照典型的機器學習模型評估流程進行思考。在標準的AI/ML設置中,我們通常使用幾個數據集,如開發、訓練和測試集,并使用定量指標來衡量模型的有效性。然而,評估大型語言模型(LLM)非常有挑戰,傳統的定量指標很難捕捉LLM的輸出質量,因為這些模型擅長生成多樣化和創造性的語言。因此,很難有一套全面的標簽來進行有效的評估。
? ? ? 在學術界,研究人員可能會使用MMLU等基準和分數來對LLM進行排名,并可能聘請人類專家來評估LLM輸出的質量。然而,這些方法并不能無縫地過渡到生產環境,因為生產環境的開發速度很快,實際應用需要立即取得結果。這不僅僅關乎LLM的性能,現實世界的需求需要考慮整個過程,包括數據檢索、Prompt合成和LLM。為每一次新的系統迭代或當文檔或域發生變化時,制定一個人工策劃的基準是不切實際的。此外,該行業的快速開發速度無法承受人類測試人員在部署前評估每個更新的漫長等待。因此,調整學術界的評估策略,以適應快速、注重成果的生產環境,是一個相當大的挑戰。
? ? ? 因此,如果您遇到這種情況,您可能會考慮讓LLM提供的偽分數。這個分數可以反映自動化評估指標和人類判斷的組合,這種混合方法旨在彌合人類評估者的細微理解與機器評估的可擴展、系統分析之間的差距。
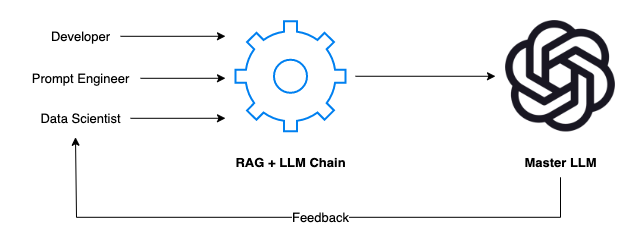
? ? ? ?例如,如果您的團隊正在開發一個內部LLM,該LLM是針對您的特定領域和數據進行訓練的,那么該過程通常需要開發人員、Prompt工程師和數據科學家的合作。每個成員都發揮著關鍵作用:
開發人員就是架構師。他們構建了應用程序的框架,確保RAG+LLM鏈無縫集成,并且可以毫不費力地在不同的場景中進行切換。
Prompt工程師是創造性的。他們設計了模擬真實世界用戶交互的場景和提示。他們思考“如果”,并推動系統處理廣泛的主題和問題。
數據科學家是戰略家。他們分析響應,深入研究數據,并運用他們的統計專業知識來評估人工智能的性能是否符合標準。
? ? ? ?這里的反饋回路是必不可少的。當我們的人工智能響應提示時,團隊會仔細檢查每一個輸出。人工智能理解這個問題了嗎?回復是否準確且相關?語言能更流暢些嗎?然后將此反饋反饋回系統以進行改進。
? ? ? 下面使用像OpenAI的GPT-4這樣的主LLM作為評估自研LLM的基準,以下是具體的操作步驟:
生成相關數據集:首先創建一個反映用戶領域細微差別的數據集。該數據集可以由專家策劃,也可以在GPT-4的幫助下進行合成來節省時間,確保其符合您的黃金標準。
定義指標:利用LLM的優勢來定義指標。可以選擇一些開源工具進行評估,比如Langchain和其他一些庫(如ragas[1])。評價指標,如可信度、上下文回憶、上下文精度、答案相似性等。
自動化評估流程:為了跟上快速的開發周期,建立一個自動化的流程。這將在每次更新或更改后,根據預定義的指標一致地評估應用程序的性能。通過自動化流程,您可以確保您的評估不僅是徹底的,而且是高效的迭代,從而實現快速的優化和細化。
? ? ? 例如,在下面的演示中,我將向您展示如何使用OpenAI的GPT-4在簡單的文檔檢索對話任務中自動評估各種開源LLM。
? ? ? ? 首先,我們使用OpenAI GPT-4創建從文檔派生的合成數據集,如下所示:
import osimport jsonimport pandas as pdfrom dataclasses import dataclassfrom langchain.chat_models import ChatOpenAIfrom langchain.chains import LLMChainfrom langchain.prompts import PromptTemplatefrom langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.output_parsers import JsonOutputToolsParser, PydanticOutputParserfrom langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate?QA_DATASET_GENERATION_PROMPT = PromptTemplate.from_template("You are an expert on generate question-and-answer dataset based on a given context. You are given a context. ""Your task is to generate a question and answer based on the context. The generated question should be able to"" to answer by leverage the given context. And the generated question-and-answer pair must be grammatically ""and semantically correct. Your response must be in a json format with 2 keys: question, answer. For example,""\n\n""Context: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.""\n\n""Response: {{""\n"" \"question\": \"Where is France and what is it’s capital?\",""\n"" \"answer\": \"France is in Western Europe and it’s capital is Paris.\"""\n""}}""\n\n""Context: The University of California, Berkeley is a public land-grant research university in Berkeley, California. Established in 1868 as the state's first land-grant university, it was the first campus of the University of California system and a founding member of the Association of American Universities.""\n\n""Response: {{""\n"" \"question\": \"When was the University of California, Berkeley established?\",""\n"" \"answer\": \"The University of California, Berkeley was established in 1868.\"""\n""}}""\n\n""Now your task is to generate a question-and-answer dataset based on the following context:""\n\n""Context: {context}""\n\n""Response: ",)?OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")?if OPENAI_API_KEY is None:raise ValueError("OPENAI_API_KEY is not set")?llm = ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.7,response_format={"type": "json_object"},)?chain = LLMChain(prompt=QA_DATASET_GENERATION_PROMPT,llm=llm)?file_loader = PyPDFLoader("./data/cidr_lakehouse.pdf")text_splitter = CharacterTextSplitter(chunk_size=1000)chunks = text_splitter.split_documents(file_loader.load())?questions, answers = [], []for chunk in chunks:for _ in range(2):response = chain.invoke({"context": chunk})obj = json.loads(response["text"])questions.append(obj["question"])answers.append(obj["answer"])df = pd.DataFrame({"question": questions,"answer": answers})?df.to_csv("./data/cidr_lakehouse_qa.csv", index=False)
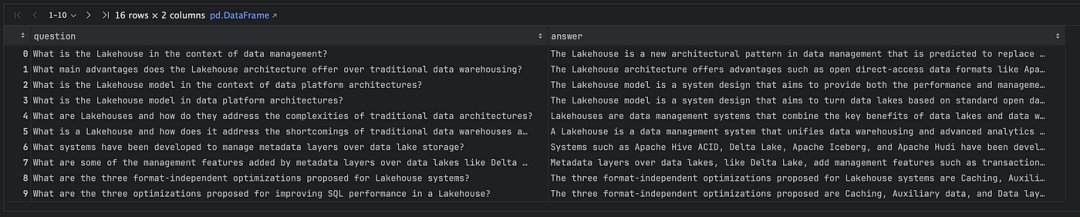
? ? ? ?在運行上述代碼后,我們獲得了一個CSV文件作為結果。此文件包含與我們輸入的文檔相關的成對問題和答案,如下所示:
? ? ? ?然后,我們使用Langchain構建簡單的DocumentRetrievalQA鏈,并通過Ollama[2]可以在本地運行幾個開源LLM(可以在這里[3]找到一些教程)。
from tqdm import tqdmfrom langchain.chains import RetrievalQAfrom langchain.chat_models import ChatOllamafrom langchain.vectorstores import FAISSfrom langchain.embeddings import HuggingFaceEmbeddings?vector_store = FAISS.from_documents(chunks, HuggingFaceEmbeddings())retriever = vector_store.as_retriever()?def test_local_retrieval_qa(model: str):chain = RetrievalQA.from_llm(llm=ChatOllama(model=model),retriever=retriever,)predictions = []for it, row in tqdm(df.iterrows(), total=len(df)):resp = chain.invoke({"query": row["question"]})predictions.append(resp["result"])df[f"{model}_result"] = predictionstest_local_retrieval_qa("mistral")test_local_retrieval_qa("llama2")test_local_retrieval_qa("zephyr")test_local_retrieval_qa("orca-mini")test_local_retrieval_qa("phi")?df.to_csv("./data/cidr_lakehouse_qa_retrieval_prediction.csv", index=False)
? ? ? ?總之,上面的代碼建立了一個簡單的文檔檢索鏈。我們使用幾個模型來執行這個鏈,如Mistral、Llama2、Zephyr、Orca-mini和Phi。因此,我們在現有的DataFrame中添加了五個額外的列,以存儲每個LLM模型的預測結果。

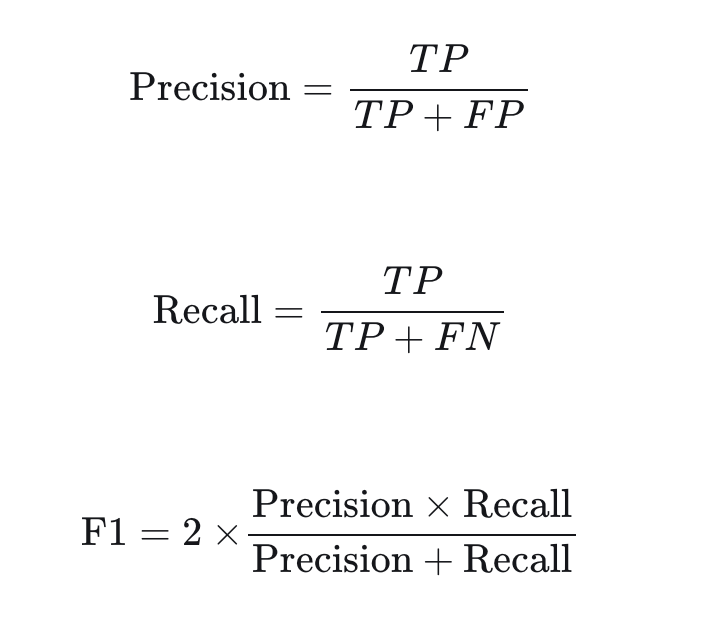
? ? ? 現在,讓我們使用OpenAI的GPT-4來定義一個主鏈,以評估預測結果。評估指標采用一個在傳統的AI/ML問題中很常見的評估指標,類似F1分數。為了實現這一點,我們將定義一些概念,如真陽性(TP)、假陽性(FP)和假陰性(FN),定義如下:
TP:在答案和ground truth都正確的事實。
FP:答案中有陳述,但在ground truth中沒有。
FN:在ground truth中找到了相關陳述,但在回答中遺漏了。
有了這些定義,我們可以使用以下公式計算精度、召回率和F1分數:
import osimport numpy as npimport pandas as pdfrom tqdm import tqdmfrom langchain.chains import LLMChainfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplate?OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")?if OPENAI_API_KEY is None:raise ValueError("OPENAI_API_KEY is not set")?CORRECTNESS_PROMPT = PromptTemplate.from_template("""Extract following from given question and ground truth. Your response must be in a json format with 3 keys and does not need to be in any specific order:- statements that are present in both the answer and the ground truth- statements present in the answer but not found in the ground truth- relevant statements found in the ground truth but omitted in the answerPlease be concise and do not include any unnecessary information. You should classify the statements as claims, facts, or opinions with semantic matching, no need exact word-by-word matching.Question:What powers the sun and what is its primary function?Answer: The sun is powered by nuclear fission, similar to nuclear reactors on Earth, and its primary function is to provide light to the solar system.Ground truth: The sun is actually powered by nuclear fusion, not fission. In its core, hydrogen atoms fuse to form helium, releasing a tremendous amount of energy. This energy is what lights up the sun and provides heat and light, essential for life on Earth. The sun's light also plays a critical role in Earth's climate system and helps to drive the weather and ocean currents.Extracted statements:[{{"statements that are present in both the answer and the ground truth": ["The sun's primary function is to provide light"],"statements present in the answer but not found in the ground truth": ["The sun is powered by nuclear fission", "similar to nuclear reactors on Earth"],"relevant statements found in the ground truth but omitted in the answer": ["The sun is powered by nuclear fusion, not fission", "In its core, hydrogen atoms fuse to form helium, releasing a tremendous amount of energy", "This energy provides heat and light, essential for life on Earth", "The sun's light plays a critical role in Earth's climate system", "The sun helps to drive the weather and ocean currents"]}}]Question: What is the boiling point of water?Answer: The boiling point of water is 100 degrees Celsius at sea level.Ground truth: The boiling point of water is 100 degrees Celsius (212 degrees Fahrenheit) at sea level, but it can change with altitude.Extracted statements:[{{"statements that are present in both the answer and the ground truth": ["The boiling point of water is 100 degrees Celsius at sea level"],"statements present in the answer but not found in the ground truth": [],"relevant statements found in the ground truth but omitted in the answer": ["The boiling point can change with altitude", "The boiling point of water is 212 degrees Fahrenheit at sea level"]}}]Question: {question}Answer: {answer}Ground truth: {ground_truth}Extracted statements:""",)?judy_llm = ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.0,response_format={"type": "json_object"},)?judy_chain = LLMChain(prompt=CORRECTNESS_PROMPT,llm=judy_llm)?def evaluate_correctness(column_name: str):chain = LLMChain(prompt=CORRECTNESS_PROMPT,llm=ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.0,response_format={"type": "json_object"},))key_map = {"TP": "statements that are present in both the answer and the ground truth","FP": "statements present in the answer but not found in the ground truth","FN": "relevant statements found in the ground truth but omitted in the answer", # noqa: E501}TP, FP, FN = [], [], []for it, row in tqdm(df.iterrows(), total=len(df)):resp = chain.invoke({"question": row["question"],"answer": row[column_name],"ground_truth": row["answer"]})obj = json.loads(resp["text"])TP.append(len(obj[key_map["TP"]]))FP.append(len(obj[key_map["FP"]]))FN.append(len(obj[key_map["FN"]]))# convert to numpy arrayTP = np.array(TP)FP = np.array(FP)FN = np.array(FN)df[f"{column_name}_recall"] = TP / (TP + FN)df[f"{column_name}_precision"] = TP / (TP + FP)df[f"{column_name}_correctness"] = 2 * df[f"{column_name}_recall"] * df[f"{column_name}_precision"] / (df[f"{column_name}_recall"] + df[f"{column_name}_precision"])evaluate_correctness("mistral_result")evaluate_correctness("llama2_result")evaluate_correctness("zephyr_result")evaluate_correctness("orca-mini_result")evaluate_correctness("phi_result")?print("|====Model====|=== Recall ===|== Precision ==|== Correctness ==|")print(f"|mistral | {df['mistral_result_recall'].mean():.4f} | {df['mistral_result_precision'].mean():.4f} | {df['mistral_result_correctness'].mean():.4f} |")print(f"|llama2 | {df['llama2_result_recall'].mean():.4f} | {df['llama2_result_precision'].mean():.4f} | {df['llama2_result_correctness'].mean():.4f} |")print(f"|zephyr | {df['zephyr_result_recall'].mean():.4f} | {df['zephyr_result_precision'].mean():.4f} | {df['zephyr_result_correctness'].mean():.4f} |")print(f"|orca-mini | {df['orca-mini_result_recall'].mean():.4f} | {df['orca-mini_result_precision'].mean():.4f} | {df['orca-mini_result_correctness'].mean():.4f} |")print(f"|phi | {df['phi_result_recall'].mean():.4f} | {df['phi_result_precision'].mean():.4f} | {df['phi_result_correctness'].mean():.4f} |")print("|==============================================================|")?df.to_csv("./data/cidr_lakehouse_qa_retrieval_prediction_correctness.csv", index=False)
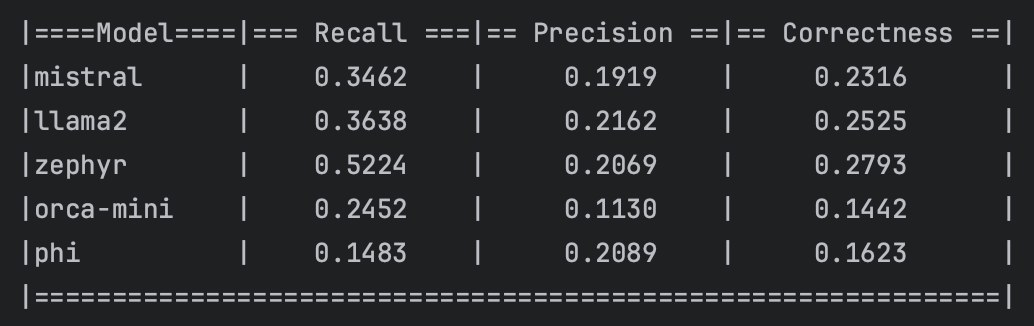
? ? ? ?現在我們有了幾個模型的簡單基準,這可以被視為每個模型處理文檔檢索任務的初步指標。它們是理解哪些模型更善于從給定語料庫中檢索準確和相關信息的基線。你可以在這里[4]找到源代碼。
二、人類在流程中進行反饋
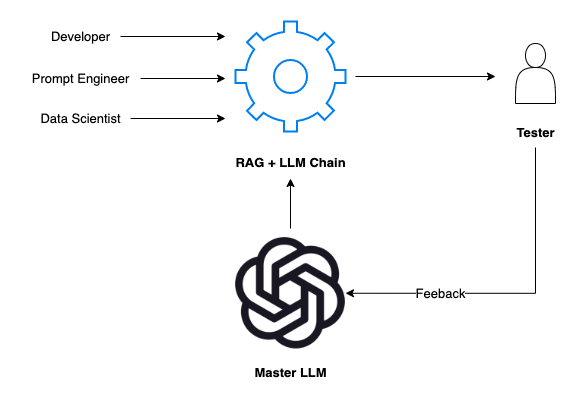
? ? ? 當涉及到通過人類在流程中反饋調整我們的人工智能時,人類測試人員和主LLM之間的協同作用至關重要。這種關系不僅僅是為了收集反饋,而是為了創建一個能夠適應人類輸入并從中學習的響應式人工智能系統。
2.1 互動過程
測試人員的輸入:測試人員參與RAG+LLM鏈,從人類的角度評估其輸出。它們提供人工智能反應的相關性、準確性和自然度等方面的反饋。
對主LLM的反饋:人類測試人員的反饋直接傳達給Master LLM。與標準模型不同,主LLM旨在理解和解釋此反饋,以完善其后續輸出。
主LLM提示調整:有了這個反饋,主LLM會調整我們開發LLM的提示。這個過程類似于導師指導學生。主LLM修改開發LLM對提示的解釋和反應方式,確保了更有效和情境感知的反應機制。
2.2 主LLM的雙重作用
? ? ? 主LLM既是內部開發LLM的基準,也是反饋循環中的積極參與者。它評估反饋,調整提示或模型參數,并從人類互動中“學習”。
2.3 實時自適應的好處
? ? ? ?這一過程具有變革性。它允許人工智能實時適應,使其更加敏捷,并與人類語言和思維過程的復雜性保持一致。這樣的實時適應確保了人工智能的學習曲線是陡峭和連續的。
2.4 改進的周期
? ? ? ?通過這種互動、反饋和適應的循環,我們的人工智能不僅僅是一種工具;它成為一個學習實體,能夠通過與人類測試人員的每次交互進行改進。這種人在流程中的反饋模型確保了我們的人工智能不會停滯,而是進化成一個更高效、更直觀的助手。
? ? ? 總之,“人在回路反饋”不僅僅是收集人類的見解,而是創建一個動態的、適應性強的人工智能,可以微調其行為,更好地為用戶服務。這種迭代過程確保了我們的RAG+LLM應用程序保持在最前沿,不僅提供了答案,而且提供了上下文感知的、微妙的響應,反映了對用戶需求的真正理解。
? ? ?可以在視頻[5]中觀看ClearML如何使用這一概念來增強Promptimizer。
三、運營階段
? ? ? ?過渡到運營階段就像從彩排到開幕之夜。在這里,我們的RAG+LLM應用程序不再是假設實體;他們成為真實用戶日常工作流程的積極參與者。這個階段是對開發階段所有準備和微調工作的試金石。
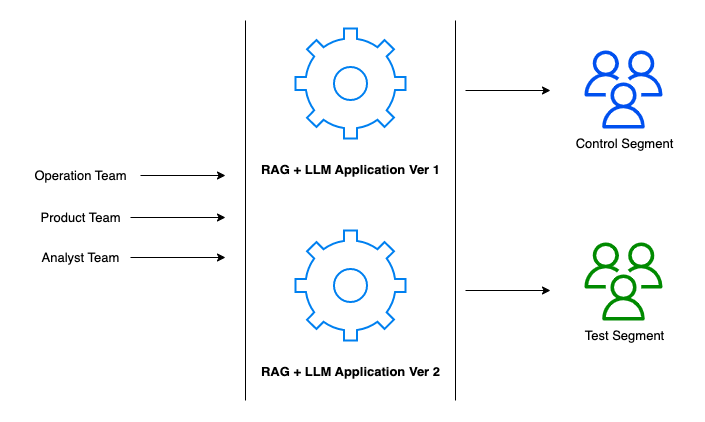
?? ? ? 在這個階段,我們的團隊——運營、產品和分析師——協調部署和管理應用程序,確保我們構建的一切不僅能正常運行,而且能在實時環境中蓬勃發展。在這里,我們可以考慮實施A/B測試策略,以可控的方式衡量應用程序的有效性。
A/B測試框架:我們將用戶群分為兩個部分——控制部分和測試部分,前者繼續使用已建立的應用程序版本(版本1),后者嘗試版本2中的新功能(實際上,您也可以同時運行多個A/B測試)。這使我們能夠收集有關用戶體驗、功能接受度和整體性能的比較數據。
運營推出:運營團隊的任務是順利推出這兩個版本,確保基礎設施穩健,任何版本轉換對用戶來說都是無縫的。
產品進化:產品團隊密切關注用戶反饋的脈搏,努力迭代產品。該團隊確保新功能與用戶需求和整體產品愿景相一致。
分析見解:分析師團隊嚴格檢查從A/B測試中收集的數據。他們的見解對于確定新版本是否優于舊版本以及是否準備好進行更廣泛的發布至關重要。
性能指標:對關鍵性能指標(KPI)進行監控,以衡量每個版本的成功與否。其中包括用戶參與度指標、滿意度得分和應用程序輸出的準確性。
? ? ? ?運營階段是動態的,由連續的反饋循環提供信息,不僅可以改進應用程序,還可以提高用戶的參與度和滿意度。這是一個以監控、分析、迭代為特征的階段,最重要的是,從實時數據中學習。
四、結論
? ? ? ?總之,檢索增強生成(RAG)和大型語言模型(LLM)的集成標志著人工智能的重大進步,將深度數據檢索與復雜的文本生成相結合。然而,我們需要一種適當有效的評估方法和迭代開發策略。開發階段強調定制人工智能評估,并通過人在流程中的反饋增強評估,確保這些系統具有同理心,并適應現實世界的場景。這種方法突顯了人工智能從單純的工具向協作伙伴的演變。運營階段在真實世界的場景中測試這些應用程序,使用A/B測試和連續反饋循環等策略來確保有效性和基于用戶交互的持續發展。
參考文獻:
[1] https://github.com/explodinggradients/ragas
[2]?https://github.com/jmorganca/ollama
[3]?https://blog.duy-huynh.com/build-your-own-rag-and-run-them-locally/
[4]?https://github.com/vndee/dev-notebooks/blob/main/Langchain_Evaluation_With_Dataset.ipynb
[5]?https://www.youtube.com/watch?v=gR__vhOVvy4
[6]?https://medium.com/@vndee.huynh/how-to-effectively-evaluate-your-rag-llm-applications-2139e2d2c7a4

)


)



》)
)








